淺談基于語義的圖像生成技術在影視氣氛圖生成中的應用
2022-09-28 02:44:42李子譞顧曉娟
現代電影技術 2022年9期
李子譞 顧曉娟
北京電影學院中國電影高新技術研究院,北京 100088
1 引言
影視制作前期準備和創意階段需要大量的腦力工作和靈感碰撞,其中的場景氣氛圖繪制部分要求藝術家在深度了解主創人員的創作意圖后,制作畫面的視覺氛圍預覽,對后期拍攝風格有著指導作用。在場景氣氛圖繪制之前,美術從業者需要在浩如煙海的網絡數據中搜索相關素材,這個不可忽略的步驟能夠幫助藝術家產出真實可信且不失藝術感的環境,然而網絡素材的精準度無法控制,并且這個過程充滿了高重復性工作,占用了大量的時間,導致工作效率下降。此時文本生成圖像技術越來越趨向成熟,使得生成復雜高精度圖像任務變成輕而易舉的工作,該技術借助龐大的數據集能夠很好地為影視行業的美術從業者前期尋找畫面參考時在構圖、光影、畫面內容上提供取之不盡用之不竭的靈感,藝術家通過有效利用科學工具,能更好地專注于創作本身和故事的敘述。
基于語義的圖像生成技術采用自然語言與圖像集特征的映射方式,根據自然語言描述生成相對應圖像,利用語言屬性通用、靈活、智能地實現視覺圖像的目的性表達,如圖1所示,輸入描述詞為“秋天里古老的法國運河”。以生成對抗網絡、擴散模型等具有代表性的基于卷積神經網絡的深度學習技術是當前文本到圖像生成的主流方法,該技術有著目標視覺屬性描述的文本高度區分度和高泛化特點,使得生成圖像無論在精準度、分辨率、多樣化還是可觀性上都有非常優異的視覺表現。

圖1 描述詞為 “秋天里古老的法國運河”生成的圖像
2 傳統影視流程中的場景氣氛圖繪制概述
場景氣氛圖是由美術設計師鉆研劇本后,根據主創人員的創作需求、內容題材、拍攝類型、場景風格等來繪制影視場景中主要鏡頭拍攝畫面的設計圖。氣氛圖雖然不能完全忠于現實,但是需要考慮實際未來場景的搭建呈現的可能性,并且在進行藝術創作和加工的前提下,更多關注色彩基調、光影構成、空間形態造型、鏡頭畫面比例結構、前后景關系等因素在當前主要場景中所營造烘托的氛圍感,渲染描繪出場景的時代氛圍、地域特色、生活氣息、情緒基調,從而展現符合影片調性的主題風格。簡而言之,作為美術設計師想象力和情感聯結的產物,場景氣氛圖是影視拍攝前期階段導演創作意圖預落地的視覺化表達,能夠事先為影視制作各個部門展示出未來影片最直觀的環境畫面形象,對后期拍攝具有指導意義。
繪制影視場景氛圍圖的方式多樣,可以用任意繪制工具表現,在計算機技術尚未普及的年代,水粉、水彩、鋼筆,甚至水墨都是常見的繪制方法,而在目前的影視工業流程上的場景氣氛圖繪制,絕大多數影視行業美術從業者采用手繪板繪制、Photoshop素材拼貼、三維軟件建模渲染等單一方式或混合方式來進行藝術創作。
3 場景氣氛圖生成的研究現狀
在計算機視覺和自然語言處理領域,隨著卷積神經網絡的深度學習技術在圖像生成領域的不斷發展,促使許多深度網絡模型不斷被提出用于基于語義的圖像生成。雖然作為后起之秀的文本到圖像技術 (Text-to-Image)研究發展時間并不算長,但是其成果顯著,不斷掀起在該領域下新的研究熱潮。早在2014年,生成對抗網絡 (Generative Adversarial Networks,GAN)由Goodfellow等人首次提出,作為在卷積神經網絡基礎上拓展的一種深度學習模型,通過生成模型和判別模型兩個基礎模型實現正向傳播和反向判別的方式互相對抗博弈,輸出最逼近于真實的運算結果,該模型有著泛化性強、數據區分度高等特點,作為主流模型廣泛運用于文本到圖像技術,而后在GAN的基礎上,衍生出針對性更強的GAN模型,其中大致可以分為四類:提高生成的圖像在語義相關性的語義增強GAN,如DC-GAN、MC-GAN;確保生成高質量圖像的分辨率增強GAN,如Stack GAN、AttnGAN;保證輸出圖像視覺外觀和類型多樣化的多樣性增強GAN,如AC-GAN、Text-SeGAN;增加時間維度生成連續圖像動作的運動增強GAN,如Story GAN。在2021年之前,文本到圖像生成領域基本上基于生成對抗網絡GAN來實現,而2021年以后,更多獨立于GAN邏輯體系的深度學習模型逐漸被提出,并取得不錯的反響,他們的效果不亞于GAN,甚至有著更出色的表現。Open AI提出基于Transformer的語言模型DALL-E,該模型能夠達到保證與文本內容一致的前提下,從頭開始創造全新圖像且能夠重新生成現有圖像的任何矩形區域。Jing Yu Koh等人提出TReCS框架,該框架修改了文本與圖像內容的映射方式以及增加了數據標注內容控制圖像元素位置的功能,極大提高了圖像生成的效率和質量。Jonathan Ho等人提出Diffusion模型,該模型邏輯基于物理學中的布朗運動,能夠捕獲更多的圖像多樣性,分布覆蓋固定訓練目標,有著更廣泛的擴展性,并且解決了GAN模型中縮放和訓練困難的問題。由清華大學和阿里巴巴達摩院共同研究開發的Cog View模型,解決大規模的文本到圖像生成預訓練中的不穩定問題,實現復雜場景中文本生成圖像的任務。
4 場景氣氛圖生成工具——Disco Diffusion
Disco Diffusion的開發者是澳大利亞數字藝術家兼程序員Somnai,在2021年10月推出的AI圖像生成程序V1版本,目前于2022年3月迭代至V5版本。它基于最新的擴散模型 (Diffusion Model)和基于自然語言監督信號的遷移視覺模型(Contrastive Language-Image Pre-Training,CLIP)語義生成機器學習框架,可以根據使用者描述場景的關鍵詞渲染出高質量、引人入勝的AI氣氛圖圖像。由于Disco Diffusion可以直接依托于谷歌的Colaboratory,方便使用者可以直接在瀏覽器中編寫和運行Disco Diffusion的代碼,避免了本地部署對電腦配置的硬性要求。只要使用者輸入畫面的關鍵詞,Disco Diffusion就會按照使用者的想法精準還原場景描述生成氣氛圖,美術從業者不需要明白其中的計算機編譯語言,也能通過這款AI程序尋找靈感,提高生產力。
通過簡單的操作步驟,就可以生成符合用戶描述的大量各異的氛圍圖內容,如圖2所示,輸入描述語為 “UE4中的寧靜大草原”。幾乎零成本產出各種天馬行空的氣氛圖,它的不確定性讓創作者看到了更多的可能性,尤其是幫助處于瓶頸期的創作者獲得更多的靈感和創意。

圖2 描述詞為 “UE4中的寧靜大草原”生成的圖像
4.1 Disco Diffusion的模型框架
下面將介紹通過基于擴散模型 (Diffusion Model)和基于自然語言監督信號的遷移視覺模型(CLIP)的Disco Diffusion來詳細描述機器學習下的文本到氣氛圖生成方法的應用。
4.1.1 擴散模型
顧名思義,擴散模型 (Diffusion Model)的基本邏輯源于非平衡統計物理學中的布朗運動,它描述的是噪聲從無序到有序之間轉換的過程,通過使用變分推理訓練的參數化馬爾可夫鏈將參數逐漸映射到多維正態分布的高斯噪聲上,以在有限時間內生成與數據匹配的樣本,迭代正向擴散過程達到破壞數據分布結構的目的,然后從中學習這條鏈的轉換來逆轉一個擴散過程,逐漸向與采樣相反方向的數據添加噪聲,直到信號被破壞,產生一個高度靈活和易于處理的數據生成模型,從而允許我們快速學習、采樣和評估深度生成模型的概率,計算學習模型下的條件概率和后驗概率以及恢復數據中的結構。雖然擴散模型可能看起來是一類受限的潛變量模型,但它們在實現過程中允許大量的自由度。簡而言之,就是從認識擴散過程到運用擴散過程的逆過程,從噪聲分布中獲取目標點的分布,如圖3所示。擴散模型定義簡單,訓練效率高,能夠生成高質量的樣本,有時比其他類型的生成模型上發表的結果更好,該模型在音頻建模、語音生成、時間序列預測、點云重建、圖像生成等模型生成領域都有著很大的優勢和應用。

圖3 Diffusion Model邏輯流程[7]
4.1.2 遷移視覺模型
基于自然語言監督信號的遷移視覺模型(CLIP)發布于2021年,該模型主要用于匹配文本和圖像,降低大量格式化數據標注構建的成本,極大地提高模型的泛化能力和遷移能力。CLIP模型的核心思想是從自然語言中包含的監督學習感知,通過學習圖像中的各種視覺概念,計算圖像文本對的余弦相似度將目標圖像關聯的視覺概念與文本聯系起來。該模型結構如圖4所示,例如,在一個充滿了鳥和昆蟲圖像的數據集里,一般標準的圖像模型是通過訓練圖像特征提取器和線性分類器來預測圖像標簽,會將該數據集中的鳥和昆蟲圖像分類;而CLIP通過同時訓練圖像編碼器和文本編碼器,來預測數據集里文本和圖像的匹配,達成訓練實例的文本圖像匹配對,會預測圖像更匹配文字描述是“一張鳥的照片”還是 “一張昆蟲的照片”。
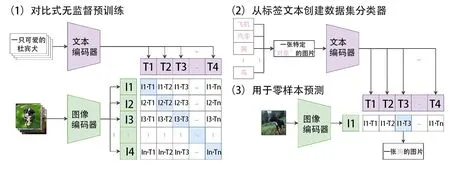
圖4 CLIP模型結構[11]
4.2 Disco Diffusion實驗與結果
本文的實驗過程中,Disco Diffusion將作為去除圖像噪聲的數學模型Diffusion和用于標記圖像的CLIP結合使用,CLIP使用其圖像識別技術迭代地引導Diffusion去噪過程朝向與文本提示緊密匹配的圖像。本章將測試不同參數對最終輸出結果的影響,并在保證能夠輸出有效結果的前提下提出規范提示語建議。
使用Disco Diffusion的方法是選擇參數,設置提示語,然后運行程序創建圖像。根據使用的設置和可用的處理器,Disco Diffusion渲染單個圖像可能需要5分鐘到1個小時或更長時間。在整個操作過程中,首先需要打開Somnai在Colaboratory中寫好的程序,并保存在自己的Google Drive中。然后對Diffusion和CLIP模型框架部分進行相應設置來控制模型生成圖像速度和質量,在圖像部分設置batch_name(圖像名字)、steps(圖像迭代次數)、width_height(圖像尺寸)、tv_scale(輸出平滑度)、range_scale(圖像量化深度)、cutn_batches(CLIP模型累計梯度)等設置來控制最終圖像輸出質量。之后關鍵的一步是需要在Prompts(關鍵詞)中寫下對畫面的文字描述內容,可以是幾個單詞比如視覺能夠辨認的物體、意象、藝術家風格、畫面構圖、輔助的情緒形容詞,也可以是一段長句子或者幾段句子來表達從而獲取想要的輸出效果。最后在Diffuse部分執行Do The Run即可渲染生成氣氛圖,如圖5所示,輸入描述詞為 “梵高夢中星空下的農村”。

圖5 描述詞為 “梵高夢中星空下的農村”生成的圖像
4.2.1 核心參數
Disco Diffusion通過參數化設置來控制CLIP模型和擴散曲線的各個方面,參數是控制Disco Diffusion圖像特征和質量的核心,各種不同的參數相互影響,使Disco Diffusion成為了一個豐富而復雜的工具。除了易于理解的參數比如圖像名字、畫面寬高等,下面將對影響氣氛圖輸出質量的參數進行介紹。
(1)steps
Diffusion是一個不斷迭代的過程,當每一次進行迭代時,CLIP都會根據提示評估現有的圖像,并為擴散過程提供 “方向”。擴散將對現有的圖像進行去噪聲處理,而Disco Diffusion將顯示其對最終圖像外觀的當前估計,在程序迭代初期,圖像只是一團模糊無序的混亂噪聲,但隨著Disco Diffusion在迭代步長中慢慢推進,圖像的細節將會以粗略到精細的過程出現,隨著擴散去噪過程被CLIP引導到所需的圖像,在迭代的范圍內逐漸變得清晰。
(2)clip_guidance_scale
該參數告訴Disco Diffusion CLIP在每個時間步向提示移動的強度。通常越高越好,但如果該參數過大,則會超出目標并扭曲圖像。如圖6所示,在其他參數恒定時,數值越大,生成圖像效果越好,但是代價是消耗更多的運行時間。同時,經過反復測試,發現該參數會隨著圖像尺寸縮放,換句話說如果將總尺寸增加50%,為獲得相同的效果,該參數也需要增加50%。

圖6 當其他參數恒定時,clip_guidance_scale和steps變化對輸出的影響①
(3)tv_scale
總方差去噪,即控制最終輸出的 “平滑度”。如果使用,tv_scale將嘗試平滑最終圖像以減少整體噪聲。當增大該參數時,輸出圖像能夠在保留邊緣的前提下,同時消除平坦區域的噪聲。
(4)sat_scale
飽和度,該參數將有助于減輕過飽和。如果圖像太飽和,可以增加sat_scale以降低飽和度,如圖7所示。
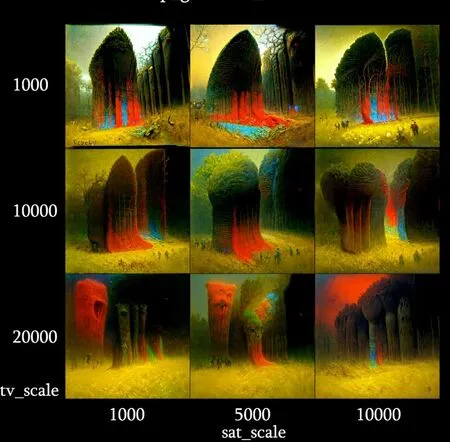
圖7 當其他參數恒定時,tv_scale和sat_scale變化對輸出的影響①
4.2.2 描述語使用建議
圖像的內容通常由關鍵詞、句子、短語或一系列描述性詞語中使用的文本來控制,這些詞語告訴CLIP用戶想看到什么。為AI藝術創建一個好的文本提示是一項細致入微、具有挑戰性的任務,需要大量的反復試驗和實踐。
本文在經過大量試驗后,給出如下建議:
(1)任何沒有提及的內容可能會帶來意想不到的結果。用戶可以明確描述或者含糊描述,但任何遺漏的信息都會隨機出現,所以盡量不要省略任何重要的背景或細節。含糊其辭雖然可能得不到最初想要的東西,但會讓畫面呈現多樣化,是一個為影視流程中的美術從業者提供靈感的好方法。
(2)使用視覺上易于辨認的事物,比如城市、荒原、房子、寺廟、海洋、高山、汽車等網絡上存在很多照片的具象事物。帶有強烈情緒色彩或迷幻主觀的抽象內容往往會讓生成的氛圍圖變得抽象,比如令人敬畏、時間的誕生、自我觀念、無限、知識的渴望等。對于氣氛圖的生成,應少用概念推斷的描述,而更多是具體外觀的描述。
(3)使用藝術家的關鍵詞可以獲取獨特的畫風。在提示語后加上藝術家的完整名字,能夠得到該藝術家風格的氛圍圖,如圖8所示。

圖8 不同藝術家描述詞生成的結果②
(4)使用特定構圖。當想要得到特定的景別構圖時,可以使用如廣角、特寫、微距、長焦、全景、近景、鳥瞰等詞匯。
(5)使用肯定句,避免使用否定句。程序對否定詞匯比如 “not”“but”“except”“without”等詞表現不佳,甚至在運行過程中會忽略否定詞匯。
(6)使用單數名詞或具體數字,由于含糊的附屬詞會增加不確定性,所以盡量避免直接使用復數名詞。
(7)關鍵詞或字符串結尾可以包含一個 “:num”值來指示該提示詞相對于其他提示詞的權重,同時權重可以為負數,負權重可以幫助抑制與不需要的提示匹配特征,例如 ["rocky beach:2","sky:-1"]將圖像推向巖石海灘,同時減弱天空細節。
5 總結和展望
本文研究介紹了基于機器學習的文本到圖像生成技術,提出使用該技術來輔助影視行業內的美術從業者進行前期場景氛圍圖的藝術創作,AI作為一個 “畫得好看”但沒有主觀表達的畫師,它的出現并不是為了替代美術從業者工作,而是作為一個工具,依靠它優秀的學習能力和龐大的數據儲備,能夠為影視行業的美術從業者在繪制畫面的構圖、色彩、光影、內容方面提供源源不斷的靈感和借鑒,美術從業者有效利用科學技術,在藝術創作工程中取其精華,去其糟粕,把更多的時間專注在創造和思考上,能夠有效提高產出場景氛圍圖的質量和效率。雖然目前對T2I技術的研究已經有了重大的突破,越來越多獨立于生成對抗網絡的深度學習模型在該領域無論是精度還是效率上都不斷刷新之前所取得的成績,但是技術研究仍存在巨大的進步潛力,在分辨率、文本圖像一致性、精確性、產出創新性等方面都有很大的發展空間。筆者認為文本到圖像生成與影視制作結合上還存在著以下亟需攻克的難點:
(1)不確定性。基于語義生成圖像的技術極度依賴準確的語義描述表達,錯誤的描述、不正確的語法結構或者不同關鍵詞的先后順序都會導致令人失望的結果,這樣的不確定性,既可以是基于語義生成圖像技術的優點,也同樣是缺點,它能不費吹灰之力地大量產出天馬行空的畫面、規則之外的構圖,為創作者提供靈感,但也同時不能特別聽話地完成使用者的指令,生成的結果可能與使用者的想法有著巨大的偏差。
(2)具體內容表現不佳。當美術從業者想要得到非常具體的結果時,程序可能會不盡人意,比如描述關于人和人體的話語,由于程序并沒有完全能夠生成比較好的 “人類”,雖然有不少非常成功的案例,但是生成結果通常會有不適感;反之,如果想要生成寫意或者注重光影的抽象場景,往往會得到讓人意想不到的優秀作品。
(3)生成圖像的版權歸屬風險。雖然大部分文本到圖像程序是完全免費開源的工具,并且遵守MIT開源協議,但由于該程序并不是對已有的畫作內容進行裁切拼貼重組,而是通過機器學習的觀察提煉規律來繪制產出,所以當程序訓練量不夠,描述詞涉及到風格鮮明的藝術家或者某部商業作品時,會存在部分認定抄襲的風險,這也是導致版權糾紛等法律風險需要時刻警惕的地方。
機器學習有著超越了傳統手工設計的能力,甚至在某些數據集上的表現已經超越人類,代替人類進行重復性強勞動密集型的工作,影視制作前中后期都存在著大量可以依靠機器學習來優化賦能的地方,當前人工智能技術的出現加快了影視工業數字化建設的進程,譬如人工智能劇本創作、人工智能預調色、基于機器學習的數字合成技術、深度學習視頻插幀技術、自動化影片修復技術、智慧影院系統等眾多突破,這些成功的人工智能與影視領域合作的案例和經驗,提高了中國影視制作的效率,提高了視效制作水平,改變了影視行業的生態生產格局。未來影視流程工業化的發展更離不開人工智能技術的不斷更新迭代,筆者相信在接下來的發展中,機器學習將應用到影視工業數字化流程上的各個領域,促進深度學習在影視制作領域發揮更多的可能性,交互流程對行業創作者更加友好,減少人工重復性操作成本,優化影視制作流程,提高影視制作效率,服務于影視制作全流程的方方面面。
①圖片來源:https://discord.com/channels/944025072648216 586/944025072648216589。
②圖片來源:https://weirdwonderfulai.art/resources/discodiffusion-70-plus-artist-studies/?continueFlag=3f57cb4501800e372f 9e1a422a68354a。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
甘肅教育(2020年8期)2020-06-11 06:10:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
核科學與工程(2015年4期)2015-09-26 11:59:03
