電網總調調度信息披露不平衡性數據處理模型
2022-09-14 08:19:58侯方迪高衛東
電子設計工程 2022年17期
侯方迪,高衛東,張 勇,翟 哲,楊 凡,吳 亮
(中國南方電網有限責任公司,廣東廣州 610106)
電力供應一直是電力企業的核心業務,隨著電力設備的改造和升級,對調度可靠性要求越來越高,通過傳統的電話下令模式進行調度已經無法滿足要求,通過移動網絡及調度數據網實現配網調度成為當下的主流方式[1]。然而,這種新興的調度模式興起時間較短,發展并不成熟,普遍存在披露的數據信息內容雜亂,缺乏深層次統計和分析的問題。
披露的數據信息內容雜亂主要是由不平衡性數據造成的,因此必須對不平衡性數據進行處理。關于不平衡性數據處理的研究有很多,如:文獻[2]基于KFDA-Boosting 算法的不平衡數據分類模型,提取樣本非線性特征并進行集成學習,有效地提高了數據分類處理算法的精度,去除了冗余信息;文獻[3]提出基于隨機森林算法的不平衡大數據動態分類方法,通過隨機森林算法建立大數據動態分類基本框架,利用決策樹模型實現不平衡數據分類;文獻[4]提出基于SMOTE 的不平衡數據分類算法,通過SMOTE算法根據少數類樣本間特征空間的相似性人工合成新樣本,解決了數據不平衡的問題,提高了數據處理的精度。
基于前人的研究成果,為提高披露數據信息的完整性、規范性和有效性,該文構建了一種電網總調調度信息披露不平衡性數據處理模型。該模型構建分為3 個步驟,即數據預處理、數據特征提取以及數據分類。最后進行不平衡性數據處理性能測試,證明了該模型的準確性和有效性。
1 基于分類器的不平衡性調度數據處理模型
調度機構信息披露對于促進電力調度運行的公開透明以及維護公平、有序的市場秩序發揮著不可替代的作用。然而,當前的電網總調調度信息披露中,數據處理部分由于不平衡性數據的存在,導致處理效率差、準確性低。不平衡性數據的典型特點就是數據中各類別所包含的樣本數量差異較大,導致在后期的分類中更容易識別包含樣本較多的類別,而包含樣本較少的類別的識別準確性較低。面對電網總調調度信息披露不平衡性數據,構建了數據處理模型。
1.1 不平衡性數據預處理
不平衡性數據預處理對于提高數據處理模型的精度具有十分重要的意義,其主要包括數據清洗、數據標準化以及數據平衡化三部分。
1.1.1 數據清洗
電網總調調度披露的數據信息中,經過采集、傳輸等環節,數據集中難免存在缺失、異常、噪聲等問題,數據清洗主要包括缺失填補、異常識別以及噪聲處理,其方法如表1 所示。

表1 數據清洗方法
1.1.2 數據標準化
電網總調調度信息披露不平衡性數據來自不同的數據源,因此每種類型數據的量綱都不同,而不同的量綱導致數據彼此之間無法進行比較和分析,因此需要對數據進行標準化處理[5],主要包括Min-Max 標準化、正規化方法及log 函數轉換法,分別如下所示:
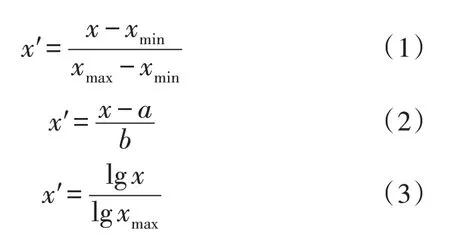
式中,x′為規范化后的大數據;x為原始數據;xmax為大數據集中最大值;xmin為大數據集中最小值;a為對應特征均值;b為標準差。
1.1.3 數據平衡化
數據的不平衡性是導致電網總調調度數據信息處理精度不高的根本原因,因此對數據進行平衡化處理是解決上述問題的關鍵。數據平衡化的關鍵在于增加少數類別的樣本數據,使其與少數類別的樣本數據數量相同,以維持二者平衡[6]。采用SMOTE算法實現數據平衡化,其原理為在一些位置距離較近的少數類樣本中線性插入新的樣本,以達到數量平衡。
SMOTE 算法數據平衡化原理如下:首先從少數類樣本點中隨機選取一個樣本點,記為x1,然后尋找該樣本點的同類近鄰,記為{x1,x2,…,xn},一般情況下n取值為5~10,接著從{x1,x2,…,xn} 中隨機選擇一個樣本,記為x2,再然后計算x1和x2在對應屬性j上的差值,記為:

然后與[0,1]范圍內的一個隨機數相乘,再與x1j相加,即可生成一個新的的屬性值f1j,即:
利用SSR分子標記技術進行純度鑒定時,有些與雜交種帶型有明顯差異的單株在種植鑒定時并不一定表現出表型性狀的差異,因此SSR分子標記技術用于純度鑒定時,可以有效鑒別出大田無法確定的表型以及難以鑒別的植株,因而分子鑒定和種植鑒定結果必然存在一定的差異,而種植鑒定是最符合生產實踐的純度鑒定方法,如何使分子鑒定結果更接近種植鑒定、更好地輔助種植鑒定結果還需進一步研究。
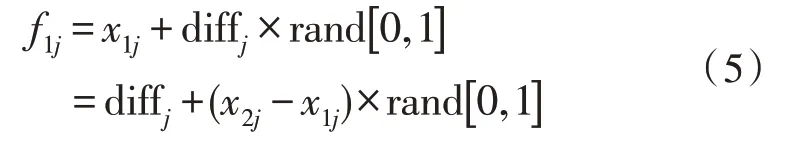
不斷重復上述過程,最后得到m個屬性值,將其組合在一起,產生一個新的少數類樣本,將這一新的少數類樣本加入到原始少數類樣本數據集中,即可完成數據平衡化處理[7-9]。
1.2 數據特征提取
不同類別的數據擁有不同的特征,如電網總調調度信息中的缺失數據、趨勢突變數據等。該文選用的特征提取方法為人工蜂群算法[10-12]。
人工蜂群算法基本流程如下:
步驟1:初始化種群,隨機生成S個可行解,記為xi,i=1,2,…,S;
步驟2:計算種群中各蜜蜂的適應值[13];
步驟3:重復計算各蜜蜂的適應值,得到蜂群新的解,記為vi,并計算適應值;
步驟4:雇傭蜂根據貪心策略選擇蜜源;
步驟5:計算引領蜂找到蜜源xi的概率pi;判斷蜜源xi是否滿足被放棄的條件,若滿足,對應的引領蜂角色變為偵察蜂,并隨機產生一個新的蜜源代替舊的蜜源,否則繼續進行下一步驟;
步驟6:判斷算法是否滿足終止條件,若滿足,則終止,記錄最優解,否則轉到步驟2[10-12]。
1.3 不平衡性數據分類處理
基于上述研究,構建分類器并進行訓練,利用訓練好的分類器進行不平衡性數據分類處理[14]。決策樹是一種分類算法器,其構建基本原理是通過遞歸的方式進行屬性歸類,生成不同的決策樹,基本流程如圖1 所示。
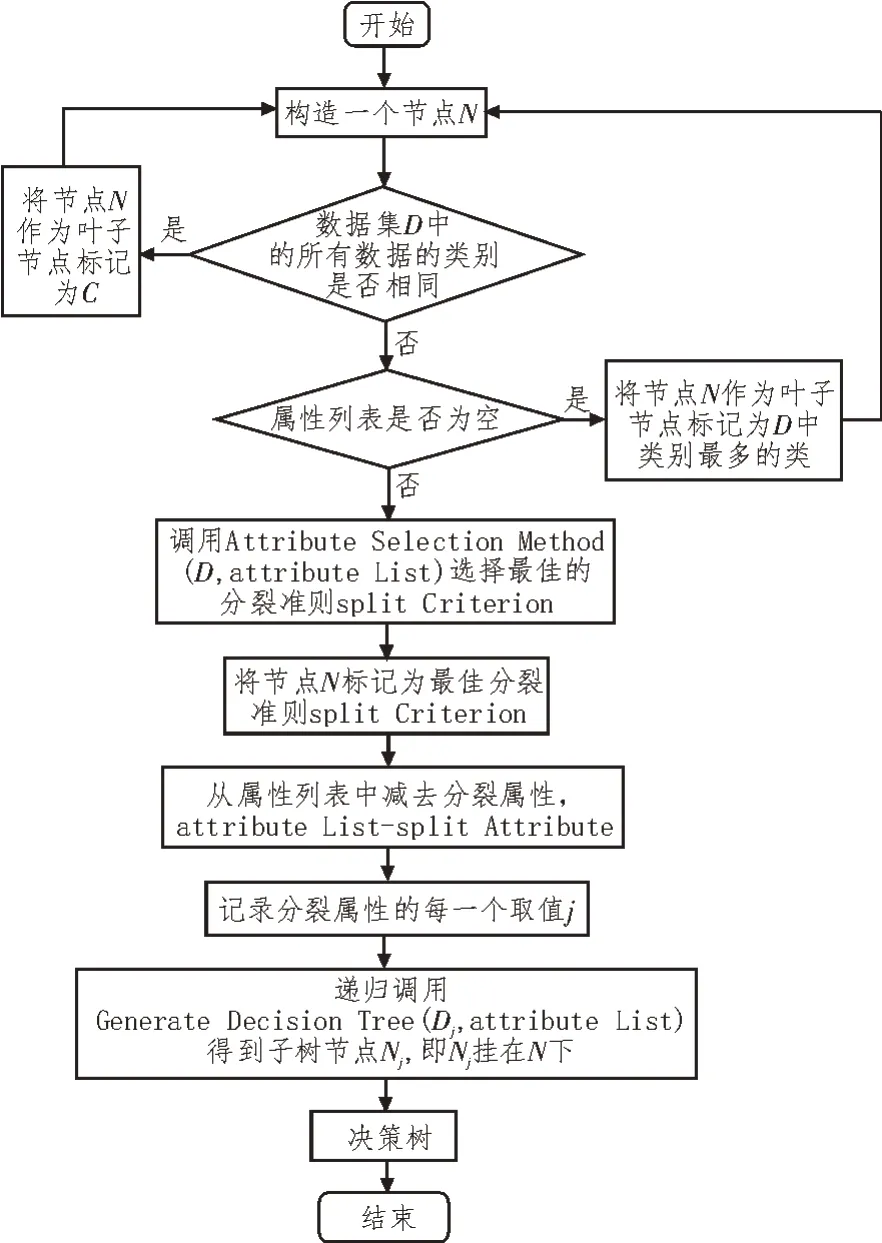
圖1 決策樹構建基本流程
將構建的決策樹作為基分類器,構成隨機森林,實現分類[15]。具體過程如下:首先利用Bagging 方法進行放回抽樣,為每棵決策樹產生訓練集,然后利用訓練集訓練決策樹[16]。訓練完成后,將決策樹組合構成隨機森林,最后將測試數據集輸入到隨機森林中,通過投票方式完成分類預測。
2 仿真實驗分析
為了驗證該文提出的電網總調調度信息披露不平衡性數據處理模型的有效性,在Eclipse 環境下的Weka 平臺進行仿真實驗,并用文獻[2]、[3]、[4]提到的3 種算法作為對比項,進行對比分析。
2.1 實驗樣本
以紅水河水庫日來水數據為例,選取2020.01.01-2020.03.31 的日來水數據作為不平衡性數據示例,仿真實驗參數設置如表2 所示。

表2 仿真實驗參數設置
2.2 實驗結果
分別采用文獻[2]、[3]算法及所提方法對實驗數據中的不平衡性數據進行分類處理,得到2020.01.01-2020.03.31的紅水河水庫日來水數據趨勢如圖2所示。
分析圖2,該文模型對不平衡性數據的處理性能較好,按照日來水數據整體趨勢對不平衡性數據進行處理,得到紅水河水庫日來水數據趨勢整體在2 200~2 800 m3/s 之間波動,而兩種文獻對比模型對數據的處理性能較差,不能很好地得到紅水河水庫日來水數據趨勢。
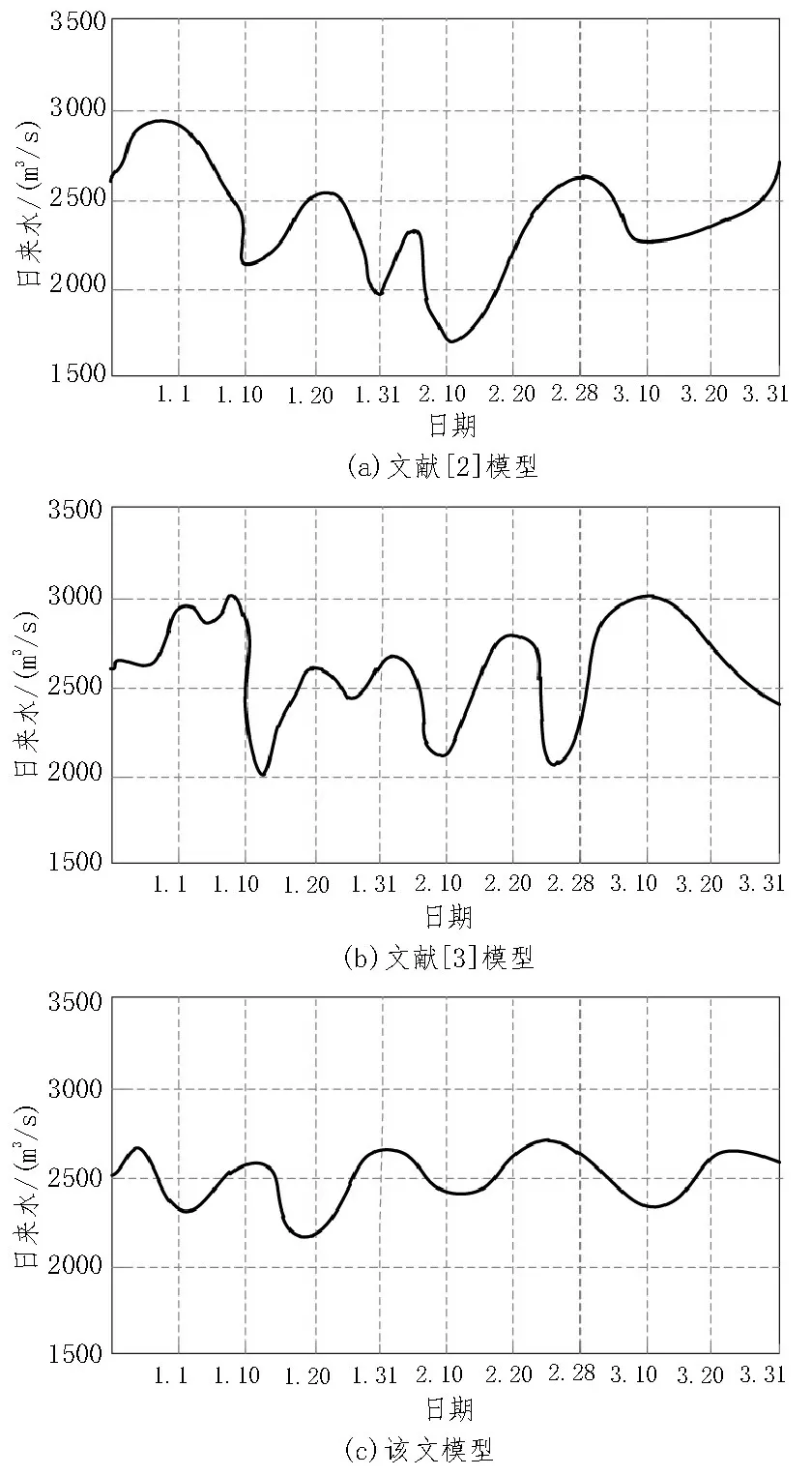
圖2 不平衡數據處理后的紅水河水庫日來水數據趨勢
經不同方法對數據處理后,根據所得數據趨勢對2020.04.01-2020.04.31 的數據進行預測,得到紅水河水庫日來水數據預測結果如圖3 所示。
分析圖3,該文模型預測值與實測值較為接近,說明該文模型能夠準確處理不平衡性數據,實現水庫日來水情況的預測。
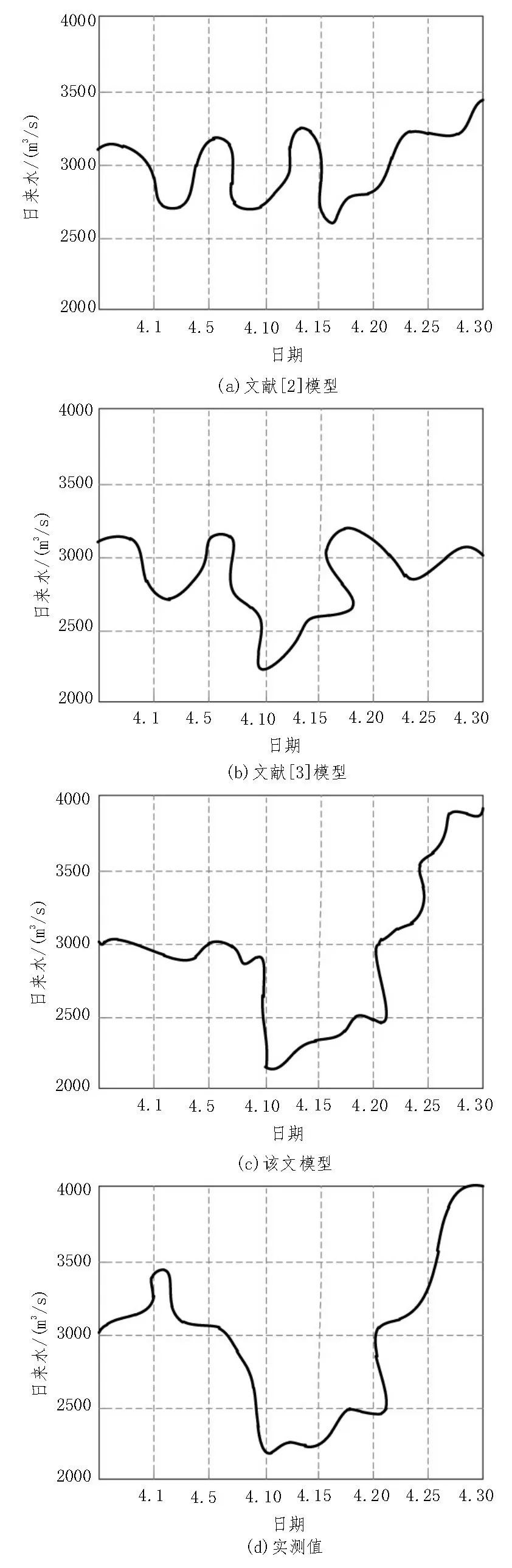
圖3 紅水河水庫日來水數據預測情況
3 結束語
綜上所述,隨著電力的需求范圍越來越廣泛,對電力調度的可靠性和效率性要求越來越高,因此,電網總調調度信息披露系統逐漸取代傳統的調度信息傳遞方式,提高了數據信息傳遞效率,然而披露系統的應用,同時也使數據信息量劇增,導致數據信息內容雜亂,缺乏深層次的統計和分析。基于此,構建一種電網總調調度信息披露不平衡性數據處理模型,該模型經仿真實驗測試,證明了其在不平衡性數據處理中的性能,提高了不平衡性數據處理的精度,規范了電網總調調度數據信息。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
心理學報(2022年4期)2022-04-12 07:38:02
水泵技術(2021年3期)2021-08-14 02:09:20
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
