基于特征增強的開放域知識庫問答系統
2022-09-06 11:09:12李帥馳楊志豪王鑫雷韓欽宇林鴻飛
計算機工程與應用 2022年17期
關鍵詞:模型
李帥馳,楊志豪,王鑫雷,韓欽宇,林鴻飛
大連理工大學 計算機科學與技術學院,遼寧 大連 116024
近年來,隨著諸如DBpedia[1]、Freebase[2]、Yago[3]、NLPCC-ICCPOL-2016KBQA 評測任務[4]發布的中文知識庫等大規模知識庫(knowledge base,KB)的產生,基于知識庫的問答(knowledge based question answering,KBQA)任務逐漸成為自然語言處理研究領域的熱點之一。知識庫是將知識結構化存儲的數據庫系統,其中的知識以三元組的形式存在,如<實體,謂詞,目標值>。基于知識庫的問答系統以知識庫作為知識來源,理解用戶輸入的自然語言形式的問題,識別出實體和謂詞查找對應的目標值作為答案。例如,對于問題“誰是奧巴馬的妻子?”,結合三元組<貝拉克·奧巴馬,妻子,米歇爾·奧巴馬>,可以查找到米歇爾·奧巴馬作為答案。根據回答問題所需三元組的數目為單個或者多個,可以分為簡單問題和復雜問題,本文工作聚焦在簡單問題問答的研究。
現有的中文簡單問題知識庫問答的主流方法通常將問答任務拆分為實體鏈接和謂詞匹配兩個子任務,其中實體鏈接包含實體提及識別和實體消歧兩部分,構建一個流水線式的問答系統,如圖1 所示。以“精忠岳飛由誰運營?”這一問題為例,首先通過實體提及識別模型識別問句中的實體提及“精忠岳飛”;結合知識庫可以生成與“精忠岳飛”相關的候選實體集合,通過實體消歧模型打分,將得分最高的候選實體“精忠岳飛(2014年全新戰爭策略游戲)”作為該問題的主題實體;結合該主題實體和知識庫,將主題實體的一度謂詞作為候選謂詞集合,接下來將實體提及替換為統一標識符“entity”的問句和候選謂詞輸入謂詞匹配模型,得到得分最高的謂詞“運營商”;結合實體和謂詞,查詢知識庫得出最終答案。
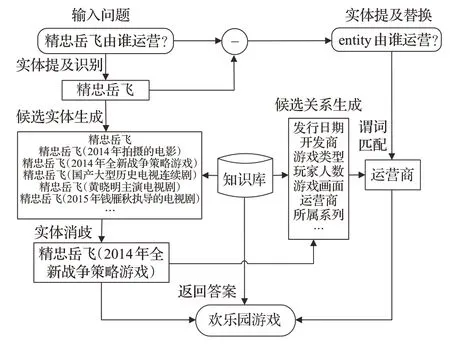
圖1 知識庫問答整體流程Fig.1 Overview of CKBQA
對于上述示例中,問題中提及的“精忠岳飛”,在知識庫中可以找到多個相關的實體,問答系統應該判斷問句詢問的“精忠岳飛”是哪一個,在問句較短、信息較少的情況下為實體消歧任務帶來了難度。并且,同一個問句意圖可以有不同的表達形式,然而知識庫中的三元組表達形式是固定的,導致了問題與知識庫知識的差異性,為謂詞匹配任務帶來了挑戰。另外,在開放域知識庫中,實體數量和謂詞的數量往往規模較大,而用于訓練的數據集由于需要人工標注通常規模較小。針對上述問題,本文提出一種基于中文預訓練語言模型BERT[5]的流水線式問答系統BERT-CKBQA,用于提升中文知識庫問答的性能,其創新性在于:(1)融合知識庫的拓撲信息,引入從候選實體出發的一度謂詞集合特征,來增強候選實體的上下文信息的BERT-CNN模型進行實體消歧,提高實體消歧的準確率,進而啟發式地縮小候選謂詞集合的規模,提升系統的問答效率。(2)提出通過注意力機制引入答案實體一度鏈出謂詞的BERTBiLSTM-CNN 模型進行謂詞匹配,提升謂詞匹配任務的性能。(3)BERT-CKBQA 方法在NLPCC-ICCPOL-2016KBQA數據集上取得了最高的平均F1值,為88.75%。同時該方法在各個子任務中也取得了較好的結果,充分說明了該方法的有效性。
1 相關工作
目前主流的知識庫問答方法主要分為:語義解析方法、信息檢索方法和向量建模方法。語義解析方法[6]對自然語言問句成分進行解析,將查詢轉化成邏輯表達式,再結合知識圖譜轉換成知識圖譜查詢,得到答案,如謂詞邏輯表達式[7]、依存組合語義表達式[8]等。這種方法雖然可解釋性強,但需要大量人工標注,且在開放域知識庫中難以解決歧義。信息檢索方法從問句中提取關鍵信息,用這些信息限定知識庫的知識范圍再檢索答案。Yao 等人[9]首先抽取問句中的實體和謂詞,構建問題的圖模型,與知識庫進行匹配。王玥等人[10]提出了DPQA,采用動態規劃的思想進行問答。隨著深度學習的發展,基于向量建模的方法逐漸興起。Xie 等人[11]使用深度語義相似度模型,計算問題和謂詞之間的相似度。Hao 等人[12]訓練TransE 模型來獲取知識庫中的實體和謂詞的向量表示,并與問題向量匹配,選擇最相似的三元組。
在中文知識庫問答的研究中,多數工作集中于NLPCC-ICCPOL 2016 KBQA 任務發布的數據集與知識庫。Wang等人[13]使用卷積神經網絡和門控循環單元模型獲取問句向量表示。Lai等人[14]通過別名詞典生成候選實體,構建人工規則進行實體消歧,并且基于詞向量計算余弦相似度對謂詞打分。隨著預訓練語言模型BERT的出現,Liu等人[15]針對CKBQA 流程中不同的子任務,使用基于BERT的預訓練任務的模型進行微調,在開放域中文知識庫問答任務上取得了相當不錯的結果。
2 方法與模型
2.1 實體鏈接
本文提出的BERT-CKBQA流水線式問答系統的實體鏈接模型分為實體提及識別和實體消歧兩部分。
首先,實體提及識別模型用于識別問句中的主題實體,作為問題語義解析的出發點,例如“精忠岳飛由誰運營?”中的“精忠岳飛”為該問題的主題實體的提及形式。實體提及識別可以看作一個序列標注任務,該部分數據使用的是序列標注任務中常用的標簽體系“BIO”標簽,其中,B 表示實體提及的起始位置,I 表示實體提及的中間或結尾位置,O表示該字符非實體提及。將問句中“精忠岳飛”對應的位置標記為“B I I I”,其他非實體提及部分標記為“O”,進行序列標注模型訓練。
實體提及識別部分采用BERT-CRF[15]模型,首先將問題的字符序列Q輸入到BERT預訓練語言模型,得到每個字符的上下文表示,之后輸入給CRF層,對輸入特征序列求出條件概率最大的標注路徑,即得到預測的標簽序列,即得到問句中的實體提及。完成模型訓練后,對輸入的問題進行實體識別,得到實體提及m,如公式(1)所示:

接下來,由于自然語言問句中提及的實體可能對應知識庫中存儲的多個實體,因此在得到每個問句中的主題實體的實體提及之后,需要從知識庫中生成與該實體提及相關的候選實體集合,并對這些候選實體集進行消歧,從而選擇正確的候選實體。準確匹配問題中所詢問的主題實體也可以為下一步的謂詞匹配減小候選集規模,提升問答系統的效率。本文提出引入實體一度鏈出謂詞特征的BERT-CNN 模型來提升實體消歧任務的性能,例如圖1 中的問題,游戲類型的“精忠岳飛”更有可能有“運營商”這樣的謂詞。
在實體消歧部分,首先,為了獲得與問句中主題實體更為接近的候選實體集,根據NLPCC-ICCPOL-2016KBQA 評測所提供的別名詞典文件,將上一步識別的實體提及映射到該詞典中,生成候選實體集合。對于無法映射的實體提及,依托知識庫檢索字符級別相似的實體作為候選實體集合。然后,將問句和候選實體集輸入至BERT-CNN模型,通過卷積神經網絡來增強BERT模型預訓練的實體特征進行實體消歧,BERT-CNN模型如圖2所示。
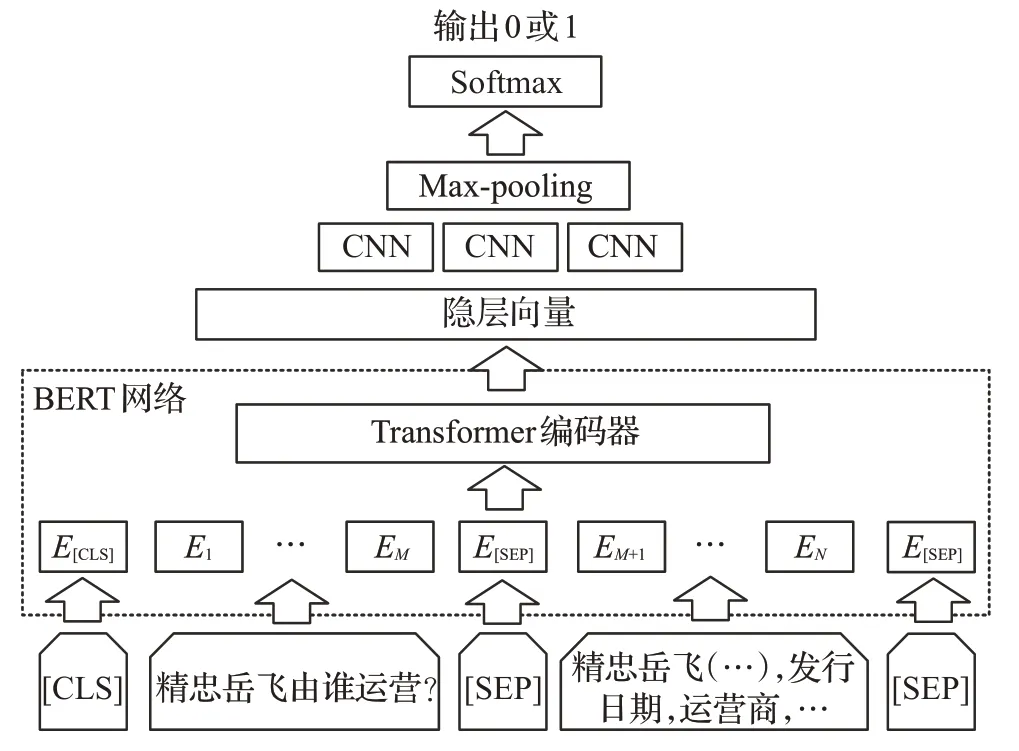
圖2 實體消歧模型Fig.2 Entity disambiguation model
該子任務可以看作一個二分類任務,候選實體如果為標注的三元組中的主題實體,則輸出標簽1,否則輸出標簽為0。輸入數據由[CLS],問題字符序列,[SEP],與謂詞特征拼接的候選實體,[SEP]組成。其中一度鏈出謂詞特征即為知識圖譜中從候選實體出發,相連接的一度謂詞的集合,如公式(2)所示。其中q表示問題,e表示候選實體,pi表示從e出發的一度鏈出謂詞。
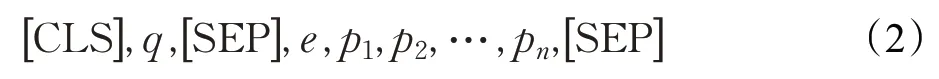
經過BERT 網絡編碼得到后四層encoder 輸出的隱層向量,相加后得到隱層輸出H,卷積層的特征C可以表示為公式(3):

其中,σ為sigmoid 函數,?為卷積運算,W為卷積核內的權重,b為偏置。H分別通過步長為1、3、5的三個卷積層提取特征。之后輸入最大池化層,將得到的三個向量拼接后輸入Softmax層分類,輸出標簽為0或1。損失函數為交叉熵損失函數,如公式(4)所示,訓練時最小化損失函數。在預測時,將候選實體被預測為標簽1的概率作為候選實體的得分。
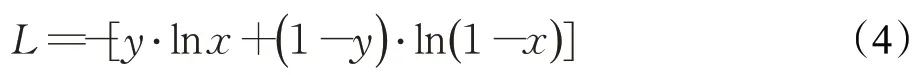
2.2 謂詞匹配
由于自然語言問句的表達形式多樣,不同的表達可能對應相同的問句意圖,并且對于同一個主題實體會產生大量的不同謂詞,這為開放域知識庫問答任務帶來了巨大挑戰,如圖一中問題的“由誰運營”與“運營商”之間的匹配。謂詞匹配模型用于將問句中的謂詞與知識庫中的謂詞匹配,理解問句意圖,選擇與問句最匹配的謂詞。首先,實體消歧結果可以很大程度地減少候選謂詞集合的規模,因此從實體消歧任務中獲得的候選實體樣本出發,檢索知識庫中該實體的一度謂詞集合作為候選謂詞集合。接下來,注意到在回答“精忠岳飛由誰運營?”問題時,通過加入候選謂詞檢索到的候選答案實體的一度鏈出謂詞信息可以豐富候選謂詞的信息,如圖3中的“發行時間”“業務范圍”等答案實體的一度鏈出謂詞與候選謂詞“運營商”有一定的關聯。
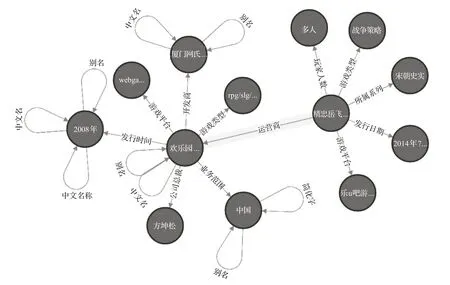
圖3 知識圖譜子圖Fig.3 Subgraph of knowledge base
于是本文提出了一種通過注意力機制引入答案實體的一度鏈出謂詞特征的BERT-BiLSTM-CNN 模型進行謂詞匹配,豐富候選謂詞在知識圖譜中的結構信息,如圖4所示。
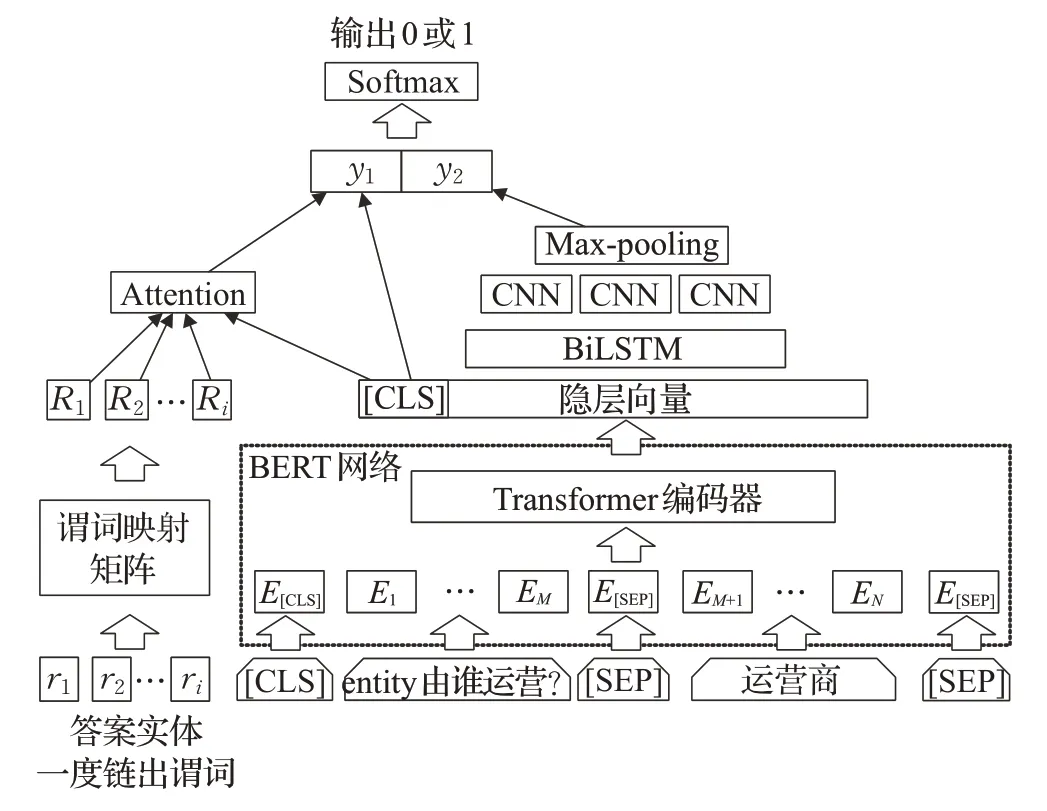
圖4 謂詞匹配模型Fig.4 Predicate matching model
該任務同樣可以看做是二分類任務,對于能夠正確反映問句意圖的候選謂詞樣本輸出標簽為1,不能正確反映問句意圖的候選謂詞樣本輸出標簽為0。輸入數據由兩部分組成:問句謂詞對部分和答案實體一度鏈出謂詞特征部分。問句謂詞對部分的輸入數據由[CLS],將實體提及替換為entity 字符的問題字符序列,[SEP],候選謂詞,[SEP]組成,如公式(5)所示。其中,pi表示候選實體的一度謂詞。
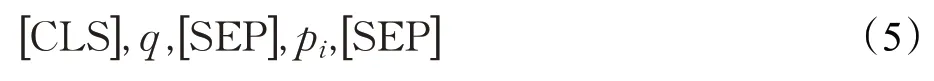
經過BERT 網絡編碼得到后四層encoder 輸出的隱層向量,相加后通過由兩個方向的LSTM 網絡構成的BiLSTM 網絡學習序列的上下文信息。給定輸入序列[x1,x2,…,xt,…,xn] ,t時刻LSTM 網絡的計算公式如公式(6)~(11)所示:
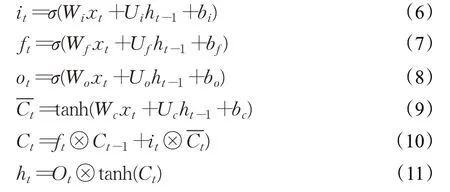
其中,it、ft、ot分別表示LSTM網絡的輸入門、遺忘門和輸出門,W和U為權重矩陣,b為偏置,Ct表示細胞狀態,ht表示網絡輸出。將兩個方向的LSTM的輸出拼接即得到BiLSTM的輸出Ht,如公式(12)所示:

再通過步長為1、3、5的三個卷積層提取特征,之后輸入最大池化層將得到的三個向量拼接后得到y2。
答案實體一度鏈出謂詞特征部分的輸入數據由以候選實體出發,沿候選謂詞檢索到的答案實體的一度鏈出謂詞集合[r1,r2,…,ri] 組成。由于在開放域知識圖譜中,謂詞詞表較大,本文工作采用組成謂詞的字對應的預訓練字向量的平均來作為謂詞的向量表示。通過謂詞矩陣映射后,得到謂詞特征的向量表示[R1,R2,…,Ri] 。接下來,利用注意力機制將答案實體一度鏈出謂詞特征與隱層向量中[CLS]位置的向量H[CLS]進行交互,得到y1。在BERT 預訓練任務中,通常將H[CLS]用作分類,所以H[CLS]中包含了問答謂詞對經過BERT 編碼后的交互信息。注意力機制部分的計算公式如公式(13)~(16)所示:
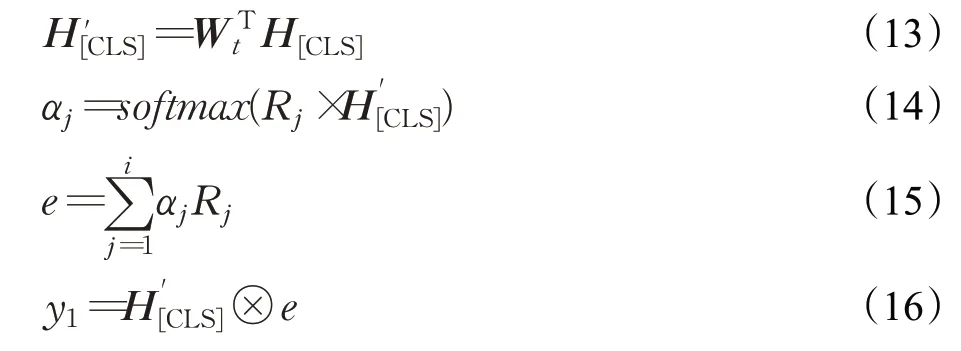
其中,Wt為可學習參數的變換矩陣,維度為dR×dBERT。
將y1和y2拼接后輸入Softmax 層分類,輸出標簽為0 或1。損失函數同樣為交叉熵損失函數,訓練時最小化損失函數。在預測時,將預測候選謂詞為標簽1的概率作為候選謂詞的得分。
3 實驗與結果分析
3.1 數據集與知識庫
本文使用NLPCC-ICCPOL-2016KBQA評測任務發布的中文知識庫和中文簡單問題問答數據集。NLPCC中文知識庫包含大約4 300 萬個三元組,謂詞種類有58萬余個。首先對知識庫文件進行預處理,例如將繁體中文轉換成簡體中文,去除三元組中謂詞中多余的空格(如<羅育德,民族,漢族>和<羅育德,民 族,漢族>只保留前者),將過長的實體名稱截斷,將英文字母統一轉換為小寫便于實驗等處理,導入到Neo4j圖數據庫存儲和檢索。
問答數據集中訓練集共有14 609個問答對,測試集有9 870 個問答對,結合知識庫中的單個三元組即可回答問題。但是由于原始數據集中并沒有實體提及和三元組的標注,所以本文參考Liu等人[15]的數據標注,生成各個子任務的數據集,數據集標注和子任務數據集的劃分情況分別如表1和表2所示。

表1 數據集樣本標注示例Table 1 Dataset annotation sample
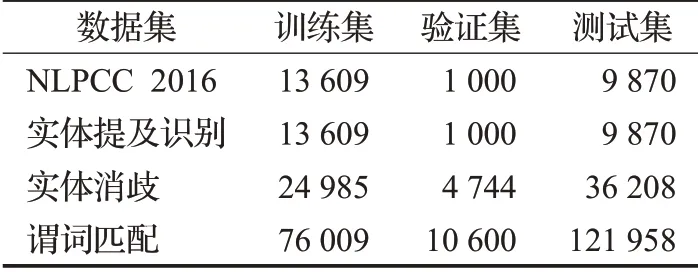
表2 子任務數據集劃分Table 2 Subtask dataset statistic
3.2 實驗設置
實驗運行 在CPU 為Intel?Xeon?CPU E5-2650 v4 @ 2.20 GHz、內存為128 GB 的計算機,操作系統為Ubuntu 16.04.6 LTS。模型訓練所用顯卡為NVIDIA TITAN Xp,顯存12 GB,所用深度學習框架為CUDA 9.0 和PyTorch 1.1.0,知識庫數據存儲和檢索使用Neo4j-community-3.5.8版本。
本文使用預訓練模型為BERT-Base Chinese。預訓練模型為基于PyTorch 框架實現和微調,有12 層Transformer 編碼器,每一層隱層輸出的維度為768。預訓練字向量使用的是基于中文維基百科預訓練的300 維字向量。模型的優化方式采用Adam 優化器。不同子任務的超參數設置如表3所示。
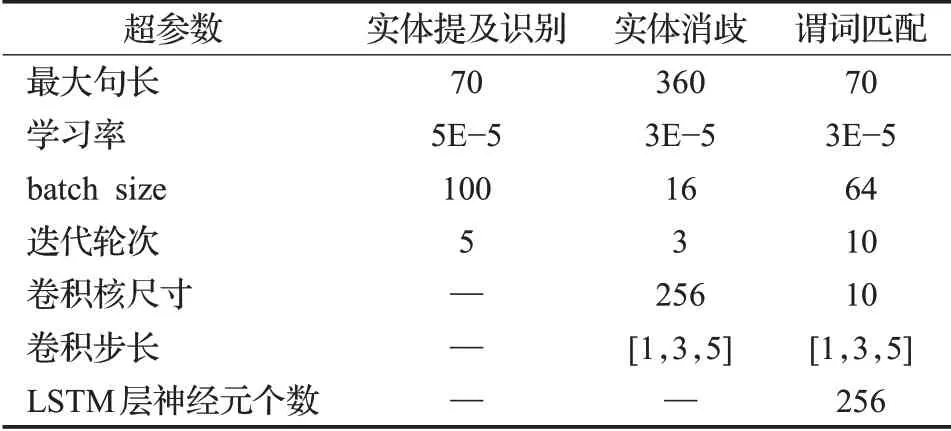
表3 子任務超參數設置Table 3 Subtask hyperparameter setting
3.3 實體鏈接
實體提及識別實驗結果如表4 所示,結果表明BERT-CRF 模型均取得了基本準確的結果。傳統的命名實體識別任務需要識別不同類型的實體和實體的邊界位置,而實體提及識別子任務只需要識別出實體提及的位置,不需要區分類型,并且簡單問句中通常只包含單個實體提及,這都降低了該子任務的難度。

表4 實體提及識別實驗結果Table 4 Result of entity mention recognition %
實體消歧子任務訓練集中正負例的比例為1∶5,驗證集和測試集中均選取所有的候選實體進行預測。該子任務在訓練過程中容易發生過擬合,所以選取了較少的訓練輪次和較低的學習率。評價指標采用Acc@N,定義如公式(17)所示:
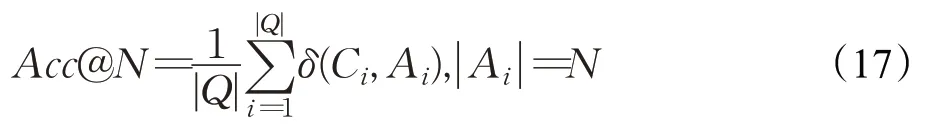
其中,Q是數據集中的所有問題的集合,Ci是正確的答案集合,Ai是模型預測給出的答案集合,|·|表示集合的大小。當Ai中的答案至少被Ci包含一個時,δ(Ci,Ai)為1,否則為0。
在測試集上實體消歧實驗結果如表5所示。其中,引入謂詞特征在Acc@1 指標上均提高了約10 個百分點。這是因為僅使用問句和實體名稱作為輸入的基準模型可利用的信息較少,而謂詞特征蘊含了主題實體在知識庫中的拓撲信息以及其關聯的謂詞內容,從而增強了主題實體與問句的匹配程度,對于改善實體消歧是有效的。并且,結合CNN的特征提取能力,也帶來了一定的提升。保留得分前三的候選實體可以達到一個很高的準確率,有助于減少謂詞匹配的候選謂詞集合規模,進而提升問答系統的效率。
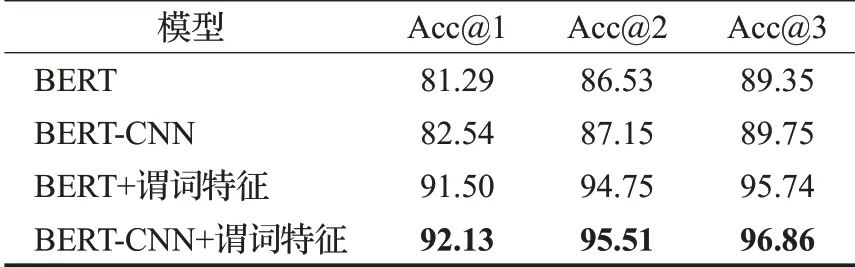
表5 實體消歧實驗結果Table 5 Result of entity disambiguation %
3.4 謂詞匹配
謂詞匹配子任務訓練集中正負例的比例為1∶5,驗證集和測試集中均取所有候選謂詞進行預測。評價指標同樣使用Acc@N。在測試集上的實驗結果如表6 所示。在只利用問句和謂詞的較少信息的情況下,相比于對比基準的的BERT 模型,BERT-BiLSTM-CNN 模型在保留前1~3 個候選謂詞時均提高了2~3 個百分點,表明使用BiLSTM 結構建模BERT 編碼后的上下文信息,對于理解問句語義是有效的。增加CNN 后,可以增強模型提取特征的能力,進一步提高了問答的準確率。并且在通過注意力機制引入謂詞特征后,帶來了進一步的準確率提升,本文提出的模型取得了最好的結果,驗證了謂詞特征的有效性。
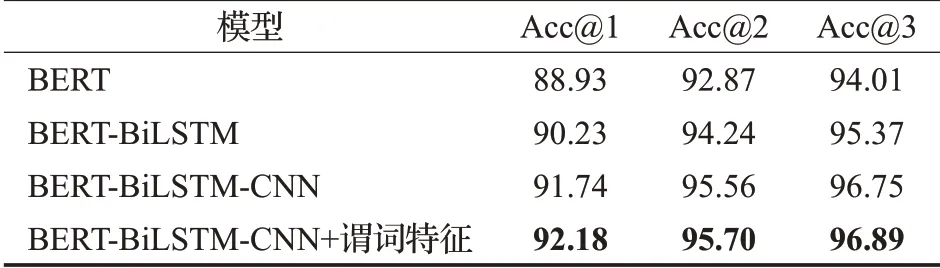
表6 謂詞匹配實驗結果Table 6 Result of predicate matching %
3.5 問答系統整體性能
在完成了上述子任務的訓練之后,可以得到每個問題對應的候選實體的得分Se和候選謂詞Sp的得分。選擇得分前三的候選實體,以及每個候選實體對應的得分前三的候選謂詞,加權相加,選擇總分最高的候選實體和候選謂詞組成查詢路徑,轉換成Cypher 查詢語句到Neo4j 知識庫中檢索答案。問答系統的整體性能評價指標平均F1值。定義如公式(18)~(20):
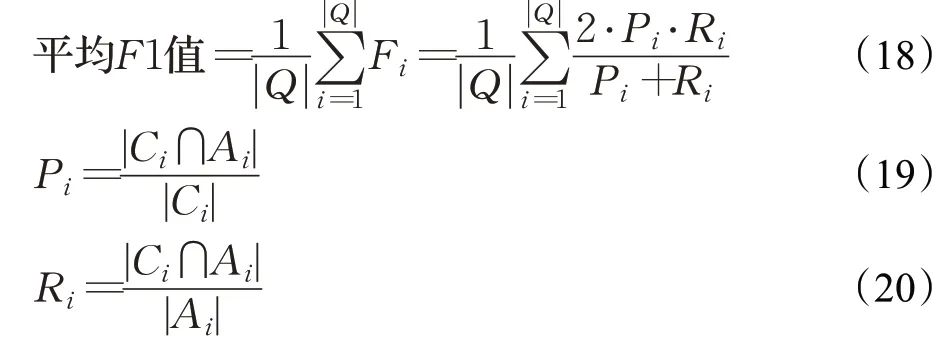
其中,Q是數據集中的所有問題的集合,Ci是正確的答案集合,Ai是模型預測給出的答案集合,|·|表示集合的大小。Pi表示預測正確的答案在預測答案集合中所占的比例,反映了問答系統的準確程度;Ri表示預測正確的答案在正確答案集合中所占的比例,反應問答系統的完備程度。計算每一個問題的F1 值,再對所有問題的F1值求和取平均值作為問答系統的評價指標。本文方法與其他公開方法的性能對比如表7所示。
其中,DPQA[10]是王玥等人基于動態規劃思想進行的研究。InsunKBQA[16]是周博通等人基于知識庫三元組中謂詞的屬性映射構建的問答系統,加入了少量人工特征。Lai 等人[14]、Xie 等人[11]、Yang 等人[17]的系統是評測任務的前三名,結合神經網絡和人工構建規則保證問答質量。BB-KBQA[15]基于BERT的預訓練任務微調,實現實體提及識別、實體消歧和謂詞匹配三個子任務,但在各個子任務上的表現弱于本文模型,導致最后的表現低于本文的問答系統。實驗結果表明,本文提出的問答方法BERT-CKBQA取得了88.75%的平均F1值,相比于其他公開的問答方法,取得了現有最好的結果,提升了問題回答的準確度。
最后,對問答系統的回答結果進行了分析。除了存在一些三元組標注和答案錯誤的情況,整個問答系統的結果比較準確。例如,問題“王杰是在什么地方出道的啊?”,對應的知識三元組為<王杰,出道地,臺灣>,本文的系統預測的主題實體和謂詞為<王杰(港臺男歌手),出道地>,表明實體消歧模塊可以正確選擇是歌手的王杰;問題“請問212型潛艇是哪個廠建造的?”,對應的知識三元組為<212 型潛艇,建造,哈德威造船廠(hdw)>,本文的系統預測的主題實體和謂詞為<212 型潛艇,制造廠>,可見雖然謂詞匹配模塊選擇的謂詞與標注謂詞不同,但通過理解問句意圖,選擇了正確的謂詞,最終找到正確答案。綜上,本文工作提出的BERT-CKBQA 問答系統的準確率較高,可以滿足中文簡單問題的開放域知識庫問答的實際應用。
4 結束語
針對中文簡單問題的開放域知識庫問答系統中實體消歧和謂詞匹配任務存在的難點,本文工作提出一種基于中文預訓練語言模型BERT 的流水線式問答系統BERT-CKBQA,應用BERT-CRF 模型進行實體提及識別;提出謂詞特征增強的BERT-CNN模型用于提升實體消歧任務的性能,提高實體消歧的準確率,進而啟發式地縮小候選謂詞集合的規模,提升系統的問答效率;提出引入答案實體一度鏈出特征的BERT-BiLSTM-CNN模型進行謂詞匹配,提升謂詞匹配任務的性能。最后,在NLPCC-ICCPOL-2016KBQA數據集上BERT-CKBQA系統取得了最高的平均F1值,為88.75%,取得了現有方法中最好的性能。在未來工作中,可以嘗試將不同的子任務聯合訓練,或引入知識圖譜表示學習方法融入更豐富的知識圖譜特征,帶來進一步的提升。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
