基于循環神經網絡和余弦相似度算法的智能客服機器人研究
2022-11-04 03:41:02蔡發群
軟件工程 2022年11期
關鍵詞:信息
蔡發群
(南京科技職業學院,江蘇 南京 210048)
295463913@qq.com
1 引言(Introduction)
隨著互聯網的發展,購物方式發生了巨變。電子商務已成為主流商務形式,越來越多的商家實施線上交易。電商渠道的商家與客戶交流的主要紐帶就是客服。為了能夠提高客戶的滿意度,促成交易,商家不得不雇傭大量的客服人員。這就導致市場上客服人員供不應求;另一方面,由于工作壓力大,晉升空間有限,所以,客服人員流失嚴重,服務質量難以保證。人工客服招聘難,流動大,成本高,促使客服機器人應運而生。部分企業也積極上馬客服機器人,取代人工客服。然而,客服機器人技術尚不成熟,很多店鋪的客服機器人不僅不能很好地解決客戶的疑慮,提高客戶滿意度,反而降低了客戶的滿意度,甚至答非所問,讓客戶抓狂。因此,如何構建智能客服機器人,實現精準解答客戶疑問和投訴成為客服機器人主攻研究方向。
2 文獻綜述(Literature review)
1966 年世界上第一個對話機器人ELIZA誕生于麻省理工學院。1995 年Richard S.Wallace博士開發了ALICE系統。2001 年,機器人SmarterChild上線。2008 年,整合了眾多網絡服務功能的蘋果Siri上架。2015 年,京東JIMI正式接入。用戶可以通過與JIMI聊天了解商品的具體信息以及反饋購物中存在的問題等。JIMI知道自己不能回答用戶的哪些問題,并且知道何時應該轉向人工客服。
對話機器人以檢索式為主,必須由一個或若干個問答數據庫作為支撐。用戶提出問題時,系統通過檢索、匹配技術從數據庫中找出答案來進行回復。因此,數據庫的質量對答復的有效性和準確性有很大的影響。然而,數據庫規模再大,質量再好,也不可能實現永遠完美答復,因為對話的場景日新月異,人們的表達方式也隨著時間不斷變化,這些變化都需要對數據庫進行更新和補充。近年來,深度學習方法在自然語言、語音、圖像、視頻等領域發展迅猛。使用圖神經網絡構建推薦算法逐漸成為當今推薦算法的研究熱潮。這個方法恰好可以解決客服機器人自動更新和擴充數據庫的需求。
3 基于循環神經網絡學習算法的智能機器人答復推薦系統(Intelligent robot reply recommendation system based on recurrent neural network learning algorithm)
客服機器人給出準確答案的過程主要包括三個步驟。第一步,數據采集。數據采集包括客戶基本信息、客戶行為信息、客戶提問信息以及常見客戶歷史問題及對應回復信息等。第二步,數據處理。數據處理主要是進行客戶提問標簽提取。首先,對客戶當前提問進行分詞處理,抽取出可以代表其含義的屬性詞,用具體的詞向量來表示客戶的抽象提問,每個詞對應的權重由信息檢索算法TF-IDF來決定,然后利用客戶購物、瀏覽、咨詢及評價等歷史信息的特征數據,以及客戶的年齡、性別、地域等來分析出此用戶的提問特征,最終提取出客戶提問標簽。第三步,答復推薦。通過對比客戶提問標簽和數據庫中問題標簽,為用戶推薦相關性最大的回復信息。具體步驟如圖1所示。
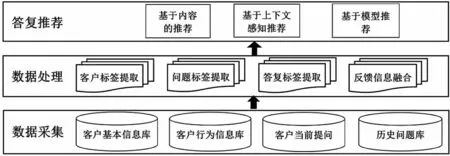
圖1 基于循環神經網絡學習算法的智能機器人答復推薦系統Fig.1 Intelligent robot reply recommendation system based on recurrent neural network learning algorithm
3.1 數據采集
客服機器人回復客戶提問的主要依據,除了客戶當下提問內容外,還要考慮客戶年齡、性別、偏好、地域、受教育程度、人口統計學信息,用戶的瀏覽、購買、評價行為信息等。因此,客服機器人必須先采集相關信息。
客戶提問可以通過相關入口直接錄入。而客戶年齡、性別、偏好、地域、受教育程度、人口統計學信息則可以在客戶注冊時錄入到客戶基本信息庫,需要時再在客戶基本信息庫中提取。用戶的瀏覽、購買、評價等行為信息可以在客戶購物過程中錄入到客戶行為信息庫中。
3.2 數據處理
對于客戶的提問,首先必須進行分詞處理,將非結構化的客戶提問分成一個個詞語,并對每個詞語賦予權重,然后結合客戶的基本信息和行為信息,構成客戶提問向量,從而獲取客戶提問標簽。問題庫中的問題也用同樣的方法設置標簽。最后將客戶提問標簽與問題庫中的問題標簽進行對比,從而確定如何答復客戶。
要想實現精準回答,智能客服機器人必須能夠分析客戶提問和問題庫中問題的語義。國內客服機器人主要服務于中國人,因此,必須要先學會中文分詞。中文分詞作為中文自然語言處理領域的重要基礎研究,近些年來很多專家學者致力于該領域的研究,研究方法主要分為三種:(a)基于規則的方法;(b)基于傳統機器學習模型的方法;(c)基于深度神經網絡模型的方法。深度神經網絡模型基礎算法是自然語言處理算法(Natural Language Processing,NLP),包括詞法分析、句法分析、語義分析、文檔分析等。
中文分詞是一個經典的預測序列問題,方法主要有基于隱含馬爾柯夫模型(Hidden Markov Model,HMM)分詞法、基于條件隨機場(Conditional Random Field,CRF)分詞法和基于LSTM的分詞方法。Hochreiter等人在1977 年又提出LSTM模型,LSTM是循環神經網絡(Recurrent Neural Network,RNN)的一個變種,它克服了RNN模型訓練過程中梯度消失和梯度爆炸的缺陷。LSTM模型的總體結構如圖2所示。
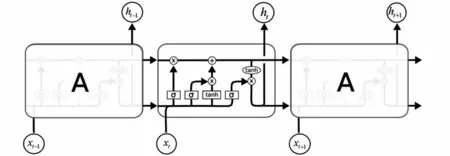
圖2 LSTM模型總體結構Fig.2 Overall structure of LSTM model
LSTM在循環單元內部引入了門限(gate)結構。LSTM模型中有三個“門”,分別是“遺忘門”“輸入門”和“輸出門”,分別用于決定哪些信息要舍棄,哪些信息要留下,最終輸出哪些信息。如圖3所示,時刻的相關信息受-1 時刻的信息影響,同時又影響著+1 時刻,從而保持持續性。
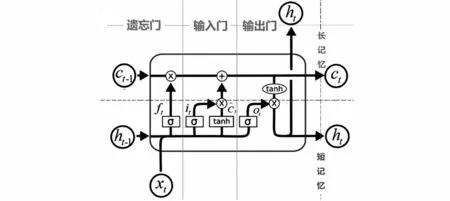
圖3 LSTM模型詳解圖Fig.3 LSTM model details


為了將中文分詞問題轉化成序列標注問題,就需要將分詞中的每一個字進行標注。在深度學習分詞研究工作中,常用的標注集是四詞位(B、M、E、S),分別表示一個分詞的開始詞位、中間詞位、結束詞位以及以單獨一個字構成的分詞。中文分詞中,LSTM記憶單元就是文本的上下文,再結合相關函數,推理出文本的分詞構成。
客服機器人研究的對象主要是客戶的提問和問題庫問題,都屬于非結構化數據。一般用向量空間模型(Vector Space Model,VSM)將非結構化的問題結構化。

這樣就可以實現對所有客戶可能提出問題歸一化。可以讓不同問題統一用向量表示,這些向量就可以作為對應答復的標簽。
客服機器人除了要考慮客戶的當前提問,還需要考慮客戶的購物經歷、評價、瀏覽、以往提問等信息,以及年齡、性別、地域、受教育程度、地域等信息,還有人口統計學特征或行為特征等,也將作為向量維度。因此客戶提問標簽可以表示為
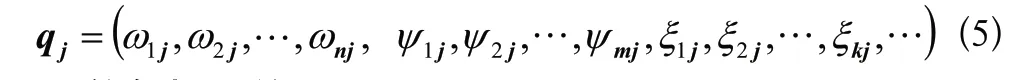
3.3 答復推薦算法
目前搜索引擎、社交媒體等平臺使用的推薦算法主要有Rocchio算法、決策樹算法(Decision Tree,DT)、線性分類算法(Linear Classifer,LC)、樸素貝葉斯算法(Naive Bayes,NB)、余弦相似度算法(Cosine Similarity,CS)等。
Rocchio算法是一種匹配推薦算法,是處理反饋的著名算法,經常用于搜索引擎。往往會先向客戶呈現各種可能結果。然后根據客戶的點擊情況,再縮小結果范圍,慢慢精準化。這種方法顯然不適合客服機器人。
決策樹算法是一種逼近離散函數值法,是一種典型的分類方法。首先利用歸納算法生成可讀的規則和決策樹,然后對數據進行分析。決策樹算法其實是通過一系列規則對數據進行分類。當項目屬性較少而且是結構化屬性時,決策樹一般會是個好的選擇。但是如果項目的屬性較多,且都來源于非結構化數據,比如文章、問題等,那么決策樹算法的效果就不理想了。
線性分類算法指用一個線性方程把待分類數據分開。對于二維的情況,就是用一條直線將數據分開。對于三維的情況,則是用一個超平面將數據區分開來。它的分類算法基于一個線性預測函數,決策的邊界是平的,比如直線和平面。這種方法顯然也不適合客服機器人。
樸素貝葉斯方法是在貝葉斯算法的基礎上進行了簡化。基于樸素貝葉斯算法進行分類的基本原理是假設特征之間互相獨立,既沒有哪個屬性對于決策結果影響比較大,也沒有哪個屬性對于決策結果影響比較小。這種方法簡化了貝葉斯方法的復雜性,但是,在一定程度上降低了貝葉斯分類算法的分類效果。
余弦相似度算法是通過向量空間中兩個向量夾角的余弦值作為衡量兩個項目間相似性的方法。余弦值越接近1,角越接近0 度,表明兩個向量越相似性高,等于1時表明兩個向量完全相同,如圖4所示。余弦值越接近-1,角越接近180 度,表明兩個向量基本不相似,或相似度很低。兩個向量之間的角度的余弦值確定兩個向量的方向的一致性。余弦相似度通常用于正空間,因此給出的值為-1到1。
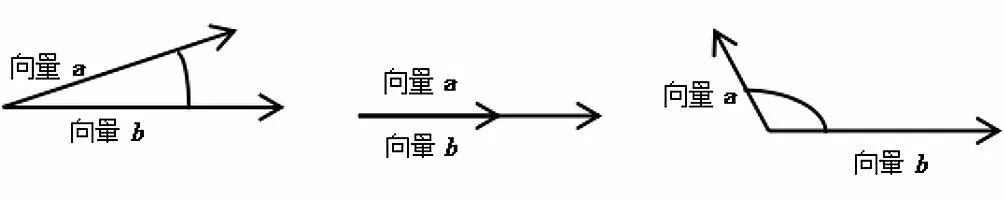
圖4 余弦相似度算法原理圖Fig.4 Schematic diagram of cosine similarity algorithm
向量空間余弦相似度理論就是基于上述原理來計算個體相似度的。假設向量(,)、向量(,)是二維向量,如圖5所示,那么余弦定理的表達形式,即向量和向量夾角的余弦為
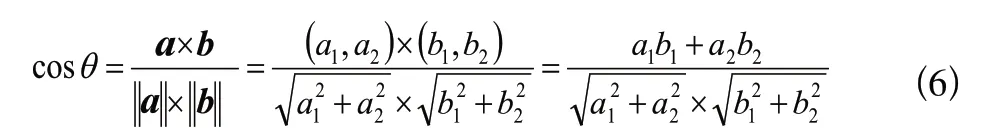
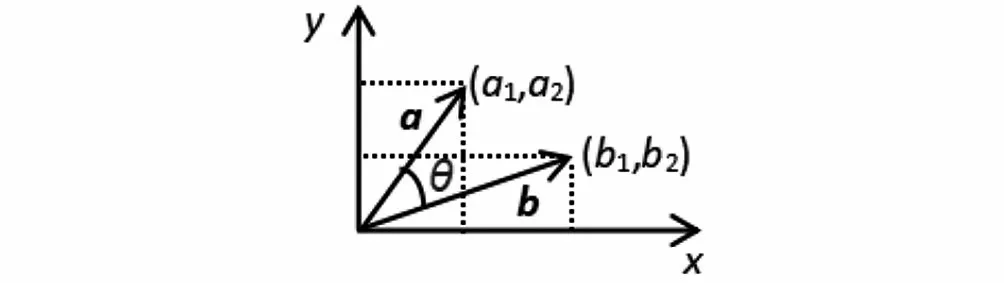
圖5 二維向量夾角示意圖Fig.5 Schematic diagram of included angle of twodimensional vector
當向量和向量為維向量時,則向量與向量夾角的余弦為
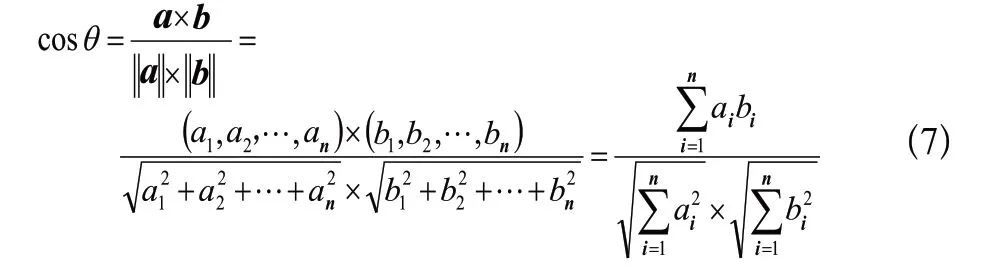
余弦相似度算法通常用于數據挖掘中的文本比較。智能客服機器人在回答客戶問題時主要用到的就是文本比較。因此,余弦相似度算法比較適合客服機器人答復推薦。首先,基于LSTM網絡學習將客戶提問和問題庫中的問題向量化,然后就可以利用余弦相似度算法比較客戶提問和問題庫中問題向量的相似度,從而確定提交給客戶的答復信息。
假設某服裝店鋪的客戶提問:皮膚黑選哪個顏色比較合適呢?
假設問題庫中有9 個問題,其中只有問題A和問題B與客戶提問有共有詞。
問題A:皮膚白哪個顏色合適?
對應答復:親,皮膚白穿什么顏色都好看哦,只是不同的顏色彰顯的氣質不同。粉色溫柔、甜美,黃色明快、純潔,紅色熱烈、有朝氣,深藍色低沉、神秘,紫色優美高雅、雍容華貴。親可以根據自己的需要選哦。
問題B:皮膚黑哪個顏色合適?
對應答復:親,您好,根據我們的經驗,淡黃色、豆沙粉、米白色比較襯皮膚,顯白哦!
在暫不考慮客戶基本信息和行為信息的情況下,到底應該把哪個答復推薦給客戶呢?基本思路是要看客戶提問與問題庫中問題的相似性,而兩者之間的相似性取決于詞向量的關系,因此,先對它們進行分詞,然后計算權重,最后得到詞向量,最后再利用余弦相似度算法計算客戶提問與問題庫中各問題的相似程度,取值最大的那個就是問題的答復。
第一步,對客戶提問和問題庫問題進行分詞處理。
客戶提問:皮膚/黑/選/哪個/顏色/比較/合適/呢?
問題A:皮膚/白/哪個/顏色/合適
問題B:皮膚/黑/哪個/顏色/合適
第二步,通過對人工客服語料庫訓練可知,語氣詞“呢”,形容詞“比較”,以及“?”等在聯系上下文的情況下可以忽略不計。因此,可以列出所有詞:皮膚,黑,白,選,哪個,顏色,合適。
第三步,計算客戶提問和問題庫問題詞頻。
客戶提問:皮膚1,黑1,白0,選1,哪個1,顏色1,合適1
問題A:皮膚1,黑0,白1,選0,哪個1,顏色1,合適1
問題B:皮膚1,黑1,白0,選0,哪個1,顏色1,合適1
第四步,給出客戶提問和問題庫問題詞頻向量,即它們的標簽。
客戶提問向量:[1,1,0,1,1,1,1]
問題A向量:[1,0,1,0,1,1,1]
問題B向量:[1,1,0,0,1,1,1]
根據TF-IDF算法可知,客戶提問標簽如下式:
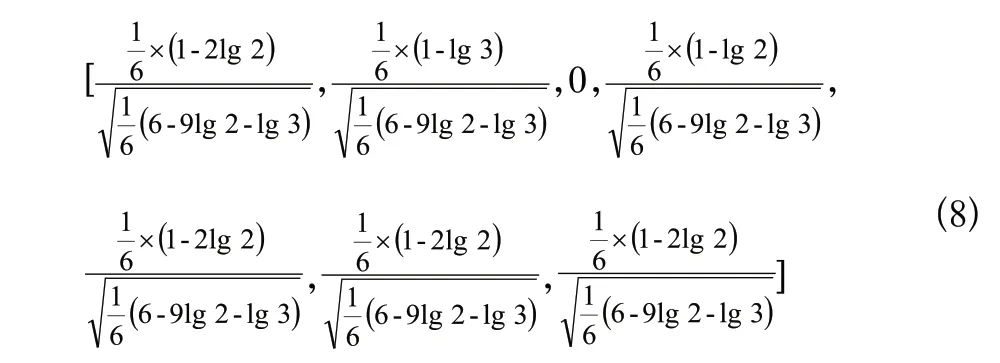
因此,客戶提問標簽為[0.1,0.13,0,0.17,0.1,0.1,0.1]。
同理可知,問題A標簽為[0.12,0,0.21,0,0.12,0.12,0.12],問題B標簽為[0.12,0.16,0,0,0.12,0.12,0.12]。
現在,問題比較就變成如何計算向量夾角余弦值的問題了。三個問題就像空間中的三條向量,都是從原點(0,0,0,0,0,0,0,0)出發,指向不同的方向。每兩個向量之間形成一個夾角,夾角余弦值代表著兩個向量方向的一致性,也就是提問和問題間的相似性程度。
根據余弦相似度算法,客戶提問和問題A兩個向量之間夾角的余弦值,如式(9)所示。
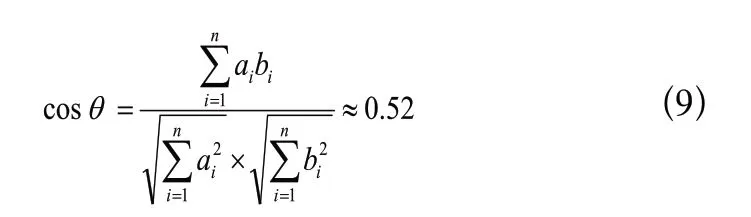
同理,客戶提問和問題B兩個向量之間夾角的余弦值約為0.81。計算結果表明客戶提問與問題B兩個向量間的夾角的余弦值為0.81,遠大于客戶提問與問題A間的夾角的余弦值0.52。所以客戶提問和問題B更相似,因此應該將問題B對應的答復提交給客戶。當然從語義表達上可以看出,雖然問題A和問題B中沒有“選”這個詞,但加上有這兩個詞后語義是沒有什么改變的。考慮到這一點,兩個余弦值應該更高,相似性也會更明顯些。
4 結論(Conclusion)
中國語言博大精深,有的一詞多義,有的則是一義多詞,因此,不同語境下分詞結果可能會不同,不同的分詞結果,向量表達也有可能相同。要想精確表達,還需進一步優化算法。本研究采用LSTM算法進行分詞,還不能完全解決分詞歧義,序列長度超過一定限度后,LSTM算法也會出現梯度消失的情況。另外,利用余弦相似度算法進行答復推薦也存在一定的局限性。余弦相似度算法只考慮向量的方向,不考慮其大小。因此,推薦答復時,可能還不夠準確。智能機器人技術在不斷發展中,相關算法在不斷升級,后期還要進一步研究相關算法,以實現客服機器人精準答復。
猜你喜歡
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
大眾創業(2009年10期)2009-10-08 04:52:00
數字社區&智能家居(2009年7期)2009-09-29 08:16:48
數字社區&智能家居(2009年11期)2009-06-25 04:30:34
數字社區&智能家居(2009年3期)2009-04-21 03:09:04
數字社區&智能家居(2009年2期)2009-03-27 04:33:44
數字社區&智能家居(2009年12期)2009-02-03 07:50:48
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
