結合RoBERTa與多策略召回的醫學術語標準化①
2022-11-07 09:08:00韓振橋付立軍劉俊明郭宇捷唐珂軻
計算機系統應用 2022年10期
韓振橋,付立軍,劉俊明,郭宇捷,唐珂軻,,梁 銳
1(中國科學院 沈陽計算技術研究所,沈陽 110168)
2(中國科學院大學,北京 100049)
3(山東大學 大數據技術與認知智能實驗室,濟南 250100)
4(中康健康科技有限公司,廣州 510620)
1 引言
近年來,隨著國家對醫療健康的重視,人們對自身健康的關注度也越來越高,很多企業和研究單位都開始深入智能醫療與健康領域,其中包括騰訊、阿里、京東、百度以及各AI 醫療企業等,共同推動了智能診療、醫療問答、臨床輔助決策等技術的發展.在醫學場景中,已經可以直觀地感受到醫學文本數量明顯的增加,其中醫學文本包括醫學文獻、臨床檢測報告、電子病歷記錄、醫療保險記錄等,這些醫學文本中包含了大量的可以挖掘利用的信息,而這些數據中大多是非結構化或者半結構化,如何更好地對這些數據進行有效的分析和利用,是當前的研究熱點和難點.
術語標準化能夠幫助數據更合理的分析和利用并且提升下游任務的應用效果.本文主要研究中文醫療文本的術語標準化.醫學術語標準化是將非正式的醫學術語如“經皮髂骨成形術”,映射到正式的醫學概念,如概念“骨盆成形術”,然后再對應到相應的醫學編碼上.這項任務在醫學領域非常重要,在臨床上,關于一種疾病、藥品、癥狀等都有各種不同的寫法(包含非正式、非標準的形式還有誤寫等),如果都能夠歸一到對應的術語上來,它能夠推動AI 技術在醫學應用系統上的落地,如“CDSS (臨床決策診療系統)”“DRGs (診斷相關分組管理系統)”等[1].并且這項技術在輔助診療、公共衛生檢測、醫療檢索等方面有巨大的作用.
在廣大研究者的積極推動下,關于術語標準化的研究經過了如下的幾個階段: 基于規則和字符詞典匹配的方法[2,3]、基于機器學習的方法[4]、基于深度學習的方法[5,6].早期的基于規則的方法,由于人工消耗較大且只能在特定的語料上達到滿意的效果,所以在處理比較復雜的數據時往往達不到預期.后來隨著機器學習、深度學習的發展,人力構建規則的成本消耗得到很大的緩解,相應術語標準化的準確率也獲得了極大的提升.由于深度學習方法的非線性建模能力更強、能夠利用語義信息等優點,所以在術語標準化的任務上的效果也能達到更好.隨著預訓練模型BERT[7]的誕生,因為它是通過未標注維基百科數據訓練得到,包含了豐富的先驗知識和語義信息,所以在術語標準化任務上利用預訓練模型會比傳統的深度神經網絡如LSTM[8]有更優越的性能.
目前來說,在使用BERT 進行術語標準化任務時一般會采用的方法為直接排序和先召回再排序兩種方式.后一種方式能夠相對減少排序時間的開銷,本次研究也是基于先召回再排序的思想.
本文在此基礎上使用多策略召回排序的思路,如圖1.在第1 階段盡可能把正確的概念召回,第2 階段使用蘊含語義評分模型將術語原詞與候選概念進行語義相似度排序,篩選出得分最高的概念.同時,之前的中文醫療領域術語標準化研究都是以ICD9 或者ICD10(international classification of diseases,ICD)為標準,本文首次在SNOMED CT (the systematized nomenclature of human and veterinary medicine clinical terms)標準的數據上進行研究探索,驗證了本方法的有效性及使用SNOMED CT 探索術語標準化的可能.該實驗結果證明,本文提出的方法具有很強的實用性.

圖1 整體算法流程圖
2 相關工作
本文主要的研究是在以中文為核心的醫療領域的術語標準化,對于醫學文本中的不規范的表達也就是術語原詞,經過標準化之后映射到正確的概念編碼上來.每一個標準的概念都有一個概念編碼.有表1 不規范的表達,最后經過術語標準化算法,最終對應到正確的SNOMED CT 編碼.

表1 術語原詞-標準概念對應表
醫學術語標準化任務的目標是將醫學文本中抽取的非標準的醫學表達映射到正確的醫學概念編碼上,以便于直接或給下游醫學任務利用.迄今為止,已經積累了很多關于醫療領域的術語標準化研究工作.
早期的醫學術語標準化工作主要是采用規則和機器學習的方法.文獻[9] 引入了一種新的基于編輯距離的方法來進行疾病名稱標準化,在SemEval 2014 疾病名稱標準化比賽[10]中排名第二.文獻[11] 使用了5 種規則的NLP 技術提升生物醫學文本中的疾病名稱標準化水平,分別提升了MetaMap[12]和Peregrine 系統[13]的效果.文獻[14] 提出一種多層篩選系統,通過定義10 種不同優先級的規則來度量術語原詞和實體庫中概念的相似性.文獻[15]利用線性模型對候選術語與概念名稱之間的相似性進行評分,并且運用了從訓練集學習候選實體和概念名稱的相似性的策略.文獻[16]在文獻[15]的基礎上采用了基于低秩矩陣近似的降維技術,減少了參數量,同時提升了疾病名稱標準化在NCBI 疾病語料上的效果.
近些年來,隨著深度學習的蓬勃發展,來源于神經網絡的深度學習技術在術語標準化任務上的表現不斷突破,這種不依賴于規則和人工特征的方案逐漸成為主流.基于深度學習的術語標準化任務相關研究工作有: 文獻[17]使用了不同語料訓練的Word2Vec[18]語義向量表示,并且利用卷積神經網絡(CNN)和循環神經網絡(RNN)提取特征,大大超越了以TF-IDF、BM25、向量相似度為基線的術語標準化水平.文獻[19]在文獻[18]的基礎上增加了醫療健康相關的文本訓練獲得醫療專業的詞嵌入(word embedding),從而更好地表示醫學概念的語義特征,在數據集上獲得新的SOAT (state of the art).文獻[20]提出了一種疾病名稱和術式名稱結合的多任務醫學術語標準化框架,利用多視角CNN提取特征,并且對兩個任務引入權重共享層,利用疾病名稱和術式名稱之間的相關性更好地進行術語標準化.文獻[21]針對術語標準化任務構建了端到端的模型結構,運用結合attention[22]的雙向LSTM 和GRU 結構[23]提取候選實體特征,與UMLS 系統中的標準詞概念特征拼接,運用Softmax 函數進行評分,證明了比單純使用CNN 結構進行術語標準化有更好的效果.文獻[24]考慮到標注醫療數據需要豐富的專業知識和時間開銷,提出了一種利用共病網絡embedding 的疾病名稱標準化的無監督方法,接近了經典有監督學習的準確性.
但是以上方法都存在一個問題: 初始的詞嵌入并不能表示一詞多義,詞向量的特征包含不夠豐富,隨著預訓練模型的提出,在術語標準化任務上有了如下的研究.
文獻[25]采用基于字符級ELMo 向量[26]與傳統的Word2Vec 詞向量拼接共同表示最終的詞向量的,以獲得包含更豐富信息的詞向量.并利用BiLSTM 提取候選實體的特征,最終結果超越了以BIGRU-attention進行術語標準化的SOAT.文獻[27]將標準化任務視為一個分類問題,在3 個不同的數據集上進行實驗,對醫學概念標準化任務的模型進行細粒度的評估.通過BERT、ELMO、RNNs 模型進行語義表示,分別對比在術語標準化上的效果,得出BERT 在醫學概念標準化上有更好的效果、神經網絡的結構會影響術醫學概念標準化的準確性等結論.文獻[28]比較BERT/Bio-BERT/ClinicalBERT 在生物醫學實體標準化任務上的準確性,結論得出對預訓練模型進行微調可以顯著提升生物醫學實體標準化水平.文獻[29]提出了一種生成和排序的框架解決醫學術語標準化問題.第一階段使用Lucene 工具生成候選對象,之后使用BERT 進行候選實體打分.
基于規則的方法需要根據不同的場景設定不同的規則,費時費力同時可移植性不強.基于機器學習的方法雖然在一定程度上緩解了人工消耗,但由于缺乏語義信息的局限性且不能考慮上下文信息,它不能在更為復雜的醫學術語標準化任務上表現得很好.深度學習在文本建模上具有強大的表征能力,不僅可以更好地表示詞語和文本,還可以學習到詞語的上下文關系和重要詞語的信息[30].隨著預訓練語言模型的誕生,因為其在上下文中可以獲得更為豐富的語義特征,且使用基于預訓練語言模型的方法在很多自然語言處理任務上都達到了最好的水平,所以現在利用預訓練模型模塊實現醫學術語標準化任務也成為了主流.
本文的研究也是基于預訓練模型提高醫學術語標準化任務準確率.由于在醫學術語標準化第一階段的召回過程中單一的方法往往不能夠覆蓋大部分正確概念,為此本文提出了多策略召回的方案,極大提升了第1 階段正確概念的召回率.結合第2 階段使用RoBERTa-WWM-ext[31]進行蘊含語義排序,術語標準化最終的準確性得到有效提高.
3 模型介紹
3.1 問題定義
在基于SNOMED CT 標注的術語標準化數據集中,設標準概念數量為m,其中概念集為C={c1,c2,···,cm}.
術語原詞為t,經過第1 階段混合召回,將概念集縮小到G={g1,g2,···,gk},其中k<m,在第2 階段經過精細化排序,在候選概念G中選擇一個得分最佳的概念,作為最終術語標準化的結果.兩階段實現術語標準化,其核心在于要在召回階段能夠盡量地把正確概念召回,召回的概念作為候選實體,這決定了后續排序階段效果的上限.在排序階段,要能夠精細化排序得出最佳的概念.
3.2 構建兩階段術語標準化模型
本文提出的模型,總體分為兩部分,下面會對這兩部分分別介紹.
第1 部分是多策略召回階段,多策略召回分為3 個小模塊.通過計算術語原詞與術語庫中所有概念的Jaccard 相關系數,取Jaccard 相關系數最高的作為候選實體的一部分.同時也在所有的概念經過分詞之后訓練一個TF-IDF 模型,這樣就能獲得所有的分詞權重,之后把術語原詞作為一個query,計算query 與所有概念的相關性,取相關性最高的概念作為候選實體.同時結合歷史召回方法對候選實體進行召回.
第2 部分是蘊含語義排序模塊,使用了RoBERTawwm-ext 模型,計算術語原詞與候選實體的語義相似性蘊含分數,再進行蘊含分數排序,選取得分最高概念,圖2 展示了整體的模型架構圖.
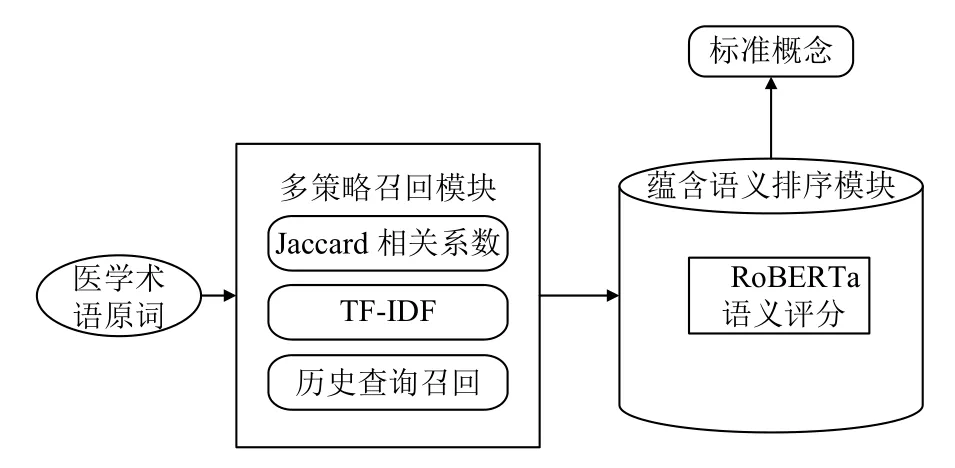
圖2 整體模型框架圖
3.2.1 候選概念多策略召回模塊
這個召回模塊主要由3 個小部分組成: 歷史召回、TF-IDF 相關性召回、Jaccard 相關系數召回模塊,下面會介紹各小部分的召回原理,圖3 展示了多策略召回的具體流程.

圖3 候選概念多策略召回
TF-IDF 召回原理: TF-IDF 是一種高效的計算特征權重的算法,其可以用來解決短文本的相似度的問題.本文將它用來作為術語原詞和概念庫中的概念相關性比較的算法,通過此算法將術語原詞匹配到部分最相關的概念.
首先要計算概念庫中特征詞的權重,將概念庫中的每個概念進行分詞,對于概念庫中概念中的特征詞其特征權重的計算公式如式(1):
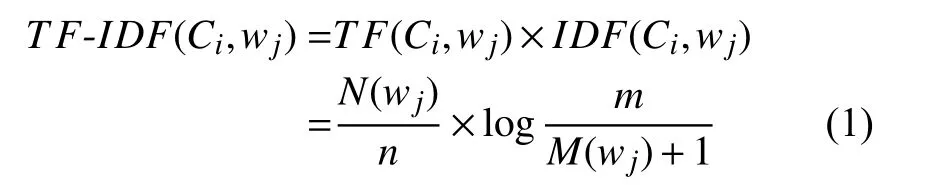
其中,N(wj)是wj在Ci中出現的次數;m是概念庫中的概念總數;M(wj)是概念庫集和中含有wi的概念數.
接下來計算術語原詞與概念庫中每個概念的相關性得分,對術語原詞s進行分詞產生詞語列表[v],Ci產生的分詞列表[w],計算s和Ci的相關性得分如式(2):
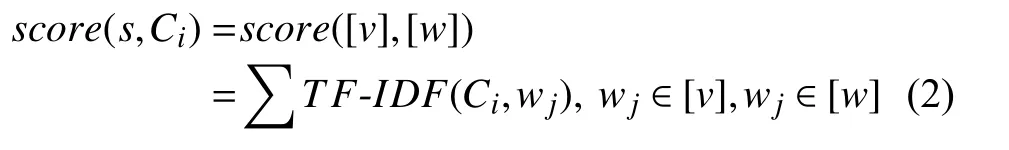
Jaccard 相關系數召回原理: Jaccard 相關系數主要計算符號度量的個體之間的相似程度.對于術語原詞s1和概念s2,要計算他們的Jaccard 相關系數,可以先將s1、s2分別分為字符集合A和字符集合B.他們的Jaccard相關系數計算如式(3):
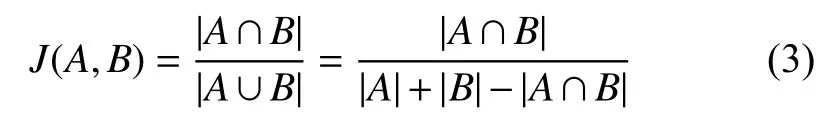
歷史召回原理: 歷史召回的算法也是采用的TF-IDF,它是對訓練數據中的術語原詞進行召回而不是直接對概念庫中的標準詞進行召回,其優勢在于能更加充分的利用訓練集中的信息.它直接對訓練集中所有的術語原詞進行計算獲得特征分詞的權重,之后計算待標準化術語與訓練集中術語原詞的相關性,最后取相關性最高的top-k個術語原詞對應的標準概念作為候選概念集.圖4 展示了歷史召回的算法原理.
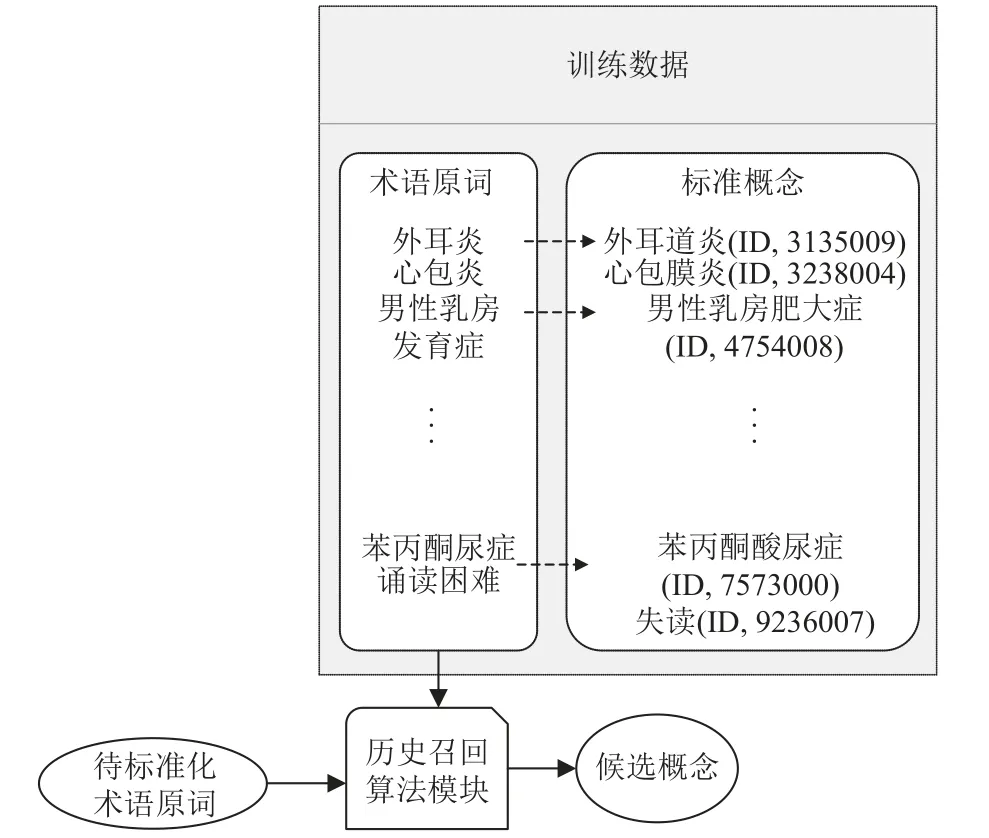
圖4 歷史召回算法流程圖
訓練集中數據是以“術語原詞-概念”的形式出現,所以找到最匹配的術語原詞,也就間接地找到了需要的概念,這種方法能夠在召回階段更充分利用數據.
3.2.2 蘊含語義排序模塊
候選實體排序階段,要對第1 階段召回的所有概念進行打分排序,這樣才能選擇與術語原詞最對應的概念作為答案.候選實體排序模塊由RoBERTa-wwmext 蘊含語義相似性評分模塊構成.
RoBERTa-wwm-ext 作為蘊含分數計算模型,主要是通過訓練一個二分類模型,之后預測原詞和術語庫中的概念之間的蘊含分數(其中把預測為1 的概率作為蘊含分數),對術語庫中的每個概念進行評分.RoBERTawwm-ext 是在BERT 的基礎上進行的改進,以下主要介紹二者的區別.
BERT 采用預訓練-微調的模式,問世以來在解決實體識別、文本分類、自然語言推斷等多個自然語言處理獲得了SOTA,給學術界提供了很多的參考.
BERT 的全稱是(bidirectional encoder representation from Transformers),本文中作為語義排序的基礎模型.在BERT 之前預訓練語言模型有ELMo (embedding from language model)和GPT (generative pre-training),但是這兩種方法都只采用了一個預訓練目標,而且沒有充分的利用上下文信息.BERT 采用Transformer 的encoder 作為基本組成,能夠充分結合上下文本信息進行有效的訓練.與早期提出的訓練語言模型的目標“預測下一個詞”不同的地方在于BERT在單詞級別和句子級別設置了兩個目標: 掩碼語言模型(masked language model,MLM)與預測下一句(next sentence predict,NSP)模型.其中MLM 可以理解為完型填空做法的思路,模型隨機會mask 每個句子中15%的詞,利用上下文信息來預測這些詞.MLM 具體做法是80%的詞用[mask] 替換原來的詞,10% 的詞隨機取一個詞替代mask 的詞,10%詞保持不變.預測下一句訓練過程的具體做法是選取一些句對與,其中50%的數據是的下一句,剩余50%是從語料庫中隨機選擇,通過對句對進行二分類訓練來學習句子間的關系.通過這兩個目標訓練出的BERT 模型,具有很強的字詞級別的表征能力.
RoBERTa-wwm-ext 與BERT 模型的基本結構基本相同,改進更多的是從訓練集和訓練策略角度來提升,主要有以下幾點: 首先相對于BERT 的靜態掩碼機制采取了動態掩碼機制,在BERT 中訓練數據時,一條樣本只進行一次隨機 mask,在訓練時 mask 的位置都保持不變,動態mask 在每次訓練前會動態生成一次mask,這種方法提高了模型輸入的隨機性,使模型可以學習更多的句式.另外它使用了更大的batch size 進行訓練,被實驗驗證有更好的效果.同時采用字節對編碼(BPE)進行文本數據處理,使用了更多的數據同時進行訓練,且取消了NSP 任務,提升了效率.且采用了WWM(全詞掩碼)策略,相較于BERT 的單字掩碼,先進行分詞,如果有詞中的部分字符被mask,那么整個詞都將會被mask,這樣做RoBERTa-wwm-ext 能夠更好地學習詞級別的信息[31-33].
本文使用RoBERTa-wwm-ext 模型將語義間相關性判別轉化為一個二分類模型,圖5 展示了RoBERTawwm-ext 模型結構作為語義蘊含評分模塊.
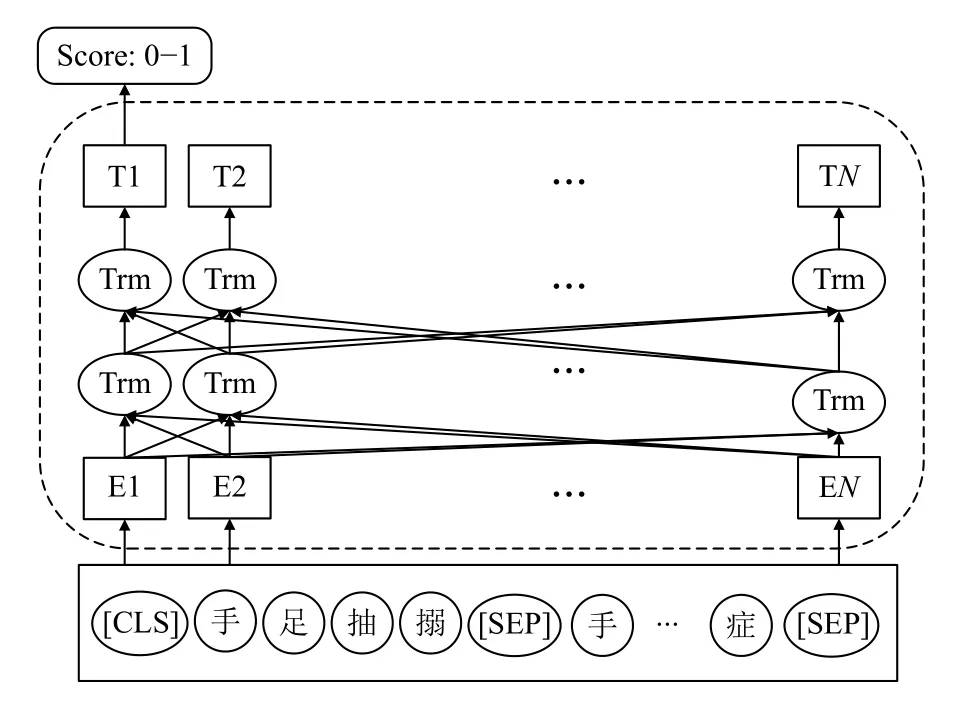
圖5 RoBERTa-wwm-ext 語義蘊含評分模型結構
分別按照相應的策略構造<術語原詞,概念,1>和<術語原詞,非正確概念,0>的正負樣本,用此數據來訓練蘊含語義評分模型.將樣本輸入到模型中具體格式為“[CLS] 手足抽搦[SEP] 手足抽搐癥[SEP]”,經過RoBERTa-wwm-ext 編碼獲得[CLS]的隱藏層狀態表示,接著輸入到全連接層,經過Softmax 函數打分,其中[CLS]和[SEP]分別表示用于分類的令牌、分隔術語原詞和候選概念的令牌.
蘊含語義評分模型使用Softmax 作為分類回歸函數,模型采用交叉熵損失函數進行優化,使用類別為1 的概率作為語義蘊含分數.其中蘊含分數及最后預測對應概念的計算過程如式(4)-式(5):

其中,FFNN表示前饋神經網絡層,l為類別標簽,y表示最終對應的概念.
本文需要比較的是術語原詞和概念庫當中概念的語義相似性,雖然使用的是二分類的方法,但是需要二分類模型評出概念相似程度的高低,涉及到排序,所以其精度要求更高,難度上比傳統二分類任務的0.5 作為閾值更難.所以對構造二分類模型的訓練樣本一定要經過特殊處理,這樣模型才能夠更好地學習到語義的相關性.

方法1.構造語義模型數據集方法1)構建空的數據列表datas=[],將其作為語義模型訓練需要的數據;2)設置困難負樣本數量k,隨機負樣本數量m,正樣本數量n;

3)訓練集術語原詞使用Jaccard 相關系數召回概念庫中得分最高的前k 個負樣本,將k 個樣本處理為<org,neg,0>并入datas;4)訓練集術語原詞從概念庫<org,neg,0>并入datas中隨機抽取m 個負樣本,將m 個樣本處理為;5)訓練集術語原詞重復n 條作為正樣本,將n 個樣本處理為<org,neg,1>并入datas;6)對datas 進行隨機打亂;
4 實驗過程與結果評估
4.1 實驗數據
SNOMED CT 是目前國際上認可的且比較全面的醫學術語集,其內容包括了臨床所需的基本信息.SNOMED CT 的概念表收錄了大量具有唯一含義并經過邏輯定義的概念,分類編入18 個頂級概念軸(hierarchy)中,分別包括臨床發現、操作/介入、身體結構等[34].
本次實驗的數據是以SNOMED CT 為標準,醫療相關人員進行標注,獲得“術語原詞-概念”標注數據9 000 余條,此次標注中選取SNOMED 術語庫中在醫學文本中常見的概念15 001 個SNOMED CT 概念作為概念標準,這些數據均來自現實的醫學場景.按照比例6:2:2 劃分為訓練集、開發集、測試集,數據集中的真實數據如表2.

表2 數據集中的數據形式
數據集中最長的術語原詞為“庫興氏綜合征(由于各種原因引起的腎上腺糖皮質激素慢性分泌過多,表現為肥胖伴有高血壓等一系列癥狀)”,最短的術語原詞為“腿”.
4.2 評價指標
4.2.1 總項評價指標
對于分類任務,總體的評價指標有如下幾個標準:準確率、精確率、召回率、F1 值,其計算方式如式(6)-式(9):


式(6)中,TS代表被預測正確概念的樣本數,N代表樣本總量,本文最終目標使用accuracy作為評價指標.
4.2.2 分項評價指標
本文是術語標準化任務作為候選概念召回和候選概念排序兩階段任務來實現的,所以在這兩個分項中也有不同的指標來衡量他們的效果.候選概念召回階段使用召回率(recall)作為評價指標.其中recall的計算公式如式(10):
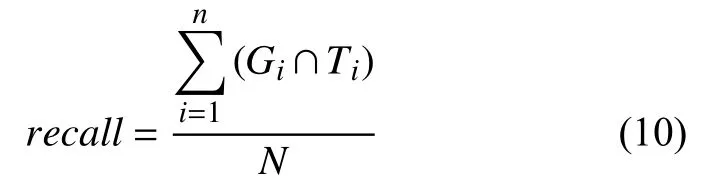
其中,Gi代表第數據集中第i個術語原詞召回來的候選概念集,Ti表示第i個術語原詞的正確答案,N為術語原詞總數.
4.3 實驗過程及分析
4.3.1 參數設置
本文中使用了RoBERTa-wwm-ext 作為蘊含語義評分模型,使用了Adam 作為優化器,實驗采用內存大小為11 GB,一張2080ti GPU 顯卡.Dropout rate 設置為0.1,學習率為2E-5,batch_size 為64,隱藏層維度為768,最大的句子長度為64.
4.3.2 結果分析
在第一階段召回主要做實驗對比單召回方式,以及本文中多策略召回的效果,表3 展示了不同方法的候選概念召回率.
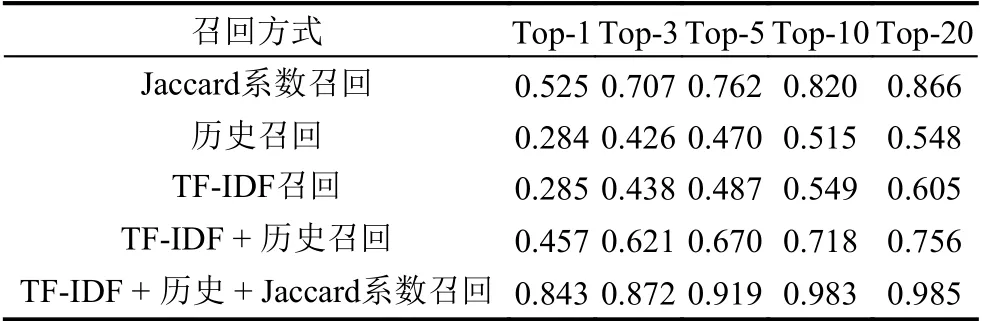
表3 候選概念召回率
表3 的結果來看,本文提出的召回策略具有明顯優勢.單一方法的召回都不能夠完全覆蓋正確的概念.結合多策略召回,其中每個召回方式都取前10 最高得分能夠達到0.983 的召回率,基本能夠覆蓋正確答案,所以將它作為蘊含語義排序模型的輸入部分.在候選概念蘊含語義排序階段,為了獲得更強的語義排序模型,本文采用了不同的策略構建負樣本.在訓練語料中引入了困難負樣本,再結合不同的訓練樣本比例,得到當前效果最佳的蘊含語義模型訓練方案.不同構造樣本的策略效果如表4.

表4 樣本構建對結果影響
表4 中,P代表訓練集中的正樣本重復次數,Nrandom數代表隨機負樣本數量,Nhard表代表困難負樣本數量.為了維持訓練集正負樣本的比例,所以始終將訓練正負樣本維持在1:1 與1:2.從蘊含語義排序的結果來看,在一定范圍內引入困難負樣本會顯著的提升蘊含語義排序模型的效果并且增加正、負樣本的數量也可以提升模型的效果.為了比較不同的語義模型蘊含排序效果的差別,本文分別在同結構的網絡模型進行了對比實驗.在召回策略相同、正負樣本構造分別是(P,Nrandom,Nhard)=(20,20,20)的條件下,各語義蘊含模型的效果如表5.
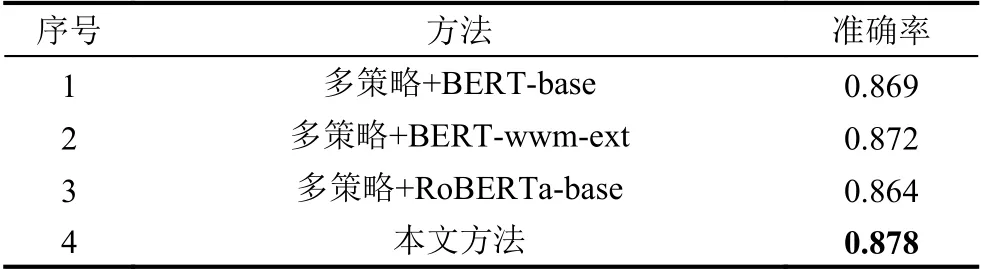
表5 部分同類型模型蘊含語義排序效果對比
從結果來看,在使用相同的召回策略且蘊含語義模型的正負樣本構建策略均相同的情況下,使用RoBERTa-wwm-ext 作為蘊含語義排序模型展現了它有更強的蘊含語義表征能力,并且效果比同類其他模型的效果更好.這是由于其模型的訓練方式和豐富的訓練語料帶來的優勢,實驗結果也展現了本方法在以SNOMED CT 為標準的醫學術語標準化上的可行性及優越性.
5 結論與展望
本文在解決醫學術語標準化的問題上,提出了一種結合RoBERTa 與多策略召回的方法,該模型使用RoBERTa-wwm-ext 作為蘊含語義排序模型.首次在醫療標準SNOMED CT 標注的數據上進行實驗驗證,證明了本方法的有效性,為其他從事SNOMED CT 標準進行的術語標準化工作者提供了參考.本文將醫學術語標準化分為兩個階段來執行,第1 階段是多策略召回,第2 階段是蘊含語義排序.在多策略召回階段,由于醫學術語的表達多樣化與口語化的特點,往往通過一種召回方法召回候選概念效果欠佳,而本文提出的多策略的召回方法可以召回98.3%的正確候選概念.在蘊含語義排序階段,為了構建強大語義模型,本文引入了困難負樣本進行訓練,并且構造不同數量的正負樣本比例確定蘊含語義模型的訓練方式,最終蘊含語義排序模型的效果得到極大提升.通過對比本文模型和其他同類型模型的基于SNOMED CT 醫學術語標準化效果,本文提出的模型有更高的準確性,準確率達87.8%.
由于醫療領域的術語一字之差可能完全表達的是兩個不同的概念、術語原詞與概念之間沒有交集等情況.在以后的工作中希望能夠引入外部信息,或者根據醫療數據特點引入特征詞典來提高醫學術語標準化的水平,同時也希望對一個術語對應多個概念或者多個術語對應多個概念的方向去展開研究.
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
口腔護理用品工業(2021年4期)2021-11-02 08:22:56
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
開放教育研究(2020年2期)2020-03-31 01:54:14
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
中國公路(2017年9期)2017-07-25 13:26:38
現代語文(2016年21期)2016-05-25 13:13:44
汽車維修與保養(2015年8期)2015-04-17 03:32:51
大連民族大學學報(2015年2期)2015-02-27 08:28:11
