基于深度學習的司法判罰研究
2022-09-14 08:19:48高珊何安娜肖清泉
電子設計工程 2022年17期
高珊,何安娜,肖清泉
(貴州大學大數據與信息工程學院,貴州貴陽 550025)
隨著大數據時代的來臨,人民法律意識的加強和法律的普及已不僅僅局限于司法部門。大數據與司法相結合已成為必然趨勢[1]。早期文獻采用N-gram進行司法智能研究,屬于利用淺層的文本特征,準確率較差[2-3]。Daniel 等人采取了人工提取案件顯著特征的方式進行美國法院的判決預測[4],準確率提高了,但耗費了時間及精力。Hu 等人提出利用注意力機制模型解決司法判罰任務[5],模型結合罪名問題和相關法條,法條被充分利用,但對法條的監督信息存在一定限制。該文利用CNN+GRU-Attention 技術,充分利用罪名信息并且對監督信息沒有限制。
1 司法判罰模型的數據處理
1.1 數據集介紹及分析
數據來源于法研杯大賽,約有20 萬條文本數據。單項罪名約有12 萬條,占訓練集78%。出現次數最多的罪名數量約為次數最少的2 000 倍,因此數據分布不均勻,此外數據中有較多易混淆罪名,易混淆罪名將影響模型性能,因此對易混淆罪名的處理是數據處理的關鍵。
1.2 數據處理
針對易混淆罪名,該文采用提取要素維度關鍵特征的方式來區分易混淆罪名,易混淆罪名的處理流程如圖1 所示,以易混淆罪名“搶奪”“搶劫”為例,對整個處理流程進行分析。
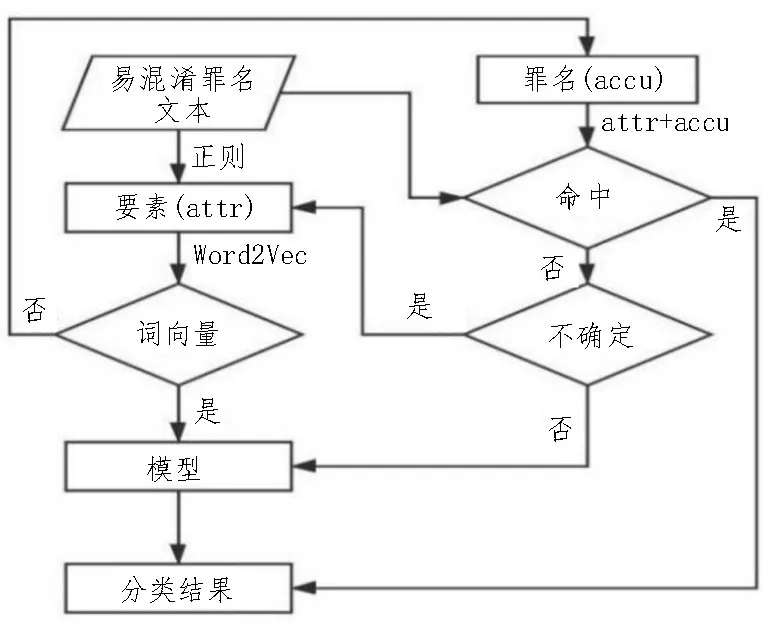
圖1 易混淆罪名處理流程
第一步:分析易混淆罪名法條:搶劫罪指暴力對人實施或者對人加物實施,搶奪罪指的是暴力對物實施。第二步:提取易混淆罪名要素。搶劫罪要素:暴力+人/暴力+人+物;搶奪罪要素:暴力+物。通過正則表達式對文書提取“暴力”的詞匯,“受害人”詞匯以及“物品”詞匯,將提取的“暴力+人+物”設置為搶劫罪要素attr1,將提取的“暴力+物”設置為搶奪罪要素attr2。第三步:處理易混淆罪名要素。方式一:直接由Word2Vec 轉化為詞向量,在輸入模型的全連接層中參與模型訓練,提高模型對易混淆罪名的分類準確性。方式二;將要素與罪名進行強綁定,每個要素設定三個值,分別為命中、不命中、不確定。將輸入樣本在要素上作三分類預測。
2 建立司法判罰模型
2.1 司法判罰模型實驗步驟
該文提出CNN+GRU-Attention 網絡的判罰模型,具有卷積神經網絡和GRU 網絡的共同特點[6-7]。模型結構如圖2 所示。
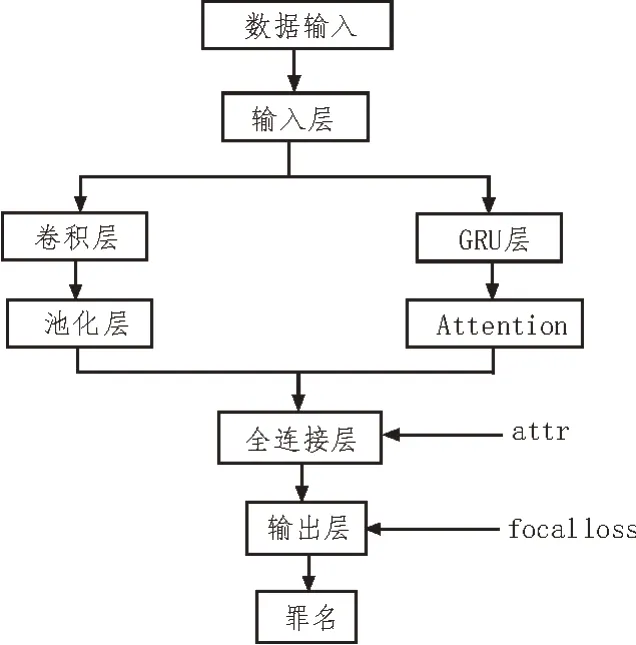
圖2 CNN+GRU-Attention模型結構圖
輸入層:司法事實描述X={A1,A2,…,An},向量化后X={x1,x2,…,xn}。卷積層采用多尺寸卷積核,一個卷積核的特征輸出如式(1)所示,高度為h,寬度為k,對h個詞進行卷積操作。
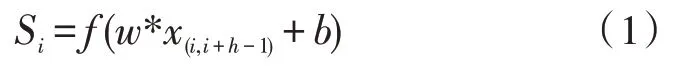
其中,w是值矩陣參數,b是偏置項,x是輸入的特征值,表示第i行到第i+h-1 行的局部特征,Si為輸出的特征值,多個卷積核可得到多個特征。
池化層:池化層采取了最大池化操作,池化后的特征如式(2)所示:
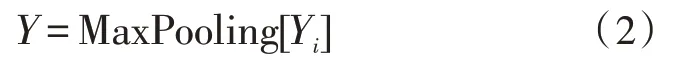
GRU 層:采用雙向GRU 網絡在編碼層對數據進行雙向編碼,如式(3)所示,編碼后生成隱層向量,將隱層向量進行拼接,如式(5)所示,拼接后向量hi融合了司法文書的上下文語義信息。
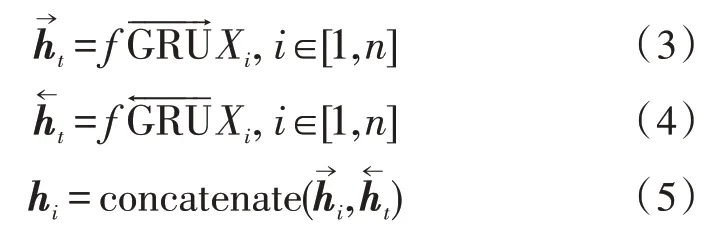
Attention 機制:將GRU 層編碼后生成的特征向量與注意力層的權值相乘,將每條文本對應罪名的詞級特征整合為句級特征。將hi輸入到Attention中,Attention 處理后輸出中間向量mi,如式(6)所示:
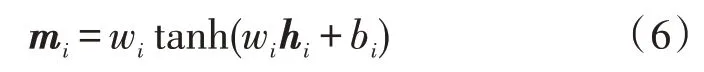
mc是實際向量,輸出向量mi與實際向量余弦相似度,求取各個詞語的注意力權重為αi,αi的計算公式如式(7)所示:
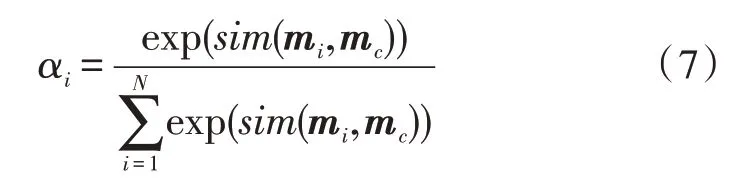
根據權重系數對輸出的拼接向量hi進行加權求和得到Hi,將求和得到的多個向量進行拼接,拼接后的矩陣為H,H如式(8)所示:
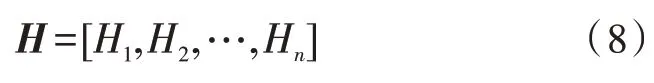
全連接層:全連接層采用ReLu、Dropout,并且加入了易混淆罪名要素,增加了模型對易混淆罪名區分的準確率。
輸出層:經過softmax 函數運算后得到判罰結果。在輸出層加入損失函數來解決罪名分布不均勻問題。focal loss 主要通過降低常見罪名權重,使模型關注于罕見罪名,進而解決罪名分布不均勻的情況。focal loss 是在交叉熵loss 基礎上進行了改進[8-9],該文的判罰模型本質是多標簽文本分類,因此將二分類focal loss展開為多標簽分類focal loss公式如(9)所示:
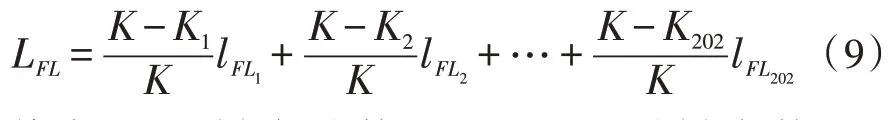
其中,K是樣本總數目,K1是lFL1時樣本數目。focal loss 的最終損失為202 種罪名損失加權值總和。模型參數較多增加了負擔[10-12],因此需分組來設置參數,具體參數如表1 所示。

表1 focal loss參數設置
2.2 模型參數設置
優化模型具體參數設置如表2 所示。
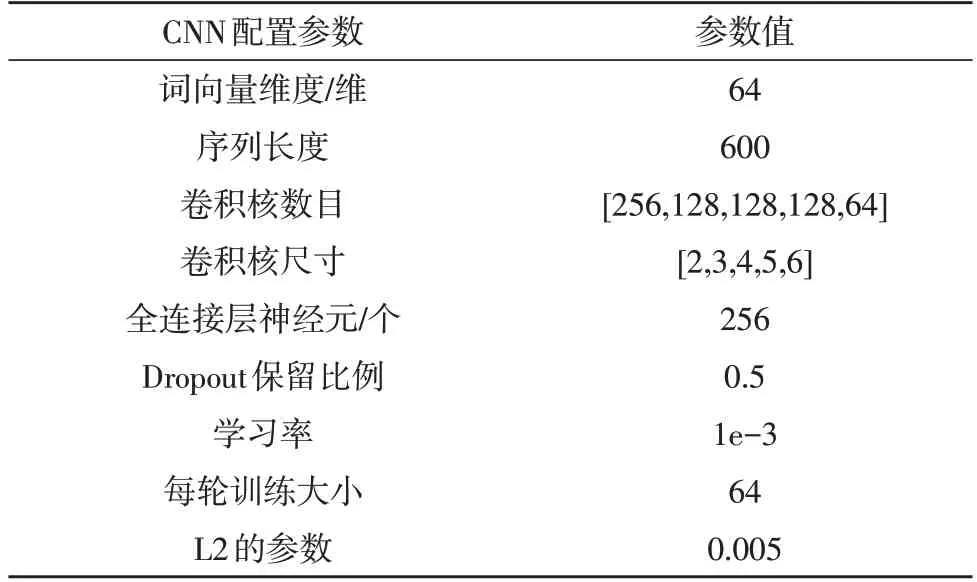
表2 優化模型參數配置
2.3 實驗結果及分析
將加入交叉熵loss 與focal loss 的模型進行性能對比,如表3 所示。

表3 模型性能對比實驗
采用focal loss 各項評估指標均高于交叉熵loss,Accu 提升了1.82%,Pre 提升了0.45%,Rec 提升了1.62%,F1 提升了1.62%,因此focal loss 能夠使模型性能得到提升[13-14]。因為focal loss 函數增加了罕見罪名權重,減少了常見罪名權重,令模型對難以訓練的標簽進行學習,從而提升模型性能[15-16]。加入其他司法判罰模型進行對比分析,各F1 值模型對比結果如表4 所示。
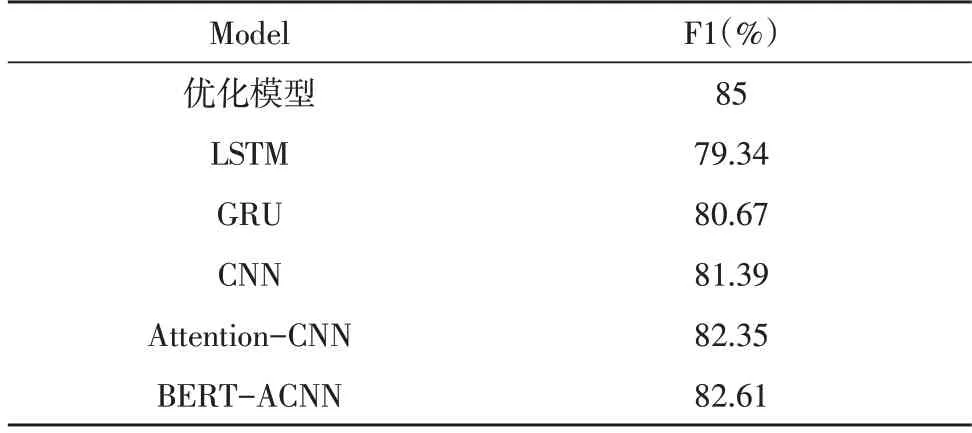
表4 各模型F1值對比
表4 加入了文獻[16]中的模型,通過對比分析得出如下結論:Attention-CNN 模型F1 值大 于CNN 模型,則加入了注意力機制模型能夠獲得更多語義信息。該文的模型F1 值最大,其次為CNN 類模型,最后是RNN 類模型,所以罪名預測時更多依據文書中的關鍵詞,而不是上下文語境信息。
3 基于深度學習司法判罰系統
3.1 系統設計
系統總體設計流程圖如圖3 所示。
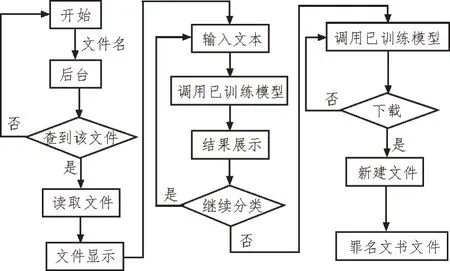
圖3 系統總體設計流程圖
1)文本顯示。點擊頁面文檔,文件名將被傳回后臺,在后臺存儲路徑中找到該文件并進行讀取,將讀取后內容顯示到前端頁面。2)文本分類。讀取數據并且調用司法判罰模型進行分類,分類結果顯示到前端頁面。3)文本生成。點擊下載后,在本地新建文件,將已分類的文本寫入到新建文件中,則在本地存儲了罪名文書文件。
3.2 系統測試
用戶選中目標件,右側顯示出文件名以及文件內容。點擊“分類”按鈕,分類結果被展示出來,如圖4 所示。用戶點擊“設置”選項,進入個人信息頁面,點擊“信息修改”按鈕即可完成修改,如圖5所示。罪名分類文書生成如圖6 所示,將分類后的文書以及分類結果生成文檔,點擊下載按鈕下載到本地。
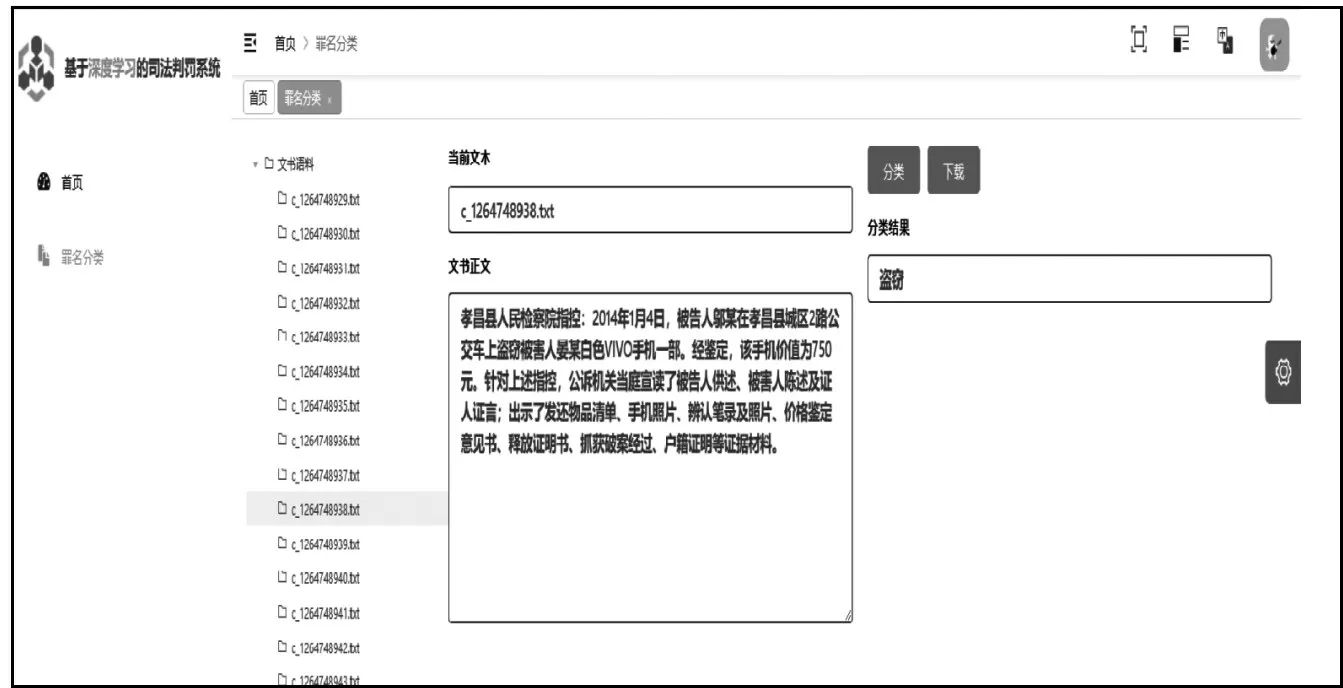
圖4 罪名分類頁面
圖5 用戶個人信息頁面
圖6 罪名分類文書下載頁面
4 結論
該文采用提取要素維度關鍵特征方式區分易混淆罪名,模型輸出層加入focal loss 函數,解決了數據不均衡問題,通過實驗對比得出:文中模型加入focal loss,相比于交叉熵函數Accu、Pre、Rec、F1 性能提升了1.82%、0.45%、1.62%、1.62%。最后建立了司法判罰系統,實現了罪名分類以及罪名分類文書生成功能,通過測試驗證了系統的有效性。
猜你喜歡
大灰狼畫報·益智版(2024年3期)2024-12-09 00:00:00
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
保健醫苑(2022年1期)2022-08-30 08:39:14
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
