面向GPU 的直方圖統計圖像增強并行算法
2022-10-16 05:50:46肖漢孫陸鵬李彩林周清雷
計算機與生活 2022年10期
肖漢,孫陸鵬,李彩林,周清雷
1.鄭州師范學院 信息科學與技術學院,鄭州450044
2.山東理工大學 建筑工程學院,山東 淄博255000
3.鄭州大學 計算機與人工智能學院,鄭州450001
隨著計算機技術的發展,數字圖像處理系統應用在安全監控、智能識別和航天遙感等眾多領域。由于圖像采集容易受到光照以及設備質量等因素的影響,有些圖像會存在例如,圖像對比度較低、模糊等質量問題。這些質量較差的圖像灰度動態范圍窄,不能很好展現圖像的細節。圖像增強技術可以通過對圖像信息分布規律的再調整以改善圖像質量。傳統的直方圖均衡方法是一種典型的基于統計學的圖像增強技術。該方法數學原理簡單,計算方便,理論基礎清晰。但是它存在噪聲大、細節損失嚴重等不足,在處理過程中還易出現飽和失真等問題。在充分考慮信息分布與人眼一致性的前提下,各種改進的直方圖統計局部增強方法可以對圖像信息實現較好的合理分配。圖像局部增強可以達到提高圖像細節的清晰度,突出圖像中需要的信息,改善圖像的視覺效果,有利于對圖像做進一步的處理。然而,隨著圖像規模的增加,在不改變算法復雜度的情況下,算法的時間成本將會成倍增長,已無法滿足大數據時代下快速處理的需求。
近些年來,CPU雖然有了很大的發展,但還是顯示出了其處理性能在功耗墻、存儲墻、頻率墻和過低的指令級并行等方面的限制。圖形處理器(graphics processing units,GPU)在數據并行上具有強大的浮點運算能力和存 儲帶寬。2020 年5 月NVIDIA發布的基于最新一代GPU 架構“Ampere”的Tesla A100,單精度和雙精度浮點計算能力分別可以達到19.5 TFLOPS和9.7 TFLOPS,帶寬1 555 GB/s。GPU 作為一種新型的高性能科學計算設備開始進入人們的視野。與CPU 相比,GPU 具有突出的性能優勢。
因此,本文將GPU 并行計算和直方圖統計算法相結合,著重研究在CPU+GPU 協同計算模型下,局部增強算法如何利用GPU 并行計算資源完成大像幅圖像的實時處理,從而驗證在該協同計算結構下圖像處理算法對于大規模圖像的運行效率。該文的主要貢獻是通過分析算法的執行特征,根據圖像數據的鄰接結構,設計了一種基于統一計算設備架構(compute unified device architecture,CUDA)的直方圖統計圖像增強并行算法,并實現了直方圖統計算法在CUDA 計算平臺上的naive 版本。基于GPU 的直方圖統計并行算法相比單線程CPU 直方圖統計算法獲得的加速比達到了261.35倍。
1 相關基礎與算法分析
1.1 研究現狀
王化喆等采用基于直方圖統計的局部圖像增強算法,取得了較好的圖像處理質量。Lei等通過對邊緣可靠度的直方圖統計,提出了一種快速可靠的二維相位圖展開算法,可以達到準實時性能。Yang等提出了一種多屬性統計直方圖用于圖像的自動配準,對噪聲和變化的網格分辨率具有魯棒性。Chu等利用直方圖統計方法構造了一個完整的紋理描述符,用于合成孔徑雷達圖像的分類,在斑點噪聲和極低的信噪比方面更具魯棒性。王勇等通過將亮度控制和直方圖分區域均衡進行結合,實現了改進的直方圖統計算法,具有良好的視覺效果。Ye等通過在全局方式的對比度差異的約束下進行局部增強,提出了一種用于在線魚類行為監測的自動圖像增強方法,避免了假陽性檢測。Zhu等運用連通域的直方圖統計量來識別和統計儲糧中的昆蟲,實現了昆蟲識別計數方法。周啟雙等利用直方圖原理,實現了基于標準差改進和局部均值的自適應直方圖統計算法,影像局部對比度增強。He等采用texton 聚類和直方圖統計等策略,提出了一種新的用于合成孔徑雷達圖像分類的統計分布紋理特征。呂新正等提出了一種改進的脈沖分選算法,算法采用直方圖統計和PRI(pulse repetition interval)變換相結合的方法,采用多DSP(digital signal processor)并行處理的方法提高了運算速度。Yang等提出了一種結合強度梯度和強度統計直方圖的標記邊緣檢測器,提高了道路標記檢測的平均召回率和準確率。胡英帥通過將極坐標直方圖統計在CUDA 平臺上進行并行化,Shape Context算法的速度得到很大提高。Karbowiak通過使用圖像直方圖實現了圖像銳化和更改顏色強度的變換,在GPU 上實現了自動圖像標簽算法并提高了效率。Gocho等提出了一種基于GPU 的高效SAR 圖像變化檢測分析器,用于對子圖像進行直方圖分析以實現SAR 圖像的變化檢測,獲得了57.5 倍加速比。裴浩等提出了基于GPU 的直方圖并行算法,算法用于實現三維空間數據距離的計算,獲得了18 倍的性能提升。陳坤等利用現場可編程門陣列(field programmable gate array,FPGA)設計了圖像直方圖統計算法,提高了數據處理能力和處理速度。
目前國內外大多數研究工作集中在將傳統的或改進的直方圖統計算法應用到各種專業領域中,從而改善了圖像增強效果,增強了圖像對比度。有部分研究成果利用GPU實現了直方圖統計算法,在應用系統中取得了幾十倍的性能提高。還有部分學者基于FPGA平臺提出了直方圖統計并行算法,提高了算法處理速度。總體來看,在提高直方圖統計局部增強算法運算效率方面的研究成果很少,速度的提升也不高。
1.2 CUDA 并行計算平臺
CUDA 的應用系統是GPU 和CPU 的混合代碼系統。在執行CUDA 系統時,主機端執行的二進制代碼在調用核函數時需要將設備端代碼通過CUDA API傳給設備端。GPU 傳給CUDA API 的設備端代碼不一定是二進制代碼CUBIN,也可能是運行于JIT 動態編譯器上的匯編形式的PTX(parallel thread execution)代碼。最后傳到設備上的是適合具體GPU 的二進制代碼,其中的信息多于PTX 或者CUBIN,這是因為CUBIN 或者PTX 只包含了線程塊一級的信息,而不包括整個網格的信息。目前,在GPU 上可以運行的指令長度仍然有限制,不能超過兩百萬條PTX指令。GPU 端二進制代碼主要包括網格的維度和線程塊的維度,每個線程塊使用的資源數量,要運行的指令以及常數存儲器中的數據。
執行內核的線程可以訪問與線程的生存期相同的高性能線程寄存器。每個線程塊都有一個共享存儲器(對該塊的所有線程可見),具有該塊的生存期。只要同一塊的線程沒有沖突訪問,共享存儲器就與寄存器一樣快。所有線程都可以隨機訪問具有應用程序生命周期的全局存儲器,即數據駐留在全局存儲器中,用于多次內核啟動。通常,全局存儲器比訪問寄存器或共享存儲器慢得多。當相同halfwarp 的線程同時訪問全局存儲器時,如果被訪問的存儲器位于相同的全局存儲器段中,則可以將訪問合并為單個存儲器事務。如果不是,則同時訪問導致多個順序存儲器傳輸。
1.3 直方圖統計關鍵技術原理
設為在區間[0,-1]內代表灰度值的一個離散隨機變量,并設(r)表示對應于r值的歸一化直方圖分量。關于圖像均值的階矩定義為:

其中,是的全局均值,即圖像中像素點的平均灰度。
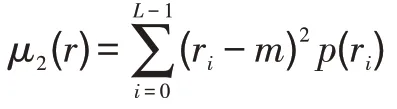
令(,) 表示給定圖像中任意像素的坐標,S表示規定大小的以(,)為中心的鄰域。該鄰域中像素的均值為:

鄰域像素的方差為:
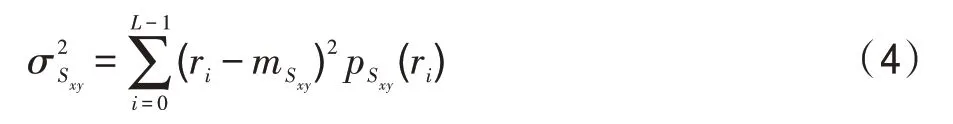


令(,)表示在圖像分辨率為×的像素點(,)處的灰度值,(,)表示增強后的圖像灰度值。對于=0,1,…,-1和=0,1,…,-1,有:其中,、、是小于1的正常數,是灰度放大系數。

使用模板參與計算,這在圖像處理的算法中有大量應用。這些算法有一個相同的運算特征:在對某個像素點進行處理時,需要其模板覆蓋范圍下的鄰域像素點的信息。因此,算法在執行時,需要依據模板大小遍歷模板范圍內的圖像像素。在圖像的邊界區域運用模板遍歷圖像時,判斷的情況尤為復雜。此時,模板覆蓋的圖像區域可能已經越過了圖像邊界。
核函數的邏輯簡潔,避免使用邏輯分支控制語句和循環體較短的循環語句,這是并行計算系統性能優化的一個準則。因此,對邊界的處理采用傳統的判斷邊界處理法將嚴重影響系統性能。根據模板的信息,并行算法采用顯式擴充邊界法來處理圖像。圖像在完成邊界擴充后,模板只需在原圖像大小范圍內遍歷。此時,在擴充圖像中不會發生遍歷越界問題。核函數的處理邏輯可實現歸一化,無需判斷邊界。直方圖統計并行算法采用偶拓展的顯式擴邊方式進行圖像擴充,即第0列被復制到左拓展的第1 列,第1 列被復制到向左拓展的第2 列,以此類推進行四條邊界上的拓展。采用邊緣像素點附近的點對原圖像邊界進行擴充,由于像素點鄰近,其相似度很高。并且使用圖像自身的像素點,既很好地解決了邊緣像素點的計算問題,也沒有違背圖像增強算法的理念。


圖1 圖像拓展示意圖Fig.1 Schematic diagram of image expansion
1.4 算法并行分析
對于總灰度級數為的圖像進行的直方圖統計算法主要包括以下模塊:(1)初始化直方圖統計圖像。該操作需要對整體圖像中所有像素點都執行一次,其時間復雜度為(×)。(2)灰度級概率估計計算。要將圖像中所有像素點的灰度值分配到某一個灰度級中進行累加,需要執行×次,其時間復雜度為(×)。然后求出每個灰度級的概率估計,其時間復雜度為()。因此,本步驟的時間復雜度為(×+)。(3)圖像均值求解。要求計算整體圖像的灰度均值和濾波窗口覆蓋下的子圖像塊的灰度均值,其時間復雜度為()。(4)圖像方差求解。要求計算整體圖像的灰度方差值和濾波窗口覆蓋下的子圖像塊的灰度方差值,其時間復雜度為()。(5)圖像擴充。由于需要分別進行原圖像左右拓展、上下拓展和保留原圖像區域,該步驟的時間復雜度為(×++×/2+×/2)。(6)局部直方圖統計計算。需要對×個像素點逐個判斷是否進行灰度增強,其時間復雜度為(×)。同時計算某個像素點的局部均值和方差,其時間復雜度為(××(/4+2))。由此可得,直方圖統計算法的時間復雜度為(××),步驟(6)是該算法的核心環節。表1 為圖像直方圖統計算法主要步驟在相同條件下的運算時間。

表1 直方圖統計算法主要功能運行時間占比Table 1 Proportion of running time of main functions of histogram statistical algorithm
由表1 可見,局部直方圖統計計算功能是算法中復雜度最高、最耗時的部分,該模塊占用了系統97%以上的資源。顯著降低直方圖統計算法復雜度的關鍵是采用高效的快速局部直方圖統計方法。因此,對局部直方圖統計計算功能結構的優化設計對直方圖統計并行算法的實現有著舉足輕重的意義。
1.5 直方圖統計算法的并行提取
算法的可并行性大小與算法自身存在的任務依賴性有關。任務之間的關聯性越低,并行性效果越好,反之則效果越差。通過上面的算法分析,可以得出直方圖統計算法具有良好的并行性。具體來說,該算法包含三級并行性:
(1)像素點級并行:為了對圖像中包含的隱含特征進行局部增強,需要將圖像進行直方圖統計,對每一幅圖像的每一個像素點的處理是相互獨立的,可以并行執行。
(2)均值和方差值級并行:每個像素點的局部均值和局部方差的計算是相互獨立的,可以并行執行。
(3)窗口級并行:每個局部統計窗口的處理是相互獨立的,可以并行處理。
直方圖統計算法的并行性如圖2 所示。圖2(1)中灰色區域為原始待處理圖像區域,進行局部處理時的鄰域大小為3×3,白色區域為圖像擴充區域。每個方塊代表一個像素點。在局部直方圖統計計算步驟中,先對像素點進行處理,即求出子圖像塊1 中的均值和方差,并進行是否增強暗區的判斷等一系列操作。然后依次對,,…,,像素點進行處理。子圖像塊1…子圖像塊一系列子圖像塊之間沒有相互依賴性,因此,局部直方圖統計計算功能可進行并行化處理。

圖2 局部直方圖統計的并行性示意圖Fig.2 Parallelism diagram of local histogram statistics
由此可見,直方圖統計算法的計算量非常大并且具備良好的并行性。因此,算法特性非常適合GPU 計算平臺大規模并行的架構特點。同時,根據1.1 節對有關研究成果的分析,本文試圖采用CUDA平臺來解決在異構計算設備上利用直方圖統計圖像增強算法對海量圖像實時處理的問題。實驗數據表明,基于GPU 的直方圖統計圖像增強并行算法在保持算法精度的同時,取得了兩個數量級的性能提高。
2 基于GPU 的直方圖統計并行映射模型
2.1 并行算法描述
根據CUDA 架構的特點,設在單指令多線程(single instruction multiple thread,SIMT)模型中啟動×個線程,每一個線程只負責處理一個像素的局部直方圖統計計算,然后把灰度增強值存儲到對應的像素點位置。具體直方圖統計并行算法形式描述如下。
SIMT 模型上的直方圖統計并行算法

假設圖像像幅為×,采用GPU 的多線程對局部直方圖統計計算部分進行并行計算,一個線程負責處理一個像素點,算法的計算時間復雜度降為()。若在一次內核函數中沒有處理完所有像素點,那么每個線程需要執行內核函數至少(×)/次,其中是活動線程的數量。此時,直方圖統計圖像增強并行算法時間復雜度為((×)/×)。需要注意的是,一般GPU 中可保持的活動線程量很大,即是一個很大的值。因此,存在直方圖統計圖像增強并行算法時間復雜度((×)/×)?(××)。
2.2 計算過程
直方圖統計并行算法的執行流程如圖3 所示。

圖3 直方圖統計并行算法執行模式Fig.3 Execution mode of histogram statistical parallel algorithm
直方圖統計并行運算主要實現步驟如下:
(1)獲取設備信息和初始化設備。在當前機器上獲得支持CUDA 的設備數量,枚舉設備信息等,并設置工作設備。
(2)圖像預處理。將圖像從文件讀入主機內存。將文件頭結構、信息頭和位圖信息讀入特定的數據結構體中,從而獲得圖像的高度、寬度和大小等數據。
(3)計算級灰度級的概率密度函數,計算圖像整體統計指標全局均值和方差。
(4)圖像數據擴展和傳輸。直方圖統計算法在遍歷計算到圖像邊界時,會發生圖像數據數組越界尋址的問題,程序中可能會出現空指針異常,從而導致意想不到的錯誤。因此,采用圖像數據擴展方式避免異常發生。
系統將存儲在主存中的圖像數據傳輸到GPU 全局存儲器中。由于帶寬的限制,制約系統整體性能提升的最大瓶頸是主存與顯存之間的數據通信。因此,并行算法中采用了整體數據傳輸,而非多次分塊傳送。根據圖像像幅大小在設備上申請分配存儲空間,用于存放由GPU 計算出來的更新灰度值數據。
(5)系統調度內核函數執行直方圖統計計算。主要執行下面幾個步驟:
①確定內核函數的執行配置。根據圖像規模大小,設置網格維度和線程塊維度。
②分解圖像數據。每個線程塊完成所包含的線程需要計算的相關像素點對應點子圖像塊的有關計算。
③發起kernel,進行線程間的并行計算。每個線程完成與之相應的像素點的有關計算。
(6)更新數據讀出并顯示圖像增強結果。GPU運算結束后,還需將更新后的像素灰度值從GPU 傳回CPU。
2.3 算法的加速策略
設計內核函數kernel<<
(1)內核函數參數block 的維度為(T,T),grid 的維度為((+T-1)/T,(+T-1)/T)。、分別是圖像的高和寬,每個線程塊處理一個子圖像塊,塊內每個線程處理一個像素及其鄰域。系統開啟線程總數滿足((+T-1)/T×(+T-1)/T×T×T)>(×)。
(2)每個線程依據索引地址計算相應像素鄰域的灰度級概率密度函數,根據鄰域的灰度級概率密度函數計算出像素的局部均值和局部方差。根據像素點鄰域的局部統計特性數據判斷其是否滿足灰度值局部增強條件,并將相應更新的灰度值數據寫入主存空間的像素值,如圖4 所示。為了實現每個線程對像素點鄰域的局部統計特性的計算,在GPU 設備函數中設計了局部均值計算函數和局部方差計算函數。__device__函數是一種設備端的子函數,是由GPU 中一個線程調用的函數。

圖4 直方圖統計劃分Fig.4 Histogram statistical segmentation
在CUDA 的執行模型中,需要滿足以下三方面的限制:(1)一個流多處理器(streaming multiprocessor,SM)所能并行運行的線程總數的限制;(2)一個SM 所能并行運行的線程塊總數的限制;(3)一個線程塊所能并行運行的線程總數的限制。一個SM 所能并行運行的線程總數是確定的,為了獲得圖像直方圖統計算法最大的并行計算效率,合理地設計線程塊中所包含的線程數目是關鍵。在對圖像直方圖統計算法進行GPU 實現的過程中,GPU 中每個SM最多可以激活的線程數目為2 048。由于一個warp一次調度32 個線程,為了提高并行計算效率,一個線程塊所包含的線程數應該是32 的倍數。同時考慮線程塊中寄存器等資源的限制,設計線程塊的尺寸為16×16=256,小于線程塊中的最大線程數1 024 的限制。每個SM 運行2 048/256=8 個線程塊,小于每個SM 上最多可以激活的線程塊數32 的限制。因此,GPU 中的所有線程塊和線程都可以同時處于并行計算的狀態。
在圖像增強中進行局部直方圖處理時,由于設置的線程數量大于圖像像素的數量,每個線程和處于、平面中的像素成一一對應關系。以式(6)計算得到的線程索引作為相應像素的、維坐標,就可實現線程坐標向像素坐標的轉換。即在GPU 上進行圖像空間的像素坐標變換計算如式(6)所示。

其中,和為某個線程塊中的線程分別在和方向的索引,.和.為某個線程塊在網格中的和方向的索引,grid在和方向的維度分別為.=(+T-1)/T,.=(+T-1)/T。
2.4 優化設計
在CUDA 上實現直方圖統計并行算法的關鍵是減少數據在主機和設備之間的數據傳輸。由于主機與設備間的數據傳輸帶寬遠低于設備和設備之間的數據傳輸顯存帶寬,如果主機和設備之間數據傳輸次數過多,就會進入傳輸瓶頸而不能充分發揮GPU的并行運算能力,造成計算效率下降。為了減少數據的傳輸過程,充分利用GPU 的計算能力,把局部直方圖統計計算功能中的全部計算過程全部映射到GPU 上,減少了中間數據在主機和設備之間的換入換出操作,并把圖像增強前后的數據一次性在主機和設備之間進行傳輸。這樣就大大減少了傳輸次數,充分利用了GPU 的計算能力,提高了計算密集度。
在CUDA 計算模型中,系統為了最大限度利用SM 的計算資源,將會定期從一個warp 切換到另一個warp 進行調度線程。由于同一個warp 中的32 個線程是被綁定在一起執行同一指令,應以32 的整數倍設置每個線程塊中線程數量,并根據任務的具體情況確認線程塊每個維度上的大小。表2 中顯示了圖像像幅大小為4 357×4 872 時,在線程塊中設置不同數量線程時的系統運行時間。從中可以看出,當線程塊維度為16×16 時,系統性能最優。

表2 線程塊維度對運算速度的影響Table 2 Influence of thread block dimension on computing speed
3 性能評測和分析
3.1 實驗條件
硬件平臺配置如表3 所示。

表3 實驗環境配置Table 3 Experimental environment configuration
軟件平臺中操作系統為Microsoft Windows 10 64 bit;MATLAB R2008b;集成開發環境IDE 為Microsoft Visual Studio 2013;多核處理器支持環境OpenMP 3.0;環境支持為CUDA Toolkit 10。
3.2 實驗數據與實驗描述
串行算法使用的是C 語言實現的圖像直方圖統計圖像增強系統。直方圖統計并行算法是采用CPU多核多線程和GPU 眾核分別實現的OpenMP 并行系統和CUDA 并行系統。每種算法共執行7 組圖像,像幅分別為547×754、1 246×1 652、2 341×2 684、3 241×3 685、4 357×4 872、6 471×6 832 和8 856×8 476。圖5分別給出了不同像幅大小的直方圖統計算法串行執行與并行執行的圖像增強結果。

圖5 直方圖統計圖像增強效果Fig.5 Histogram statistics image enhancement effect
表4 給出了直方圖統計算法CPU 串行和并行執行時間的統計數據。GPU 并行執行時間分為三部分:初始化、計算和結束。因此,系統總運行時間可以用這三部分時間之和來表示,即=++。其中,是指系統初始化、讀取圖像數據到內存、為數據分配顯存空間和將數據從主存加載到GPU 等的執行時間,是指GPU 計算以及CPUGPU 間數據傳輸時間,是指把計算得到的結果寫回到指定位置的時間。
加速比是指CPU 執行串行算法的總運算時間與并行系統執行并行算法總運算時間的比值。加速比反映了相應并行計算架構下并行算法相比CPU 串行算法整體提升效率情況,可用于對實際系統速度方面的客觀評價,如表5 所示。根據表4 和加速比的定義,由表4 中第二列數據與第三列相應數據的比值可得表5 中基于OpenMP 的直方圖統計并行算法的加速比。由表4 中第二列數據與第四列相應數據的比值可得表5 中基于CUDA 的直方圖統計并行算法的加速比。

表4 直方圖統計算法運行時間對比Table 4 Comparison of running time of histogram statistical algorithm

表5 直方圖統計算法性能對比Table 5 Performance comparison of histogram statistical algorithm
3.3 驗證并行算法結果
圖像直方圖統計并行處理的目的是縮短圖像處理時間,獲得更高局部圖像增強速度。然而,如果以損失圖像質量為前提,就沒有了并行化處理的作用。下面以三組實驗圖像數據為例進行局部圖像增強效果分析。
如圖5 可見,原始鎢絲圖像中部的鎢絲和支架都很清楚并且容易分析。圖像右側即暗區域,有部分比較細微的圖像幾乎看不見。原始圖像經過串行/并行直方圖統計圖像增強處理后,在圖像右側的鎢絲,甚至鎢絲上的紋路都清晰可見。原始人體脊椎骨折圖像左部存在大片的暗淡區域,在經過串行/并行直方圖統計圖像增強處理后,在圖像左部顯示出了更多的人骨表面細節。原始月球北極圖像右上部存在大片的模糊區域,在經過串行/并行直方圖統計圖像增強處理后,在圖像右上部顯示出了更多的月球表面細節。
以上可以看出,原始圖像經過串行/并行直方圖統計處理后增強了其暗色區域,亮灰度區域被完整地保留,串行/并行處理后的圖像展示效果完全一致。
從微觀層面上看,將串行系統和并行系統處理三組實驗圖像數據得到的圖像灰度值用直方圖表示,如圖6 所示。經過分析對比,各組串/并行處理后的圖像直方圖均相同。

圖6 串/并行算法直方圖對比Fig.6 Histogram comparison of series/parallel algorithm
由此可以看出,無論是從宏觀層面還是微觀層面來看,直方圖統計串行算法和并行算法雖然在方法設計和運行時間上不同,但是在圖像處理的結果上保持一致,從而驗證了算法的正確性和可行性。
3.4 討論實驗結果
在直方圖統計并行算法的處理過程中,需要原始圖像數據的×次存儲器讀取,直方圖統計圖像增強數據的×次存儲器寫入操作。設圖像數據大小×=3 241×3 685,每個像素值分配存儲空間大小是2 Byte,因此,存儲器存取數據總量約為0.048 GB。除以kernel實際執行的時間0.000 22 s,得到的帶寬數值是218.18 GB/s,這已經接近GeForce GTX 1070 顯示存儲器的256 GB/s 帶寬了。因此,可以看出,基于CUDA 架構的直方圖統計并行算法的效率受限于全局存儲器帶寬。
從表5 可以看出,GPU 加速的直方圖統計算法性能提升明顯,但GPU并行算法的加速比隨著圖像大小的增加呈現緩慢下降的趨勢。主要原因是在CUDA并行算法實現中,CPU 負責讀取和輸出圖像數據,而這一過程并沒有加速。隨著被處理圖像大小的增加,讀取和輸出圖像數據所花費的時間也在增加。因此,CUDA 架構下的直方圖統計并行算法的性能瓶頸是顯存帶寬和主存與顯存之間數據傳輸的帶寬。
從圖7 中可以看出,同樣的算法,當計算規模較小時,CUDA 并行計算方式加速效果較為明顯,甚至出現260 倍的加速比效果。如圖像數據計算規模為3 241×3 685 時,串行算法計算時間為205 714.00 ms,OpenMP 算法計算時間為84 655.96 ms,CUDA 并行算法計算時間為787.11 ms,CUDA 并行方式計算時間遠小于傳統串行方式和OpenMP 并行方式計算時間。當圖像規模較大時,串行算法耗時呈現近直線上升趨勢,OpenMP 算法耗時也是一種緩慢上升勢頭,而CUDA 并行算法耗時只是出現了十分平緩的上升。雖然CUDA 加速效果有所放緩,但仍舊保持了兩個數量級的加速。
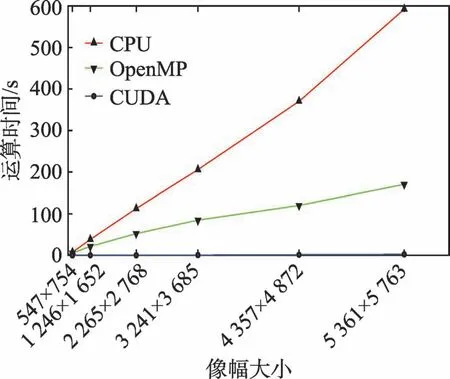
圖7 不同架構下直方圖統計算法運算時間對比Fig.7 Comparison of running time of histogram statistical algorithm under different architectures
產生該現象的原因是,主機內存和GPU 存儲器之間數據交互需要一定的時間開銷,圖像規模不大時這部分開銷對最終的計算時間影響較小,而當圖像數據規模很大時,數據交互時間所占比例有所提高,GPU 計算時間不足以抵過傳輸延遲帶來的時間開銷,CUDA 加速的效果才出現減緩的趨勢。
從圖8 可以看出,當圖像像幅大小在1 246×1 652以內時,OpenMP 并行方式的加速比曲線斜率變化不大,而CUDA 并行方式的加速比曲線斜率變得較為陡峭;當像幅大小從1 246×1 652 擴展到3 241×3 685時,OpenMP并行方式曲線斜率變化仍不明顯,CUDA并行方式的加速比曲線斜率則出現一種緩慢上升的特點;當像幅大小從3 241×3 685 擴展到5 361×5 763時,OpenMP 并行方式曲線斜率仍保持著非常平穩的上升態勢,而CUDA 并行方式的加速比曲線則呈現出一種緩慢下降的趨勢。因此,從圖8中可見,隨著像幅規模的增加,CUDA 曲線斜率的變化都大于OpenMP方式曲線斜率變化。

圖8 直方圖統計并行算法加速比趨勢Fig.8 Speedup trend of histogram statistical parallel algorithm
曲線斜率的大小,在一定程度上可反映出數據計算規模與計算時間的關系,即在相同的計算規模下,曲線斜率越大,說明該并行計算方式的時間消耗變化越劇烈。當曲線正斜率較大時,數據計算規模稍微擴大,僅能夠導致計算時間的平穩增加,這時計算規模與消耗時間的性價比極高,形成了計算效率的高峰期,但擴展性較差。
根據上述分析,可以看出CUDA 并行計算方式的擴展性不如OpenMP 方式,CUDA 方式更容易形成計算瓶頸。但是,由于CUDA 并行計算方式帶來的巨大的加速比優勢,在圖像像幅大小不斷擴大的趨勢下,仍然具有OpenMP 傳統并行計算方式無法企及的加速效果,因此,CUDA 并行計算方式仍更有優勢。
由圖8 還可以看出,使用在CUDA 架構上進行GPU 計算,速度遠高于基于OpenMP 傳統模式的CPU 計算,且隨著圖像像幅的不斷增大,這個速度差距始終保持。這是由于CPU 核心數的限制,CPU 處于滿載狀態時,很難有較大的性能提升,同時還存在線程創建和調度的額外開銷。而在一定的計算量范圍之內,GPU 中每個線程的計算時間大致相同,計算時間的增加僅僅由于更多的線程和線程塊與硬件之間交互造成的必要時間開銷。
4 結束語
本文提出了一種基于CPU+GPU 協同計算的直方圖統計的圖像增強并行算法。首先進行核函數基本配置設計和任務劃分映射,使該并行算法在GPU上可執行。然后通過優化數據傳輸和優化線程塊資源配置,進一步將并行算法的執行效率提高。實驗結果表明,在NVIDIA GTX 1070和Intel Core i5-7400 CPU組成的實驗平臺上,使用并行算法進行了三組直方圖統計圖像增強實驗,相比單線程CPU 算法最大加速比達到了261.35 倍,可以滿足大數據圖像的實時處理需求。此外,將經過本文方法與傳統CPU 串行算法處理后的圖像采用直方圖計算比較,二者在宏觀和微觀層面結果均保持一致,驗證了方法的正確性。文中采用的并行優化方法,對其他圖像處理算法在GPU 計算架構下的實現和優化也具有很好的指導意義和參考價值。
本文所完成的工作還有進一步優化的空間,還有待做更深入的研究:數字圖像本質上就是一個二維數組,每個像素的處理過程是相互獨立并且完全一樣的計算過程。因此,可以在GPU 集群上采用MPI 和CUDA 相結合的技術,由MPI 完成更大圖像塊之間的并行,由每個節點上的GPU 完成圖像塊內的并行,通過GPU 集群可以使處理速度更快,爭取在更短的時間內完成更大尺寸的圖像處理工作。
