大數據驅動下的智慧醫療服務系統設計
2022-10-10 01:23:28李勝旭
軟件工程 2022年10期
李勝旭,王 穎
(福建中醫藥大學人文與管理學院,福建 福州 350122)
1 引言(Introduction)
近年來,大數據、云計算、人工智能等新技術發展迅速,大數據和云計算作為信息化建設的新理念、新方向在不同的領域得到了研究人員的廣泛關注。在醫療大數據環境下,傳統的醫療模式對數據的處理滯后,已經不能適應新時代醫療信息化發展的形勢及任務發展的要求,如何將云計算技術與大數據服務相結合,將兩者引入智慧醫療建設,已成為當前智慧醫療是否實現轉型升級的重大機遇。
將大數據、云計算和智慧醫療三者結合起來進行,實現醫療信息化的研究,是擺在科研人員面前的一個新的高度。首先,醫療大數據中蘊含著巨大的有價值的信息,如何提煉挖掘出這些有價值的信息,對智慧醫療的發展有很大的促進作用。比如對醫療大數據中的病歷,利用文字搜索的技術、自然語言理解的技術、數據挖掘的技術進行對比、歸納、分析,為我們的醫生提供智慧提示、提醒和建議,提高醫生的診療水平;其次,醫療數據的大規模快速擴張,要保證這些數據可以被安全、可靠、高效地存儲和讀取,同時還需要有“彈性”擴張的存儲機制,而傳統的計算機架構方式牽制著數據存儲能力,特別是大數據處理能力,無法適應新技術發展需求,云計算中采用的相關存儲技術為大數據的存儲提供了有力手段。通過云計算進行醫療架構整體部署、數據的集約管理,最終達到提高整個醫療系統資源的利用率,減少設備重復投入,降低了系統運營成本;最后,實現在大數據環境下的數據分析,特別是某些疾病的數據分析,把這些分析后的數據提供給醫療機構和醫生,將其作為參考數據,在沒有與病人“面對面”接觸的情況下,通過對這些數據的分析,可以給政府、醫療機構提供合理的醫療資源分配決策。本文為了解決將云計算和大數據技術引入智慧醫療建設存在的不足,提出在部署建設中的幾種算法及構想,這些算法構想的提出對提升現代醫學信息化發展新理念、新技術及新模式有很好的參考借鑒作用。
2 大數據下智慧醫療數據管理(Smart medical data management based on big data)
大數據驅動的智慧醫療云平臺涉及大量數據的處理,以及針對醫療行業的科學研究模型。本文主要從兩個方面進行分析。
2.1 醫療數據采集和清洗規則、數據倉庫與接口規范研究
醫療大數據的數據來源非常廣泛,各類臨床醫療數據有的以結構化數據的形式存放在關系型數據庫中,但有的卻以半結構化或非結構化數據的形式存放在文件系統中,而且這些數據可以隨時更新訪問。因此,需要制定對應的數據倉庫技術(Extract Transform Load,ETL)進行數據采集,以及整合各類碎片化的方法,還要對這些數據進行清洗,淘汰數據干擾,保證數據質量,以防止后期在數據分析中的困擾。同時由于醫療領域本身的特性,每時每刻要根據時間推進不斷更新數據狀態,及時判斷數據實體情況,做到將各種各樣數據按照統一的格式進行存儲,以方便提供給上層后臺人員進行有效的數據分析,減少干擾。本文提出大數據收集模塊方法,首先基于Sqoop開發ETL模型,通過這個方法實現統一的結構化數據從關系型數據庫到Hadoop平臺的遷移;其次提出采用基于Hadoop Common開發的半結構化數據、非結構化數據的傳輸功能。
數據倉庫對外統一的數據接口規范研究,包括接口格式、使用語言、負載均衡設計等內容。通過其他研究人員提出的觀點,采用基于Hadoop的云中間件技術在智慧醫療上的研究,可以對建立智慧醫療系統提供有效的大數據支撐。另外為了增強云平臺能力的性能,再引入部分針對醫療信息處理的新組件,最終達到采集海量用戶的生理參數、實現資源合理分配、有效存儲在各種介質,有針對性地分析展示數據。在數據存儲部分,引入了分布式文件系統和分布式緩存數據庫,同時支持傳統的關系型數據庫。
2.2 醫療大數據存儲管理模塊的設計
醫療大數據存儲和管理模塊的建立同樣需要滿足數據倉庫設計的要求,建立一個既面向主題,又具有集成性的且能夠基于時間變量與決策支持的數據倉庫。本文采用圖1設計的基于Zookeeper的分布式Redis框架來滿足醫療大數據的存儲管理。
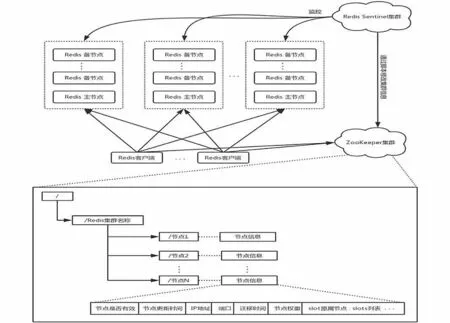
圖1 分布式緩存系統架構圖Fig.1 Architecture diagram of distributed cache system
圖1用于醫療數據處理系統,其設計思想是基于分層思路。它把整個框架分為數據層和服務層兩個不同的層次,數據層負責具體的Redis數據庫的實例,負責在服務層實現醫療業務服務和醫療數據封裝過程。ZooKeeper提供高效的負載均衡集群,提供高穩定性能的保障。ZooKeeper提供一致性服務,統一維護Redis集群的數據分片信息,客戶端通過ZooKeeper獲得Redis集群的數據分片信息并建立路由算法,實現醫療大數據Redis集群的動態擴縮容和數據自動遷移的能力,結合Redis-Sentinel,為每個Redis主節點配備若干個備節點,利用Redis備節點可以對Redis主節點進行數據同步復制,通過和Redis-Sentinel集群來保障Redis集群的可用性,同時通過ZooKeeper與客戶端通信來將后端Redis主節點和備節點的切換信息通知給客戶端,實現集群故障的自動轉移,保證Redis集群的高可用性。
3 智慧醫療服務數據挖掘分析及決策信息服務體系研究(Research on data mining analysis and decision-making information service system of smart medical service)
分布式緩存的存儲模塊建立之后,需要建立預測數據模型、關聯模型、服務模型的研究,設計結合智慧醫療應用所需及實際數據要求狀況,在海量的醫療數據中準確收集有效有用信息建立數學模型,并進行預測研究。系統面對用戶運維過程中,接收到的數據量以數量級形式呈現,數據量增加迅速,因此通過建立預測模型,可以在數據變化過程中就進行分析,及時對系統進行改變。最終產生的數據結果可以在醫療過程中或醫療后發揮作用,比如對某一個時期某些疾病是否有可能爆發進行預測判斷。針對新型冠狀病毒肺炎疫情發展的可能性,項目提出的方案可以對病毒的后期走向建立一種預測模型,給政府部門、醫療機構提供合理的參考價值。
在醫療大數據的分析中,將以醫院信息管理和醫療信息服務的應用為驅動,基于大數據系統框架模型和醫療專題數據模型,采用先進的數據分析方法,比如關鍵績效指標分析、聚類縫隙分析技術、數據多維分析技術、數據報表分析技術及數據儀表分析等,提供醫療大數據分析與決策信息服務。
大數據的分析算法和方法很多,結合醫療大數據的特點,特別是分析臨床醫學信息系統,研究其與臨床決策支持系統的關聯,建立基于醫療大數據的系統框架模型,研究支持PB級海量數據的、面向專題數據倉庫的高效、快速的數據存儲、數據索引及數據檢索方法。在大數據系統中,由于數據量龐大,高效、快速的數據存儲、數據索引及數據檢索在數據倉庫和大數據領域非常之重要,這種方法依靠良好的、優化的數據組織結構和相應的算法。一個優良的檢索技術對數據庫具有至關重要的作用,并且是衡量一個數據庫系統性能的重要指標。本文采用協同過濾算法來分析管理存儲在數據倉庫里的醫療大數據,通過算法設計基于HL7消息的推薦系統接口,最后通過HL7推薦消息使系統與電子病歷系統等院內其他信息系統實現應用的實時對接。
算法設計:首先,我們利用基于Sqoop的大數據收集模塊分布式地從各醫院信息系統中收集患者就診信息,截取其有效數據集組成用戶可信內容,并將這些可信的記錄收集過程轉換為一個三元組序列:
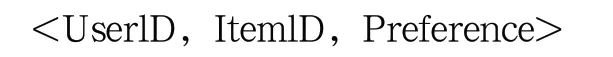
然后,我們使用若干相似度度量方式計算用戶之間的相似度,比如歐氏距離、皮爾遜相關系數和余弦相似度等。
歐式距離表示多維空間中兩個點的真實距離,其計算如式(1)所示:
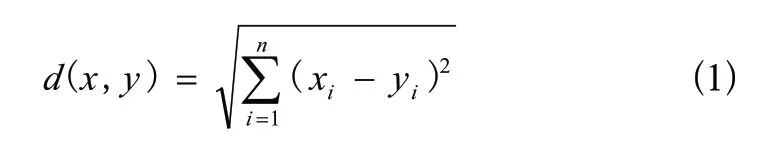
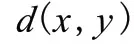
而用歐式距離表示的相似度則為式(2)所示:
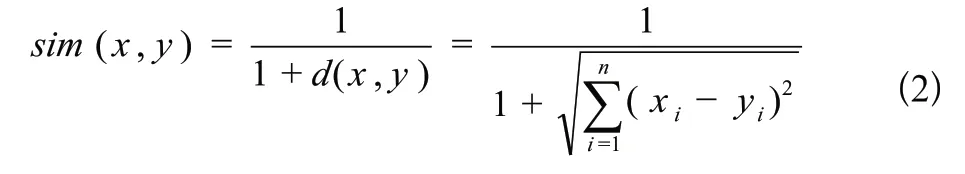
皮爾遜相關系數表示兩個三元組之間協方差和標準差之間的比率,其計算如式(3)所示:

通過皮爾遜相關系數衡量線性相關關系。若=0,說明與之間無線性相關關系。相關系數的絕對值越大,相關度越強;相關系數越接近于1或-1,相關度越強;相關系數越接近于0,相關度越弱。
相對于歐氏距離,余弦距離更關注兩個向量在方向上的差異。余弦相似度表述了向量空間中兩個三元組的向量值之間夾角的余弦值,通過計算的值來衡量兩者之間差異的大小,其計算如式(4)所示。
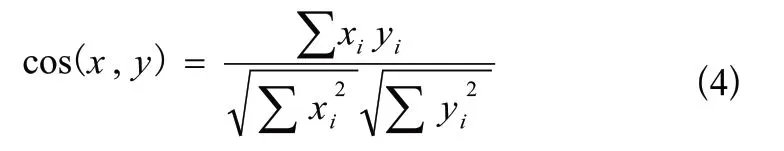
綜合上述幾種相似度計算方法,通過計算得到相似度度量值,應用在智慧醫療系統中來獲得毗鄰的用戶或者項目,也就是一種基于相似度門檻閾值的固定數量的鄰居。通過以上方法,設計了一種符合智慧醫療服務的數據挖掘及分析系統。算法代碼如下。


4 智慧醫療大數據云服務數據展示平臺(Data display platform of smart medical big data cloud service)
在智慧醫療領域,無論是病人、醫生或者管理人員,都期望把蘊藏在大數據背后對自己有價值的信息清晰地展示在面前,所以最終的數據如何展現出來是非常關鍵的。
通過分析智慧醫療云平臺的功能,數據展現主要有幾個方面:(1)醫療機構實時了解和掌握近期的醫療動態并調整目標。醫療大數據云平臺幫助各個醫療服務機構實現醫療資源共享共用,信息及時溝通、信息協同共享,共同為用戶實現不同的服務視圖,實現類型豐富的服務方式。另外也可以根據平臺提供的信息將一些醫療服務進行整合,構建一種新的服務模式,以便節約運行成本。(2)決策或政府部門對數據的需求主要通過豐富的各類報表、圖表及分析結果來滿足,這些數據要具有一定的說服力,在決策過程中提供數據支撐。(3)患者主要通過提供的數據綜合分析個人自身信息并進行預判斷,根據數據或信息選擇合適的醫生進行咨詢或者從平臺中得到指導、治療和參考,避免盲目的診療。(4)醫生也可以根據患者及平臺提供的數據分析病況,對患者規劃一個有針對性的治療目標,最終制定合適的治療方案。
因此大數據驅動下的智慧醫療服務系統設計的最后,是在智慧醫療云平臺的應用上能夠建立一個友好的交互。因此項目在智慧醫療應用層架構中,通過基于Zookeeper的分布式緩存框架來實現數據展示平臺,分布式緩存架構要及時準確快速地返回不同用戶的請求,根據用戶需要合理地提供查詢服務。
本文提出一種分布式發布訂閱消息隊列系統,實現針對醫療數據的多樣化處理方法,解決Hadoop無法實現即時查詢和交互設計的局限。即針對獲得的不同的醫療信息數據源,提出離線批處理與在線實時計算相結合的醫療數據處理策略,如圖2所示。
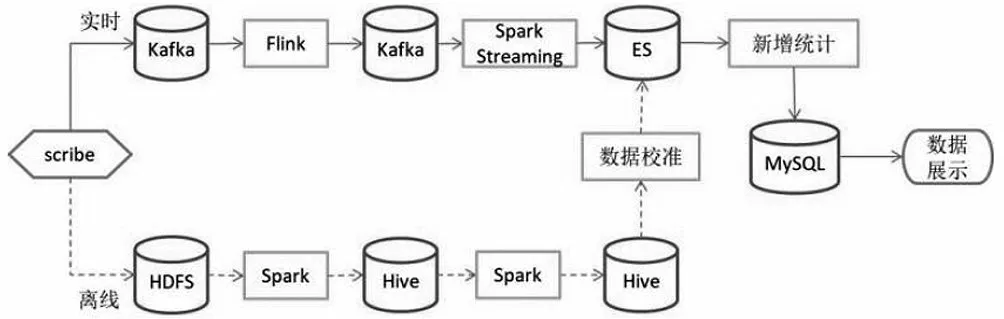
圖2 離線批處理和在線實時計算的數據處理策略Fig.2 Data processing strategies for offline batch processing and online real-time computation
為應對大量復雜的醫療大數據,盡可能降低處理延遲,實時計算部分采用了數據分層與分流相結合的技術路線,將數據計算流程拉長,采用單功能多階段的數據處理方式將數據處理拆分為三個階段:日志解析、產品分流和新增計算。在實時處理部分,采用了Flink和Spark Streaming相結合的方式。Flink是一種具有高吞吐、低延遲的實時離線統一的流式數據處理引擎,非常適合醫療大數據分析中第一階段的日志解析特點。而Spark Streaming是微批處理,可以將實時數據流輸入的數據劃分為一個個小批次數據流,保障后續新增計算中聚合操作穩定的分鐘級響應。為了將計算引擎的性能發揮到最大,將新增計算的延遲降到最低,
5 結論(Conclusion)
醫療云計算平臺系統其數據的復雜性及整個系統的彈性伸縮能力與傳統IT基礎設施的技術有很大的差別。醫療大數據挖掘處理需要云計算技術作為平臺,反之云計算技術也將計算資源作為一種服務支撐醫療大數據的有效挖掘,兩者相輔相成,相得益彰,提供了各自需求的有價值信息。對于云計算理論應用,本文提出了智慧醫療云服務體系結構設計模型及其工程實現方法,將多個差異的醫療服務組織及醫療資源聚集于醫療云中,構建一個多樣化、開放式、可伸縮、多用戶的智慧醫療云數字化生態環境。在大數據的挖掘中,根據醫療大數據的特點,設計算法實現數據分析,給后期工作者提供以下幾個方面的理論及實踐研究的參考。
(1)針對不同對象提供個性化服務
通過大數據采集與關聯技術,面向患者的分析結果提供具有針對性、個性化的服務方式;針對醫療機構及管理部門進行管理行為預測,提前發現可能出現的潛在問題。
(2)大數據環境下智慧醫療更加完善
在設計不同階段對他人的不足之處提出解決方案,并通過算法分析實現,提出的方法及算法節省了運維時間和空間,節省了硬件成本。
(3)智慧醫療云平臺的建立
智慧醫療云服務平臺重點解決平臺開放性、可持續擴展性以及服務之間松耦合的問題。在云平臺架構設計時考慮了可擴展性問題,不斷集成新的服務而不需要對整體架構做過多修改,最終建立智慧醫療云平臺時把其中的每個服務都看作一組服務接口的集合,達到服務之間松耦合,實現整體架構的開放和易擴展性。
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
今日農業(2019年12期)2019-08-15 00:56:32
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年16期)2019-01-03 11:39:20
電子制作(2018年18期)2018-11-14 01:48:24
商周刊(2017年9期)2017-08-22 02:57:56
山東工業技術(2016年15期)2016-12-01 05:31:22
小天使·一年級語數英綜合(2014年6期)2014-07-22 23:32:38
智慧與創想(2013年7期)2013-11-18 08:06:04
網球俱樂部(2009年9期)2009-07-16 09:33:54
