一種采用Transformer網(wǎng)絡(luò)的視覺人格識別方法
2022-11-04 03:40:52唐志偉張石清趙小明
軟件工程 2022年11期
唐志偉,張石清,趙小明,
(1.浙江理工大學(xué)機(jī)械與自動控制學(xué)院,浙江 杭州 310018;2.臺州學(xué)院智能信息處理研究所,浙江 臺州 318000)
1456792435@qq.com;tzczsq@163.com;tzxyzxm@163.com
1 引言(Introduction)
自動人格識別技術(shù)是指通過計算機(jī)等輔助工具,對人們第一印象的行為數(shù)據(jù)(如聽覺、視覺等)進(jìn)行自動識別的過程。目前心理學(xué)中最具影響力的人格評估模型為美國心理學(xué)家MCCRAE等提出的大五類(Big-Five)因素模型。該模型包括開放性(Openness,O)、盡責(zé)性(Conscientiousness,C)、外向性(Extroversion,E)、宜人性(Agreeableness,A)和神經(jīng)質(zhì)(Neuroticism,N),這五個維度代表了人類的人格特征。自動人格識別的研究已成為心理學(xué)、計算機(jī)科學(xué)等相關(guān)領(lǐng)域的研究熱點(diǎn)。
早期的視覺人格識別方法主要是基于手工設(shè)計的視覺人格特征,然后將特征輸入支持向量機(jī)(Support Vector Machine,SVM)等經(jīng)典的分類器,用于實(shí)現(xiàn)視覺人格識別。在面向動態(tài)視頻序列的手工視覺人格特征中,動態(tài)視頻序列是由一系列視頻圖像幀組成,包含了時間信息和場景動態(tài)。面向三個正交平面的局部Gabor二值模式(Local Gabor Binary Patterns from Three Orthogonal Planes,LGBPTOP)是其中一種代表性的手工動態(tài)視頻描述符。KAYA等利用18 個Gabor濾波器對動態(tài)視頻序列人臉圖像提取手工特征LGBP-TOP,進(jìn)一步輸入核極限學(xué)習(xí)機(jī)(Kernel Extreme Learning Machine,KELM)中預(yù)測大五人格特質(zhì)。
隨著深度學(xué)習(xí)技術(shù)的不斷發(fā)展,一系列深度學(xué)習(xí)網(wǎng)絡(luò)模型被用于識別顯著視覺人格特征,包括卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Network,CNN)、長短時記憶(Long Short Term Memory,LSTM)網(wǎng)絡(luò)等。BEYAN等通過采用CNN+LSTM模型學(xué)習(xí)關(guān)鍵動態(tài)圖像的空間和時間信息,最后利用SVM分類器實(shí)現(xiàn)自動人格識別。現(xiàn)有的視覺人格識別模型忽略了視頻序列中每幀圖像對人格識別的影響,為了有效利用視頻中的視覺信息,本文提出一種基于Transformer的視覺人格識別方法。首先采用預(yù)訓(xùn)練好的人臉卷積神經(jīng)網(wǎng)絡(luò)模型VGG-Face提取出視頻序列中的每幀圖像的深度幀級特征,包括視覺場景圖像和視覺人臉圖像。然后將提取出的兩種幀級視覺特征輸入到雙向長短時記憶網(wǎng)絡(luò)(Bidirectional Long Short Term Memory Network,Bi-LSTM)和Transformer網(wǎng)絡(luò)分別進(jìn)行時間信息和注意力信息的建模。最后,將視覺全局特征級聯(lián)并輸入一個線性回歸層網(wǎng)絡(luò),融合視覺特征信息,從而實(shí)現(xiàn)特征層的視覺大五人格預(yù)測得分。在公開數(shù)據(jù)集ChaLearn First Impressions V2上對所提出的模型進(jìn)行了評估,實(shí)驗(yàn)表明,本文所提出的方法能夠有效提升視覺人格識別效果。
2 本文方法(The proposed method)
圖1給出了本文提出的一種采用CNN+Bi-LSTM+Transformer的視覺模態(tài)人格識別模型框架,該方法采用兩種視覺模態(tài)信號:全局場景圖像信號與局部人臉圖像信號,具體包括三個步驟:數(shù)據(jù)預(yù)處理、特征提取和特征層融合,細(xì)節(jié)如圖1所示。
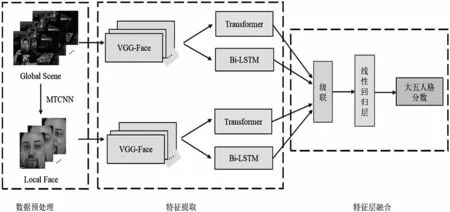
圖1 CNN+Bi-LSTM+Transformer模型框架示意圖Fig.1 Schematic diagram of CNN+Bi-LSTM+Transformer model framework
2.1 數(shù)據(jù)預(yù)處理
對視頻中的視覺圖像信號進(jìn)行采樣處理。對于視頻中的場景圖像,在每個原始視頻中等間隔選擇100 幀場景圖像,并將每幀場景圖像的分辨率從原來的1280×720 像素重新采樣到224×224 像素,進(jìn)而輸入VGG-Face模型中。視頻中的人臉圖像采用多任務(wù)卷積神經(jīng)網(wǎng)絡(luò)(Multi-Task Convolutional Neural Network,MTCNN)進(jìn)行人臉檢測。MTCNN使用三個子網(wǎng)和非極大值抑制(Non-Maximum Suppression,NMS)生成邊界框,并將它們組合輸出面部區(qū)域和關(guān)鍵點(diǎn)。采集的人臉圖像分辨率為224×224。針對部分視頻受光照等環(huán)境影響,導(dǎo)致采用MTCNN方法截取人臉成功率較低,最后選取30 幀截取后的人臉圖像用于后續(xù)人臉圖像特征提取。對于采用MTCNN方法截取人臉圖像多余30 幀的視頻,進(jìn)行等間隔選取30 幀人臉圖像。對于采用MTCNN方法截取人臉圖像少于30 幀的視頻,重復(fù)插入第一幀和最后一幀的人臉圖像,直到獲得大小為30 幀的人臉視頻。
2.2 特征提取
特征提取是對視頻中視覺信號的局部特征和全局特征進(jìn)行提取。
(1)視覺局部特征提取
對于視頻序列中的每幀預(yù)處理圖像(包括場景圖像和人臉圖像),使用在ImageNet數(shù)據(jù)集上預(yù)訓(xùn)練好的VGG-Face模型來學(xué)習(xí)深度視覺場景圖像特征和人臉圖像特征的高層次特征。VGG-Face網(wǎng)絡(luò)由13 個卷積層、5 個池化層和2 個全連接層組成。由于VGG-Face網(wǎng)絡(luò)最后一個全連接層的神經(jīng)元數(shù)為4,096,VGG-Face網(wǎng)絡(luò)學(xué)習(xí)到的視覺幀級特征的維度為4,096。
(2)視覺全局特征提取
當(dāng)完成對視頻中視覺局部特征任務(wù)之后,需要學(xué)習(xí)與時間和幀級注意力相關(guān)的全局視覺場景特征和視覺人臉圖像特征,進(jìn)一步用于完成面向整個視頻序列的人格預(yù)測任務(wù)。為此,擬采用Bi-LSTM與Transformer網(wǎng)絡(luò)分別對視頻序列中提取的視覺局部特征進(jìn)行時間與幀級注意力信息的建模。
①Bi-LSTM方法:給定一個視頻片段序列e=(,,…,e),時間步長∈[1,],Bi-LSTM由前向傳播算法和反向傳播算法疊加組成,輸出則由這兩種算法的隱藏層的狀態(tài)決定。
給定輸入序列e,輸入Bi-LSTM網(wǎng)絡(luò)中,相應(yīng)的學(xué)習(xí)過程為
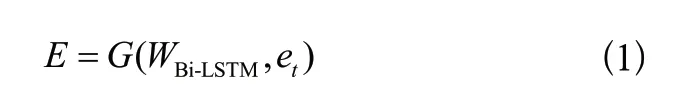
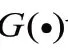
②Transformer方法:如圖2所示,采用的Transformer模塊包括位置嵌入編碼、Transformer編碼層及編碼層內(nèi)置的多頭注意力機(jī)制。
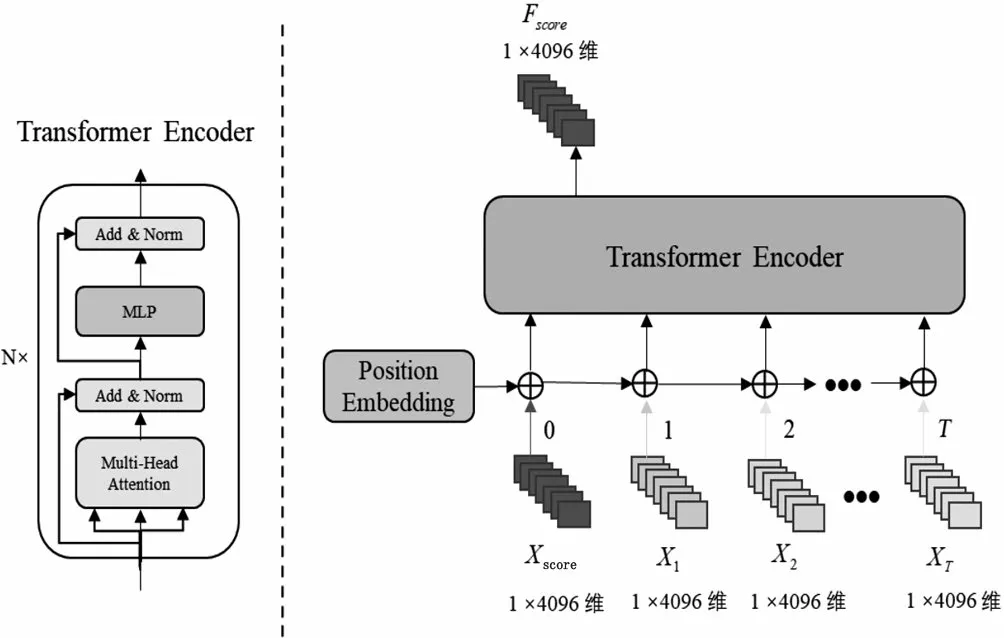
圖2 Transformer模型結(jié)構(gòu)示意圖Fig.2 Schematic diagram of Transformer model structure
(a)位置嵌入編碼:本文采用位置嵌入(Position Embedding)編碼方法為輸入的語音片段和每幀圖像特征添加相應(yīng)的位置信息。以圖像片段特征為例,給定一個片段特征∈R,隨機(jī)生成一個位置矩陣∈R,位置編碼公式如下。
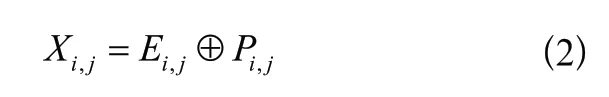
式中,∈[1,] ,∈[1,];位置矩陣P在訓(xùn)練過程中更新;∈R是包含位置信息的片段特征;⊕表示元素相加。
(b)Transformer編碼層:該模塊由多頭自注意力(Multi-Head Self-Attention,MHA)層,殘差(Residual)塊和層歸一化(LayerNorm),一個由兩個全連接層和兩個GELU(Gaussian Error Linear Unit)激活函數(shù)組成的多層感知機(jī)(Multi-Layer Perceptron,MLP)網(wǎng)絡(luò)組成,最后輸出一個片段幀注意力特征∈R,計算過程如下。

(c)多頭注意力機(jī)制:多頭注意力機(jī)制是自注意力機(jī)制的一個變種,最早在自然語言處理領(lǐng)域中用來處理文本序列數(shù)據(jù)。
2.3 特征層融合
為了有效融合學(xué)習(xí)到的視覺場景圖像特征與視覺人臉圖像特征,需要將這兩種視覺模態(tài)信息進(jìn)行融合,以實(shí)現(xiàn)不同視覺模態(tài)的人格識別。本文采用特征層融合方法進(jìn)行不同視覺信息的融合,并與決策層融合方法進(jìn)行比較。這兩種多模態(tài)信息融合方法主要內(nèi)容如下。
決策層融合被稱為后期融合(Late Fusion,LF)。首先對每個模態(tài)先進(jìn)行單獨(dú)的人格預(yù)測,然后通過某種決策規(guī)則將各個單模態(tài)的預(yù)測結(jié)果進(jìn)行結(jié)合,并得到最終的融合結(jié)果,因此本文對兩個視覺模態(tài)進(jìn)行加權(quán)決策融合。擬采用XU等提出的均方誤差(Mean Squared Error,MSE)最小化的思想,得到了各個模態(tài)的最優(yōu)權(quán)重值。
特征層融合被稱為早期融合(Early Fusion,EF),是將提取的多種特征直接級聯(lián)成一個總的特征向量。本文將提取的全局性的視覺場景特征和視覺人臉圖像特征級聯(lián)到一個線性回歸層(Linear Regresion Layer),實(shí)現(xiàn)大五人格預(yù)測。
3 實(shí)驗(yàn)(Experiment)
3.1 數(shù)據(jù)集
實(shí)驗(yàn)采用的人格識別數(shù)據(jù)集為ChaLearn First Impression V2,由YouTube視頻中的10,000 個短視頻組成,每個視頻分辨率為1280×720,時長約15 s,面對攝像機(jī)說話的人使用英文。視頻所涉及的人具有不同的性別、年齡、種族等,其中6,000 個用于訓(xùn)練,2,000 個用于驗(yàn)證,2,000 個用于測試。因?yàn)闇y試集只對參加競賽者開放,本文實(shí)驗(yàn)只使用訓(xùn)練集和驗(yàn)證集。這些視頻剪輯使用大五人格特質(zhì)進(jìn)行注釋,每個特質(zhì)都用范圍[0,1]之間的值表示。
3.2 實(shí)驗(yàn)參數(shù)設(shè)置
模型在訓(xùn)練過程中,樣本的批處理大小(Batch Size)設(shè)為32,初始學(xué)習(xí)率設(shè)為1×e,每一個輪次(Epoch)后都會變?yōu)樵瓉淼囊话搿W畲笱h(huán)次數(shù)設(shè)為30,使用自適應(yīng)矩估計(Adaptive Moment Estimatio,Adam)優(yōu)化器進(jìn)行優(yōu)化,采用均方誤差損失函數(shù)(Mean Squared Error Loss,MSEloss),實(shí)驗(yàn)平臺為顯存24 GB的NVIDIA GPU Quadro M6000。
本文使用如下公式作為評價指標(biāo)用來評估預(yù)測的人格特質(zhì)分?jǐn)?shù):
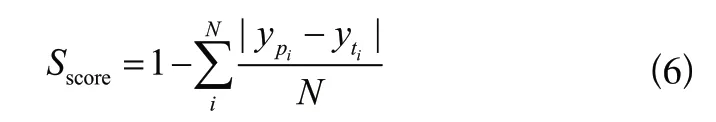
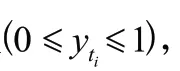
3.3 實(shí)驗(yàn)結(jié)果及分析
(1)消融實(shí)驗(yàn)
本文模型主要由Bi-LSTM和Transformer模塊組成,在第一印象數(shù)據(jù)集上進(jìn)行三組實(shí)驗(yàn),驗(yàn)證各模塊的有效性。
表1為消融實(shí)驗(yàn)結(jié)果。如表1所示Bi-LSTM模型在ChaLearn First Impression V2人格數(shù)據(jù)集中的大五人格平均分?jǐn)?shù)為0.9136,而Transformer模型在人格數(shù)據(jù)集取得的大五人格平均分?jǐn)?shù)為0.9022,Bi-LSTM表現(xiàn)更好,可知Bi-LSTM模型學(xué)習(xí)的時間維度特征比Tansformer模型學(xué)習(xí)的幀注意力特征更重要。Transformer與Bi-LSTM相結(jié)合后的模型BL+Tran取得了最好的分?jǐn)?shù)。這說明Transformer學(xué)習(xí)到的幀注意力特征與Bi-LSTM學(xué)習(xí)到的時間維度特征存在互補(bǔ)性,兩者相結(jié)合能夠明顯提升多模態(tài)人格識別性能。
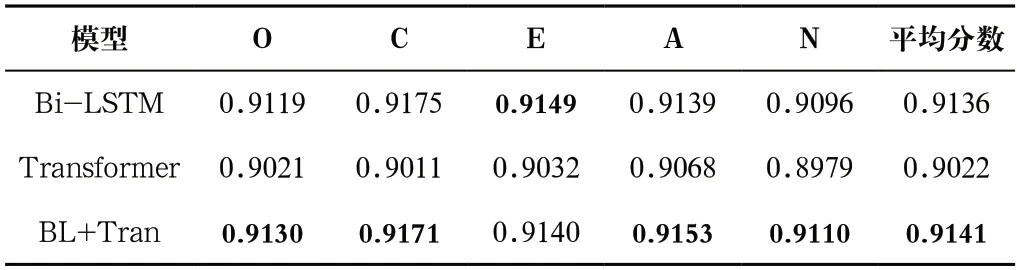
表1 消融實(shí)驗(yàn)對比結(jié)果Tab.1 Comparison results of ablation experiments
(2)單視覺模態(tài)人格識別結(jié)果及分析
本文將支持向量回歸(Support Vector Regression,SVR)和決策樹回歸(Decision Tree Regression,DTR)經(jīng)典回歸模型用于單視覺模態(tài)人格識別實(shí)驗(yàn)。其中SVR采用了多項(xiàng)式(Poly)函數(shù)、徑向基函數(shù)(Radical Basis Function,RBF)和線性(Linear)函數(shù)三種核函數(shù),核函數(shù)的階數(shù)degree=3,懲罰因子C=2.0,參數(shù)gamma=0.5。這些回歸模型使用的輸入特征是對提取的視覺局部特征經(jīng)過平均池化后得到的全局特征。深度學(xué)習(xí)模型LSTM和Bi-LSTM,均使用兩層結(jié)構(gòu),且最后一層均輸出2,048 維特征。對于基于注意力機(jī)制的Transformer模型,使用六層編碼層,最后一層輸出1,024 維特征。對于Bi-LSTM+Transformer,級聯(lián)后最后一層輸出3,072 維特征。
表2和表3分別是對深度視覺場景圖像特征與深度視覺人臉圖像特征采用預(yù)訓(xùn)練好的VGG-Face提取后從不同模型學(xué)習(xí)得到的人格預(yù)測結(jié)果。由表2和表3可見,深度視覺場景圖像特征與深度視覺人臉圖像特征在深度學(xué)習(xí)模型Bi-LSTM+Transformer中分別獲得0.9044和0.9128的最高大五人格平均分?jǐn)?shù),表明該模型在視覺模態(tài)人格識別中具有一定的優(yōu)勢,傳統(tǒng)回歸模型DTR、SVR與深度學(xué)習(xí)模型Transformer、LSTM和Bi-LSTM在視覺模態(tài)人格預(yù)測分?jǐn)?shù)上相比,劣勢明顯,其中DTR表現(xiàn)最差。這兩種單視覺模態(tài)特征在人格預(yù)測中,深度視覺人臉圖像特征表現(xiàn)優(yōu)于深度視覺場景圖像特征,這表明人臉圖像特征在人格識別任務(wù)中包含更多的識別信息。
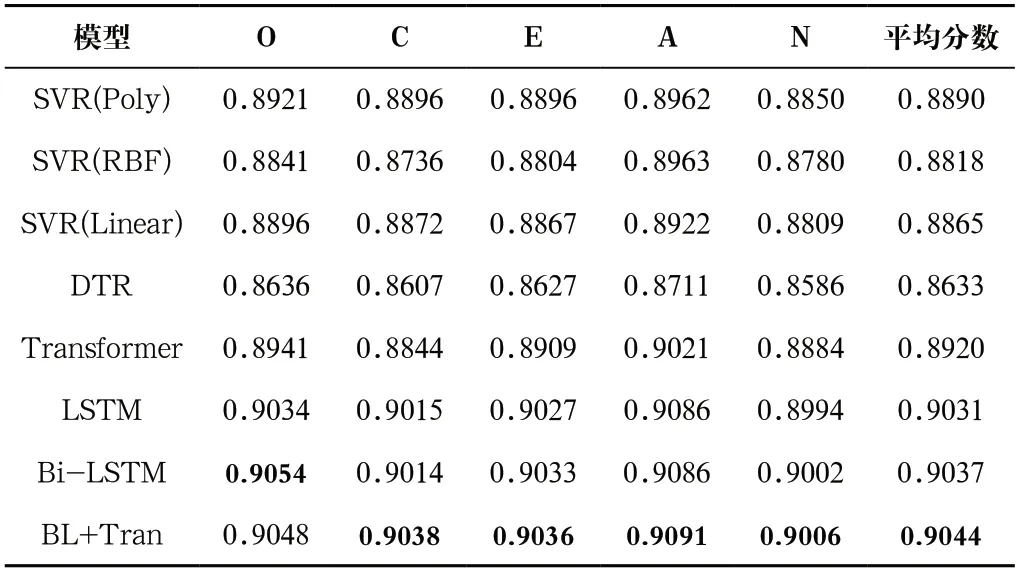
表2 不同方法下深度視覺場景圖像特征的人格預(yù)測結(jié)果Tab.2 Personality prediction results of image features of deep vision scene under different methods
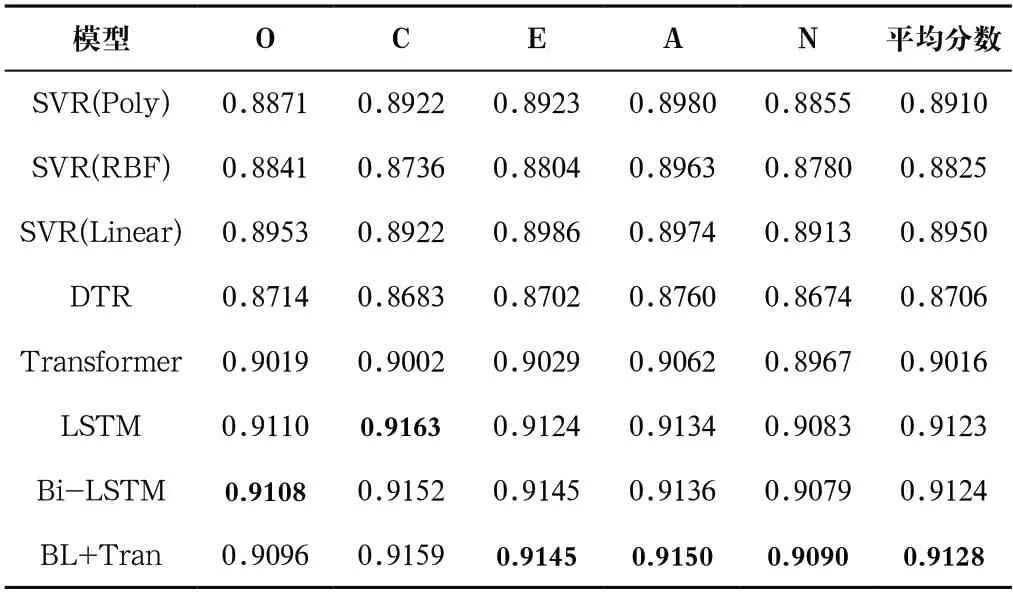
表3 不同方法下深度視覺人臉圖像特征的人格預(yù)測結(jié)果Tab.3 Personality prediction results of image features of deep vision face under different methods
(3)融合場景與人臉圖像的視覺人格識別結(jié)果及分析
在視覺模態(tài)人格識別任務(wù)中分別使用特征層與決策層融合方法進(jìn)行實(shí)驗(yàn)。
表4列出了單視覺模態(tài)和兩種視覺模態(tài)在特征層融合和決策層融合方法取得的人格識別結(jié)果比較,其中Scene指場景圖像,F(xiàn)ace指人臉圖像。特征層融合是對Transformer與Bi-LSTM學(xué)習(xí)到的視覺全局特征(6,144 維)進(jìn)行級聯(lián),然后輸入一個線性回歸層而獲得的結(jié)果。決策層融合是對Bi-LSTM+Transformer在兩種視覺模態(tài)獲得的大五人格分?jǐn)?shù)采用XU等最優(yōu)加權(quán)策略融合得到的。
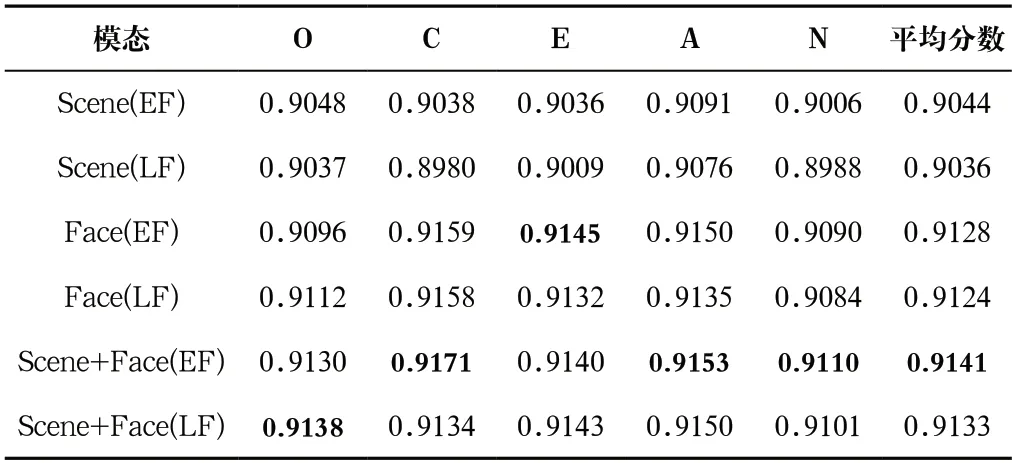
表4 特征層融合和決策層融合方法取得的人格識別結(jié)果比較Tab.4 Comparison of personality recognition results obtained by feature-level fusion and decision-level fusion methods
由表4可見,兩種視覺模態(tài)融合時,使用特征層融合方法效果優(yōu)于決策層融合方法,大五人格平均分?jǐn)?shù)為0.9141。
4 結(jié)論(Conclusion)
本文提出了一種基于Transformer的視頻序列的人格識別方法。該方法將VGG-Face、Bi-LSTM和Transformer模型結(jié)合,分別用于學(xué)習(xí)對應(yīng)更高層次的視覺全局特征。最后比較了特征層與決策層的視覺人格預(yù)測結(jié)果。在ChaLearn First Impression V2公開人格數(shù)據(jù)集上的實(shí)驗(yàn)表明,本文方法能有效提升視覺模態(tài)人格識別模型的性能。由于當(dāng)前工作中只考慮了視覺模態(tài),在未來工作中應(yīng)考慮增加文本、聽覺、生理信號等更多與人格特質(zhì)相關(guān)的模態(tài)信息,嘗試更多先進(jìn)的融合方法,以便更好地提升人格識別效果。
猜你喜歡
今日農(nóng)業(yè)(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學(xué)生數(shù)理化(高中版.高考數(shù)學(xué))(2021年1期)2021-03-19 08:28:38
現(xiàn)代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學(xué)小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
湖北經(jīng)濟(jì)學(xué)院學(xué)報·人文社科版(2015年8期)2015-12-29 05:53:07
上海電機(jī)學(xué)院學(xué)報(2015年4期)2015-02-28 14:30:00
計算物理(2014年2期)2014-03-11 17:01:39
