基于輕量級神經(jīng)網(wǎng)絡的新冠肺炎CT新型識別技術
2022-11-02 07:26:36郭藝杜秋晨吳朦朦馬鵬濤李冠華
中國醫(yī)學物理學雜志 2022年10期
郭藝,杜秋晨,吳朦朦,馬鵬濤,李冠華
1.火箭軍特色醫(yī)學中心麻醉科,北京 100088;2.北京航空航天大學電子信息工程學院,北京 100191;3.火箭軍特色醫(yī)學中心影像科,北京 100088
前言
新型冠狀病毒肺炎(簡稱新冠肺炎)是指由2019新型冠狀病毒感染所導致的肺炎,具有傳染性強和隱蔽性高等特點。目前,新冠肺炎感染了全球2億人并導致500萬人死亡,對經(jīng)濟發(fā)展和人民生活造成嚴重的影響。控制新冠肺炎最有效的方式是加強檢測,有效地控制傳染源。核酸檢測利用病毒中特異性RNA 序列區(qū)分新冠肺炎病毒,已成為新冠肺炎檢測的首要標準。但由于核酸檢測至少需要4 h 才能得到結果,并且陽性準確率約為50%,需連續(xù)檢測多次才能確診,并且在疫情爆發(fā)地區(qū)存在核酸檢測試劑數(shù)量不足的情況。對比之下,電子計算機斷層掃描(CT)設備普及程度高,各級醫(yī)院均可完成檢測,并且CT 檢測高效快捷、輻射量低、準確性高,已成為新冠肺炎臨床檢測的標準[1]。
新冠肺炎的CT 影像具有與其他肺炎不同的特征,新冠病毒進入人體后會在支氣管和肺泡的上皮細胞中大量繁殖,人體則產(chǎn)生淋巴細胞和單核細胞對抗病毒,導致肺間質(zhì)增厚、肺泡腔滲出增多,CT 影像呈現(xiàn)磨玻璃影。新冠肺炎早期的病灶多呈現(xiàn)于胸腔外圍、肺部下方,CT 圖像呈現(xiàn)小斑片狀磨玻璃影;隨著新冠肺炎的發(fā)展,病灶融合擴大,磨玻璃影出現(xiàn)不規(guī)則狀,呈邊界模糊的扇形或楔形;重癥期病灶范圍大量增加,胸腔大部分呈現(xiàn)磨玻璃影,俗稱“白肺”[2]。雖然新冠肺炎的CT 影像特征明顯,但由于患病初期的病灶范圍小,識別準確率不高。
隨著人工智能(AI)技術迅速發(fā)展,AI技術已經(jīng)廣泛應用于醫(yī)學影像分析[3],在新冠肺炎CT識別方面取得了一定成果。研究表明,AI能夠有效輔助低年資的影像科醫(yī)師,提高新冠肺炎CT診斷的準確性[4]。國家超級計算長沙中心發(fā)揮AI和區(qū)塊鏈等新技術優(yōu)勢,利用高性能計算資源提高檢測效率和準確性[5]。國家超級計算天津中心提出新冠肺炎CT影像綜合分析輔助系統(tǒng),實現(xiàn)快速高效的新冠肺炎檢測[6]。深度神經(jīng)網(wǎng)絡是AI技術在醫(yī)學影像分析中的常用方法,深度神經(jīng)網(wǎng)絡可以從大量數(shù)據(jù)樣本中自動學習新冠肺炎CT影像特征,但特征識別模型訓練過程通常需要在高性能GPU上花費大量的時間,并且訓練出的模型參數(shù)龐大,不適合在基層醫(yī)院廣泛部署。
為了提高新冠肺炎CT 影像識別率的同時降低深度神經(jīng)網(wǎng)絡的運算量,設計一種基于輕量級深度學習的新冠肺炎CT 新型識別技術,其創(chuàng)新點在于:(1)選取目前公開的所有新冠肺炎CT 圖像數(shù)據(jù)集,經(jīng)過數(shù)據(jù)集清洗、樣本灰度圖均衡化等預處理后作為訓練數(shù)據(jù),通過大樣本提高深度學習的泛化能力,進而提高新冠肺炎CT 診斷的準確性;(2)提出基于DenseNet 的人工神經(jīng)網(wǎng)絡結構,采用GhostNet 卷積簡化網(wǎng)絡參數(shù),使深度學習模型能夠在無GPU 的醫(yī)用計算機上運行,便于網(wǎng)絡的部署及CT 序列識別;(3)利用傳統(tǒng)圖像處理方法進行肺部圖像分割,利用分割出的肺部位置引導深度學習網(wǎng)絡進一步提高新冠肺炎CT 診斷的準確性;(4)由于新冠肺炎檢測中漏檢比誤檢的風險更大,在損失函數(shù)中提出加權交叉熵函數(shù),重點降低漏檢率。誤檢情況可通過增強CT或其他診療方法進一步排查。
1 相關研究
新冠肺炎的CT 診斷方法引起越來越多的研究者重視,主流研究方法大多是基于神經(jīng)網(wǎng)絡的,從利用現(xiàn)有深度學習模型在新冠肺炎CT 圖像上訓練發(fā)展到利用新冠肺炎CT 圖像的特點設計高精度的深度學習模型。
早期研究中,研究者利用現(xiàn)有的神經(jīng)網(wǎng)絡模型在新冠肺炎CT 數(shù)據(jù)集上進行微調(diào),取得了一定的成果。文獻[7]是最早將神經(jīng)網(wǎng)絡用于新冠肺炎CT 診斷的研究,作者利用AlexNet 識別新冠肺炎CT 圖像,提取COVID-CT 數(shù)據(jù)集中每位患者的一幅圖像作為訓練集,達到80%的準確率,盡管準確率不高,但是證明了神經(jīng)網(wǎng)絡在新冠肺炎CT 圖像識別中的可行性。文獻[8]基于VGG模型進行新冠肺炎遠程診斷,結合CT影像和X光圖像使準確率達到了90%。文獻[9]選擇GoogleNet和ResNet神經(jīng)網(wǎng)絡模型在COVID-19數(shù)據(jù)集上進行試驗,準確率分別為90%和91%。文獻[10]采用ResNet152 和VGG16 網(wǎng)絡模型,在所收集的2 373幅新冠肺炎CT圖像中進行試驗,準確率超過92%。上述方法采用通用的神經(jīng)網(wǎng)絡模型,沒有結合新冠肺炎CT圖像的特點,識別準確率有待提高。
針對新冠肺炎CT 圖像識別準確率不高的問題,研究人員不斷對神經(jīng)網(wǎng)絡模型進行改進,探索適合新冠肺炎CT 圖像識別的模型。文獻[11]從新冠肺炎病理區(qū)域提取圖像塊作為訓練集,利用禁忌遺傳算法獲取卷積神經(jīng)網(wǎng)絡模型中最優(yōu)的超參數(shù)組合,準確率達到93%,不過該方法僅能利用圖像塊的局部信息,不能利用肺部圖像的整體信息。文獻[12]基于公開的COVID-19 CT 分割數(shù)據(jù)集進行訓練,在UNet++網(wǎng)絡的基礎上引入注意力模塊和殘差模塊用于有效提取紋理和語義信息,不僅能夠判斷是否具有新冠肺炎,而且具有全自動分割新冠肺炎病灶區(qū)域的能力。文獻[13]采用VGGNet 和ResNet 兩個卷積神經(jīng)網(wǎng)絡作為基礎的深度學習模型,引入可視化類激活圖,提高新冠肺炎CT 識別的深度學習模型的可解釋性。
2 數(shù)據(jù)集構建及數(shù)據(jù)預處理
2.1 數(shù)據(jù)集構建
為了提高新冠肺炎圖像CT 識別的準確性,構建的深度學習數(shù)據(jù)集應包含盡可能豐富的新冠肺炎CT圖像。在構建數(shù)據(jù)集的過程中,本研究整合了目前公開的新冠肺炎CT 影像數(shù)據(jù)集,構建出包含大量樣本的數(shù)據(jù)集,該數(shù)據(jù)集優(yōu)勢在于:第一,使用公開數(shù)據(jù)集方便與其他研究者進行分析和對比,消除由于數(shù)據(jù)集中樣本分布不同對結果造成的影響;第二,將多個數(shù)據(jù)集中的影像圖像整合在一起,組合成大樣本數(shù)據(jù)集,大樣本量不僅能夠提供足夠多的新冠肺炎共性特征用于訓練,而且能夠提供不同患者的個性特征,增強深度學習網(wǎng)絡泛化能力,從而提高新冠肺炎識別的準確性。
本研究構建的數(shù)據(jù)集整合了4種公開的數(shù)據(jù)集,分別為COVID-CT識別數(shù)據(jù)集[14]、COVID-19 CT分割數(shù)據(jù)集[15]、COVID-CTset數(shù)據(jù)集[16]和SIRM COVID-19數(shù)據(jù)集[17],4種數(shù)據(jù)集包含的新冠肺炎影像數(shù)量如表1所示。COVID-CT識別數(shù)據(jù)集是從medRxiv和bioRxiv預印本論文中提取的影像,多數(shù)為彩色PNG圖像,根據(jù)論文中描述的患者情況,獲取了216例肺炎患者的349張新冠CT影像。由于不同論文中影像的亮度、胸腔位置不同,數(shù)據(jù)集中的影像差異較大,COVID-CT識別數(shù)據(jù)集需要進行預處理;COVID-19 CT分割數(shù)據(jù)集包含40例患者的100幅CT影像,均為JPG格式,每幅圖像有對應的由放射專家分割出的新冠肺炎區(qū)域,由于COVID-19 CT分割數(shù)據(jù)集是用于影像分割而非識別的,所以沒有未感染新冠肺炎的影像;COVID-CTset是目前樣本數(shù)量最多的新冠肺炎CT影像數(shù)據(jù)集,包含95例患者的15 589幅新冠肺炎CT影像以及48 260幅正常肺部影像,影像采用16位的TIFF格式影像序列表示,比8位圖像包含更多的灰度級信息,但一些影像沒有顯示出肺窗,影像大小統(tǒng)一為512像素的正方形,TIFF格式影像不能直接顯示,需要轉化為灰度圖像才能正常顯示;SIRM COVID-19數(shù)據(jù)集包含60例患者的379幅圖像,不僅有胸腔橫向CT影像,而且有縱向CT影像。

表1 整合的4種公開數(shù)據(jù)集對比Table 1 Comparison of 4 public datasets
2.2 CT影像預處理
預處理是CT 影像識別的前提條件,不同數(shù)據(jù)集中的影像亮度和尺寸不同,并且CT 影像序列中有部分圖像沒有包含肺窗,難以實現(xiàn)新冠肺炎識別。需要進行預處理的CT影像如圖1所示。圖1a中肺部影像區(qū)域較小,包含的肺部特征較少,難以進行新冠肺炎識別;圖1b 中肺部影像亮度較低,影像特征不明顯;圖1c 中肺部影像亮度過高,會引入肺部血管影響的干擾。因此,CT 影像預處理包括影像亮度均衡化和數(shù)據(jù)集清洗兩個步驟。亮度規(guī)范化是將不同數(shù)據(jù)集中亮度范圍不同的圖像規(guī)范化到同一范圍,數(shù)據(jù)集清洗是去掉數(shù)據(jù)集中不能用于識別的無肺窗影像。
(1)圖像亮度規(guī)范化:圖像亮度規(guī)范化是將數(shù)據(jù)集中所有圖像亮度規(guī)范化到同一范圍,目的是消除不同數(shù)據(jù)集中影像數(shù)據(jù)范圍的差異。例如COVIDCTset數(shù)據(jù)集中影像最大灰度值為5 000,其他數(shù)據(jù)集中影像最大灰度值為255,二者差距將近20 倍,特征差距太大會導致神經(jīng)網(wǎng)絡不容易收斂;此外,同一數(shù)據(jù)集中也會出現(xiàn)亮度差異很大的圖像,例如圖1b 和圖1c 均源自COVID-CT 識別數(shù)據(jù)集。考慮到CT 影像的特點主要分為胸壁和胸腔兩部分,分別以淺色和深色作為主要色調(diào),將胸壁和胸腔分別規(guī)范化到兩個固定灰度級,圖像其他區(qū)域灰度級通過線性變換得出。圖1經(jīng)過亮度規(guī)范化后的結果圖像如圖2所示,可以看出所有數(shù)據(jù)集圖像亮度處于同一范圍。
(2)數(shù)據(jù)集清洗:數(shù)據(jù)集清洗的目的是剔除掉沒有肺窗區(qū)域的圖像,該類圖像產(chǎn)生于CT 掃描的開始階段和結束階段,對肺部CT 新冠肺炎識別沒有意義,去掉沒有肺窗的圖像可以防止對后續(xù)數(shù)據(jù)預處理過程造成影響。數(shù)據(jù)集清洗的方法是肺部圖像分割,采用傳統(tǒng)圖像處理方法分割出肺窗區(qū)域,計算肺窗區(qū)域占整幅圖像的比例。根據(jù)對數(shù)據(jù)集中圖像的分析,肺窗區(qū)域占整幅圖像的比例低于20%則認為肺窗區(qū)域過小,不能包含足夠的特征用于檢測識別,應該從數(shù)據(jù)集中去掉。
數(shù)據(jù)集清洗的具體步驟包括閾值分割、圖像形態(tài)學和圖像連通域操作。第一,閾值分割是對圖像進行二值化處理,通過觀察可見,肺窗區(qū)域是胸腔CT影像中最大的兩個空洞,空洞的亮度值明顯低于周圍的腹腔壁,可以通過二值化進行區(qū)分,二值化的閾值使用經(jīng)典算法大津法(OSTU)實現(xiàn)。二值化的結果是將圖像大致分成3 個區(qū)域:外部區(qū)域、胸腔區(qū)域和胸壁區(qū)域;第二,經(jīng)過閾值分割的影像胸腔區(qū)域留有一些毛細血管的圖像,通過圖像形態(tài)學中的開運算去除,開運算是先對圖像進行腐蝕,去除圖像細節(jié)部分,但胸壁區(qū)域會變薄;之后對圖像進行膨脹,恢復影像中胸壁區(qū)域厚度,CT 影像經(jīng)過開運算后得到光滑的分割圖像;第三,通過計算連通域的面積確定胸腔區(qū)域占整幅圖像的比例,如果比例小于10%則認為影像中沒有肺窗,無法進行新冠肺炎識別,需從數(shù)據(jù)集中去掉。以圖2c 為例,進行數(shù)據(jù)集清洗的過程圖像如圖3所示。
CT影像經(jīng)過上述步驟不僅完成數(shù)據(jù)集清洗,同時實現(xiàn)肺窗區(qū)域的分割,雖然這種分割方法不一定精確,但是大致位置是正確的,可以用來作為輔助信息提高CT影像識別的準確性。新冠肺炎病灶集中在肺窗區(qū)域,新冠肺炎早期病灶集中在胸腔和胸壁交界處,正如圖3c中黑色和白色分界線區(qū)域,所以利用CT影像分割結果能夠為CT影像識別提供有用信息。
3 新冠肺炎CT識別模型
由于新冠肺炎CT 影像特征不明顯,較淺的神經(jīng)網(wǎng)絡結構難以充分提取特征,識別準確度較低;較深的神經(jīng)網(wǎng)絡中用于訓練的參數(shù)過多,在樣本不足時容易過擬合,導致識別準確性降低。綜合考慮現(xiàn)有網(wǎng)絡模型,考慮選用DenseNet作為CT 影像識別的主干網(wǎng)絡模型。由于DenseNet主要是通過拼接每個特征擴大特征容量,網(wǎng)絡模型中參數(shù)量不會過大,有利于訓練過程穩(wěn)定收斂,提高識別準確性。新冠肺炎CT 識別模型如圖4所示,圖4a 表示組成DenseNet 的DenseBlock結構,圖4b表示完整的DenseNet網(wǎng)絡。
3.1 模型輸入部分
新冠肺炎CT 識別模型的輸入部分包括亮度規(guī)范化后的CT 影像(Ctimg)以及在數(shù)據(jù)集清洗過程中得到的胸腔區(qū)域分割結果圖(Seg),Ctimg 為單通道灰度圖像,Seg 為二值圖像,二者融合方式為按通道拼接。首先將Ctimg 通過卷積核為3×3 的卷積層得到16 通道的特征圖I,之后將I 與Seg 按通道拼接,得到17通道的特征圖作為DenseNet識別部分的輸入。
3.2 DenseBlock結構
DenseNet 是近年來提出的高精度網(wǎng)絡結構,由于其高效利用了特征圖,一定程度上減少了訓練參數(shù)的數(shù)量,并且減輕了反向傳播中的梯度消失,因此DenseNet 在圖像生成和識別任務中均取得了較好的效果。DenseNet 由多個 DenseBlock 構成,DenseBlock 建立起所有層之間的密集連接,后一層的輸入是前面所有輸出特征層的按通道級聯(lián),實現(xiàn)特征層的重用。DenseBlock 的結構如圖4a 所示,圖中的DenseLayer 包含兩個卷積層:第一個卷積層的卷積核大小為1、步長為1、邊界填充為0、輸出特征通道數(shù)為128;第二個卷積層的卷積核大小為3、步長為1、邊界填充為1、輸出特征通道數(shù)為32,每個卷積層之前都有BatchNorm 層和ReLU 層。DenseLayer 的輸入特征圖和輸出特征圖尺寸相同,輸出特征圖通道數(shù)固定為32,用于提取局部特征。
DenseLayer 是構成DenseBlock 的主要元素,圖4a 中的DenseBlock 由3 個DenseLayer 級聯(lián)組成,分別稱為DenseLayer1、DenseLayer2 和DenseLayer3。DenseLayer1 的輸入特征i0 為輸入部分得到的17 通道特征,經(jīng)過該層處理后得到淺層特征d1;DenseLayer2 的輸入特征i1 為DenseLayer1 的輸出特征d1 和DenseLayer1 前一層的d0 按通道拼接而成,通過DenseLayer2 的卷積運算得到中層特征d2;同理,DenseLayer3 的輸入特征i2 為前面所有層的特征圖d0、d1 和d2 按通道拼接而成,通過DenseLayer3 后得到深層特征d3;整個DenseLayer 的輸出特征O 為d0、d1、d2和d3按通道拼接。
從圖4a 可以看出,由3 個DenseLayer 組成的DenseBlock,實際應用中可由n個DenseLayer 組成DenseBlock,第i個DenseLayer 的輸入為之前所有DenseLayer 的輸出以及第一個DenseLayer 的輸入按通道拼接而成,DenseBlock 的輸出特征通道數(shù)為:輸入特征通道數(shù)+DenseLayer 數(shù)量×32。通過DenseBlock,深度神經(jīng)網(wǎng)絡各個階段的特征得到充分融合,有利于提取新冠肺炎特征。
3.3 DenseNet網(wǎng)絡
DenseNet由多個DenseBlock組成,如圖4b所示。圖像識別神經(jīng)網(wǎng)絡通常通過池化層或步長大于1 的卷積層來減小特征圖的大小,但是DenseBlock 的密集連接需要保證特征圖大小一致,因此在每個DenseBlock 之間插入轉接層來減小特征圖尺寸。轉接層由BatchNorm 層、ReLU 層、卷積層(核尺寸為1,步長為1)和平均池化層(核尺寸為2,步長為2)級聯(lián)組成,經(jīng)過轉接層的特征圖通道數(shù)和尺寸均減小為輸入特征圖的一半。
新冠肺炎CT 識別的DenseNet 模型包含4 個DenseBlock,每個DenseBlock 包含的DenseLayer 數(shù)量分別為6、12、32和32,每個特征圖像的通道數(shù)標注在特征圖向下方。最后通過全局池化層和線性層得到患病和正常的概率。
3.4 Ghost卷積
DenseNet 網(wǎng)絡的后半段 DenseBlock3 和DenseBlock4 中由于卷積層通道數(shù)過多,會一定程度上影響網(wǎng)絡的效率。文獻[18]提出Ghost 卷積用于解決卷積層通道數(shù)量過多的問題,文獻中可視化了卷積特征圖中每個通道的圖像,發(fā)現(xiàn)多組相似的特征圖像,提出卷積層中的一半特征圖可利用另一半特征圖通過簡單變換得到,如圖5所示。以輸入和輸出特征通道數(shù)分別為256 和32 的卷積層為例,Ghost卷積首先通過普通卷積層得到166通道特征圖L2,之后將L2 通過變換層得到L3,變換層通過通道可分離卷積實現(xiàn),最后將L2 和L3 按通道拼接作為Ghost 卷積的輸出。在特征圖通道較多時會減少將近一半的計算量。
4 實驗與分析
4.1 實驗條件
實驗中所用的硬件平臺CPU 為Intel i7-7700K,16 GB 內(nèi)存,顯卡為NVIDIA GTX1080,8 G 顯存。軟件系統(tǒng)為CentOS7,Python 版本為3.6.8,深度學習框架為PyTorch 1.3.1。實驗數(shù)據(jù)集按照5:1 隨機劃分為訓練集和測試集,訓練前批尺寸(BatchSize)和學習率需要設置為固定值,批尺寸通常根據(jù)經(jīng)驗值設置為4 或8,由于顯存限制,實驗中設置批尺寸為4,能夠滿足穩(wěn)定收斂的要求。學習率首先通過經(jīng)驗值設定為0.01 進行訓練,在訓練中觀察誤差曲線,發(fā)現(xiàn)振蕩較大,難以穩(wěn)定收斂。改進學習率為0.001 后進行訓練,發(fā)現(xiàn)誤差曲線下降緩慢并且訓練集損失和測試集損失有一定誤差,表明網(wǎng)絡有一定的過擬合。因此選擇學習率為0.005。二分類模型的評價標準通常采用精確率、召回率、準確率和F1值,根據(jù)二分類混淆矩陣計算。二分類混淆矩陣包含TP、FP、TN 和FN 4個值,TP表示正確識別出的新冠肺炎影像數(shù)量,F(xiàn)P 表示把正常影像識別成新冠肺炎影像的數(shù)量,TN表示正確識別出的正常影像數(shù)量,F(xiàn)N 表示把新冠肺炎影像識別成正常影像的數(shù)量。
模型的精確率、召回率、準確率和F1值定義如式(1)~式(4)所示:
在上述指標中,召回率是新冠肺炎CT 識別中最重要的指標,保證能夠完全檢測出感染者,允許部分的正常人誤檢為患者。因此在二分類交叉熵損失函數(shù)的基礎上提出加權交叉熵損失函數(shù),即增大假陰性的懲罰,損失函數(shù)L表達式如下:
其中,y表示真實類別,患病為1,正常為0,y'表示網(wǎng)絡預測概率,w為權重,設置為0.7。
4.2 遷移學習
實驗過程采用遷移學習的方式進行訓練。遷移學習利用新冠肺炎識別任務之間的相關性,把已經(jīng)訓練好的模型參數(shù)遷移到新的模型中,賦予新的模型先驗知識,使模型學習效率提高,容易實現(xiàn)更高的分類精度[19]。本研究提出的網(wǎng)絡模型的初始參數(shù)值參考文獻[20],文獻[20]中網(wǎng)絡結構采用標準的DenseNet-169,與圖4b 中的DenseNet 部分一致。文獻[20]利用COVID-CT 識別數(shù)據(jù)集采用自監(jiān)督方式進行訓練,得到的精確率、召回率、準確率和F1值分別為0.91、0.79、0.85、0.84,是目前CT 影像識別效果最好的模型之一。
本研究提出的網(wǎng)絡結構在DenseNet-169 的基礎上增加輸入部分,替換后兩個DenseBlock 中的卷積層為Ghost 卷積并修改最后的線性層為全局池化層來減小訓練參數(shù)量[21]。本研究提出的網(wǎng)絡結構DenseNet 部分的前兩個DenseBlock 層(D0-T2)與文獻[20]中網(wǎng)絡結構完全相同,利用文獻[20]中訓練好的網(wǎng)絡參數(shù)作為初始值。DenseNet 部分的后兩個DenseBlock 層(T2-D4)使用Ghost卷積,Ghost卷積層中一半的參數(shù)從文獻[20]對應的卷積層中選取,另一半的參數(shù)通過學習關系自動生成。本研究提出網(wǎng)絡的輸入部分參數(shù)采用隨機數(shù)方式初始化。
4.3 實驗結果
為了證明本研究所提網(wǎng)絡結構的有效性,采用本研究數(shù)據(jù)集與其他常見網(wǎng)絡結構的結果進行對比。同時為了證明遷移學習的有效性,對本文網(wǎng)絡沒有使用遷移學習和使用遷移學習的情況進行對比,結果如表2所示。由表2可知,隨著網(wǎng)絡層數(shù)的增加,從VGG-16、ResNet-50 到DenseNet-169 的效果逐漸變好。本研究網(wǎng)絡識別結果的召回率在所有對比方法中最高,表明加權交叉熵損失函數(shù)的有效性。雖然本研究網(wǎng)絡精確率不是很高,但是在所有對比方法中處于平均水平。本研究網(wǎng)絡在遷移學習中的效果好于無遷移學習的情況,表明遷移學習能夠為網(wǎng)絡參數(shù)提供先驗知識,避免陷入局部最優(yōu)。在遷移學習情況下,本研究網(wǎng)絡召回率、準確率和F1值達到最高,表明所提出方法的有效性。
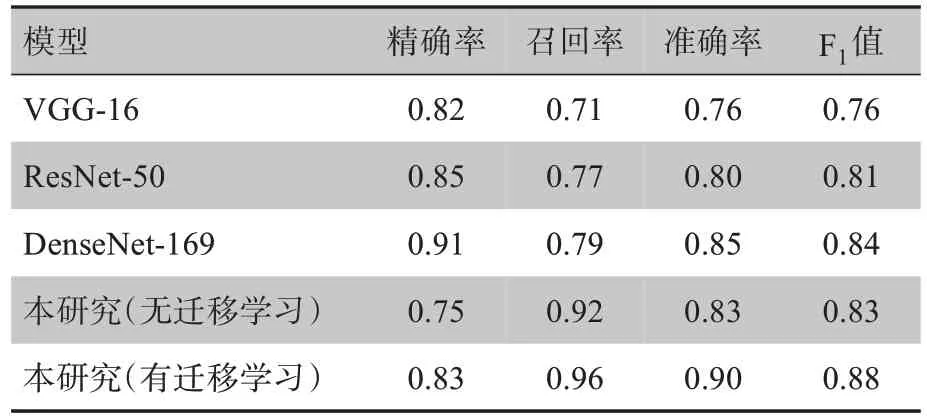
表2 實驗結果對比Table 2 Comparison of experimental results
將訓練好的模型移植到普通醫(yī)用PC(CPU Intel i5-750,內(nèi)存8 G,無GPU)上,模型推理時間為236 ms,能夠達到快速識別的效果,能夠滿足對CT 影響序列的連續(xù)識別。雖然本研究網(wǎng)絡對單幅CT 影像識別率有限,但對CT 掃描過程中的多幅影像識別結果進行綜合分析判斷后,能夠得出非常準確的診斷結果。
5 結論
本研究提出的基于輕量級人工神經(jīng)網(wǎng)絡的新冠肺炎CT 影像識別方法,網(wǎng)絡結構采用DenseNet主干網(wǎng)絡外加輕量級Ghost 卷積,大量增加網(wǎng)絡深度的同時沒有增加太多訓練參數(shù)。整合所有公開的新冠肺炎CT 影像數(shù)據(jù)集以提高網(wǎng)絡泛化能力,加入肺部區(qū)域分割圖像以提高網(wǎng)絡的識別能力,采用加權交叉熵損失函數(shù)降低新冠肺炎識別的漏診率,采用遷移學習的方法進行訓練。實驗結果表明,本研究所提出的方法能夠有效識別新冠肺炎CT 影像,精確率、召回率、準確率和F1 值分別為83%、96%、90%和88%,后三項均優(yōu)于對比方法,精確率處于所有對比方法的平均水平。這表明實驗結果降低了漏診率,能夠保證有效地控制新冠疫情。所提方法雖然在新冠肺炎CT 識別方面取得了較好的效果,但隨著新冠肺炎病毒不斷變異,新冠肺炎CT 影響可能會呈現(xiàn)新的變化,網(wǎng)絡模型應該快速適應這種變化,在實際使用中,應進一步提高人工網(wǎng)絡模型微調(diào)的效率,以適應新冠病毒變化,保證網(wǎng)絡識別效率始終在較高水平。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
