基于聲音融合特征與OCSVM的機(jī)床故障分類診斷*
2022-10-11 06:13:56丁少虎張瑞晨楊稱稱
制造技術(shù)與機(jī)床 2022年10期
丁少虎 張瑞晨 楊稱稱 張 森
(①北方民族大學(xué)機(jī)電工程學(xué)院,寧夏銀川 750021;②北方民族大學(xué)電氣信息工程學(xué)院,寧夏銀川 750021)
高檔數(shù)控機(jī)床和基礎(chǔ)制造裝備是實(shí)現(xiàn)制造技術(shù)和工業(yè)現(xiàn)代化的基石[1],也是實(shí)施強(qiáng)國(guó)戰(zhàn)略的重點(diǎn)領(lǐng)域,全球制造業(yè)強(qiáng)國(guó)也都在研究水平先進(jìn)的制造設(shè)備。由于數(shù)控機(jī)床結(jié)構(gòu)復(fù)雜,零部件構(gòu)造精密,在運(yùn)行時(shí)很容易被周圍各種因素影響,加上長(zhǎng)時(shí)間不停歇的使用,導(dǎo)致設(shè)備故障頻繁發(fā)生[2],對(duì)產(chǎn)品性能和數(shù)控機(jī)床壽命都會(huì)產(chǎn)生影響,如果在問(wèn)題剛出現(xiàn)或即將出現(xiàn)時(shí)能快速反饋并采取解決措施,就能挽回更多損失,因此精準(zhǔn)的故障分類診斷就成了生產(chǎn)過(guò)程的重要環(huán)節(jié)。機(jī)械故障診斷技術(shù)通過(guò)采集和分析設(shè)備運(yùn)行時(shí)的數(shù)據(jù),可以了解和掌握機(jī)器在運(yùn)行過(guò)程中的狀態(tài),實(shí)現(xiàn)對(duì)設(shè)備運(yùn)行狀態(tài)的監(jiān)測(cè)。常采用的診斷技術(shù)包括油液監(jiān)測(cè)、振動(dòng)監(jiān)測(cè)、性能趨勢(shì)分析和無(wú)損探傷等,其中早期最常用的是基于接觸式振動(dòng)傳感器的診斷方法,該方法在齒輪、高壓斷路器等故障部位的應(yīng)用較為成熟,但該方法需要接觸測(cè)量,將振動(dòng)傳感器放置在被測(cè)物體上,當(dāng)遇到高溫、腐蝕液體、難以附著的光滑位置等問(wèn)題時(shí),該方法無(wú)法發(fā)揮作用;此外,振動(dòng)傳感器也只能對(duì)機(jī)械的局部問(wèn)題進(jìn)行故障檢測(cè),當(dāng)局部的振動(dòng)特征對(duì)故障不敏感時(shí),診斷效率會(huì)受到影響。隨著聲音技術(shù)的發(fā)展,基于聲音的故障診斷技術(shù)逐漸受到更多研究人員的關(guān)注,該技術(shù)采用非接觸式測(cè)量,無(wú)需將傳感器附著在被測(cè)機(jī)械位置上,可以將機(jī)械整體聲音進(jìn)行收集處理,操作簡(jiǎn)單且靈活。近年來(lái)聲學(xué)故障檢測(cè)也逐漸得到推廣,應(yīng)用在多種機(jī)械領(lǐng)域上,如鉆機(jī)鉆頭的斷裂檢測(cè)[3]、刨機(jī)故障診斷[4]等。
常見(jiàn)的特征提取方法有時(shí)頻域分析[5]、小波變換[6]等,但單一的特征提取方法往往不能充分表征數(shù)控機(jī)床音頻信息,因此使用Mel頻率倒譜系數(shù)(mel-frequency cepstral coefficient,MFCC)提取特征和線性預(yù)測(cè)倒譜系數(shù)(linear predictive cepstral coefficient,LPCC)提取特征融合,從不同標(biāo)準(zhǔn)獲得更多數(shù)控機(jī)床聲音特征;因?yàn)樘卣鞯木S度較高,數(shù)據(jù)處理較慢,使用主成分分析(PCA)降維方法和歸一化處理特征數(shù)據(jù),可以消除不同維度和量綱導(dǎo)致的距離計(jì)算不合理情況;傳統(tǒng)的診斷方法只有在正常和異常樣本均衡時(shí)才會(huì)有較高的檢測(cè)準(zhǔn)確率,而數(shù)控機(jī)床工作時(shí)的異常樣本(如刀具斷裂、主軸磨損等)難以大量獲取,因此使用一類支持向量機(jī)方法對(duì)數(shù)控機(jī)床數(shù)據(jù)進(jìn)行檢測(cè)可以解決樣本不均衡的問(wèn)題。本文將利用MFCC和LPCC方法提取數(shù)控機(jī)床聲音信號(hào)的多維特征,分別進(jìn)行PCA降維和歸一化后進(jìn)行特征融合,將融合特征使用一類支持向量機(jī)方法判斷是否存在故障,若檢測(cè)為正常,則繼續(xù)工作,若判斷為異常,則通過(guò)SVM分類器[7]識(shí)別具體故障類別并停止工作,精準(zhǔn)定位故障快速解決問(wèn)題。通過(guò)該流程能快速且高效診斷識(shí)別數(shù)控機(jī)床的故障類別。
1 算法原理
1.1 LPCC特征提取
在聲音特征參數(shù)提取技術(shù)的發(fā)展歷程中,線性預(yù)測(cè)倒譜系數(shù)最早被用于語(yǔ)音特征參數(shù)的提取,該方法能較好反映語(yǔ)音的聲道特征。隨著環(huán)境音的發(fā)展,雖然工程機(jī)械音與語(yǔ)音產(chǎn)生過(guò)程有所差異,但通過(guò)對(duì)比分析語(yǔ)音與機(jī)械環(huán)境音的產(chǎn)生和特征,在本質(zhì)上發(fā)音過(guò)程類似,且常規(guī)的部分特征都適用,因此,可使用LPCC對(duì)機(jī)械音進(jìn)行特征分析[8]。譜質(zhì)量下降。LPCC具有計(jì)算量小,對(duì)共振峰的描述清晰等優(yōu)點(diǎn),其核心思想是:第n個(gè)音頻樣本可以通過(guò)其之前p個(gè)樣本的線性組合來(lái)估計(jì),表示為
LPCC是 由 線 性 預(yù) 測(cè) 編 碼(linear predicative coding,LPC)計(jì)算頻譜包絡(luò)得到的倒譜系數(shù),因?yàn)長(zhǎng)PC對(duì)誤差比較敏感,導(dǎo)致一些小誤差也會(huì)造成頻
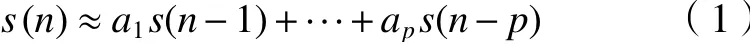
式中:a1,a2,···,ap被 假定為語(yǔ)音分析框架上的常數(shù)[9]。LPCC特征的階數(shù)通常與其所反映的信息和運(yùn)算量成正比,階數(shù)越大,通常所包含的信息就越大,階數(shù)通常選擇8~16[10]。特征提取聲譜圖如圖1所示,這是對(duì)聲音信號(hào)進(jìn)行預(yù)加重、分幀和加窗等預(yù)處理后,再進(jìn)行線性預(yù)測(cè)分析、快速傅里葉變化、取對(duì)數(shù)和快速傅里葉逆變化獲得的關(guān)鍵特征信息。

圖1 LPCC的13維特征聲譜圖
1.2 MFCC特征提取
不同于LPCC對(duì)發(fā)聲處機(jī)理進(jìn)行研究而得到的聲學(xué)特征,MFCC是依據(jù)人耳的聽(tīng)覺(jué)系統(tǒng)研究推出的特征提取方法。與LPCC類似的是,MFCC也是利用求倒譜系數(shù)分析特征,倒譜分析是常用的一種方法,它可以用有限特征表征聲音包含的信息。
這種方法不基于信號(hào)本質(zhì)的變化,對(duì)輸入的聲音信號(hào)不附加各種條件,又利用了聽(tīng)覺(jué)模型上的研究,因此這種特征提取方法具有更強(qiáng)的魯棒性[11],而且在信噪比較低時(shí)仍有可觀的檢測(cè)正確率。通過(guò)將頻率轉(zhuǎn)換成Mel尺度,特征能夠更好地匹配人類的聽(tīng)覺(jué)感知效果,從頻率到Mel頻率的轉(zhuǎn)換公式為
其中:f為頻率,利用Mel濾波也是該特征提取方法的一個(gè)關(guān)鍵,MFCC的特征提取聲譜圖如圖2所示,圖2中MFCC的特征聲譜圖是經(jīng)過(guò)對(duì)聲音信號(hào)預(yù)處理、快速傅里葉變化、Mel濾波、取對(duì)數(shù)以及離散余弦變化后獲得的關(guān)鍵特征信息。
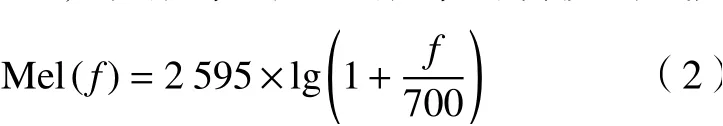

圖2 MFCC的13維特征聲譜圖
1.3 PCA特征降維
通常特征的維度越高,其所包含的信息就越多,準(zhǔn)確率也會(huì)相應(yīng)提高,但當(dāng)處理的文件數(shù)量增多,且特征維度較高時(shí),一次檢測(cè)運(yùn)行可能就是以小時(shí)起步,因此為了節(jié)省時(shí)間與內(nèi)存,選擇一種合適的降維算法進(jìn)行處理數(shù)據(jù)就顯得格外重要。不同的算法會(huì)根據(jù)數(shù)據(jù)的不同特性進(jìn)行降維,常見(jiàn)的降維方法有t分布隨機(jī)鄰域嵌入(t-SNE[12])、一致流形近似與投影(UMAP)和PCA方法。
PCA是主成分分析方法。這是一種常見(jiàn)的數(shù)據(jù)處理算法,一般用來(lái)給高維數(shù)據(jù)降維。通過(guò)選擇不同的基對(duì)同一組數(shù)據(jù)給出不同的表示,若基的數(shù)量小于數(shù)據(jù)本身的維數(shù),則說(shuō)明達(dá)到了降維的目標(biāo)[13]。其中的關(guān)鍵問(wèn)題是怎樣選擇K個(gè)基去表示N維向量。
(1)方差。方差代表著數(shù)值的分散程度,為方便處理,將變量均值化為0可得
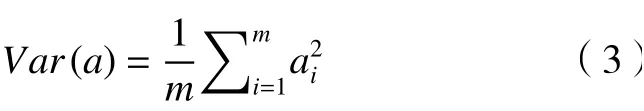
需要尋找1個(gè)一維基,使得變換數(shù)據(jù)到基上后,方差值最大。
(2)協(xié)方差。協(xié)方差能代表1個(gè)變量之間的相關(guān)性。要讓2個(gè)變量之間不存在線性相關(guān)性,這樣能使其表示更多不重復(fù)的原始信息。同樣將均值化為0可得
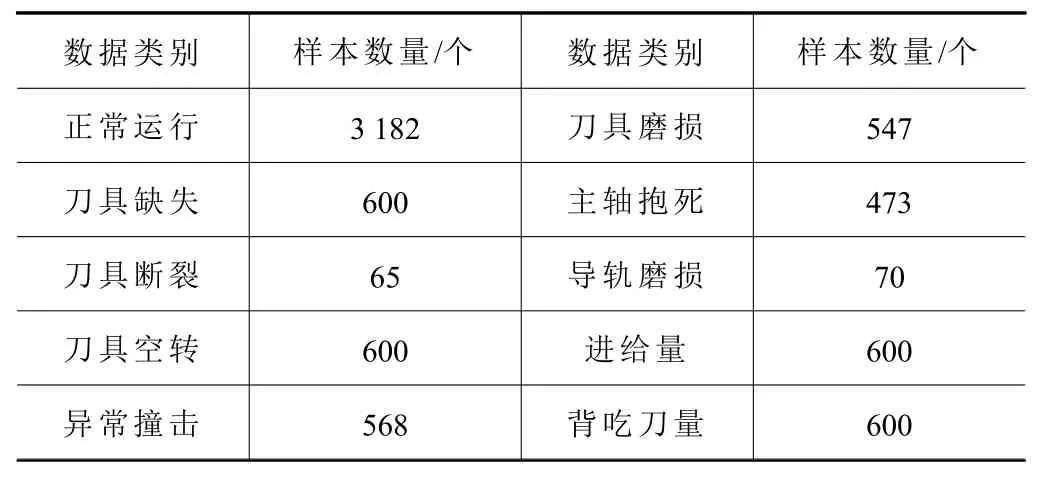
表1 實(shí)驗(yàn)采集數(shù)據(jù)信息
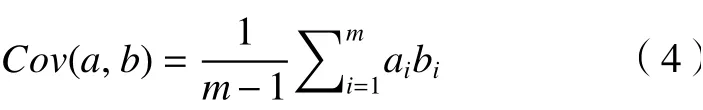
當(dāng)協(xié)方差為0時(shí),表示2個(gè)變量線性不相關(guān),在選擇第2個(gè)基時(shí)在第1個(gè)基正交的方向上進(jìn)行選擇,就能滿足相互正交的期望。有a和b兩個(gè)變量,按行組成矩陣X
(3)協(xié)方差矩陣。要滿足優(yōu)化目標(biāo),就要將方差與協(xié)方差統(tǒng)一表示,可用矩陣的方式,假設(shè)

由式(6)可得統(tǒng)一表達(dá)后的方差與協(xié)方差。
(4)矩陣對(duì)角化。假設(shè)P是1組基按行組成的矩陣,設(shè)Y=PX,則Y就是X對(duì)P做基變換后的數(shù)據(jù)。設(shè)Y的協(xié)方差矩陣為D,則D為
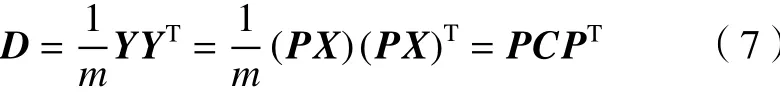
由式(7)可以看出優(yōu)化目標(biāo)已經(jīng)變?yōu)閷ふ?個(gè)矩陣P,滿足D是1個(gè)對(duì)角矩陣,則對(duì)角元素從大到小的前K行就是要尋找的基。
由實(shí)對(duì)稱矩陣定義可知,1個(gè)n行n列實(shí)對(duì)稱矩陣一定能找到n個(gè)單位正交特征向量,設(shè)為e1,e2,···,en,將其按列組成矩陣E=[e1,e2,···,en],則協(xié)方差矩陣C可為
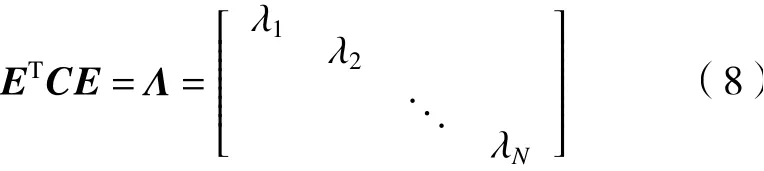
對(duì)角元素λ就是各特征向量對(duì)應(yīng)的特征值。得到P=ET,P的每1行都是C的1個(gè)特征向量,將P從大到小排列的前K行組成的矩陣乘原始數(shù)據(jù)X,就得到了Y=PX,即為降到K維后的數(shù)據(jù)。
文章對(duì)比了t-SNE、UMAP以及PCA這3種降維方法診斷效果,具體實(shí)驗(yàn)見(jiàn)后文。
1.4 特征融合
傳統(tǒng)理解中,特征維度越高代表其所包含的關(guān)鍵信息越多,檢測(cè)準(zhǔn)確率就會(huì)相應(yīng)地提高。環(huán)境聲具有非線性且背景復(fù)雜發(fā)聲點(diǎn)較多,使得單一特征無(wú)法完全表征環(huán)境聲音信號(hào),融合特征可以解決這一問(wèn)題。因此,采用LPCC與MFCC方法提取特征,之后進(jìn)行降維及歸一化處理,最后結(jié)合生成新的特征。

其中:μ為所有樣本數(shù)據(jù)的均值,σ為所有樣本數(shù)據(jù)的標(biāo)準(zhǔn)差。
如式(9),對(duì)數(shù)據(jù)進(jìn)行標(biāo)準(zhǔn)歸一化,是機(jī)器學(xué)習(xí)與統(tǒng)計(jì)學(xué)習(xí)任務(wù)中常用的一種處理方式。由于MFCC和LPCC是基于不同方法的濾波器提取得到的特征,具有不同的量綱,因此直接對(duì)兩者進(jìn)行疊加或結(jié)合可能會(huì)導(dǎo)致精度下降。為了消除量綱不同帶來(lái)的影響,采用特征降維和標(biāo)準(zhǔn)歸一化處理可以解決由于不同維度和量綱導(dǎo)致的距離計(jì)算不合理情況,此外還能方便處理數(shù)據(jù)和加快收斂速度。
文章對(duì)兩種特征提取方法都設(shè)置為13維特征提取,因此MFCC和LPCC特征具有相同的維數(shù),在經(jīng)過(guò)降維、歸一化處理后,聲譜圖已轉(zhuǎn)換為多維數(shù)組,利用Python中的concatenate函數(shù)將處理后的2種特征的對(duì)應(yīng)位置相互融合,融合后的新特征既包含MFCC提取的特征信息,也包含LPCC提取的特征信息,2種方法提取的特征之間相關(guān)性較小,反映出環(huán)境聲音不同特征,預(yù)計(jì)融合后效果較好。
1.5 OCSVM分類法
一類支持向量機(jī)(one-class support vector machine,OCSVM)是由Bernhard Scholkopf等人基于支持向量機(jī)(SVM)提出[14]。SVM有著諸多算法不具備的優(yōu)良特性,首先,SVM算法是基于統(tǒng)計(jì)學(xué)習(xí)中VC維與結(jié)構(gòu)風(fēng)險(xiǎn)最小原理的典型機(jī)器學(xué)習(xí)方法。通過(guò)添加對(duì)應(yīng)的正則項(xiàng),使該方法具有良好的泛化能力,不易過(guò)擬合;將SVM的原二次規(guī)劃求解問(wèn)題轉(zhuǎn)化為凸優(yōu)化問(wèn)題,當(dāng)數(shù)據(jù)集線性可分時(shí),則必定能得到全局最優(yōu)解;其次利用線性、多項(xiàng)式和高斯等核函數(shù),將原樣本空間投影至高維空間,利用高維空間線性可分的特性,將非線性問(wèn)題轉(zhuǎn)化為線性問(wèn)題進(jìn)行求解;最后,通過(guò)引用一個(gè)松弛變量和懲罰系數(shù),最大化軟分類間隔,使得SVM算法具有較好的魯棒性。
OCSVM算法也使用了核函數(shù)來(lái)處理線性不可分的情況。給定數(shù)據(jù)X=[x1,x2,···,xl],其中包含l個(gè)觀測(cè)數(shù)量,設(shè)為1個(gè)R N的1個(gè)子集,假設(shè)Φ是1個(gè)從X低維輸入空間到高維Hilbert空間H的映射,利用核函數(shù)運(yùn)算通過(guò)k(x,z)對(duì)任意x,z∈X:
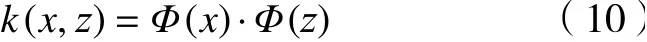
為了將數(shù)據(jù)集與原點(diǎn)分離,并使這個(gè)距離最大化,對(duì)其求解二次規(guī)劃,得
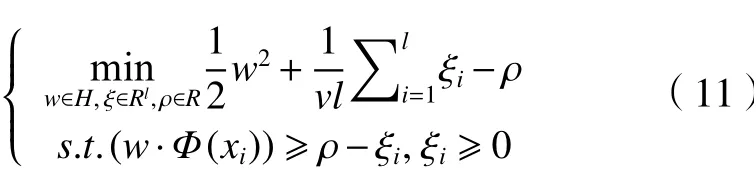
由于非零松弛變量ξi在目標(biāo)函數(shù)中受到懲罰,可以預(yù)期,如果w和ρ解決了這個(gè)問(wèn)題,則對(duì)于訓(xùn)練集中包含的大多數(shù)示例xi,決策函數(shù)將會(huì)為正,其中v扮演重要權(quán)衡角色,v∈(0,1)是1個(gè)參數(shù),類似于SVM中的懲罰參數(shù)C。采用拉格朗日求解,并通過(guò)上面核函數(shù)可證明解具有SV展開(kāi)式:
具有非零αi的模式xi稱為SVs,其中找到系數(shù)便可得優(yōu)化問(wèn)題的對(duì)偶形式:
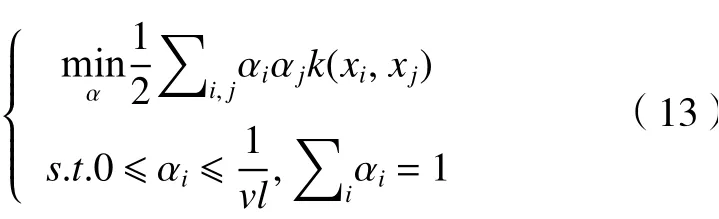
單分類支持向量機(jī)基本思想:首先通過(guò)非線性變換將數(shù)據(jù)映射到高維的特征空間,然后在特征空間中,將原點(diǎn)作為異常點(diǎn),求出訓(xùn)練樣本與原點(diǎn)的最大間隔的超平面。對(duì)測(cè)試樣本,通過(guò)超平面進(jìn)行分類[15]。這是一種無(wú)監(jiān)督學(xué)習(xí)方法,能規(guī)避手工貼標(biāo)錯(cuò)誤引起的識(shí)別下降,還能節(jié)省大量時(shí)間。為預(yù)防將通過(guò)的人聲鳥叫等都識(shí)別為異常聲音,所以在訓(xùn)練測(cè)試時(shí),會(huì)給定一個(gè)總比例約0.1的異常樣本,使機(jī)器認(rèn)識(shí)異常樣本,通過(guò)機(jī)器自動(dòng)識(shí)別異常樣本數(shù)量,對(duì)比已知數(shù)據(jù)觀察檢測(cè)效果。
2 基于 聲音 特 征融 合與OCSVM的 機(jī) 床故障分類診斷方法
機(jī)床的異音故障分類診斷方案主要有以下3個(gè)方面的工作,分別是機(jī)床音頻信號(hào)的采集、數(shù)據(jù)信號(hào)的處理和異音診斷方法的實(shí)現(xiàn)。根據(jù)實(shí)現(xiàn)的流程,將機(jī)床異音檢測(cè)系統(tǒng)分為以下幾步:
(1)使用Brüel&Kj?r(BK)信號(hào)采集設(shè)備(包括傳聲器、信號(hào)采集儀等)采集機(jī)床正常工作與多種異常工作的聲音信號(hào),為后續(xù)算法分析提供數(shù)據(jù)支持。
(2)對(duì)采集的信號(hào)先在BK Pulse Reflex軟件上進(jìn)行時(shí)頻域觀察分析,再通過(guò)Python進(jìn)行切割命名等處理數(shù)據(jù),使用MFCC和LPCC方法進(jìn)行信號(hào)濾波和特征提取,選擇PCA降維方法進(jìn)一步處理特征,對(duì)提取的兩種特征進(jìn)行特征融合,為之后的決策方法處理好數(shù)據(jù)。
(3)利用OCSVM方法對(duì)機(jī)床音頻數(shù)據(jù)進(jìn)行檢測(cè),得到是否有異常音頻,若為異常音頻,再進(jìn)一步判斷是哪一類異常音頻。
基于聲音特征融合與OCSVM的機(jī)床故障分類診斷詳細(xì)流程圖如圖3所示。
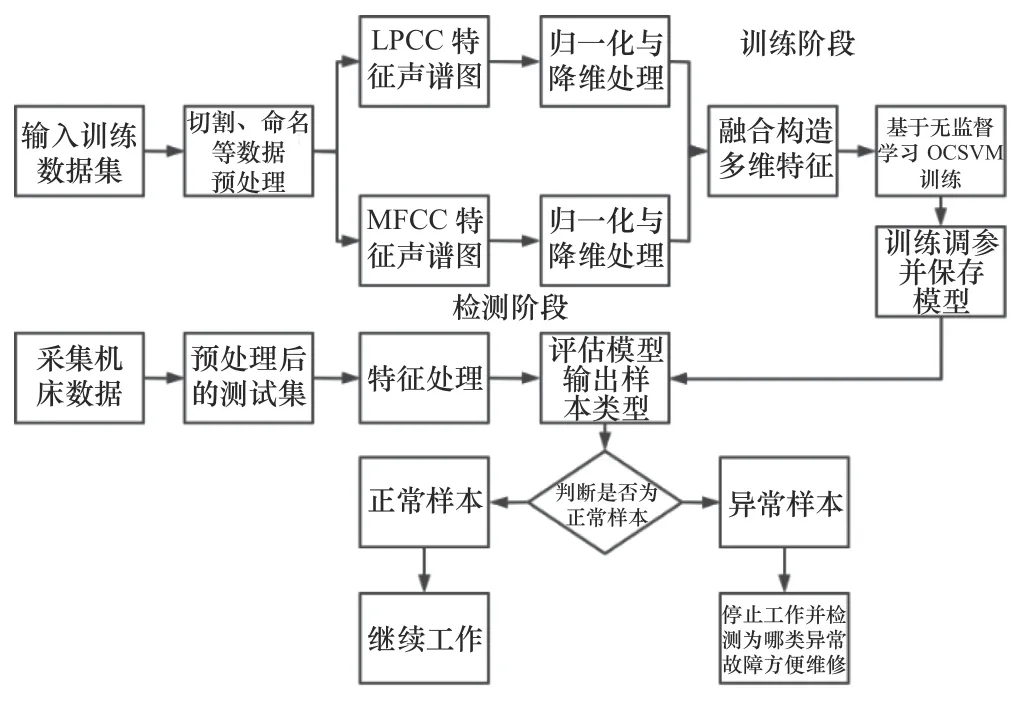
圖3 機(jī)床的故障診斷分類流程圖
3 實(shí)驗(yàn)研究
實(shí)驗(yàn)采用Type 4189-A-021傳聲器和Type0671前置放大器采集數(shù)控機(jī)床的各類音頻,搭配3050-A-060信號(hào)采集儀傳入計(jì)算機(jī)進(jìn)行數(shù)據(jù)分析,傳聲器懸掛放置在機(jī)床內(nèi)部?jī)蓚?cè),傳聲器方法采集數(shù)據(jù)區(qū)別于振動(dòng)傳感器,不能放置在機(jī)床的某一單獨(dú)位置附近,應(yīng)確保對(duì)工作環(huán)境的整體監(jiān)測(cè),同時(shí)對(duì)傳聲器包裹海綿套,在濾除部分雜音和降噪的同時(shí)保護(hù)設(shè)備正常使用,部分設(shè)置參考GB/T 12060.4聲系統(tǒng)設(shè)備第4部分:傳聲器測(cè)量方法,測(cè)試圖如圖4所示。
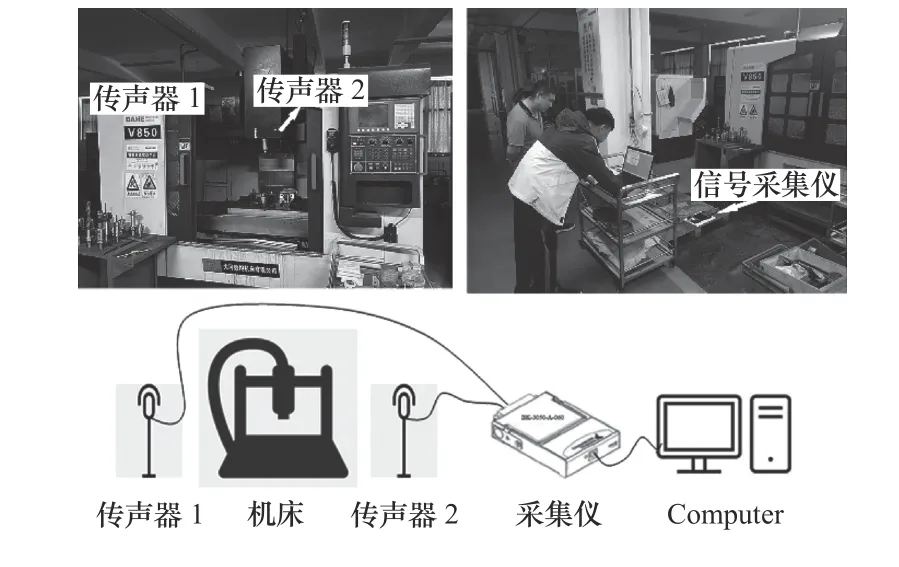
圖4 采集現(xiàn)場(chǎng)和采集設(shè)備搭建示意圖
機(jī)床音頻信號(hào)數(shù)據(jù)采集時(shí),先確定正常運(yùn)轉(zhuǎn)的各項(xiàng)參數(shù)值,選擇8 mm尺寸的切削刀具,機(jī)床轉(zhuǎn)速設(shè)置為3 000 r/min,進(jìn)給量為250 mm/min,背吃刀量為1 mm。刀具磨損音頻采集選擇70%左右界值的磨損刀具進(jìn)行工作,進(jìn)給量增至350 mm/min時(shí)運(yùn)行狀態(tài)作為異常音頻采集,背吃刀量增至1.5 mm時(shí)作為異常音頻采集。考慮到不同的異常音頻故障采集難度不同,因此每個(gè)音頻的采集數(shù)量都會(huì)有區(qū)別,如刀具斷裂錄制時(shí)間較短,采用音頻裁剪的方式擴(kuò)充數(shù)據(jù)集。采集頻率為51.2 kHz,使用雙聲道采集音頻,數(shù)據(jù)每30 s分為一個(gè)音頻文件,后期切割為每500 ms一個(gè)音頻文件,并去除其中的空白音頻,錄制的各類正常與異常音頻總數(shù)如表1所示。
機(jī)床數(shù)據(jù)采集過(guò)程中會(huì)存在環(huán)境噪聲的影響,采用2種方法解決該問(wèn)題:第一種是在聲音特征提取時(shí)對(duì)信號(hào)預(yù)處理、加濾波器濾除部分噪音;第二種是對(duì)持續(xù)存在的機(jī)床噪音混入每一個(gè)音頻中,將采集的機(jī)床每類音頻都設(shè)為一個(gè)整體,默認(rèn)該噪聲為數(shù)據(jù)集的一部分去訓(xùn)練診斷。
對(duì)機(jī)床的所有類型音頻信號(hào)進(jìn)行時(shí)頻譜分析如圖5所示,從左上圖至由右下圖分別為刀具磨損、刀具斷裂、刀具缺失、主軸抱死、導(dǎo)軌磨損、進(jìn)給量改變、背吃刀量改變、異常撞擊、刀具空轉(zhuǎn)和正常工作時(shí)頻圖。由圖5對(duì)比可見(jiàn),刀具斷裂和導(dǎo)軌磨損的異常音頻與機(jī)床正常運(yùn)轉(zhuǎn)的聲音差別較大,其他7種異音時(shí)頻圖與正常聲音時(shí)頻圖差別會(huì)小很多,因此可以選擇更多的分析方式識(shí)別故障。

圖5 機(jī)床各類音頻信號(hào)時(shí)頻圖對(duì)比
分別使用MFCC和LPCC各提取機(jī)床音頻信號(hào)特征進(jìn)行實(shí)驗(yàn)檢測(cè),在異音故障檢測(cè)上主要設(shè)置特征融合和降維方法的選擇對(duì)比實(shí)驗(yàn)。理論上融合特征會(huì)獲得更高的檢測(cè)效果,因此先固定融合特征選擇效果更好的降維方法,待確定降維方法后,再進(jìn)行單特征與多特征提取實(shí)驗(yàn)對(duì)比。實(shí)驗(yàn)中以9∶1比例選擇正常與異常樣本,由于本文采用的診斷方法是OCSVM,可以在數(shù)據(jù)樣本不均衡的情況下使用,選擇訓(xùn)練數(shù)據(jù)樣本總量為2 828個(gè),測(cè)試樣本總量為701個(gè),將所有異常故障聲音合并為一個(gè)整體稱為故障總類,具體每一類的訓(xùn)練和測(cè)試數(shù)據(jù)量如表2所示。
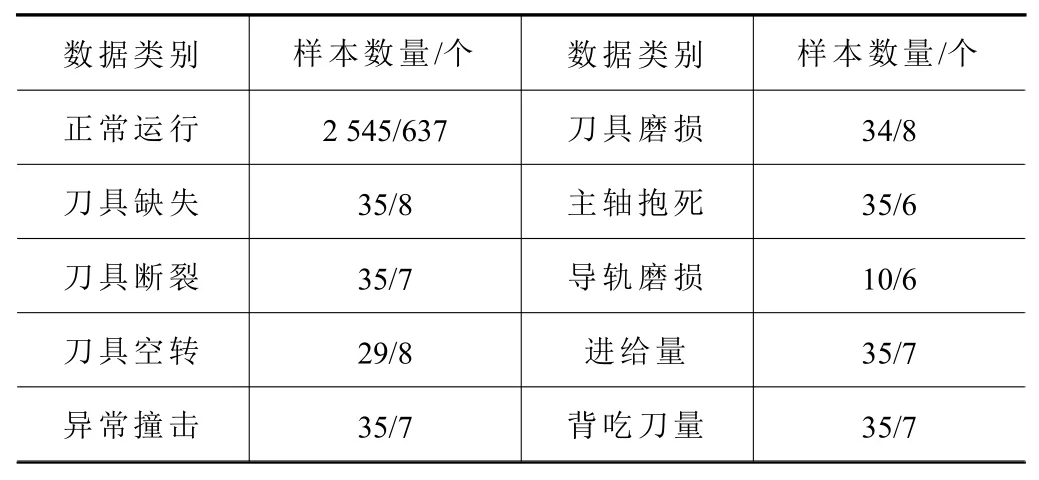
表2 訓(xùn)練/測(cè)試樣本數(shù)量說(shuō)明
數(shù)據(jù)樣本量為n為2 828,數(shù)據(jù)時(shí)長(zhǎng)為500 ms,每一次檢測(cè)模型會(huì)對(duì)數(shù)據(jù)特征處理,將每一個(gè)數(shù)據(jù)點(diǎn)的值表示出來(lái),計(jì)算得到結(jié)果,如表3所示。
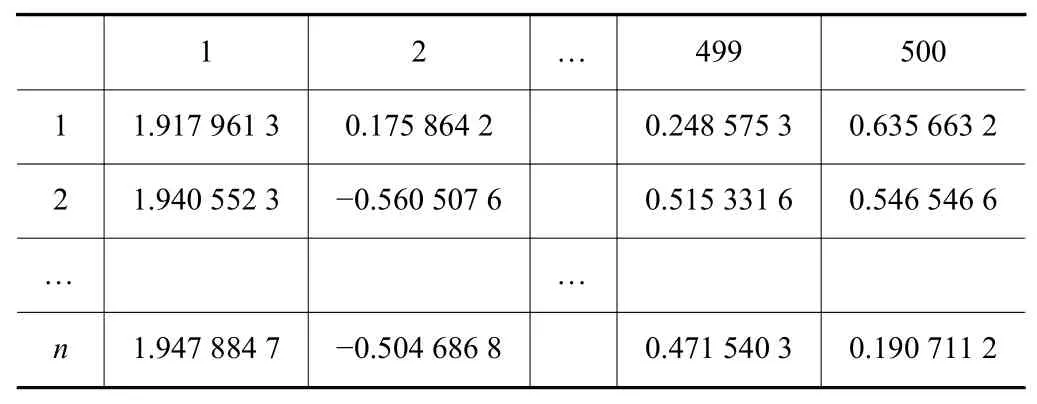
表3 單次檢測(cè)數(shù)據(jù)值表示
分別對(duì)機(jī)床音頻數(shù)據(jù)進(jìn)行t-SNE、UMAP和PCA 降維方法實(shí)驗(yàn),并進(jìn)行調(diào)參,實(shí)驗(yàn)結(jié)果如圖6。
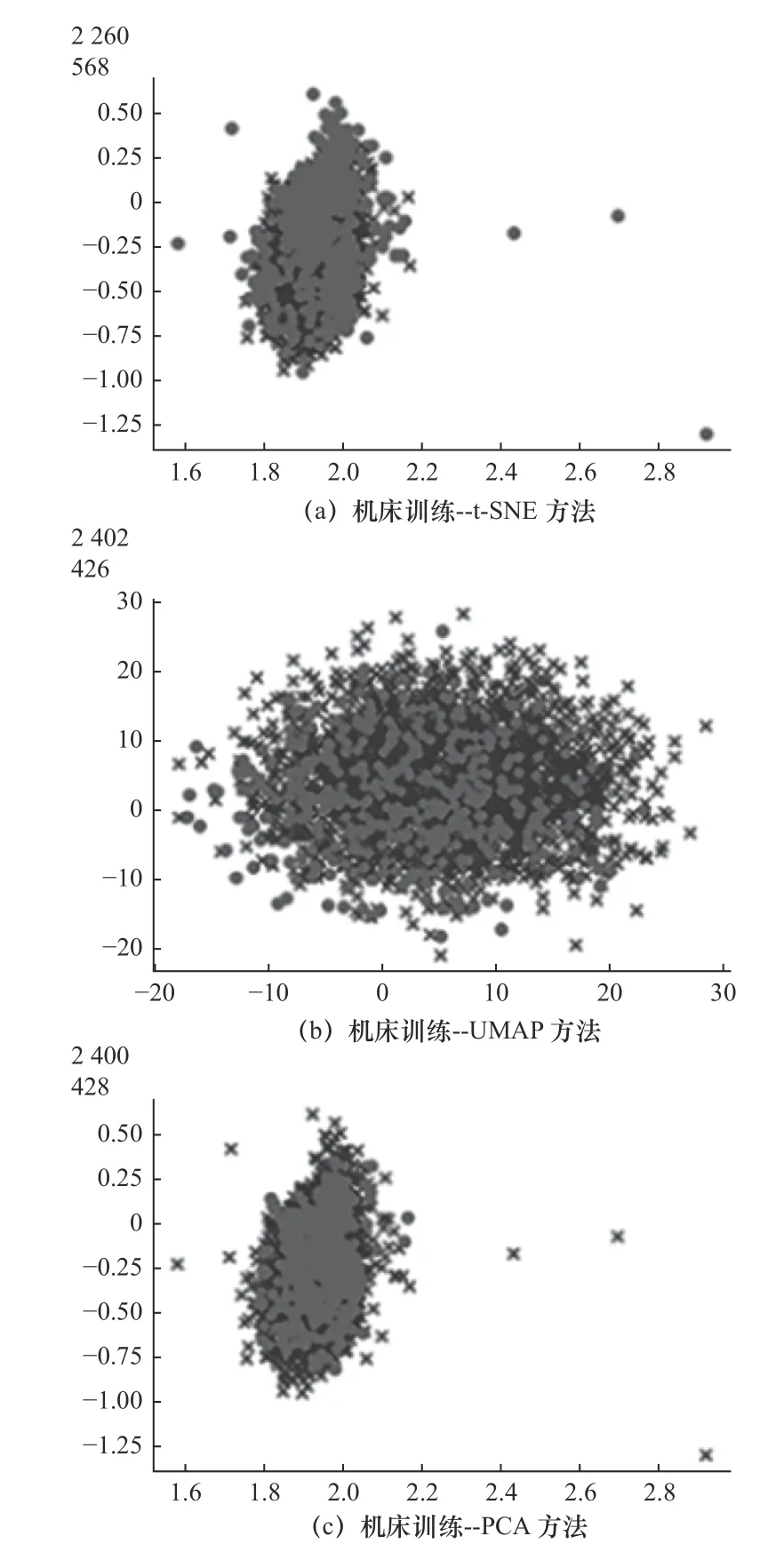
圖6 3種降維方法實(shí)驗(yàn)結(jié)果圖
在保持核函數(shù)和多特征融合方法情況下,常用混淆矩陣表達(dá)模型數(shù)據(jù)預(yù)測(cè)結(jié)果,見(jiàn)表4。
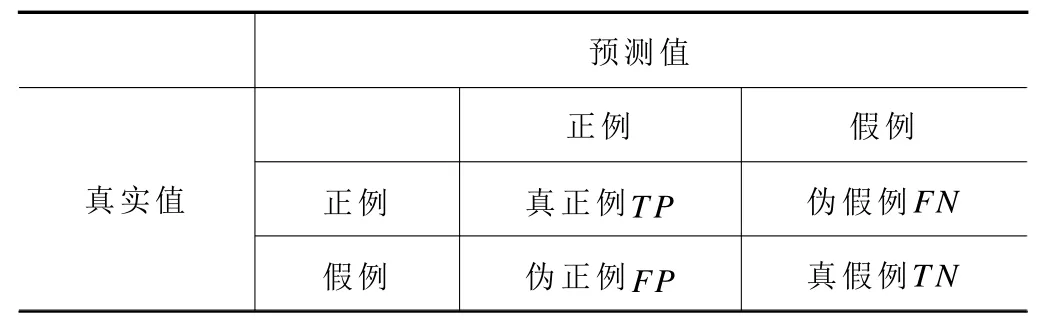
表4 混淆矩陣
采用式(14)準(zhǔn)確率方法來(lái)體現(xiàn)模型效果。
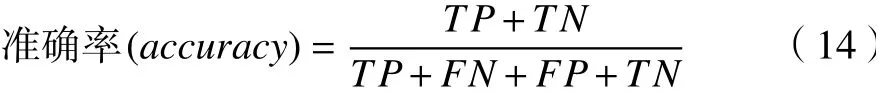
通過(guò)準(zhǔn)確率對(duì)比特征融合下不同降維方法的檢測(cè)效果,如表5所示。
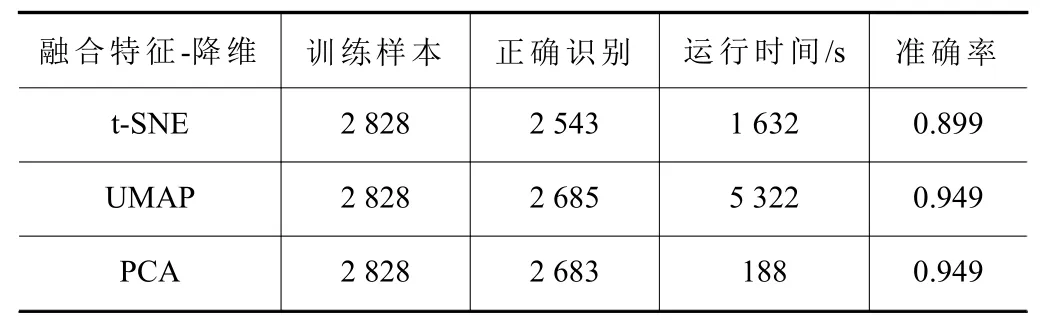
表5 3種降維方法檢測(cè)結(jié)果對(duì)比
t-SNE降 維 方 法 在2 828個(gè) 數(shù) 據(jù) 中 共 識(shí) 別 錯(cuò)285個(gè),這種效果并不盡如人意。UMAP降維方法在2 828個(gè)數(shù)據(jù)中識(shí)別錯(cuò)143個(gè),識(shí)別準(zhǔn)確率相比t-SNE較高,但識(shí)別時(shí)間增加過(guò)多。PCA方法在所選的數(shù)據(jù)中識(shí)別率較高,且運(yùn)行時(shí)間較短,說(shuō)明PCA降維方法相對(duì)更加合適。
在確定PCA降維方法后,開(kāi)始進(jìn)行單特征提取與多特征融合的實(shí)驗(yàn),對(duì)機(jī)床音頻數(shù)據(jù)集進(jìn)行單獨(dú)MFCC和LPCC特征提取實(shí)驗(yàn),并進(jìn)行調(diào)參,結(jié)果如圖7所示,詳細(xì)信息如表6所示。
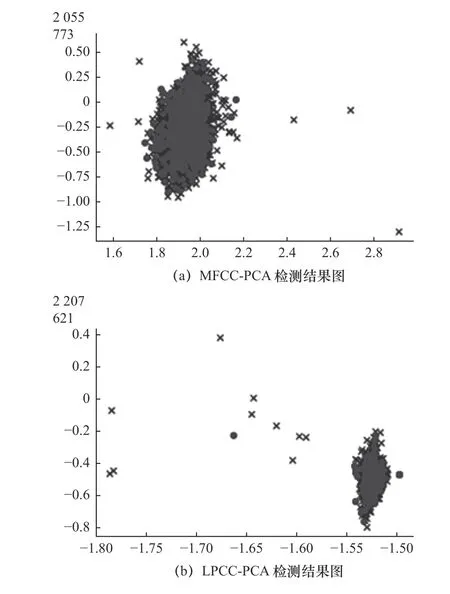
圖7 單特征提取實(shí)驗(yàn)結(jié)果圖
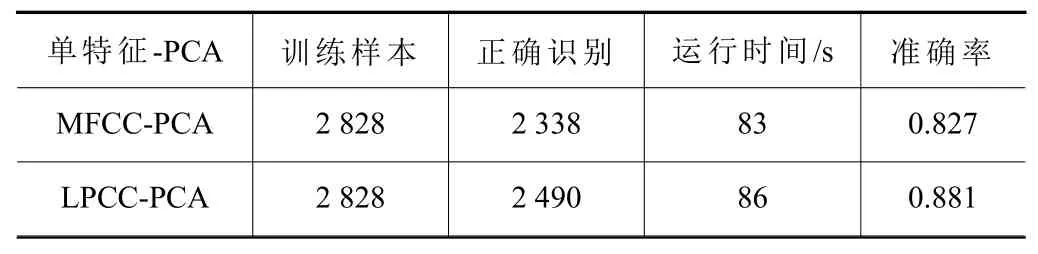
表6 單特征檢測(cè)結(jié)果
由圖7和表6可見(jiàn)單特征效果較好的為L(zhǎng)PCC特征提取,檢測(cè)效果為88.1%,在運(yùn)行時(shí)間差距不大的情況下,檢測(cè)效果相比于表5中特征融合-PCA方法的94.9%準(zhǔn)確率還是低了6.8%,因此特征融合和PCA降維方法搭配OCSVM分類器使用是診斷故障效果最好的方法,下面將使用該方法進(jìn)行測(cè)試驗(yàn)證。
將測(cè)試數(shù)據(jù)代入訓(xùn)練好的故障診斷模型,診斷效果如圖8所示。
由圖8檢測(cè)效果可見(jiàn)正確診斷樣本674個(gè),錯(cuò)誤診斷樣本27個(gè),故障診斷準(zhǔn)確率達(dá)到了96.1%,能夠?qū)崿F(xiàn)機(jī)床運(yùn)行故障的診斷。
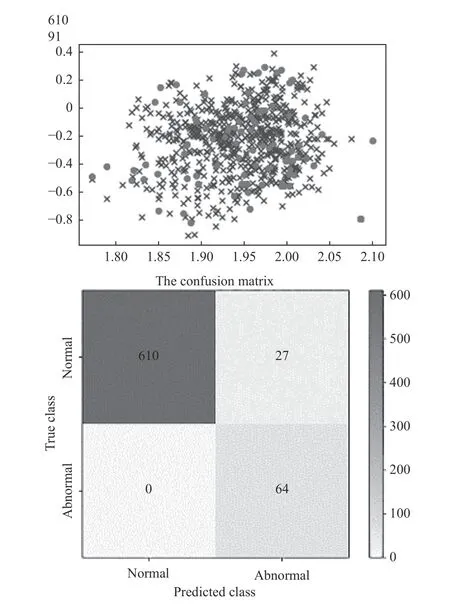
圖8 測(cè)試集檢測(cè)效果圖與混淆矩陣圖
通過(guò)機(jī)床異音故障診斷后,當(dāng)診斷為正常工作聲音時(shí),機(jī)床正常工作,當(dāng)診斷為異常聲音時(shí),需要進(jìn)一步識(shí)別該音頻對(duì)應(yīng)的機(jī)床故障類別并停止機(jī)器,通過(guò)K近鄰(K-nearest neighbors,KNN)方法和SVM方法進(jìn)行具體檢測(cè)。機(jī)床異音故障分類的總數(shù)為4 123個(gè)樣本,共9類如表7所示。
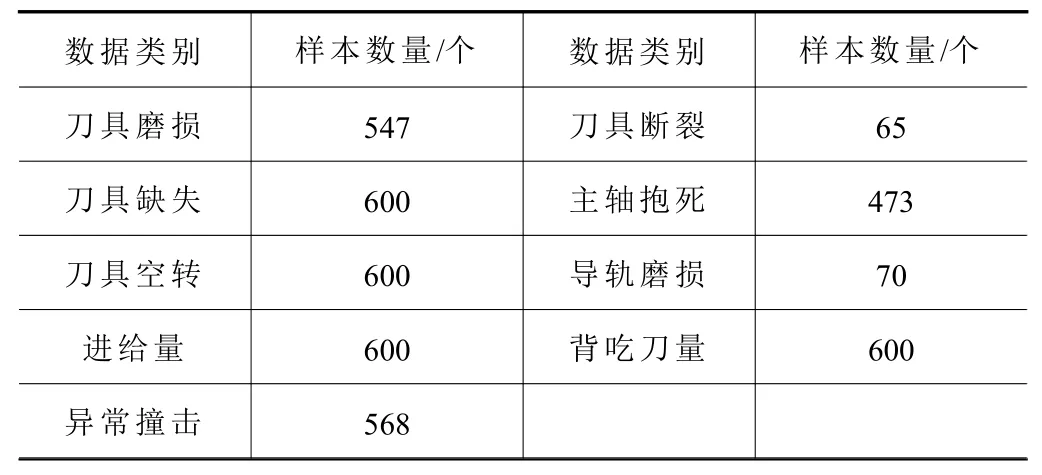
表7 機(jī)床異音故障類別樣本數(shù)量
將整體數(shù)據(jù)以7∶3分為訓(xùn)練集與測(cè)試集進(jìn)行實(shí)驗(yàn),觀察測(cè)試集檢測(cè)效果,實(shí)驗(yàn)結(jié)果如表8所示。
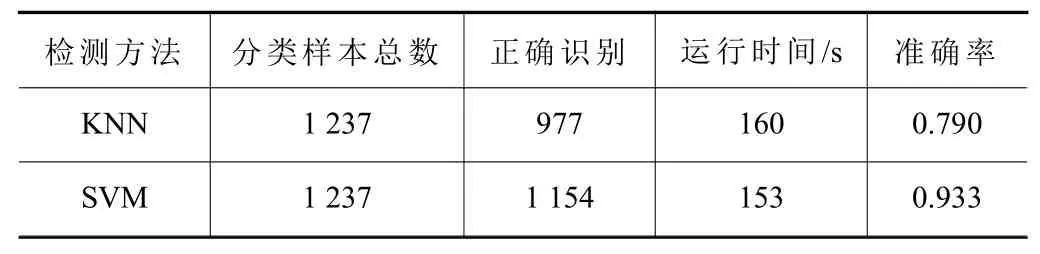
表8 多類故障檢測(cè)結(jié)果對(duì)比
由表8可見(jiàn)SVM檢測(cè)效果相比KNN方法準(zhǔn)確率提高了14.3%,因此在檢測(cè)異音故障問(wèn)題上選擇SVM方法能更準(zhǔn)確地檢測(cè)出異音所屬故障類別。通過(guò)機(jī)床故障分類的檢測(cè)方法流程,可以對(duì)大多數(shù)故障問(wèn)題進(jìn)行分類診斷,大大降低因故障帶來(lái)的各項(xiàng)損失。
4 結(jié)語(yǔ)
文章提出一種基于聲音特征融合與OCSVM的異音故障分類診斷方法,并將該方法應(yīng)用于機(jī)床實(shí)際工作,進(jìn)行了故障診斷與分類,由實(shí)驗(yàn)結(jié)果得到以下結(jié)論:
(1)將LPCC與MFCC提取的特征進(jìn)行融合可以獲得機(jī)床聲音數(shù)據(jù)更完整的各項(xiàng)信息,故障診斷準(zhǔn)確率分別比MFCC和LPCC高12.2%和6.8%,說(shuō)明對(duì)數(shù)據(jù)進(jìn)行特征融合會(huì)獲得更好的診斷效果。
(2)對(duì)比t-SNE、UMAP和PCA降維方法,通過(guò)機(jī)床故障診斷實(shí)驗(yàn)結(jié)果可見(jiàn),無(wú)論是故障診斷準(zhǔn)確率還是診斷時(shí)間,PCA都屬于效果更好的方法,因此使用PCA對(duì)機(jī)床數(shù)據(jù)進(jìn)行降維處理。
(3)通過(guò)機(jī)床測(cè)試數(shù)據(jù)集的故障診斷實(shí)驗(yàn)可見(jiàn),即使在樣本不均衡的情況下,OCSVM分類器的故障診斷準(zhǔn)確率也能達(dá)到96.1%,說(shuō)明該方法契合此類異常樣本難以獲取的應(yīng)用方向且環(huán)境噪音對(duì)診斷的結(jié)果影響不大。由多類故障檢測(cè)結(jié)果說(shuō)明了在機(jī)床故障分類診斷應(yīng)用上,SVM是比KNN更好的分類方法。
猜你喜歡
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
瘋狂英語(yǔ)·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
中國(guó)生物醫(yī)學(xué)工程學(xué)報(bào)(2017年6期)2017-02-10 05:11:45
汽車維護(hù)與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
汽車維護(hù)與修理(2015年2期)2015-02-28 12:15:39
噪聲與振動(dòng)控制(2015年4期)2015-01-01 07:08:21
