惡意PDF 檢測中的特征工程研究與改進
2022-10-29 01:57:36何涇沙吳亞飈
電子科技大學學報 2022年5期
黃 娜,何涇沙,吳亞飈
(1. 北京天融信科技有限公司 北京 海淀區 100085;2. 北京工業大學信息學部 北京 朝陽區 100124)
基于文件格式漏洞的攻擊行為是網絡安全的主要威脅之一。文件格式往往具有跨平臺的特點,一旦漏洞被利用,各類目標主機都可被輕易攻破。文檔類的文件格式,如doc、docx、xls、pdf,在日常工作與生活中傳播廣泛,是藏匿和傳播惡意行為的重要媒介,由此引起的安全事件不勝枚舉。據Cisco 發布的《2018 年度網絡安全報告》統計,在2017 年間,惡意郵件附件中最普遍的3 種文件格式為Office 文檔(38%)、壓縮文件(37%)以及PDF文件(14%)。
PDF 文件格式是由Adobe 公司于1993 年制定的一種電子文檔分發開放式標準,具有以下優點:1) 靈活的層次結構,可以封裝文字、圖像、字體格式、超鏈接、聲音、影像等眾多信息;2) 跨平臺的特性,在各類操作系統中通用。正是由于這些突出的特點,使得PDF 文件在為我們帶來便利的同時,也為黑客提供了可乘之機。從攻擊角度來看,惡意PDF 文件可分為兩種類型:1) 利用PDF文檔規范本身存在的漏洞,如字典中相同key 值對應不同value、對象號錯誤引起誤識別,以及利用ASCII 編碼隱藏關鍵節點等;2) PDF 文件中攜帶惡意內容分為4 種具體情況,即嵌入惡意JavaScript代碼、嵌入惡意文檔、嵌入惡意遠程鏈接以及嵌入惡意軟件。
PDF 文件數量十分龐大,且具有統一的文件格式規范,便于提取出結構化特征,因此機器學習技術在惡意PDF 檢測中有良好的應用條件及效果。本文首先回顧惡意PDF 檢測研究現狀,對其中存在的混淆和逃逸問題進行闡述;然后針對混淆和逃逸設計完善的特征組合,包括內容特征、結構特征以及邏輯樹的間接結構特征,提高檢測模型的性能。
1 研究背景
1.1 PDF 規范介紹
從物理意義上看,PDF 文件由文件頭、對象集合、交叉引用表以及文件尾組成。文件頭中儲存該PDF 遵循的規范版本。對象集合包括文檔包含的所有對象,每個對象都以obj 作為開頭標志,endobj 作為結尾標志,中間為對象所包含的字段、子對象、流內容等。交叉引用表是PDF 文件內部的重要組織方式,用戶可以直接訪問某對象,以xref 作為開頭標志。文件尾以trailer 為開頭標志,包含一些鍵值對形式的文檔描述信息,如所有對象的數量、文檔的作者、創建時間、ID 等。
從邏輯意義上看,PDF 文件為樹形結構,如圖1 所示,Catalog 為字典類型的根節點,包含Outlines、Pages 等子對象節點。其中,Pages 本身為字典型數據結構,是所有頁面的集合入口,包括Count、Kids、Parent、Type 等字段,Kids 包含描述頁面信息的Page 對象或PagesTree 對象。除Pages 之 外,Catalog 字 典 中 還 有Type、Version、PageLabels、PageLayout、AA 等對象節點,表1 描述了部分關鍵對象及其意義。
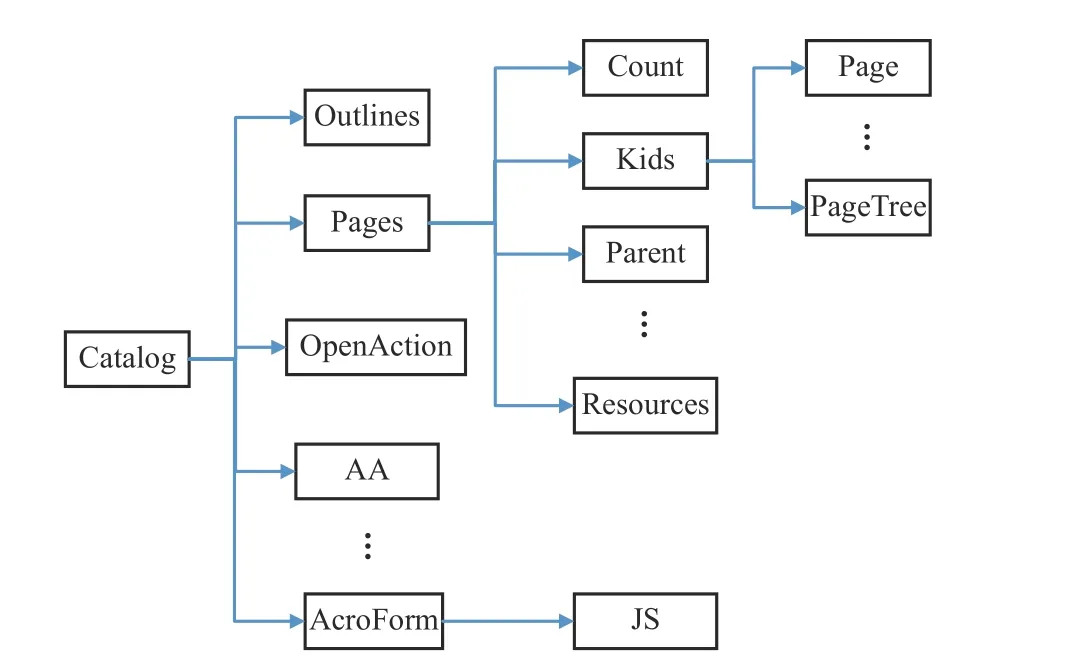
圖1 邏輯結構示例

表1 Catalog 字典中常見的對象
1.2 相關研究
文獻[1]結合使用動態特征與靜態特征進行惡意PDF 檢測,提取動態API 調用特征,在選擇靜態特征時,對文檔結構中的關鍵字出現頻次使用KMeans 聚類,選出正常樣本的關鍵字集合以及惡意樣本的關鍵字集合[1]。在基于機器學習的檢測方法中,所用的靜態特征可分為邏輯結構特征和物理內容特征兩類。物理內容特征包括元數據特征和具體內容特征等;邏輯結構特征包括節點路徑特征、節點數量特征等。各類方法的歸納分類如圖2 所示。
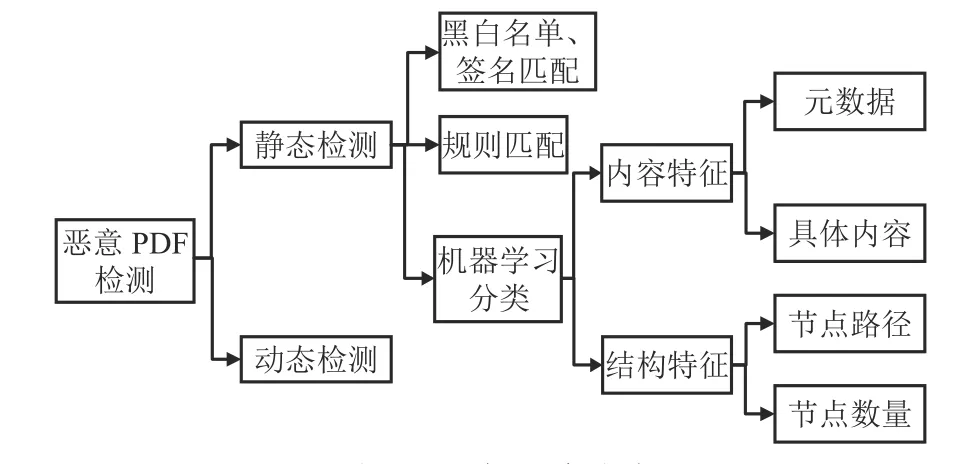
圖2 現有方法分類
元數據包括版本、作者、創建時間、編碼方式等直接信息,以及文件大小、頁面數目等間接信息。文件具體內容特征是指根據PDF 文件中具體內容提取的特征,如流內容的序列特征、熵、JavaScript 代碼的特征等。PDF 中的JavaScript 代碼容易成為惡意行為的載體,是一種比較廣泛的攻擊方式。文獻[2]通過分析PDF 文檔中的JavaScript對象來檢測惡意PDF。這種方法雖具有可靠的準確性,但對于非嵌入JavaScript 類型的惡意PDF 檢測無效。
目前常用的邏輯結構特征主要包括節點的路徑特征和數量。文獻[3-4]提出了Bag-of-Path 方法,即使用節點路徑作為特征,路徑葉子節點的值經過數值化等處理作為相應的特征值。該方法直接利用對象路徑反映PDF 文檔包含的對象特性及內容,不容易受混淆影響,但提取過程較為復雜,使得檢測效率較低,難以適用于實時檢測環境。文獻[2]提出的PDFMS(PDF malware slayer),將PDF 中存在的對象節點的數量作為特征,提取過程簡便,但沒有將正常PDF 文檔中一些常見的對象數量作為判別特征。
物理內容特征和邏輯結構特征能從不同的方面反映惡意PDF 和正常PDF 的區別,文獻[5-7]將兩者結合,常用的機器學習算法,如支持向量機(support vector machine, SVM)、決策樹(decision tree,DT)以及隨機森林(random forest, RF)等,都有相應的研究及應用。文獻[8]從VirusTotal 收集了2008 年?2019 年間的正常及惡意PDF 樣本,直接將原始的PDF 文件輸入卷積神經網絡(convolutional neural network, CNN)進行分類檢測,取得了94%的檢測準確率。
隨著機器學習安全問題逐漸引起重視,惡意PDF 檢測領域也出現了關于防御對抗的研究[9],旨在增強檢測模型的魯棒性。文獻[10]為了防御惡意樣本逃逸SVM 模型的檢測,分別提取正常和惡意PDF 樣本集合中的高頻節點作為特征,通過增加正常節點對惡意PDF 進行偽裝,將生成的逃逸樣本加入SVM 分類器的訓練,經過3 次迭代后,分類器能夠完全檢測出這類逃逸樣本。文獻[11]提出了防御特征加法攻擊的集成決策樹方法,但沒有給出特征加法攻擊中的具體特征。
2 方法研究及改進
2.1 惡意PDF 中的混淆和逃逸
除了增加正常節點的逃逸方式外,在對大量惡意PDF 進行分析之后,發現還存在利用PDF 規范漏洞的混淆和逃逸手段。利用這幾種方式,惡意PDF 文檔中的關鍵對象能逃逸現有檢測方法,但依然能夠在目前計算機中正常執行。
1) 對象號重寫。對于對象號重復的情況,大部分解析器只讀取對象號相同的最后一個對象。
2) 對象隱藏。對象隱藏在文件尾(trailer)中,能逃避目前大部分的解析方法,但隱藏在trailer 中的對象依然能正常執行。另外,在PDF 文檔body 內,ObjStm可以將對象壓縮或加密為流(stream),若不對ObjStm進行解析,則不能讀取壓縮對象的內容。
3) 關鍵節點混淆。現有的一種主流靜態檢測方法,是以關鍵節點數量作為特征,但關鍵節點可以通過Ascii 編碼混淆,使檢測器提取出錯誤的關鍵節點數量。另外,PDF 嵌入文件有兩種方式:“/Type/EmbeddedFile”與“/EmbeddedFiles”,但現有的相關方法通常只提取后者的數量作為關鍵節點數量特征。
4) 對象無結束標志。正常來說,PDF 中每一個對象都是以“obj”作為開始標志,以“endobj”作為結束標志。但有些惡意PDF 在關鍵對象中刪除結束標志,使得靜態檢測方法不能正常讀取該對象,也就無法提取該對象的特征。
2.2 改進的靜態解析方法
本文提出了一種改進的PDF 靜態解析方法,能夠更加準確地提取出靜態特征,包括預處理和具體特征提取,對抗逃逸手段。先對PDF 文檔預處理:1) 讀取整個PDF 文檔的字節流,搜索ObjStm對象,其中/filter 節點中儲存了所采用的編碼算法,如“FlateDecode”,根據相應的算法將對象解碼并替換原有內容;2) 搜索標識對象類型的節點,檢查是否有Ascii 編碼,若有,對照Ascii 編碼將其還原;3) 匹配每一個對象的開始和結束標志,若沒有結束標志,則將“endobj”添加到該對象的結尾處。然后,分別提取PDF 文檔的內容特征、結構特征以及邏輯樹間接結構特征。
2.2.1 內容特征
本文設計及采用的內容特征具體見表2。PDF規范版本號、文件尾標志(“EOF”)數量、尾部所包含字節數是否經過修改,根據這些特征能夠初步判斷一個PDF 文檔是否符合規范、是否為偽造PDF。其中,尾部所包含字節數能體現出是否有對象隱藏在尾部。
字節熵E的計算方法為:
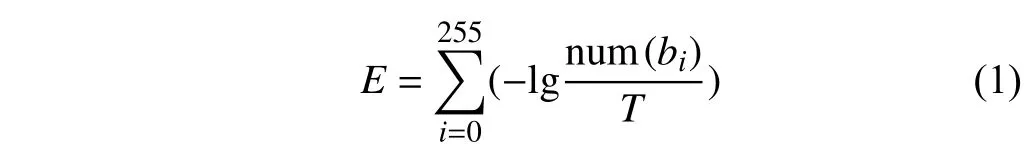
式中,bi表 示一個字節, num(bi)表 示字節bi的數量;T表示計算內容的字節總數。
采用字節熵值、字節比例以及對象數與文件大小的比例作為特征,能夠分辨攻擊者向惡意PDF中添加的字節流、對象節點及其他無意義內容,防止對檢測器產生誤導。與正常PDF 相比,惡意PDF 的字節熵值、流與非流字節比例、對象數與文件大小比例往往較低,因此將其作為判別正常PDF 和惡意PDF 的特征。經過實驗證明,關鍵節點(如OpenAction、URI 等)數量在節點總數中所占的比例,也是一個重要的判別特征。
2.2.2 結構特征
惡意PDF 的主要攻擊方式是嵌入JavaScript 惡意代碼、嵌入惡意文件、嵌入惡意鏈接或交互式表單,因此,這4 類相關對象的數量能夠反映文檔是否具有潛在的惡意行為。現有相關方法通常以JavaScript、OpenAction、URI 等能夠反映出文檔具有潛在惡意屬性的對象為檢測重點。正常的PDF文檔通常儲存較多的文字、圖像等,因此包含較多的Encoding、Font、Resources 以及MediaBox 等正常屬性對象。
Bag-of-Path 方法是將邏輯結構中所存在的葉子節點的路徑作為特征,能夠表征更加具體的節點信息以及節點嵌套關系,但是該方法的實現效率較低,且提取的特征維度高。本文基于該方法,將具有相同葉子節點的路徑合并,提取高頻次節點的數量作為結構特征,實現更加簡便,且能夠降低特征維度。
為了找出對惡意檢測意義較大的關鍵節點,利用Bag-of-Path 方法提取了數據集中所有樣本的路徑,將其中的高頻節點作為候選特征,節點數量作為特征值。根據本文提出的靜態解析方法提取結構特征,遇到具有重復對象號的對象、隱藏在trailer中的對象,它們所包含的節點數量也會被提取,避免逃逸;將“EmbeddedFile”與“EmbeddedFiles”兩類節點的數量合并,作為“EmbeddedFile”特征值。
2.2.3 邏輯樹間接結構特征
完成以上預處理后,再解析PDF 文件的邏輯結構,如圖3 示例,通過解析一個PDF 文件的邏輯結構,生成邏輯結構樹。從尾部入手,采用遞歸的方法遍歷,生成XML 格式的DOM 樹,算法詳細描述如下。
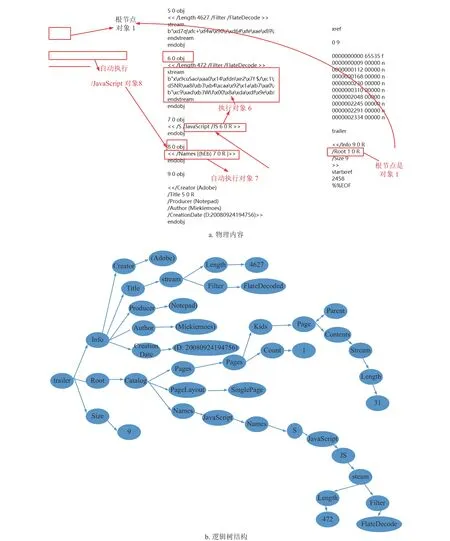
圖3 PDF 邏輯結構示例

從生成的DOM 樹提取間接的結構特征,具體包括樹的深度和廣度、特殊子樹的深度和廣度、子樹平均廣度、所有節點的類型數以及各類節點的熵。深度是從根節點到所有子節點的路徑中,最長路徑的節點數;廣度是在樹的所有層中,節點最多的一層所包含的節點數。經過對大量樣本的分析,發現較多惡意PDF 會將關鍵節點藏匿在一個較深的分支中,如圖3 所示,因此DOM 樹的深度和廣度是區分PDF 文檔是否為惡意的一個有效特征。特殊子樹是根據正常PDF 和惡意PDF 所包含的節點對象的區別,或者節點對象梳理的區別,確定一個特殊節點,取出DOM 樹中以該特殊節點為根節

2.3 特征選擇
使用決策樹算法中的信息增益率評價某個特征在分類任務中的重要性。將信息增益率表示為:
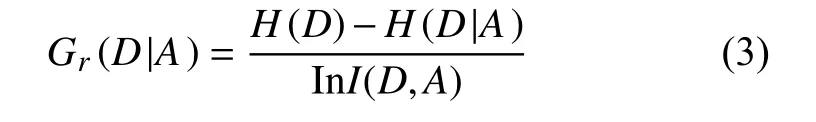
式中,D表示數據集;A表示某個特征;H(D)為數據集中樣本類別的信息熵;H(D|A)為加入特征A作為分類依據后類別的信息熵; InI(D,A)為特征A內部的信息熵,其計算分別為:
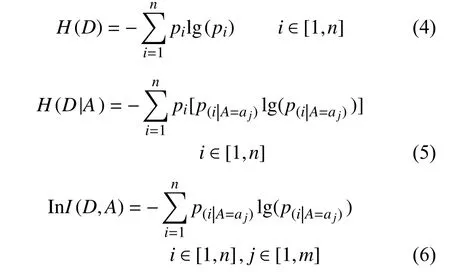
式中,n為數據集中的樣本類別數;m為特征A 的取值個數;pi表 示隨機取出一個樣本屬于類別i的概率;p(i|A=a j)則 表示在特征A取值為aj的條件下,隨機取出一個樣本屬于類別i的概率。
2.4 LightGBM 分類器
集成學習是目前常用的一種防御對抗方法,通過融合多個弱學習器來降低攻擊風險。文獻[11]提出使用Adaboost 算法訓練集成決策樹,提高惡意PDF 檢測魯棒性的方法。LightGBM 也是一種采用Boosting 方式的集成學習算法,以梯度提升決策樹(gradient boosting decision tree, GBDT)為核心,通過改進的生長策略、分割算法以及并行策略,提高GBDT 的訓練效率,降低內存占用率。與深度學習以及其他集成學習算法相比,LightGBM 在并行拓展與運行效率上具有明顯的優勢,成為工業界主要應用的機器學習算法之一[12]。本文使用LightGBM框架訓練GBDT 模型,根據前面所提取的特征區分正常和惡意的PDF 文檔。
3 實驗與分析
3.1 方法驗證
收集了網絡環境中近兩年的正常和惡意PDF樣本各6 000 個,作為實驗數據集,如表3 所示。在數據集上首先使用Bag-of-Path 方法提取至少出現于1 000 個樣本中的路徑,找出這些路徑的葉子節點對象;然后提取對象數量作為結構特征。提取本文設計的其他特征,形成71 維特征。圖4 給出了正負樣本其中4 種特征的分布,可看出明顯差異:特征Ratio 表現為黑樣本的特征值較高,白樣本的特征值較低;特征Root_depth 表現為白樣本特征值較高,黑樣本的特征值較低;特征ObjCount_by_size 表現為黑樣本的特征值高于白樣本特征值;特征Stream_by_nonstream 表現為白樣本特征值高于黑樣本特征值。
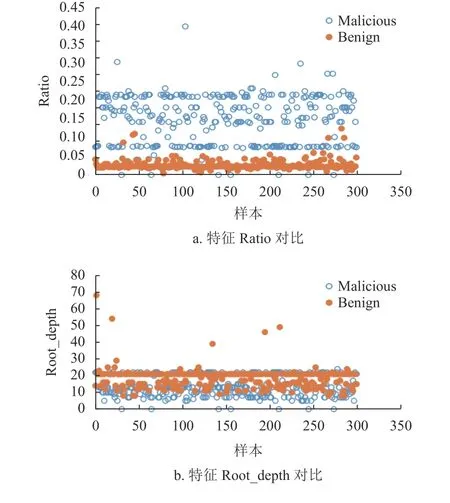
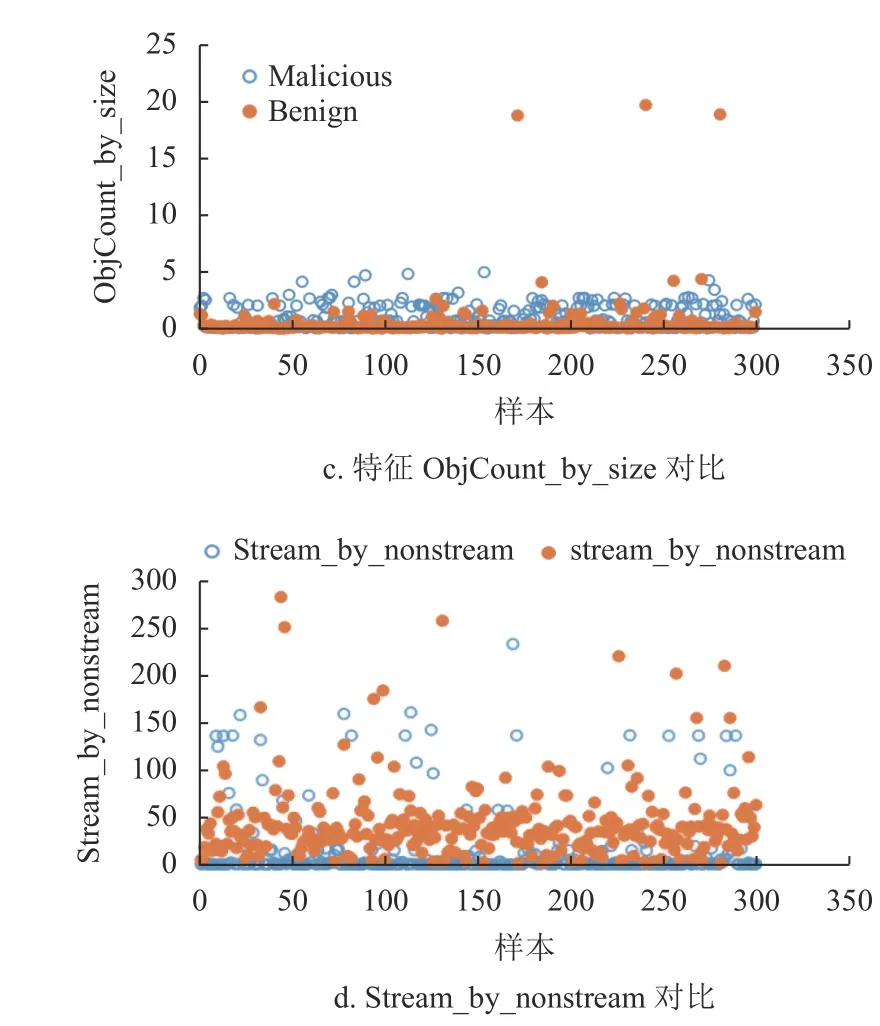
圖4 黑白樣本的特征對比

表3 實驗數據集
圖5 展示出所提取的71 維具體特征及它們各自的重要性。可以看出,本文提出的內容特征以及DOM 樹結構的間接特征,如關鍵節點數量、節點總數比例、根節點深度、字節熵、流內容字節數、字節比例等的重要性較高;在結構特征中,Resources、ToUnicode、BaseEncoding 等正常屬性的對象數量特征,與OpenAction、AA、EmbeddedFile、JavaScript 等具有惡意屬性的對象數量特征都具有較高重要性。結尾標志“%EOF”、JBIG2Decode、colors 等13 維特征不具有重要性,因此,在后續的模型訓練中刪除這13 維特征。
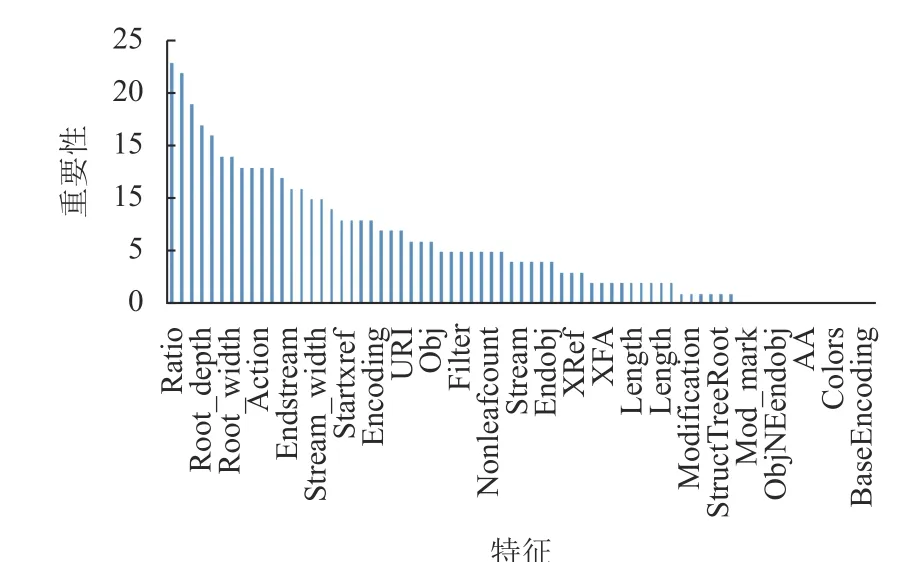
圖5 特征重要性
3.2 與其他特征的性能對比
為了對比改進的特征工程方法,按照文獻[4]和文獻[13]使用的特征工程分別提取實驗數據集的特征,同樣使用LightGBM 算法訓練模型。測試性能的對比如表4 所示,可以看出本方法比PDFMS具有更高的AUC 值,與Bag-of-Path 處于同一水平。對比表5,本方法仍然顯示出更高的準確性,而且特征維度較低,有利于簡化模型,在效率上得到提高。

表4 不同方法的AUC 值對比
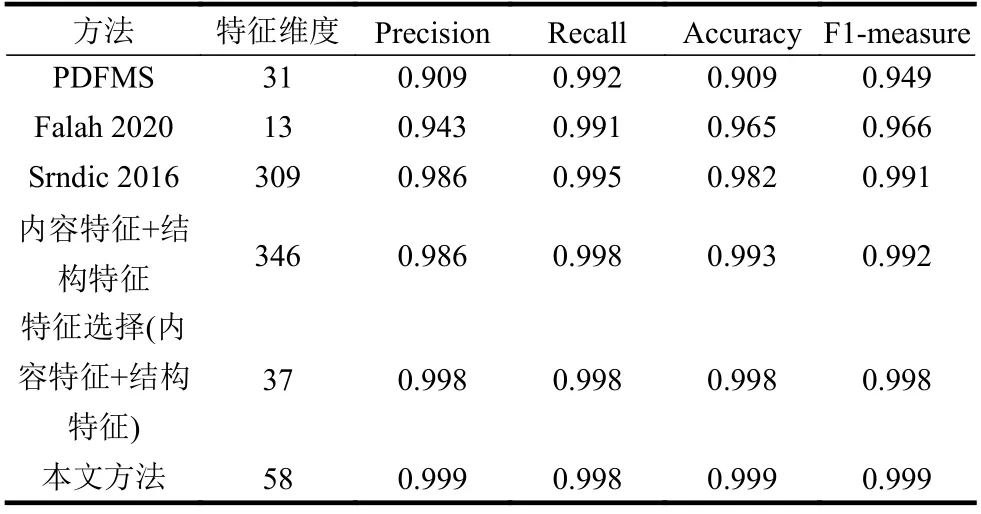
表5 不同特征的性能對比
3.3 魯棒性驗證
黑客在制造對抗機器學習檢測的惡意PDF時,既要保留PDF 中所嵌入的惡意對象,又要誤導檢測模型,因此大多數的做法是向惡意PDF 中插入一些正常的節點對象、內容流等,試圖使模型將其誤認為正常PDF。如惡意PDF 中obj 數量少于正常PDF,于是黑客通過增加obj 對象的方式生成對抗樣本。在現有惡意樣本的基礎上,統計惡意PDF 和正常PDF 中各個對象的數量差異,通過增加正常對象的數量,生成對抗樣本測試集,用于測試、評估模型的魯棒性。表6 對比了模型檢測無對抗樣本和有對抗樣本的性能,精確率降低了0.1%,召回率提高了0.1%,整體準確率無差別,可以證明該模型防御對抗手段的魯棒性較為可靠。

表6 對抗魯棒性測試結果
4 結 束 語
本文改進并實現了PDF 靜態特征提取方法,能夠提取出更加準確的靜態特征,防止混淆和逃逸。實驗驗證表明,與現有的其他特征工程相比,本文結合使用的結構特征、內容特征以及邏輯樹間接結構特征,能夠使機器學習檢測模型實現較高的準確性和魯棒性。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
