面向科普翻譯的語料庫建設與研究:應用及展望
2022-10-13 03:06:02郭鴻杰
科普創作 2022年3期
郭鴻杰 盧 靜
(上海財經大學外國語學院,上海 200433)
一、引言
科學往往是涉及艱澀的概念、術語、知識、信息等的結構嚴謹的知識系統。把科學普及到社會大眾(popularization of science),從而促成“公眾理解科學”(public understanding of science),再拓展為科學傳播(science communication),由此來提升社會大眾的科學素養(scientific literacy),是信息時代的一件大事。當今社會,大部分科學文獻是通過英語來完成的。因此,要創作更多適合本土文化的科普作品,我國的科學家和科普工作者仍任重道遠。事實上,從傳播的本質來看,科普亦與翻譯有著內在的相似性和相通性。近年來,國內出版的科普譯作數量可觀,然而其翻譯質量魚龍混雜,不少英語科普原著常常以“遇人不淑”終場。特別要指出的是,相比其他應用翻譯研究,科普翻譯研究尚未真正形成體系,仍處于極度“欠發達”階段,這無疑是當代翻譯理論研究的一大缺憾。
近年來,語料庫作為一種新的研究范式和研究手段廣泛應用于語言學、翻譯學、文學、傳播學等諸多人文社科領域,且取得了重要的研究成果。筆者認為,語料庫對與科普翻譯相關的研究亦具有重要的理論意義和應用價值。基于語料庫的科普翻譯研究涉及科普翻譯語料庫的建設、科普翻譯策略及其制約機制研究、科普話語特征研究,以及術語提取、機器翻譯訓練、科普翻譯教學平臺建設等應用研究。此外,基于語料庫的研究范式在很大程度上彌補了科普翻譯在定量研究方面的短板,推動了科普翻譯研究從規約性研究范式向描述性研究范式的轉變,拓寬了科普翻譯的研究空間和疆界。特別值得一提的是,值此中國科技蓬勃發展、科技文化蔚然成風之際,推進中國科技“走出去”,向世界傳播中國科技文明,是時代所向。基于英漢科普平行語料庫的逆向檢索功能亦有助于我們熟悉西方的科技話語模式,從而借帆出海,提升中國科技外譯質量,推動中國科技國際化。
二、科普翻譯語料庫建設概覽
廖七一指出,西方翻譯研究的理論突破往往伴隨著研究范式的變遷。數智時代下基于語料庫的科普翻譯研究呈現出強大的生命力。縱覽相關文獻,科普語料庫建設已成規模,業已公開的科普平行語料庫建設如表1所示。
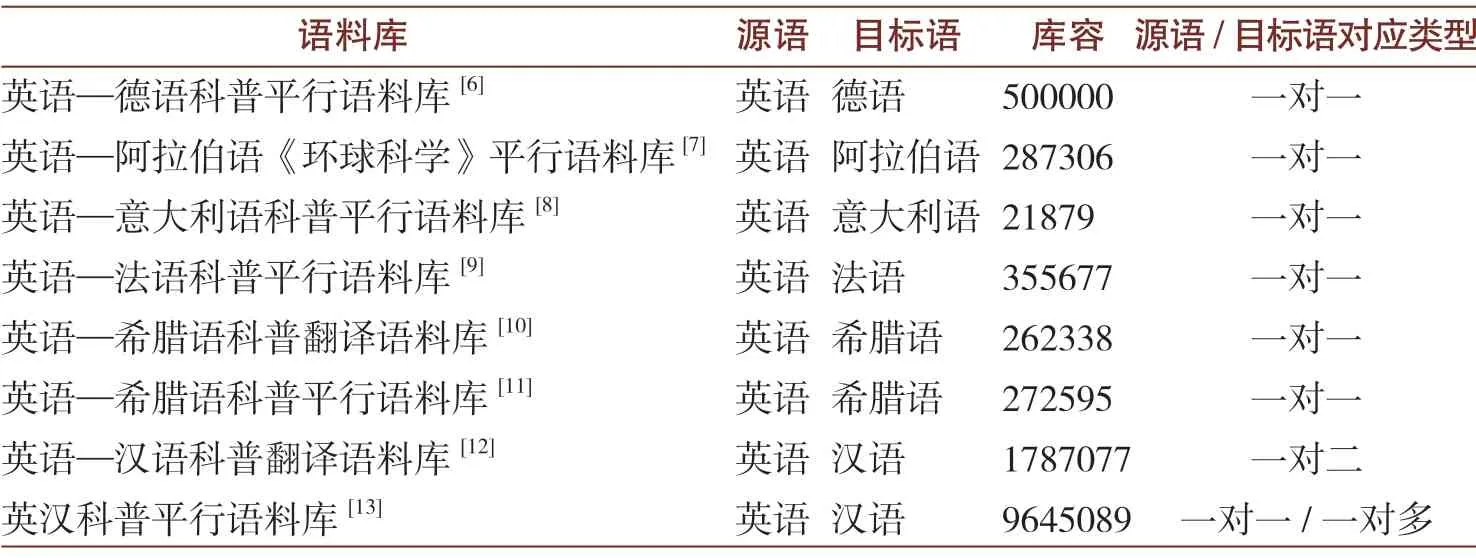
表1 國內外主要科普平行語料庫一覽表
總體上,國內外知名科普語料庫因建庫目的不同,規模參差不齊,從數萬詞到近千萬詞不等,語料大多為單譯本。與之相應,學界也開展了基于語料庫的科普翻譯研究。下文將簡要介紹一下筆者正在主持建設的英漢科普平行語料 庫(English-Chinese Parallel Corpus of Popular Science,簡稱ECPCPS)。
第一,ECPCPS主要收集了20世紀80年代以來源自科普書籍和科普雜志的英漢雙語語料,其中包括2002年以來已評選11屆的吳大猷科普譯著獎中的英譯中作品,如《費馬最后定理》(上海譯文出版社1998年版)、《魔鬼出沒的世界》(吉林人民出版社1998年版)、《大崩壞:人類社會的明天》(時報文化出版有限公司2006年版)、《人類大歷史:從野獸到扮演上帝》(天下文化出版公司2014年版)等,以及《中國近代科學的文化史》(上海古籍出版社2009年版)、《萬物簡史》(接力出版社2005年版)、《數字生存》(海南出版社1997年版)等其他具有影響力的科普雙語文本,還包括《自然》)、《科學新聞》()、《新科學家》()、《科學美國人》()等報紙雜志上登載的科普文章及漢語譯文。目前,科普語料庫仍在擴容,現已超過千萬字/詞,包括中國大陸、中國臺灣兩個子庫,有上千個英漢科普對應文本,保證每個文本的語篇盡量完整,且單個英漢對應語篇的字/詞數上限約為45000。
第二,對ECPCPS語料庫進行統計,結果顯示源語單詞和目標語漢字的比例是1∶1.64。表2為我們所統計到的幾個大型平行語料庫的英語單詞、漢字數量對比結果。

表2 平行語料庫英語單詞、漢字數量對比
第三,語料庫加工采用了句對齊標準,以英語源語句子為參照,分割標記為句號、分號、問號、嘆號等。若英語句子為完整的語義單元,碰到破折號、冒號等也進行了斷句處理。王克非提到,“句子仍不失為翻譯的一個主要轉換單位,特別是除文學漢譯英之外的另三類翻譯,其1∶1的句對齊比例達到80%以上……英譯漢1∶1的語句對應高于漢譯英,主要原因是漢語譯者翻譯時多參照原文的句式和標點,特別是在比較嚴肅的文本中。”根據王克非的統計結果,文學類和非文學類英譯漢的句對齊比例分別為81.9%和84.7%。而我們的科普平行語料庫統計出1∶1的句對齊語料約為84%,數據基本接近。特別值得一提的是,鑒于科普翻譯具有較強的應用性,翻譯過程中會出現不少改寫、編譯、創譯等,這對于句對齊語料加工是一項重要挑戰。
第四,ECPCPS主要收集了一對一類型的文本。鑒于某些出名的科普作品存在多個譯本的情況,如中國大陸版和中國臺灣版,ECPCPS中也收集了同一地域或不同時期的多個譯本。這不僅有利于基于平行語料庫的語言對比研究,而且有助于揭示翻譯模式以及影響翻譯策略的底層機制和動因。
三、語料庫在科普翻譯中的應用
如前文所述,語料庫為科普翻譯研究提供了一個新視角,引起了科普翻譯研究范式的變化,拓展了科普翻譯研究的深度和廣度。下文將從科普語言特征、翻譯共性、翻譯策略、翻譯應用四個方面介紹基于語料庫的科普翻譯研究現狀和未來前景。
首先,譯語語料庫海量的數據有助于高效準確地獲取一些語言特征的計量結果,在宏觀層面,包括詞單(word list)、關鍵詞單(keyword list)、詞頻分布(frequency profile)、詞頻譜(frequency spectra)、平均詞長(mean word length)、詞串(cluster)、詞覆蓋率(coverage)、詞匯密度(density)、平均句長(mean sentence length)等;在微觀層面,可以分析主題語氣詞、量詞、固定習語、句型、語用、隱喻、篇章等內容。科普讀物為吸引大眾讀者,常常比科技文本寫得更為生動有趣,通俗易讀,從而讓讀者享受這種知性的樂趣。通過語料庫可以容易地捕捉到這些語言特征。比如,“摹聲詞”在科普讀物中的出現頻率是十分高的,略舉幾例如下:
They can snap,whistle,hum,vibrate,boom,and whine.
(羽毛)能發出啪嚓聲、哨笛聲、嗡嗡聲、顫動聲、隆隆聲與刺耳的尖銳聲。(《羽的奇跡》)
Tigers did not purr at all but instead emitted “a peculiar short snuffle,accompanied by the closure of the eyelids” when happy.
老虎完全不會發出呼嚕聲,不過開心的時候,會用鼻子發出“一種特別的短嗤聲,然后闔上雙眼”。(《動物也瘋狂》)
Sooner or later,there will be real human hardware,great whirring,clicking cabinets intelligent enough to read magazines and vote,able to think rings around the rest of us.
遲早有一天,會出現真正與人一樣的硬件,出現一些嗡嗡叫、嘁哩咔嚓響的聰明的大盒子,能讀雜志,能參加選舉,腦瓜轉得極快,快得我們沒法比。(《細胞生命的禮贊》)
大自然的神秘奇妙時時讓我們嘆為觀止。諸如“摹聲詞”之類的語言,生動貼切,能夠幫助讀者享受到閱讀之趣,感受到語言之美。徐彬、郭紅梅也提出,閱讀、翻譯當代科普書籍,我們會越來越感覺許多一流的科普作品也是一流的科學散文作品。
其次,翻譯語言早就引起了學者的研究興趣。學界一般持兩種觀點。一種觀點認為翻譯文本是一種可預測的語言變體(variety),這歸因于受翻譯為媒介的間接語言接觸的影響。這種變體常被稱為“第三碼”(third code)。莫娜·貝克(Mona Baker)提到,在分析譯本語言時完全可以把源語拋開進行分析,并在此基礎上提出了翻譯共性假設(translation universals),即相對于源語和目標語原創語言,譯文具有顯化(explicitation)、簡化(simplification)、消歧(disambiguation)、規范化(normalization)等特征。另外一種觀點認為翻譯語言偏離目標語規則,被標簽為“翻譯腔”,這是一種消極的語言觀。事實上,基于語料庫的翻譯語言計量分析結果有助于客觀地呈現這種“第三碼”的共性特征,而非一種“蝴蝶標本式”的感性認識。譬如,分析翻譯語言特征的一個重要參數為詞覆蓋率,即在詞頻表中按次序選擇一定數量的單詞,計算這些單詞在總語料中所占的比例。ECPCPS中前50個常用詞的覆蓋率統計結果顯示,中國大陸譯本均高于中國臺灣譯本。由此推測,中國臺灣譯本用詞更富于變化。在此基礎上,我們將基于譯本的相關數據與漢語原創文本比較,結果見圖1。其中,原創文本的數據參照了彭臨桂有關兩岸小說譯本詞匯覆蓋率的數據。
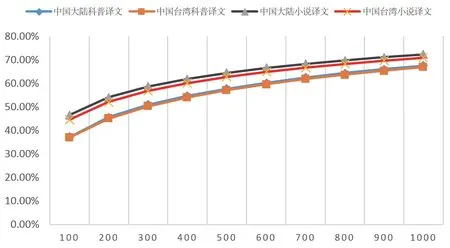
圖1 兩岸科普和小說文體譯本詞匯覆蓋率差異
依上圖,4條折線呈現出三個分布趨勢:第一,無論是中國大陸譯本,還是中國臺灣譯本,小說譯本的詞匯覆蓋率顯著高于科普譯本,可見科普文本的詞匯變化更大;第二,詞匯覆蓋率的地域差異在小說文本中差異更加顯著,科普文本的詞匯覆蓋率特征比較穩定;第三,相似之處是,兩種文體詞匯覆蓋率的差異在前300個常用詞最顯著,隨著詞頻的減少,差距越來越小。
再其次,基于語料庫的研究還有助于從語素、詞語、習語、隱喻等多個層面分析科普翻譯的策略和技巧。比如,一詞多譯是科普中常見的翻譯策略。海量的自然語言例證能更清楚地顯示該詞或詞語豐富的語義特征。下文將以語料庫中出現的development一詞為例來說明:
Also,the rise or origination of anything by natural development,as distinguished from its production by a specific act.
或者任何事物經由自然演變的增長或初生,有別于經由特定作為而產生。(《從達爾文到愛因斯坦》)
One of the principal benefits of the development of human intelligence is our ability to understand the true nature and import of dreams.
理解夢一般的生活實質和含蓄的意思對了解人類智力進化是很有好處的。(《伊甸飛龍》)
On the other hand,the sun of Naples might be conducive to learning something about the biochemistry of the embryonic development of marine animals.
另一方面,那不勒斯的陽光倒可能有助于學習海洋動物胚胎發育生物化學。(《雙螺旋》)
These plants are threatened by lumbering,grazing,and development.
這些植物受到砍伐、放牧和開發的威脅。(《花朵的秘密生命》)
The development of a flower is one of the things we understand least about plants.
花的成長是我們對植物最不了解的部分之一。(《花朵的秘密生命》)
Drug development will change in two dramatic ways.
藥物的研制工作將在兩方面徹底改觀。(《細胞叛逆者:癌癥的起源》)
由此,不同主題內容下的代表性例句,為分析一詞多譯現象提供了重要參照。此外,語料庫還會提供影響一詞多譯的其他語言因素或非語言因素。
一般說來,人們在理解抽象艱深的新理論或新概念時,常常會提取已存的認知基模做映射(mapping)。此類以一種具體熟悉的概念結構來構造另一種陌生抽象概念的現象被稱作隱喻(metaphor)。事實上,為吸引讀者注意并增進對新概念的理解,科普文本經常使用隱喻。隱喻對形成科學觀念的重要性亦逐漸受到重視,隱喻翻譯研究也成了科普翻譯的重要話題。比如,以科普文本中英文植物詞或植物結構習語及其漢譯為例,基于ECPCPS的研究結果顯示,英漢植物詞語義的異同可大致分為重疊、錯位和空缺三種情況,在此基礎上,其翻譯策略可歸納為直譯、意譯、替換三種手段等,詳見以下各例:
He recalled a child in Memphis who was an excellent student,got influenza,and became ‘a vegetable’.
他回想起孟菲斯的一個孩子,曾是一名優秀的學生,患上流感之后卻變成了“植物人”。(《大流感》,直譯法)
Health inspectors were looking for cases among civilians“to nip the epidemic in the bud”.
衛生檢查員正在尋找平民病例以便“將流行病扼殺在搖籃中”。(《大流感》,替換法)
But numbers do not fall ripe into our laps,someone has to find and fetch them; far easier,some feel,not to bother.
有用處的數字絕不會憑空而降,一定要有人去發現、獲得,但是有些人認為,別自找麻煩會比較好。(《如何用數字唬人》,意譯法)
英漢科普平行語料庫不僅為我們提供了有關英譯漢策略的數據支撐,而且其豐富的科普英語語料亦對漢譯英實踐提供了重要參考依據。譬如,以漢語成語的英譯為例,中文為母語的譯者可能十分熟悉漢語成語,但不一定有能力將其譯成地道的英文;而英文為母語的譯者往往只能在成語字典找到直譯、歷史典故或是冗長的解釋。如果從回譯(back translation)的視角來看,英漢平行語料庫的逆向搜索功能則在某種程度能夠彌補這種翻譯的缺憾。比如,以“生死攸關”這個成語為例,我們通過檢索漢語譯文,會發現其對應的英語表達方式靈活多樣,結果見表3所示。

表3 部分科普作品中與“生死攸關”相關的英語表達
“生死攸關”的英語對應形式包括單詞、習語、短語、復合詞等,而且語法功能也不完全能對號入座,包括名詞(短語)、表語性形容詞、描繪性形容詞等。顯而易見,英語表達靈活,追求變化,不拘泥于某一固定結構。所以,雙語平行語料以及英語源語語料無疑對提高中譯英質量具有一定的啟發意義和參考價值。
最后,從翻譯應用來看,科普翻譯語料庫的價值主要體現在機助翻譯、機器翻譯、檢索平臺三個方面。加工好的句對齊語料除了用于構建平行語料庫或檢索平臺外,還可以用作翻譯記憶庫(translation memeory),協助人機翻譯。ECPCPS語料庫主要分為五大子庫,即自然科學庫、生命醫學庫、地球環保庫、技術發明庫、科技教育庫。每個子庫下又分為若干小類。例如,自然科學包括化學能源、數學統計、物理機械、宇宙航空、信息智能等,這樣可以確保語料內容豐富,包羅萬象,從而在借助Trados等機輔翻譯工具進行人機協同翻譯時,就可以根據翻譯的題材調取各個主題內容下的翻譯記憶庫。因此,無論從主題相關性,還是儲存的高質量句對齊語料來看,都會大大提升翻譯效率。
人工智能時代下數智技術應用日益廣泛是科普翻譯無法回避的現實,機器翻譯已經承擔了譯者以前大量重復枯燥的勞動。因此,機器學習或深度學習模型的應用,將為科普翻譯提供另一種新視野,即呈現出更為細膩的數字信息,進而幫助識別大數據科普語料庫框架下科普翻譯的語義內涵。而基于高質量精準翻譯語料,借助于深度神經網絡機器翻譯模型,可以訓練機器翻譯的深度和精準度。
目前,我們已經根據英漢科普平行語料庫,開發了網絡共享檢索平臺(SUFE-Corpus),為科普翻譯愛好者或者譯者提供瀏覽、檢索、統計等各項功能,深化智能化、專業性、共享型資源建設,如圖2所示。

圖2 SUFE-Corpus英漢科普翻譯檢索平臺
此外,科技術語是科普語篇進行敘述和描寫的重要手段。在技術層面,語料庫通過提取科普術語,建立術語庫,規范術語譯名,有助于訓練機器翻譯,推動雙語科普術語庫的構建,將實現術語查詢、歸類、對照、統計等功能;在語言層面上,基于對比短語學的理論框架,分析雙語術語在構詞理據、形式結構、功能關系、搭配句法、隱喻認知層面的異同,以及通用詞匯和科技術語的轉換機制;在翻譯層面上,探討術語翻譯策略選擇的國際化與民族化、術語譯名的規范化和本地化等。
在翻譯教育背景下,語料庫建設亦與翻譯教學存在天然契合。眾所周知,可比語料庫(comparable corpus)已經應用于翻譯教學。相比之下,平行語料庫應用于翻譯培訓的潛力尚未開發。事實上,越來越多的學者提出,平行語料庫可以應用于開發翻譯教學案例庫,輔助教材編寫、詞典編纂等,從而解決資源短板和時效瓶頸等問題。另外,基于語料庫的定量研究結果對于翻譯質量評估亦具有重要的借鑒意義。
四、結語
數智時代下的雙語語料庫建設在數字人文基礎建設中大有作為。構建一個動態性、多維度、多層次的科普翻譯語料庫有助于把科普翻譯置于一個大歷史背景中去觀照,從而有助于準確把握科普翻譯與時代背景、意識形態、地域文化、譯者主體等社會因素之間的互動關系。這不僅有助于科普翻譯學科體系的建設,而且也有助于激發科普翻譯研究的多學科交叉與多元化突破。基于語料庫的科普翻譯研究方興未艾,將來可以在以下幾個方面繼續探索,如研發語料標注系統(如翻譯策略的標注、句法系統的標注等)、術語抽取、機器翻譯訓練的效率,科普翻譯在個別語言中呈現出何種異質性,在跨語言中又呈現何種同一性,原創語言和翻譯語言的隱喻性表達差異,如何將可比語料庫和平行語料庫結合并更有效地應用于“以譯者為中心”的翻譯教學模式,以及基于語料庫的翻譯質量評估等方面。此外,科普翻譯語言會對科普原創語言乃至現代漢語的詞匯、構詞,甚至句法帶來什么樣的影響等話題,也仍有十分廣闊的研究空間。
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
文苑(2020年4期)2020-05-30 12:35:30
科技傳播(2019年22期)2020-01-14 03:06:54
制造技術與機床(2019年10期)2019-10-26 02:48:08
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
電子制作(2018年18期)2018-11-14 01:48:06
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
小學教學參考(2015年20期)2016-01-15 08:44:38
