基因數據的交互依賴特征選擇算法
2022-10-29 01:57:36張俐
電子科技大學學報 2022年5期
張 俐
(江蘇理工學院計算機工程學院 江蘇 常州 213001)
過去幾十年,在生物信息領域產出大量基因數據[1-2]。這些基因數據普遍具有樣本小、維度高和高噪聲等特點[3]。如何處理這些不相關和冗余特征給數據降維帶來重大挑戰。常見的數據降維包括特征提取[4]和特征選擇[5]兩類。特征選擇由于可以刪除無關和冗余特征,同時保留相關原始特征,因此引起許多關注。
在特征選擇中主要有數據層面(過濾式方法)和算法層面(包裝器方法和嵌入式方法)[6-8]兩方面的研究。過濾式特征選擇算法憑借其計算成本低、與具體分類器分離及應用領域廣等優點,逐漸成為特征選擇技術中的研究熱點。常見的基于信息論的過濾式特征選擇算法包括采用平均冗余策略的特征選擇算法(MID[9]、MIQ[9]、JMI[10]和CFR[11]等)和采用“最大最小”極端標準的特征選擇算法(CMIM[12]、JMIM[13]和DWUR[14]等)。然而這些算法存在忽視對交互依賴特征相關性和冗余性判斷的問題。
因此,本文提出一種利用聯合互信息和互信息判斷特征與類標簽之間相關性和冗余性的特征選擇算法(joint feature relevance and redundancy, JFRR)。該算法利用聯合互信息計算在已選特征下候選特征與類標簽之間的相關性;通過互信息計算已選特征和候選特征的冗余性;通過在9 個基準基因數據集的實驗對比,該算法(JFRR)優于其他特征選擇算法(MID、MIQ、CMIM、JMIM、CFR 和CMIMRMR[15])。
1 聯合互信息的一些概念
設X、Y和Z是3 個 離 散 型 變 量[16],其 中,X=

2 JFRR 算法的提出
通過以上描述可知,傳統的特征選擇算法通常使用最小化冗余項和最大化相關項選擇特征子集S。但是由此產生如下問題:1) 當已選特征量增加時,冗余項的大小也會隨著相關項的增加而增加。這就存在一些冗余特征可能被選中;2) 在冗余項中,只考慮已選特征和候選特征之間互信息的計算,而忽視類標簽,可能會造成已選特征和候選特征共享信息,意味著它們之間存在冗余信息。事實上,它們可能與類標簽集合C之間共享不同信息。
以上問題可能會高估某些候選特征的重要性[17-19]。因此需要考慮,如何在已選特征集合S規模不斷增加的情況下,解決S與類標簽集合C的相關性,同時解決候選特征fk與S的冗余性,以及解決在S條件下,候選特征fk與 類標簽C的相關性的問題。
為此,本文提出一種基于信息論的特征選擇算法(JFRR)。該算法充分利用了線性累計加和的方式,具體如下:
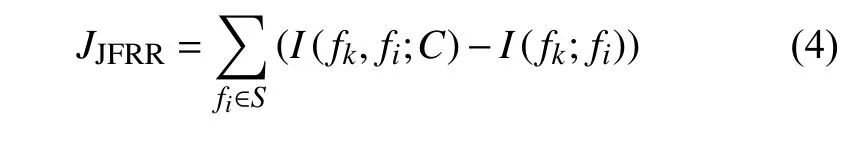
式中,設F是原始特征集合,S?F;J(·)代表評估標準;fi∈S,fk∈F?S。
通過式(4)可知,JFRR 算法利用聯合互信息和互信息原理充分考慮S與C之 間的相關性,fk與S的冗余性以及在S條件下,fk與C之間的相關性。JFRR 算法的具體描述如下。
輸入:原始特征集合F={f1,f2,···fn},類標簽集合C,已選特征子集S,閾值K

從式(4)可知,JFRR 算法采用前向順序搜索特征子集。JFRR 算法主要分為3 部分。第1 部分為1)~7),主要是初始化S集合和計數器k;將選擇出最大的特征fk加 入S集合,同時fk變成已選特征fi。第2 部分為8)~13),分別計算I(fi;C)、I(fk;fi)和I(fk,fi;C)的值。第3 部分為14)~19),根據式(4)的選擇標準選擇fk,一直循環到用戶指定的閾值K就停止循環。
3 實驗驗證與分析
3.1 實驗環境設置
本節將JFRR 與MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算法進行對比。具體分類器為:決策樹(C4.5)和支持向量機(support vector machine, SVM)。本 文 的 實 驗 環 境 是Intel-i7 處 理器,16 GB 內存,仿真軟件是Python2.7。實驗數據集選擇ASU 和UCI 基因數據集[9,20],詳細描述見表1。其中,這9 個數據集包含不同的樣本數、特征數和類數。樣本范圍為50~569,特征范圍為31~9 712,類的范圍為2~12,數據類型涉及連續型和離散型。采用6 折交叉驗證方法進行實驗驗證。為保證實驗公平,分別通過分類評價指標fmc(F1_micro)和pcm(Precision_micro)來評價預測性能。
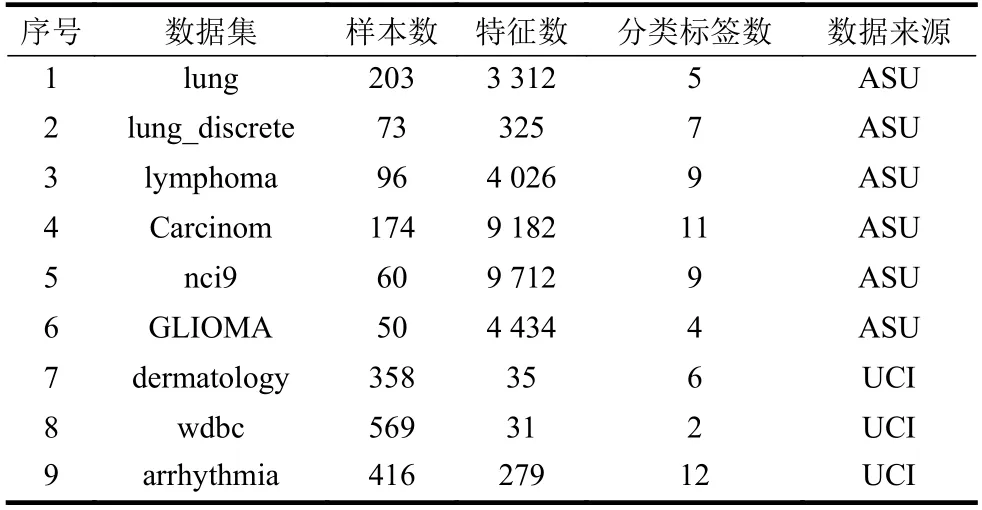
表1 數據集描述
3.2 特征選擇算法性能比較與討論
為了比較JFRR 與MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算法之間的優劣性,將它們所選的特征子集放到同一個分類器(C4.5 和SVM)進行比較,特征子集的規模設置為30。表2 選擇C4.5 分類器。表3 選擇SVM 分類器。在表2~表3 中,粗體代表該數據集下特征選擇算法中最高平均分類預測值。“Wins/Ties/Losses”描述JFRR算法分別與MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算法之間的優/平/輸個數。
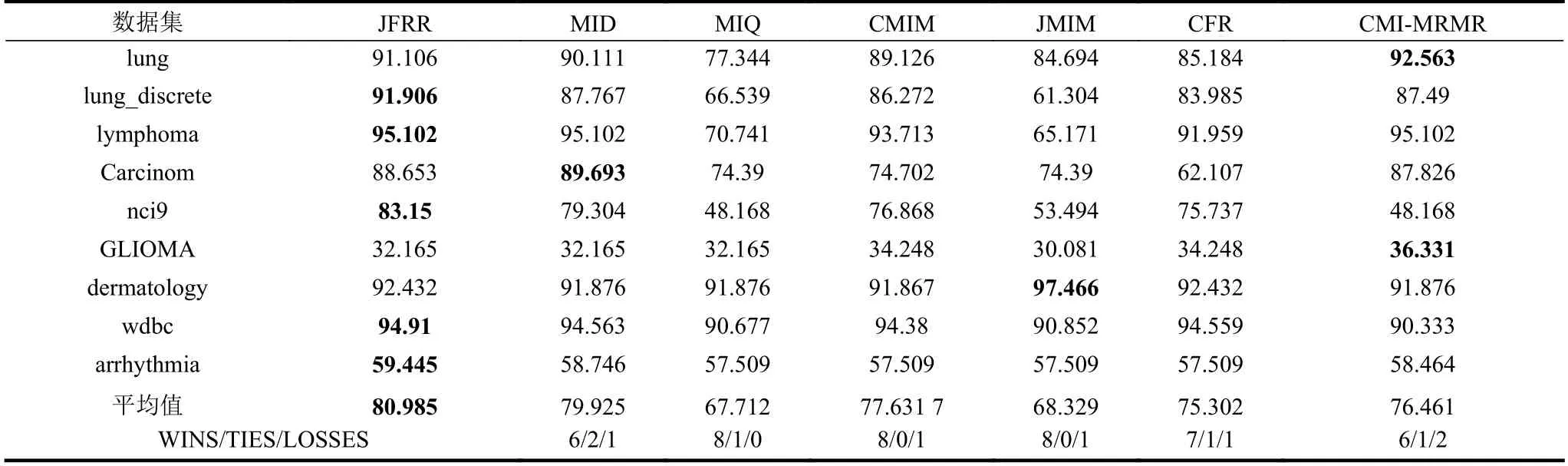
表3 SVM 分類器的平均fmc 性能比較 %
3.2.1 特征選擇算法的fmc 性能比較
在表2 中,7 個特征選擇算法的平均fmc 精度值分別為82.459%、80.24%、68.122%、75.356%、68.695%、73.047%和77.296%。JFRR 算法獲得最高fmc 值。同時,從WINS/TIES/LOSSES 行的統計結果得出JFRR 分別優于MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算 法9、9、9、9、8 和6 次。
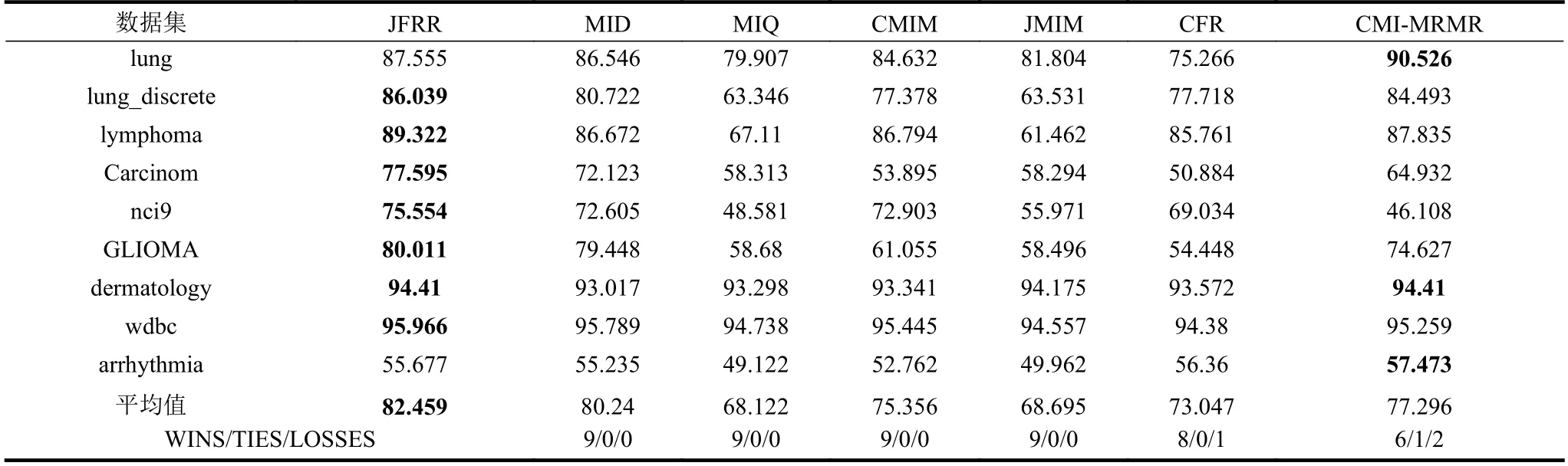
表2 C4.5 分類器的平均fmc 性能比較 %
在表3 中,7 個特征選擇算法的平均fmc 精度值分別為80.985%、79.925%、67.712%、77.631 7%、68.329%、75.302%和76.461%。JFRR 算法獲得最高fmc 值。同時,從WINS/TIES/LOSSES 行的統計結果得出JFRR 分別優于MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算 法6、8、8、8、7 和6 次。
為了進一步比較特征子集對fmc 值的影響,圖1 和圖2 分別給出部分數據集的fmc 性能差異。當數據的維數不斷增加時,JFRR 算法通過動態調整特征間的相關性和冗余性提升了特征子集的數據質量。圖1 和圖2 的實驗結果顯示,JFRR 算法對分類提升的效果明顯。并且,JFRR 明顯優于MID、 CMIM、 MIQ、 JMIM、 CFR 和CMIMRMR。
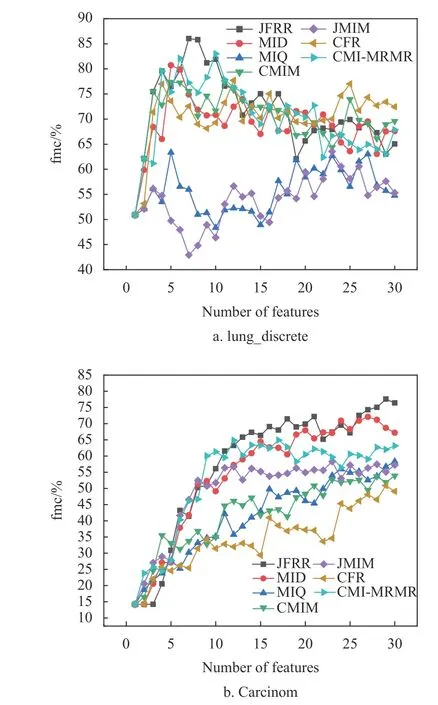
圖1 C4.5 在高維數據集上的性能比較
圖1 是C4.5 在高維數據集上的性能比較。在圖1a 中,JFRR 算法的分類fmc 值為86.039%,是7 種分類算法中最高的,分別比MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 高出5.317%、22.693%、8.661%、22.508%、8.321%和1.546%。在圖1b 中,JFRR 算法的分類fmc 值為77.595%,也是7 種分類算法中最高的,分別比MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 高出5.472%、19.282%、23.7%、19.301%、26.711%和12.663%。圖2 是SVM 在高維數據集上的性能比較。在圖2a中,JFRR 算法的分類fmc 值為95.102%,是7 種分類算法中最高的,分別比MID、MIQ、CMIM、JMIM、 CFR 和CMI-MRMR 高出0.0%、24.361%、1.389%、29.931%和3.143%和0.0%。在圖2b 中,JFRR 算法的分類fmc 值為94.91%,是7 種分類算法中最高的,分別比MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 高出0.347%、4.233%、0.53%、4.058%、0.351%和4.577%。
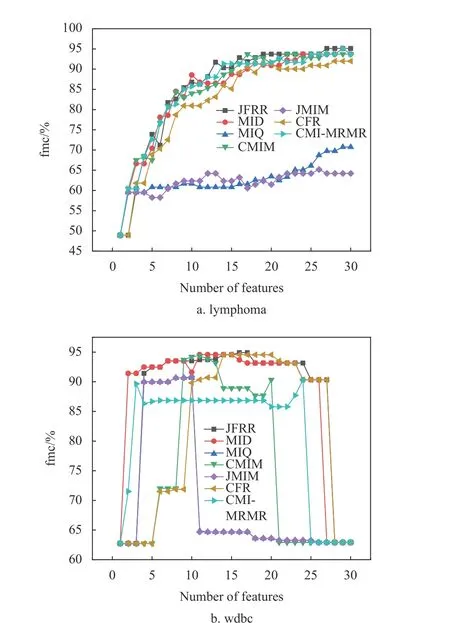
圖2 SVM 在高維數據集上的性能比較
3.2.2 特征選擇算法的pcm 性能比較
圖3 為pcm 盒圖。從圖3a 中可以得出,在C4.5 分類器的pcm 盒圖中,使用JFRR 算法選擇出的特征集合在五位數(最小值、四分位數(第25 個百分位數)、中位數、四分位數(第75 個百分位數)和最大值)中體現出的分類效果都是最優。同時,從圖3b 中也可以得出,在SVM 分類器的pcm 盒圖中,使用JFRR 算法選擇出的特征集合在五位數(最小值、四分位數(第25 個百分位數)、中位數和四分位數(第75 個百分位數))中體現出的分類效果都是最優的效果。
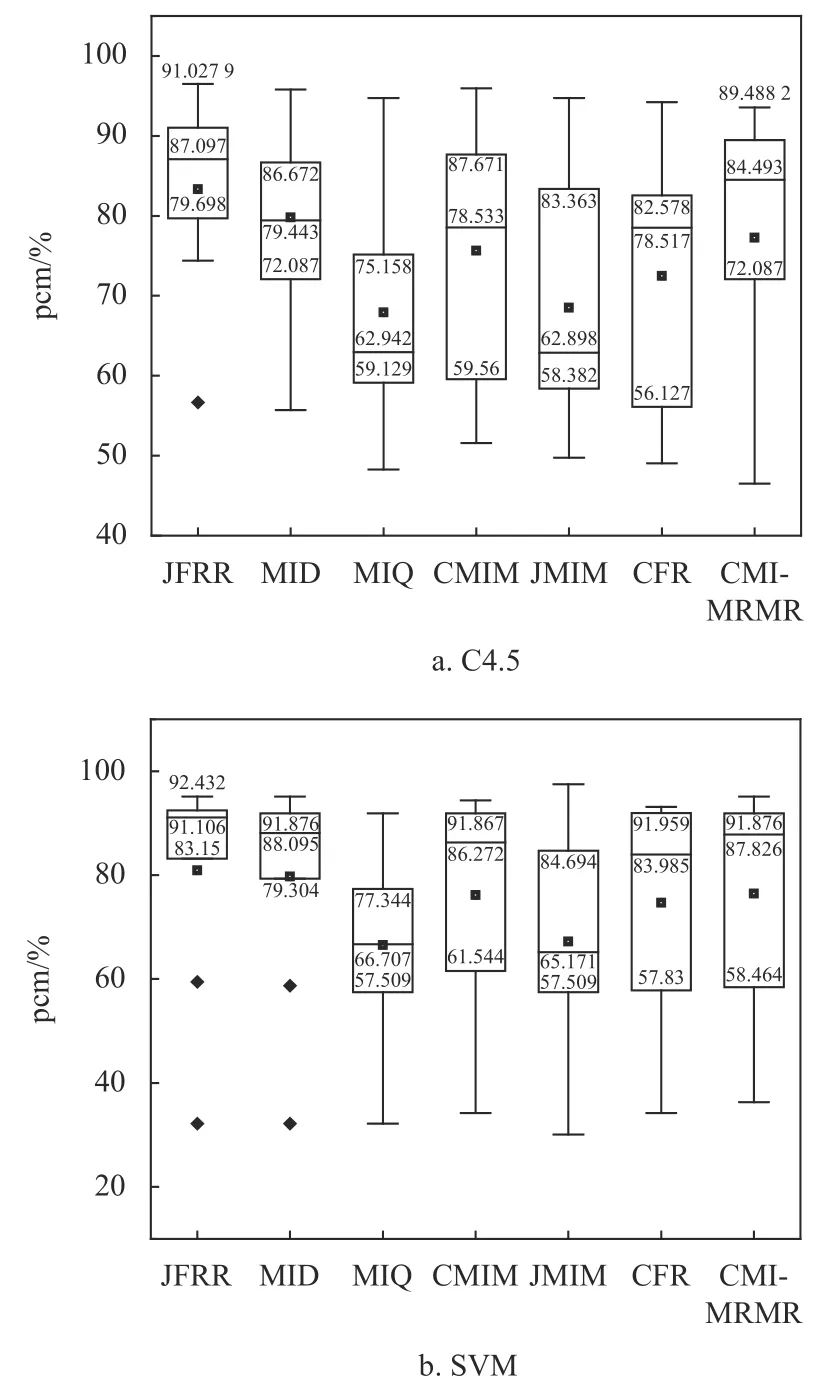
圖3 C4.5 分類器和SVM 分類器的pcm 盒圖
綜上,不同分類器表現出的分類結果不盡相同。但是,JFRR 算法在fmc 和pcm 的評價指標值在大多數數據集上都是最好。從C4.5 和SVM 分類器表現結果中可知,C4.5 分類性能明顯優于SVM分類性能。
3.3 算法的運行時間分析
計算特征選擇算法的運行時間也是衡量特征選擇算法重要性的標準之一。JFRR、MID、MIQ、CMIM、JMIM、CFR 和CMI-MRMR 算法在9 個數據集上進行特征排序后得出的運行時間如表4 所示。可以看出,JFRR 算法的運行時間在可接受的范圍之內。

表4 不同特征選擇算法運行時間比較 s
3.4 實驗算法比較
本節分析JFRR 與MID、CMIM、MIQ、JMIM、CFR 和CMI-MRMR 之間在交互特征依賴相關性和冗余性的差異。從表5 可以得出,與JFRR 相比,MID、MIQ、CMIM 和CFR 將I(fk;C)定義為衡量特征相關性的標準。CMI-MRMR 將I(fi,C|fk)定義為衡量特征相關性的標準。只有JFRR 和JMIM 將I(fk,fi;C)定義為衡量交互特征依賴性動態變化標準。但是,JMIM 算法卻忽視特征冗余性變化。因此,得出JFRR 與其他特征選擇算法差異明顯。

表5 算法比較
4 結 束 語
隨著基因數據中高維特征數據的不斷增多,特征間的關系變得越來越復雜(包含大量無關特征和冗余特征)。而傳統的特征選擇算法往往忽視特征間的相關性和冗余性之間的聯系。本文提出一種基于聯合互信息的JFRR 算法。該算法利用互信息和聯合互信息間的關系動態分析和調整特征間以及特征與類標簽間的相關信息和冗余信息,從而達到刪除無關特征和冗余特征的目的,以此提高特征子集的數據質量。為了全面驗證JFRR 算法的有效性,實驗在9 個基因數據集上進行。分別通過使用分類器(C4.5 和SVM)和分類準確率指標(fmc 和pcm)全面評估所選特征子集的質量。實驗結果證明JFRR 明顯優于MID、MIQ、CMIM、JMIM、CFR和CMI-MRMR 等6 種特征選擇算法。
但在一些基因數據中,JFRR 算法仍舊存在選擇出的特征子集不理想的情況。未來的工作將進一步研究和改進互信息和聯合互信息的關系,并以此優化JFRR 算法,同時在更廣泛的基因數據集中對算法進行驗證,以此提高分類預測精度。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
