基于知識蒸餾的YOLOv3算法研究
2022-09-06 11:08:52李姜楠劉競升王洪剛
計算機工程與應用 2022年17期
李姜楠,伍 星,劉競升,王洪剛
重慶大學 計算機學院,重慶 400000
人工智能的快速發展使深度學習技術廣泛應用于目標檢測領域,2014 年Girshick 等人首次將深度學習應用于目標檢測,提出R-CNN[1]二階段檢測模型,并在此基礎上引入感興趣區域池化(RoI 池化)得到Fast R-CNN[2],然后使用區域提取網絡結構(RPN)代替選擇性搜索算法生成候選框進一步得到Faster R-CNN[3]。Lin等人提出特征金字塔網絡(FPN[4]),通過融合低層特征信息和高層語義信息,提升了小目標檢測效果。Cai等人提出Cascade R-CNN[5],通過不斷提高并交比(IoU)閾值,在保證樣本數不減少的情況下訓練出高質量檢測器。針對二階段檢測模型預測速度較慢的問題,2016 年Redmon 等人提出YOLO[6]一階段檢測模型,然后在此基礎上將全連接層替換成卷積層,并利用聚類算法獲得先驗框而提出YOLOv2[7],接著使用更強大的特征提取網絡并引入類FPN結構提出YOLOv3[8]。鄒承明等人[9]在YOLOv3 基礎上引入Focal loss 和GIoU loss,提高了YOLOv3對小目標的檢測能力。Bochkovskiy等人將CSP 結構引入特征提取網絡并在特征融合層中使用PAN結構而提出了YOLOv4[10]。Liu等人提出了可在多尺度特征圖上檢測的SSD[11]模型,彌補了YOLO在小物體檢測上精度不佳的問題。Lin等人提出RetinaNet[12],通過引入Focal loss[12]消除了大量背景造成數據不平衡的影響,使一階段檢測模型獲得了接近二階段模型的精度。隨著目標檢測模型開始向移動端部署,研究人員將目光轉向了參數少且內存占用低的輕量級模型。知識蒸餾作為一種有效的模型壓縮方法,逐漸受到研究者的青睞。
自2015年Hinton等人提出知識蒸餾[13]后,大量研究者對圖像分類領域的知識蒸餾展開研究,但在目標檢測上的研究依舊較少。Chen 等人[14]打破了這個僵局,以Faster R-CNN為檢測網絡,對特征提取層,分類損失和回歸損失同時展開蒸餾,提升了二階段目標檢測模型的精度。Wang等人[15]針對全局特征圖的蒸餾算法會引入大量背景信息的問題,提出使用信號圖(mask-map[15])將教師網絡傳遞的知識限制在真實框附近,獲得了更高的精度,但基于二階段檢測模型蒸餾出的網絡因速度依然較慢難以在移動端部署。Mehta等人[16]將知識蒸餾應用于一階段檢測模型,通過類FPN 結構優化學生網絡架構,加入無標簽數據集進行訓練,蒸餾時使用特征圖非極大值抑制算法(FM-NMS)過濾冗余框,在tiny-yolov2基礎上mAP 提升了14 個百分點,但蒸餾的提升效果有限,mAP只提升不到1個百分點。
2019年,管文杰等人[17]將知識蒸餾引入Cascade RCNN,將二、三階段檢測器回歸分類的結果作為“軟目標”加入損失函數中進行蒸餾,達到和四階段檢測相當的精度。同年,溫靜[18]將知識蒸餾的Attention轉移算法與歸一化后的損失函數應用于智能車駕駛環境理解中的目標檢測任務,有效提高了小網絡的準確性。
針對目前在一階段目標檢測器上蒸餾的研究較少,且蒸餾提升效果有限的情況,本文以YOLOv3為檢測網絡,提出將信息圖作為監督信號在特征提取層和特征融合層上同時展開蒸餾。本文的貢獻點如下:(1)將信息圖作為監督信號對學生網絡展開蒸餾。信息圖是教師網絡傳遞的知識重要性的分布圖,不僅過濾掉了教師網絡傳遞的背景信息,且強化了學生網絡對教師網絡重點知識的學習。(2)在特征提取層和特征融合層上同時展開蒸餾。在特征提取層上蒸餾后,特征融合層上的蒸餾對前者的蒸餾有一個校正作用,可以進一步提升蒸餾效果。
1 目標檢測模型的蒸餾算法
Chen 等人[14]提出對二階段目標檢測器Faster R-CNN 進行蒸餾,教師網絡和學生網絡具有相同的檢測框架,但是學生網絡會選擇輕量級的特征提取網絡(Backbone)。如圖1所示,圖片分別輸入至教師網絡和學生網絡,在特征提取層(hint)、分類結果(classification)、回歸結果(regression)上產生不同的輸出。通過度量教師網絡和學生網絡輸出的差距,構建蒸餾損失。將蒸餾損失加上檢測的真實損失(Detection loss)構成總損失,計算方式如式(1)所示:
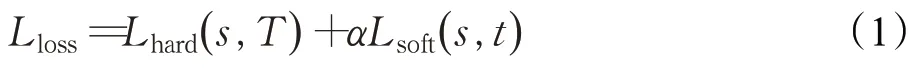
式中,Lloss為總損失,Lhard為真實損失,Lsoft為蒸餾損失。s為學生網絡,T為真實標簽,t為教師網絡,α為平衡真實損失和蒸餾損失的權重。通過反向傳播算法更新學生網絡的權重,不斷降低損失值,可以使學生網絡的輸出逐漸接近教師網絡。Lhard的計算方式如式(2)所示:
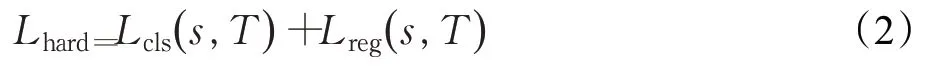
式中,Lcls為目標檢測中的分類損失,Lreg為目標檢測中的回歸損失。Lsoft的計算方式如式(3)所示:
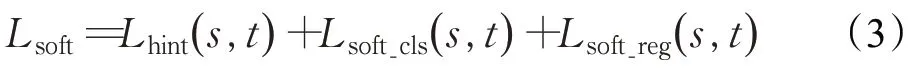
式中,Lhint為hint 損失(度量了學生網絡和教師網絡輸出的特征層的差異,此處使用了平方差損失,即圖1 中的L2 loss),Lsoft_cls為兩者之間的分類損失(交叉熵損失,即圖1 中的Cross Entropy Loss),Lsoft_reg為兩者之間的回歸損失(平方差損失)。在hint損失中,為了保持學生網絡輸出的特征層維度和教師網絡一致,使用一個由1×1卷積組成的自適應層(adaption)調節學生網絡輸出的維度。
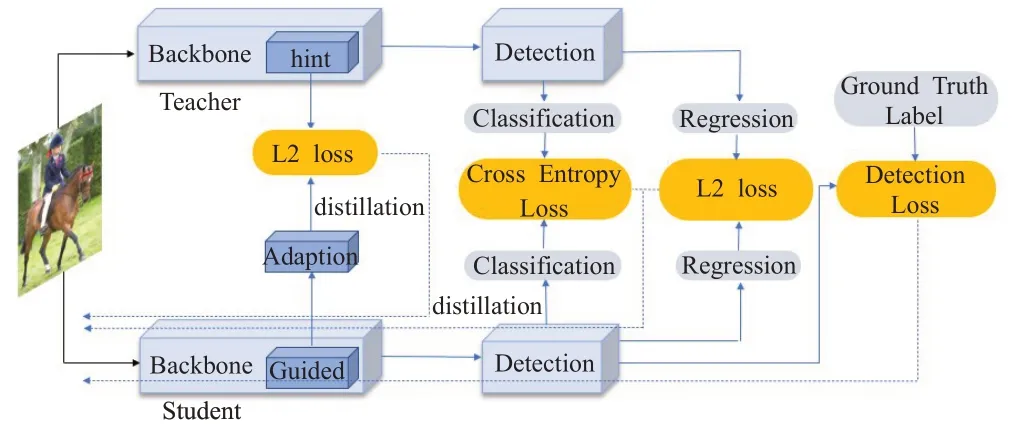
圖1 二階段檢測模型蒸餾架構Fig.1 Two-stage detection model distillation architecture
Wang 等人[15]發現圖1 中的hint 損失是針對特征層的全局信息展開蒸餾,會引入大量背景信息,對此提出了改進。引入信號圖(mask-map[15])去掉教師網絡傳遞的背景信息,只針對目標周圍的特征層進行蒸餾(未對分類和回歸信息進行蒸餾)。如圖2 所示,教師網絡對學生網絡蒸餾時,使用了一張標識目標區域的maskmap做監督信號,虛線框描述了由教師網絡輸出的預測框和真實標簽作為輸入,獲得mask-map 的過程,計算方式如式(4)所示:
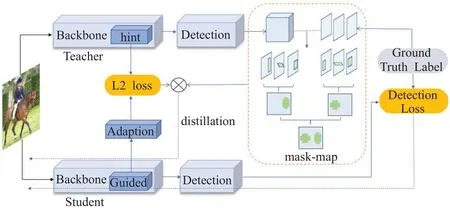
圖2 改進的二階段檢測模型蒸餾架構Fig.2 Improved distillation architecture of two-stage detection model
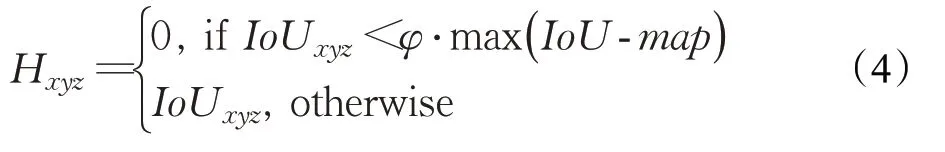
式中,Hxyz為相應位置mask-map 的取值,IoUxyz為相應位置IoU 的取值,φ為控制mask-map 范圍的參數,IoU-map為教師網絡輸出的預測框和真實標簽生成的IoU 的取值。通過max 函數獲得每組IoU-map的最大值,并和φ的乘積作為閾值,小于該閾值的IoU 置為0。對每組IoU-map做或操作獲得一張IoU-map,再對多組IoU-map做或操作,可獲得過濾掉背景信息的maskmap。該蒸餾架構的蒸餾損失為基于IoU-map監督的教師網絡和自適應層輸出的平方差損失。
Mehta 等人[16]在一階段目標檢測器上進行蒸餾,針對教師網絡將大量重復框傳遞給學生網絡的問題,提出在教師網絡的輸出上做非極大值抑制的FM-NMS 算法。如圖3 所示,圖片輸入至教師網絡和學生網絡,將教師網絡的輸出經過FM-NMS 過濾(對同類別預測框的得分進行排序,只留下同類別得分最高的預測框)。將過濾后預測框的置信度(Confidence)、分類(Classification)和回歸(Regression)信息與學生網絡輸出的預測框信息計算蒸餾損失,加上學生網絡的輸出和真實標簽產生的真實損失(Detection Loss)構成總損失,對該損失進行反向傳播來訓練學生網絡。
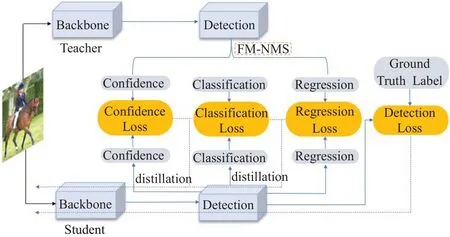
圖3 一階段檢測模型蒸餾架構Fig.3 One-stage detection model distillation architecture model
二階段目標檢測器中的區域提取網絡可以去除大量冗余框,且蒸餾過程中,通過mask-map過濾掉了背景信息,可以達到較好的蒸餾效果。但二階段目標檢測器參數量較多,占用內存大,即使是蒸餾后的小網絡,也難以在移動端部署,相比之下,蒸餾后的一階段目標檢測器可在移動端部署。因此,本文對圖3中的知識蒸餾架構進行改進,并應用于一階段目標檢測器,提出基于信息圖對特征提取層和特征融合層同時蒸餾的知識蒸餾架構。如圖4 所示,圖片分別輸入教師網絡和學生網絡,在特征提取層(Backbone)和特征融合層(Neck)輸出的特征層上同時展開蒸餾,計算損失時,引入信息圖作為監督信號對蒸餾過程提供指導,最后通過反向傳播算法更新學生網絡的權重。
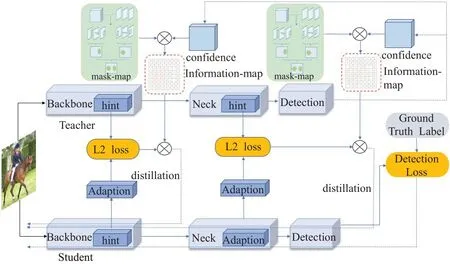
圖4 基于信息圖的知識蒸餾架構Fig.4 Knowledge distillation architecture based on information map
2 知識蒸餾算法改進
2.1 基于信息圖的蒸餾
基于信息圖的蒸餾過程分為3個步驟:(1)如圖5所示,將學生網絡輸出的特征層輸入一個由1×1卷積組成的自適應層,使學生網絡輸出特征層的維度和教師網絡保持一致;(2)在信息圖的指導下計算特征層之間的平方差損失,信息圖對涵蓋目標的區域均賦予了權重,非目標區域的值為0;(3)進行反向傳播,只更新學生網絡的權重。經過模型多次訓練,學生網絡的輸出將越來越接近教師網絡的輸出。
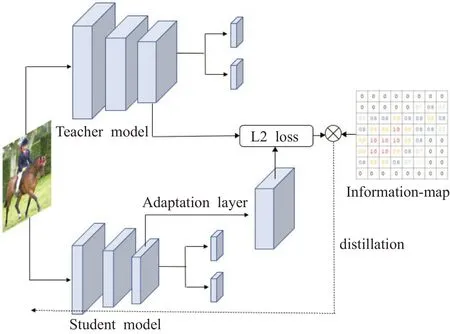
圖5 特征提取層的蒸餾Fig.5 Distillation of feature extraction laye
信息圖的生成如圖6所示,首先由教師網絡的預測框和真實標簽獲得mask-map,mask-map 中包含圓圈的部分值為1,表示前景區域,未包含圓圈的部分值為0,表示背景區域。在教師網絡傳遞的前景信息中,越靠近目標的關鍵部分,最終對目標的判斷越具有決定性影響,但mask-map 中只有0 值和1 值,無法對不同前景信息的重要性進行區分。教師網絡輸出的置信度包含了前景信息的重要程度,越靠近目標核心部分的置信度越大,越遠離的置信度越小。本文基于教師網絡輸出的置信度,對現有的mask-map進行改進,提出了可以在蒸餾過程中提供監督信號的信息圖,信息圖的計算方式如式(5)所示:
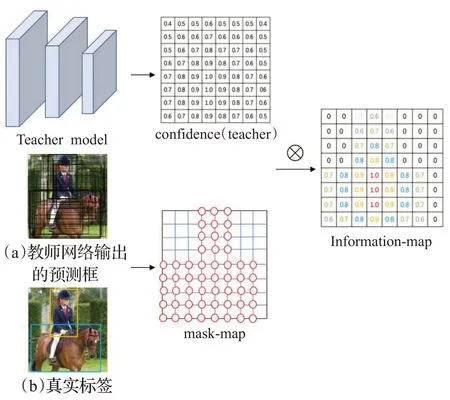
圖6 信息圖的生成Fig.6 Generation of Information-map
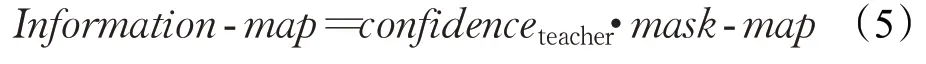
式中,Information-map表示信息圖,confidenceteacher表示教師網絡輸出的置信度。將置信度和mask-map相乘獲得信息圖,可以在值為1的部分獲得有區分度的權重,在計算損失時,權重更大的位置會受到更多關注,加強了學生網絡對教師網絡傳遞的重點知識的學習。
2.2 特征融合層的蒸餾
在網絡結構中,特征提取層負責獲得圖片的特征信息,并以特征層的形式輸出。特征融合層可以將不同尺度的特征層進行拼接或相加,獲得來自不同感受野的信息,如圖7所示。目前的知識蒸餾架構大多只針對特征提取層展開蒸餾,無法獲得教師網絡在特征融合層的知識。針對這個問題,本文提出同時對特征提取層和特征融合層展開蒸餾,相比于現有的知識蒸餾架構,可以進一步提升蒸餾效果,蒸餾中的損失函數如式(6)所示:
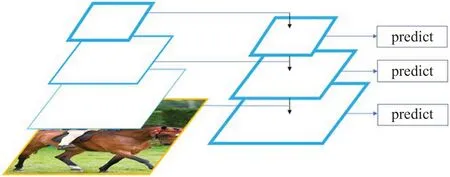
圖7 特征融合層Fig.7 Feature fusion layer
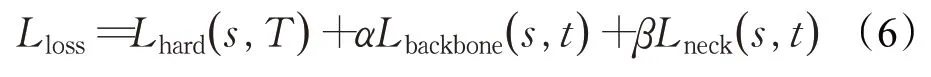
式中,Lloss為總損失,Lhard為檢測的真實損失,Lbackbone和Lneck分別為特征提取層和特征融合層產生的蒸餾損失,α和β是用來平衡三者之間的權重,這里均設置為1,Lbackbone和Lneck的計算方式如下所示:
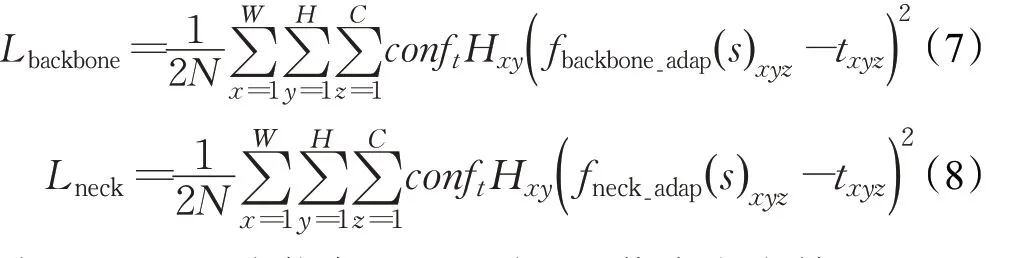
式(7)中,N為信息圖中不為0 的像素點個數的總和。W、H、C分別表示特征提取層輸出的特征層的尺寸,Hxy為mask-map 的取值,conft為教師網絡輸出的置信度,兩者相乘則為信息圖,對特征層的蒸餾提供指導。fbackbone_adap(s)為學生網絡特征提取層經過自適應層處理后輸出的特征層,txyz為教師網絡輸出的特征層。基于特征融合層的蒸餾損失與特征提取層的蒸餾損失類似,如式(8)所示。
3 實驗結果與分析
3.1 數據集和評價指標
本文使用的數據集為VOC[19]數據集,同時取VOC2012[19]和VOC2007[19]的訓練集和驗證集作為訓練集,VOC2007 的測試集作為測試集。VOC 數據集共有20 個類別,本文選擇的訓練集有16 551 張圖片,用來蒸餾出學生網絡的權重參數,測試集有4 952張圖片,可以測試出蒸餾的效果。評價指標為目標檢測模型常用的平均類別精度(mAP),兼顧了模型的準確率和召回率,mAP的表達式為:

式中,IAP,C表示每類缺陷的平均精確度,C表示數據集的類別,N表示數據類別數目。
3.2 實驗環境和訓練細節
實驗基于Pytorch 深度學習框架,運行在Ubuntu 18.04 系統環境下,中央處理器為4.7 GHz Intel Core?CPU i7-9700,內存為32 GB,顯卡型號是NVIDIA Ge-Force RTX 2080ti,加速庫為CUDA10.2和CUDNN7.6。
訓練時,首先將教師網絡和學生網絡訓練出合適的精度,然后將訓練好的權重分別加載到知識蒸餾框架中,凍結教師網絡的權重,只訓練學生網絡。蒸餾實驗的訓練過程中,動量和權重衰減系數分別為0.9 和0.000 5,批量大小設置為4,并交比(IoU)為0.5。采用SGD優化器進行優化,以余弦函數為周期,周期性地設置學習率,學習率的范圍為[10-6,10-4]。
本文選擇YOLOv3為教師網絡,tiny_yolov3為學生網絡。教師網絡在YOLOv3 的基礎上使用Focal loss、GIoU loss 和mix-up 數據增強的方式,平均精度提升至84.7%。學生網絡在tiny_yolov3 的基礎上加入了一個52×52的分支,便于蒸餾過程中和YOLOv3的三分支輸出結構匹配。本文將Chen[14]和Wang[15]的知識蒸餾架構應用于YOLOv3,做了相關的對比實驗。雖然Metha 等人[16]也將知識蒸餾應用于目標檢測,在學生網絡的基礎上mAP提升了14個百分點,但蒸餾架構提升效果有限,mAP只提升了不到1個百分點,所以未加入對比實驗。
3.3 結果與分析
實驗結果如表1 所示,經過蒸餾后,學生網絡mAP指標均有提升,驗證了知識蒸餾可提升小網絡的檢測效果。(1)Chen[14]提出的知識蒸餾架構在tiny_yolov3 的基礎上提升了6.2 個百分點的mAP,Wang[15]提升了6.8 個百分點的mAP,本文的知識蒸餾架構提升了9.3個百分點的mAP,驗證了知識蒸餾的有效性;(2)相比現有的知識蒸餾架構,本文提出的知識蒸餾架構高出Chen[14]3.1 個百分點的mAP,且高出Wang[15]2.5 個百分點的mAP,充分驗證了本文創新點的有效性,且優于現有的知識蒸餾架構;(3)教師網絡和學生網絡在鳥、貓、狗、沙發這四類精度的差距最大,蒸餾后這四類的精度相比其他類別均有較大提升,驗證了知識蒸餾可以使學生網絡獲得更高的特征提取能力和檢測能力,大幅度縮小學生網絡和教師網絡的差距。

表1 知識蒸餾實驗結果Table 1 Knowledge distillation experiment results
圖8 為訓練時loss 的收斂曲線圖,實驗中使用余弦函數為周期調整學習率大小,震蕩較為嚴重。但隨著訓練輪數的增加,loss 曲線逐漸趨于平緩,逐步縮小了學生網絡與教師網絡的差距。
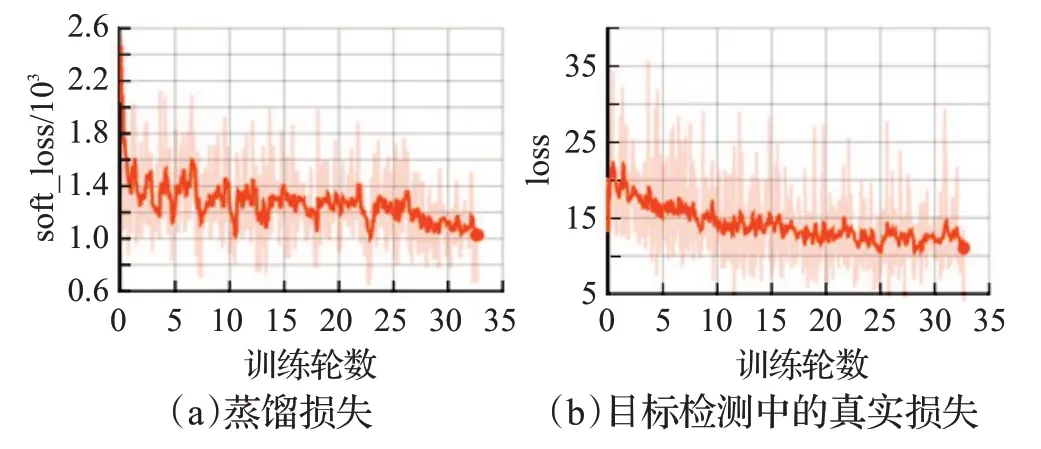
圖8 蒸餾訓練曲線圖Fig.8 Distillation training curve graph
為了驗證蒸餾的有效性,圖9對比了蒸餾前后的檢測效果,左邊一欄為學生網絡的輸出,右邊一欄為教師網絡的輸出,中間一欄為蒸餾后的學生網絡的輸出。通過觀察可發現,針對學生網絡沒有檢測出來的框,蒸餾后的學生網絡均可以檢測出來,且更接近于教師網絡的預測結果。

圖9 蒸餾效果可視化Fig.9 Visualization of distillation results
3.4 消融實驗
本文基于YOLOv3 做了相關的消融實驗。為了驗證該實驗結果,將圖1網絡結構中的圖片作為輸入進行特征圖的可視化,3.5 節也采用該圖片作為輸入進行蒸餾過程的可視化。
表2 顯示了消融實驗結果,可分為以下3 個步驟:(1)首先通過Wang[15]的知識蒸餾架構對學生網絡的特征提取層展開蒸餾,mAP指標提升6.8個百分點。(2)加入信息圖后,在過濾掉教師網絡傳遞的背景信息的同時,強化了學生網絡對重點知識的學習,mAP提升了1.5個百分點。如圖10所示,相比于圖(b3)、(c3)中的特征圖強化了目標核心區域的特征,邊緣區域至中心區域的重要性逐漸升高。(3)同時對特征融合層蒸餾,將教師網絡在特征融合后的知識有效傳遞給學生網絡,補充了特征提取層未傳遞的知識,且特征融合層中的卷積層對特征提取層的蒸餾有一個校正作用,mAP進一步提升1.0個百分點。如圖10所示,相比于圖(c1)中蒸餾后特征提取層的輸出,圖(d1)中特征融合層的輸出在獲得高層語義信息的同時,依舊保持了物體清晰的輪廓。綜上所述,基于信息圖對一階段目標檢測器的特征提取層和特征融合層同時展開蒸餾,可有效提高一階段目標檢測器的精度。

圖10 蒸餾前后特征圖對比Fig.10 Feature map comparison before and after distillation

表2 消融實驗(mAP)Table 2 Ablation experimen(tmAP)%
3.5 蒸餾可視化
為了驗證本文方法的有效性,從特征提取層、特征融合層、卷積層這3個方面對蒸餾過程進行可視化。
特征提取層的可視化。圖11 顯示了蒸餾前后,學生網絡經自適應層輸出和教師網絡特征提取層輸出的三張特征圖。相比蒸餾前的(a1),蒸餾后的(b1)更準確地提取出目標的局部特征。相比蒸餾前的(a2),蒸餾后的(b2)更明顯地劃分了前景和背景區域之間的邊界。相比蒸餾前的(a3),蒸餾后的(b3)與教師網絡輸出的特征圖更接近,且更準確地突出了圖片中的前景區域。

圖11 特征提取層的輸出Fig.11 Output of feature extraction layer
特征融合層的可視化。圖12分別顯示了蒸餾前后的學生網絡特征融合層輸出和教師網絡特征融合層輸出的三張特征圖。相比蒸餾前的(a1)和(b3),蒸餾后(b1)和(b3)中目標的輪廓更加明顯,局部特征更加清晰,更有利于小目標的檢測。

圖12 特征融合層的輸出Fig.12 Output of feature fusion layer
卷積層的可視化。圖13顯示了蒸餾前后學生網絡同一層卷積層輸出的三張特征圖,如圖中所示,蒸餾后輸出的特征圖不僅更好地區分了目標的前景和背景,且更細致地保留了目標的局部特征,有利于提高檢測精度。

圖13 蒸餾前后學生網絡特征圖對比Fig.13 Comparison of feature maps of student model before and after distillation
4 結束語
本文針對現有的目標檢測知識蒸餾架構進行改進,提出基于信息圖對一階段目標檢測器的特征提取層和特征融合層同時展開蒸餾。信息圖標識了教師網絡傳遞知識的重要性,加強了學生網絡對特征層關鍵區域的學習;對特征融合層展開蒸餾,使學生網絡在獲得特征提取層知識的同時,也獲得了來自教師網絡特征融合后的知識。實驗結果表明,改進后的知識蒸餾架構,在不改變學生網絡結構的基礎上,提升了更高的精度,為小模型在移動設備上部署奠定了基礎。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
