我國圖情檔領域關聯數據的研究現狀與前沿熱點
2022-09-20 13:08:52蘇州大學圖書館社會學院
圖書館理論與實踐 2022年5期
王 飛,徐 芳(蘇州大學 .圖書館,b.社會學院)
1 引言
關聯數據(Linked Data)是由Web的發明人Tim Berners-Lee提出的一種數據規范,用來在萬維網上發布和連接各類數據、信息和知識,使人們能借助互聯網發現更多相互關聯的信息[1]。由于關聯數據是一種較為容易掌握的技術規范,隨著關聯數據發布工具的日益成熟,瑞典、美國、英國、法國、德國等國家圖書館開始創建和傳播自己圖書館書目記錄、主題詞表(LCSH)的關聯數據[2-3]。2015年,國務院印發的《促進大數據發展行動綱要》明確提出要大力推動政府數據共享,穩步進行公共數據資源開放[4]。截至2021年5月,關聯開放數據(LinkedOpenData,LOD)云圖中收集的全球地理、政府、媒體及用戶等機構和個人發布的開放關聯數據集已經達到1,301個,鏈接 16,283 條[5]。
國內對于關聯數據的研究始于2006年,2011年之前的研究成果以關聯數據概念介紹和文獻綜述為主,少有對關聯數據實踐應用的研究。此后,關聯數據吸引了更多學者的關注,相關研究成果的數量和質量都有了明顯增長,已有文獻對2016年之前傳統受控詞表的語義化描述、關聯數據成果發布、計算機與圖書情報領域關聯數據的研究現狀進行了文獻計量分析[6-7]。隨著我國將構建全國信息資源共享體系上升為國家戰略[4],作為數據共享開放的重要基礎,關聯數據研究的重要性進一步提升。2017年至今,CNKI(中國知網)中收錄的相關新增文獻超過383篇,約占所有相關文獻總數的一半。有鑒于此,本研究旨在通過對我國圖情檔領域關聯數據研究現狀進行全面的梳理與分析,挖掘該領域的核心主題和前沿熱點,以期為后續研究提供參考和借鑒。
2 數據采集與分析方法
2.1 數據采集
本文選擇CNKI為文獻數據來源,以 “主題” 為檢索選項, “關聯數據” 為檢索詞,限定學科為 “圖書情報與數字圖書館” 與 “檔案及博物館” ,檢索時限為2006—2020年,共檢索到中文文獻874篇,去除序言、報紙文章等非研究型文獻及外文文獻后,將剩余的867篇文獻作為本文分析的對象。
2.2 分析方法
本研究一方面利用SATI文獻題名信息統計分析工具[8]對研究機構、學者、期刊等主體關系進行計量分析,以了解其知識關系模式;另一方面綜合利用詞頻分析、共詞分析以及聚類分析對文獻的關鍵詞進行研究和可視化展示,以厘清該領域的核心主題和發展趨勢。最后,筆者選擇重點文獻對該領域的研究內容進行述評,揭示該領域研究的核心內容和熱點前沿。
3 文獻分布特征與合作網絡
3.1 文獻增長特征分析
筆者對我國圖情檔領域關聯數據研究的文獻發表數量按年份進行了統計分析,2006—2020年我國圖情檔領域關聯數據研究的發文量和增長率見表1。
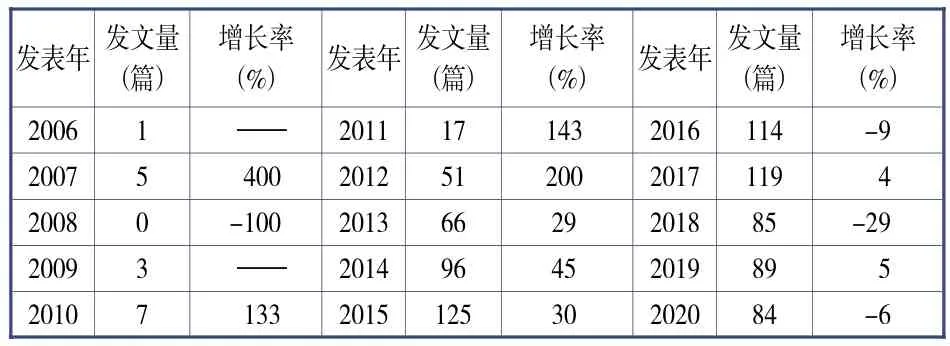
表1 2006—2020年我國圖情檔領域關聯數據研究的發文量和增長率
從表1可以看出,2010年之前相關研究的年發文量均為個位數,研究的開展尚處于萌芽階段。從2011年起,該領域的研究熱度逐年提升,2012年發文量迎來爆發性增長,增長率達到了200%,并且這種增長趨勢一直持續到2015年,發文量達到125篇。此后兩年發文量趨于平穩,均在120篇上下。這一時間線與我國一系列推動數據資源開放共享文件的發布時間點基本重合,反映了我國圖情檔領域學者對國家政策的敏感性,以及研究開展的果斷與快速。2018年,發文量出現較明顯回落,但此后兩年又基本維持在同一水平,關聯數據的研究進入第二個平穩期。
3.2 研究機構分布及合作網絡分析
科學文獻與研究機構之間的數量關系和分布情況反映了研究主體的文獻產出能力。表2為筆者利用SATI和EXCEL統計出的發文數量大于或等于10篇的研究機構分布情況。為了更客觀地了解機構分布情況,筆者對機構更名,學院或圖書館下屬的系、研究所(中心)和部門的數據做了合并處理。
根據表2數據,發文數量超過10篇的研究機構共有18個,發文量之和約占總體1,034個機構全部發文量的40%,表明我國圖情檔領域關聯數據研究機構分布比較分散。進一步統計發現,這18個核心機構由高校院系、公共圖書館和中國科學院研究所組成,其中高校院系有13家,占據了絕對主力地位,這與高校學術氛圍濃厚、科研隊伍強大密不可分。筆者對18個機構的發文量按年份統計發現,上海圖書館開展關聯數據研究的時間最早(2009年),且延續性最強,他們的研究隊伍遍布圖書館的所有部門。中國科學技術信息研究所和中國科學院國家科學圖書館也較早開展了相關研究(2010年)。兩者不同的是:前者將研究一直延續了下來,而后者在2013之后暫停了相關研究。總體而言,高校開展關聯數據研究的時間較晚,2014年之前13所高校的發文量之和與另外5家機構相比還有不小差距,而近7年的發文量統計情況則展現了高校在研究持續性和爆發性上的優勢。
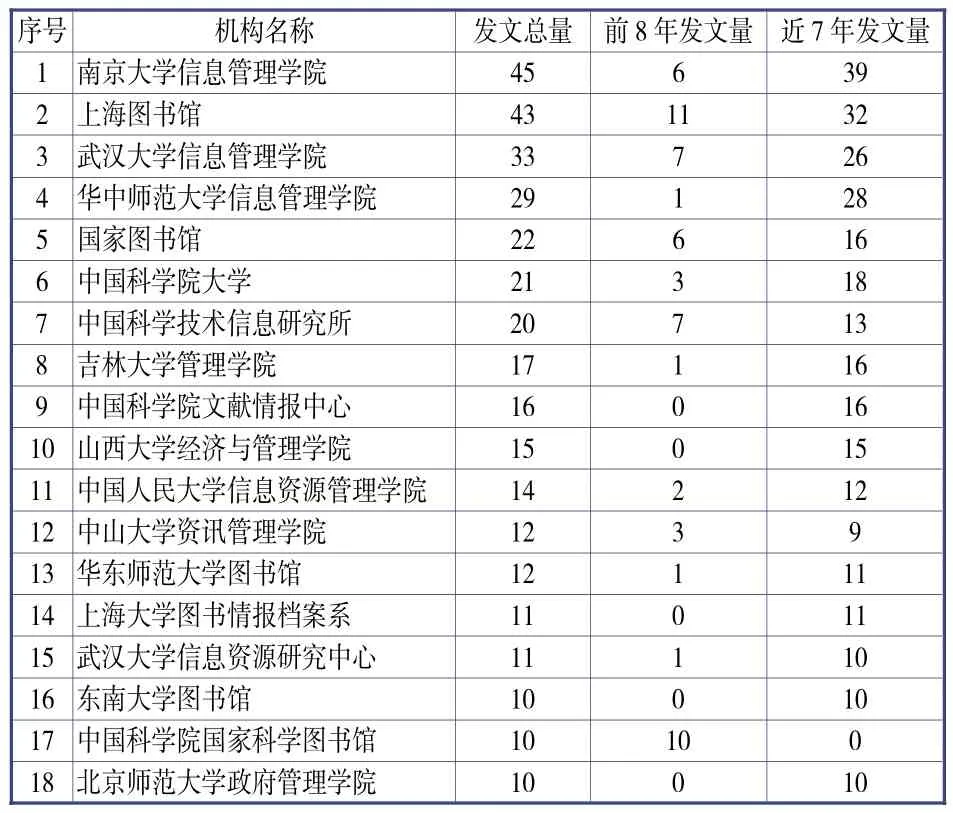
表2 總發文數量≥10篇的研究機構分布
3.3 核心作者及合作網絡分析
SATI統計顯示,本研究搜集的867篇文獻共有1,652位作者,其中夏翠娟發文量最多(20篇)。根據普萊斯定律,本項研究中核心作者的最Nmax為最高產作者的發文量[9]),計算得出M≈3.35,即核心作者的最低發文量為4篇。符合這一要求的作者共有63位,他們的總發文量為388篇,約占全部論文的45%,基本符合普萊斯 “核心作者集群發文量約占總發文量的一半” 的理論,由此說明我國圖情檔領域關聯數據研究核心作者集群已經基本形成。對核心作者發文的總被引量進行統計發現,劉煒撰寫的16篇文獻總被引835次,夏翠娟撰寫的20篇文獻總被引690次,歐石燕撰寫的13篇文獻總被引356次,陳濤撰寫的12篇文獻總被引216次,以他們為代表的核心作者在該研究領域具有很大的影響力。
為進一步分析學者間的合作關系,筆者采用知識圖譜對63位核心作者之間的合作網絡進行描繪(見圖1)。為了更清楚地顯示主要合作者間的關系,筆者在數據處理中進行了去除噪點處理。
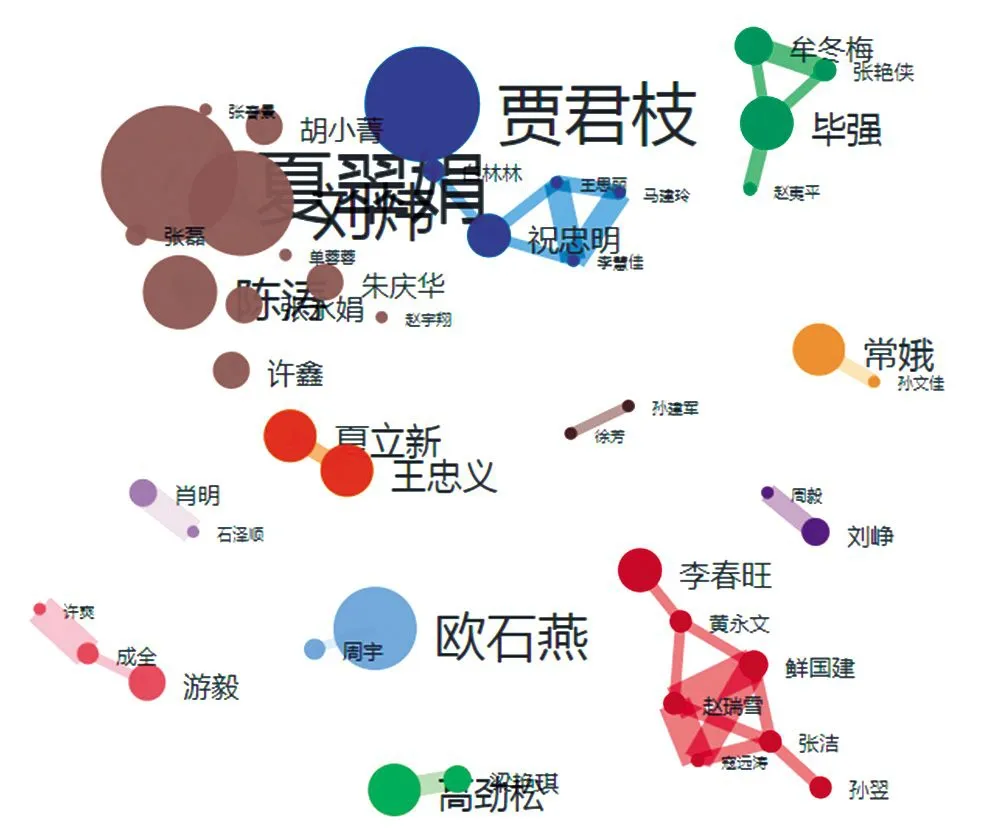
圖1 我國圖情檔領域關聯數據研究核心作者合作網絡
從圖1中可以看出,核心作者之間的合作度較弱,63位作者僅形成了12個合作集群,且只有3個集群的合作者超過了5人。其中,夏翠娟、劉煒、陳濤等組成的集群規模最大,發文量最多,他們來自上海圖書館的不同部門,屬于內部合作,具有很強的專業能力和文獻產出能力。規模第二的集群由中國科學院文獻情報中心的李春旺、中國農業科學院農業信息研究所的黃永文等組成,調研發現他們是以師生關系為基礎構建的合作網絡。同樣地,規模第三的集群也是基于師生和同事關系形成的山西大學、中國人民大學以及中國科學院之間的合作網絡。總之,雖然我國圖情檔領域關聯數據研究已經形成了具有一定影響力的核心作者集群,但學者之間的合作交流還不夠密切,大部分都是師生或同一機構內部的合作,高校內部各院系之間的合作以及高校與公共圖書館之間的合作都不常見。
3.4 來源期刊分布
一般來說,核心期刊刊載的論文質量較高,論文的研究主題具有一定的學術創新力,因此對刊載論文的期刊進行統計分析不僅可以在宏觀上判斷關聯數據研究主題的創新力,還有助于挖掘該領域的高影響力期刊。筆者利用UCINET進行統計分析,構建期刊載文量分布圖,并將載文量低于10篇的期刊歸于其他類(見圖2)。
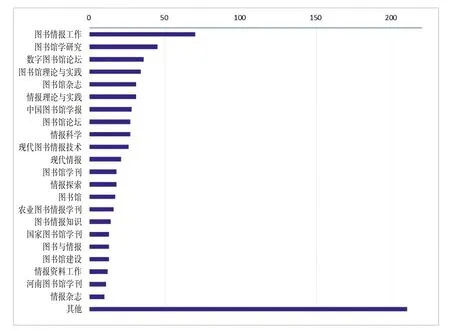
圖2 期刊載文量分布圖
從圖2可以看出,在載文量大于10篇的22種期刊中,核心期刊有15種,占比68%;CSSCI來源期刊1種,CSSCI擴展版來源期刊2種,一般期刊僅有4種。可見,我國圖情檔領域關聯數據研究的學術成果大部分都刊載在核心期刊上,論文整體質量較高,論文的研究主題具有較強的學術創新性。根據布拉德福定律,筆者將各種期刊的載文量降序排列,并將論文數量劃分為數量大致相等的三個區域,得到三個區域的期刊數為5∶17∶100,近似等于1∶3.4∶4.472,其中第二區在嚴格數值(4.49)的基礎上下浮動了約24%,可以認為此種情況符合布拉德福定律[10]。據此,我國圖情檔領域關聯數據研究的 “核心區” 期刊為《圖書情報工作》《圖書館學研究》《數字圖書館論壇》《圖書館理論與實踐》《圖書館雜志》和《情報理論與實踐》(兩者載文量相同,排序不分先后)。
4 研究主題及其發展趨勢
4.1 關鍵詞詞頻分析
關鍵詞是文章核心內容的高度凝練,體現了作者的學術思想和觀點,詞頻分析法是利用關鍵詞在某一研究領域文獻中出現的頻次高低來確定該領域研究熱點和發展動向的文獻計量方法[11]。筆者利用SATI對本研究所選文獻的關鍵詞進行統計分析,共得到1,536個關鍵詞,由于詞頻最高的 “關聯數據” 與數據采集所用的主題檢索詞一致,且詞頻與其他關鍵詞相差太大,因此在下面的分析中將 “關聯數據” 一詞去除。其中,關鍵詞詞頻大于10的關鍵詞有43個,詞頻之和為955次,占總詞頻3,169次的30%,根據 “二八定律”[11],上述43個關鍵詞為高頻關鍵詞,從中可以分析出該領域的研究特點。圖3為這43個高頻關鍵詞云圖,圖中的字體越大表示該關鍵詞的詞頻越高。

圖3 前43個高頻關鍵詞云圖
從圖3可以看出,國內學者圍繞關聯數據在圖情檔領域應用的研究主要集中在書目數據、書目框架發布、數字資源、資源整合、數據模型構建、知識組織、知識服務、知識發現等領域,反映出圖情檔機構和學者緊跟時代發展,注重利用新興技術為用戶提供更好的服務,提升用戶體驗。同時,國內學者對關聯數據相關的關鍵技術也進行了深入研究,產生了本體、元數據、RDF、RDA、D2R等研究主題。科學數據、機構知識庫、科技文獻等高頻關鍵詞則顯示了關聯數據在促進科技資源開放共享、提升知識資產管理效能方面應用的潛力。
4.2 關鍵詞的聚類和共現分析
筆者利用UCINET對高頻關鍵詞進行聚類分析,分析得到的8個聚類可以看作8個研究領域,包括:圖書館數據模型構建、書目數據語義化編制、科學數據和科技文獻開放共享、知識組織系統SKOS化和關聯化、元數據與本體、高校圖書館知識發現系統建設、數字圖書館資源整合和機構知識庫建設、博物館資源整合和數據關聯。這8個研究領域在一定程度上集中體現出圖情檔領域關聯數據的研究狀況。為了更直觀展示高頻關鍵詞之間的共現關系,筆者利用知識圖譜進行可視化描述(見圖4)。
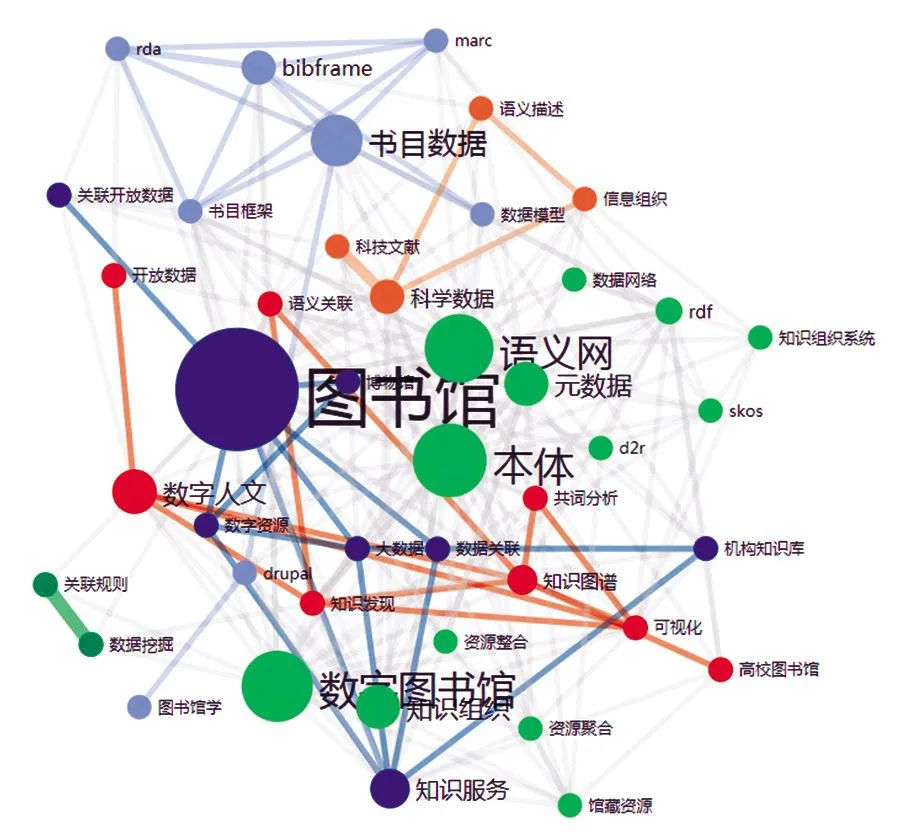
圖4 高頻關鍵詞共現關系
從圖4可以看出,關鍵詞層層相連,形成了一張完整的網絡圖,沒有出現孤立的點。其中,圖書館的節點最大,與周圍關鍵詞形成網絡連線最多,知識服務、機構知識庫、數字資源、數據關聯、大數據、書目數據、數據模型等都與圖書館聯系密切,說明關聯數據在圖書館的應用研究涉及圖書館服務的多個方面。此外,本體、語義網、元數據占據了中心位置,幾乎與每個關鍵詞都有聯系,是關聯數據應用研究的重要技術基礎和支撐。而數字人文、知識圖譜、知識發現、共詞分析、開放數據、語義關聯等關鍵詞也聯系緊密,同樣是研究的熱點主題。
4.3 研究主題動態分析
在聚類和共現分析的基礎上,筆者按年份對高頻關鍵詞進行統計分析,進一步理清了熱點研究主題的動態發展脈絡。分析表明,高頻關鍵詞的數量逐年增加,2010年以前,所有關鍵詞的頻次均低于5;2011—2015年,頻次達到5的關鍵詞快速增長,共有22個;2016—2020年,這一數字增長到了40個。15年內高頻關鍵詞增長速度近似等差數列,一方面說明我國圖情檔領域關聯數據研究的逐漸擴展,另一方面也表明研究熱點正在快速形成。筆者根據上文聚類分析的結果,將8個聚類內的關鍵詞分別相加,繪制出8個研究主題的頻次隨時間變化的圖像(見圖5)。
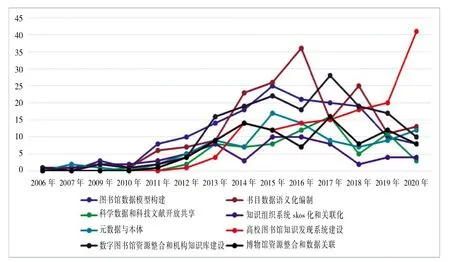
圖5 高頻關鍵詞頻次時間圖(基于8個聚類)
從圖5可以看出,高校圖書館知識發現系統建設這一研究熱點近年來一直處于上升趨勢,2020年更是迎來爆發性增長,關鍵詞頻次在2019年的基礎上翻倍增長,達到了41次。書目數據語義化編制、圖書館數據模型構建、數字圖書館資源整合和機構知識庫建設、科學數據和科技文獻開放共享、博物館資源整合和數據關聯五個研究熱點的波動性較大,在2015—2017年之間達到峰值后,整體均呈下降趨勢。元數據與本體的研究在經歷了2016—2018年的短暫降溫后,又恢復了上升趨勢。相對而言,知識組織系統SKOS化和關聯化的研究熱度一直不高。以上結果在很大程度上反映了我國圖情檔領域關聯數據研究的發展方向。
5 核心內容與前沿熱點分析
5.1 技術與平臺視角的關聯數據研究
關聯數據在圖書館、檔案館和博物館(以下簡稱LAM)中的應用可以歸納為發布、消費、服務和平臺四種模式,其中數據的發現和檢索機制是關聯數據成功應用的關鍵。與此同時,關聯數據與其他Web服務的整合、不同語義描述系統之間的互操作、消費關聯數據在本地系統的功能實現、嵌入外部社會信息環境的穩定性等都是關聯數據應用面臨的技術性挑戰[12]。各類信息資源的關聯數據化發布可以分解為六個關鍵步驟:數據建模、實體命名、實體RDF化、實體關聯化、實體發布、開放查詢[13],發布方式主要包括靜態發布、批量存儲、調用時生成、事后轉換(D2R)四種類型,常見的實現技術和工具有VoID詞表、前端轉換工具、OWL及SKOS相關工具、Web Services、Web應用框架、CMS及RDFa、Drupal等[14]。為了實現LAM中不同類型的數據、信息和知識的發現與共享,需要以OAI-PMH協議為基礎,構建由數字圖書館(DL)、數字檔案館(DA)、數字博物館(DM)和圖檔博數字化協作中心(DLAM)組成的D-LAM框架,通過DLAM對DL、DA、DM的元數據進行收割、語義映射和關聯標引,形成面向用戶的一體化信息服務體系[15]。此外,隨著關聯數據集的快速增加,基于關聯數據的服務平臺、監護平臺建設與信息資源的移動視覺搜索和可視化展示逐漸成為高效消費和利用關聯數據的熱點主題。為了保障關聯數據發布及消費參與者的合法權益,提升關聯數據集的質量,關聯數據的開放應用協議、建設標準、發布規范以及質量評價方法的制定與實施也是關聯數據在LAM中應用發展迫切需要解決的問題[16]。
5.2 數據資源視角的關聯數據研究
LAM兼有資源收集、管理和服務功能,在關聯數據運動中扮演著發布者、信度驗證者、消費者和組織協調者的角色[17],關聯數據的發展為數據資源的獨立標識、結構化描述和語義化關聯提供了契機。數據資源視角的關聯數據研究大致可以分為三個階段。
第一階段,數據資源的發布。在關聯數據發展初期以中國科技信息研究所、中國科學院文獻情報中心為代表的機構對書目組織語義化,詞表、分類法、規范數據等知識組織關聯化展開了大量研究。此后,更多的機構參與進來,進一步完善了科學數據、科技文獻、科研實體、檔案與異構數據等更多形式數據資源的關聯數據化[18-19]。目前,國家圖書館已經建設了關聯數據注冊與服務系統,實現了涵蓋關聯數據整個生命周期的管理,發布了中分表、國圖公開課、館藏文獻3個數據集[20],書目數據涵蓋了目錄資源、期刊、引文、手稿、家譜等多種資源類型,規范數據已經擴展到生物、醫學、農業、經濟、信息技術、藝術圖像等眾多領域[21]。
第二階段,數據資源的聚合。數據資源的關聯數據化滿足了用戶的一般需求,但主動、多元、深層次的信息服務還需要數據資源的深度聚合,關聯數據強大的語義聚合能力促進了數據集中URI的開放復用,語義鏈接機制將各類客觀實體與抽象概念關聯在一起,從而為數據資源的聚合提供了一種現實可行的途徑[22]。與元數據、本體、敘詞表等資源聚合模式相比,關聯數據在關聯強度、關聯維度、關聯階度、關聯粒度等方面都具有獨特優勢[23]。
第三階段,知識發現。人類知識活動的價值在于可用知識的發現,從知識生命周期來看,知識發現包含數據收集、數據預處理、數據挖掘、關聯數據生成和數據表示等階段,數據資源的關聯數據化發布與多維度聚合為知識發現打下了堅實基礎,關聯數據提升了半結構化與非結構化文檔的知識發現能力,增強了知識發現結果的語義驗證能力[24]。通過關聯數據的語義關聯,可以更準確地發現所需知識,拓展知識發現的范圍,簡化知識發現的過程。然而,由于關聯數據只是 “弱連接的三元組” 構成的數據網絡,需要進一步的知識發現才能滿足用戶的深層知識需求,因此關聯數據的發展離不開知識發現的推動,知識發現是關聯數據應用的基本方法和最終目標[25]。雖然將關聯數據應用于知識發現仍然面臨著關聯數據的制備問題、不同語言的語義差異問題以及可信度的挑戰,但關聯數據依然是LAM擴展資源發現平臺、推進知識服務的有效方案,基于關聯數據的知識發現研究將會是未來一段時期內的研究熱點[24]。
5.3 用戶視角的關聯數據研究
智能技術和信息技術的發展促進了LAM服務由大眾化向個性化、由一般向精準轉變。由用戶需求驅動,通過數據資源的聚合與知識發現,提供知識資源與用戶需求高度匹配的知識服務是當前關聯數據研究的熱點。用戶視角的關聯數據研究主要包含兩方面內容。① 基于關聯數據的用戶需求與行為研究。用戶需求組織是對用戶需求進行描述和揭示的過程,將關聯數據應用于用戶需求組織,利用關聯數據技術創建和發布關于用戶需求及其相互間聯系的規范化描述信息,可以形成以用戶需求為節點,以用戶需求之間的關系為邊界的語義化用戶需求網絡[26]。利用物聯網、大數據、關聯數據等技術,收集并關聯用戶與LAM交互中產生的各類數據,構建用戶小數據行為的關聯數據庫,進而更清楚地了解用戶需求[27]。在保護用戶隱私的前提下,將用戶信息通過關聯數據的方式發布有利于擴展知識發現服務,實現數據融合與語義檢索[28]。② 用戶需求與知識資源的關聯匹配與精準服務。在通過調查問卷、用戶行為本體模型、FP-growth關聯挖掘算法、科研本體等方式深入了解用戶的顯性興趣和隱性需求的基礎上,將關聯數據、書目框架技術引入學科信息資源、科研實體資源、紙電資源等資源體系中形成基于用戶需求的信息資源規范化語義描述,并在此基礎上實現個性化精準服務,幫助用戶形成關聯知識發現[29-30]。基于用戶視角的關聯數據研究已經覆蓋科研服務、學科服務、文獻傳遞、閱讀推廣等多個領域,而基于用戶需求和關聯數據技術的自動問答、智能參考咨詢服務研究也取得了一定進展。
5.4 數字人文視角的關聯數據研究
從實踐角度來看,數字人文就是利用數字工具、技術和媒體改變藝術、人類和社會科學知識的生產和傳播,其本質上是一種知識創新[31]。LAM擁有規模龐大、種類豐富的數字化館藏資源,以上海圖書館劉煒、夏翠娟等為代表的研究團隊已經探索出了一個讓人類記憶和文化遺產在數字時代充分發揮價值的實現方案。上海圖書館以家譜為實踐探索的起點,利用關聯數據的知識組織功能,把散落在不同家譜文獻中的人、地、時、事關聯起來,并進行可視化展示[32],于2016年推出了上海圖書館家譜知識服務平臺,同時推出了開放數據應用開發競賽。日前,該競賽已經成功舉辦了5屆,匯聚了豐富、海量的歷史人文數據,其中家譜元數據有72,593余條,家譜的家規家訓全文文本300余種,世系表3家[33]。經過6年的發展,上海圖書館已將家譜的成功經驗應用到了歷史地理數據、名人檔案、人物傳記、古籍等其他歷史文化記憶資源,數字人文數據基礎設施的建設也取得了顯著進展。除上海圖書館外,吉林大學、武漢大學、華東師范大學、山東大學等研究團隊也紛紛加入該研究領域,在LAM資源整合、視覺資源知識組織、城市記憶資源整合[34]等方面作出了重要貢獻。
6 研究結論
作為一種數據發布規范,關聯數據已成為影響互聯網基礎結構的關鍵技術之一,在全球開放數據運動的推動下,國內學者對關聯數據展開了跨學科、多視角的研究,取得了豐碩的研究成果。
(1)我國圖情檔領域關聯數據的研究正處于第二個平穩期,形成了以夏翠娟、劉煒、賈君枝、歐石燕、李春旺等為代表的核心作者集群,研究期刊分布呈現出核心化趨勢,研究成果具有較強的創新性和影響力。但另一方面,也存在著核心作者集群規模小、研究機構分散、學者間合作度低、多數學者研究持續性不強等問題。
(2)國內學者能夠緊跟國家宏觀政策走向和時代熱點,及時調整研究方向,不斷豐富關聯數據研究的理論體系和實踐成果,對關聯數據的關鍵核心技術、在圖情檔領域的實踐應用、對促進信息資源開放共享、提升知識資產管理效能等方面的作用均展開了大量的研究,形成了圖書館數據模型構建、書目數據語義編制、科學數據和科技文獻開放共享、知識組織系統SKOS化和關聯化、元數據與本體、高校圖書館知識發現系統建設、數字圖書館資源整合和機構知識庫建設、博物館資源整合和數據關聯8個聚類。此外,一些學者在不斷延伸研究廣度的同時,也在不斷拓展研究深度,關聯數據的研究已經覆蓋了圖情檔領域業務工作和理論體系的方方面面。
(3)我國圖情檔領域關聯數據的研究主要從技術與平臺、數據資源、用戶和數字人文四個視角展開,隨著關聯數據相關技術的不斷完善以及數據資源關聯數據化覆蓋面的不斷擴大,以用戶需求為驅動,提升關聯數據服務平臺的資源聚合度和顆粒度、促進用戶需求與知識資源的高效匹配、支持用戶便捷知識發現與精準服務是該領域研究的核心主題和熱點前沿。關聯數據的開放應用協議、建設標準以及質量評價方法的制定與實施是當下迫切需要解決的問題。與此同時,主動參與數字人文研究,將數字化的館藏資源融入數字人文基礎設施,充分發揮人類記憶和文化遺產的巨大價值也是圖情檔領域必須抓住的重要機遇。
猜你喜歡
吉林廣播電視大學學報(2021年4期)2022-01-14 02:35:48
當代陜西(2021年17期)2021-11-06 03:21:36
作文成功之路·小學版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數英綜合(2018年11期)2018-11-23 09:47:26
小太陽畫報(2018年1期)2018-05-14 17:19:25
學苑創造·A版(2018年11期)2018-02-01 06:29:20
資源再生(2017年3期)2017-06-01 12:20:59
讀者(2017年5期)2017-02-15 18:04:18
少年博覽·小學低年級(2016年10期)2016-11-24 06:48:23
漫畫月刊·炫版(2015年4期)2015-05-27 07:52:10
