基于VSM 算法的集中性運(yùn)維信息智能檢索方法
2022-10-17 08:24:42張海濤
科海故事博覽 2022年29期
張海濤
(深圳供電局有限公司,廣東 深圳 518000)
在互聯(lián)網(wǎng)技術(shù)不斷發(fā)展的進(jìn)程中,網(wǎng)絡(luò)信息和網(wǎng)絡(luò)用戶的數(shù)據(jù)不斷激增,互聯(lián)網(wǎng)也從信息發(fā)送和接收端口,正逐漸轉(zhuǎn)換為信息流的傳輸渠道。在大數(shù)據(jù)網(wǎng)絡(luò)時(shí)間潮流中,僅通過傳統(tǒng)的信息檢索方法,難以支撐運(yùn)維數(shù)據(jù)這種多源異構(gòu)超文本數(shù)據(jù)的搜索和應(yīng)用,因此需要研究一種更加快速且智能的信息檢索方式[1-3]。集中性運(yùn)維信息管理方法解決了這一問題,但隨著網(wǎng)絡(luò)頁數(shù)的覆蓋量急劇增加,用戶發(fā)現(xiàn)越來越難以應(yīng)用該檢索方法,幫助自己找到所需要的運(yùn)維信息數(shù)據(jù)。隨著計(jì)算機(jī)技術(shù)和互聯(lián)網(wǎng)的進(jìn)一步普及,為更好地滿足用戶檢索要求,該領(lǐng)域的研究者改進(jìn)了集中性運(yùn)維信息管理檢索方法,提出了面向特定運(yùn)維主體的信息檢索技術(shù),即在給定的信息內(nèi)容中,有選擇性地從網(wǎng)絡(luò)中搜索出邊緣信息,提高了檢索效率。但這種方法只在所要求的范圍內(nèi)進(jìn)行針對性檢索,雖然在一定程度上滿足了區(qū)域內(nèi)的檢索,但若不事先給定預(yù)設(shè)運(yùn)維數(shù)據(jù)庫,則仍然難以真實(shí)地描述用戶檢索需求。另外該方法在大量的數(shù)據(jù)信息中,也不能精準(zhǔn)有效地檢索出所有相關(guān)信息,而放棄不相關(guān)信息,存在數(shù)據(jù)信息判斷不準(zhǔn)確的問題。現(xiàn)有信息檢索方法想要從海量運(yùn)維信息中準(zhǔn)確獲取真正的所需信息,依舊非常困難。向量空間模型VSM 可以考慮詞頻之間的有效關(guān)系,以權(quán)值計(jì)算的方法,對具有相似性的文本進(jìn)行聚類。為了提高集中性運(yùn)維信息智能檢索的準(zhǔn)確性,本文以VSM算法為基礎(chǔ),研究基于VSM 算法的集中性運(yùn)維信息智能檢索方法,為信息的同步獲取提供理論支持。
1 基于模糊聚類法分類集中性運(yùn)維信息
對集中性運(yùn)維信息進(jìn)行檢索,主要是對其特征內(nèi)容進(jìn)行選擇和設(shè)定。其中,信息選擇是以特征相似模糊聚類方式對集中性運(yùn)維信息進(jìn)行檢索需求的特征提取,在聚類組成后進(jìn)行分類處理。
對文本信息進(jìn)行分類處理主要分為預(yù)處理和聚類兩個(gè)部分。在預(yù)處理過程中,主要是將即將分類的信息,以中文分詞的形式進(jìn)行特征選擇,并將其映射至空間向量模型中。通過文本信息預(yù)處理,將待分類的本文信息按照不同的向量形式,進(jìn)行初始文本集合的若干分類。
將文本表示為以特征權(quán)值項(xiàng)的維度形式,對其進(jìn)行簡化選擇,經(jīng)過模糊聚類的方式,對文本進(jìn)行空間向量轉(zhuǎn)換設(shè)定[4-5]。
根據(jù)內(nèi)容所示,對文本信息中的任意一個(gè)文本進(jìn)行設(shè)定,將VI對應(yīng)在選擇的向量中,表示為:
公式中:特征向量權(quán)值表示為B(VI)。向量個(gè)數(shù)表示為M,其中M=1,2,...,主要為文本集合中進(jìn)行特征向量值計(jì)算時(shí),所有特征項(xiàng)的總數(shù)。NM(VI)表示文本VI在I維度中的數(shù)值,也是在第I個(gè)特征項(xiàng)中,文本所計(jì)算出的權(quán)值。
由于模糊聚類算法屬于無監(jiān)督學(xué)習(xí)形式,即可以不用進(jìn)行預(yù)先的樣本訓(xùn)練,直接以模糊相似聚類的形式對預(yù)處理后的數(shù)據(jù)進(jìn)行規(guī)則分類,并按照一定的規(guī)則進(jìn)行類和簇的組合。正常分類情況下,每個(gè)類中的相似度需大于類間的相似度。數(shù)據(jù)分類完成后,要在其具備準(zhǔn)確性的前提下,對其相似度進(jìn)行計(jì)算,以準(zhǔn)確率和召回率為指標(biāo),表示為:
式中:準(zhǔn)確率用q來表示。召回率用r來表示。在聚類結(jié)果為該類的數(shù)據(jù)中,w1表示真正屬于該類的文本數(shù)量,w2表示不屬于該類的文本數(shù)量。而當(dāng)聚類完成后,其結(jié)果為非該類的數(shù)據(jù)集合時(shí),則w3表示真實(shí)屬于非類的數(shù)據(jù)量,而不在其類型的文本數(shù)量為w4,可不計(jì)入計(jì)算內(nèi)。在利用準(zhǔn)確性和召回率完成數(shù)據(jù)對比分類后,采用VSM 算法計(jì)算信息的相似度。
2 基于VSM 算法計(jì)算信息相似度
基于分類后的數(shù)據(jù)利用VSM 算法進(jìn)行集中性運(yùn)維信息的相似度計(jì)算,對語句進(jìn)行分詞權(quán)重統(tǒng)計(jì),以擴(kuò)展語義使其自身具有匹配能力,為信息的智能檢索奠定基礎(chǔ)。
對文本信息進(jìn)行統(tǒng)計(jì),若在兩組文本中出現(xiàn)相同的詞匯較少,或者從未出現(xiàn)較為相似的詞匯,則其相似值可能會很低,甚至為0。將余弦系數(shù)計(jì)算與VSM算法進(jìn)行融合,計(jì)算所有語句中所有詞匯的相似度,并利用概念對應(yīng)的距離形式,設(shè)定檢索信息與需求信息之間的關(guān)系。
通過VSM 模型計(jì)算向量空間中的內(nèi)容,用以描述信息中的具體內(nèi)容,將詞轉(zhuǎn)變?yōu)樵~向量,從而進(jìn)行余弦相似度的計(jì)算,當(dāng)兩個(gè)向量的余弦夾角值越小,說明兩個(gè)文本之間更為相似,反之則存在很大的不同之處[6-7]。假設(shè)需要檢索的運(yùn)維信息中,含有A1和A2兩組語句,利用VSM 計(jì)算方式,具體步驟如下:
對A1和A2兩組語句進(jìn)行分詞處理,其中A1={S1,S2,...,SD}、A2={F1,F2,...,FG}。當(dāng)A1和A2語句分別完成分詞后,共同建立為一個(gè)數(shù)據(jù)集合H。將A1和A2中出現(xiàn)的所有詞匯,進(jìn)行合并處理,即H={S1,S2,...,SD,F(xiàn)1,F2,...,FG}。統(tǒng)計(jì)A1和A2兩個(gè)語句中,每個(gè)詞匯在集合H中,出現(xiàn)的次數(shù),即可作為每組詞匯的權(quán)重,能夠完成本文數(shù)據(jù)的特征向量值。
將A1和A2中每個(gè)詞匯的權(quán)重進(jìn)行匯總,定義A1中的文本特征向量為JKS=(ZS,1,ZS,2,...,ZS,D)和JKF=(ZF,1,ZF,2,...,ZF,D),兩個(gè)特征向量空間夾角為β,則:
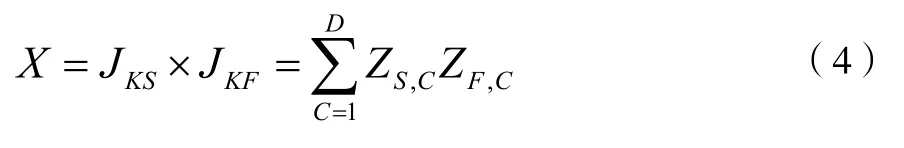
公式中:兩組向量的內(nèi)積為X。向量個(gè)數(shù)為C=(1,2,...,G)。利用余弦系數(shù)進(jìn)行相似度求解,如下:
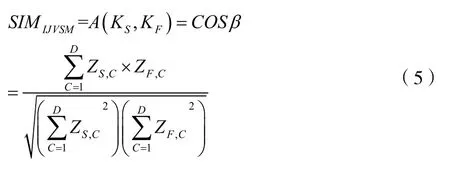
公式中:對兩個(gè)文本之間的相似度,用SIMIJVSM來表示。在VSM 算法中會出現(xiàn)高頻詞匯和低頻詞匯,因此對本文中詞匯權(quán)重的計(jì)算尤為重要,通過上述方法獲得權(quán)重匯總,將詞匯中的奇異值進(jìn)行剔除,尋找到集中性信息的相似度。通過集中性運(yùn)維信息的相似度計(jì)算,以擴(kuò)展語義方法,進(jìn)行文本信息的內(nèi)容擴(kuò)充,使其自身具有匹配能力,完成信息的智能檢索。
3 實(shí)現(xiàn)智能匹配信息檢索
用戶進(jìn)行集中性運(yùn)維信息的檢索,需要通過自然語言檢索進(jìn)行表達(dá)。在自然語言檢索下,直接以分詞和語義進(jìn)行分析,完成概念之間的邏輯關(guān)系轉(zhuǎn)換,形成新的邏輯關(guān)系概念集合,即用戶檢索概念空間集。一般情況下,對信息檢索的整個(gè)過程,即是在概念空間里,對運(yùn)維信息進(jìn)行檢索匹配的過程。而檢索中難免會出現(xiàn)失敗現(xiàn)象,為避免用戶信息檢索中出現(xiàn)失誤,需要優(yōu)化和拓展信息所處的語言空間集合,對用戶需求充分表達(dá),拓展語義能力,處理運(yùn)維信息檢索過程中的缺陷問題,實(shí)現(xiàn)智能匹配信息檢索。
以擴(kuò)展語義能力為基礎(chǔ),利用ONTOLOGY 的關(guān)聯(lián)關(guān)系,對信息所處的空間集合進(jìn)行優(yōu)化和拓展。在原始空間為{Q,W}的前提下,其中Q為用戶查詢過程中的檢索項(xiàng)目集合,W為概念邏輯關(guān)系的集合。對其進(jìn)行語義擴(kuò)展優(yōu)化,主要分為兩個(gè)部分。首先是將Q中關(guān)于用戶的概念,以O(shè)NTOLOGY 中的概念定義,映射為新的概念集合E。其次,在語義關(guān)系和原始邏輯中,利用W對E進(jìn)行規(guī)則轉(zhuǎn)換,確定新空間中概念之間的邏輯屬性,形成新的一個(gè)隸屬概念空間。
對于第一步中的概念假設(shè)問題,即在Q中設(shè)置為(Q1...QN)種概念項(xiàng),對于每一組項(xiàng)目進(jìn)行ONTOLOGY內(nèi)部的邏輯匹配,包括同類型詞匯以及詞條的變化形式。在每次轉(zhuǎn)換成功后,均可產(chǎn)生一組匹配記錄(QI...EI),其中QI為Q中的某一個(gè)概念項(xiàng)目檢索,EI是ONTOLOGY 中能夠與QI相匹配的概念。而由于QI可能會匹配出多個(gè)EI,因此QI可以擁有多條運(yùn)維信息記錄,以此在所有的EI總計(jì)中生成新概念集合E。至此完成用戶檢索概念空間集優(yōu)化拓展,實(shí)現(xiàn)智能檢索方法設(shè)計(jì)。
4 實(shí)驗(yàn)測試分析
4.1 實(shí)驗(yàn)數(shù)據(jù)準(zhǔn)備
采用DBLP 數(shù)據(jù)集中的一個(gè)子集代表海量運(yùn)維信息,其中包含有AUTHOR 數(shù)據(jù)表、PAPER 數(shù)據(jù)表、WRIRE 數(shù)據(jù)表和CITE 表。每種數(shù)據(jù)表中的信息記錄分別為290000 條、450000 條、900000 條、120000 條。通過對DBLP 數(shù)據(jù)集中抽取,構(gòu)造其檢索對象的級別關(guān)系模式。
在數(shù)據(jù)子集中的數(shù)據(jù)表,所屬關(guān)系為互通形式,符合運(yùn)維數(shù)據(jù)關(guān)系特征。在處理后對數(shù)據(jù)中的檢索對象進(jìn)行統(tǒng)計(jì),其中論文對象共計(jì)440000 組、作者對象共計(jì)290000 組,最終形成的檢索對象模式圖的節(jié)點(diǎn)數(shù)為740000 個(gè)。基于以上數(shù)據(jù),對測試的檢索方法進(jìn)行效果論證。
4.2 選擇評估指標(biāo)
信息檢索的目的是通過一系列相關(guān)操作,找到所需要的數(shù)據(jù)信息。為驗(yàn)證本文方法的有效性,對設(shè)計(jì)的檢索方法進(jìn)行評估。由于檢索的目的主要是盡可能多地檢索出所需信息,并且排除掉不相關(guān)信息。選擇P@K 指標(biāo)和MAP 指標(biāo)進(jìn)行評價(jià):
1.P@K 指標(biāo):表示準(zhǔn)確率的變形,是指在檢索結(jié)果中占據(jù)前K 個(gè)結(jié)果的準(zhǔn)確率。
2.MAP 指標(biāo):反映檢索方法在全部數(shù)據(jù)檢索過程中的單項(xiàng)指標(biāo),為平均準(zhǔn)確率。
通過選擇的兩組指標(biāo),驗(yàn)證本文方法與傳統(tǒng)方法的檢索效果。
4.3 對比檢索效果
按照選擇的兩組指標(biāo),首先進(jìn)行準(zhǔn)確率的變形測試,設(shè)定指標(biāo)為P@K100、P@K200、P@K300、P@K400、P@K500。每個(gè)指標(biāo)共進(jìn)行10 組測試,對檢索記錄的結(jié)果均進(jìn)行登記后,統(tǒng)計(jì)其準(zhǔn)確率平均值。
本文的檢索方法準(zhǔn)確率指數(shù),均在傳統(tǒng)方法之上。當(dāng)指標(biāo)為P@K500 時(shí),本文檢索方法的準(zhǔn)確度為0.95,較比傳統(tǒng)方法高出0.35。
在此基礎(chǔ)上,針對P@K 指標(biāo)測試情況,分別對比P@K100、P@K200、P@K300、P@K400、P@K500 的10組查詢MAP 值。
傳統(tǒng)方法在初始階段的準(zhǔn)確率與本文方法較為一致,但隨著測試指標(biāo)的增加,本文檢索方法更具有優(yōu)勢,其中仍以P@K500 時(shí)作為參考,本文方法的MAP 值為0.95,傳統(tǒng)方法為0.65,說明本文方法更加有效。
5 結(jié)語
信息檢索在數(shù)據(jù)應(yīng)用中具有重要作用,隨著互聯(lián)網(wǎng)信息的快速融合,為保證用戶能夠完成所需信息的準(zhǔn)確檢索,本文以VSM 算法為基礎(chǔ),設(shè)計(jì)了集中性運(yùn)維信息的智能檢索方法。在實(shí)驗(yàn)論證下,本文方法取得了一定優(yōu)勢,無論是MAP 指標(biāo)和P@K 指標(biāo)均可以保證較高的準(zhǔn)確率。但由于此次時(shí)間有限,在研究過程中沒有對數(shù)據(jù)的吞吐情況和丟失情況進(jìn)行分析,存在不足之處。后續(xù)研究中會進(jìn)一步進(jìn)行分析,為實(shí)現(xiàn)高效能的信息檢索提供理論支持。
猜你喜歡
制造技術(shù)與機(jī)床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
新聞傳播(2016年18期)2016-07-19 10:12:06
現(xiàn)代計(jì)算機(jī)(2016年11期)2016-02-28 18:35:15
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
河南科技(2014年11期)2014-02-27 14:10:19
圖書館界(2013年5期)2013-03-11 18:50:29
