基于檢索與生成混合模型的個性化聊天機器人系統的設計與實現
2022-11-04 03:40:56孔繁恒高永祺張子帥阮俊豪
軟件工程 2022年11期
孔繁恒,高永祺,張子帥,阮俊豪,馮 時
(東北大學計算機科學與工程學院,遼寧 沈陽 110819)
kongfanheng426@163.com;905323742@qq.com;1060876095@qq.com;954369920@qq.com;fengshi@stu.neu.edu.cn
1 引言(Introduction)
伴隨著互聯網數據的爆發式增長,聊天機器人產品出現在人們的視野中。聊天機器人是經由對話或文字進行交談的計算機程序,能夠模擬人類對話,為用戶提供了智能、自然連貫的對話服務。聊天機器人根據其對話生成技術主要分為檢索式和生成式。檢索式模型使用信息檢索的技術,從事先處理好的語料庫中選擇匹配的對話作為應答。生成式模型使用深度學習的技術,通過預先訓練的模型合成適當的應答。
在對話中保持一致的個性對于人類來說是很自然的,但對于機器來說卻不是一件平凡的任務,由于在自然語言中體現個性的困難,以及在大多數對話語料庫中觀察到的人物角色稀疏問題,仍然沒有得到很好的探討。本文設計了一種檢索-生成混合模型,該模型可以利用人物角色稀疏對話數據生成連貫的響應。通過對說話人的角色和對話歷史進行編碼,設計個性屬性嵌入,來模擬更豐富的對話語境,從而實現個性化的聊天機器人系統。
2 需求分析(Requirements analysis)
作為人機交互領域一個非常重要的研究方向,人機對話系統正處于蓬勃發展的階段。傳統的問答系統已經不能滿足人們的要求,如今人們更偏向于系統擁有更廣泛的知識領域并能夠具有特定的個性,使得人機對話更加生動、順暢。聊天機器人,主要任務是利用自然語言完成與人在任意話題上的交流,其涉及的話題之廣、表達方式之多更能符合用戶的需求。
本系統所要實現的目標為個性化的智能聊天機器人系統,擁有進行個性化聊天的功能。用戶在與本系統交互時,可以設置聊天機器人的個性信息。系統會通過對用戶設置的角色和對話歷史進行編碼,模擬對話語境,分別得到檢索式和生成式兩種回復方式,將兩者評價比較后選擇最優回復,并顯示在聊天界面上,實現個性化的聊天。本系統的各功能模塊如圖1所示。
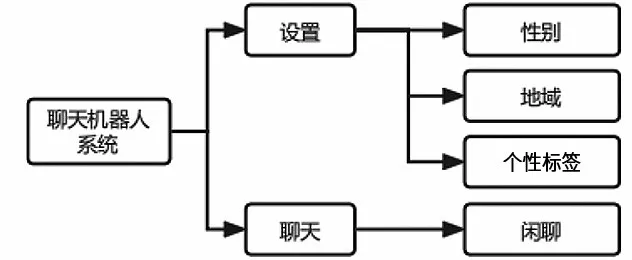
圖1 系統功能模塊圖Fig.1 System function block diagram
3 系統設計和實現(System design and implementation)
3.1 總體設計
本系統以PyTorch為開發框架,采用深度學習的技術,使用檢索-生成混合模型,構建了一個個性化的智能聊天機器人系統。前端采用Tkinter模塊接口,后端采用PyTorch開發框架,均使用Python語言編寫。前端為Graphical User Interface(GUI),分為兩部分:設置界面(可供用戶設置聊天機器人的個性信息,包括性別、地域和個性標簽)與聊天界面。后端使用檢索-生成混合模型,檢索模型采用Elasticsearch搜索服務器,檢索速度極快,大大降低了整體系統的回復生成時間;生成模型采用PostKS模型,可以定向設置聊天機器人的個性并生成具有特定個性的回復。通過混合兩種模型提高了回復的相關性和流暢性,語句質量較高。
在后端設計中,選擇具有個性信息的2019 年社會媒體處理大會中文人機對話技術評測(SMP2019-ECDT)對話集和質量較高的小黃雞語料庫作為數據集,然后進行數據預處理,包括篩選高頻個性標簽、數據清洗、調整數據格式等。檢索模塊使用Elasticsearch搜索服務器及小黃雞語料庫構建檢索模型,生成模塊首先構建PostKS個性化生成模型,然后利用SMP2019-ECDT對話集進行訓練。前端為用戶提供窗口輸入個性信息與對話,以字符串的形式傳送到后端。后端接收到用戶發送的信息,分別傳送到檢索和生成模塊中生成應答,在回復選擇模塊比較兩種模型生成的應答并選擇合適的應答,同時將此應答傳回前端并展示到界面上。系統總體結構如圖2所示。
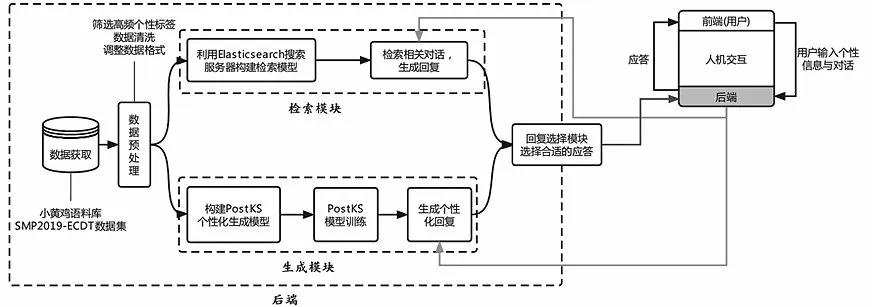
圖2 系統總體結構圖Fig.2 System overall structure diagram
3.2 數據集獲取及預處理
本文選取SMP2019-ECDT提供的數據集作為生成模型的原始數據,數據集中包含約500萬輪次的對話(既包含單輪對話又包含多輪對話),以及參與這些對話的發話人的個性化信息(包括性別、個性標簽、所屬地域)。數據集為JSON格式,如{"dialog":[["瘋了瘋了"],["我要帶到教室去上課你就羨慕我吧!"]],"profile":[{"tag":["美食"],"loc":"四川成都","gender":"female"},{"tag":["娛樂;旅游"],"loc":"四川","gender":"female"}],"uid":[0,1]},其中dialog為對話,profile表示對話人的個性化信息,包括tag——個性標簽、loc——所屬地域、gender——性別、uid——對話人id。
由于生成模型需要個性信息作為特征,標簽的篩選十分重要,因此要對數據集進行預處理。首先將相似的標簽進行合并,例如“電影”“愛電影”“電影愛好者”這類標簽可以合并成一類。然后篩選出高頻出現的標簽,得到高頻標簽字典。算法描述如下所示。

由于數據集中存在很多個性信息不完善(缺少性別/地域/個性標簽)的對話,因此需要對數據集進行清洗,并且保證對話中的每個單詞都在單詞表中,以此來提升數據集的質量。算法描述如下所示:

對于檢索模型,SMP2019-ECDT提供的數據集對話噪音較多,在語意連貫、流暢性等方面有所欠缺,因此本文采用小黃雞語料庫作為檢索模型的數據集。該數據集只需調整數據格式即可使用。
3.3 檢索模塊
Elasticsearch是一個分布式、可擴展、實時的搜索與數據分析引擎。由于Elasticsearch是在Lucene基礎上構建而成的,所以在全文本搜索方面表現十分出色。Elasticsearch是一個近實時的搜索平臺,這意味著從文檔索引操作到文檔變為可搜索狀態之間的延時很短,相比一些傳統的檢索方法回復速度提升了10%以上。Elasticsearch提供了強大的索引能力,其使用的倒排索引相較于關系型數據庫的B-Tree索引更快。
通過文本匹配的相關度分數來判斷檢索對話的相關性。其相關度評分的計算規則涉及布爾模型(Boolean Model)、詞頻-逆文檔頻率(TF-IDF)和向量空間模型(Vector Space Model)。Elasticsearch使用布爾模型查找匹配文檔,并用一個名為實用評分函數(借鑒TF-IDF和向量空間模型)的公式來計算相關度,同時也加入了協調因子、字段長度歸一化、詞或查詢語句權重提升。
映射(Mapping)是定義文檔及其包含的字段如何存儲和索引的過程。每個文檔都是字段的集合,映射數據時,將會創建一個映射定義,其中包含與文檔相關的字段列表。
本文檢索的映射規則設置如下:


其中,type 表示每個字段的數據類型,常用的有keyword和text等,可根據檢索的目的設置。analyzer表示索引時用于文本分析的分析器,search_analyzer表示搜索時使用的分析器,本文分別設置為ik_max_word和ik_smart。IK分詞器是一款中文分詞器,ik_max_word算法是最細粒度切分算法,比如將“中華人民共和國人民大會堂”拆分為中華人民共和國、中華人民、中華、華人、人民共和國、人民、共和國、大會堂、大會、會堂等詞語。而ik_smart算法是最粗粒度切分算法,比如將“中華人民共和國人民大會堂”拆分為中華人民共和國、人民大會堂。對于中文內容,在索引時用ik_max_word,在搜索時用ik_smart可以使檢索的效果達到最佳。
3.4 生成模塊
生成模塊中使用PostKS模型,這是一個可以利用知識的先驗和后驗分布來促進知識選擇的神經模型。通過使用先驗分布有效地逼近后驗分布,該模型可以在推理過程中產生適當的回答。根據用戶輸入的個性化信息通過知識管理器來設定聊天機器人的個性,使得系統能夠生成具有特定個性的回復。

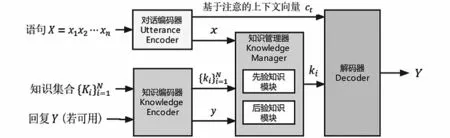
圖3 PostKS模型圖Fig.3 PostKS model diagram
(1)對話編碼器和知識編碼器


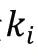
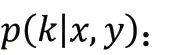
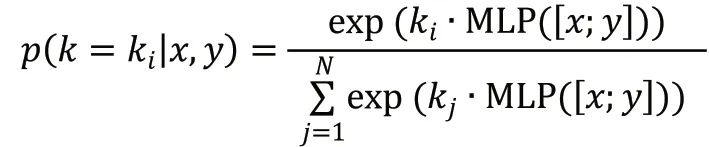
顯然,后驗分布在選擇知識時是優于先驗分布的,但在推理生成應答階段中,后驗分布是未知的,因此期望先驗分布能夠盡可能地接近后驗分布。為此,引入了KLDivLoss(Kullback-Leibler Divergence Loss)作為輔助損失函數,用來衡量先驗分布和后驗分布的接近性:
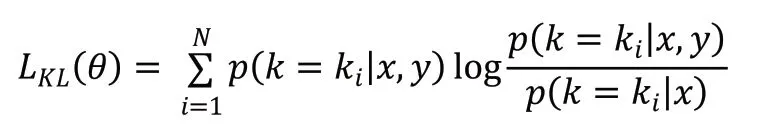
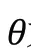
(3)解碼器
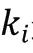

然后,融合單元將它們組合在一起,生成整體的隱藏狀態:

3.5 回復選擇模塊
檢索模型與生成模型各有利弊。檢索模型直接使用語料庫中的對話,選擇匹配度較高的對話進行回復,回復語句的質量較高,保證了對話的信息性,但無法回復語料庫中未出現的問題;生成模型將對話經過一系列處理從而產生相應的回答,且PostKS模型能夠根據特定的個性產生對應個性的回復,具有多樣性,但相較于檢索模型產生的回復可能會出現缺乏相關度或語義不通等問題。
為使聊天機器人系統既能保持檢索模型的信息性,也能保持生成模型的多樣性,且盡可能地克服兩種模型的缺點,因此設計了一種檢索-生成混合模型,結構如圖4所示。
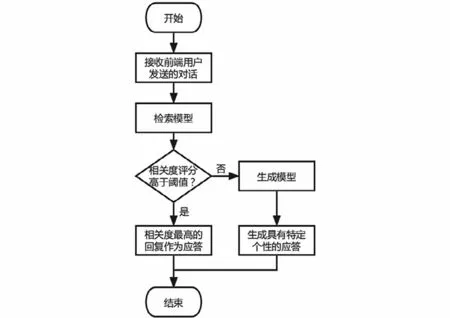
圖4 回復選擇模塊流程圖Fig.4 Reply selection module flowchart
當接收到用戶發送的對話時,先在檢索模塊通過Elasticsearch搜索引擎進行檢索并進行相關度評分,設定一個適當的閾值(本文設為5),若存在相關度評分高于閾值的對話,則將評分最高的回復發送給用戶,否則調用PostKS個性化生成模型,依據用戶設置的個性化信息,生成具有特定個性的回復發送給用戶。
由于用戶設置過聊天機器人的個性信息,當詢問聊天機器人的性別與地域相關問題時,為防止機器人的回復與先前用戶設置的信息不一致,機器人的回復不應通過檢索或生成模型來獲取,而是調用回復性別或地域的函數。
3.6 前端設計
前端使用Tkinter模塊,是Python標準Tk GUI庫。前端包括設置界面(可供用戶設置聊天機器人的個性信息,包括性別、地域和個性標簽)與聊天界面。
在設置界面(圖5)分別輸入性別、地域和個性標簽即可設置聊天機器人的個性,點擊“確定”后進入聊天界面(圖6),在輸入框中輸入語句,點擊“發送”即可生成應答并顯示在界面中,點擊“返回”將退回到設置界面,可重新設置聊天機器人的個性。
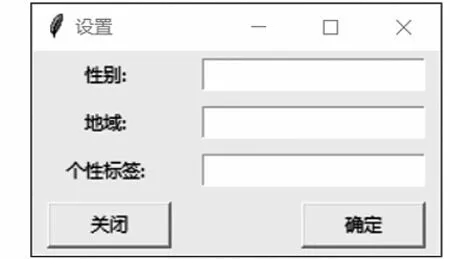
圖5 設置界面Fig.5 Interface for settings
圖6 聊天界面Fig.6 Interface for chatting
4 系統展示(System display)
系統運行結果如圖7和圖8所示。
圖7 設置界面展示Fig.7 Display of setting interface
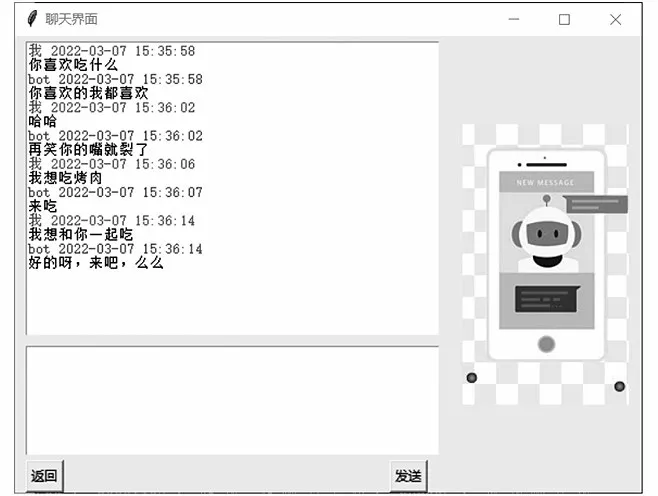
圖8 聊天界面展示Fig.8 Display of chatting interface
5 結論(Conclusion)
本文設計了一種可以實現個性化回復的聊天機器人系統。本系統基于PyTorch開發框架,后端各個模塊結構清晰簡潔,易于修改、擴展。使用檢索-生成混合模型,既保留了檢索模型的信息性,語句流暢、質量高,也保留了生成模型的多樣性,且可生成特定個性的應答。檢索模型使用Elasticsearch搜索引擎,檢索速度極快,大大縮減了整個系統生成應答的時間,通常情況下1 s內即可產生應答,對話具有實時性。生成模型使用PostKS模型,可以生成具有特定個性的應答。本系統可供用戶閑聊,同時也可以應用到多種不同的場景中。在面向特定的應用場景時,依據實際場景采取相應的個性,會使交流過程更為順暢和專業,這無疑具有一定的社會價值。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
少先隊活動(2021年4期)2021-07-23 01:46:22
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
當代陜西(2020年13期)2020-08-24 08:22:02
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2017年5期)2018-01-19 02:49:17
濰坊學院學報(2016年2期)2016-12-01 13:00:11
光學精密工程(2016年6期)2016-11-07 09:07:19
沈陽醫學院學報(2015年1期)2015-12-27 13:44:40
醫學教育管理(2015年3期)2015-12-01 06:43:16
