基于YOLOv5s模型的車輛類型檢測算法
2022-10-11 04:32:52李建義
廊坊師范學院學報(自然科學版) 2022年3期
劉 鶴,李建義
(北華航天工業學院,河北 廊坊 065000)
0 引言
隨著近些年私家車數量的增加,交通問題日益凸顯,智慧交通對滿足人們的生活需求、提高交通運輸效率具有重要意義[1]。車輛類型檢測是智慧交通的重要部分,例如在高速路口根據車輛類型會有不同的收費標準。目前,車輛類型檢測的方法主要有基于CNN的車輛目標檢測[2]、基于改進的Harris角點檢測的車型識別[3]、基于SVM的車型檢測和識別算法[4]、基于特征融合的車型檢測。基于CNN與SVM的算法特征維數高、訓練時間長,而且在面對較多車輛時會有遺漏情況。基于改進的Harris角點檢測與基于特征融合的車型檢測實時性差,不能及時檢測車輛類型。因此,以上算法都不能滿足車輛類型實時檢測的需求。
為解決以上問題,本文選擇目前流行的YO‐LOv5s[5]為基礎框架,進一步高效地檢測識別車輛類型。針對YOLOv5s算法使用Giou[6]作為損失函數時,如果兩個目標邊界框出現包含關系,或長寬高相同,差集會變為0,無法評估相對位置等問題,提出使用Ciou[7]作為損失函數代替Giou,既提高了模型訓練的速度,又進一步改善了模型的精度。仿真實驗結果表明:該改進方法對車輛類型的檢測具有較好的實時性和較高的精確度。
1 YOLOv5s網絡模型
YOLOv5是一種單階段目標檢測算法,它和YOLOv3、YOLOv4整體布局相似,由Input、Back‐bone、Neck、Prediction四部分構成[8],車輛檢測流程結構如圖1。v5系列總共有四個版本:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x,這四個版本在結構上一致,其中YOLOv5s網絡最小[9],精確度不如其余三種,但是速度最快。其余三種網絡在YOLOv5s的基礎上不斷加深和加寬,精確度高但是速度較慢。由于本次實驗是對車輛的類型進行檢測,對檢測的速度有較高的要求,因此,選擇YOLOv5s作為本實驗目標檢驗的框架基礎。
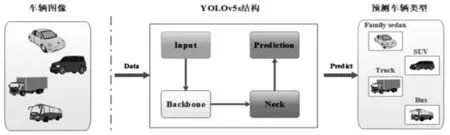
圖1 車輛檢測流程結構
1.1 Input區域
YOLOv5s輸入端結構如圖2所示,它采用Mo‐saic數據增強的方式[10],將輸入的四張汽車圖像進行隨機縮放、裁剪、排布拼接[11]。YOLOv5s針對采集的車輛圖像信息不一致問題,采用自適應圖片縮放的方式,將輸入的汽車圖像縮放或填充到608*608尺寸。對統一長寬的汽車圖像設定初始長寬的錨框,每次訓練將預測車型錨框與真實錨框比對,計算兩者差距并更新網絡參數,自適應找出最佳錨框。

圖2 Input結構
1.2 Backbone區域
Backbone[12]是YOLOv5s網絡的主干部分,車輛圖像依次經過一次Focus結構,X次CBL、CSP1[13]結構和一次SPP[14]結構。
Focus結構的主要工作是對車輛圖像進行切片操作,結構如圖3所示。Focus將3*608*608切成四個3*304*304的切片,然后采用Concat拼接這四個切片,經過卷積層提取車輛特征。最后使用Leaky_relu激活函數輸出一個沒有信息丟失的采樣特征圖[15]。
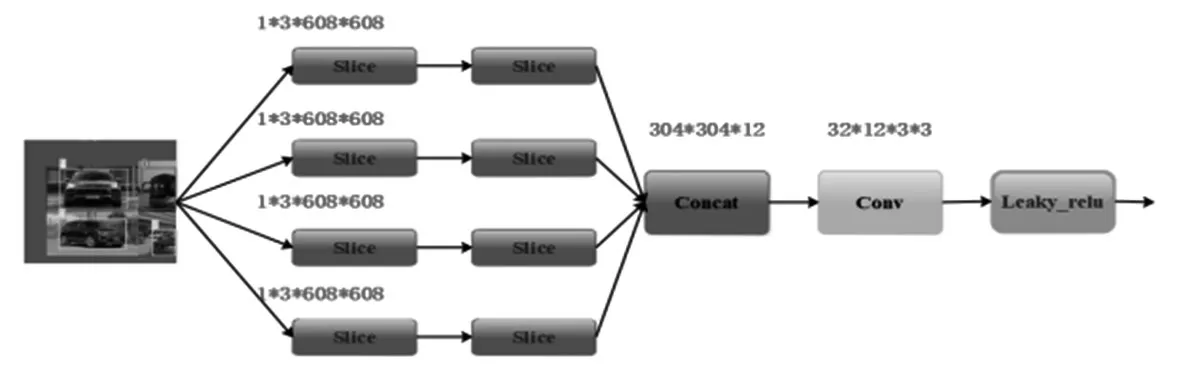
圖3 Focus結構
經Focus輸出的車輛采樣特征圖會依次經過X次CBL、CSP1結構。CBL由卷積層、歸一化層、激活層組成,即采樣特征圖先經過卷積層進一步提取不同的特征,其次經過歸一化層,實現特征結果的歸一化,最后經過Leaky_relu激活函數輸出結果到CSP1。
CSP1的結構如圖4所示,CSP1的工作是提取特征,一個CSP1由兩條“路徑”組成,其中一條只有一個卷積層,另一條包含一個或多個CBL塊、多個殘差組件和一個卷積層。兩條“路徑”由Concat層拼接經歸一化層和激活函數Leaky_relu輸出。

圖4 CSP1結構
SPP結構由Conv、max pooling和Concat三部分組成,結構如圖5所示。SPP接收的圖像尺寸為512*20*20,將輸入圖像通過Conv層進行特征提取之后輸出尺寸為256*20*20,將提取后的特征在fea‐ture map上選取候選框,再經過四個max pooling提取固定大小特征,最后由Concat層拼接輸出。

圖5 SPP結構
1.3 Neck區域和Prediction區域
Neck區域采用FPN[16]的反向擴展結構FPN+PAN[17],如圖6所示。自頂向下傳遞的FPN結構與兩個自底向上的PAN結構結合操作,極大加強了網絡特征的融合能力。

圖6 FPN+PAN結構
Prediction負責將輸入的車輛圖像進行識別和分類。Prediction有三個輸出,每個輸出都是由卷積層與全連接層構成。針對每個輸出,使用非最大抑制(NMS)[18]算法來消除多目標檢測。
2 YOLOv5s網絡模型改進
損失函數作為評價模型預測值和真實值差距的關鍵指標,損失函數和構建模型的性能呈正相關關系。傳統YOLOv5s采用Giou作為損失函數。不同于Iou只關注重疊區域,對于非重合區域Giou同樣關注,但是當兩個目標邊界框出現包含關系,或長寬高相同時,差集為0,Giou退化成Iou,無法評估相對位置,同時,Giou收斂速度慢。為解決此問題,本文采用Ciou作為損失函數,它可以充分考慮重疊面積、中心點距離、長寬比3個幾何參數,使檢測框更加符合真實框。因此,本實驗采用基于Ciou損失函數的YOLOv5s模型。
Ciou損失函數公式如下:

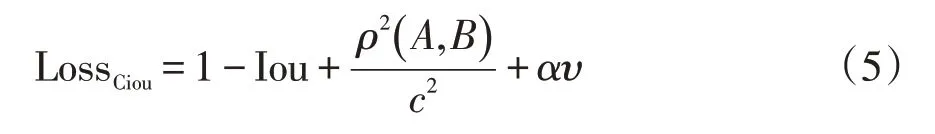
式中α是權重函數;υ用來度量寬高比的一致性;ρ2(A,B)表示A(預測框)與B(目標框)的中心距離;c代表A與B最小并區間對角線距離;Iou等于A和B的交集除以二者的并集是矩形對角線傾斜角度。
3 仿真實驗對比及分析
3.1 數據集介紹
本次實驗自制了一個車輛信息數據集,包括家用轎車、公交車、消防車、卡車、吉普車、SUV、面包車、出租車八種車型。車輛數據來自街道、校園和汽車展廳,共1260張圖像,如圖7所示。通過使用LabelImg軟件將收集的圖片標注出車輛類別,并將每個圖像標注好的結果以.txt文件保存,該文件名和圖像名稱一致,包含對象的類別,對象中心的坐標、寬度和高度。本次實驗將以7:3的比例劃分訓練集和測試集,分別用于本實驗模型的訓練和測試。

圖7 車輛數據集圖例
3.2 YOLOv5s網絡訓練
本實驗運行環境:操作系統為Centos7,CPU為Intel Xeon Platinum8156,GPU為NVIDIA GeForce RTX 3080 Ti,內存16G,通過Python編程語言實現,使用框架為Pytorch。
為了查看訓練周期對訓練模型的影響,本實驗對同一數據集訓練四次:25、50、75和100個周期,實驗周期對比結果見表1。
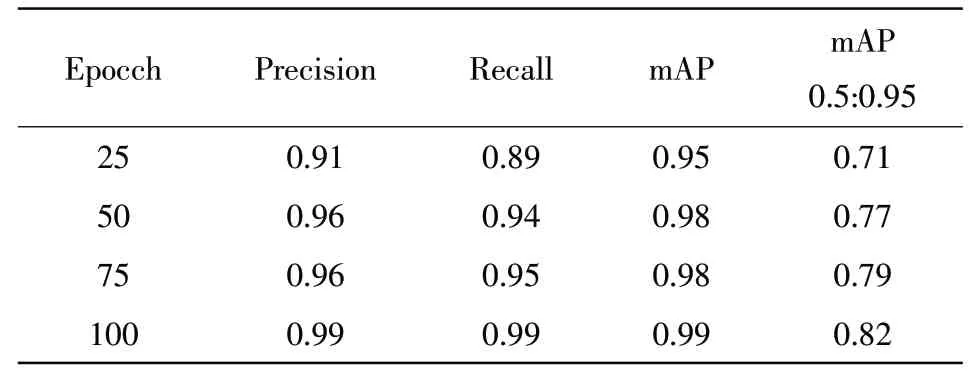
表1 周期對比結果
從表1中可以看出,訓練的周期長短影響YO‐LOv5訓練模型的質量,當接近100個周期時,參數增加幅度極低,因此,epochs為100時是最佳次數。
3.3 模型評估指標
本實驗使用mAP作為模型的評價指標,mAP值越大說明車輛類型檢測識別率越好,mAP公式如下:

其中,AP代表平均精度,是P-R曲線下的面積,mAP為AP的平均值。P表示預測為正例的樣本中有多少是預測正確的,R表示真正為正例的樣本中有多少被預測正確。P和R公式如下:


3.4 測試結果
本實驗的YOLOv5s與傳統YOLOv5s在訓練100個epochs后,新YOLOv5s的mAP收斂速度明顯高于YOLOv5s,而且起伏較小,如圖8所示。
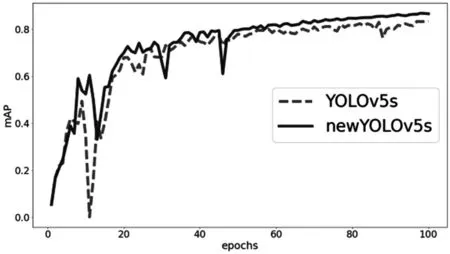
圖8 mAP對比結果
從上圖可以得出,本實驗中的mAP值在60輪時就已經比傳統YOLOv5s在100輪的效果要好,可以節省大量的訓練時間,在有限時間下改進YOLOv5s會取得更加顯著的效果。
除mAP外,本實驗訓練模型的Precision、Recall分別能達到0.995和0.996,如圖9所示。
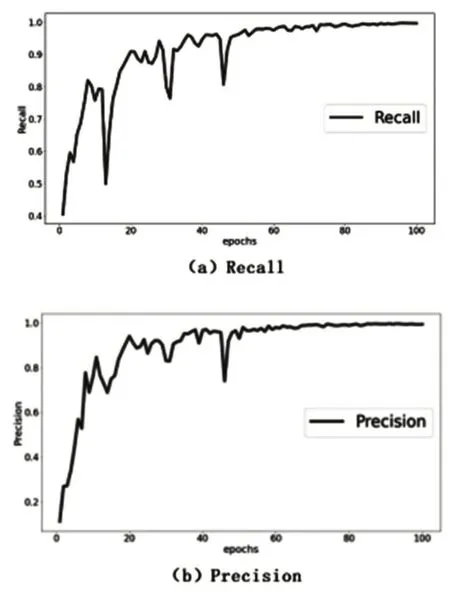
圖9 Precision和Recall結果
為了直觀檢驗訓練車輛檢測模型的效果,隨機從測試集抽取部分圖片作為輸入,這些圖片包含多種角度、多種拍攝距離下的交通照片,結果如圖10所示。從圖中可以看到能夠準確識別消防車、公交車和私家車,證明了本實驗可以精確的識別車輛類型,滿足實際交通應用需求。

圖10 優化后檢測效果
4 結語
本實驗為滿足智能交通中對車輛類型檢測精度以及速度的需求,提出以YOLOv5s為基礎框架,用Ciou代替Giou作為損失函數。實驗結果表明,本實驗改進的YOLOv5s在mAP上明顯優于原YO‐LOv5s,且收斂速度提升20%,實現了速度與精度兩個方面的提升,非常適用于車輛類型識別的任務。
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
哲學評論(2021年2期)2021-08-22 01:53:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
