基于Hadoop的學習行為數據云存儲平臺的設計與實現
2022-10-10 01:23:26蔡春花黃思遠高繼梅
軟件工程 2022年10期
蔡春花,黃思遠,高繼梅
(黃河交通學院,河南 焦作 454000)
1 引言(Introduction)
在當下為數不多的云存儲相關技術中,Hadoop的HDFS(Hadoop Distributed File System)文件系統是所有互聯網公司中使用最廣泛的分布式文件系統。HDFS是Google在2003 年提出的GFS(Google File System)的一個開放源碼的實現,不過在Google的設計中,為了降低數據存儲與數據管理的耦合,GFS僅對數據的存儲負責而不提供類似數據庫查詢的方案。也就是說,GFS只存數據,而對數據的具體內容一無所知,自然也就不能提供基于內容的檢索功能。所以,更進一步,Google開發了Bigtable作為數據庫,向上層服務提供基于內容的各種功能,而HBase是Bigtable的實現。與原始的存儲模式相比,云存儲具有訪問方便、可靠性高、成本低、可擴展性好等優點。目前,云計算技術在中國的應用已經從幾年前僅在國家高端領域推廣到民用技術等領域,云存儲已成為未來存儲的趨勢。由于一些相關云存儲技術的開源性質,云存儲的應用領域變得越來越廣泛。云存儲所用的存儲結構不同于傳統的網絡體系,隨著科技的發展,它將會取代傳統模式的存儲數據的方法。
在線學習行為的日志數據如學生登錄、瀏覽資源、點擊課件等操作產生的日志數據來源于在線學習平臺,平臺上的日志數據將會依據不同的數據格式,分別存儲于與之對應的數據庫中。首先,網站中每天都可能產生較多關于學習者觀看視頻、學習課程等的日志數據;其次,學習平臺的數據需要進行保留(至少保留一年時間),以供跨年數據的分析及對比;而HDFS在Hadoop技術體系中負責分布式存儲數據,一個文件存儲在HDFS上時會被分成若干個數據塊,每個數據塊分別存儲在不同的服務器上,因此HDFS解決了存儲容量以及數據安全的問題。
2 云存儲平臺設計(Design of cloud storage platform)
2.1 存儲集群規模及服務的規劃
云存儲業務主要面向海量數據和文件的存儲和計算,強調單節點存儲容量和成本,因此配置相對廉價的串口硬盤,滿足成本和容量的需求。
測試環境為了控制成本,采用虛擬化技術虛擬出三臺Linux服務器構成集群,主機名分別設為Hadoop101、Hadoop102、Hadoop103,集群配置Hadoop101 CPU核心數4,磁盤空間50 GB,內存大小8 GB;Hadoop102 CPU核心數2,磁盤空間50 GB,內存大小4 GB;Hadoop103 CPU核心數2,磁盤空間50 GB,內存大小4 GB。
集群服務規劃:Hadoop101部署的服務有NameNode、DataNode、QuorumPeerMain、HMaster、HRegionServer、SecondaryNameNode;Hadoop102部署的服務有DataNode、QuorumPeerMain、HRegionServer;Hadoop103部署的服務有DataNode、QuorumPeerMain、HRegionServer、SecondaryNameNode。
2.2 請求處理系統設計
云存儲平臺是指Spring Boot應用服務器,可以為用戶直接提供服務,比如進行文件的上傳或下載。基于Hadoop的學習行為數據云存儲平臺用戶功能模塊主要包含用戶注冊登錄、文件操作、用戶關注和文件分享等。用戶功能模塊如圖1所示。
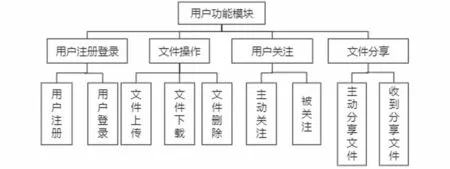
圖1 用戶功能模塊框架圖Fig.1 Framework diagram of the user function module
2.3 HBase數據表設計
傳統關系型數據庫是可以支持隨機訪問的,但關系型數據庫卻不能很好地適用于存儲海量的數據,比如關系型數據庫MySQL,單表在存放約500萬條的數據時,性能會大大降低。在這種情況下,必須有一種新的方案來解決海量數據存儲和隨機訪問的問題,HBase就是其中之一,HBase的單表可存儲百億級的數據且不影響查詢效率。
HBase的表結構設計與關系型數據庫有很多不同,主要HBase有行鍵(Row Key)和列族(Column Family)、時間戳(Time Stamp)這幾個全新的概念,如何設計表結構就非常重要。HBase就是通過Table、Row Key、Column Family、Time Stamp確定一行數據。這與MySQL、Oracle等關系型數據庫管理系統(Relational Database Management System,RDBMS)完全不同。大數據云存儲平臺涉及的主要表有file表、id_user表、user_file表和share表等。
在設計HBase列族時,使用文件的編號(Identity Document,ID)來作為每一個行鍵,使用file來當列族,只設計一個列族,file中包含的各種字段都是該列族的列,使用Row Key和Column Family可以確定一個存儲單元(Cell),使用Time Stamp可以確定最新版本,如表1所示。

表1 文件表Tab.1 File table
3 云存儲平臺實現(Implementation of cloud storage)
3.1 云存儲平臺的搭建
(1)Hadoop集群的安裝及配置
假設已經配置好服務器集群的靜態網址,并且Java開發環境都配置正確,集群之間可以進行免密登錄。下面對Apache Hadoop的具體實現步驟做簡要闡述。
第一步,在Apache Hadoop的官方文檔中下載Apache Hadoop3.1.3的安裝包到hadoop101,并解壓到/opt/app/hadoop,再將Hadoop添加到環境變量中。
第二步,在HADOOP_HOME下的etc/hadoop中修改hadoop-env.sh配置文件,其中添加JAVA_HOME的路徑。
第三步,在HADOOP_HOME下的etc/hadoop中修改core-site.xml配置文件,添加NameNode的地址hadoop101:8020,并指定Hadoop數據的存儲目錄。
第四步,在HADOOP_HOME下的etc/hadoop中修改hdfs-site.xml配置文件,指定NameNode的網頁端訪問地址為hadoop101:9870,指定SecondaryNameNode的WEB端訪問地址為hadoop103:9868。
第五步,在HADOOP_HOME下的etc/hadoop/workers中添加節點,共三行,分別是hadoop101、hadoop102、hadoop103。
第六步,分發Hadoop和環境變量配置文件到hadoop102、hadoop103。
至此,Hadoop集群的安裝及配置已經完成,可以使用sbin/start-dfs.sh來啟動HDFS集群,在瀏覽器訪問hadoop101:9870,可以查看Hadoop集群的節點狀態。
(2)Zookeeper集群的安裝及配置
Zookeeper的作用在前文已經介紹過,這里是Zookeeper的集群安裝和安裝過后的配置過程。下面對Apache Zookeeper的具體實現步驟做簡要闡述。
第一步,在Apache Zookeeper官方下載Apache Zookeeper3.5.7的安裝包,并上傳到hadoop101,解壓到/opt/app/zookeeper,再將Zookeeper添加到環境變量中。
第二步,將ZOOKEEPER_HOME/conf/下的zoo_sample.cfg文件重命名為zoo.cfg,并在其中添加Zookeeper的數據存儲路徑,存放在ZOOKEEPER_HOME/zkData,添加hadoop101、hadoop102、hadoop103的Zookeeper監聽地址。
第三步,在ZOOKEEPER_HOME下創建zkData文件夾,并在zkData文件夾下創建myid文件,并寫入序號1。
第四步,分發Zookeeper到hadoop102、hadoop103,并修改myid文件為不同的ID序號,在hadoop102中寫入2,在hadoop103中寫入3,保證ID序號不同即可。
至此,Zookeeper集群的安裝及配置已經完成,可以使用bin/zkServer.sh start命令進行Zookeeper服務的啟動,要注意的是需要在三臺服務器上都運行該命令。啟動完成后可以使用bin/zkServer.sh status查看Zookeeper是否啟動成功。
(3) HBase集群的安裝及配置
下面對Apache HBase的具體實現步驟做簡要闡述。
第一步,在Apache HBase官方下載Apache HBase2.0.5的安裝包,并上傳到hadoop101,解壓到/opt/app/hbase,再將HBase添加到環境變量中。
第二步,在HBASE_HOME/conf下的hbase-env.sh配置文件中將HBASE_MANAGES_ZK的屬性值設置為false,代表使用我們自己配置的Zookeeper集群而不是使用HBase自帶的Zookeeper。
第三步,在HBASE_HOME/conf下的hbase-site.xml中添加HBase的數據在HDFS存儲的位置,并指定HBase以分布式的方式工作,再指定使用自己的Zookeeper集群。
第四步,在HBASE_HOME/conf下的regionservers中添加三行記錄,分別為hadoop101、hadoop102、hadoop103,代表HBase節點。
第五步,分發HBase到hadoop102、hadoop103。
至此,HBase集群的安裝及配置已經完成,可以使用bin/start-hbase.sh來啟動HBase集群,并且可以使用瀏覽器訪問hadoop101:16010查看HBase集群的狀態。
3.2 請求處理系統
用戶進行成功注冊驗證后,使用正確的信息即可登錄到系統。在Controller層進行用戶認證后如果用戶信息沒問題,那么即可放行用戶進入平臺,如果用戶信息不正確,會提示用戶。
其中文件分享部分關鍵代碼:

關注某用戶關鍵代碼:


4 性能測試(Performance testing)
4.1 HBase庫億級大數據查詢性能測試
在云存儲平臺HBase的所有表中,只有與文件file相關的表的數據會比較大,因此只需對file表進行性能測試。下面對查詢性能測試步驟做簡要概述。
第一步,模擬生成file表的1 個列族,10 列字段,目標數據量1億多條。
第二步,使用Java客戶端連續根據Row Key查5 條記錄,將查詢耗時記錄下來,得到表2。

表2 HBase查詢性能測試Tab.2 Tests of HBase query performance
通過表2可以看出,使用Row Key進行查詢時,初次查詢較慢,需要 8 秒左右的時間,但之后查詢很快,基本可以做到百毫秒級查詢。當然,測試環境配置不高,如果在5 個節點,16核CPU,128 GB內存的配置下可以實現幾十毫秒甚至幾毫秒級查詢。這得益于HBase適合存儲PB級別的海量數據(百億千億量級條記錄),能在幾十到百毫秒內返回數據,并且不會因為數據量的劇增而導致查詢性能下降。
4.2 Hadoop集群性能測試
(1)寫性能I/O測試
使用Hadoop自帶的基準測試工具進行HDFS寫性能I/O測試,運行如下命令hadoop jar/opt/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-3.1.3-tests.jar TestDFSIO-write-nrFiles 10-fileSize 128 MB,其中向HDFS寫入10 個128 MB的文件,測試結果如圖2所示。

圖2 HDFS寫性能測試圖Fig.2 Test plot of HDFS write performance
如圖2所示,向HDFS寫入了10 個文件,一共處理1,280 MB的數據,每秒的吞吐量為73.64 MB,平均I/O速率為91.73 Mb/s,執行時間為20.63 s。
(2)讀性能I/O測試
接下來進行HDFS讀性能測試,使用Hadoop自帶的基準測試工具,運行如下命令hadoop jar/opt/app/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-clientjobclient-3.1.3-tests.jar TestDFSIO-read-nrFiles 10-fileSize128 MB,其中讀取HDFS的10 個128 MB的文件,測試結果如圖3所示。

圖3 HDFS讀性能測試圖Fig.3 Test plot of HDFS read performanc
如圖3所示,向HDFS讀取了10 個文件,一共處理1,280 MB的數據,每秒的吞吐量為147.13 MB,平均I/O速率為348.56 Mb/s,執行時間為19.48 s。
5 結論(Conclusion)
本論文重點研究以Hadoop和HBase集群實現的大數據云存儲平臺,成功實現了一個自動化、高效率的大數據云存儲平臺。各部分的功能都能實現后,搭建合適的環境進行功能的測試,通過測試結果可見各模塊的功能需求可以滿足使用條件,可用性很高。
在平臺高峰時請求量非常大,如果不進行“流量削峰”,服務器可能因無法承受而宕機,因此接下來可使用Kafka來進行“流量削峰”。在存儲成本方面,盡管存儲設備都是低廉設備,但是由于備份機制,存儲成本也需要進一步控制。因此在接下來的平臺版本升級中,會使用壓縮技術對文件進行壓縮,并且對不同用戶的相同文件進行“文件指紋技術”,對于重復文件只保留一份。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
財經(2016年15期)2016-06-03 07:38:02
商用汽車(2016年4期)2016-05-09 01:23:12
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
