基于機(jī)器學(xué)習(xí)的C4 烯烴收率的回歸分析
2022-10-21 14:02:04范曉東張亞萍馮睿哲王勇皓
科學(xué)技術(shù)創(chuàng)新 2022年30期
關(guān)鍵詞:催化劑
范曉東*,張亞萍,馮睿哲,王 碩,王勇皓
(1.吉林化工學(xué)院 理學(xué)院,吉林 吉林 132022;2.吉林化工學(xué)院 信息與控制工程學(xué)院,吉林 吉林 132022)
C4 烯烴作為一種重要的化工原料,它被廣泛的應(yīng)用于醫(yī)藥和化工產(chǎn)品的生產(chǎn)。采用乙醇制備C4 烯烴具有巨大的經(jīng)濟(jì)效益和應(yīng)用前景,近年來(lái)受到了國(guó)內(nèi)外的廣泛關(guān)注[1]。在制備過(guò)程中,溫度和催化劑組合對(duì)C4 烯烴收率將產(chǎn)生影響。現(xiàn)研究如何選擇溫度和催化劑組合,使得在其它實(shí)驗(yàn)條件不變的情況下C4 烯烴收率盡可能高。隨機(jī)森林是一類重要的機(jī)器學(xué)習(xí)算法,也是一類集成學(xué)習(xí)算法[2-3],被廣泛應(yīng)用于回歸和分類問(wèn)題[4-5],但基于隨機(jī)森林的C4 烯烴收率的回歸分析的研究還未見報(bào)道,本研究選取催化劑組合和溫度為特征變量,建立基于隨機(jī)森林的回歸模型來(lái)預(yù)測(cè)不同催化劑組合和溫度下的C4 烯烴收率。
1 隨機(jī)森林回歸模型

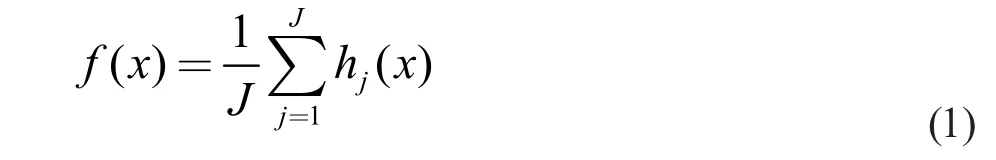
1.1 決策樹
隨機(jī)森林中使用的樹是基于二叉遞歸分割樹,這些樹對(duì)每個(gè)變量進(jìn)行二叉分割的方法,并對(duì)預(yù)測(cè)空間進(jìn)行分割。樹的根結(jié)點(diǎn)由整個(gè)的預(yù)測(cè)空間構(gòu)成,沒(méi)有被分割的結(jié)點(diǎn)被稱為終端結(jié)點(diǎn),它們最終形成了對(duì)整個(gè)預(yù)測(cè)空間的分割。每個(gè)非終端結(jié)點(diǎn)被分成兩個(gè)子結(jié)點(diǎn),即左結(jié)點(diǎn)和右結(jié)點(diǎn)。決策樹的算法見文獻(xiàn)[6]第8章。
1.2 隨機(jī)森林算法
設(shè)D= {(x1,y1), …,(x N,yN)}表示訓(xùn)練數(shù)據(jù),其中xi= (xi1,xi2, … ,xip)T。對(duì)于j= 1,2, …,J:
1.2.1 從D 中選取容量為N 的自助抽樣樣本Dj。
1.2.2 使用自助抽樣樣本Dj做為訓(xùn)練數(shù)據(jù),使用二叉遞歸分割擬合一棵決策樹。
(1) 對(duì)于每個(gè)結(jié)點(diǎn)都從所有觀測(cè)變量開始。
(2) 對(duì)每個(gè)沒(méi)有分裂的結(jié)點(diǎn)都遞歸地重復(fù)下面的步驟,直至停止規(guī)則被滿足:a.從可用的p 個(gè)預(yù)測(cè)變量隨機(jī)選擇m 個(gè)預(yù)測(cè)變量;b.關(guān)于第i 步中的m 個(gè)預(yù)測(cè)變量的所有的二叉分裂中選擇最好的二叉分裂;c.使用第二步中的分裂方法把這個(gè)結(jié)點(diǎn)分裂為兩個(gè)子結(jié)點(diǎn)。
對(duì)于一個(gè)新的結(jié)點(diǎn)x,公式(1)中f(x)預(yù)測(cè)值為
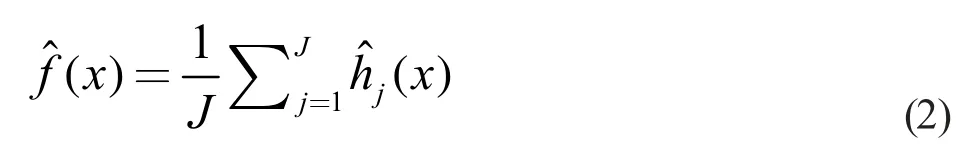
2 三次樣條回歸模型
本研究采用三次樣條回歸模型來(lái)擬合乙醇轉(zhuǎn)化率與溫度之間的關(guān)系,擬合C4 烯烴的選擇性與溫度之間的關(guān)系,假設(shè)乙醇轉(zhuǎn)化率與溫度可以由下列含有k 個(gè)節(jié)點(diǎn)的三次回歸樣條表示:
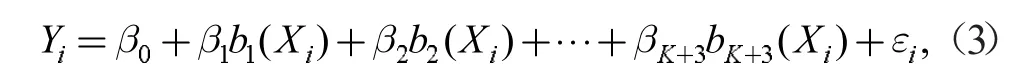
式中,Yi,Xi分別為乙醇的轉(zhuǎn)化率和溫度,b1(Xi),b2(Xi), …,bK+3(Xi)為樣條基函數(shù),β0, β1, β2, …,βK+3為回歸系數(shù),為誤差項(xiàng)[6]。同理假設(shè)C4 烯烴的選擇性與溫度可以由下列含有k 個(gè)節(jié)點(diǎn)的三次回歸樣條表示
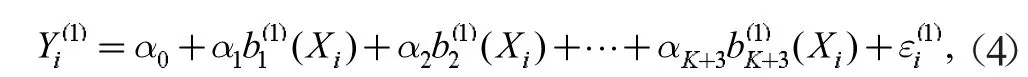
3 數(shù)據(jù)集介紹及插補(bǔ)
數(shù)據(jù)集來(lái)源于2021 年9 月全國(guó)大學(xué)生數(shù)據(jù)建模競(jìng)賽B 題,整理后數(shù)據(jù)集包含催化劑組合、溫度和C4烯烴收率,其中催化劑組合包括SiO2的質(zhì)量(mg)、Co的質(zhì)量(mg)、HAP 的質(zhì)量(mg)、乙醇加入速率(ml/min)和裝料方式。本研究基于隨機(jī)森林的方法建立C4 烯烴收率關(guān)于不同催化劑組合和溫度的回歸模型,然而,我們發(fā)現(xiàn)預(yù)測(cè)準(zhǔn)確率偏低,因此對(duì)數(shù)據(jù)集進(jìn)行了插補(bǔ)。在每種催化劑組合和裝料方式下分別基于三次樣條回歸模型(3)和(4)建立乙醇轉(zhuǎn)化率和C4 烯烴收率關(guān)于溫度的樣條回歸模型,在本研究中采用在數(shù)據(jù)區(qū)域的均勻分布的方法選擇3 個(gè)內(nèi)結(jié)點(diǎn),分別為25%,50%,75%分位數(shù)作為結(jié)點(diǎn)的位置,樣條回歸采用R 軟件包splines 中的lm()函數(shù)進(jìn)行擬合。圖1 給出了利用三次樣條回歸得到的在催化劑組合A1 下乙醇轉(zhuǎn)化率關(guān)于溫度的圖像。圖2 至圖4 分別給出了利用三次樣條回歸得到的在催化劑組合A1 至A3 下C4烯烴的選擇性關(guān)于溫度的圖像。在其它催化劑組合下利用三次樣條回歸模型也得到了乙醇轉(zhuǎn)化率關(guān)于溫度的圖像和C4 烯烴的選擇性關(guān)于溫度的圖像。從圖像可知,在其他條件保持不變的前提下,隨著溫度升高乙醇轉(zhuǎn)化率呈上升趨勢(shì)。但并非所有催化劑組合下均滿足隨著溫度升高C4 烯烴轉(zhuǎn)化率均呈上升趨勢(shì)。例如A1、A3 兩組隨著溫度升高,C4 烯烴選擇性呈先上升后下降趨勢(shì),對(duì)于其它催化劑組合下隨著溫度不斷上升,C4 烯烴選擇性均呈上升趨勢(shì)。進(jìn)而,在每種催化劑組合和裝料方式下分別預(yù)測(cè)溫度為260℃、290℃、310℃和340℃的乙醇轉(zhuǎn)化率和C4 烯烴選擇性,通過(guò)計(jì)算乙醇轉(zhuǎn)化率乘以C4 烯烴的選擇性得到C4 烯烴的收率。我們把這些數(shù)據(jù)補(bǔ)充到原有數(shù)據(jù)集中,最后得到的數(shù)據(jù)集包含207 條數(shù)據(jù),部分?jǐn)?shù)據(jù)見表1。
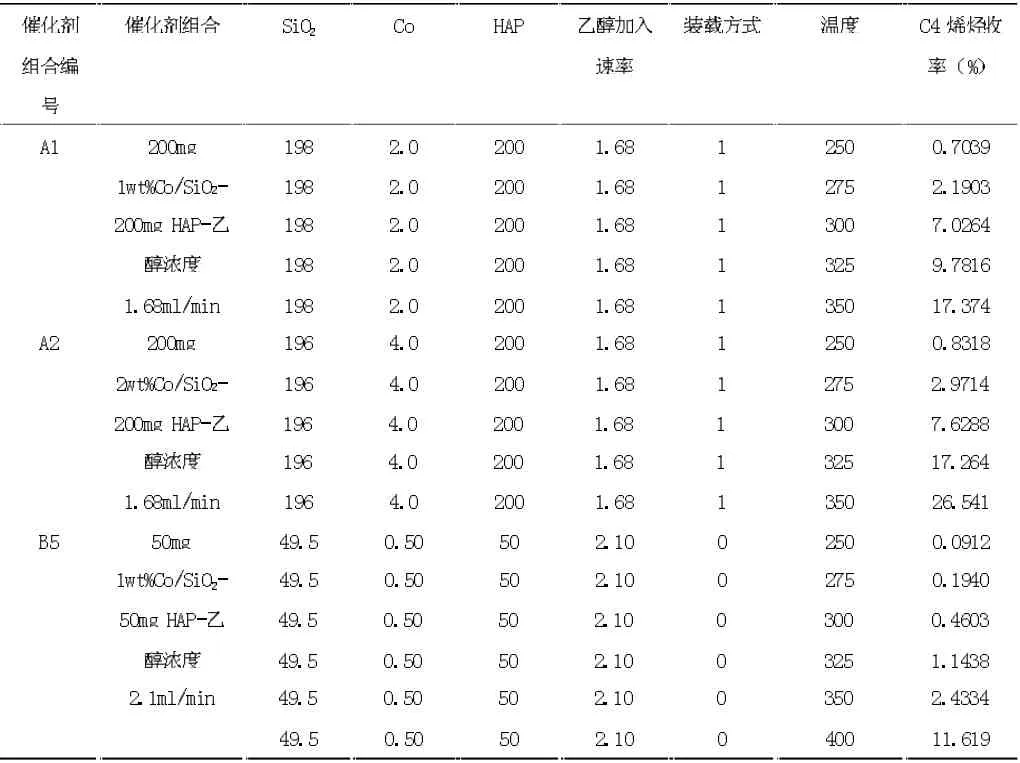
表1 C4 烯烴的收率數(shù)據(jù)

圖1 催化劑組合A1 下乙醇轉(zhuǎn)化率關(guān)于溫度的圖像
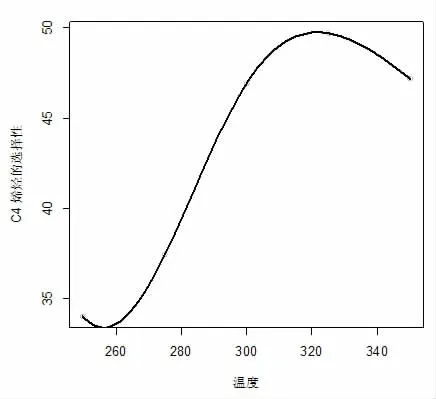
圖2 催化劑組合A1 下C4 烯烴的選擇性關(guān)于溫度的圖像
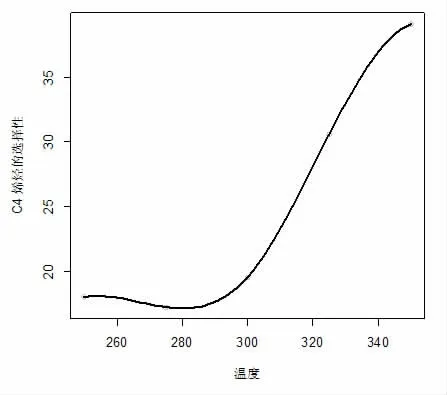
圖3 催化劑組合A2 下乙醇轉(zhuǎn)化率關(guān)于溫度的圖像
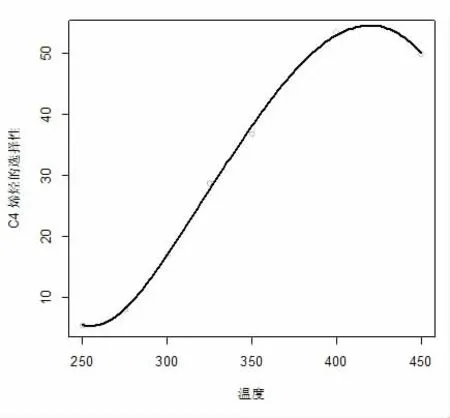
圖4 催化劑組合A3 下C4 烯烴的選擇性關(guān)于溫度的圖像
4 結(jié)果與分析
我們將上面的數(shù)據(jù)集隨機(jī)分為一個(gè)訓(xùn)練集和一個(gè)測(cè)試集,采用R 軟件包randomForest 來(lái)實(shí)現(xiàn)隨機(jī)森林算法。選取=3個(gè)變量和500 棵決策樹來(lái)建立隨機(jī)森林,此時(shí),足以提供良好的預(yù)測(cè)性能,得到測(cè)試的均方誤差為10.7275,方差的解釋性達(dá)到85.57%。我們利用得到的隨機(jī)森林模型進(jìn)行預(yù)測(cè),通過(guò)嘗試不同的催化劑和溫度的組合,得到催化劑組合為A3 和溫度為400℃時(shí)的預(yù)測(cè)結(jié)果達(dá)到最高值,此時(shí)C4 烯烴收率為34.795%。表2 給出了特征變量重要性的兩個(gè)測(cè)度,其中%IncMSE 表示基于當(dāng)前給定變量被排除在模型的時(shí)候預(yù)測(cè)袋外樣本的準(zhǔn)確性的平均的減小量。IncNodePurity 衡量由此變量導(dǎo)致的分裂點(diǎn)使得節(jié)點(diǎn)不純度所減小的總量。圖5 列出了各變量的重要性,結(jié)果表明,在所有的變量中溫度、SiO2含量和HAP 的含量是目前最重要的三個(gè)變量。
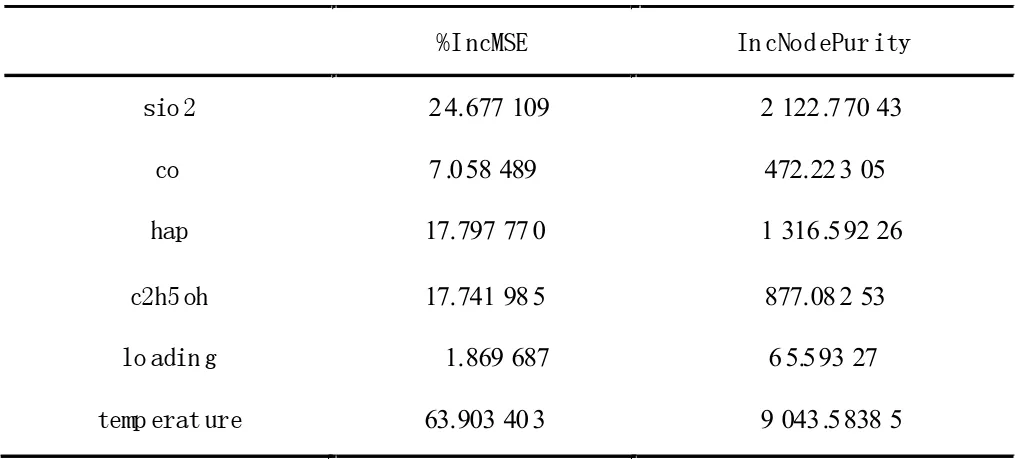
表2 變量重要性
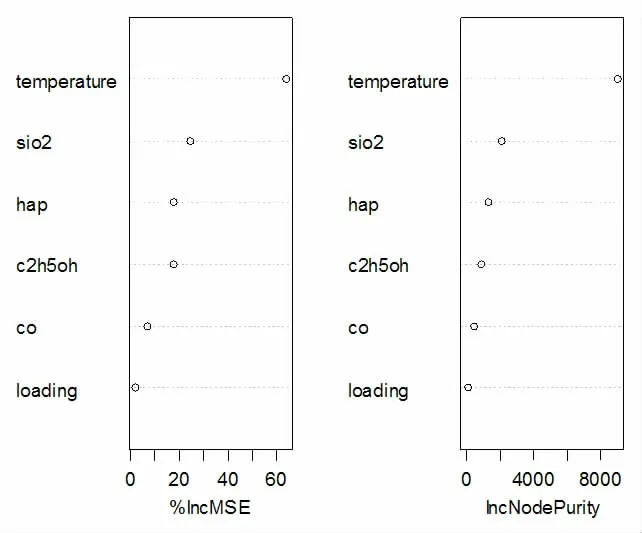
圖3 變量重要性排序
5 結(jié)論
通過(guò)選取溫度和催化劑組合為預(yù)測(cè)變量,C4 烯烴收率為響應(yīng)變量,建立了基于隨機(jī)森林的回歸模型,得到測(cè)試的均方誤差為10.727 5,方差的解釋性達(dá)到85.57%,模型的預(yù)測(cè)效果較好。當(dāng)催化劑組合為A3 和溫度為400 度時(shí)預(yù)測(cè)結(jié)果達(dá)到最高值,此時(shí),C4烯烴收率為34.795%。從隨機(jī)森林模型特征變量的重要性可以看出,溫度、SiO2含量、HAP 含量這幾個(gè)變量的重要性更靠前,因此,在研究C4 烯烴收率時(shí)排名靠前的變量應(yīng)該作為重點(diǎn)關(guān)注的變量。
猜你喜歡
大自然探索(2023年7期)2023-11-14 13:08:06
石油石化綠色低碳(2019年6期)2019-02-13 09:39:01
石油石化綠色低碳(2019年6期)2019-01-14 01:16:22
智富時(shí)代(2018年3期)2018-06-11 16:10:44
浙江大學(xué)學(xué)報(bào)(工學(xué)版)(2016年11期)2016-06-05 09:21:04
Coco薇(2016年2期)2016-03-22 02:45:06
超硬材料工程(2016年1期)2016-02-28 22:20:04
中國(guó)資源綜合利用(2016年4期)2016-01-22 08:27:23
合成化學(xué)(2015年4期)2016-01-17 09:01:27
應(yīng)用化工(2014年3期)2014-08-16 13:23:50
