基于支持向量機的閱讀理解試題難度預估研究
2022-09-19 08:27:44吳生蕾
考試研究 2022年5期
吳生蕾 任 杰
一、引言
閱讀理解是語言測試的考查重點,把握閱讀理解試題的難度有利于平衡語言測試的整體難度。根據影響因素不同,難度可分為相對難度和絕對難度[1]。絕對難度由試題本身決定,而相對難度來源于試題與考生兩個方面:源于試題本身的難度,影響因素主要有知識點、問題情境、提問方式、試題考查的學生的認知層次等;源于考生的難度,影響因素主要有考生群體的能力水平、教師的教學方法等。因不步及對考生群體的研究,本文中閱讀理解主式題的難度指絕對難度。
對于閱讀理解試題來說,題目難度來源于閱讀文本與題目設置兩方面。閱讀理解測試研究專家奧德森認為,文本選擇與題目設置對控制閱讀理解試題的難度是同等重要的[2]。幺書君認為,HSK聽力試題的難度受聽力語料類型、試題題型、題目的提問方式與提問角度等因素影響,認為無情節和觀點的聽力語料難度較高;在題型上,判斷題難度高于選擇題;對具有概括性事物提問的試題難度較高[3]。閱讀理解試題的題目材料與聽力試題的題目材料有相似之處,二者都由成段的或成篇的文本材料和提問的題目構成。因此,與文本材料、題目設置影響聽力試題的難度類似,文本材料、題目設置也影響閱讀理解試題的難度。
許多學者從內容效度、閱讀能力角度研究影響閱讀理解試題難度的因素,前者主要包括對文本易讀性、文本題材、話題、體裁等的研究。荊溪昱從文本的信息量、句法難度和語義難度角度提出適用于中文教材的易讀性公式[4]。Drum等的研究表明,詞匯頻數、高頻次與低頻詞數量、詞匯認知、語法控制、具有迷惑性的選項、句子長度等因素對題目難度有重要影響[5]。王佶旻研究發現,文章的題材、題干類型與選項字數會影響試題難度[6]。
有研究者認為閱讀能力的核心是“理解”,圍繞“理解”從人們解答閱讀理解客觀題的認知過程入手,將對于不同認知對象且具有不同難度水平的閱讀理解進行縱向分級。武永明將閱讀能力從低到高分為四種,分別是最基本的認讀字詞句的能力、理解主要內容的能力、進行評價鑒賞的分析能力以及要求最高的創造運用能力等[7]。楊帥將閱讀能力由低到高分為四個等級,將題目對考生閱讀能力的要求作為試題難度的影響因素[8]。
由于計算機具有非常強大的運算大數據的能力以及較高的運算速度,能夠高效地分析處理數據并挖掘數據的潛在規律,1995年,Perkins等學者使用人工神經網絡構建試題難度的預測模型,將機器學習算法引入了試題的難度預估領域[9]。在閱讀理解測試方面,韓菡對漢語水平考試中的閱讀理解試題進行了難度預估研究,使用BP(Back Propagation,反向傳播)神經網絡建立了試題難度的預估模型;研究結果顯示,預估難度和實測難度在0.01水平下顯著相關[10]。付佩宣使用BP網絡模型,將選取出的實用漢語水平認定考試閱讀理解題目的難度影響因素作為訓練網絡的初始輸入變量進行試驗,之后增加輸入變量繼續進行試驗,結果顯示預估難度與真實難度的相關達到了0.61[11]。張玄采用樸素貝葉斯分類器對某考試的言語理解與表達部分進行了難度預估研究,其預估的準確率為64.5%,遠超過專家預測的24.5%的準確率[12]。龔晨曦采用樸素貝葉斯和文本相似度方法進行了試題難度預估,得出基于以上兩種模型的難度預估準確率均高于專家預估的準確率,相較于文本相似度模型,樸素貝葉斯模型的性能更好[13]。
本研究以難度預估為主題,將支持向量機的機器學習方法用于語言測試之中,選取了支持向量機的分類模型和回歸模型對HSK初、中等的常規閱讀理解試題進行難度預估。
二、支持向量機
在二維平面中,將兩類樣本點劃分開來的是一條線,在三維空間中,將兩類不同樣本劃分開的是一個平面,而在n維空間(n>3)中,這個將樣本分類的平面被稱為分類超平面。支持向量機(Support Vector Machines,SVM)是一種二分類的線性分類器,根據距離分類超平面最近的點,即支持向量計算兩個類別間的最大間隔,建立分類超平面模型。它不僅能夠為線性可分的原始數據構建線性分類器,也能夠為非線性可分的原始數據建立線性分類器。
在許多分類任務的原始樣本空間內,(類別)與(數據特征)之間的關系是非線性的,可能并不存在能將兩個不同類別的樣本正確劃分的分類超平面,于是選擇核函數定義一個高維特征空間,將非線性可分的數據映射到高維空間,使原始數據在高維空間變為線性可分,選擇了不適合的核函數會導致分類模型的性能不佳。
徑向基核函數、多項式核函數、sigmoid核函數以及線性核函數是四種較為常用的核函數,這四種核函數的表達式如下。

核函數的作用范圍是由參數γ決定的。為了選擇出合適的核函數,于是允許模型對部分樣本的分類出現錯誤,以保證大部分樣本點被更好地分類。因此引入懲罰因子與松弛變量兩個參數,表示對模型犯錯的容忍度。懲罰因子C為常數且C>0,C越大,則會要求更多的樣本均滿足約束條件。松弛變量(slack variables)ξ可以調節模型對誤差的容忍范圍,ξ越大,模型對誤差的容忍越高。
三、實證研究
本研究的試題樣本選自HSK初等、中等的八套試卷,由閱讀理解第二部分的210道試題組成,包括試題的閱讀材料、題干、選項以及題目的IRT難度參數等數據。本研究對210道試題的難度進行了類別與數值的預估,采用R-4.0.4軟件進行數據處理和可視化分析。
(一)確定難度的影響因素
本研究從文本特征、題目特征兩方面挖掘難度的影響因素。從以下幾個方面進行HSK初、中等閱讀理解試題的文本特征研究。
1.文本題材。考生的學科、背景知識影響其對閱讀材料的理解程度,當試題的閱讀文本選取了冷門的題材,就會對閱讀的難度造成較大影響,因此本研究將文本題材分為10類,對語料進行了標注。
2.文本體裁。考生對不同體裁文章的閱讀能力是不相同的,這與對特定體裁的閱讀能力的培養和訓練有關。HSK初、中等閱讀理解閱讀文本的體裁主要有記敘、議論、說明三種。
3.文本易讀性。荊溪昱的易讀性公式為:易讀性=17.5255+0.0024X1+0.04415X2-18.3344X3(X1、X2、X3分別代表文章字數、文章句子的平均長度、文章中熟悉詞語所占的比重)。因此,本研究確定了文本字數、平均句子長度和熟悉詞比重等三個影響難度的因素。
在計算熟悉詞比重時,首先借助NLPIRICTCLAS漢語分詞系統對樣本題目的閱讀文本進行分詞標注,之后對分詞結果進行人工檢查,參照HSK初、中等的考試詞匯大綱對分詞結果進行調整,最后借助自編程序計算HSK初、中等所應掌握的甲、乙、丙三個等級的詞匯數量占總詞匯數量的比重。
題目包括題干和選項,因此題目特征也應從題干特征與選項特征兩方面考慮,包括以下幾點:
1.題干對閱讀能力的要求。本研究根據題干的提問,將題目對閱讀能力的要求按照從低到高分為微觀理解能力、整體感知能力、解釋推理能力和評價鑒賞能力四個等級。
2.選項長度。選項字數越多意味著選項包含的信息越豐富,對題目難度以及答題所用的時間均有影響。
3.題目中熟悉詞所占的比重。計算題干、選項中的熟悉詞比重。
4.干擾項數量。當干擾項不符合題干要求但符合語料大意,或者干擾項的觀點與人一般的邏輯思維習慣相一致時,會對考生產生迷惑,增加題目難度。
(二)支持向量分類模型的難度預估
1.對題目難度因素進行編碼
通過對HSK初、中等閱讀理解文本的分析,以200字為一個區間將閱讀文本字數分為兩個水平;以20個字符為一個區間將平均句長因素劃分為三個水平;樣本題目中,文本的熟悉詞的比重均在60%以上,于是以10%為間隔將其分為四個水平。
對于文本因素的具體分類情況如表1所示。
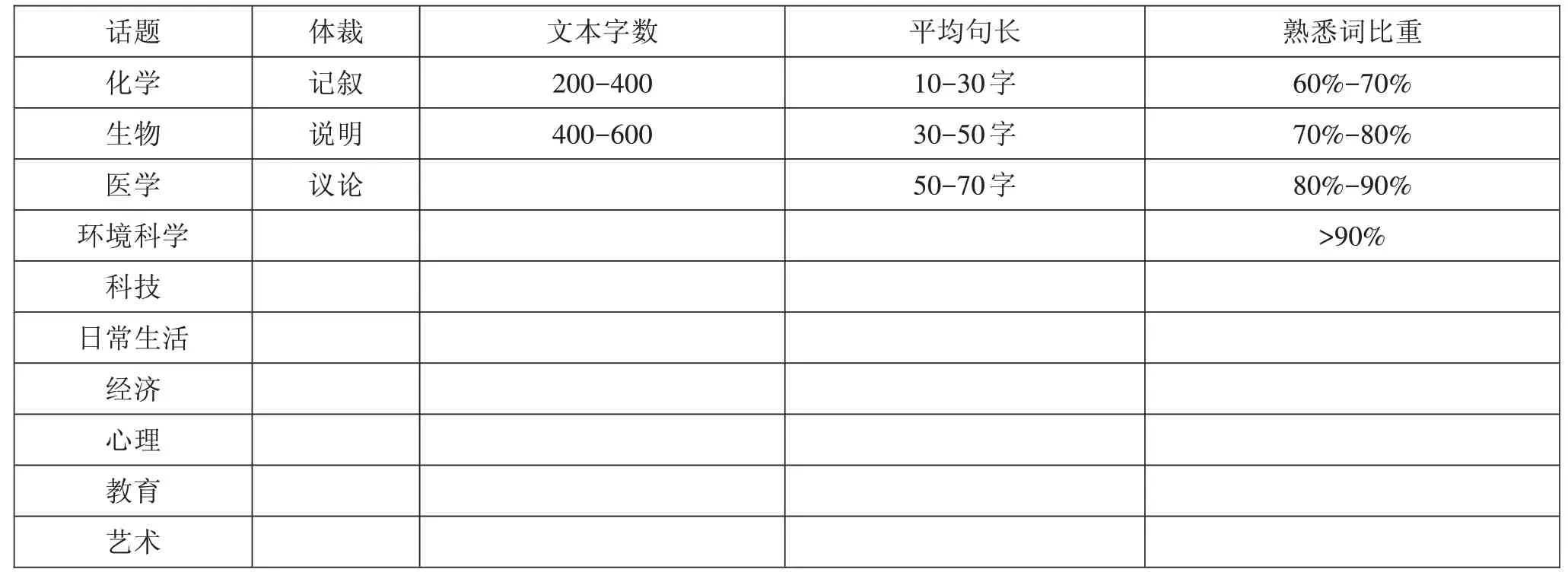
表1基于文本特征的難度影響因素編碼表
通過對HSK初、中等閱讀理解題目的分析,210個題目樣本的熟悉詞比重在30.77%~100%之間,由于熟悉詞比重低于60%的題目數量極少,考慮到等級中的題目樣本數量,將熟悉詞比重在80%以下的試題分為一個等級,并以10%為區間將熟悉詞比重在80%以上的部分分為兩個等級;以16個字符為一個等級,將選項長度分為三個等級;將選項中符合閱讀文本大意的或者符合人的思維習慣的錯誤選項作為干擾項,干擾項的數量有0、1、2、3四種。表2是基于題目特征的難度影響因素的編碼表。

表2基于題目特征的難度影響因素編碼表
本研究使用基于IRT模型的難度值,為了控制各難度類別中題目數量差異對模型效果的影響,將試題難度按照題目數量劃分四個等級,使各等級的題目數量盡量接近,并且考慮等級臨界處的題目難度值,確保各等級的題目難度值不相同。劃分結果見表3。
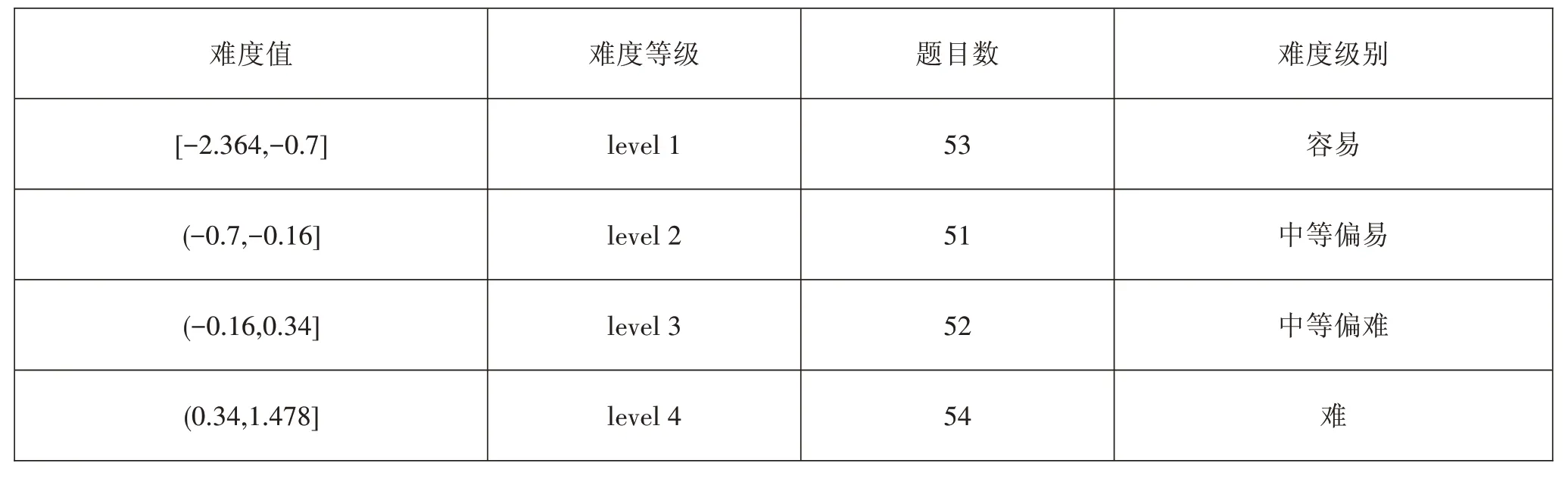
表3 根據題目數量的難度等級劃分
2.構建支持向量分類模型
支持向量機進行分類首先需要輸入訓練樣本,讓分類器學習數據的特征、模式,進而找到分類函數,建立分類模型。本研究將210道閱讀理解試題的難度與九個影響因素數據分成十份數據集,在訓練集上使用十折交叉驗證法訓練模型。在模型的訓練過程中,對其進行交叉驗證時采用了四種常用的核函數,即多項式核函數、徑向基核函數、線性核函數以及sigmoid核函數。其準確率,即參照核函數所建立起的支持向量分類模型的結果如表4;其中,總體準確率的計算方式是:正確預測的題目數量除以預測集的題目數量,各類別的準確率是該類別上正確預測的題目數量除以預測集中該類別的題目數量,而類別平均準確率是各類別的準確率的平均值。
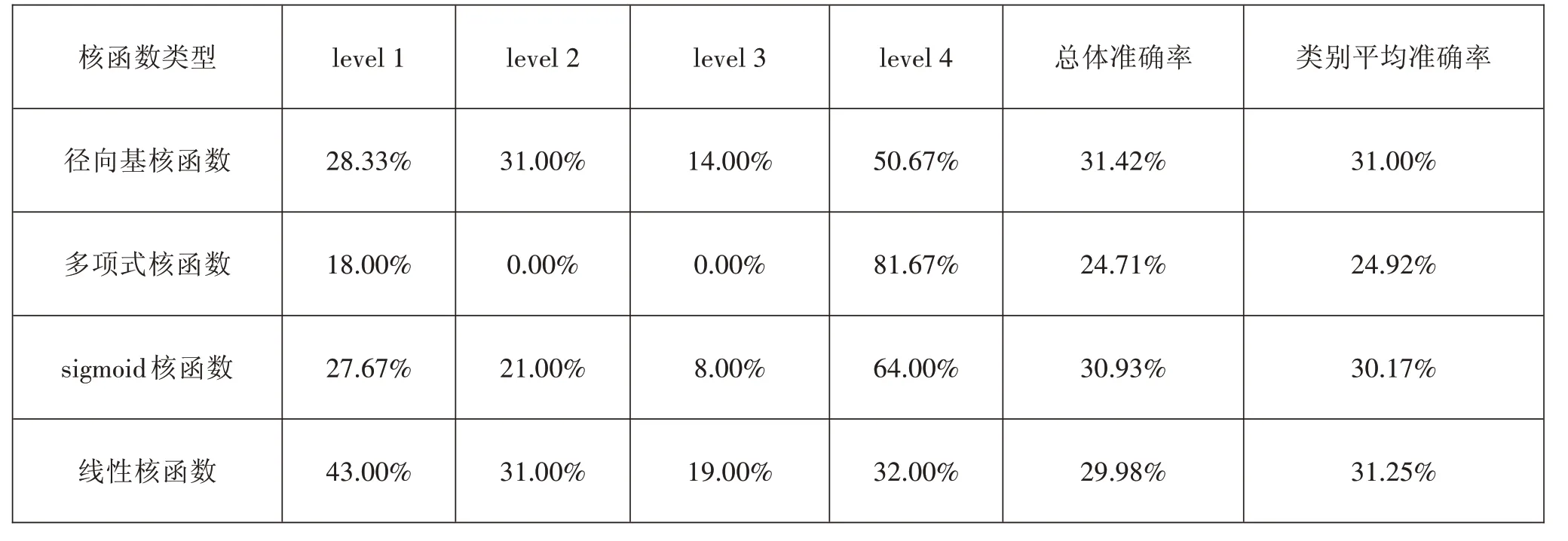
表4四種核函數交叉驗證的平均預測準確率
根據表4可以看出徑向基核函數的效果最好。總體預測準確率最高的是徑向基核函數,其次是sigmoid核函數。類別平均準確率最高的是線性核函數,其次是徑向基核函數。基于多項式核函數的分類模型在level2與level3上的準確率為0。sigmoid核函數在總體及各類別上的準確率也較好。
以總體預測準確率最高的徑向基核函數建立支持向量分類模型,并采用網格搜索法,在sigma(1,210)及C(2-10,2)的范圍內選擇出最優sigma參數和懲罰因子的取值,可以參照圖1觀察參數選擇的熱力圖。圖1縱坐標代表的是核參數sigma,橫坐標代表的是懲罰因子C。
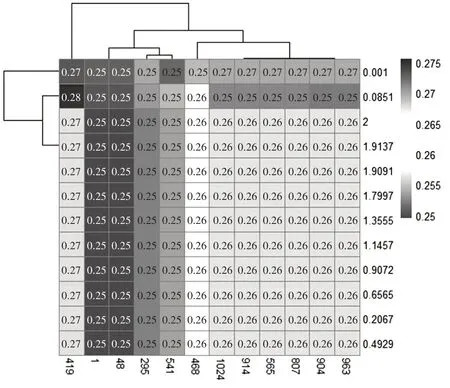
圖1徑向基核函數的核參數熱力圖
據圖1可知,當C=1.3555,sigma=1時,以徑向基核函數構建的支持向量分類模型進行難度預測的錯誤率最低,為0.25,即此時模型的預測效果最好,預測準確率為75%。
(三)支持向量回歸模型的難度值預估
以試題難度作為因變量,以文本題材、文本體裁、文本字數、平均句子長度、文本熟悉詞所占比重、選項長度、題目熟悉詞比重、干擾項數量以及題目的能力要求等九個變量作為自變量,選擇以下四種核函數:多項式核函數、線性核函數、徑向基核函數以及sigmoid核函數,對訓練集和測試集進行劃分時使用十折交叉驗證法,進行支持向量回歸。四種核函數十次交叉驗證的均方誤差結果如表5所示。
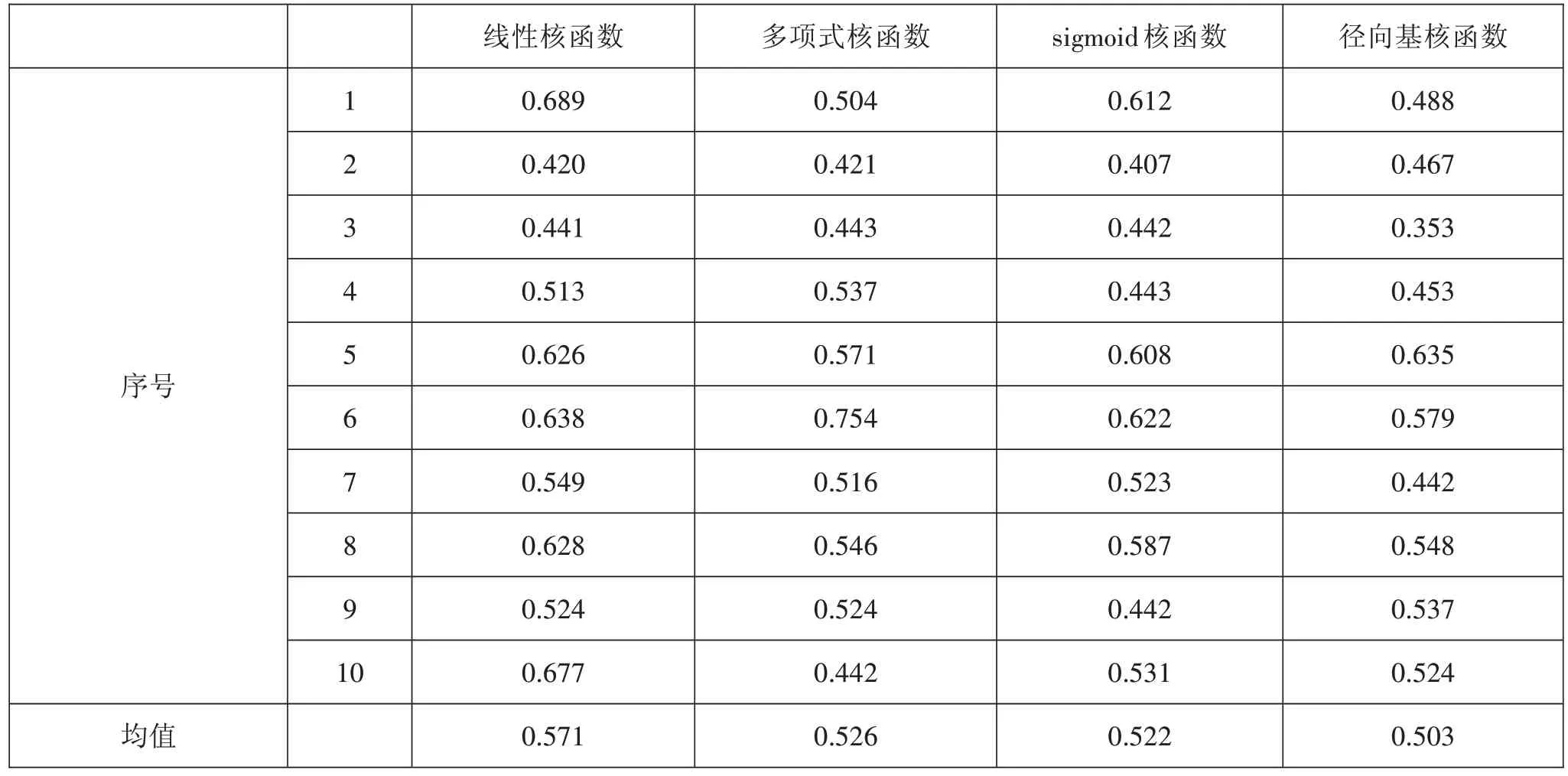
表5十折交叉驗證難度預測的均方誤差
為了更清晰地顯示四種核函數的均方誤差差異,將表5中數據以折線圖的形式呈現,如圖2所示。
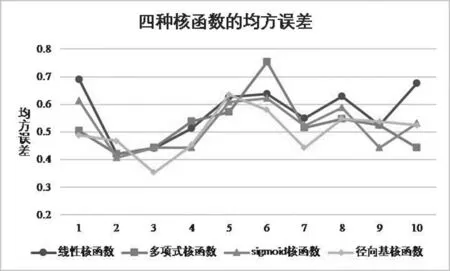
圖2四種核函數的均方誤差圖
根據表圖2及表5可以看出,sigmoid核函數的均方誤差波動最小,預測效果最穩定。多項式核函數的均方誤差波動最大,其均方誤差的最大值與最小值相差0.3以上。從十次交叉驗證的均方誤差均值來看,以徑向基核函數構建的支持向量回歸模型的平均均方誤差最小,其十次結果的平均均方誤差為0.503,sigmoid核函數和多項式核函數的平均均方誤差也較小,分別為0.522和0.526。
表6是使用徑向基核函數進行支持向量回歸的一個測試集中試題的預測難度值與實際難度值的對比。
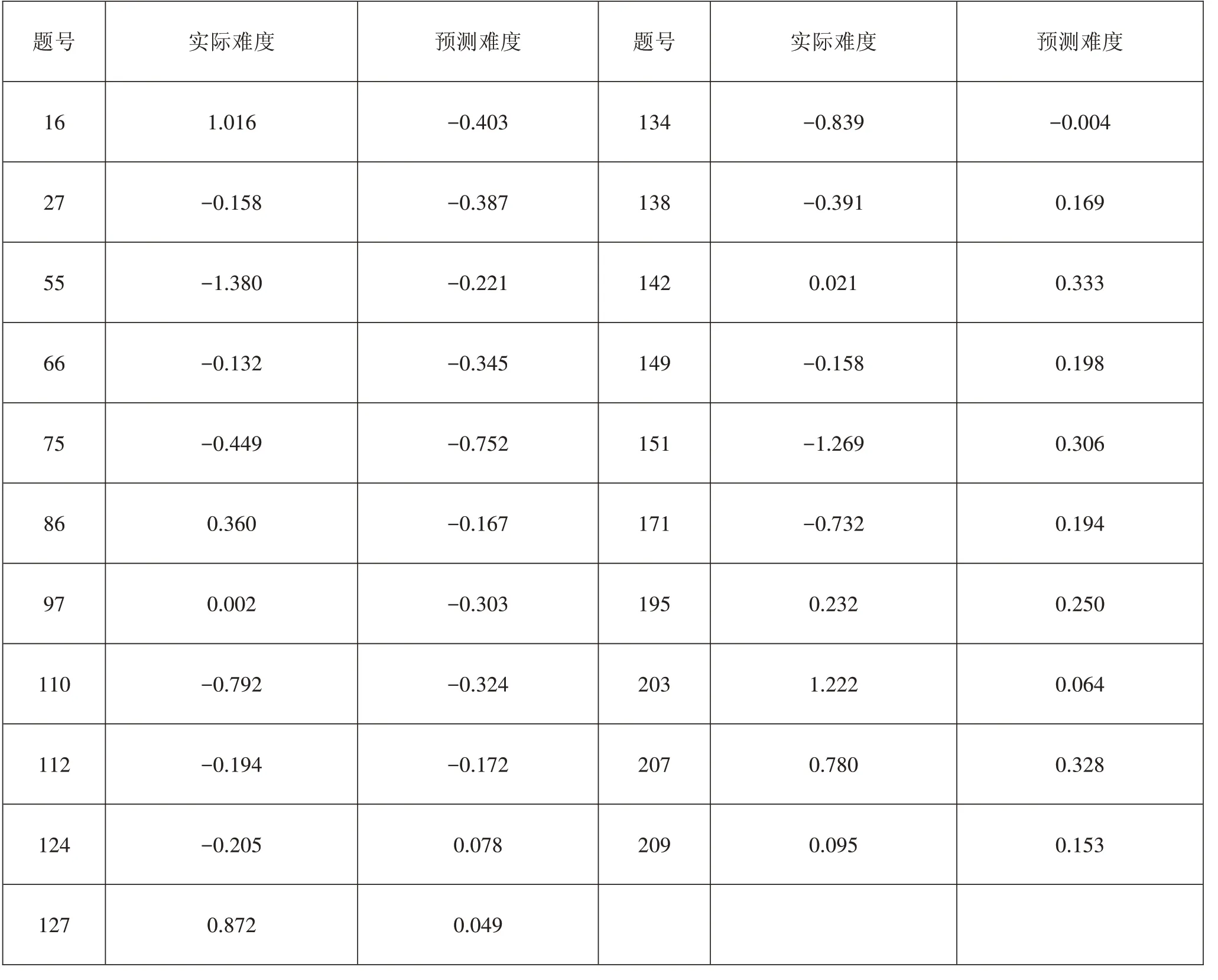
表6徑向基核函數的預測難度與實際難度的對比
由于徑向基核函數是十個均方誤差的均值最小的,因而選擇核函數作為支持向量回歸模型時,徑向基核函數為最優選項,在懲罰因子C∈[0,10]及gamma∈[2-10,2]的范圍內經十折交叉驗證選出支持向量回歸模型的最優核參數,最優模型的核函數及核參數選擇如表7所示。

表7最優支持向量回歸模型的核函數及核參數
本研究的支持向量回歸采用徑向基核函數,且核參數取值為C=3.37495及gamma=0.0009765625時模型效果最佳。采用優化后的最佳模型對樣本題目數據進行十折交叉驗證,得到的十次均方誤差及其均值如表8所示。
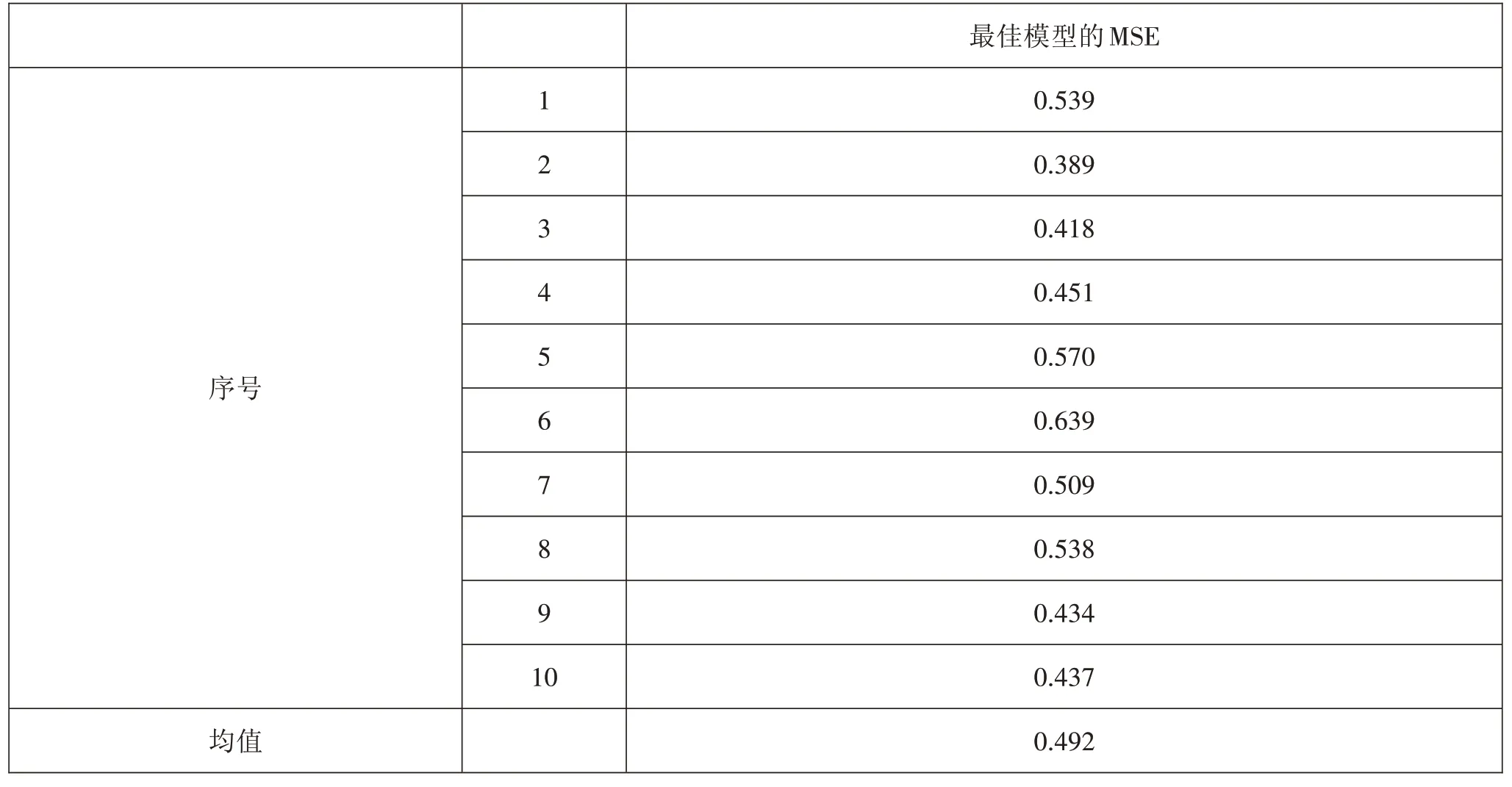
表8最佳支持向量回歸模型交叉驗證的均方誤差
最佳支持向量回歸模型進行十折交叉驗證的平均均方誤差為0.492,比徑向基核函數進行核參數優化前的0.503更小。表9是一個測試集中試題的預測難度值與實際難度值。
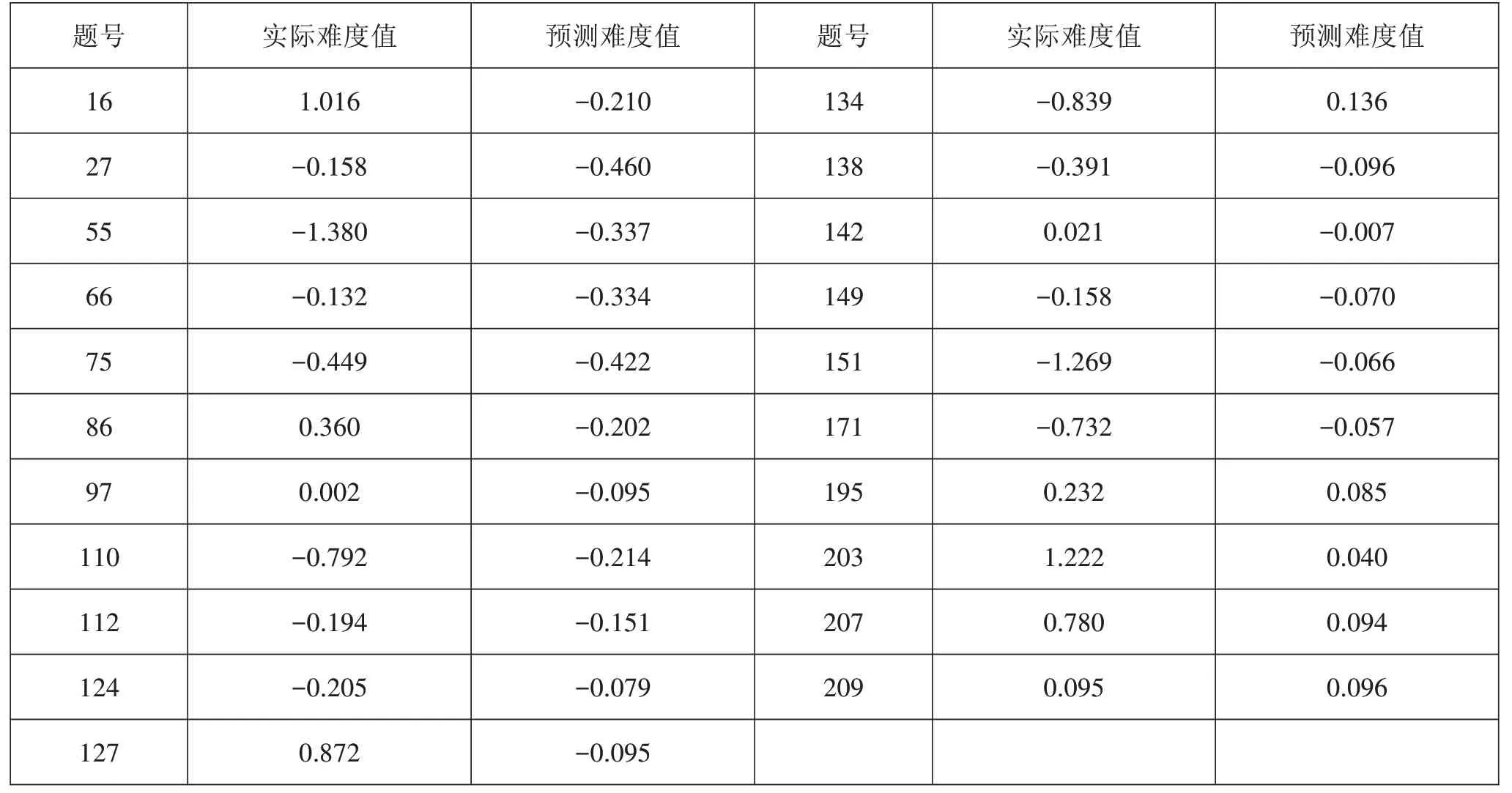
表9最優模型預測難度與實際難度的對比
為了更清楚地呈現模型的預測效果,圖3繪制了支持向量回歸預測的試題難度與實測的試題難度的折線圖。
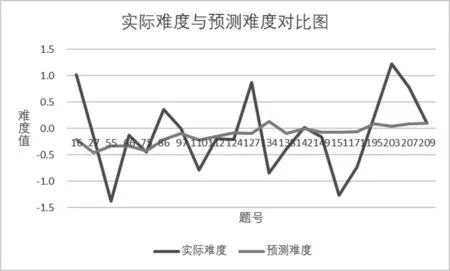
圖3實際難度與預測難度對比圖
由圖3可知,支持向量回歸模型對閱讀理解試題的難度預測結果與實際難度值差距較大,二者在折線圖上的波動趨勢并不一致,且模型的預測難度值始終在-0.5至0.3之間,說明支持向量回歸模型對閱讀理解試題難度值的預測精度不理想。
四、結論與不足
根據計算出來的難度預估效果的評價指標,本研究得出的結論如下:
(一)支持向量機的最優分類模型對難度預估的準確率能夠達到75%,支持向量機的最優回歸模型的預測難度值與實際難度值的均方誤差的平均值為0.492,但其預測的難度值集中在(-0.5,0.2)之間,趨于預測為中間難度。說明支持向量機方法用于閱讀理解試題的題目難度預估是可行的,能夠對題目的難度類別進行區分,但對于難度值的預測精度不佳。
(二)在使用支持向量機方法構建分類與回歸模型時,分別選擇了徑向基核函數、多項式核函數、sigmoid核函數以及線性核函數四種核函數,其中多項式核函數在兩種模型中的表現均不佳,徑向基核函數在兩種模型中的表現均較好。
在研究過程中,本研究也存在以下不足之處:
在對難度的影響因素進行等級分類時,很難兼顧類別的細致程度與每一類別的樣本量,類別劃分越精細,每一類別中所包含的樣本量必然會減少,導致對這一類別預估的誤差變大。本研究將題材按照學科劃為了生物、化學、醫學、科技等各個小類,因此各類別的樣本量較少。
不同的難度影響因素對難度的重要程度是不一樣的,明確不同難度影響因素的權重對于提高預估準確率具有重要意義。支持向量機的分類模型與回歸模型均能夠設置影響因素的權重,但本研究在構建預測模型時未考慮難度影響因素的權重問題,這也是本研究存在的另一不足之處。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
