含缺失標簽的大規模多標簽分類算法
2022-09-06 11:08:48劉依璐曹付元
計算機工程與應用 2022年17期
關鍵詞:分類
劉依璐,曹付元,2
1.山西大學 計算機與信息技術學院,太原 030006
2.山西大學 計算智能與中文信息處理教育部重點實驗室,太原 030006
隨著數據量的爆炸式增長,大規模多標簽分類算法比傳統的多標簽分類算法更符合實際的分類要求。大規模多標簽分類的目標是訓練一個分類器,該分類器可以從大規模的標簽集合中挑選出與實例最相關的標簽子集。目前已被廣泛用于圖像及視頻標注[1-2]、文本分類[3-4]、基因功能預測[5]、臨床醫學[6]等實際任務中。
對于大部分現有的大規模多標簽分類算法[7-10],都要求訓練數據中所有的標簽信息是完整的。然而在實際應用中,用戶提供的標記可能是不完整的。一方面是因為標簽數量多,逐個標注的過程費時費力,因此大部分人工標注者會選擇只標注相對重要的標簽,而丟棄不太重要的標簽。另一方面原因是標注者的知識范圍有限。例如,在維基百科的在線收藏中給文章標記類別時,人工標注者通常只標注他們知道的類別標簽。這就導致了多標簽數據集中標簽的缺失情況。在這種情況下,直接在含有缺失標簽的數據集上訓練傳統的分類器會給分類效果帶來較大的誤差。
因此,許多用于解決含缺失標簽的大規模多標簽分類算法被提出。例如,Tan 等人[11]提出的歸納式解決方法Smile,該方法借助標簽在整個原始數據集中的共現概率來獲取標簽之間的相關性,而后利用它來恢復原始數據集中丟失的信息,然后構建一個線性的分類器,通過一致性和平滑性這兩個基本的假設來優化最終的目標函數。為了便于處理大規模數據,該算法還引入了共軛梯度加速算法及基于樹的最近鄰查找方法進行模型優化。王晶晶等人[12]提出MCWD+傳統多標簽分類器的方法進行缺失標簽的恢復及模型訓練,該算法主要通過迭代地更新每個訓練實例的權重并且引入一個標簽相關性矩陣來恢復訓練數據中的缺失標簽信息,最后采用傳統分類器進行模型訓練。由于該算法采用傳統分類器進行訓練,因此在處理大規模數據時效率并不高。Akbarnejad等人提出的ESMC算法[13]是一種基于嵌入的方法,為充分考慮標簽之間的相關性,采用了非線性嵌入標簽向量的方法,并通過學習特征空間與潛在空間之間的映射進行建模。此外,還借助了偽實例參數化稀疏高斯過程的思想,大大減少了模型的訓練時間,使其能夠處理大規模數據。LSML算法[14]提出一種學習標簽特定特征的新方法,用于帶有缺失標簽的多標簽分類。通過學習高階標簽相關性,從原始標簽矩陣中增加一個新的補充標簽矩陣。然后,學習每個類標簽的標簽特定數據表示,并在此基礎上結合學習到的高階標簽相關性來構建多標簽分類器。MLLCRS-ML 算法[15]提出一種能夠處理含缺失標簽的分類器,該分類器考慮了特定于標簽的特征,同時利用成對的標簽相關性來恢復丟失的標簽,并使用加速近端梯度法來有效地解決潛在的優化問題。
上述方法可以歸類為全局多標簽分類方法,因為它們都假設標簽之間的關系可以在整個實例集上進行建模,然而在實際任務中,標簽之間的相關性只能適用于一部分實例子集,并且很少有相關性是全局適用的。例如,在給雜志中的圖片標注標簽時,“apple”與“fruit”之間的高相關性就不能同時被美食類雜志和科技類雜志共享,而只能被美食類雜志使用。
與全局標簽相關性不同,局部標簽相關性是由部分樣本計算得出的,利用這種相關性進行訓練更加符合實際任務需要。例如:在美食類的雜志中,使用“apple”與“fruit”之間的高相關性;在科技類的雜志中不使用“apple”與“fruit”之間的高相關性,而使用“apple”與“phone”之間的高相關性。為此,本文提出一種基于局部標簽相關性的多標簽分類方法LMC(local label correlations-based multi-label classification algorithm),通過使用局部的標簽相關性進行缺失標簽信息的恢復及低秩分類器的訓練。具體來說,該算法首先對特征空間進行聚類分析,將訓練集中的所有示例劃分到不同的簇中,然后在標簽空間中使用共現次數來估計局部標簽相關性。最后,利用得到的標簽相關性進行缺失標簽的恢復,并將該過程與低秩模型的訓練過程整合至一個統一的框架中,以提升大規模數據上的模型訓練速度。
1 含缺失標簽的大規模多標簽分類算法
本章講述提出的LMC算法。第一部分介紹多標簽分類算法的問題定義。第二部分詳細介紹LMC算法主要處理過程:獲取局部標簽相關性、缺失標簽的恢復及模型訓練。第三部分介紹算法的優化。第四部分介紹算法的測試過程。
1.1 問題定義
在傳統的多標簽分類任務中,X=Rd代表含有d維特征向量的輸入空間,Y={1,-1}q代表含有q個可能標簽的輸出空間,訓練集D={(xi,yi)|1 ≤i≤n} ,其中n表示訓練樣本的個數,xi=(xi1,xi2,…,xid)∈X 表示第i個實例的d維特征向量,yi=(yi1,yi2,…,yiq)∈Y 表示第i個實例相應的q維標簽向量,yi中的取值yij=1 時表示第j個標簽屬于第i個實例,否則表示為yij=-1。多標簽分類任務的目標是從已知的訓練集D中學習一個分類模型h:X→2Y來準確地預測新實例的標簽集合。
讓X=(x1;x2;…;xn)∈Rn×d為實例的特征矩陣,Y=(y1;y2;…;yn)∈{1,-1}n×q為實例的標簽矩陣,對于傳統的多標簽分類來說矩陣Y中的數據沒有缺失,然而在含有缺失標簽的矩陣Y中只有部分相關標簽是已知的,只能得到一個不完整的標簽矩陣C=(c1;c2;…;cn)∈{1,0,-1}n×q,其中ci=(ci1,ci2,…,ciq),當cij=1 時表示第j個標簽屬于第i個實例,cij=-1 時表示第j個標簽不屬于第i個實例,cij=0 則表示第j個標簽缺失。此外,本文中采用的標簽矩陣C是高維的,即C中的q值較大。
1.2 LMC算法
在含有缺失數據的大規模多標簽分類問題中,主要面臨兩個問題:一方面是較大的數據量[16-20],另一方面是訓練數據中存在缺失的標簽信息[21-24]。在這種情況下,采用傳統的多標簽分類器不僅會降低分類器的分類準確度,還會產生較大的時間和存儲代價。為了解決上述兩個問題,本文提出一種基于局部標簽相關性的LMC算法,該算法首先對訓練樣本的特征域進行聚類分析,將原始數據集分成k個數據簇,使得同一個數據簇中的樣本具有相似的標簽相關性;然后在每個數據簇中挖掘標簽之間的局部相關性,并利用得到的相關性進行缺失標簽信息的恢復;最后為每個數據簇訓練一個低秩的分類器,并將標簽的分類任務與缺失標簽的恢復任務進行集成,采用迭代優化的方式得到最終的分類器。在預測階段,給出一個新樣本,利用與樣本距離最近的數據簇對應的局部模型進行標簽預測。圖1 簡明扼要地說明了LMC 算法的框架,在下面的章節中將對該算法進行詳細闡述。

圖1 算法框架Fig.1 Architecture of algorithm
1.2.1 獲取局部標簽相關性
不同的實例會產生不同的局部標簽相關性。因此,本文提出的算法不再從整個數據集中挖掘標簽關系,而是在相似的樣本中尋找標簽之間的相關性,舍棄掉不相似的樣本,以減少其對標簽關系獲取準確度的影響。為了準確地獲取標簽之間的相關性,LMC 算法采用聚類的方式來挖掘數據之間的局部標簽相關性信息。由于標簽集合中有信息的缺失,直接對其進行聚類分析會影響相關性獲取的準確度。鑒于標簽中包含的信息來源于特征域,而且特征域中沒有信息的缺失,因此LMC算法選擇對特征域進行聚類分析。同時也可以在一定程度上避免因數據缺失產生的異常點及類別不均衡情況。
本文在實驗過程中選擇k-means 聚類算法來劃分訓練數據。對樣例集合進行聚類后,訓練數據被分為k個組{D1,D2,…,Dk},使得具有相似標簽相關性的實例分到同一組中。然后在每個數據簇Di中挖掘局部的標簽相關性。詳細計算過程如下:
以標簽l1與l2之間的相關性L(l1,l2)為例:
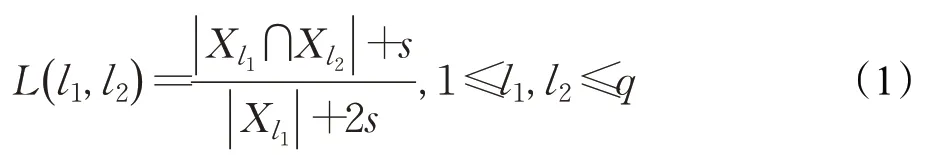
其中,Xl1表示被標簽l1標注的實例集合,|Xl1|表示被標簽l1標注的實例數目,Xl2、|Xl2|與Xl1、|Xl1|同理。|Xl1∩Xl2|表示同時被標簽l1及l2標注的實例數目。s是引入的一個平滑參數,可以在一定程度上避免由于標簽不平衡所產生的極端情況。例如,有100 篇文章,其中10 篇本應標注為足球和鞠蹴,而其他文章標記為足球。但此時由于文化差異,這10 篇文章中的鞠蹴標簽全部丟失,即同時被標注為足球和蹴鞠的樣本個數為0,則在不考慮s計算相關性時,足球和鞠蹴之間的相關性估計將為0,然而這兩個標簽是存在關聯的。因此,通過設置s>0,就可以在一定程度上避免這種情況。
用L(· ,l2)=(L(l1,l2),L(l2,l2),…,L(lq,l2)) 表示所有標簽與l2標簽之間的相互關系。進一步地,將計算出的L(· ,l2)向量進行歸一化處理,使得向量各元素之和為1,此時得到的所有相關性值在[0,1]區間內,因此,可以將歸一化之后的L(· ,l2)中的值視為其余標簽對某標簽的貢獻率。同樣以標簽l1與標簽l2的相關性為例,具體的歸一化過程如下:
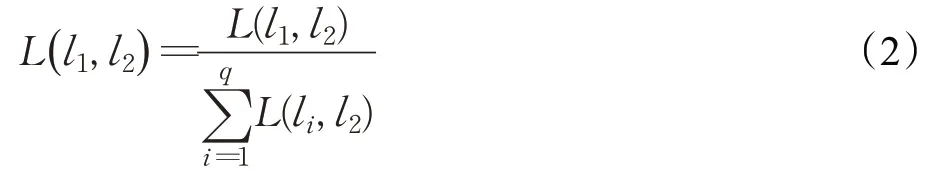
最終,所有的標簽相關性構成相關性矩陣L。
1.2.2 缺失標簽的恢復
在獲取了局部的標簽相關性之后,就利用它對缺失標簽進行恢復。恢復的基本原則有兩點:
(1)在原始數據集中存在的標簽在恢復的數據集中仍然存在,因為這部分信息是準確無誤的,因此需要保留這部分信息。
(2)在進行不同樣本標注時,具有強相關性的標簽的取值相近,反之亦然。
因此,LMC中具體的標簽恢復過程如下:
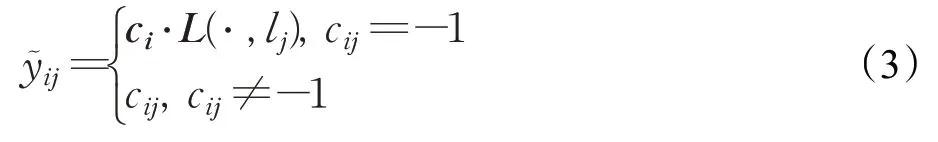
其中,是對第i個實例的第j個標簽恢復后的值,ci表示含缺失標簽數據集中第i個實例的標簽向量,L(·,lj) 表示其余標簽與第j個標簽之間的相關性向量。采用式(3)可以很好地保證兩點基本準則。
最后選擇閾值0.5 來確定最終的值,如果的值大于0.5 時,在C中cij的值變為1;否則在C中cij的值變為-1。并將恢復好的標簽矩陣記為Y~ ∈{-1,1}n×q,同時將其作為新的標簽集。
1.2.3 模型訓練
在處理在現有的解決方案中,許多算法都將分類任務與缺失標簽的恢復任務分離開來,但是在處理大規模數據時會增加模型的訓練時間。因此,LMC算法將這兩個任務進行結合,在恢復數據的同時進行多標簽分類。
在使用傳統的線性分類器f(x;Z)=xZ(Z∈Rd×q)時,模型的訓練誤差通常表示為:
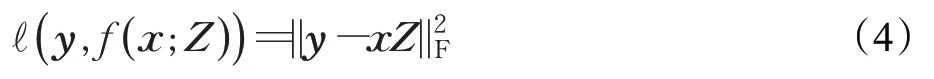
但直接在大規模數據集中使用傳統線性分類器的訓練時間會很長。基于以下觀察:盡管多標簽分類問題中的標簽數量可能很大,但通常存在顯著的標簽相關性,這意味著輸出空間是低秩的,LMC算法選擇將建模所需的有效參數數量減少到遠小于d×q,即通過對矩陣Z的低秩分解限制Z僅學習少量潛在因素來捕捉標簽與特征之間的關系。這樣不僅能有效控制過擬合,而且還能提高在大規模數據上的計算速度。具體做法如下:
在每個數據簇Di中,先利用標簽之間的相關性進行缺失數據的恢復,后將恢復后的標簽矩陣投入分類模型中進行訓練,再將模型訓練的結果作為新的輸入重新進行標簽恢復和訓練。在分類模型中,采用低秩分解技術將矩陣Z分解為兩個秩為r(r?q) 的低秩矩陣W∈Rd×r和H∈Rq×r,使得Z=WHT。因此,模型的目標函數更新如下:
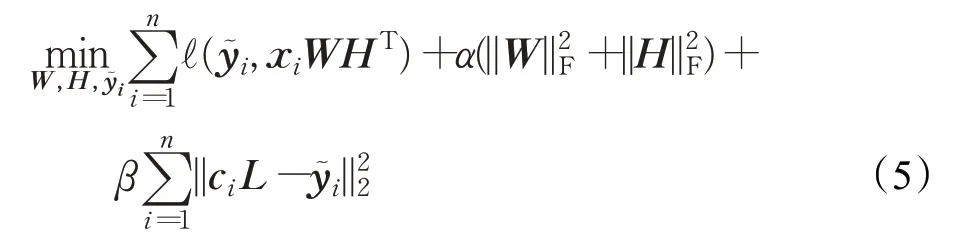
其中,表示第i個實例對應的恢復后的標簽向量;α及β為調節因子,α用來進行低秩控制,防止模型的過擬合,β用來約束數據恢復的準確度。
在式(5)中,第一項用來計算模型的訓練誤差;第二項實現對參數的低秩控制;第三項為標簽恢復的誤差項,旨在使用標簽之間的局部相關性進行缺失數據的恢復,若某標簽缺失,且該標簽與已存在標簽之間的相關性越大,則該標簽被恢復為1的概率就越大,反之亦然。
1.3 優化
針對式(5),LMC算法采用迭代最小化的方式進行優化。為了便于運算,首先將式(5)簡化為矩陣形式。
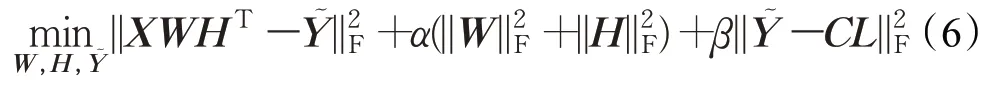
步驟1固定W、Y~ ,求H,則目標函數可以轉化為:
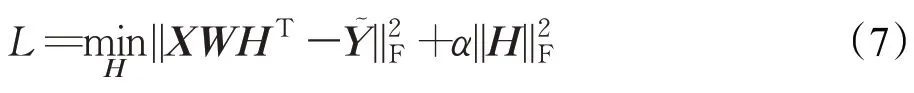
接下來對上式進行求導,可得:
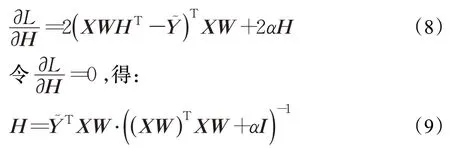
其中,I為單位矩陣。
步驟2固定H、,求W,則目標函數可以轉化為:
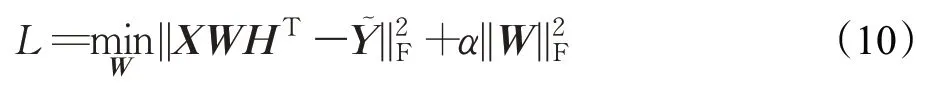
與步驟1方法類似,令該式的導數為0,得到:
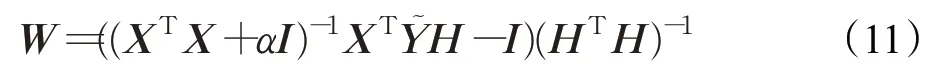
但是在計算W時,涉及大量的大規模矩陣相乘,計算速率會大大降低。因此,LMC 算法選擇采用其他的方法進行優化。共軛梯度法是非常重要的一種優化算法,該方法所需存儲量小,穩定性高,收斂速度快,是求解大型線性及非線性方程組最有用的方法之一。結合上述分析,LMC 算法采用共軛梯度算法對式(10)進一步進行優化。
首先需要對式(10)求解出一階導數和二階導數:
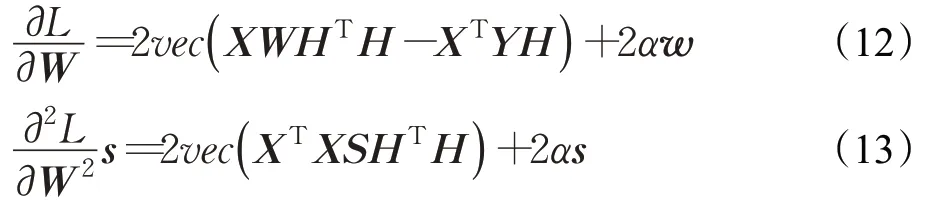
其中,w=vec(W),s=vec(S),vec(*)代表矩陣的向量化操作,S是一個d×q維的任意矩陣。
接下來就可以直接使用共軛梯度法進行問題的求解。具體的執行過程可參考相關文獻[13]。
步驟3固定H、W,更新Y~ ,則目標函數可以轉化為:
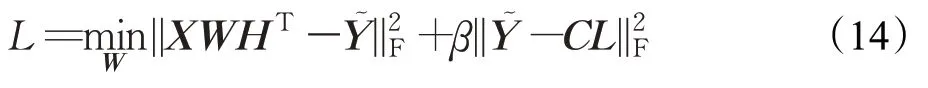
與步驟1方法類似,令該式的導數為0,得到:

然后,對中原本為1和-1的數據進行恢復,以保證原始數據集中的信息不發生丟失。
1.4 模型預測
在優化完成之后就可以得到最優的W和H,記為W*,H*。對于待預測的樣本特征向量xtest,首先計算距離其最近的聚類簇,然后利用該聚類簇的局部分類器進行預測,公式如下:

上述利用局部標記相關性的LMC算法的詳細步驟如算法1所示。
算法1LMC算法
輸入:訓練集D=[X,C],測試樣本xtest,聚類個數k,平衡因子α、β,最大迭代次數max_iter。
輸出:測試樣本的預測標簽向量ytest。
1.對訓練樣本的特征域進行k-means 聚類分析,得到k個小聚類簇{D1,D2,…,Dk}
2.fori=1 tokdo
3.將聚類簇Di作為訓練樣本
4.初始化Y~ =C,隨機初始化矩陣W、H,max_iter=100
5.forj=1 tomax_iterdo
6.根據式(9)更新H
7.將式(12)、(13)作為共軛梯度算法的輸入更新W
8.根據式(14)更新Y~
9.end for
10.end for
11.計算各聚類簇中心與xtest的距離
12.挑選距離最近的聚類簇對應的分類器,得到W*,H*
13.根據式(16)得到預測的標簽向量ytest,并返回
2 實驗
這部分主要評估LMC 算法的有效性。將LMC 算法在7 個多標簽數據集進行實驗,并和現有的5 種相關算法進行比較和分析,從而來驗證LMC 算法的可行性和有效性。
2.1 實驗設置
2.1.1 數據集
本文將LMC 算法在7 個來自不同領域的數據集上與其他算法進行對比實驗。實驗中用到的數據集的詳細信息如表1所示。
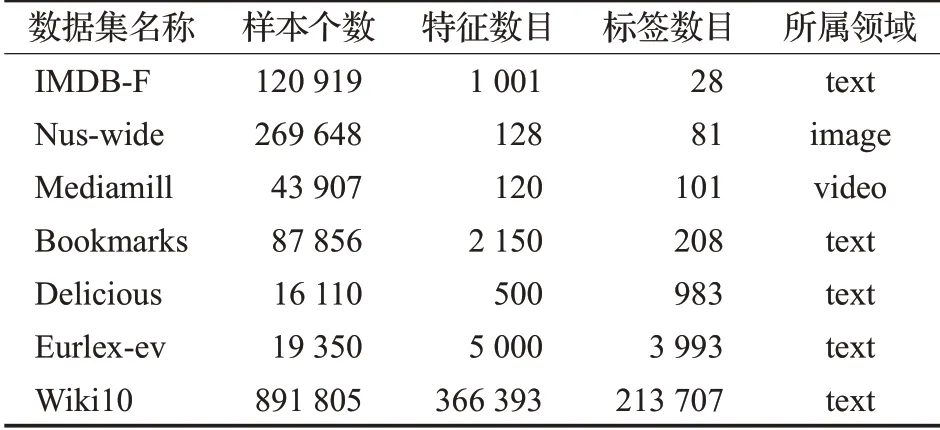
表1 數據集描述(按標簽數目升序排列)Table 1 Description of data sets(sorted in ascending order of number of labels)
在實驗過程中,對于每一個數據集,將其隨機劃分為訓練集(占70%)和測試集(占30%),此過程反復進行5次,最后將這5次實驗結果的均值作為最終的結果。
2.1.2 評價指標
現有評價多標簽分類性能的指標主要分為基于實例的評價標準、基于標簽的評價標準和基于排序的評價標準,詳細描述可參考相關文獻[25]。本文從中選擇其中5 個常用的評價指標來對比各算法的性能,分別為P@1、P@3、P@5、average-AUC 和coverage。前三種標準是基于實例的評價標準,用來評估在測試集中預測值較高的幾個標簽的分類性能,coverage則用來評估整體的分類性能,average-AUC 屬于基于排序的評價標準,從標簽排序的角度來衡量分類性能。對于前4 種評價指標來說,指標的取值越大,則表明算法的性能越好;對最后一個評價指標而言,取值越小則算法的性能越好。
2.1.3 參數設置
本文將提出的LMC 算法與現有的5 種多標簽分類算法進行比較,這些算法都可以用來解決含有缺失標簽的大規模多標簽分類問題。每個算法都根據原論文建議配置了相應的參數。
(1)Smile[11]:該算法利用標簽之間的相關性進行缺失標簽的估計,并建立線性的分類器進行模型的訓練和對未知樣本的標簽預測。各個參數的具體設置詳見文獻[11]。
(2)MCWD+MLKNN[12]:該算法將標簽恢復方法MCWD與傳統多標簽分類算法MLKNN進行結合用來進行缺失數據的恢復,且可以擴展至大規模數據集上。其中MLKNN算法中近鄰個數的取值設置為10,平滑系數取值設置為1,其余各參數的具體設置詳見文獻[12]。
(3)ESMC[13]:該算法使用隨機方法非線性嵌入標簽向量,以解決基于嵌入式的學習方法中尾標簽預測不準確的問題。該方法在處理丟失標簽及大規模數據集方面具有良好的表現。各個參數的具體設置詳見文獻[13]。
(4)LSML[14]:該算法提出一種學習標簽特定特征的新方法,用于帶有缺失標簽的多標簽分類。通過學習高階標簽相關性,從原始標簽矩陣中增加一個新的補充標簽矩陣。然后,學習每個類標簽的標簽特定數據表示,并在此基礎上結合學習到的高階標簽相關性來構建多標簽分類器。各個參數的具體設置詳見文獻[14]。
(5)MLLCRS-ML[15]:該算法提出一種能夠處理含缺失標簽的分類器,該分類器考慮了特定于標簽的特征,同時利用成對的標簽相關性來恢復丟失的標簽,并使用加速近端梯度法來有效地解決潛在的優化問題。各個參數的具體設置詳見文獻[15]。
(6)LMC:對于本文提出的算法,k-means中聚類個數的取值在[50,150]內進行選擇,平衡因子α的取值在[0.5,1.5]范圍內進行選擇,β取值在[0.5,1.0]之間,低秩參數r的取值在[30,300]內進行選擇,迭代參數max_iter的取值設為50。
以上參數均采用五折交叉驗證方法選擇適用于各數據集的最優值。
2.2 參數影響
本節對LMC 算法中的五個重要參數:k-means 聚類中的類簇個數k,平衡因子α,平衡因子β,低秩約束參數r及最佳迭代次數max_iter展開研究。每次僅改變一個參數的取值,其余參數保持不變。
2.2.1 聚類個數k 的影響
在LMC 算法中,聚類個數k用來確定k-means 聚類的個數,進一步影響標簽相關性的獲取細致度。本文將k的取值從1 取到250,步長為50,并在LMC 算法上運行了10 次,然后取平均值作為最終結果。在各個數據集上隨聚類個數變化時的Precision@1取值變化如圖2所示。
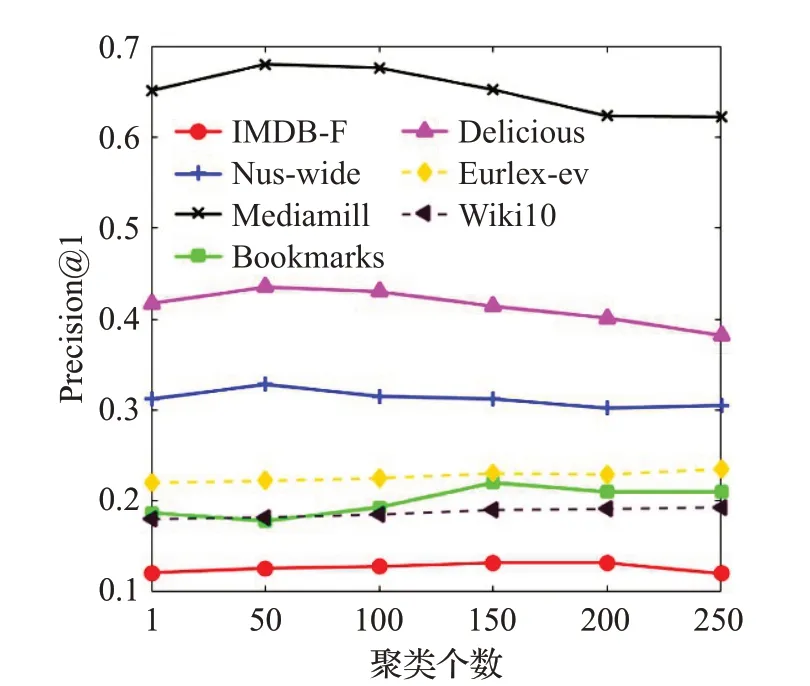
圖2 聚類個數的影響Fig.2 Influence of number of clusters
從圖2中可以看出當聚類簇個數為1時,Precision@1取值較低,說明此時算法的分類性能并不是最優,因為此時僅僅利用了全局的標簽相關性。隨著聚類個數的增加,算法的性能有所提升。但是當到達某個最優聚類個數之后算法的性能有所下降,這是因為當聚類個數過多時,每個聚類簇中的樣本個數過少,無法準確捕捉標簽之間的相關性。而且當聚類個數較多時,LMC 算法訓練的分類器個數也較多,訓練時間也會明顯增加。鑒于圖2顯示的結果,本文建議聚類個數的設置為50/100/150。在下列實驗中,LMC算法在各數據集中的聚類個數取值均以該圖為指導進行設置。
2.2.2 平衡因子α 的影響
平衡因子α用來控制模型的低秩性,以避免模型出現過擬合及降低模型的復雜度。本文設置α的取值從0至2.0,步長為0.5,并將10 次實驗結果的平均值作為最終結果。圖3展示了LMC算法在各個數據集上隨平衡因子α變化時的Precision@1取值。
從圖3 中可以看出當α取值為0 時,Precision@1 取值較低,因為此時并沒有對分類器施加低秩約束,而且模型的復雜度非常高。當α取值增加時,算法的性能有所提升,這是因為模型的復雜度得以降低,過擬合的可能性也得到了減少,最終使得模型的處理效率得到了提升。鑒于圖3結果,本文建議α參數取值大于0.5。
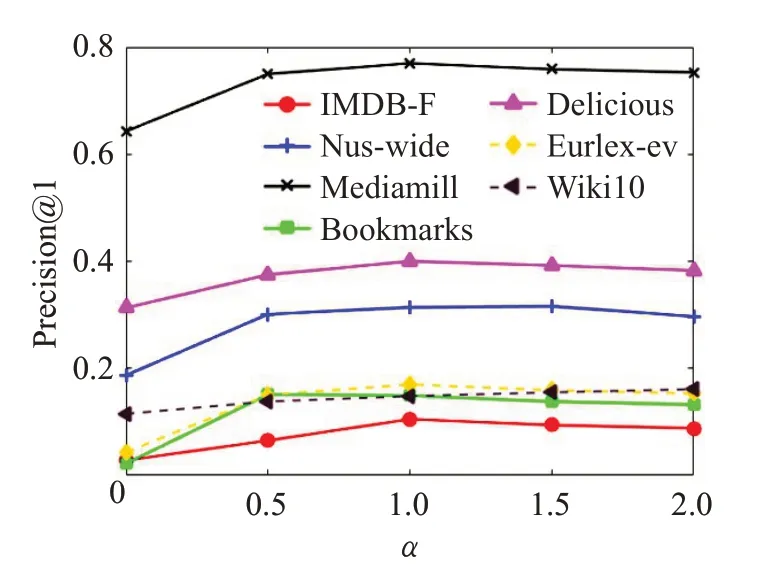
圖3 平衡因子α 的影響Fig.3 Influence of balance factor α
2.2.3 平衡因子β 的影響
平衡因子β用來約束缺失標簽恢復的準確度。該參數選擇與參數α同樣的取值范圍進行實驗。給定平衡因子β不同的取值,LMC 算法在各數據集上Precision@1的變化如圖4所示。
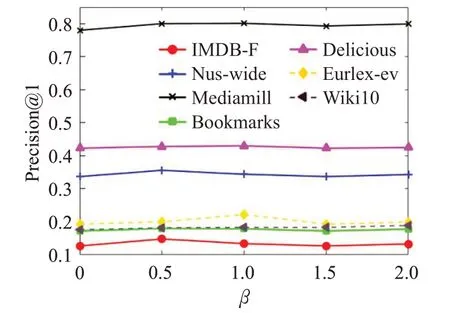
圖4 平衡因子β 的影響Fig.4 Influence of balance factor β
從圖4可以看出,當β取值為0時,算法并沒有進行缺失標簽恢復的情況下,而是直接使用含缺失的標簽進行訓練,因此算法的性能并沒有達到最優。隨著取值的增大,該算法會更加注重缺失標簽的恢復,性能逐步提升。但是β取值過大時,算法會約束恢復后的標簽過分接近含缺失標簽取值,此時,算法的性能會逐步下降,設置退化為β取值為0的性能。因此,本文建議β參數的取值在[0.5,1.0]之內。
2.2.4 低秩參數r 的影響
參數r用來表示低秩矩陣的維度。該參數的取值范圍從標簽個數q的1/10 提升至標簽個數的取值。同樣將10次實驗結果的平均值作為最終結果。
圖5 展示了算法隨著低秩的維度約束r變化時的性能變化情況,橫坐標表示低秩約束的維度。在不同的數據集中,數據的冗余度及標簽相關的程度不同,因此算法在該變量上的最優取值涉及范圍較廣。同樣,r的取值不能過大也不能過小,過大會破壞標簽的低秩約束,而且也會增加模型訓練負擔,過小則不能準確捕捉到標簽之間的相關性。基于圖5的實驗分析,本文推薦r參數取值在標簽個數較少的數據集上在總標簽數的1/2~1/4 之間選擇,在大規模數據集上則在總標簽數的1/8~1/10之間選擇。
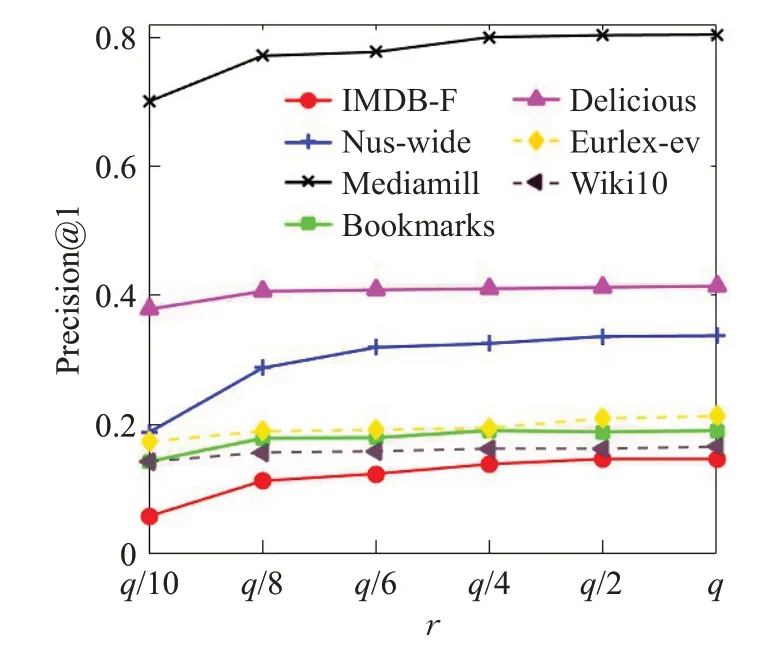
圖5 低秩參數r 的影響Fig.5 Influence of low-rank parameter r
2.2.5 迭代次數max_iter 的影響
參數max_iter為模型的訓練截止條件。該參數的取值范圍從1 逐次增至150。圖6 展示了算法增加迭代次數時目標函數的收斂情況,在其他數據集上的實驗結果也是類似的。
從圖6 可以看出,在迭代次數為50 之前,算法在以上四個數據集均達到收斂,具有較快的收斂速度。基于圖6,推薦max_iter取值設為50。
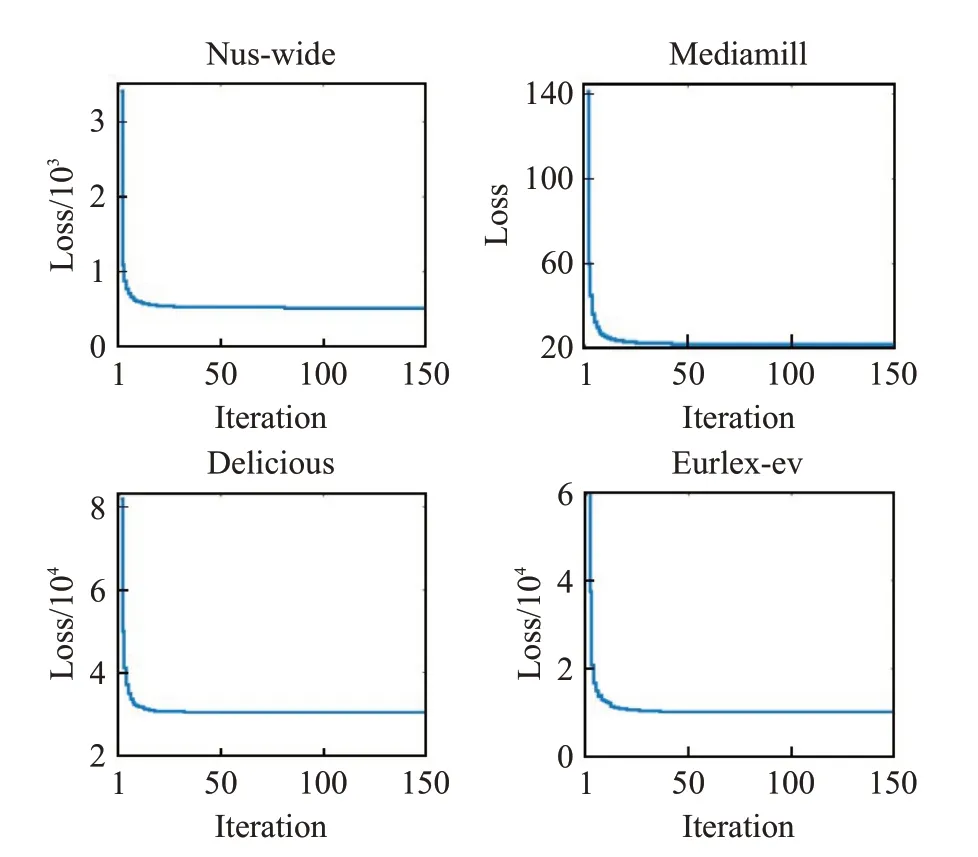
圖6 迭代次數max_iter 的影響Fig.6 Influence of number of iterations max_iter
2.3 實驗結果
本文僅展示缺失率為10%(缺失的標簽個數占總標簽個數的10%)時各對比算法在不同數據集上的實驗結果,如表2~6 所示。其中最優的實驗結果已用粗體標識出來,“—”表示因實驗花費時間過長暫未取得實驗結果,括號中的數字表示各算法在同一數據集上的結果排名。
從表2~6 中可以看出,在35 組(5 個評價指標×7 個數據集)對比實驗結果中,LMC算法共有27次排名第一(含并列),7 次排名第二(含并列),排在第三的共有1次。這說明提出算法在缺失率為10%時分類的準確度上要優于其余五種算法,其他缺失率設置下的分類性能也類似。
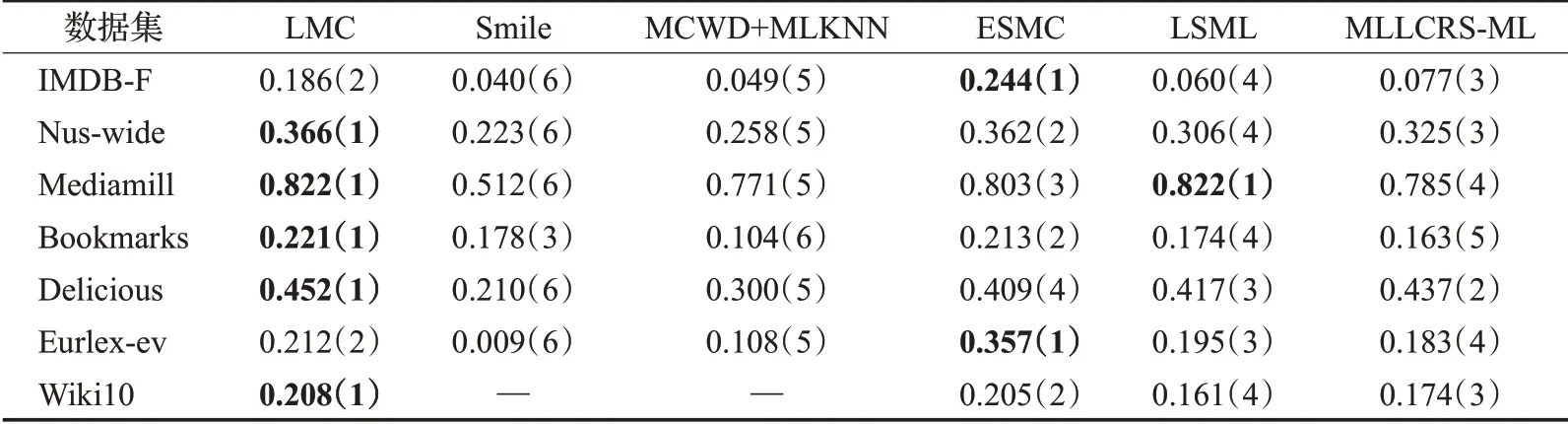
表2 在P@1下的實驗結果“均值(排名)”(取值越大越好)Table 2 Experimental result on P@1“mean(ranking)”(the larger the value,the better)
2.4 分類結果分析
為了分析不同算法在不同數據集中的性能,使用Friedman 檢驗進行性能分析。在實驗中,總共有6 種方法和7個數據集并分別將其記為k=6,N=7,Rj表示第j個算法在所有數據集上的平均排名,則Friedman統計值服從自由度為6-1=5 的χ2分布。表7 顯示了在顯著性水平α=0.05 上每個評估標準的FF取值。如表7 所示,所有的評估值都超過了臨界值,因此這些方法的性能是不同的。
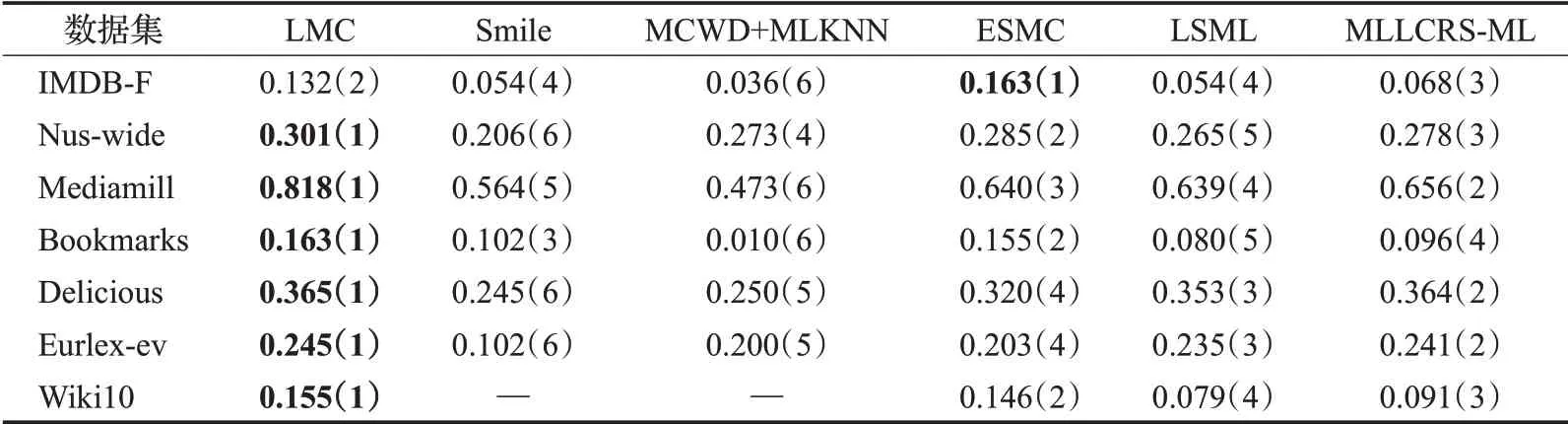
表3 在P@3下的實驗結果“均值(排名)”(取值越大越好)Table 3 Experimental result on P@3“mean(ranking)”(the larger the value,the better)
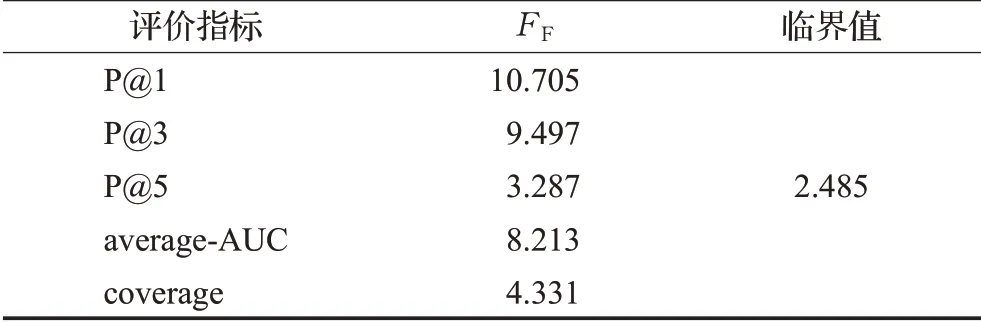
表7 在每個評價標準下的Friedman統計值Table 7 Friedman statistics FF on each evaluation criteria
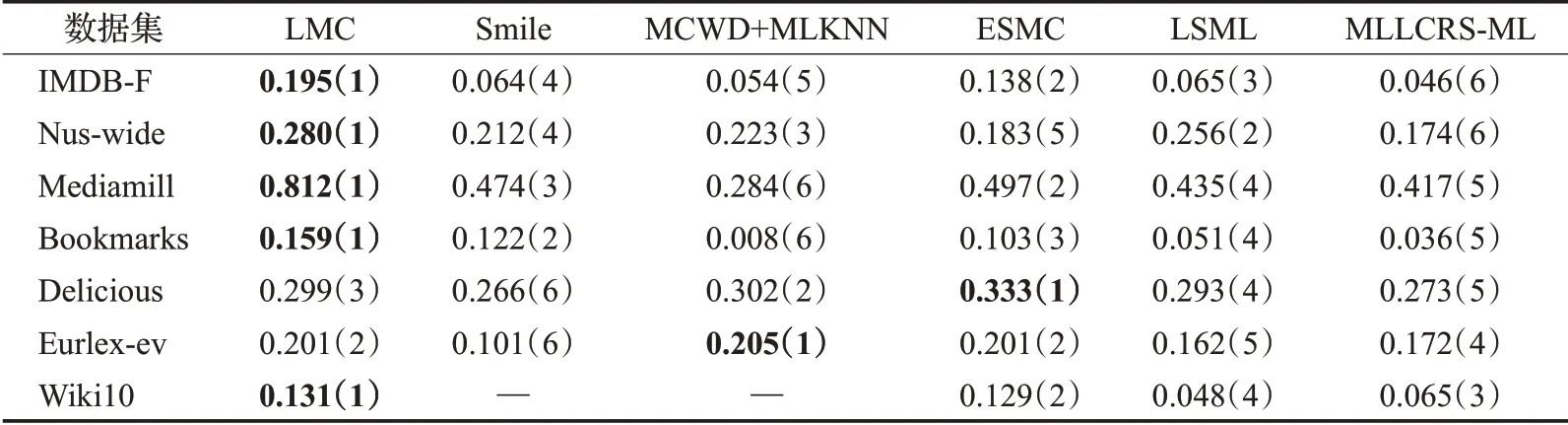
表4 在P@5下的實驗結果“均值(排名)”(取值越大越好)Table 4 Experimental result on P@5“mean(ranking)”(the larger the value,the better)
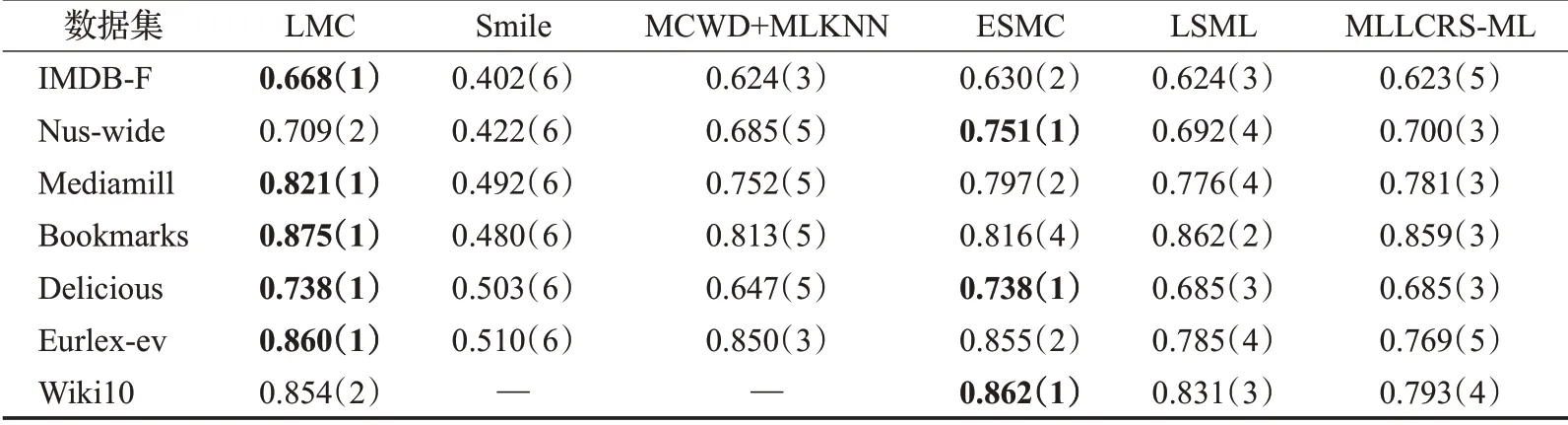
表5 在average-AUC下的實驗結果“均值(排名)”(取值越大越好)Table 5 Experimental result on average-AUC“mean(ranking)”(the larger the value,the better)
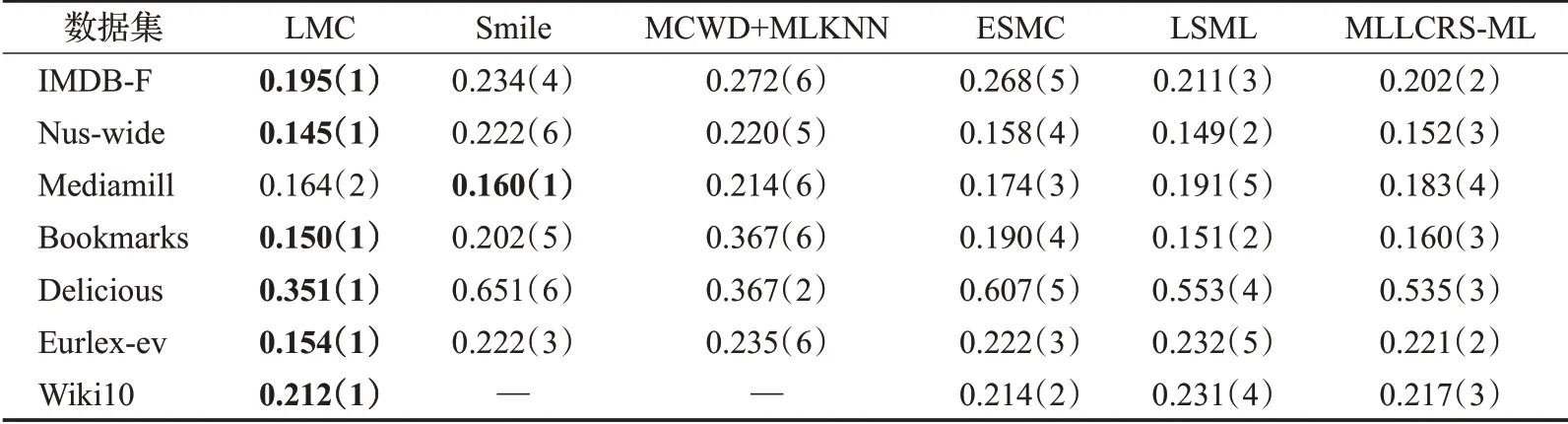
表6 在coverage下的實驗結果“均值(排名)”(取值越小越好)Table 6 Experimental result on coverage“mean(ranking)”(the smaller the value,the better)
之后,使用Nemenyi 檢驗進一步分析所有比較方法之間的相對性能,它可以顯示提出的LMC 算法是否能比比較算法實現更好的性能。臨界值域(CD)由計算。通過查表,可以得到qα=2.850。然后,可以計算出CD=2.850。如果LMC的平均排名與另一種方法在所有數據集上至少有一個CD 差異,則這種方法的性能明顯不同于LMC。圖7總結了每個評估標準的CD圖。在圖7中,可以看到LMC的水平段在所有評估標準中與除ESMC 之外的其他算法沒有重疊,因此這意味著LMC 與其他算法之間存在顯著差異。ESMC與LMC差別不大的原因是兩個算法都是用標簽之間的相關性進行缺失標簽恢復,并且都存在對長尾標簽的處理。此外,通過圖7 可以得出結論,LMC 在所有評估指標上都優于其他算法。
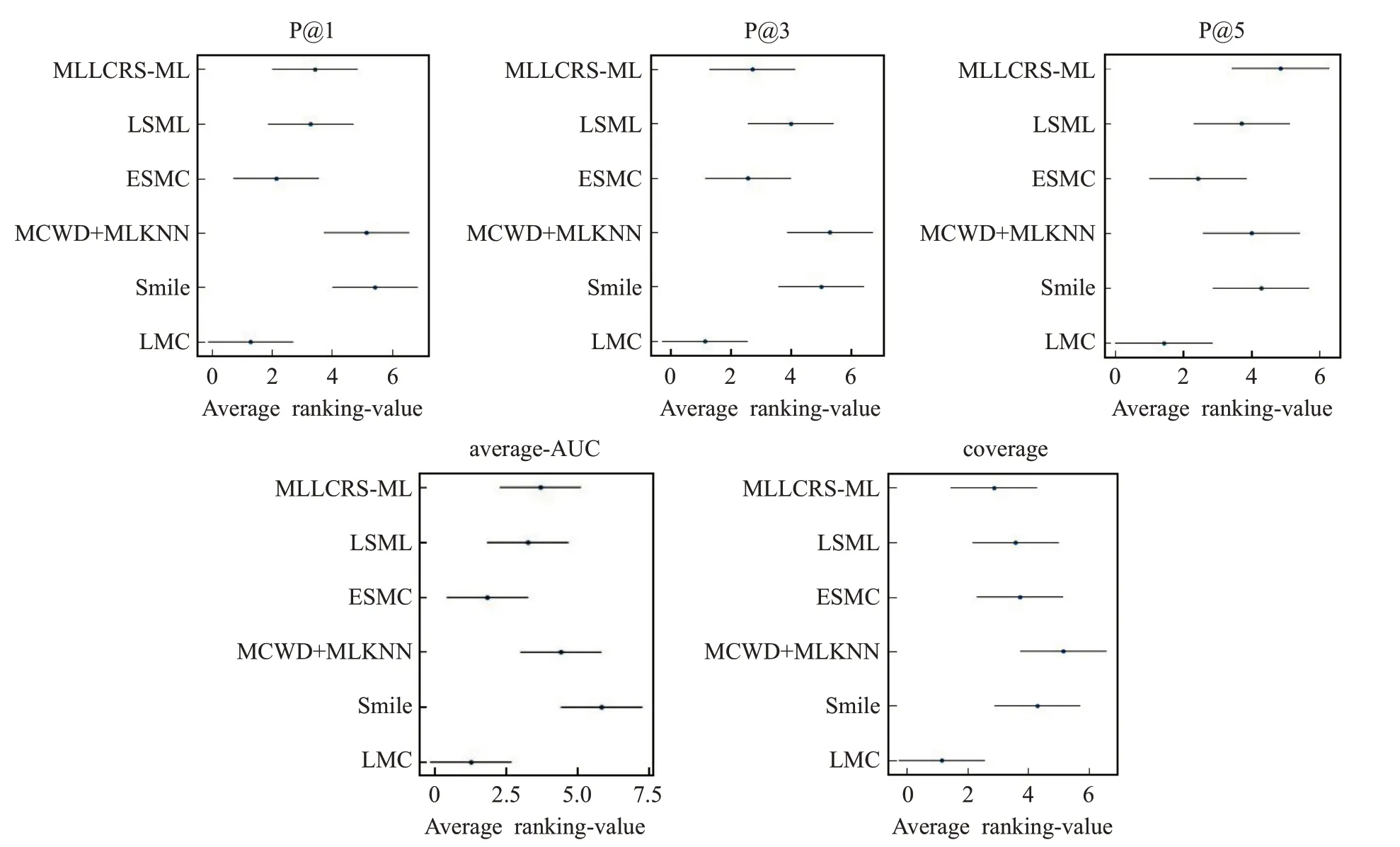
圖7 在每個評價標準上的CD圖Fig.7 CD diagrams on each evaluation metric
2.5 算法時間復雜度
LMC算法主要包括聚類和迭代兩個部分。k-means聚類的時間復雜度為O(n),在迭代中,主要時間成本是計算變量W,時間復雜度為O(r(nq+nr+rq))。因此,總的時間復雜度為O(nrq+nr2+qr2+n) 。為了分析LMC算法的訓練速度優勢,表8總結了所提出方法和比較方法的時間成本,一般來說,n?d>q>r。為了便于比較,此處取每個算法復雜度的最高項進行對比,由于MCWD+MLKNN算法涉及n3,因此該算法的時間復雜度最高。Smile涉及n2,LSML中涉及d3,MLLCRS-ML中q2dn值大于ESMC 中的nq3,ESMC 中的r為三次方,而在LMC 中為二次方。因此,所提出的LMC 方法的復雜性優于其他方法。

表8 各算法的時間開銷Table 8 Time costs of different methods
通過上述大量實驗的比較分析,充分體現了LMC算法在恢復缺失數據和大規模多標簽數據分類方面的優勢。
3 結束語
本文提出了一種基于局部標簽相關性的多標簽分類算法,用于解決在大規模數據集上含有缺失標簽的分類問題。該方法首先通過在特征空間上應用聚類分析,將原始數據集分解為多個數據簇,后利用隱藏在數據簇內部的局部標簽相關性來進行缺失標簽的恢復及局部模型的訓練。本文在7 個來自不同領域的基準數據集上進行了大量實驗,結果表明本文提出算法在處理大規模數據及缺失數據上具有一定的優越性。對于未來的工作,將尋求一種更合適的方法將具有相似標簽相關性的多標簽實例進行聚類。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
