基于聚類算法的交通網絡攻擊識別方法
2022-09-18 06:43:36徐建斌陳旻瑞
交通科技與管理 2022年18期
關鍵詞:網絡安全
徐建斌,陳旻瑞
(江西省交通監控指揮中心,江西 南昌 330036)
0 引言
隨著互聯網的蓬勃發展,多樣化的網絡攻擊手段威脅著網絡安全,交通運輸作為生活中必不可少的部分,交通網絡攻擊嚴重影響日常生活。目前,眾多學者深入研究了交通網絡安全,文獻[1]研究了城市軌道交通云平臺網絡安全防護平臺方案,通過分析城市軌道交通網絡安全現狀及國家網絡安全政策要求,提出基于網絡安全等級保護2.0的基本要求,構建城軌云網絡安全防護平臺,根據“一個中心”管理下的“三重保護”體系框架進行設計,構建安全機制和策略,形成定級系統的安全保護環境。但是該方法對網絡攻擊邏輯分析不夠深入,導致攻擊識別準確率低;文獻[2] 研究了符合等級保護三級要求的城市軌道交通綜合監控系統信息安全,根據國家標準有關等保的要求,分析了目前ISCS信息安全現狀和存在的問題,圍繞“一個中心、三重防護”要求,提出了ISCS信息安全的設計方案,并從ISCS網絡安全架構、信息安全功能設置等方面給出了實施建議,但是該方法的針對多樣化的攻擊方式,識別的準確率低。針對上述問題,提出了基于聚類算法的交通網絡攻擊識別方法。
1 交通網絡攻擊識別方法
1.1 K-means聚類算法度量相似性
K-means聚類算法[3]是常用的聚類算法技術,其是一種改進的聚類算法中的劃分方法,并且以特征空間的距離作為測量相似性的標準。通過測算特征距離計算兩個數據樣本之間的相似性,間距越短代表兩個數據差異越小,間距越長代表兩個數據差異越大。計算相似性度量使用的函數,需要滿足兩個數據對象間的距離大于等于0且互為對稱等條件。閔可夫斯基距離(Minkowski Distance)度量是常見的相似性度量計算方法:
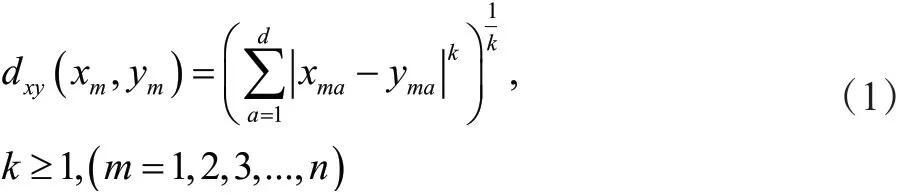
式中,mx與ym代表兩個數據對象;dxy代表兩個數據對象之間距離相似性;k為常數,當k=1時,公式(1)代表絕對距離;當k=2時,公式(1)代表歐幾里得距離,又稱歐氏距離,該距離是目前聚類分析[4]中應用最多的距離。在聚類算法計算中,使用歐氏距離算得的結果不會受到特征空間平移和旋轉的影響。
1.2 網絡攻擊數據平衡化處理
網絡攻擊數據不平衡是網絡攻擊識別中經常面臨的問題,不均衡的攻擊數據集會影響識別的準確率。過采樣指合成少量類樣本的一種方法,合理的采樣方式會提高合成偽樣本的適用性、降低網絡攻擊識別的錯誤率。該文基于Smote算法進行優化后,得到了Keans-Smote過采樣算法,平衡化處理網絡攻擊數據。Keans-Smote算法的類間離散度較低、數據對象較多時生成偽樣本較少、偽樣本的分布形式與原始樣本差異性較小以及保證了偽樣本合理性,并使其在分類邊界內。使用Keans-Smote算法處理數據,生成的偽樣本與真實樣本相似度更高,在網絡攻擊識別模塊中,算法處理數據的適用性更強。Keans-Smote算法基本原理圖如圖1所示:
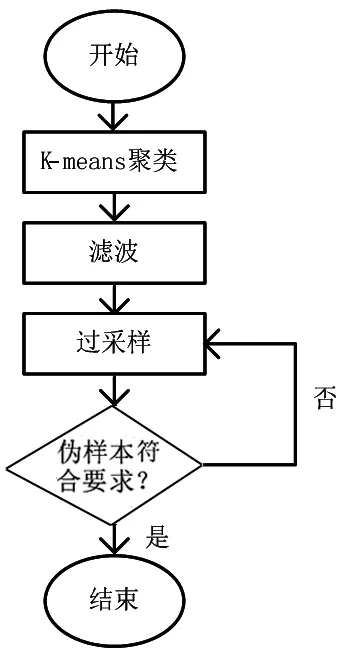
圖1 Keans-Smote算法基本流程圖
首先利用Keans-Smote算法在少量類樣本內計算出聚類中心數據,參考聚類中心數據來劃分聚類內的簇;然后選擇采樣簇,通過單個簇與平均簇的密度比,計算過采樣簇的比重,比重影響偽樣本的生成數量,簇的密度公式如下式所示:

式中,Mc——簇內少量類樣本數據;AMDc——計算少量類樣本平均距離。根據采樣簇的比重,進行濾波操作,進一步獲得需要過采樣的簇,并執行過采樣操作,直到所有參與采樣的簇中全部偽樣本符合要求,結束操作。
利用Keans-Smote算法采樣操作后,考慮到操作過程中遇到數據缺失等問題,該次實驗使用平均值法平衡化處理攻擊數據。首先,通過隨機排列組合將小樣本的參數構建成大樣本的網絡攻擊數據集,然后計算多分類數據的不平衡率、采樣次數與偽樣本數量,利用過采樣算法生成攻擊數據的偽樣本,隨機混合偽樣本與原始數據,獲得數量平衡的網絡攻擊數據樣本集。經過平衡化處理的網絡攻擊數據用于最終的實驗測試階段。
1.3 利用流頭部探測邏輯攻擊
隨著互聯網攻擊頻率的增長,流量攻擊成為互聯網攻擊的主要方式,以前通過系統Bug攻擊主機的方式已經逐步被流量攻擊取代,因此需要分析流量攻擊。源IP、目的IP、各種端口號以及協議號的集合定義為流,而流中的報文數據就是流頭部。流頭部是識別網絡受到流攻擊的重要模塊,如向目標廣播地址發送icmp-echorequest報文時,這就是Smurf攻擊,因為Smurf攻擊數據流是偽造的源地址數據。當攻擊數據流的字節大時,成為Ping of Death 攻擊。當傳輸層控制協議為TCP與UDP時,當攻擊流的源IP與目的IP都相同時且源端口與目的端口也相同,則攻擊是LAND attack;若攻擊流的源端口和目的端口都是通過UDO回射客戶服務器,那么該次攻擊就是Ping攻擊,與此同時,如果假設目的地址都是廣播地址,那么該次攻擊就是Fraggle攻擊。當識別模塊在各應用協議處的流頭部識別出很大的字節數與數據包個數時,此攻擊為SYNC Flooding攻擊,其中字節數與數據包個數可以利用提前設置的閾值判定。
1.4 構建網絡攻擊識別模型
當交通系統受到網絡攻擊后,因受到空間分布異常的影響,識別方法無法準確劃分攻擊樣本,因此,為了實現此類樣本的精準劃分,通過焦點損失函數改進Lightgbm算法,提升網絡攻擊識別模型的數據分類能力。原始Lightgbm損失函數如公式(3)所示,焦點損失函數優化后如公式(4)所示:
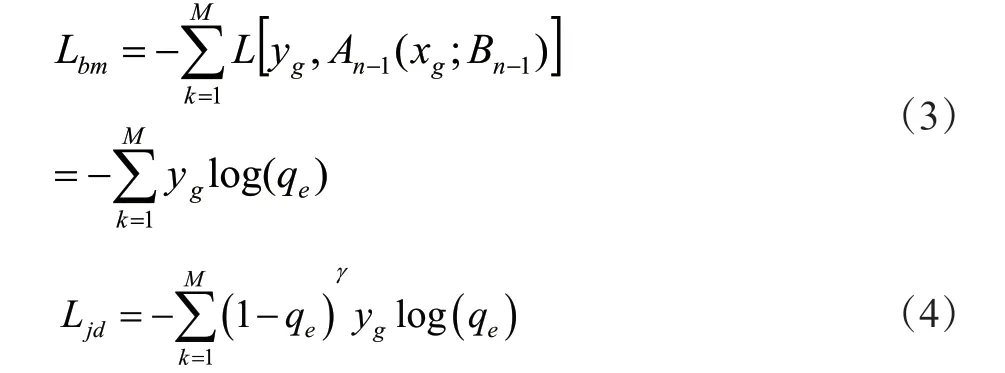
式中,n——第n棵決策樹;M——攻擊樣本類別的參數;qe——預測攻擊樣本g為e的概率;An-1(xg;Bn-1)——在Bn-1條件下,第n?1棵決策樹模型預測攻擊樣本xg的數據;Bn-1——n?1棵決策樹的集合;L[yg,An-1(xg;Bn-1)]——誤差函數;1?qe表示損失的調節因子;數據γ——容易分類的攻擊樣本比重降低的速率數據。通過此焦點損失函數優化后的Lightgbm函數,可以使攻擊樣本分類的正確率上升。
優化后的此算法作為該次設計的攻擊識別模型,如網絡攻擊數據進行平衡化處理后的集合為R,那么R={(x1,y1),(x2,y2),(x3,y3),…,(xn,yn)},xg∈R,yg∈{0,1,2,3}。其中xg表示攻擊樣本,yg表示攻擊數據的標注,則交通網絡攻擊識別模型輸出如下式所示:

網絡攻擊識別模型[5]屬于多分類建模,不同的輸出結果代表不同的攻擊以及非攻擊事件,當此模型輸出為0,表示交通網絡系統未受到攻擊;當輸出為1,表示交通網絡系統受到來自改變量測參數的攻擊;當輸出為2,表示交通網絡系統受到了來自改變控制信號的攻擊;當輸出為3,表示交通網絡系統受到了來自改變設備數據的攻擊。構建交通網絡攻擊識別模型詳細步驟:步驟一,通過歸一化方法處理受到攻擊的最佳特征子集,同一級別化系統狀態變量參數;步驟二,通過焦點損失函數優化后的Lightgbm函數分類攻擊樣本,找出最佳樣本參數;步驟三,通過貝葉斯公式獲取最佳樣本參數中重要數據;步驟四,再次通過焦點損失函數優化后的Lightgbm函數分類最佳數據集,獲得最后的識別模型;步驟五,利用測試集評估識別模型性能,不滿足條件的再次執行步驟三、四,滿足條件后保存結果[6-8]。
2 實例分析及討論
2.1 劃分江西省交通網絡演變階段
實驗以江西省交通監控指揮中心的網絡為研究對象。江西省自90年代起,逐步拓展、發展交通網絡。低等級道路網形成、高速公路網誕生、低等級道路網成熟和高速公路網成熟這四個階段是江西省交通網絡演變的代表。江西省的交通網絡類別比較簡單的時期,低等級公路網絡系統較為完整,監控范圍寬廣,因此,在當時的交通運輸中起著核心作用;江西省內各處高速公路的全面建成,標志著這時期全新高速公路交通網絡的誕生,在國道線路的穩定、省道以及縣鄉道線路的增多中發揮了重要作用;在江西省高速公路快速發展的時期,低等級公路網走向成熟,高速公路骨干網也初步形成;當江西省進入高鐵時代,形成了占比較高的骨架路網,這一時期,完成了高鐵網絡的搭建,在高速公路的線路大幅增加的同時,高速公路網趨于成熟。
2.2 實驗研究測試
通過MATLAB平臺分析江西省交通監控指揮中心的交通網絡,試驗通過數據管道對網絡攻擊流、攻擊識別模塊與指揮中心的交通網絡之間傳輸數據。設置好實驗環境參數,首先利用網絡攻擊流對交通網絡攻擊網絡,在此過程中,分別使用基本的網絡攻擊識別方法與該文所提的基于聚類算法的網絡攻擊識別方法對此攻擊流進行識別,最后通過Linux算法分別評估這兩個方法對網絡攻擊的識別性能,并比較識別結果。實驗過后,統計這兩個方法識別的有效次數,并分別計算識別率,得到的結果如圖2所示。
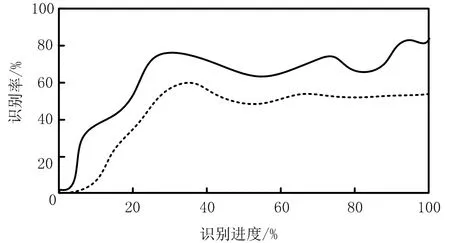
圖2 網絡攻擊識別率對比
圖中,實線代表該文所提識別方法,虛線代表基本識別方法。由圖2可知,基于聚類算法的交通網絡攻擊識別方法的識別效果遠好于基本網絡攻擊識別方法,其識別率達到了80.4%,基本識別方法的識別率僅為59.7%,該文識別方法提高了20.7%。該文攻擊識別方法大幅度提升了識別率,與此同時還可以保護交通網絡的設備安全,識別模塊控制主板中的微型處理器與網絡設備的各硬件結構搭配,不僅滿足了交通監控指揮中心的多種需求,也提升了對網絡攻擊識別的正確率。
基本交通網絡攻擊識別方法由于其數據庫資源不足,并且硬件與軟件的協調程度低,因此,在面臨時下多樣性的網絡攻擊下,不僅識別的正確率低,而且受到攻擊后的應急手段也較差。但該文提出的基于聚類算法的交通網絡攻擊識別方法,在原有的識別方法基礎上增加了聚類算法,具備聚類算法的優點,大幅度提升了新型網絡攻擊識別的正確率,也給指揮中心更多的功能選擇,最大限度地幫助指揮中心識別多種網絡攻擊,保證交通網絡安全。
3 結束語
交通網絡是當代人類發展的重要組成部分,而交通監控指揮中心是實現交通網絡正常運轉的關鍵,其交通網絡安全至關重要,因此,該文提出基于聚類算法的交通網絡攻擊識別方法,該方法引入了聚類算法,其對多樣化的網絡攻擊識別準確率較高,并且可以保證交通網絡設施的安全性。但是該系統仍然需要一定的優化,現代網絡攻擊手段存在多樣化特性,而該文所提識別系統僅可以保證部分網絡攻擊的識別準確率,識別的范圍還不夠全面,今后仍需繼續研究,提高交通監控指揮中心的網絡安全,保證其安全管理與維護。
猜你喜歡
兒童故事畫報·智力大王(2025年3期)2025-03-09 00:00:00
工會博覽(2023年27期)2023-10-24 11:51:28
科學大眾(中學)(2019年2期)2019-04-08 02:26:40
中國生殖健康(2019年10期)2019-01-07 01:21:04
信息安全研究(2018年12期)2018-12-29 11:01:46
小學生必讀(中年級版)(2018年4期)2018-07-05 06:00:48
湖北警官學院學報(2017年3期)2017-06-21 09:25:51
信息安全與通信保密(2016年3期)2016-08-23 01:23:32
互聯網天地(2016年1期)2016-05-04 04:03:20
信息安全研究(2015年3期)2015-02-28 20:18:17
