小麥加工鏈中重金屬鎘含量的深度網絡預測模型
2022-09-30 07:49:14金學波張佳帥郭天洋王小藝蘇婷立賴燕群孔建磊白玉廷
食品科學 2022年17期
關鍵詞:模型
金學波,張佳帥,郭天洋,王小藝,蘇婷立,賴燕群,孔建磊,白玉廷
(1.北京工商大學人工智能學院,北京 100048;2.北京工商大學 中國輕工業工業互聯網與大數據重點實驗室,北京 100048;3.北京工商大學食品與健康學院,北京 100048;4.北京服裝學院,北京 100105;5.中糧糧油工業(荊州)有限公司,湖北 荊州 434300)
小麥是一種在世界各地廣泛種植的谷類作物,在我國小麥的生長范圍廣泛,是人們喜愛的主食之一,也是牲畜的主要飼料用料之一。據《國家統計局關于2021年糧食產量數據的公告》,2021年全國小麥播種面積23 568.4千 hm,總產量為12 226萬 t。
在小麥的生產中,重金屬污染問題引起了人們的廣泛關注。若食用被重金屬污染的小麥,當污染物生物累積性達到一定濃度后會引起慢性中毒甚至癌癥、生理畸形等病癥。如重金屬鎘在攝入后可在人體的肝、腎等器官組織中蓄積,造成各器官組織的損傷,當達到一定濃度后會破壞骨骼中鈣的正常補給,嚴重者會造成骨軟化癥等惡性疾病。因此,通過預測方法掌握食品加工鏈重金屬污染發展規律并及時加以預防控制具有極大的實際應用意義。
目前用于預測建模的方法主要是多元線性回歸方法。例如,牛耀星等采用一級動力學模型結合Arrhenius方程建立了基于金針菇子實體品質指標的貨架期預測模型,并對模型的預測精確度進行了驗證及評價。李婕使用Huang模型、Baranyi模型、修正的Gompertz模型對雙孢蘑菇表面背景菌群和假單胞菌的生長情況進行建模,模型適合描述溫度對雙孢蘑菇樣品表面假單胞菌生長速率的影響。宋波等采用逐步多元回歸分析建立不同鎘濃度等級下水稻籽粒重金屬鎘含量預測模型,模型能夠預測稻米中鎘的累積量,為廣西鎘異常區內其他水稻產地的安全生產提供了參考。王燁鋒采用多元逐步線性回歸分析方法對土壤-水稻體系中鎘的積累情況建立預測模型,決定系數()均達0.7以上。通過實測值反推模型,3 組模型擬合散點值均勻分布在=線兩側,并通過采集田間樣品對模型進行了驗證。也有一些學者進行了神經網絡建模的嘗試,取得了良好的效果。例如,于灝等針對小麥中鎘的含量分別建立了多元回歸模型與淺層神經網絡模型,結果表明基于神經網絡的小麥鎘含量預測模型的精度總體優于多元線性回歸模型。
綜上可知,目前對于原糧產地小麥中鎘含量分析的研究較多,卻鮮有研究涉及小麥加工過程中鎘含量的變化。而在加工過程中,鎘含量的變化與小麥粉的品質直接相關。本研究基于小麥原糧(即原麥)的鎘含量數據預測小麥加工成品——小麥粉中的鎘含量,以此為依據指導加工環節中的重金屬危害管控,從而避免小麥粉的重金屬含量超標,保證食品安全。
另一方面,加工過程中的危害物含量具有強非線性、強隨機性的特征,因此線性回歸、淺層神經網絡等模型建模精度不高,預測性能有待提升。將深度學習網絡應用于強非線性、強隨機性數據預測領域的研究有很多。Haider等建立了一種基于長短期記憶(long and short term memory,LSTM)網絡的小麥產量預測模型。牛哲文等建立了基于門控循環單元(gated recurrent unit,GRU)的預測模型,使用具有波動性和不確定性的風速、風向等歷史天氣數據對風力發電的功率進行了預測。但是,由于這些深度網絡模型對噪聲非常敏感,并不適用于小麥加工過程中鎘含量預測模型的建立。
為了提升小麥加工過程中鎘含量預測的準確度,本研究基于小麥加工鏈鎘含量數據進行深度學習網絡建模,并使用正則化方法優化其損失函數,通過加入噪聲懲罰項防止訓練時模型對噪聲的過度擬合,并使用貝葉斯超參數優化方法對模型超參數進行優化。
1 材料與方法
1.1 材料
小麥為某企業收購原糧。
1.2 設備
Y7000P便攜式電腦(配備16 GB運行內存和RTX3050Ti顯卡) 聯想控股股份有限公司。
1.3 方法
1.3.1 小麥加工鏈及關鍵節點
小麥加工鏈是指從原麥到小麥粉的所有生產環節,簡化示意圖如圖1所示。該加工鏈共有清理、潤麥、皮磨等10 個加工環節。原糧委托某公司按圖1進行加工,并對各加工環節進行抽檢。抽檢方法為:每隔2 h對全加工鏈抽檢1 次,共抽取16 次,每次在各環節分別抽取3~4 份(每份1 kg)平行樣品。為便于表示各環節的樣本,設定原糧、清理、潤麥、皮磨一(1M芯)、皮磨二(2M芯)、皮磨三(3M芯)、皮磨四(4M芯)、皮磨五(5M芯)、皮磨六(6M芯)、包裝、存放環節分別為~。

圖1 小麥加工鏈簡化示意圖Fig. 1 Flow chart of wheat processing chain
1.3.2 鎘含量的測定
取1.3.1節樣品,委托某公司參照GB/T 20380.4—2006《淀粉及其制品 重金屬含量 第4部分:電熱原子吸收光譜法測定鎘含量》測定鎘含量(以鎘元素計),單位為mg/kg。
1.4 數據處理與分析
1.4.1 鎘含量數據集構建
取樣時設置3~4 個平行,各環節每次取樣的鎘含量結果以平行樣品鎘含量的平均值表示,共獲得16 條全加工鏈的鎘含量數據。由于這些數據數量不足以訓練神經網絡,利用等差插值的方法對數據進行增廣處理。
1.4.2 基于正則化損失函數的GRU深度網絡模型分析
首先用門控循環單元建立深度學習模型,其次,設計基于正則化方法優化的損失函數,該損失函數在模型原損失函數的基礎上添加訓練數據中噪聲的懲罰項,達到在訓練過程中減小對噪聲擬合程度的目的。因此訓練過程中損失函數會在一個穩定值附近波動,該穩定值用來量化數據中的噪聲。
GRU在時序預測任務中有很好的效果,此前已經有大量的研究中都使用GRU作為預測模型并且證明了其性能。GRU模型中只有兩個門,分別是更新門和重置門。更新門控制前一時刻的狀態信息帶入到當前狀態的程度,該門的數值越大就說明前一時刻的信息帶入越多。重置門用于控制前一時刻狀態的遺忘程度,數據越大說明忽略越少。
GRU模型結構如圖2所示,根據該結構進行前向傳播時每個單元中參數計算,如式(1)~(4)所示。
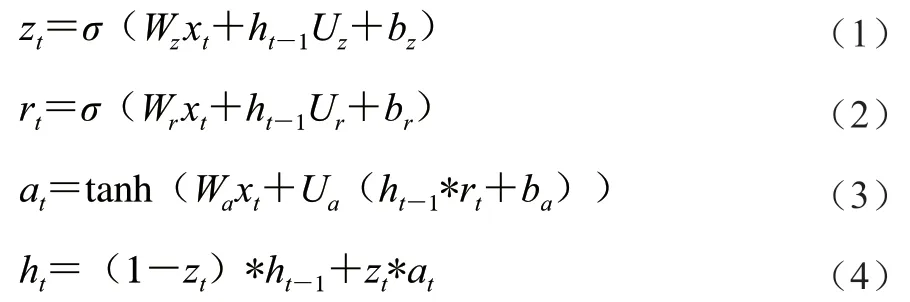
式中:x為時刻的輸入;z為更新門衰減系數;r為重置門衰減系數;h是-1時刻的狀態向量;h為時刻狀態向量;W、U為更新門權重;W、U為重置門權重;W、U為待選a的權重;b、b、b為偏置向量;為Sigmoid激活函數;*表示逐元素乘法;tanh為tanh激活函數。
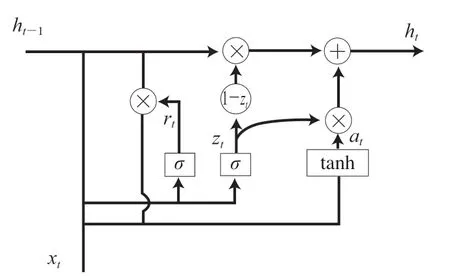
圖2 GRU模型結構圖Fig. 2 Structure diagram of GRU model
但GRU模型在訓練時易對鎘含量數據中含有的非線性噪聲過度擬合,降低模型的泛化能力,從而影響模型的預測性能,因此需要采取措施防止模型過度擬合。正則化的作用在于限制模型中的參數,讓模型的參數不會過大,從而減少模型過度擬合的可能。在此步驟中,為減少模型因過度學習加工鏈數據中的隨機噪聲而導致模型過度擬合,設計噪聲平滑損失函數,如式(5)所示。
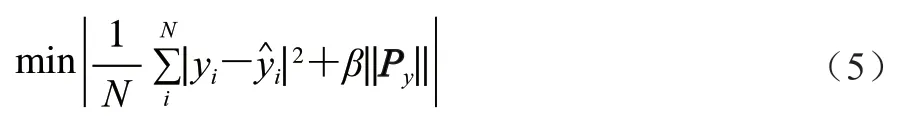
噪聲平滑損失函數的計算公式中包括兩個部分,第一部分衡量數據擬合程度,表示將實際序列與擬合序列之間的殘差平方和最小化的目標;第二部分衡量數據平滑程度,表示訓練過程中對序列平滑度的需求。其中,擬合程度用平均絕對誤差表示,平滑程度通過計算P的范數來實現。是正則化項,將其視為在擬合與平滑兩個目標之間的權衡取舍。
P的計算是實現噪聲平滑損失函數的關鍵,計算時首先需要定義矩陣,該矩陣對數據進行平滑度懲罰。矩陣如式(6)所示。

矩陣的維度由輸入數據決定,假設輸入數據長度為,則的維度為(,),然后通過與輸入數據組成矩陣的乘法計算得到矩陣P,最后通過矩陣范數的計算得到可以表示數據每3 個點間平滑程度的范數。
在訓練過程中,本實驗所設計的損失函數可以有效地考慮噪聲對模型的影響從而達到減少過度擬合的作用。當公式(5)中為0時,網絡學習原始數據,隨著不斷增大,擬合線趨向平滑。所以,本實驗所設計的損失函數可以使模型對噪聲具有更強的魯棒性,有效減小噪聲在訓練過程中的影響,從而提高模型的預測準確度。
1.4.3 應用網絡的貝葉斯優化方法分析
深度學習模型的超參數選擇直接決定了模型的性能。本研究基于序列模型的優化(sequence model based optimization,SMBO)方法進行模型超參數優化,優化的超參數主要包括GRU中的神經元數、Dropout率、訓練次數、批處理大小、優化器。
貝葉斯優化方法在確定模型參數時,使用代理模型來擬合真實的目標函數,并根據擬合結果主動選擇最“潛在”的評估點。所以需要定義一個目標函數()和優化的超參數空間。目標函數(式(7))表示通過貝葉斯優化需要達到的最小化的目標,通過設定模型的目標函數,找到此度量上產生最佳得分的模型超參數。
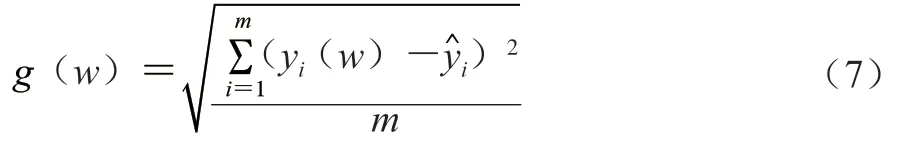
貝葉斯優化的代理函數如式(8)所示。

式中:*為貝葉斯優化確定的最優參數;為輸入的一組超參數;為多維超參數的參數空間;()為目標函數。
貝葉斯優化主要由兩個步驟組成:首先通過第+1步估計和更新高斯過程,然后通過最大化代理函數來指導超參數的采樣。在高斯過程中,設置目標函數()服從高斯分布(式(9))。
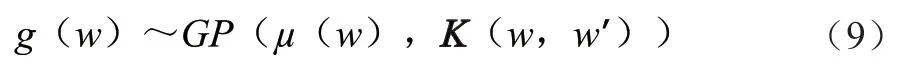
式中:()為目標函數;()為目標函數()的均值;(,’)為目標函數()的協方差矩陣;表示高斯分布。初始的(,’)如式(10)所示。
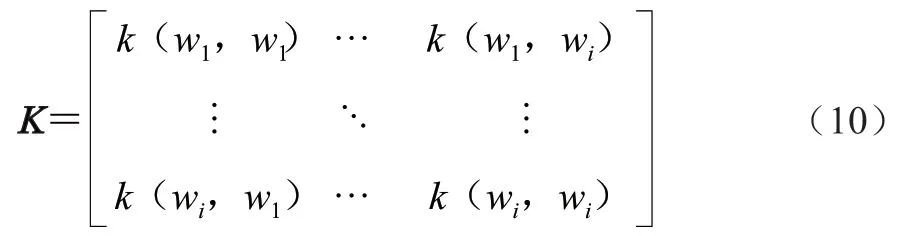
式中:為超參數的數量;表示協方差矩陣;(,)、(,w)、(w,)、(w,w)為矩陣內的不同超參數的組合。
在進行貝葉斯優化時,高斯過程的協方差矩陣會隨著迭代過程改變,假設在第+1步輸入的一組參數為w,則此時協方差矩陣如式(11)所示。
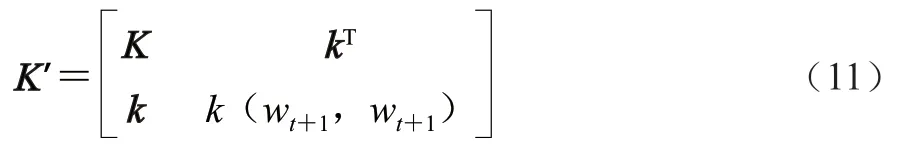
式中:’為+1時刻的協方差矩陣;為初始的協方差矩陣;w為+1時刻的超參數值;為超參數的組合矩陣,為的轉置,的組合公式為=[(w,),(w,),…,(w,w)],此時可以得到目標函數的后驗概率(式(12))。
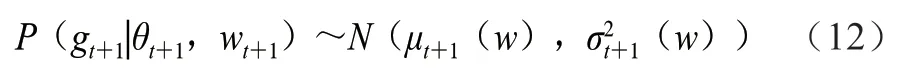
得到后驗概率后,通過超參數搜索方法來尋找最優超參數,本實驗使用上置信界(upper confidence bound,UCB)采集函數(式(13))來完成超參數搜索。
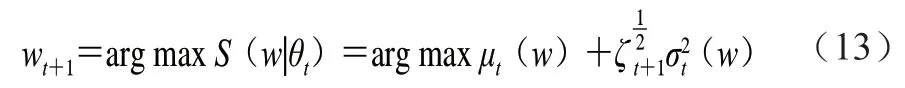
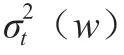
1.4.4 預測效果評價標準與模型對比驗證
以80%的鎘含量數據用作訓練集,對模型的性能進行訓練優化;以20%的鎘含量數據數據作為驗證集,驗證模型的性能。采用均方根誤差(root mean square error,RMSE)、平均絕對誤差(mean absolute error,MAE)、皮爾遜相關系數評估預測的性能,計算分別如式(14)~(16)所示。三者均反映模型預測值與真實值之間的關系。RMSE、MAE越小,說明模型預測結果與真實情況越接近。越大,說明模型預測結果與真實情況越接近。
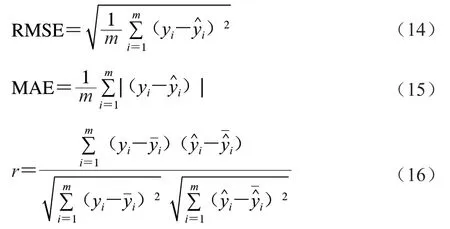
采用線性回歸、循環神經網絡(recurrent neural network,RNN)、LSTM和GRU模型與本研究所得模型進行對比。通過比較各模型基于小麥加工鏈鎘含量數據的預測效果評價指標(RMSE、MAE、)驗證模型的預測性能,驗證本研究所得模型在實際小麥加工鏈鎘含量預測中的可靠性。
2 結果與分析
2.1 小麥加工鏈中小麥的鎘含量數據集構建
小麥加工鏈各環節樣品的鎘含量數據經增廣處理后最終獲得2 057 條全加工鏈的鎘含量數據。以其中3 條全加工鏈的鎘含量變化為例,如圖3所示,在清理環節、潤麥環節中鎘含量略有增加,之后各環節鎘含量的變化相對平穩。
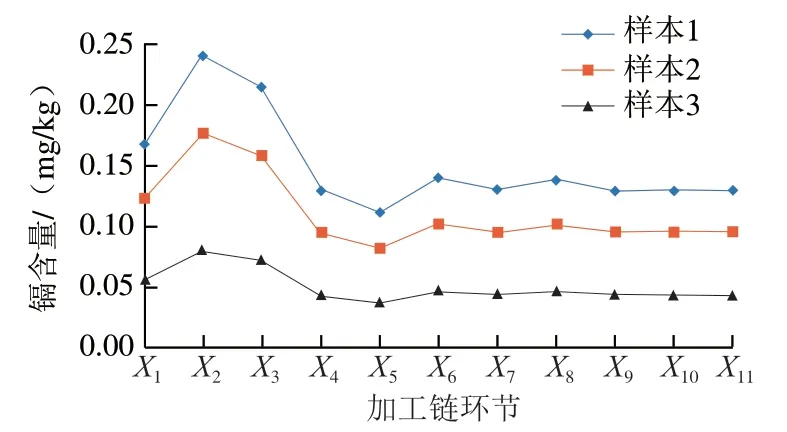
圖3 各加工環節不同樣本中鎘含量Fig. 3 Cadmium contents in different samples measured during processing
2.2 不同模型預測的性能對比
基于2.1節小麥加工鏈10 個環節中2 057 條全加工鏈的鎘含量數據進行實驗。將本研究所得模型與線性回歸、RNN、LSTM、GRU模型進行對比,采用RMSE、MAE、評估模型的性能,結果如表1所示。本研究所得模型的RMSE(0.259 5)最小、MAE(0.161 6)最小且最大,比GRU模型的預測性能更好(RMSE降低了46.37%)。

表1 不同預測方法基于鎘數據的性能對比Table 1 Performance comparison of different prediction methods based on cadmium data
通過驗證集的驗證與對比分析可知,本研究所得模型在預測任務中表現更為出色,擁有更強的含噪時序數據分析能力。由此可見,本研究所得模型可以有效地分析含噪時間序列數據,對于小麥加工鏈危害物等含噪數據有良好的預測性能。
2.3 模型預測結果
基于2.1節中20%的原糧鎘含量數據,對后續清理、潤麥、皮磨等10 個環節鎘含量進行預測,其中6 個樣本預測結果如圖4所示。其中,清理環節和潤麥環節樣品的鎘含量略有上升,尤其是清理環節,由于鎘元素在小麥表皮的富集,這兩個環節的浸潤對鎘元素有一定的析出作用。皮磨一及皮磨二環節后鎘含量持續下降,說明皮磨對危害物鎘有較好的去除作用。預測結果還表明,~環節鎘含量基本趨于平穩。
GB 2762—2017《食品安全國家標準 食品中污染物限量》規定小麥原糧及成品糧的鎘含量不得高于0.1 mg/kg。由本研究所得模型可知,當小麥原糧中鎘含量低于GB 2762—2017規定的0.1 mg/kg時,加工鏈中清理環節和潤麥環節的鎘含量可能會使其暫時超標,但最終成品小麥粉符合GB 2762—2017要求;而當原麥中鎘含量高于0.1 mg/kg時,成品小麥粉中鎘含量將高于0.1 mg/kg。因此考慮檢測數據偏差的情況下,為確保小麥粉的食用安全,原糧中危害物鎘含量高于0.1 mg/kg時不能進行后續加工流程。

圖4 模型預測小麥加工鏈中樣品鎘含量的變化規律Fig. 4 Trend of cadmium content in wheat processing chain predicted by the model
3 結 論
本實驗基于小麥加工鏈各個環節小麥中的鎘含量。采用深度學習的建模方法對加工鏈各環節樣品中的鎘含量進行建模預測。所建模型首先使用正則化方法修改深度學習模型的損失函數,通過加入噪聲懲罰項來減小噪聲項對模型預測性能的影響。同時使用貝葉斯優化算法優化模型超參數。經過對比驗證,本研究所建模型對于實際的小麥加工鏈鎘含量數據預測準確度較高。
應用該預測模型可以準確地預測出加工鏈中從原麥到小麥粉的各個關鍵環節鎘含量的變化,能夠對小麥加工鏈的鎘危害物防控實踐進行指導。預測結果表明,通過加工,原麥中的鎘含量呈整體下降趨勢。但是,在清理和潤麥的環節,鎘含量會略有上升。由預測模型可知,如果原麥的鎘含量滿足GB 2762—2017要求,即小麥中的鎘含量不高于0.1 mg/kg,則經過加工的成品小麥粉基本滿足GB 2762—2017的要求。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
