基于深度強化學習的室內視覺局部路徑規劃
2022-10-10 06:04:22朱少凱孟慶浩金晟戴旭陽
智能系統學報 2022年5期
朱少凱,孟慶浩,金晟,戴旭陽
(天津大學 電氣自動化與信息工程學院 機器人與自主系統研究所,天津 300072)
視覺導航是一類新興的導航技術,具有使用成本低、獲取信息豐富的優點,成為近些年來機器人領域的研究熱點之一[1-4]。路徑規劃是移動機器人實現自主視覺導航的關鍵技術之一,分為全局路徑規劃算法和局部路徑規劃算法[5]。常用的全局路徑規劃算法有A*算法[6]和D*算法[7]等。局部路徑規劃算法根據全局路徑和部分環境信息,輸出機器人運動控制指令,使機器人大致沿著全局路徑的軌跡移動。動態窗口法(dynamic window algorithm, DWA)作為一種廣泛使用的局部路徑規劃算法,具有良好的避障能力,且計算量小、實時性高,是機器人操作系統(robot operating system, ROS)的默認局部路徑規劃算法[8]。但是,當環境變得復雜時,DWA算法容易陷入局部極小值點,同時無法保證規劃出的路徑是最優的。時間彈性帶(timed elastic band, TEB)算法是另一種廣泛使用的局部路徑規劃算法,采用圖優化的方法迭代求解局部路徑規劃問題,有較高的操作性[9]。模型預測控制(model predictive control,MPC)能根據機器人當前的運動狀態預測其未來幾個時間步的軌跡,通過二次規劃方法來優化,求出一個最優局部路徑規劃解[10]。但是,TEB和MPC算法有非常多的參數需要設置,所以在復雜的環境應用時需要配備較高性能的計算機和花大量時間手工調參。綜上所述,傳統的局部路徑規劃方法存在參數調整耗時,缺乏對新環境的泛化能力等問題。此外,當與視覺SLAM協同工作時,傳統局部路徑規劃算法僅僅考慮機器人運動代價等因素,沒有考慮機器人在視覺SLAM過程中易在低紋理區域跟蹤丟失的問題,以上原因導致傳統局部路徑規劃算法應用于基于視覺SLAM的導航時表現較差。
深度強化學習自提出以來逐漸得到國內外學者的廣泛關注,其相關理論和應用研究都得到了不同程度的發展[11-12]。由于其“交互式學習”和“試錯學習”的特點,適用于很多問題的決策,已成為機器人控制領域的研究熱點,其中也包括局部路徑規劃任務。張福海等[13]以激光雷達作為環境感知器,并構造了基于Q-learning的強化學習模型,將其應用在了局部路徑規劃任務中,提高了移動機器人對未知環境的適應性。Guldenring等[14]利用激光雷達來獲取動態環境信息,并根據環境數據基于PPO的強化學習算法進行局部路徑規劃。Balakrishnan等[15]在A*全局路徑規劃算法基礎上,利用深度強化學習訓練了一種局部路徑規劃策略,以到達局部目標點。然而,該方法依賴于真實先驗地圖。Chaplot等[16]同樣訓練了一種基于深度強化學習的局部路徑規劃策略,并與全局策略相結合,以完成視覺探索任務。但是該方法依賴于真實先驗位姿。在實際的視覺導航任務中,機器人需要依靠視覺傳感器來獲取位姿和環境地圖。因此,如何合理地設計局部路徑規劃機制,使局部路徑規劃能夠和視覺SLAM方法更好地配合,最大限度地避免碰撞和位姿跟蹤丟失、提升導航成功率是這類方法的關鍵,也是至今仍未被探索的問題。
針對以上問題,本文在視覺SLAM和全局路徑規劃算法的基礎上,提出一種基于深度強化學習的室內視覺局部路徑規劃策略。該策略在強化學習PPO[17](proximal policy optimization)算法的基礎上,充分考慮了機器人避障、防止視覺SLAM跟蹤丟失以及機器人行走效率等多方面因素,設計獎勵函數和網絡結構,在大量的場景下學習最佳狀態-動作映射網絡,提高移動機器人導航成功率。既避免了部分傳統路徑規劃算法調參復雜的問題,又具有很好的泛化性,且與視覺SLAM模塊契合。最終,在三維物理仿真平臺 Habitat[18]中利用機器人對該局部路徑規劃策略進行相關仿真分析,證實了所提出策略的有效性。
本文的創新點主要包括:1)提出了一種基于深度強化學習的移動機器人室內視覺局部路徑規劃算法,合理地設計了環境交互機制與觀測的狀態空間; 2)研究了多樣的獎勵函數,加快了算法的收斂速度,提高了模型的性能,最大限度地避免了碰撞和位姿跟蹤的丟失、可盡快到達局部目標點。3)將局部路徑規劃模型融入總體導航框架,與視覺SLAM模塊、全局路徑規劃、仿真平臺相互配合,有助于長距離室內復雜場景下的點導航。
1 問題描述
機器人在室內導航的過程中,在低紋理區域易發生視覺SLAM跟蹤失敗現象。因此,考慮機器人快速接近局部目標點的同時,還要兼顧低紋理區域、障礙物等諸多不利因素對于視覺導航任務造成的影響。本文設計的局部目標點導航策略,可以實現規避障礙物、保證跟蹤穩定性以避免視覺SLAM失敗、成功到達局部目標點的目的。
局部路徑規劃策略是與視覺SLAM模塊、全局路徑規劃、仿真平臺相互配合的,它們的關系如圖1所示。首先,選用Habitat仿真平臺,機器人在該平臺中能以實體的形式存在。該平臺能實時地提供機器人在當前位置所采集到的彩色圖、深度圖,并實時檢測機器人是否發生碰撞等。對于每一個導航任務,仿真平臺會給定機器人的初始位置和機器人距離全局目標點的相對位置。其次,機器人通過視覺SLAM模塊與三維重建技術[19-21]得到室內三維環境的稠密點云地圖,然后將一定高度范圍內的點云投影之后,獲得用于導航的二維柵格地圖。此外,視覺SLAM模塊還能實時提供機器人在當前位置所采集到的ORB (oriented FAST and rotated BRIEF)特征點圖[22]并實時監測機器人當前的位姿跟蹤狀態(跟蹤正常/跟蹤丟失)。然后,在得到的二維柵格地圖基礎上,使用A*算法規劃全局路徑。局部目標點位置的確定依賴于全局路徑,如圖2所示,以機器人當前位置為圓心,半徑為r的圓與全局路徑的交點即為局部路徑規劃目標點。最后,局部路徑規劃策略的目標是使機器人從起點成功移動到局部目標點的位置,同時兼顧避障、避免跟蹤失敗的目的。在本文中,局部路徑規劃策略的輸入是當前時刻的觀測(包括:彩色圖、深度圖、特征點圖、當前位置與局部目標點之間的距離和方向),輸出是機器人當前時刻所采取的動作。訓練目標是避免發生碰撞和視覺SLAM跟蹤丟失的同時,采取盡量少的動作運動到局部目標點。當機器人到達局部目標點或機器人行動步數達到步數限制時,則開始規劃下一個局部目標點,以此循環,直到機器人到達全局目標點。當機器人在行走過程中發生碰撞或視覺SLAM跟蹤丟失時,則認為導航任務失敗。

圖1 總體導航架構Fig.1 Overall navigation framework
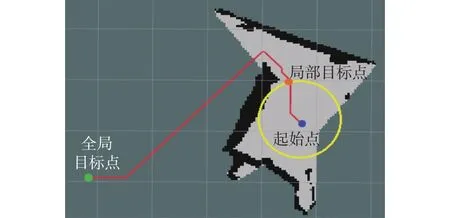
圖2 局部導航示意圖Fig.2 Schematic diagram of the local navigation
2 基于深度強化學習的路徑規劃
2.1 模型建立
大多數強化學習可以用部分可觀測馬爾科夫決策過程(POMDP)描述,POMDP用一個五元組(S,A,P,R,γ)來表示。其中S為機器人狀態空間,A為機器人動作空間,P為從一個狀態到另一個狀態的轉換概率,R為獎勵,γ表示折扣因子。常用演員-評論家(actor-critic, AC)算法來解決該部分可觀測的馬爾科夫決策問題。AC算法基于策略梯度方法,并通過最大化平均回報來直接更新策略。在執行策略參數 π時,累積每個時間步動作的預期獎勵來計算價值函數,如式(1)所示。隨后,按式(2)的貝爾曼方程迭代直至策略參數收斂至最優。
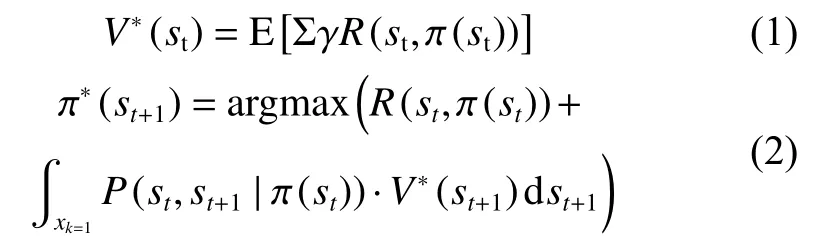
式(1)和(2)中,E為求期望函數,st代表t時刻機器人觀測狀態,R(st,π(st)) 為當前策略在狀態st下的獎勵值,V*(st)為最優狀態值函數,γ為折扣因 子。P(st,st+1|π(st))為狀態轉移概率。對于從狀態st可以到達的任何狀態st+1, π′′(st+1)為能夠使得狀態st+1獲得最優價值的策略。
2.2 框架設計
深度強化學習中,智能體(Agent)負責與環境交互,是算法的應用對象。外部環境(Env)是客觀存在,用于制定獎懲規則和交互機制。本文將局部路徑規劃問題轉換到深度強化學習的框架中進行求解。在交互過程中,需要定義相應的接口標準,主要有step、reset、render 3個函數。
1) step函數:負責制定Agent與Env的交互機制和獎懲規則,在基于深度強化學習的局部路徑規劃策略根據當前狀態si求解出動作a1后,該函數能夠返回執行a1后的獎勵ri,以及是否結束的標志位done。此外,該函數能返回下一時刻的狀態st+1。該函數是將局部路徑規劃問題轉換到深度強化學習問題的關鍵,是算法設計中最重要的函數, (si,at,rt,si+1,done)構成了局部路徑規劃策略訓練所需要的基本數據單元。
2) reset函數:定義一個回合(episode)為Agent與Env的一次完整交互。Agent通過與Env多次交互積累經驗,從而學到好的局部路徑規劃策略。回合結束的判斷標志位為done,當其為True時,回合結束。此時,Agent和Env需要通過該re-set函數重新初始化,開始新一輪的交互。為了保證Agent和Env的可持續性交互,回合結束在機器人到達局部目標點、發生碰撞、視覺SLAM跟蹤失敗、到達每回合的最大步數限制時觸發。
3) render函數:局部路徑規劃策略需要與視覺SLAM模塊、全局路徑規劃、仿真平臺相互配合。為了便于算法調試,使用render函數來輸出可視化窗口顯示機器人當前的狀態及所處環境,如彩色圖(RGB)、深度圖(Depth)、全局地圖、路徑規劃等。
step函數、reset函數、render函數構成了Env部分。step函數負責Agent與Env之間的交互,其中嵌套了負責重置的reset函數和負責顯示功能的render函數。
2.3 可觀測狀態與獎勵函數設計
step函數是基于深度強化學習的局部路徑規劃策略實施的重點,其中涉及到兩個關鍵問題:一是如何描述可觀測狀態空間,另一個是如何設計獎勵函數。前者反映了機器人在局部路徑規劃的實施過程中需要注意的環境信息,后者能指導局部路徑規劃策略向目標方向更新。
在機器人的局部路徑規劃任務中,Agent所能觀測到的狀態S來源于自身所裝備的RGB-D相機以及視覺SLAM模塊,具體可用一個五元組(srgb,sdepth,sdis,sangle,smpt)來表示。其中srgb和sdepth來源于RGB-D相機,分別表示彩色圖和深度圖;sdis表示機器人與局部目標點的相對距離,計算方法如式(3)所示;sangle為機器人當前朝向角與機器人和局部目標點連線角度的差值,設機器人在二維柵格地圖上的坐標為(x1,y1),朝向角為β,局部目標點坐標為(x2,y2),sangle計算方式如式(4):
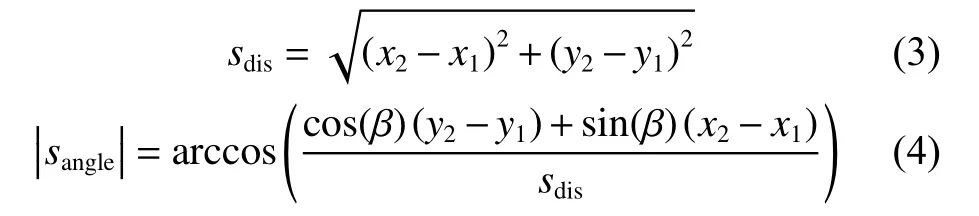
smpt為采樣時刻當前幀的特征點圖的位置矩陣,包含了特征點在圖像幀上的位置和數量信息。在ORB-SLAM2[23]算法中,ORB特征點的匹配是實現前端視覺里程計的基礎,特征點在圖像中的位置和數量包含了視覺SLAM跟蹤穩定的信息。如圖3所示,圖3 (b)由圖(a)采樣位置向左旋轉30°后得到。在圖3(a)所示采樣位置視覺SLAM跟蹤成功,在圖3(b)所示采樣位置則跟蹤丟失。由圖3(a)可知,特征點集中于右半部分,左半部分特征較為稀疏,相機此時左轉視覺SLAM跟蹤失敗的風險較高。定義動作空間A(al,af,ar),其3個元素分別代表機器人左轉、前行和右轉3個動作,每個動作執行時間為1 s,左轉和右轉的角速度為0.3 rad/s, 前進速度為0.1 m/s。

圖3 ORB特征點跟蹤圖Fig.3 Pictures of ORB feature point tracking
充分考慮了機器人避障、防止視覺SLAM在低紋理區域跟蹤丟失以及機器人行走效率等多方面因素,把獎勵函數分為6個部分。其中,避障、距離、視覺SLAM的獎勵函數部分分別用robv、rdis、rslam表示,λ1、λ2、λ3為相應部分獎勵的系數。該3部分獎勵函數已能夠滿足點導航的基本需求。然而,由于算法初期網絡訓練不充分,機器人在面對障礙和低紋理區域時會選擇錯誤的動作導致碰撞、跟蹤失敗。在很多次試錯之后,PPO算法的Actor網絡才會在面對障礙時選擇正確的動作,此時算法才開始收斂。所以僅依靠上述3部分的獎勵函數訓練局部路徑規劃算法會存在訓練時間長、算法收斂速度慢的缺點。為了加快算法收斂速度,提高模型性能,本文又設計了角度、特征點數及到達局部目標點的獎勵,分別使用rangle、rnmpt、rbonus表示,λ4、λ5、λ6為系數。為方便表示,ssts表示機器人運行狀態,其值域為{0,1,2,3},分別表示機器人正常運行、碰撞、視覺SLAM跟蹤丟失和到達局部目標點。
1) 避障
避障是導航的基本要求,機器人撞到障礙物就意味著本次導航任務的失敗,機器人運動過程發生碰撞,會產生一個較大的負值獎勵。具體設計如式(5):

2) 距離
導航過程中需要逐步減小與局部目標點的距離,故根據執行當前策略動作后與局部目標點距離的變化量設計相應獎勵函數。設當前時刻機器人坐標為(xt,yt),執行當前策略得出的動作at后坐標為(xt+1,yt+1),局部目標點坐標為(xd,yd)。可以簡單在笛卡爾坐標系上計算得到執行動作后,距目標點的距離變化量為
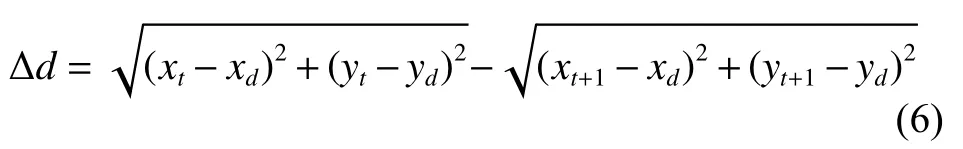
對應的獎勵函數為

3) 視覺 SLAM 跟蹤
在訓練過程中,若機器人視覺SLAM跟蹤穩定運行,執行某一動作后,若視覺SLAM跟蹤能保持運行,不給予獎勵,若執行動作后跟蹤丟失,則導航失敗,給予一個較大的負值獎勵,即如式(8)所示:

4) 角度
正確的導航方向是機器人能到達目標點的前提,為防止機器人在調整方向時出現獎勵稀疏的問題,根據機器人動作執行前后其與局部目標點的相對角度的變化量給予獎勵。設當前時刻機器人與局部目標點的相對角度為αt,執行當前策略得出的動作后變為αt+1,對應獎勵為

5) 特征點數
本文使用的ORB-SLAM2算法進行同時定位與建圖。對ORB特征點的數量與視覺SLAM具有很強的關聯性,當前幀中的特征點數高于一定數量時,視覺SLAM跟蹤丟失的風險很低,而低于一定數值時,跟蹤丟失的風險將會急劇上升。設執行動作前后,當前幀ORB特征點的數量分別為nmptt和nmptt+1,則對應獎勵為
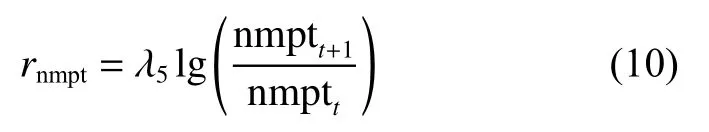
6) 達成目標獎勵
為了使局部路徑策略更快向局部目標點收斂,在訓練過程中,若機器人順利到達局部目標點,意味著當前策略更加接近目標策略,給予額外的正獎勵值,加快算法的訓練速度,故設計如式(11)所示獎勵函數。

綜上,綜合獎勵函數為
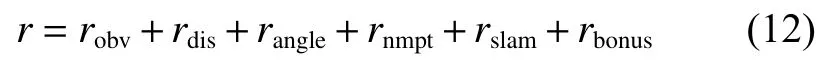
2.4 PPO算法
本文采用PPO算法來訓練局部路徑規劃算法,這是一種基于策略梯度的算法,采用Actor-Critic架構集成了雙網絡的算法結構,并改進了基于置信域策略優化的強化學習算法[24](trust region policy optimization, TRPO)的步長選擇機制。與TRPO算法相比,PPO算法計算復雜度更低,算法的訓練速度更快,可實施性更強。算法的基本框架如圖4所示。

圖4 基于Actor-Critic框架的PPO算法示意圖Fig.4 Schematic diagram of PPO algorithm based on Actor-Critic framework
基于Actor-Critic框架的PPO算法包含Actor和Critic雙網絡。Actor網絡負責生成策略,其網絡參數為 θA。Critic網絡通過計算優勢函數An來評估當前策略,其網絡參數為θc。Actor網絡目標函數如式(13)所示。
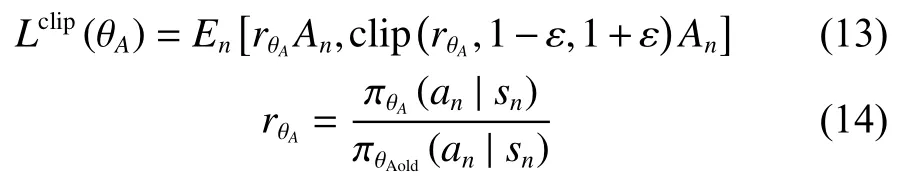
式中:clip為剪切函數,ε為剪切參數;ε為n次采樣的期望函數。 πθA(an|tn)是待優化的策略網絡,πAold(an|sn)為當前用于收集數據的策略網絡,通過重要性采樣來估計新策略。兩者比值越接近1,說明新舊策略更新偏移越小。更新過程中,PPO算法利用式(13)中的剪切函數來限制策略的更新幅度。當新舊策略更新偏移量過大時,使用剪切項代替,這樣確保新舊策略的偏離程度不至于太大,讓Actor網絡以一種相對平穩的方式進行更新,收斂速度更快。
Actor網絡根據當前狀態生成機器人當前動作,機器人執行當前動作后產生新狀態并獲得獎勵為一次完整交互過程,按訓練批次的大小將多次交互數據進行存儲,用于更新Actor網絡和Critic網絡,獲得相對最優的網絡參數。
2.5 網絡結構
PPO算法包含了Actor和Critic兩個神經網絡。Actor網絡結構如圖5所示,整個網絡包含了一個Resnet18網絡[25],4個全連接層(fully connected,FC)和一個Softmax層。PPO算法的觀測狀態空間為S(srgb,sdepth,sdis,sangle,smpt),RGB 圖像srgb、深度圖像sdepth及ORB特征點圖矩陣smpt整合而成的640×480×5的張量,作為Resnet18網絡的輸入,sdis和sangle分別作為全連接層的輸入,三者均輸出一維的向量,將其輸出進行拼接(Concat),后接兩個全連接層和一個Softmax層,輸出PPO算法動作空間中的動作。Actor網絡的參數設置如表1所示,Critic網絡結構及參數與Actor網絡大致相同,FC4層作為輸出層,輸出一維數據,用來估計狀態價值函數。
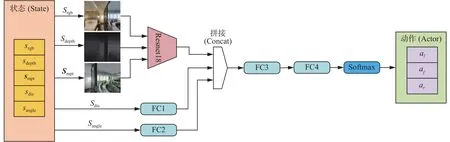
圖5 Actor網絡結構Fig.5 Actor network structure

表1 網絡參數設置Table 1 Network parameters setting
3 仿真結果與分析
3.1 實驗環境及參數設置
仿真所使用硬件平臺為一臺CPU型號為Intel Core i9-10900X,內存為64 GB,顯卡類型為NVIDIA RTX 3090的臺式機。軟件方面裝有:Ubuntu 18.04系統、python 3.6版本,Pytorch 1.7.1版本,ROS Melodic版本。仿真器使用Facebook公開的室內仿真平臺Habitat[18]。訓練集采用Gibson數據集,包含72個不同場景。算法在與訓練集不同的3個 Gibson數據集[26]場景{Edgemere、Eastville、Mosquito}中測試,每個場景均包含71個導航任務。{Edgemere、Eastville、Mosquito}場景中導航任務的平均最短路徑距離[26](geodesic distance along the shortest path, GDSP)分別為 3.24 m、7.51 m、10.84 m,可分別代表簡單、中等和困難3種場景,如圖6所示。可以看到,Edgemere場景的布局相對最簡單,Mosquito場景的布局相對最復雜。

圖6 導航地圖可視化Fig.6 Navigation map visualization
仿真過程中,局部路徑規劃策略的訓練相關參數如表2所示。本文選擇前進動作時,距離變化為0.1 m,選擇轉向動作時,角度變化為0.3 rad。為了使機器人快速接近局部目標點,需先快速調整航向角,再向局部目標點快速移動,可通過設計獎勵函數,使得角度獎勵比距離獎勵略大。因此,距離獎勵系數和角度獎勵系數可根據經驗分別設置為20和40。如2.3節所述,本文在設計特征點獎勵函數部分時采用以10為底數的對數函數。在實驗過程中,可注意到機器人在紋理較豐富的區域時,圖像幀中的特征點數變化幅度不大,大概在850~950。而機器人在由紋理較豐富的區域向低紋理區域運動時,相鄰幀之間的特征點變化幅度較大,比值 n mptt+1/nmptt大概在1.3~1.8。因此,特征點獎勵系數可根據經驗設置為80。此外,本文將碰撞和跟蹤失敗時的獎勵值設為-30,以此降低導致碰撞和跟蹤失敗的動作選擇概率。為了提高正常到達局部目標點的動作選擇概率,本文將順利到達局部目標點的額外獎勵設為80。
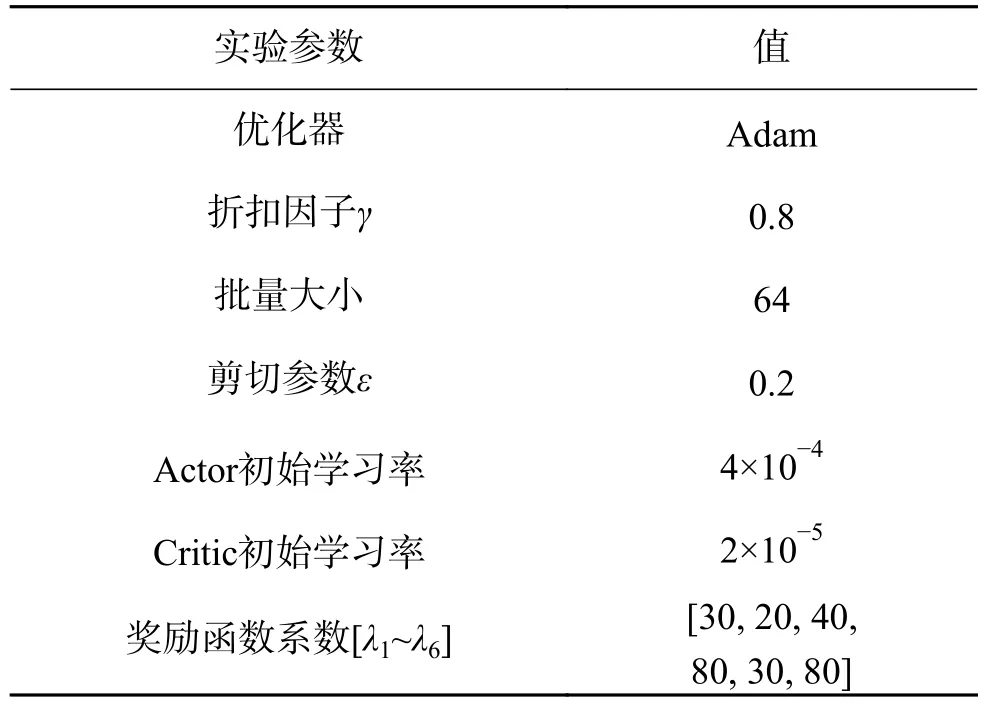
表2 算法訓練參數Table 2 Algorithm training parameters
3.2 結果及分析
為了證明所述方法的有效性和優越性,對比了DWA、TEB、MPC算法和路徑跟隨(path follower, PF)算法。DWA、TEB、MPC算法是ROS系統中默認的局部路徑規劃算法,可作為很好的比較基準;PF算法是文獻[27]中提到的一種路徑跟隨算法,算法基于PID的離散控制實現機器人沿著規劃出的全局路徑行走。在行走過程中,若機器人沒有面朝局部目標點(當前位置與局部目標的朝向角超過15 °),則執行左轉或右轉以縮小自身朝向角,否則執行前進動作。當機器人與全局目標點的距離小于0.2 m時,則認為一個導航任務成功。
本文計算了相應的成功率(success rate, SR)、跟蹤丟失率(tracking failure rate, TFR)、碰撞率(collision rate, CR)。表3~5分別給出了使用不同方法在Edgemere、Eastville和Mosquito 3種場景任務中的平均結果對比。可以得到以下幾點結論:
1) PF算法在所有場景任務中表現都相對較差,這是因為該算法僅僅沿著規劃出的全局路徑行走,沒有考慮如何避障。當全局路徑附近存在障礙物時,該算法很難避免發生碰撞。因此,在所有場景的任務中,該算法的平均碰撞率均是最高的。
2) DWA、TEB、MPC算法運行時需要載入局部地圖,根據參數對行走軌跡進行采樣,選擇運動代價最小的軌跡。因此,DWA、TEB、MPC算法在進行視覺導航時具有一定的避障能力。但是,DWA、TEB、MPC算法沒有考慮機器人在視覺SLAM過程中易在低紋理區域跟蹤丟失的問題,無法保證跟蹤的穩定性。因此,在3個場景的任務中均會發生較高的跟蹤丟失率。
3) 所提出的方法在所有的場景任務中都取得了最好的性能,可以在室內雜亂環境中也能較好完成導航任務。具體來說,本文所述方法在所有場景任務中相比于傳統的路徑規劃算法的平均成功率提高了53.9%,位姿跟蹤丟失率減小了66.5%,碰撞率減小了30.1%。這說明相比于傳統的局部路徑規劃方法,本文所提出的方法能夠實現到達局部目標點的同時,更好地規避障礙物,并保證跟蹤穩定性。
4) 在表3~5中,本文所提出的方法在Edgemere場景任務中表現最好,在Eastville場景任務中表現次之,在Mosquito場景任務中表現相對較差。這是因為Mosquito場景的面積相對更大,包含了多個房間和障礙物,導航任務也相對較難,起點與終點距離較長。而Edgemere場景的面積相對較小,僅包含一個臥室和衛生間。
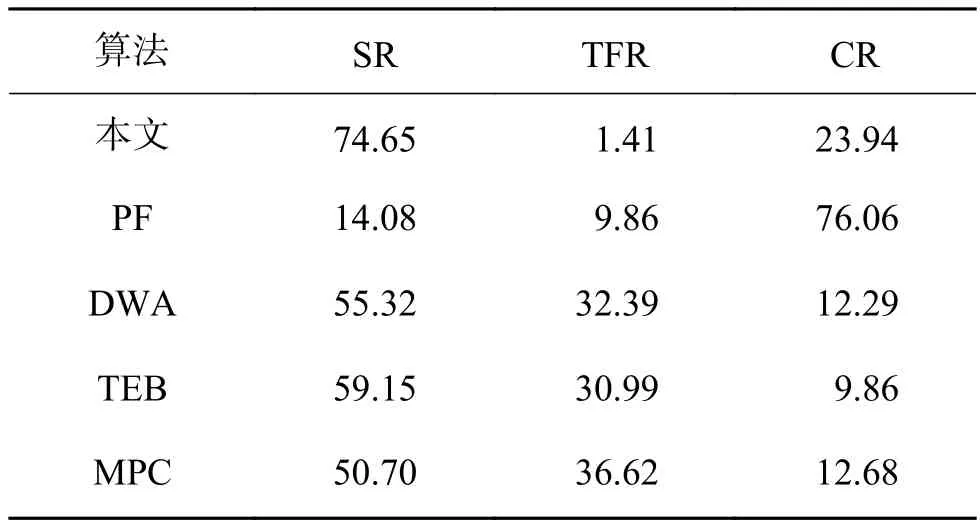
表3 不同算法在Edgemere場景任務中的平均結果對比Table 3 Comparison of the average results of different algorithms in the Edgemere scene task
5類算法導航成功率、碰撞率以及SLAM跟蹤丟失的概率隨導航距離的變化分別如圖7的3種圖所示,隨著導航距離增加,各類算法碰撞概率和SLAM跟蹤概率都有所增加,但本文提出算法的導航效果對導航距離更加魯棒,尤其是SLAM跟蹤丟失概率受導航距離影響很小。
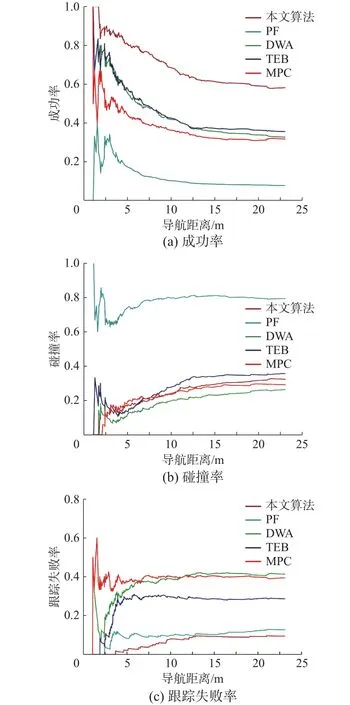
圖7 性能-導航距離變化曲線Fig.7 Performance-navigation distance change curves
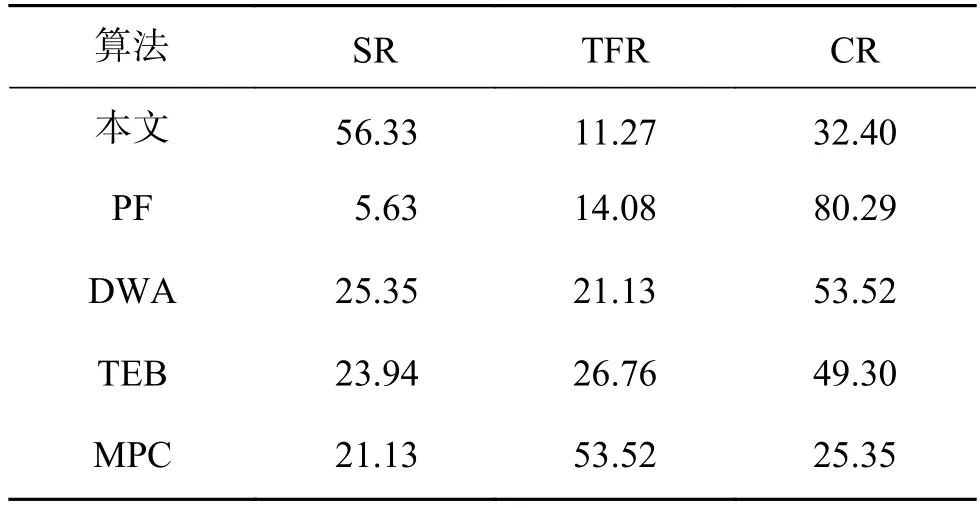
表4 不同算法在Eastville場景任務中的平均結果對比Table 4 Comparison of the average results of different algorithms in the Eastville scene task
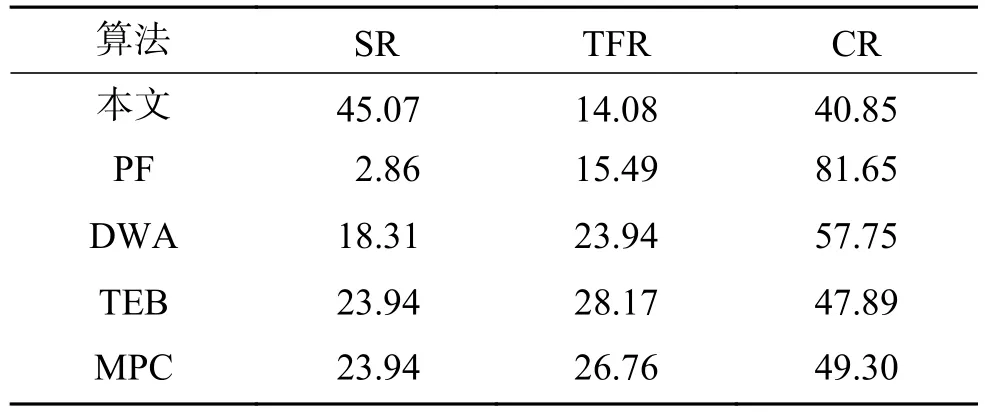
表5 不同算法在Mosquito場景任務中的平均結果對比Table 5 Comparison of the average results of different algorithms in the Mosquito scene task
為了進一步驗證所述方法在避免視覺SLAM跟蹤失敗方面的有效性,以Edgemere場景的第30個導航任務為例,將機器人行走過程中的特征點個數進行對比統計。如圖8所示,PF方法和MPC方法在低紋理區域發生了跟蹤丟失現象,造成視覺SLAM失敗。而DWA方法雖然沒有發生跟蹤丟失現象,但在第5~15個關鍵幀之間特征點急劇下降,有很大的跟蹤丟失風險。類似地,TEB方法在第30~45個關鍵幀之間特征點急劇下降,也存在較大的跟蹤丟失風險。相反,采用本文所提出的方法后,機器人在行走過程中所跟蹤到的特征始終維持在580個以上,具有較強的穩定性。3種方法的軌跡對比如圖9所示(起點在左上角)。綠色軌跡代表本文所提出的方法的行走過程,紅色軌跡代表DWA方法的行走過程,藍色軌跡代表PF方法的行走過程,青色軌跡代表TEB方法的行走過程,紫色軌跡代表MPC方法的行走過程。由于PF方法和MPC方法在行走的前15步時就跟蹤失敗,軌跡長度較短。機器人在沿著DWA方法規劃出的軌跡行走時,需要近距離,DWA方法有沿墻行走的習慣,容易發生碰撞。
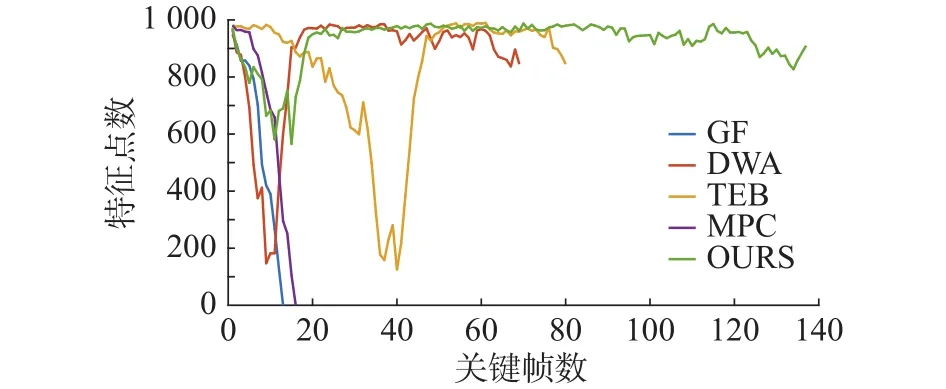
圖8 特征點個數對比(Edgemere場景的第30個導航任務)Fig.8 Comparisons of the number of feature points (The 30th navigation mission of the Edgemere scene)

圖9 軌跡對比Fig.9 Trajectory comparison
為了更客觀地衡量本文獎勵函數的設計對于模型性能的影響,使用消融實驗證明其有效性。消融實驗是深度強化學習研究中確定某種方法是否有效的最直接的方式。本文在500個任務組成的訓練集中對所提出的6部分獎勵函數進行消融實驗,訓練過程中每次剔除其中一部分獎勵函數以查看對模型指標的影響。評價指標包括成功率、跟蹤丟失率和碰撞率。實驗結果如圖10所示。同時使用6部分獎勵函數時,模型在點導航問題上具有最好的性能。其他6個消融實驗在各種指標上都略遜于6種獎勵函數同時使用的效果,證明了這6種獎勵函數在點導航任務上具有快速到達局部目標點,并降低碰撞率和跟蹤丟失率的能力。另外,在刪除角度獎勵部分后,模型的性能有較大程度的下降,說明在本文的點導航任務中,角度獎勵相比另外5種獎勵更能提升模型的性能。

圖10 消融實驗結果圖Fig.10 Results of ablation experiments
4 結論
本文針對傳統局部路徑規劃算法不適用于基于視覺SLAM導航的問題,使用深度強化學習算法訓練局部路徑規劃策略,根據輸入輸出數據特點進行Actor網絡和Critic網絡的設計,根據一般導航需求和視覺SLAM工作特點設計獎勵函數,在Habitat仿真平臺中使用點導航數據集進行訓練,最終得到訓練好的策略。在與傳統導航策略的對比中,訓練好的策略在防止視覺SLAM失敗避障導航方面都表現出良好的性能,最終在3種不同難度場景中的導航成功率,均有巨大提升。下一步計劃,考慮將視覺SLAM建立的二維地圖納入強化學習的觀測空間,使局部導航策略的決策具有記憶性;對特征點分布進行分析,不僅考慮特征點的數量,還要考慮將特征點分布對SLAM穩定性的影響。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
公民與法治(2020年11期)2020-07-25 02:02:06
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
數學大世界(2018年1期)2018-04-12 05:39:14
領導決策信息(2018年50期)2018-02-22 06:17:16
商周刊(2017年5期)2017-08-22 03:35:26
中國衛生(2016年2期)2016-11-12 13:22:16
華東科技(2016年10期)2016-11-11 06:17:41
