基于Keras的LSTM模型的心肌梗死患者發病預測
2022-09-22 07:48:44劉志雄潘媛媛
電腦知識與技術 2022年23期
關鍵詞:模型
劉志雄,潘媛媛,2
(1.皖南醫學院醫學信息學院,安徽蕪湖 241002;2.皖南醫學院健康大數據挖掘與應用研究中心,安徽蕪湖 241002)
1 相關問題提出
心肌梗死(AMI)是冠狀動脈急性、持續性缺血缺氧所引起的心肌壞死。約半數以上的急性心肌梗死患者,在起病前1—2天或1—2周有前驅癥狀,其前驅癥狀需要得到患者以及家屬重視,最常見的是原有的心絞痛加重,心絞痛發作時間延長,或患者對硝酸甘油效果變差;或一些繼往無心絞痛者,突然出現長時間心絞痛或出現不規律的頻繁心絞痛癥狀。心肌梗死可并發心律失常、導致患者休克或心力衰竭,其癥狀嚴重,常可危及生命。患者一旦確診心肌梗死,病情難以控制或無法預測其發病時間,導致患者傷亡高。中國近年來心絞痛患者人數呈明顯上升趨勢,且40歲以下中年人群發病率呈逐年上升趨勢,每年新發至少50萬,現有患者至少200萬,心肌梗死作為老年人常見病,其發病率高,發病后會對患者造成不可逆的傷害。
關于疾病發生預測的研究一直是各領域研究的熱點,目前國內的心肌梗死疾病預測大多數針對預后治療和疾病死亡率,2020年有學者通過Logistic回歸分析急性ST段抬高型心肌梗死患者(STEMI)PCI術后6月發生不良心血管事件(MACE)的危險因素[2];在心肌梗死領域,學者通過獲取Holter文件、心率變異SDNN及超聲心動圖檢測的左室射血分數、左室舒張末期直徑的參數,對患者進行隨訪,采用變量回歸分析得到室性早搏后竇性心律震蕩現象的減弱或消失是急性心肌梗死后患者死亡的獨立預測指標[3];在疾病預測領域也有學者采用回顧性分析,探討SYNTAX積分和Gensini評分對急性ST段抬高心肌梗死(STEMI)患者遠期預后的預測價值[4].
基于深度學習的模型正在革命性地改變部分領域,它能夠解決涉及大量快速變化的高維數據[5]。深度學習模型的搭建也成為熱門應用。神經網絡與預測臨床事件的遞歸神經網絡(RNN)模型被發現相對于其他傳統的方法更準確,但不容易解釋。長短時記憶網絡(LSTM)是近年來應用于臨床數據的一種遞歸神經網絡,用于學習醫學概念的低維表示,并對特定臨床措施活動的時間序列進行分類處理,LSTM對于時間序列的處理準確度高,模型更易被大眾接受,因此,LSTM現在被廣泛應用于時間序列分析預測。相比較RNN而言,LSTM可以保存數據更久,其時間梯度損失較慢,LSTM使得計算機對語言的處理不再停留在簡單的字面匹配層面,而是進一步深入到語義理解的層面。
心肌梗死涵蓋人體系統范圍廣、病因復雜,因此,針對心肌梗死的研究進展一直比較緩慢,并且心肌梗死的研究主要集中于病理學、臨床醫學、生物化學和分子生物學等醫學或生命學領域,計算機科學領域的研究相較不多。本項目將基于LSTM算法,關注在未確診病情狀況下,通過對患者出現心肌梗死早期癥狀進行研究,預測患者患有心肌梗死的概率。
2 基于Keras的LSTM模型
長短期記憶網絡(Long—Short Term Memory,LSTM)在1997年提出的。LSTM模型是RNN模型的一種。LSTM由于其設計特點,適合對時間序列進行建模預測,如文本數據、圖片數據、時間序列數據。RNN模型在處理長期記憶時[6],存在嚴重的梯度消失問題,因此RNN模型很難處理長序列的數據或RNN模型在處理長序列的數據時準確度斷崖式下降。為了解決這一問題,從RNN模型上衍生出了LSTM模型,它解決了常規RNN模型的梯度消失問題,使得模型在進行長序列數據預測時,能夠表現出更好的效果,因此LSTM模型受到了廣泛的應用。
2.1 LSTM網絡
LSTM模型的結構相對于RNN較為復雜,LSTM模型的細胞結構是隊列結構,LSTM模型是若干個細胞串聯而成,在進行模型訓練或數據預測時,數據從第一個細胞進入,在細胞內存在激活函數,遺忘門等細胞內容,數據被當前細胞處理之后,將得到一個輸出結果并將輸出結果傳遞至下一個細胞,下一個細胞將對傳入的數據進行同樣的處理,直至最后一個細胞將最終結果輸出。在訓練LSTM模型的過程中,數據通過細胞后,得出最終結果,LSTM模型會將該結果與真實結果進行比對,同時LSTM會通過比對的結果,對細胞內部的參數進行調整、優化,使LSTM模型下一次輸出的結果與真實結果更加相近。但訓練過程中,為了防止出現結果過擬合,LSTM模型會在每次訓練時,會使用正則化防止過擬合。LSTM模型細胞結構如圖1所示。
1)細胞狀態
LSTM模型每個細胞都擁有自己的細胞狀態,細胞狀態為LSTM訓練過程中,該細胞輸出的值,在數據完整地通過一次所有細胞,細胞狀態會根據此次結果進行更新優化,細胞狀態的優化調整直至訓練結束或細胞狀態達到最佳。
2)遺忘門
遺忘門是控制是否遺忘信息的“決策機構”。遺忘門為當前細胞輸入內容,即為上一細胞的輸出結果。細胞并不能直接處理上一個細胞的輸出結果,在實際的模型中,細胞的輸入以及細胞的輸出具有很大的差異,遺忘門會對上一細胞的輸出結果進行函數變換,將上一個細胞的結果轉化成可用的細胞輸入。遺忘門的公式如式(1)所示。ht,xt為兩個向量合并,Wf為函數的權重,σ是細胞的激活函數(sigmoid函數),bf是函數偏置量。
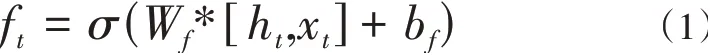
3)輸入門
輸入門由兩個部分組成,第一部分使用了sigmoid激活函數,輸出為it。第二部分為使用了tanh激活函數,輸出為at。輸出門的公式如式(2)與式(3)所示。
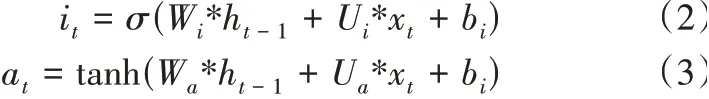
公式中Wi,Ui,Ua,Wa為權重,bf為函數的偏置量。
4)細胞狀態更新
細胞狀態更新是輸出門之前重要的一環,遺忘門與輸入門的結果都會作用于細胞狀態,細胞狀態的更新將決定該模型的優劣,當訓練結束后,細胞狀態停止更新。細胞狀態更新公式如式(4)與式(5)所示。?為Hadamard積,Ct-1為前一時刻細胞狀態,Ct為當前時刻細胞狀態。
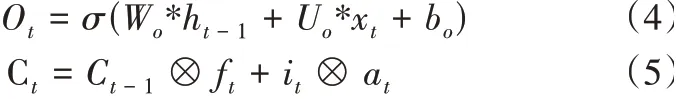
5)輸出門
輸出門分為兩個部分,第一部分如式(6)所示,第二部分如式(7)所示。輸出門最終結果為當前時刻的輸出。
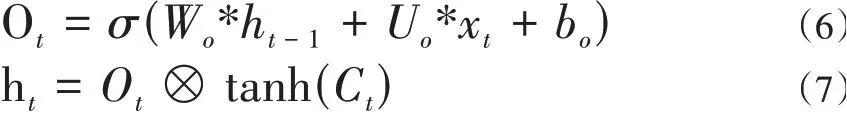
2.2 基于Keras的LSTM神經網絡模型
Keras是基于TensorFlow框架和Theano的深度學習庫,是由Python語言編寫而成的神經網絡API,Keras具有很多優勢:原型快速且簡易,對初學者友好;模塊化結構,Keras內模型獨立,損失函數,優化函數,激活函數模塊可根據需求直接進行調用,數據處理效果理想;模型擴展性好,添加新模塊容易,只需要仿照現有的模塊編寫新的類或函數;模型與Python協作性好,Keras無需單獨的模型配置文件,模型內容在代碼可以直接體現,因此模型調試擴展很方便。
3 心肌梗死的LSTM模型實現
利用LSTM模型實現對心肌梗死的發病預測,將數據集劃分為訓練集與測試集,通過訓練集訓練LSTM模型,多次訓練得出最優的訓練模型,再用測試集測試訓練出的LSTM模型,得出模型對心肌梗死患者發病預測的準確率,選擇準確度最高的模型,模型準確率是判斷模型優劣的重要指標。
3.1 數據介紹
該數據集包括Age,Sex,Cp等等14個標簽,該標簽內容呈時間序列,時間間隔為3個月。數據部分如表1所示,數據部分標簽的意義如下。
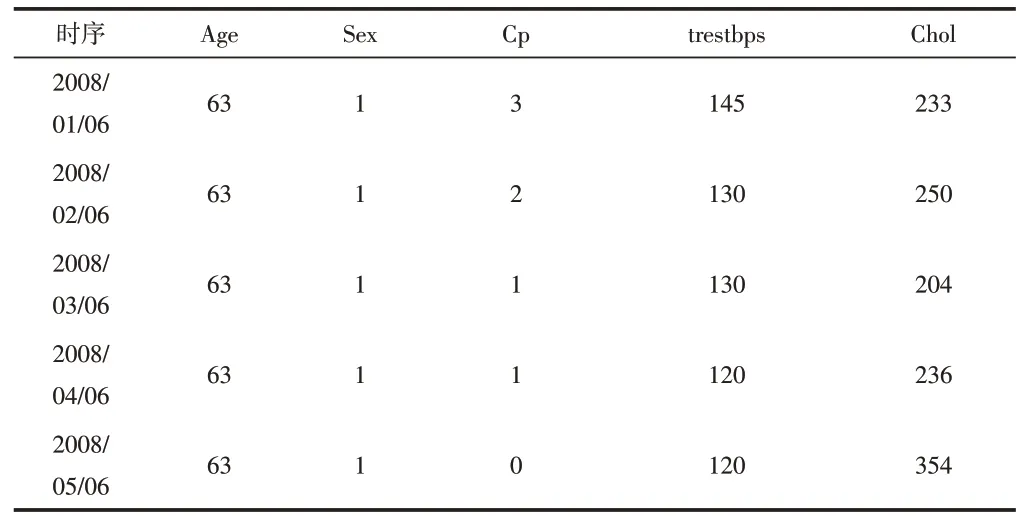
表1 數據集(部分)
Cp:經歷過的胸痛類型(值1:典型心絞痛,值2:非典型性心絞痛,值3:非心絞痛,值4:無癥狀)。
Trestbps:患者的靜息血壓(入院時的毫米汞柱)。
Chol:患者的膽固醇測量值,單位:mg/dl。
3.2 數據分析及處理
對各項標簽進行相關性分析,可以得出各個標簽對最終結果的相關性,以此為依據,可以排除部分無相關性的數據,這種做法可以提高模型的準確性,分析結果如圖2所示,其中1代表該標簽與患者患病完全正相關,-1代表該標簽與患者患病完全負相關。

圖2 相關性分析
由圖2知:是否患病和Cp、Thalach、Slope等標簽正相關,和Eang、Oldpeak、Ca、Thal等標簽負相關。選取與患病相關性較高標簽進行下一步處理,同時去掉與患病相關性較低的標簽。進一步處理相關性最較高的標簽與患者患病的關系,Thalach(靜息血壓)與Target關系,如圖3所示。Cp(胸痛類型)與Target關系,如圖4所示。
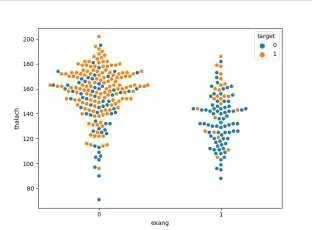
圖3 Thalach相關性
從圖3中橙色點分布情況可知,Thalach越大,患病的人數更多。而在運動中產生胸痛的人中(Target值為1),該類人群存在許多胸痛現象,該類人群心率比較高,大部分集中在120~150之間,對于并沒有心臟病的人群,該人群僅僅心率較高,并未產生胸痛。由圖4知,胸痛類型1、2、3患病概率更大[7]。
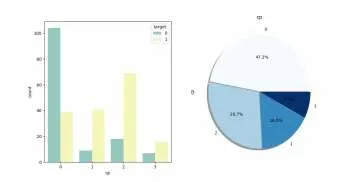
圖4 Cp相關性
3.3 模型搭建
使用Keras建立LSTM模型包括數據預處理、定義模型、訓練模型、評估模型以及使用模型進行預測。數據預處理階段,提取數據集中相關性較高的若干特征標簽,為該數據集生成DataFrame類型數據,作為序列索引,提取出Target用作Y標簽,即結果標簽。對提取出的數據進行非空處理,填補缺失的數據,并對其中Trestbps、Chol等特征標簽歸一化處理,將數據映射至(0,1)范圍內,如果不對數據進行歸一化處理,模型的LOSS將會很大,模型訓練效果也會很不理想。將處理后的數據劃分數據集,設置標志dataFlag=0.7,標志前數據為訓練集,標志后為測試集。xtrain={x1,x2,x3,...x0.8*len}和xtest={x0.8*len+1,...xlen-1xlen}。數據處理完成后,定義、構建LSTM神經網絡,本次實驗采用了Keras中Sequential層次模型,采用層層線性疊加構架激活函數為relu函數,評估函數為MSE(均方誤差)。輸入處理好的訓練集數據進入模型,訓練迭代128次,若訓練損失函數較低,將提前結束訓練。訓練結束后,對模型進行測試,輸入測試集數據進入模型,分析測試結果,得出結果參數。
3.4 實驗結果分析
本次使用采用了對比實驗,選取卷積神經網絡RNN是深度學習常用算法之一,屬于多層前饋網絡,使用訓練完成的LSTM神經網絡模型與RNN卷積神經網絡模型對同一組數據進行預測,對比預測結果。
1)評估標準
使用均方誤差(MSE),檢測模型預測值與真實值之間的差異,MSE公式如式(8)所示。
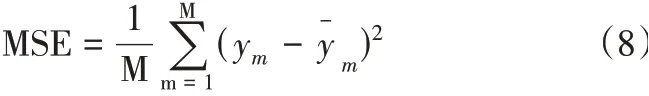
損失函數(LOSS),損失函數可以用來評估模型的預測值和真實值不一致程度,LOSS函數可以很好地反映該模型訓練結果是否準確。LOSS公式如式(9)所示。
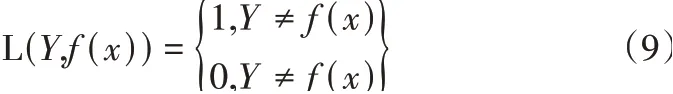
2)實驗結果分析
本節將通過MSE與LOSS兩種評估方法,去對比LSTM模型與RNN模型對本數據集的處理效果。在LSTM模型中,一共訓練了100次,BitchSize為訓練集的長度,優化器為Adam。
LSTM模型的MSE為0.332,RNN模型的MSE為0.711。LSTM模型的LOSS為0.0604,RNN模型的MSE為0.351。
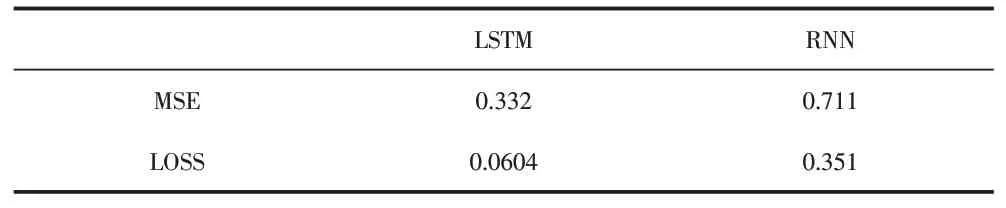
表2 實驗結果比對
從實驗評估標準看,LSTM模型的預測精度更高。
4 結束語
本文基于LSTM模型,通過對心肌梗死患者在不同時間的生命體征數據進行相關性分析,擇取與心肌梗死發病相關性較高的若干項標簽數據進行訓練。利用LSTM模型對處理后的數據進行訓練并對實現心肌梗死發病預測,得到發病預測結果。將上述結果與RNN模型預測結果進行對比,對比結果顯示:LSTM模型對心肌梗死發病預測結果準確更高,模型擬合性更優,LSTM模型可用于心肌梗死發病率預測。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
