基于異構數據融合的地震綜合數據分析系統設計
2022-09-14 08:20:02張婷婷章熙海王冬辰
電子設計工程 2022年17期
張婷婷,章熙海,王冬辰
(江蘇省地震局,江蘇南京 210014)
近年來,我國多地頻繁發生地震災害,對人們的生產生活和社會經濟的發展產生了嚴重影響[1-3]。由于我國有很多地區位于地震高危區,對地震的預測能力以及針對地震災害的準備工作顯得尤為重要[4-5]。
隨著大數據技術和計算機技術的快速發展,越來越多的學者開始使用大數據與深度學習對地震綜合數據進行信息挖掘[6-10]。傳統數據分析方法僅適用于單一模態數據,由于各項地震相關數據的格式不同,為多模態數據,因此如何提高多模態、異構數據的分析效率成為了當前的熱門課題之一[11-16]。
針對地震綜合數據中的多模態、異構數據,該文構建了無監督多模態、非負相關特征融合算法,用于實現多模態數據共享空間內部特征的融合規律學習和聚類分析;同時,利用深度置信網絡構建了多模態、異構數據特征分析模型,在網絡平滑約束下將融合后的特征進行學習和分類,有效提高了數據分析能力。
1 地震綜合數據分析系統框架
地震綜合數據分析系統是面向地震高危區用于應急準備、處置和預評估的系統。其涉及的數據包含了各個地區的地震應急基礎數據和各類地震探測儀器所產生的數據,旨在評估地震風險和可能造成的災害損失,以便有針對性地提高地震應急準備能力。地震應急基礎數據包含了當地轄區的建筑物類別、密度、逃生避難場所的數量等;地震探測數據包含地震矢量數據中的縱橫波速度、振幅、頻率以及同一波場的空間偏振狀態等信息。地震應急基礎數據多為文字、數字格式;而地震探測數據多為數字格式。這些數據因來源、格式不同,屬于異構數據。
地震綜合數據分析系統采用B/S 結構,可在電腦、智能手機瀏覽器訪問。該系統共有3 層,分別為表現層、邏輯層和數據層。表現層為系統所有功能的展示、交互界面;邏輯層為分解功能需求提供必要的邏輯操作;數據層為功能需求提供必要的數據及運算。由于地震應急基礎數據和地震探測數據量較大,且處理操作、速度需要較高的要求,因此將云計算技術用于數據的儲存、計算以及相關算法的存儲、更新,具體框架如圖1 所示。
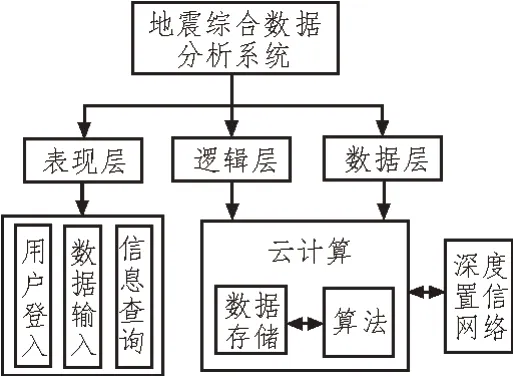
圖1 地震綜合數據分析系統框架
由于地震預測數據通常來自于多個數據源或數據信道,能夠從不同的側面反映數據的不同特征,進而形成互補,提高地震預測精度。與傳統單模態數據分析不同的是,多種模態的數據融合方式與該模態數據的統計特性相關,直接影響數據特征的有效性。該文基于深度置信網絡來構建無監督、多模態數據非負相關特征的融合算法,以解決多模態地震數據的融合問題。主要包含了以下3 個方面:構建無監督多模態、非負相關特征融合算法,以解決多模態數據共享空間內部特征的融合規律學習和聚類分析;構建針對多模態數據的相關和不相關特征共享學習機制,將私有特征分離后得到具有可靠魯棒性的模態共享特征;針對多模態數據制定聯合目標優化函數,以完善無監督、多模態數據非負相關特征融合算法的優化和收斂過程。
2 地震綜合數據分析算法
2.1 異構數據融合
地震探測數據主要為面波的頻散特征數據,分為多分量面波相速度頻散特征和瑞利波多模式橢圓率頻散特征。由于瑞利波在不同深度時的各個模式相對位移大小并不一致,可以利用這一特點并將其作為瑞利波的頻散特征。故在垂直方向上,瑞利波的梯度場可用下式得到:
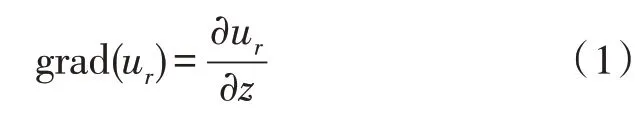
那么,對于深度為h1的梯度值,利用差分近似原理可推導出:
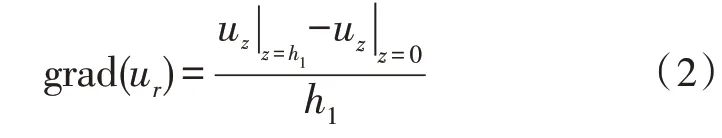
由于瑞利波各個方向的速度不同,將徑向位移和垂向位移的比值隨頻率改變的現象稱為瑞利波的橢圓極化,可用下式計算在彈性介質條件下第j階瑞利波的橢圓率:

式中,ur、uz分別表示的是瑞利波質點軌跡相對于水平軸、垂直軸的分量。
該文所設計的融合算法框架如圖2 所示,首先將不同模態之間的私有特征與共享特征分離,可提高對共享特征的學習效率,進而實現更加準確的多模態數據融合,通過對多模態共享特征VC進行聚類分析,最終實現有用信息的挖掘。
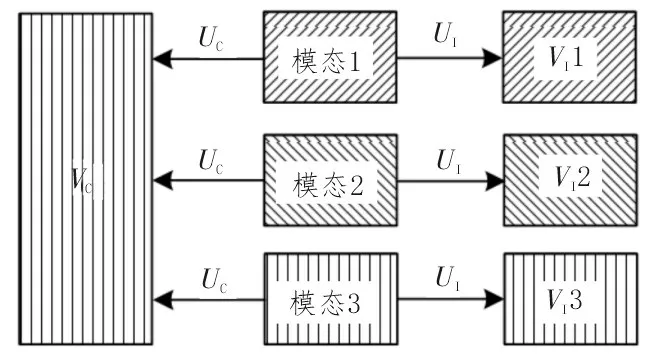
圖2 非負相關特征融合算法框架
當給定跨模態數據的潛在共享特征的維度UC和各自的私有特征維度UI時,多模態非負相關特征學習模型被定義為下式:
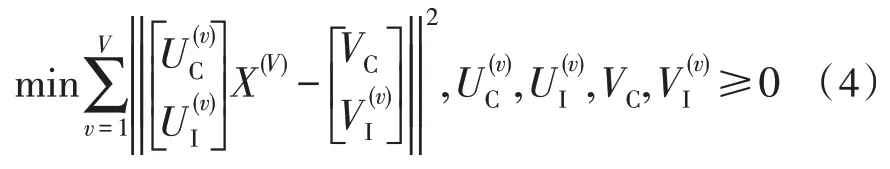
由于對模態實例的相似結構描述方式會影響特征降維后的精準度,該文使用不變圖模型對VC進行規范化描述,進而將模態數據與共享特征的幾何結構誤差降到最低。模態數據之間的幾何結構可通過最近鄰圖來表示,Wij表示兩個數據Xi與Xj之間的相似程度,當Xi和Xj均在彼此的p個鄰接點范圍內時,有如下關系:
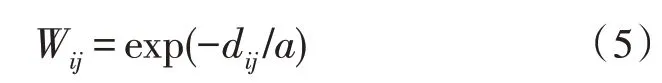
式中,dij為數據Xi、Xj之間的歐氏距離。該實例數據的不變圖嵌入函數為:
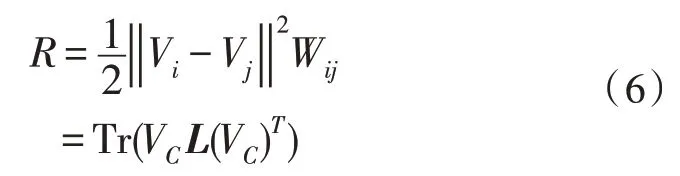
式中,Tr(·)為矩陣的跡;L(·)為圖拉普拉斯矩陣。
2.2 地震綜合數據分析模型
利用上文所述無監督、多模態數據非負相關特征融合算法進行多模態特征的融合,得到的結果作為地震綜合數據分析模型的輸入數據。如圖3 所示,該文使用深度置信網絡(DBN)進行地震綜合數據分析模型的構建。深度置信網絡的基本結構為限制波爾茲曼機(RBM),由于其是雙層結構,因此通常被用來構建實驗數據與人工標簽之間的聯合分布。同時,RBM 結構的能量可通過式(8)來計算。θ={pi,qj,Wij}為RBM 結構參數,分別代表輸入層神經元的偏置、隱藏層神經元偏置以及兩層神經元之間的權重,其數值表征神經元之間的相似程度。
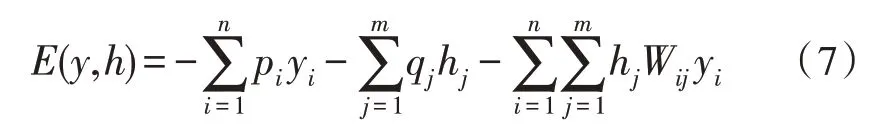

圖3 地震綜合數據分析系統原理框圖
針對地震矢量數據中的縱橫波速度、振幅、頻率和同一波場的空間偏振狀態等信息,由于不同模態的數據范圍有限以及相鄰節點所受到的影響相似,RBM 結構并不能充分與地震多模態數據融合后的特征相結合。因此該文對RBM 結構進行優化,通過對連接矩陣建立約束來適應地震多模態數據。具體方式為將懲罰函數融入至RBM 損失函數中,其損失函數被定義為:
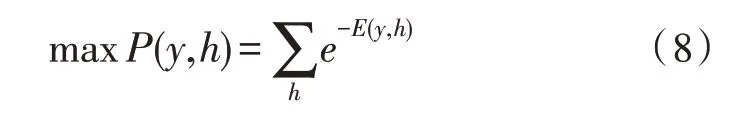
如圖4 所示,該文使用網絡平滑約束因子b對RBM 權重參數進行約束。當地震發生時,距離較近的位置所展現出來的瑞利波特征是類似的,且同種建筑類別所受到的損害也是相似的,所以地震綜合數據分析模型中RBM 結構有著相似的網絡權重參數。網絡平滑約束通過使RBM 結構中相鄰網絡權重參數的差值趨近于0 來實現連接矩陣之間的約束,從而達到讓相鄰節點在學習特征能力上有著相似的效果。
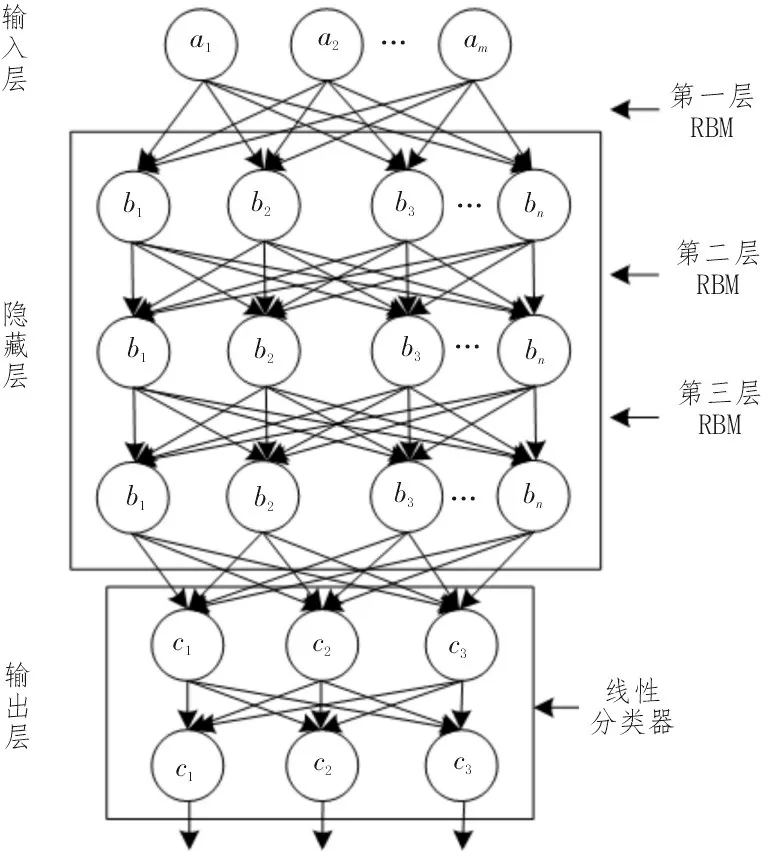
圖4 地震綜合數據分析模型結構
文中將地震災害類別定義為特別重大、重大、較大以及一般共4 個級別,因此模型的輸出項分類設定為5 項,使用5 個神經元。第一層RBM 結構中隱藏層的神經元個數由下式確定:
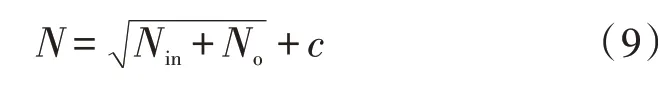
式中,Nin與No分別代表數據輸入層神經元數量和輸出層神經元數量,c為模型調節因子。該文使用Sigmoid函數作為隱藏層中的激活函數,其表達式為:
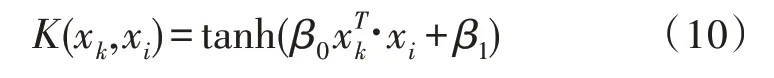
由于RBM 每一層的神經元個數和隱藏層的數量對模型訓練時間、學習效率有著相反的作用,綜合考慮模型訓練時間與精度,該文將地震綜合數據分析模型設計成由3 層RBM 結構和一層線性分類器所組成的結構。每一層RBM 隱藏層均具有120 個神經元,線性分類器含有50 個神經元。
3 測試與驗證
該研究使用江蘇省某地區近5 年的地震應急基礎數據和地震探測數據作為樣本數據進行模型訓練。地震應急基礎數據涉及各個社區、村莊所有常住人口的基本信息、人員結構以及建筑物信息等。其中建筑物信息重點關注學校、醫院、避難場所以及大型企業的地理位置、建筑形式、不同級別地震發生后所受到的損害等信息。地震探測信息包含近5 年地震矢量數據中的縱橫波速度、振幅、頻率以及同一波場的空間偏振狀態等信息。
基于異構數據地震綜合數據分析系統,采用Python 集成開發平臺進行地震應急基礎數據和地震探測數據的預處理以及DBN 模型的開發。異構數據特征的融合和DBN 模型的構建、訓練所使用的硬件環境如下:配置為Intel(R)Core(TM)i7-5410 CPU@8.0 GHz,1 TB 固態硬盤,GPU 為Nvidia 的RTX 系列計算機。
實驗數據共有54 000 個樣本,按照8∶1∶1 的比例隨機分為非線性表達訓練數據、分類器訓練數據和測試數據,使用純度、精度聚類指標來驗證該文所述異構數據的融合效果。文中設置MultiNMF 算法作為對照組來驗證所述無監督多模態、非負相關特征融合算法的優越性,兩種算法的學習因子均設定為0.01;所有模態規則化參數均設定為100。
在使用相同的測試數據和輸入、輸出節點數情況下,純度、精度指標如圖5 所示,圖中1 代表純度,2代表精度。從圖中可以看出,該文所提出的無監督多模態、非負相關特征融合算法無論是純度或是精度均優于MultiNMF 算法。這主要是因為無監督多模態、非負相關特征融合算法能夠同時對相關和非相關的特征進行學習,并在共享模態中分離出私有模態,從而提高聚類性能。而MultiNMF 算法僅是將不同模態的特征無差別融合,削弱不同模態之間的差異性。
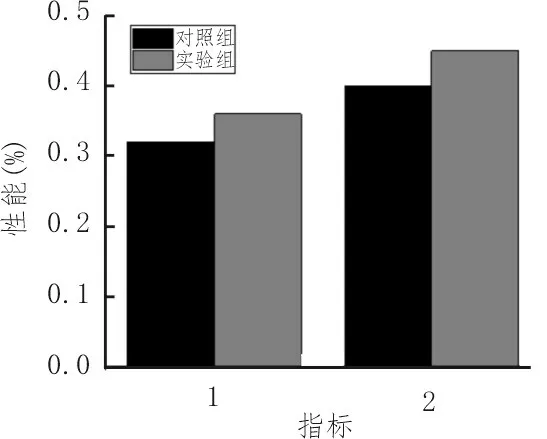
圖5 純度和精度兩種算法對比
圖6 分別展示了規則化因子a和稀疏化因子b對聚類結果精度的影響。從圖中可以看出,隨著參數a和b的增加,聚類精度均呈現出先上升再下降的趨勢。當a=0.6 時,聚類精度取得最大值0.665%,這表明各個模態數據與共享特征之間具有極高的相似性;而稀疏化因子b的增加,在一定程度上會改善聚類精度,但一旦取值過大,則會起到反作用。
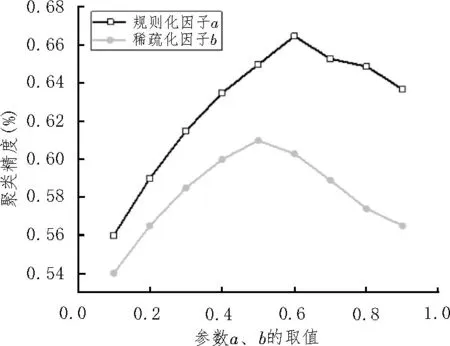
圖6 影響聚類結果精準度的變化曲線
4 結束語
該文采用深度置信網絡進行了地震綜合數據分析系統的設計與開發,該系統可以有效解決不同模態數據的特征融合問題。經過測試與數值分析,該方案具有較強的可行性,系統綜合性能優越。值得注意的是,該文所述的地震綜合數據分析系統僅針對文本、數字這兩種格式的數據,而對于圖片、視頻等多媒體格式尚未進行研究,這也將是下一步的工作內容之一。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機學院學報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
