基于融合特征的長文本分類方法
2022-10-26 10:52:58李海斌
重慶理工大學學報(自然科學) 2022年9期
鮑 闖,喬 杰,李海斌,馮 姣,李 鵬
(1.南京信息工程大學 電子與信息工程學院, 南京 210044;2.浙江海洋大學 信息工程學院, 浙江 舟山 316022)
0 引言
隨著互聯網的快速發展,人們習慣于使用關鍵詞在海量的電子資源中檢索信息,如何對后臺數據庫中的文檔進行有效分類,從而提升用戶體驗效果顯得尤為重要。由于數據量龐大,采用人工方式是一種費時、費力的操作,因此一般采用按照預先設定好的類別標簽,通過提取文本的高級特征,給文本自動分類。文本分類作為自然語言處理(natural language processing,NLP)中最經典、最基本的任務之一,被廣泛應用于情感分析[1]、垃圾郵件識別[2]和輿情分析[3]等具體領域。
文本分類大致可以分為2類方法:傳統的機器學習方法和深度學習方法。傳統的機器學習方法通過提取詞頻或者詞袋特征,然后將文本特征送入樸素貝葉斯(naive bayes,NB)[4]、支持向量機(support vector machine,SVM)[5]等分類模型中預測類別標簽。由于傳統的機器學習算法是淺層的特征提取,存在高維的稀疏性、無序性和無法聯系文本上下文的缺陷,限制了傳統文本分類模型的分類效果,尤其在長文本分類上準確率較低。
伴隨著深度學習技術的進步,研究者嘗試使用神經網絡搭建分類模型,簡化傳統方法的特征選擇,使得建模更加智能化,成為文本分類領域的研究熱點。針對文本表示一般采用詞嵌入,Mikolov等[6]提出Word2vec模型,其中包含CBOW和Skip-gram 2種模型結構。Pennington等[7]提出Glove模型,基于全局詞頻統計的詞表征工具,考慮文本的局部信息和整體信息。Word2vec和Glove訓練出來的詞向量和詞是一對一映射關系,無法解決了一詞多義問題,因此動態詞向量模型被提出。2019年,谷歌團隊提出BERT(bidirectional encoder representations from transformers,BERT)模型[8],是真正在雙向上深度融合特征的語言模型,解決了一詞多義問題,在多項自然語言處理任務中均表現出優異的結果。在分類模型的構建上,Kim[9]針對卷積神經網絡(convolutional neural networks,CNN)的輸入層做了一些變形,提出了文本分類模型TextCNN。TextCNN模型包含一個卷積層和最大池化層,該模型參數量少、訓練速度快,但其卷積核的視野受卷積核控制,固定大小的卷積核只能提取局部的特征,無法關注更長視野的特征。Zhang等[10]同時采用CNN模型實施文本分類,在文本向量表示中按照句子矩陣形式排列。Liu等[11]使用長短期記憶網絡(LSTM)對語句的序列信息進行建模,將網絡的最后一個狀態作為文本表示。Miyato等[12]通過采用對抗和虛擬對抗,進一步提升LSTM性能,獲得更佳的分類效果。對于短文本,循環神經網絡具有較好的表現。隨著文本長度變長,序列數據之間的間隔就會加大,這會使得長短期記憶網絡的記憶性減弱。LSTM只能學習文本的全局時序特征,因此姜恬靜等[13]將卷積神經網絡與長短期記憶網絡結合,使用CNN學習文本的局部特征,再結合LSTM學習時序特征。
然而,上述研究均忽略了長文本自身所帶有的結構化特征,導致在長文本分類時準確率不高。不僅如此,以上方法直接將數據編碼為長序列(如期刊論文、小說、裁決文書)輸入,給模型的性能以及機器硬件開銷帶來很大挑戰。針對長文分類研究,主流方式是采用層次結構網絡模型[14-15]并增加注意力機制[16]。Lin等[17]通過引入自注意力機制獲取可解釋句子嵌入的新模型。Manning等[18]提出全局注意力和局部注意力模型,其中局部注意力機制是對硬注意力的改進,是硬注意力和軟注意力的一種平衡。現有分層模型在訓練過程中采用全局目標向量,無法關注到文本明顯的語義特征。
針對目前長文本分類研究中忽略文本明顯語義信息,以及預訓練模型BERT對輸入長度限制等缺點,本文提出將分割注意力長文融合模型應用于海事海商長文數據集和復旦大學中文文本分類數據集,與基線模型分類準確率比較,提升長文本類文檔的分類效果。通過模型分類準確率以及收斂速度驗證了所提出的分割注意力長文融合模型有效性。
本文主要貢獻如下:
1) 將輸入文本分割成小塊,不需要重新預訓練BERT模型,將文本表示階段的復雜度由O(n2)降低為O(ns),其中n表示輸入的文本長度,s表示劃分的小塊文本長度。
2) 在句向量表示中通過融合特征,組合卷積神經網絡提取的特征向量和BERT模型表示生成的句向量,使用2組目標向量綜合表示句子特征,關注到文本最具區別性的語義特征。
3) 針對海事海商長文數據集在篇章結構方面的正式程度以及存在冗余信息導致文本的特征不突出等特點,結合提出的分割注意力長文融合模型對其進行文本分類,實驗表明該模型相對于基準模型具有更優的表現。
1 分割注意力長文融合模型
本文提出的長文本分類模型如圖1所示,主要包括詞嵌入層、CNN層、Bi-LSTM層、注意力層。
分割注意力長文融合模型首先對預處理的長文本進行分割,將劃分好的小段文本分別送入BERT預訓練模型,獲取包含局部文本的詞向量和句向量。其次,將詞向量送入卷積神經網絡(convolutional neural network,CNN)生成局部文本的特征向量,融合局部文本的特征向量和句向量作為文本的最終句向量。然后,將長文劃分后的n組文本融合的句向量輸入到雙向長短期記憶網絡(bi-directional long short-term memory,Bi-LSTM)提取文本的全局信息。最后,通過引入注意力機制關注重點,采用softmax得到長文本最終概率表達,提高模型分類效率和準確度。
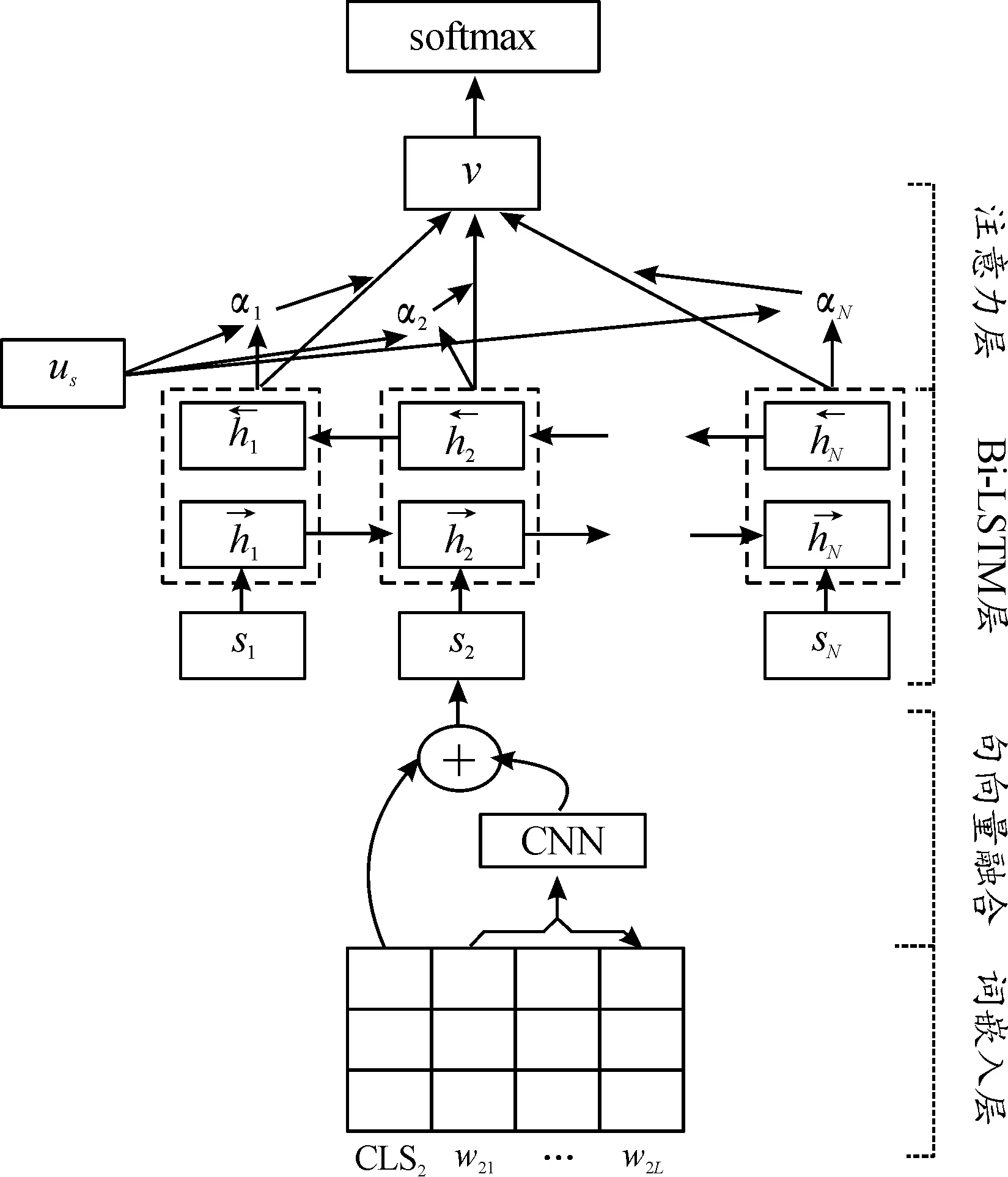
圖1 分割注意力長文融合模型結構圖
1.1 文本劃分
由于本文研究內容是長文本分類,文本篇幅較長,遠大于BERT的最大輸入序列長度。如果采用截斷文本方式使其滿足BERT對輸入序列長度要求,則會丟失文本的大量信息,降低分類的準確率。而如果增加位置嵌入的長度,從頭開始重新預訓練,不僅將消耗大量的硬件資源,而且由于計算復雜度隨輸入文本長度的平方增長,將耗費大量的計算時間。因此,本文采用將長文本劃分為多個短句子的方式,保留文本全局信息。
文本劃分的過程首先是判斷數據庫中文本每句話的平均長度L,按照每K個句子為一組作為預訓練語言模型BERT的輸入,將文本分為N組。文本劃分的偽代碼如下:
算法:文本劃分
Input:一篇裁決文書x,句子平均長度L,一組句子數K,抽取次數N
Output:被分為N組的新文書X_chunk
1: Begin
2:X_stence=[],X_chunk=[]
3: num_sentence=len(x)//L//一篇文書有多少句話
4:i=0
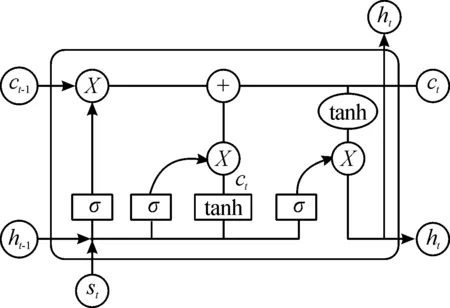
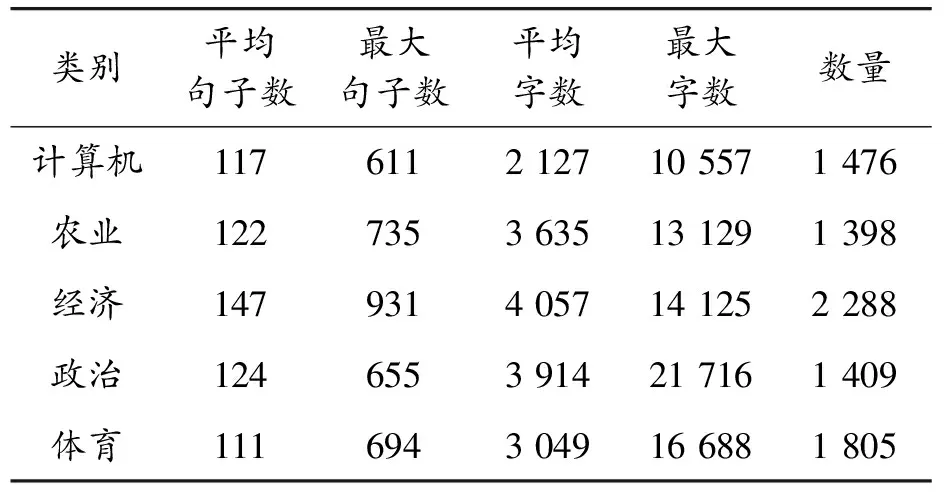
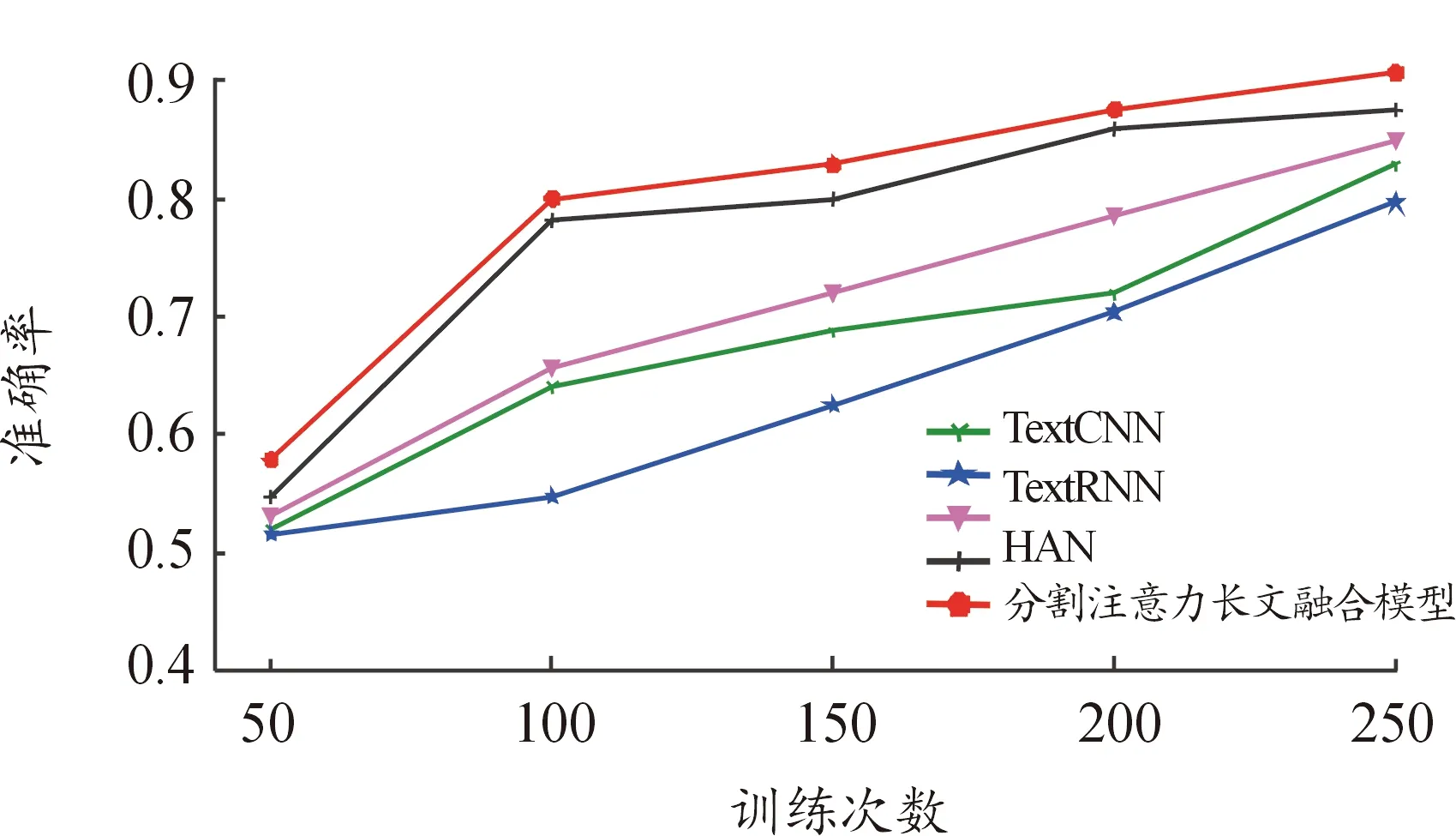
5: whilei 6: start_index=i*L//起始索引 7: end_index=min(start_index+L,len(x)) 8:X_stence.add(x[start_index:end_index]) 9: //將分割的句子追加到X_stence 10:i=i+1 11: end while 12: if len(X_stence) 13: while len(X_stence) 14: re=K*N-len(X_stence) 15:X_stence=X_stence+X_stence[:re] 16: end while 17: end if 18:j=0 19: whilej 20:X_chunk.add(X_stence[j*k,(j+1)*k] 21:j=j+1 22: end while 23: end 采用BERT預訓練語言模型作為詞嵌入層來學習文本表示,對劃分文本內容的兩端加入BERT特殊的標記,[CLS]表示句子的分類,[SEP]表示句子的結束。文本經過詞嵌入 (token embeddings)、句子嵌入(segment embeddings)、位置嵌入(position embeddings)三者的相加融合得到BERT編碼器的輸入信息,過程如圖2所示。通過多個雙向Transformer編碼器編碼后得到文本的向量表示。[CLS]位于句首,對應的最終隱藏狀態將表示輸入文本的句向量,記為L∈RH;第i個詞所對應的詞向量,記作Ti∈RH。 圖2 詞嵌入構造 在已有的層次分類網絡模型研究中,研究者在訓練模型的過程中往往使用全局目標向量,缺乏關注文本中明顯的語義特征。因此,在文本的句向量表示階段,融合BERT的self-attention機制獲得的句向量以及卷積神經網絡提取的特征向量雙通道信息,作為文本的最終句向量表示。 對劃分好的局部文本進行特征提取,本文的TextCNN網絡由輸入層、卷積層、池化層、融合層構成,如圖3所示。輸入層是文本所對應的詞向量組成n×k的矩陣,其中n為局部文本的詞數量,k表示詞向量的維度。輸入層的每一行都是一個單詞對應的維詞向量。卷積層通過運用多組不同大小的卷積核進行特征提取,每種尺寸的卷積核有m個。卷積運算公式為 (1) 圖3 TextCNN網絡 (2) 池化層對卷積層的結果維度進行降維,減小過擬合,提高所提取特征的魯棒性。池化層常采用的方式是均值池化和最大池化。在本文研究中,采用最大池化方式提取文本特征圖的主要特征,最大池化公式為: (3) 以上是使用一種卷積核的計算過程,在本文模型中采用3種不同尺寸的卷積核提取特征。將不同卷積核池化后的特征進行融合,將得到如下的特征向量zj。 (4) 將第j組局部文本通過BERT預訓練模型獲得的句向量lj與卷積神經網絡提取的特征向量zj進行融合,構成局部文本的最終句向量sj。 sj=lj⊕zj (5) 雖然循環神經網絡(recurrent neural network,RNN)具有很強的捕獲上下文信息的能力,但是容易出現梯度爆炸或梯度消失的問題。引入門控機制的LSTM能夠解決RNN問題,但只能學習當前序列節點之前的信息,無法聯系下文,所以本文利用雙向長短期記憶網絡(Bi-directional long-short term memory,Bi-LSTM)代替普通的LSTM,通過前向LSTM和后向LSTM網絡結合,充分考慮當前節點的上下文語義信息。 圖4 LSTM單元結構 LSTM按照時間順序接收局部文本特征st作為輸入向量,Ct-1和ht-1分別為前一時刻的單元狀態和輸出值;Wf、Wi、Wc、Wo分別代表遺忘門、輸入門、當前輸入單元狀態和輸出門的權重矩陣;bf、bi、bc、bo分別代表遺忘門、輸入門、當前輸入單元和輸出門的偏置項;LSTM在各節點的更新計算如式(6)—(11)所示。通過式(6)決定遺忘細胞狀態Ct-1中的哪些信息;借助式(7)—(8)決定保留新輸入信息ht-1和st中的哪些信息;通過式(9)實現細胞狀態Ct的更新;借助式(10)—(11)實現時刻的信號輸出。 ft=σ(Wf·[ht-1,st]+bf) (6) it=σ(Wi·[ht-1,st]+bi) (7) (8) (9) ot=σ(Wo·[ht-1,st]+bo) (10) ht=ot*tanh(Ct) (11) (12) (13) uj=tanh(Wshj+bs) (14) (15) v=∑jαjhj (16) 文本向量v經過一層隱藏層后,通過softmax函數計算其概率最大值的類別作為目標類別,計算公式如下: (17) 為驗證分類模型性能,本文所提出的方法和基準實驗均在Ubuntu 18.04系統上進行,CPU為Intel(R) Xeon(R) Silver 4216,使用Python 3.6.5版本編程語言,為表示語義信息使用BERT訓練詞向量,并采用CUDA 10.2加速訓練。具體實驗環境如表1所示。 表1 實驗環境 本文方法在海事海商長文數據集和復旦大學中文文本分類語料庫2個數據集上進行實驗。 海事海商長文數據集來源于中國裁判文書網,由專門審理海事和海商案件的海事法院發布。收納的案件包括如下5類:海事請求保全、海商合同糾紛、其他海事海商、海事執行、海事侵權糾紛。裁判文書已由法律專業人員進行案由標注,具有權威性。與其他類型的文本相比,裁決文書中各法律要素之間相關性強、專業術語使用頻率高,且文本冗長、特征不突出,在中文長文本領域具有重要的研究價值。本文使用的數據集包括22 137篇文書,每類文書的平均字數均大于700字,數據集整體文書字數均值2 000字左右,明顯長于常見的數據集(THUCNews、Amazon review等)。將數據集按照8∶1∶1分別劃分為訓練集、驗證集和測試集,海事海商長文數據集的詳細信息如表2所示。 表2 海事海商長文數據集統計信息 復旦大學中文文本分類語料庫來源于復旦大學計算機信息與技術系國際數據庫中心自然語言處理小組。通過對文本語料庫去重和預處理,去掉字數小于500字的文本,選取其中的5類文本作為最終的實驗數據集。該數據集包含8 376篇文書,每類文書的平均字數均超過2 100字,數據集的整體文書字數均值在3 400字左右,屬于長文本。復旦大學中文文本分類語料庫實驗數據集的詳細信息如表3所示。 表3 復旦文本分類語料庫實驗數據集統計信息 本文選用文本分類領域的通用評測標準:準確率Acc(Accuracy)評測模型效果,表示預測正確的樣本數占樣本總數的比例,公式為 (18) 式中:TP表示實際為正例且預測為正例;FP表示實際為負例且預測為正例;TN表示實際為負例且預測為負例;FN表示實際為正例且預測為負例。 本研究所提出的模型參數包括詞嵌入層BERT模型和分割注意力長文融合模型的參數。在固定其他參數的前提下,通過改變可變參數數值,獲得模型的最優參數。 BERT采用Google發布的中文預訓練模型“BERT-Base-Chinese”,其模型參數如表4所示。 表4 BERT-Base-Chinese模型參數 本文研究中每批次輸入64篇文書,所有的詞向量均采用768維的BERT詞向量表示。分割注意力長文融合模型中的卷積神經網絡采用單層結構,卷積層利用3、4、5的卷積核尺寸各128個;池化層利用最大池化提高所提取特征的魯棒性。采用雙向長短期記憶網絡(Bi-LSTM)關聯局部文本,隱藏單元個數為100。drop_out比例設為0.5,防止模型的過擬合。選取Adam作為模型的優化器,并將學習率設置為0.001。 本文使用如下的基準模型進行比較: 1) TextCNN[9]:TextCNN采用單層卷積神經網絡(CNN),將經過預處理得到的詞向量作為CNN的輸入,卷積核的尺寸以及數量與原論文設置相同,利用最大池化提取特征,最后外接softmax進行N分類。 2) TextRNN[19]:將文本整體編碼向量化,向量序列輸入到雙向長短期記憶網絡(Bi-LSTM)中,然后將最后一位的輸出輸入到全連接層中,再對其進行softmax分類。 3) CNN_LSTM[12]:文本先經過CNN提取局部特征,再用LSTM提取局部特征的長距離信息,經過變換輸入全連接層。 4) HAN[14]:HAN模型為分層注意力網絡模型,將輸入文本按照文檔結構劃分為一定數量的句子,在詞級以及句子級別分別進行編碼和加入注意力操作,從而實現對較長文本的分類。 將本文提出的模型與以上模型進行實驗比較,結果如表5所示。 表5 長文數據集實驗準確率 % 由表5可以看出,分割注意力長文融合模型相較于其他分類模型在所實驗的長文數據集上分類效果更優。相對于TextCNN分類模型,本文所提出的模型分類效果在海事海商長文數據集和復旦大學中文數據集上分別了提升了7.82%、14.06%。TextCNN采用多組不同卷積核尺寸提取文本特征時只考慮了局部特征,而分割注意力長文融合模型在設計時考慮到文本的上下文語義信息,能更好地表示文本高層特征。相較于TextRNN文本分類模型,分類效果分別提升了10.94%、12.50%。TextRNN模型雖然考慮到文本的上下文信息,但是對于長文存在記憶減退,而且在分類時認為每個詞語對于分類結果的重要程度等同,分割注意力長文融合模型不僅考慮文本上下文信息,還引用注意力機制關注重點詞、重點句,提升了分類效果。相較于CNN與LSTM的組合模型,效果分別提升了4.69%、9.37%。對于組合模型來說,同時考慮了文本上下文信息以及局部特征,因此分類準確率比單一模型均有所提升,但仍然存在無法關注對分類結果起重要作用的部分,分割注意力長文融合模型不僅利用CNN網絡獲取文本的局部重要特征和采用雙向長短期記憶網絡提取文本上下文語義信息,而且采用注意力機制關注重要段落,讓重要部分在分類時起更大的作用,從而提升分類效果。相對于采用分層結構的HAN模型,分割注意力長文融合模型與HAN模型相比,分類準確率分別提升3.13%、2.50%。HAN模型雖然考慮到輸入文本的層次結構,并在詞級別和句子級增加注意力機制關注重要信息,但是在訓練中采用全局目標向量,無法關注到文本明顯的語義特征。本文所提模型采用融合的方式,在句向量層次上通過結合預訓練語言模型生成的句向量和卷積神經網絡提取的局部特征,有效提高文本語義表示,分類的準確率更優。 為進一步研究各種分類模型在海事海商長文數據集和復旦大學中文數據集上訓練過程中的變化趨勢,分別繪制了各個模型在驗證集上的準確率變化曲線。從圖5、圖6可以看出,本文提出的分割注意力長文融合模型收斂速度明顯快于其他分類模型。 圖5 海事海商長文數據集分類準確率變化曲線 圖6 復旦大學中文數據集分類準確率變化曲線 提出一種基于融合特征的中文長文本分類方法。該方法采用谷歌中文預訓練語言模型(BERT)進行文本表示。首先對預處理的長文本進行分割,將劃分好的小段文本分別送入BERT預訓練模型,獲取包含局部文本的詞向量和句向量。然后,將詞向量送入卷積神經網絡生成局部文本的特征向量,融合局部文本的特征向量和句向量作為文本的最終句向量。將長文劃分后的n組文本融合的句向量輸入到雙向長短期記憶網絡提取文本的全局信息。最后,通過引入注意力機制關注重要段落,提高模型分類準確率。實驗結果表明,針對中文長文本分類,本文所提方法具有較高的分類準確率。1.2 BERT詞嵌入

1.3 句向量融合
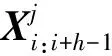

1.4 Bi-LSTM與注意力機制

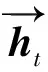
2 實驗與分析
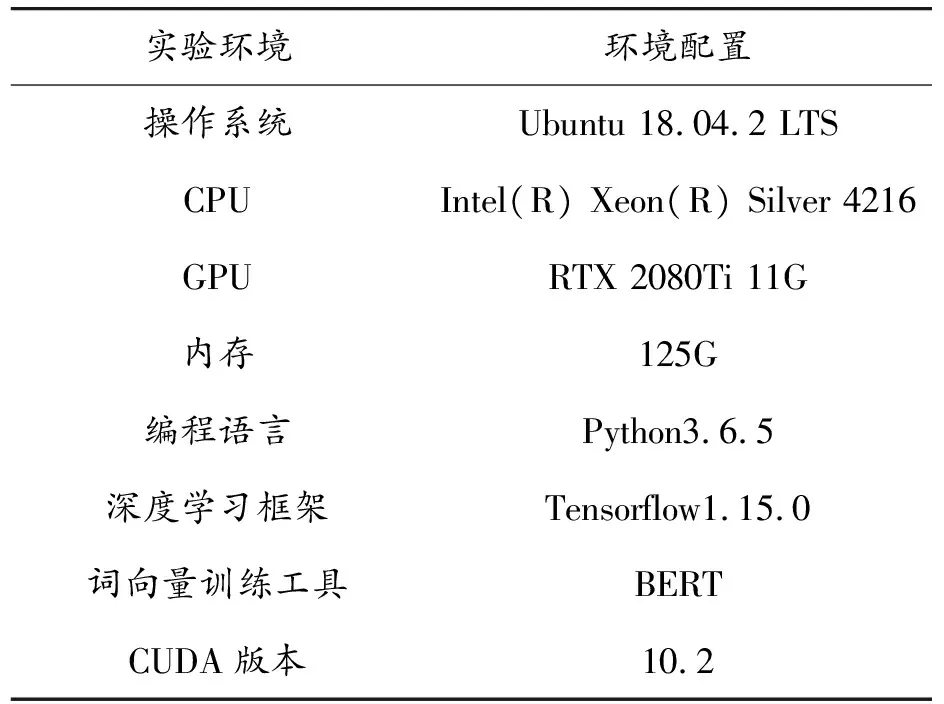
2.1 實驗環境
2.2 實驗數據

2.3 評價指標
2.4 實驗參數設置

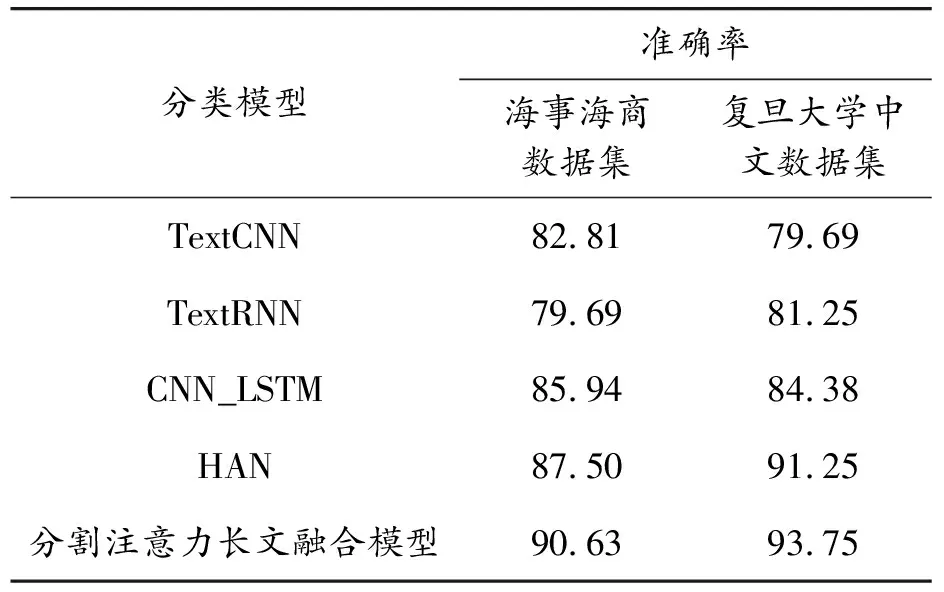
2.5 實驗結果與分析

3 結論
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28制造技術與機床(2019年10期)2019-10-26 02:48:08當代陜西(2019年10期)2019-06-03 10:12:04中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32電子制作(2018年18期)2018-11-14 01:48:06中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06初中生世界·七年級(2017年9期)2017-10-13 22:27:46數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54小學教學參考(2015年20期)2016-01-15 08:44:38
