基于Look-alike和K-means算法的音樂冷啟動問題研究
2022-09-29 01:10:22王屯屯
電腦知識與技術 2022年23期
王屯屯


摘要:在音樂推薦領域,根據(jù)用戶的行為習慣進行偏好建模并進行推薦。但是對于熱度較低的音樂,由于很少有用戶進行消費,幾乎得不到推薦,導致系統(tǒng)中的馬太效應越發(fā)明顯,不利于音樂平臺的長期發(fā)展。基于look-alike框架針對冷門音樂分別進行建模,訓練周期較長,且由于樣本數(shù)量少,模型效果不理想。利用K-means算法對冷門歌曲進行聚類,再投入look-alike框架進行訓練,訓練周期大幅度縮短,且推薦準確率更高。
關鍵詞:Look-alike;kmeans;音樂推薦;冷啟動
中圖分類號:TP311? ? ? ? 文獻標識碼:A
文章編號:1009-3044(2022)23-0001-02
1引言
隨著互聯(lián)網(wǎng)的飛速發(fā)展以及智能移動終端的普及,隨時隨地聽音樂已經(jīng)成為當代社會的一種常態(tài)。面對海量音樂,主動檢索和排行榜成為很多人的選擇。推薦系統(tǒng)的推出,可以很好地主動為用戶提供音樂[1]。推薦系統(tǒng)一般需要大量用戶日志信息作為支撐[2],但是冷門音樂相關訓練數(shù)據(jù)較少,推薦效果不佳,因此需要針對冷啟動狀態(tài)下的音樂制定特殊推薦算法。一種可行的思路是根據(jù)冷門音樂的消費群體,找到與這些用戶相似的目標用戶進行推薦。而look-alike的工作機制就是基于用戶畫像和社交關系找到相似用戶,因此該算法適合用于解決音樂冷啟動問題。但是在該算法框架中,需要為每首音樂進行模型訓練,使得推薦的音樂數(shù)量較少,并且每首音樂消費用戶較少,訓練樣本不足,導致模型準確率不高。K-means算法作為復雜度較低的聚類算法,可以快速地將相似的音樂進行聚類,然后將該群體下音樂集中起來進行訓練,不僅可以擴大樣本數(shù)量,還可以提高look-alike的效率。
2 相關工作
針對推薦系統(tǒng)物品冷啟動問題,很多研究者提出自己的算法。SAVESKI等人[3]綜合考慮物品的內(nèi)容特征和消費該物品的用戶產(chǎn)生的行為特征,將這兩個特征矩陣一起分解。借助矩陣分解可以實現(xiàn)精準的推薦,在此基礎上利用物品的內(nèi)容特征實現(xiàn)物品冷啟動。LIU等人[4]在協(xié)同過濾的基礎上,再次進行內(nèi)容過濾實現(xiàn)物品冷啟動。通過虛擬分配項目的信息文件,在進行內(nèi)容篩選的基礎上,借助傳統(tǒng)的協(xié)同過濾框架得到推薦結果。陳克寒等人[5]基于兩個階段的聚類過程,在考慮圖摘要算法的基礎上,通過常規(guī)的內(nèi)容相似算法,得到較為理想的推薦結果。文獻[6]基于look-alike框架,借助于種子用戶與目標用戶間的行為相似性,達到受眾擴展目的。此外,考慮到種子的不同成員,為了達到目標用戶的自適應學習的健壯性,在局部attention單元的基礎上,還精心設計了全局attention單元。為了降低時間性能消耗,對Seeds進行了聚類操作,不僅訓練變快,而且最大限度地減少了種子信息的丟失。
3 模型介紹
3.1 Look-alike
Look-alike模型由Facebook公司于2013年發(fā)表,最初的目的是為廣告主尋找與已有廣告(種子)類似的潛在用戶群體。本文將冷門音樂作為廣告,根據(jù)已經(jīng)消費過冷門音樂的用戶,發(fā)掘相似的用戶進行音樂推薦,從而提高冷門音樂的熱度,緩解系統(tǒng)中的馬太效應。Look-alike框架根據(jù)具體實現(xiàn)的算法,主要分為三種:基于相似度,基于邏輯回歸以及基于注意力深度學習模型。
(1)基于相似度的look-alike模型
基于相似度的look-alike模型是最直觀、最簡單的一種方法:選取某種相似度評價指標,計算種子用戶與目標用戶的相似度,降序排序并取頭部用戶進行投放。常用的相似度指標包括:余弦相似度和Jaccard系數(shù)。
余弦相似度主要針對具備連續(xù)值屬性特征,具體定義如下:
其中N表示特征數(shù)量,Uik和Ujk分別表示用戶Ui和Uj的第k維特征的取值。
Jaccard系數(shù)主要針對具備離散值屬性特征,具體定義如下:
其中U(i,j)表示用戶Ui和用戶Uj特征值相同,TUik和TUjk分別表示用戶Ui和Uj在k維特征上進行的截斷值。
定義好兩個用戶間的相似度后,需要定義目標用戶Ut與種子用戶群體Seeds間的相似度,主要方式有取最大值simmax和平均值simmeans,具體定義如下:
其中sim(Ut,Us)的計算方式,要根據(jù)具體需求確定。基于相似度的實現(xiàn)方法設計比較簡單,但是當數(shù)據(jù)規(guī)模較大時,時間復雜度比較高。
(2) 基于邏輯回歸的look-alike模型
該方式將look-alike作為概率預測問題,而該問題通常借助二分類任務進行,通過邏輯回歸預測目標用戶的喜歡程度。模型的效果取決于樣本的質(zhì)量,因此數(shù)據(jù)集的生成至關重要。正樣本比較好獲取,可以直接采用種子用戶的行為,對于負樣本一般選擇所有非種子用戶的數(shù)據(jù)。
(3)基于深度學習的look-alike模型
該實現(xiàn)方式最具代表性的是由騰訊發(fā)布的look-alike系統(tǒng),用于緩解微信的“看一看”中存在的馬太效應。該模型將用戶的行為送入word2vector模型訓練,得到Embedding特征,并且將特征分為離線訓練和在線處理兩部分,并且將常用的softmax改為negative sampling,而損失函數(shù)則采用傳統(tǒng)的sigmoid cross entropy。
3.2 融合K-means模型
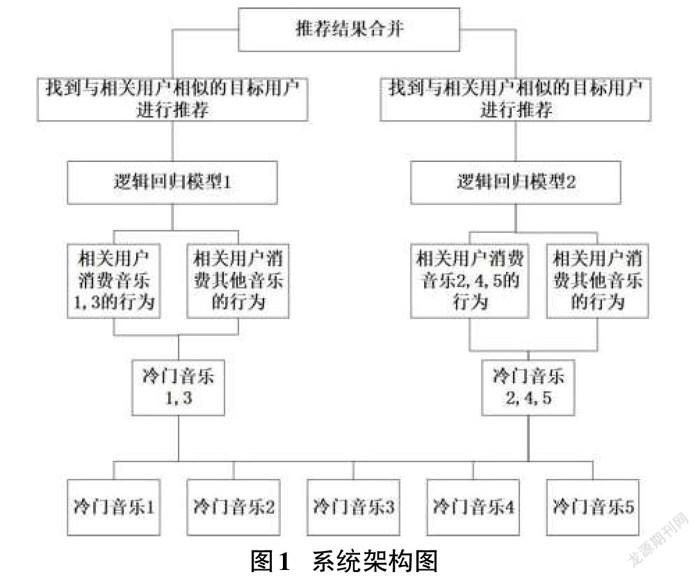
本文采用基于邏輯回歸的look-alike模型解決音樂冷啟動問題,模型結構如圖1所示:
傳統(tǒng)的look-alike框架會為每一首音樂訓練模型,并進行推廣。但是這樣會對計算性能要求比較高,訓練周期較長。此外,單首音樂的樣本數(shù)據(jù)較少,模型訓練效果不佳。根據(jù)啟發(fā)式算法,相似的音樂會被同一批人喜歡,這里將所有音樂送入K-means模型進行聚類,將相似的音樂歸入一類進行模型訓練和目標用戶投放。
圖中音樂1和音樂3比較相似,被劃分為一個簇,音樂2、音樂4和音樂5被劃分到另外一個簇。將這兩個簇內(nèi)相關用戶對簇內(nèi)音樂的行為作為正樣本,相關用戶對簇外音樂的行為作為負樣本,分別訓練邏輯回歸模型。最后將目標用戶送入訓練好的模型,提取消費概率最高的用戶進行投放。
4 實驗
本章節(jié)對算法框架進行了詳細的闡述,將通過投放準確度和時間消耗兩方面分別驗證本文所提模型的優(yōu)勢。本文實驗所采用數(shù)據(jù)為真實互聯(lián)網(wǎng)公司脫敏后的用戶行為數(shù)據(jù)。
4.1 評價指標
在投放準確度方面,這里采用AUC評價指標,具體定義如下:
其中Rk表示第k個正樣本所在的位置,i表示正樣本數(shù)量,j表示負樣本數(shù)量。該評價指標的取值范圍為[0,1],值越大,代表模型的效果越好。
在對模型的時間消耗評價方面,會計算每個模型推送M首音樂時所需要的總時間。總時間分為數(shù)據(jù)預處理、模型訓練、結果預測以及數(shù)據(jù)推送四個步驟。由于數(shù)據(jù)預處理和數(shù)據(jù)推送對每個模型保持一致,因此只計算模型訓練和結果預測的時間進行對比。
4.2 實驗設置
提取用戶的音樂歷史行為,行為類型包括:播放,收藏以及下載。將播放時間小于10秒的用戶行為設置為負樣本,其他行為設置為正樣本。此外,考慮到負樣本數(shù)量太少,將這些用戶對應的其他音樂收藏下載行為也設置為負樣本。
將“用戶-音樂”行為進行倒排,獲取每首音樂對應的用戶數(shù)量UNUM,將UNUM分布在[10,100]的音樂作為冷門音樂進行實驗。數(shù)量小于10的音樂,用戶行為過少,訓練出來的模型效果較差;數(shù)量大于100的音樂,暫時不認定為冷門音樂。
4.3 實驗結果
本文所提模型LAKM(Look-alike based on K-means),首先將所有音樂的以后行為送入K-means模型進行聚類,將相似的音樂作為一個整體,每個簇訓練一個邏輯回歸模型,預測目標用戶對簇的喜歡程度,按照打分降序取TOPN進行推薦。對比模型look-alike直接為每一首音樂訓練邏輯回歸模型并進行投放。具體實驗結果如圖2和圖3所示:
通過實驗結果發(fā)現(xiàn),本文所提模型LAKM在AUC和TIME上均優(yōu)于對比模型look-alike。LAKM模型通過K-means方法進行聚類,該聚類算法較為簡單,耗時較短,而以簇為單位進行投放,訓練的邏輯回歸數(shù)量遠遠小于對比模型,因此所需時間極大縮減;相較于單首音樂,多首相似音樂的用戶行為明顯較多,訓練出來的模型效果更好,因此能夠更好地進行音樂推送。
5 總結與展望
在利用look-alike框架投放冷門音樂時,需要每一首音樂訓練邏輯回歸模型。利用K-means對冷門音樂進行聚類,找到相似的音樂作為一個整體進行推薦,不僅可以提高樣本數(shù)量,還降低了訓練模型的數(shù)量,在提高投放準確度的同時,降低了訓練時間,使得更多音樂可以得到投放機會,解決音樂推薦的冷啟動問題。在特征選擇方面,只采用了音樂的Embedding特征,后續(xù)將考慮加入更多音樂特征。
參考文獻:
[1] 田杰,胡秋霞,司佳豪.基于深度信念網(wǎng)絡DBN的音樂推薦系統(tǒng)設計[J].電子設計工程,2021,29(23):162-165,170.
[2] 喬雨,李玲娟.推薦系統(tǒng)冷啟動問題解決策略研究[J].計算機技術與發(fā)展,2018,28(2):83-87.
[3] Saveski M,Mantrach A.Item cold-start recommendations:learning local collective embeddings[C]//Proceedings of the 8th ACM Conference on Recommender systems.Foster City,Silicon Valley,California,USA.New York:ACM,2014:89-96.
[4] Liu H S,Goyal A,Walker T,et al.Improving the discriminative power of inferred content information using segmented virtual profile[C]//Proceedings of the 8th ACM Conference on Recommender systems.Foster City,Silicon Valley,California,USA.New York:ACM,2014:97-104.
[5] 陳克寒,韓盼盼,吳健.基于用戶聚類的異構社交網(wǎng)絡推薦算法[J].計算機學報,2013,36(2):349-359.
[6] Liu Y D,Ge K K,Zhang X,et al.Real-time attention based look-alike model for recommender system[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining.Anchorage AK USA.New York,NY,USA:ACM,2019:2765-2773.
【通聯(lián)編輯:聞翔軍】
