手語識別與翻譯綜述
2022-11-15 16:17:12閆思伊薛萬利袁甜甜
計算機與生活 2022年11期
閆思伊,薛萬利+,袁甜甜
1.天津理工大學 計算機科學與工程學院,天津300384
2.天津理工大學 聾人工學院,天津300384
根據全國第二次殘疾人抽樣調查,目前我國聽障人數接近3 000 萬,是國內最大數量的殘障群體,手語是聽障人士交流表達的主要手段。無障礙溝通是廣大聽障人群打破信息孤島、進行平等社會交流的重要途徑[1]。實現聽障人士無障礙溝通的主要需求是健聽人士能夠知曉聽障人的手語表達。隨著人工智能技術的發展特別是計算機視覺研究與自然語言處理研究的進步,使得這一需求的實現成為可能。手語識別與翻譯研究正是為實現上述需求的具體研究任務。如圖1所示,手語識別是指將手語視頻中所做手語動作對應的文字注釋(Gloss)順序地識別出來,而手語翻譯是指將對應的手語視頻直接翻譯為健聽人交流時所用的自然口語語句。
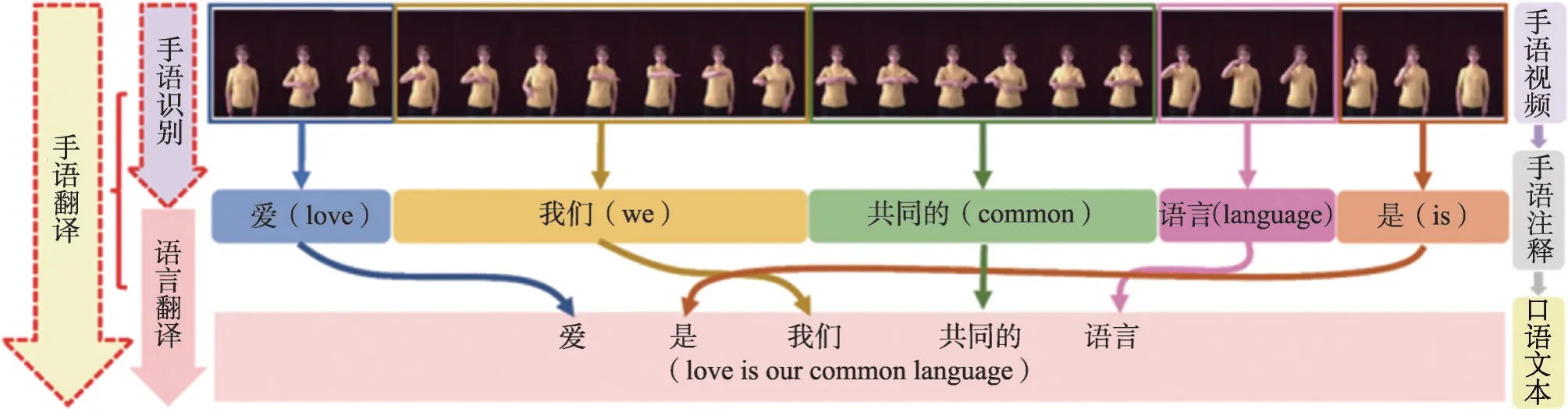
圖1 手語識別和翻譯流程Fig.1 Pipeline of sign language recognition and translation
手語識別和翻譯研究主要包括視覺感知和語言理解兩部分:基于計算機視覺技術感知手語視頻圖像對應深層特征;基于自然語言處理理解手語視頻對應文本信息。這種基于感知和理解的研究思路,更接近人的思考過程。
當前,對于手語識別與翻譯的研究主要集中在手語識別任務。手語識別的目標是將手語視頻自動翻譯成相應的手語注釋。根據所使用的數據集不同,手語識別可以細分為孤立詞手語識別和連續手語詞識別[2]。
孤立詞手語識別是一種細粒度的動作識別,每個視頻只對應一個手語的注釋[3-8]。孤立詞手語識別的主流方案是將整個句子分割成若干手勢片段,再進行單獨識別[9]。孤立詞手語識別主要關注對注釋場景的分割,方法上更類似于動作識別研究。為了避免像孤立詞手語識別一樣,需要大量人力對手語視頻中的手語手勢進行分割,因此,引入連續手語識別研究。
連續手語識別是指將一個手語視頻,在弱監督的情況下(只進行句子級別的標注而非幀級標注),映射為一個注釋序列(gloss sequence),且該注釋序列中Gloss順序與視頻中對應的手勢片段的順序一致,即符合手語語法的文本序列。相較于孤立詞手語識別,連續手語識別不再需要對手語視頻中的手勢片段進行繁重的人為分割。
基于自然語言發展而來的手語,其目的是快速便捷地利用肢體動作、面部表情等進行交流,因而形成一套獨特的語法規則。通常,一段手語視頻對應聽障人士表達的文本序列會和對應的聽障人士理解的自然語言序列存在差異性。為了便于健聽人群對手語的理解,需要對手語視頻進行翻譯研究以得到對應的呈現口語化的自然語言文本序列,這一過程就是手語翻譯研究。手語翻譯研究的目標是從連續手語視頻中提取對應的符合自然語言語法規則的文本表達。因此,手語翻譯研究任務需要結合計算機視覺感知和自然語言處理理解。根據不同研究范式,手語翻譯框架可分為:手語視頻到文本(sign2-text,S2T)和手語視頻到注釋到文本(sign2gloss2text,S2G2T)。S2T是將連續的手語視頻直接翻譯成口語句子,而S2G2T 利用連續手語識別模型從手語視頻中提取注釋序列,然后通過一個預訓練的Gloss2Text網絡來解決手語序列(sign sequence)到自然語言文本的翻譯[10]。
當前,在手語識別與翻譯方面的綜述,國外具有代表性的工作,如2020年Koller[11]對使用德國手語數據集的相關研究工作進行綜述報告,該綜述涵蓋從1983 年至2020 年約300 項工作,并對其中約25 項研究進行了深入分析。但報告僅對RWTH-PHOENIXWEATHER-2014[12]數據集上的研究工作進行總結,缺乏基于其他數據集的研究工作介紹。國內相關手語識別與研究方面的綜述則更多關注手語識別方面[13-15]。為了便于研究者對手語識別與翻譯、主流手語數據集及評測指標等方面進行快速全面的了解,本文對當前主流手語識別和翻譯研究進行了詳細的概括和總結。
1 手語識別和翻譯研究工作總結
本章將分別從手語識別研究和手語翻譯研究兩方面進行相關工作總結。其中,手語識別研究將進一步細分為孤立詞手語識別和連續手語識別;手語翻譯研究將從手語視頻到文本和手語視頻到注釋到文本兩個分支進行簡單介紹。
1.1 手語識別研究任務
手語識別框架通常包括視覺特征提取、識別模型兩部分。前者用于手語視頻的高維特征描述,后者則通過對齊約束提升模型的泛化能力。下面將分別從孤立詞手語識別和連續手語識別兩方面對當前主流研究方法進行總結。
1.1.1 孤立詞手語識別
(1)基于非深度學習的視覺特征的孤立詞手語識別
視覺特征提取是手語識別研究的關鍵。早期的孤立詞手語識別研究,在視覺特征提取時以非深度學習的手工特征為主。例如,以手部形狀特征作為視覺特征[16]。基于手形的方法可以反映相對簡單的手勢的含義,但無法應對復雜連貫手語視頻下的手語識別任務。
為了解決具有連貫動作的孤立詞手語識別,一些研究諸如,尺度不變特征轉換(scale-invariant feature transform,SIFT)[17]、方向梯度直方圖(histogram of oriented gradient,HOG)[18]、時空關鍵點(spatial temporal interesting points,STIPs)[19]和內核描述符[20]等二維特征描述子進行視覺特征提取。但特征僅在目標單一且清晰的情況下才能表現出良好的識別性能。為了解決手語視頻中的手勢遮擋挑戰,研究者們提出了3D/4D 時間空間特征[21]和隨機占用模式特征[22]。進一步,為了解決深度圖中存在的噪聲和遮擋問題,Miranda等人[23]使用時空占用模式[24]來表征人類手勢的四維時空模式,以充分利用空間和時間的背景信息,同時允許類內多樣性。Zhang等人[25]提出了一種基于隱馬爾可夫模型軌跡建模的孤立詞手語識別方法,重點設計了一種新的基于形狀上下文的曲線特征描述符。
為了提升孤立詞手語識別的魯棒性,Yin 等人[26]設置了包含一組手語引用和相應的距離度量的魯棒性模型。Zheng 等人[27]提出一種基于三維運動圖的面向梯度金字塔直方圖的描述子來識別人體手勢的深度圖,該描述子能夠在不同空間網格大小下刻畫局部信息。
在基于非深度學習的特征的孤立詞手語識別研究中,在識別方案部分,通常采用的方法有模板匹配、字典學習、視覺詞袋[28-29]、條件隨機場[30]、隨機森林[31]、支持向量機[32]和隱馬爾可夫模型[33]等。支持向量機[34]由于具備較好的預測泛化能力而受到研究者的關注[35]。Pu 等人[36]將兩種模態的手語視覺特征融合并輸入到支持向量機分類器中進行訓練。Kumar[37]通過離散小波變換提取手工特征經過處理后采用支持向量機進行分類。隱馬爾可夫模型其變體在手語識別研究中同樣得到廣泛的應用。例如,Guo等人[38]利用隱馬爾可夫模型狀態自適應方法,建立每個手語詞的學習模型。
(2)基于深度學習的視覺特征的孤立詞手語識別
由于非深度學習的特征不能很好地適應手語復雜動態的手勢及其他關鍵身體部位的變化,一些研究者采用深度學習的視覺特征進行孤立詞手語識別中的視覺特征建模。考慮到長短時記憶網絡能夠很好地對時間序列的上下文信息進行建模,Liu 等人[39]提出了一種端到端的長短時記憶網絡孤立詞手語識別方案。Hu 等人[40]利用深度殘差網絡(deep residual network,ResNet)提取視覺特征信息,并進行全局與局部增強。Huang等人[2]提出一種基于注意力模型的三維卷積神經網絡用于刻畫手語視頻的時空特征。Wang等人[41]融合二維和一維深度學習模型提取視頻幀中的時空特征。Hu等人[42]在手部深度學習的特征模型中引入手部先驗信息,提供從語義特征到緊湊手部姿態表示的映射。特別的,Wu 等人[43]提出一種通用的半監督分層動態框架用于手勢分割和識別,將骨架特征和深度圖像作為輸入,利用學習后的隱馬爾可夫模型進行推斷。
1.1.2 連續手語識別
與孤立詞手語識別相比,連續手語識別由于更復雜的手勢動作、更長的視頻序列表達而更具挑戰性。早期的連續手語識別方法,主要基于孤立詞手語識別展開研究[44]。例如,部分研究利用視頻分割算法,將連續視頻序列分割成若干視頻片段,然后采用孤立詞手語識別方法進行識別并整合[45]。
(1)基于卷積神經網絡的連續手語識別
受益于深度神經網絡在視頻表示學習中的發展,基于深度學習的視覺特征的連續手語識別逐漸成為主流[46]。Wei等人[46]提出了一種基于循環卷積神經網絡框架的多尺度感知策略,用于學習手語視頻的高維特征表示。針對連續手語識別研究中的弱監督問題,Koller等人[47]通過在迭代算法中嵌入卷積神經網絡,利用其更好的描述能力輔助細化幀級標注進而提升模型訓練精度。文獻[48]則將卷積神經網絡嵌入到隱馬爾可夫模型框架中。Li 等人[49]使用一個去除最后的全連通層的ResNet-152 網絡來提取任意長度視頻的高維視覺特征。Cheng 等人[50]提出了一種用于在線手語識別的全卷積網絡用于學習視頻序列的時空特征。隨著三維卷積神經網絡在動作識別任務中的廣泛應用[51-54],Zhao等人[55]提出了一種結合光流處理的三維卷積神經網絡方法來提升識別精度。Liao等人[56]基于B3D-ResNet執行長期時空特征提取的任務。Yang等人[57]提出了一種結構化特征網絡(structured feature network,SF-Net),通過長短時記憶網絡與三維卷積神經網絡在幀級的組合創建一個有效的時間建模架構。為了更好地對齊視頻片段和文本注釋,Pu等人[58]引入軟動態時間翹曲(soft dynamic time warpping,soft-DTW)算法,提出了一種新的基于3D-ResNet 和編碼-解碼器的網絡結構,在soft-DTW的作用下,3D-ResNet特征提取器和編碼器-解碼器序列建模網絡逐步交替優化。
(2)基于循環卷積神經網絡的連續手語識別
循環卷積神經網絡被廣泛應用于處理序列建模問題,如長短期記憶網絡(long short-term memory,LSTM)[59]、雙向長短期記憶網絡(bi-directional long short-term memory,Bi-LSTM)[60]、門控循環單元網絡[61]等。在連續手語識別中,通常結合循環卷積神經網絡與隱馬爾可夫模型,由于隱馬爾可夫模型需要計算先驗估計,文獻[62-64]嘗試用連接主義時態分類(connectionist temporal classification,CTC)方法[64-65]把路徑選擇的問題歸納為最大后驗估計問題,通過引入空白類和映射法則模擬了動態規劃的過程,從而緩解輸入序列和輸出序列的對應難的問題。Wang等人[66]提出了一種由時域卷積模塊、雙向門控循環單元模塊和融合層模塊組成的混合深度學習結構進行特征的連接融合。Xiao 等人[67]將長短期記憶網絡與注意力網絡融合進行連續手語識別。
(3)基于Transformer的連續手語識別
Transformer[68]作為一種領先的深層級網絡特征提取模型被廣泛應用于自然語言處理、計算機視覺和語音處理等領域。在連續手語識別研究中,Tunga等人[69]利用圖卷積網絡對手語演示者身體部位的關鍵點之間的空間關系進行編碼,進而挖掘幀間的時間依賴關系。Niu等人[70]使用二維卷積神經網絡提取視頻序列的空間特征,用Transformer 編碼器來提取時序特征。Varol 等人[71]利用預訓練的I3D 模型通過滑動窗口提取時空視覺特征。然后訓練一個2 層Transformer模型進行手語識別。Zhang等人[72]將Transformer與強化學習相結合進行連續手語識別。Yin等人[73]提出了一種基于編碼器-解碼器架構的輕量級手語翻譯模型SF-Transformer用來識別手語。
(4)基于多線索協同的連續手語識別
手語在傳遞信息、表達思想時,通常以手勢動作配合臉部表情及身體姿勢進行綜合表達。因此,可以簡單地認為,在手語識別研究中,其所表達的含義可以由多種線索共同作用[74]。Zhou 等人[74]結合基于視頻的手語理解與多線索學習,提出一種時空多線索網絡來解決基于視覺的序列學習問題,其中空間多線索通過姿態估計分支學習不同線索的空間表示,時間多線索則分別從線索內及線索外兩個角度對時間相關性進行建模獲得線索間的協作關系。
在手語識別研究中,一般將不同的信息來源定義為不同模態,例如圖像特征、文本特征和利用圖卷積網絡(graph convolutional networks,GCN)提取的骨架特征就是不同種模態。從多模態中學習各個模態的信息,并且實現各個模態的信息的交流和轉換。Papastratis等人[75]提出利用文本信息來改進視覺特征進行連續手語的跨模態學習,模型最初使用兩個強大的編碼網絡來生成視頻和文本的特征,再將它們映射和對齊到聯合潛在特征中,最后使用聯合訓練的解碼器對處理后的視頻特征進行分類。Gao等人[76]設計了一種視頻序列特征和語言特征多模態融合的手語識別系統。Huang等人[5]基于雙流結構從視頻中提取時空特征,其中高層流用于提取全局的信息,低層流更關注局部的手勢。
1.2 手語翻譯研究任務
手語作為一門特殊的語言體系,擁有一套區別于其他語言的語法規則。為了讓健聽人士能夠高效、準確地理解聽障人士演示的手語,則需要利用手語翻譯研究將手語視頻翻譯成口語化的句子。
1.2.1 手語視頻到文本的手語翻譯
手語翻譯的目的是從執行連續手語的人的視頻中提取等效的口語句子。因此,一種研究方案是直接將手語視頻翻譯成文本,即S2T[77]。Camgoz等人[77]提出Sign2Text模型,使用基于注意力的編碼器-解碼器模型來學習如何從空間表征或手語注釋中進行翻譯。Guo 等人[78]建立了一種面向手語翻譯的高級視覺語義嵌入模型。Li 等人[79]提出一種考慮多粒度的時間標識視頻片段表示方法,減輕了對精確視頻分割的需求。雖然Sign2Text 結構簡化了手語翻譯模型,但容易出現模型的長期依賴問題。且受制于當前技術及數據的制約,當前手語視頻到文本的翻譯在沒有任何明確的中間監督的情況下很難獲得較好的效果。考慮到手語注釋的數量遠低于其所代表的視頻幀的數量,另一些研究者開始引入手語注釋作為中間標記,設計了手語到注釋到文本的手語翻譯(S2G2T)。
1.2.2 手語視頻到注釋到文本的手語翻譯
在基于手語視頻到注釋到文本的手語翻譯范式中,手語翻譯過程被分為兩個階段[80]:第一階段將手語識別視為一個中間標記化組件,該組件從視頻中提取手語注釋;第二階段是語言翻譯任務,將手語注釋映射為口語文本。
在Sign2Gloss2Text 的手語翻譯研究中,典型的工作包括:受手語翻譯數據集規模限制,Chen等人[80]將手語翻譯過程分解為視覺任務和語言任務,提出一種視覺-語言映射器來連接兩者,這種解耦使得視覺網絡和語言網絡在聯合訓練前能進行獨立的預訓練。Camgoz 等人[81]通過在手語翻譯中利用Transformer 融合手工和非手工特征進行手語翻譯。Fang等人[82]將手語翻譯模型嵌入可穿戴設備。Yin等人[83]基于文獻[74]將預訓練的詞表達嵌入至解碼器用于手語翻譯。Zhou等人[84]使用文本到注釋翻譯模型將大量的口語文本整合到手語翻譯訓練中。Camgoz等人[10]將手語識別和口語翻譯的任務整合成一個統一的網絡結構進行聯合優化。為了實現實時手語翻譯,Yin等人[85]基于Transformer設計了一個端到端的手語同步翻譯模型,并且提出一種新的重編碼方法來增強編碼器的特征表達能力。
基于手語視頻到注釋到文本的手語翻譯是目前使用較多的手語翻譯范式。但是,一方面手語注釋是語言模態的離散表示,若注釋遺漏、誤譯部分信息,很大程度上會影響翻譯結果;另一方面,如何確保兩個階段在翻譯過程中的高效配合也是手語翻譯的難點之一。
2 數據集與評價指標介紹
2.1 數據集介紹
2.1.1 數據采集方式簡介
早期手語數據采集主要使用手部建模設備,如數據手套等,來進行數據收集。利用手語演示者的手型、手部運動的軌跡和手部的三維空間位置信息來描述手勢變化的過程。Gao 等人[86]利用數據手套將采集到的手勢數據輸入到特征提取模塊,模塊輸出的特征向量輸入到快速匹配模塊生成候選單詞列表。
然而,手部建模設備不僅價格昂貴并且不易攜帶,因此一些研究人員開始簡化或消除設備上復雜傳感器,并在不同的設備部位使用不同的顏色標記進行數據采集。如Iwai 等人[87]利用顏色手套獲取手部實時位置和形狀。但是,使用顏色手套進行數據采集時對手語演示者的著裝、環境等要求較高,否則容易引起數據偏差。
為了更好地方便手語者演示手語,一些研究者通過采用非接觸式傳感設備來獲取手部的運動軌跡信息。如文獻[88]使用RealSense技術將手掌方向和手指關節的數據作為識別模型的輸入。但是,手語是一種結合手勢變換、臉部表情、身體姿態等多因素綜合作用的語言體系,僅只關注手部信息是不夠的。因此,研究者們開始轉向基于視覺特征的手語識別與翻譯研究。
在采用視覺特征的手語識別與翻譯研究方法中,由攝像機得到手語演示者的彩色圖像并做相應的圖像處理,將其用作手語識別模擬的輸入數據。不僅如此,一些其他模態的手語信息也受到關注[89],例如體感攝像機,以便同時獲取視覺圖像信息、深度信息、骨架信息等。總的來說,相較于基于非視覺的采集方式而言,基于視覺的采集方式,具備成本低、采集方便、設備依賴度低等優勢,同時在特征處理、算法模型上更具挑戰性。
2.1.2 公共數據集簡要分析
手語數據集可以大致分為孤立詞手語數據集和連續手語數據集。孤立詞手語數據集主要用于孤立詞手語識別研究,由較短的手語單詞視頻構成。而連續手語數據集主要用于連續手語識別與手語翻譯研究任務,由較長的手語句子視頻組成。表1列舉了部分手語數據集。
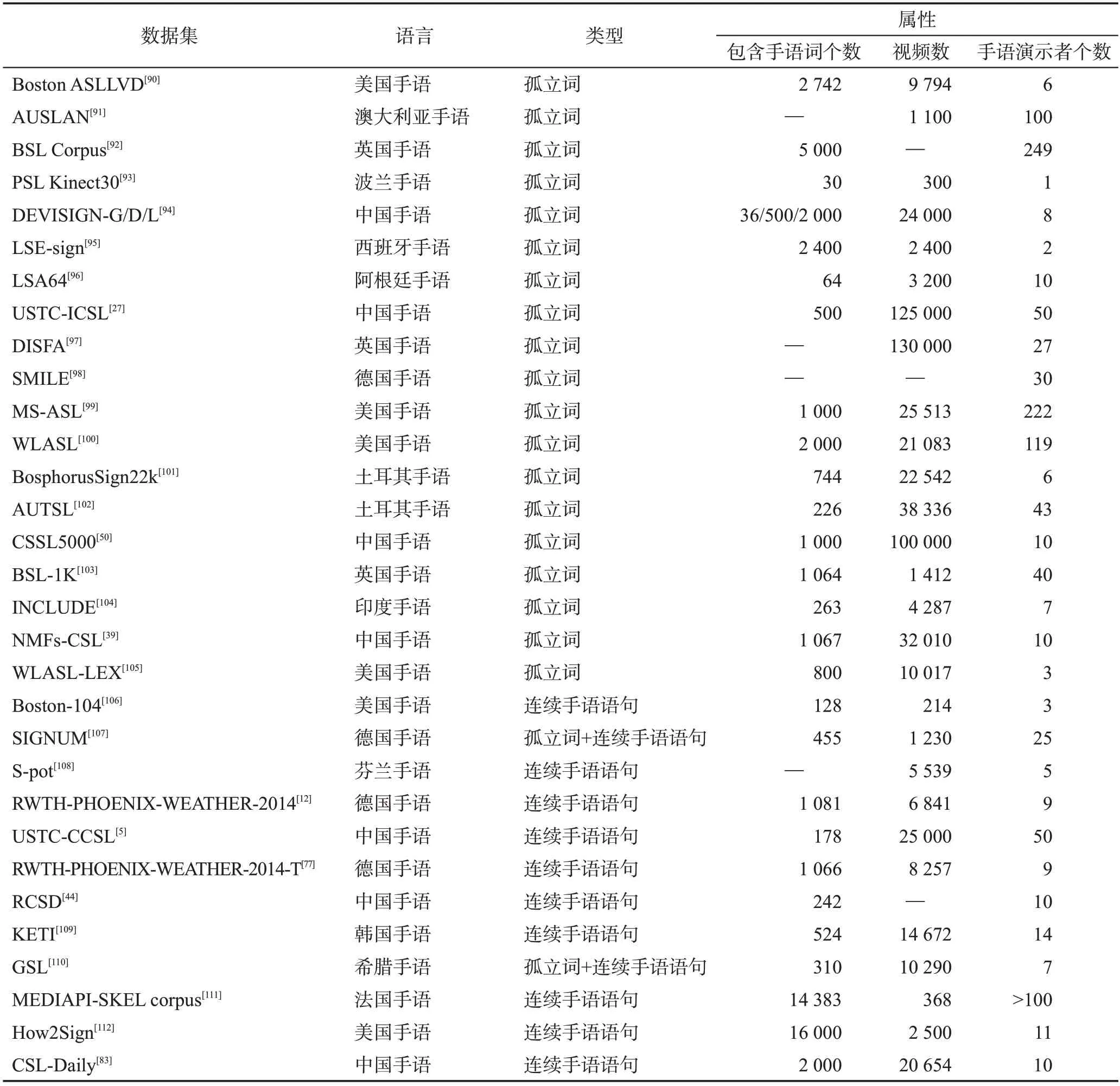
表1 手語數據集總結Table 1 Summary of sign language datasets
其中,目前使用較多的公共手語數據主要包括:RWTH-PHOENIX-WEATHER-2014[12]數據集、RWTHPHOENIX-WEATHER-2014-T[76]數據集、USTC-CCSL[5]數據集和CSL-Daily[83]數據集。
RWTH-PHOENIX-WEATHER-2014[12]是用于連續手語識別的德國手語數據集,其素材來源于9位手語主持人播報的天氣預報視頻。數據集的訓練集、驗證集和測試集分別包含5 672、540和629個數據樣本。
RWTH-PHOENIX-WEATHER-2014-T 數據集[76]可以同時用于手語翻譯任務和識別任務,該數據集同樣來自于德國手語的天氣播報。數據集的訓練集、驗證集和測試集分別包含7 096、519 和642 個樣本。與RWTH-PHOENIX-WEATHER-2014數據集類似,同樣擁有9個手語演示者。
USTC-CCSL數據集[5]是目前使用最廣的中國手語[113]數據集,該數據集包含約25 000 段已標記的手語視頻,由50 名手語演示者進行手語演示。數據集的訓練集、驗證集和測試集分別包含約17 000、2 000及6 000 個樣本。特別的,該數據集采用Kinect 攝像機[114]采集數據,可提供RGB視覺信息、深度信息及骨架信息。
CSL-Daily數據集[83]可用于連續手語識別及翻譯任務,相較于USTC-CCSL,CSL-Daily 更側重于日常生活場景,包括家庭生活、醫療保健和學校生活等多個主題。CSL-Daily的訓練、驗證和測試集分別包含18 401、1 077和1 176段視頻樣本。
在連續手語語句數據集中,一部分數據集有注釋與正常口語語序的文本對照,可用作手語翻譯,主要包括Boston-104[106]、RWTH-PHOENIX-WEATHER-2014-T[77]、KETI[109]、GSL[110]、MEDIAPI-SKEL corpus[111]和CSL-Daily[83]數據集。
2.2 評價指標介紹
對于孤立詞手語識別,常采用準確率和召回率進行評價[115]。準確率(Acc)又叫查準率,表示在所有的樣本數中得到正確分類的樣本數所占據的比例。通常采用Top-1準確率和Top-5準確率進行評價。前者用于預測結果中取最大的概率向量,若正確則分類結果正確,反之則錯誤;后者預測結果中取最大的前五個概率向量評判正確性,若五個全部預測錯誤時則預測分類結果錯誤,反之則正確。召回率(Recall)又叫查全率,表示的是樣本中的正例有多少被預測正確。
對于連續手語識別,常采用誤字率和準確率。誤字率(word error rate,WER)[116]作為手語識別研究中衡量兩句之間相似度的指標。其是指將已識別句子轉換為相應參考句子所進行的替換、插入和刪除操作的最小總和。

其中,S、I和D表示將假設句轉換為標注序列所需的替換、插入和刪除操作的最小數量。N是標注序列的單詞數。一些文章中使用準確率表示手語識別的性能,具體公式為:
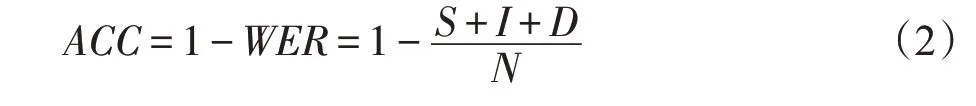
對于手語翻譯,評價體系參考自然語言翻譯研究,包括評價指標:BLEU(bilingual evaluation understudy)[117]、CIDEr(consensus-based image description evaluation)[118]、ROUGE(recall-oriented understanding for gisting evaluation)[119]和METEOR[120]。BLEU 得分是手語翻譯常用的評估指標。假設一個文本由機器和人工各翻譯一次,BLEU的值為n個連續的單詞序列(n-gram)同時出現在機器翻譯和人工翻譯中的比例。根據n-gram可以劃分成多種評價指標,如BLEU-1、BLEU-2、BLEU-3、BLEU-4。CIDEr 是BLEU 和向量空間模型的結合。通過計算其TF-IDF向量[121]的余弦夾角,得到各個n-gram 的權重來度量得到候選句子和參考句子的相似度。ROUGE 是通過統計系統生成的機器翻譯與人工生成的標準翻譯之間重疊的基本單元(n元語法、詞序列和詞對)的數目,來評價翻譯的質量。與BLEU 得分不同,METEOR 考慮到了語言的變化性。METEOR不僅雙向比較了機器翻譯和人工翻譯,而且還考慮到了語言語法等因素。例如在英語中,ride 或riding 在BLEU 方法中算作不同的詞,在METEOR中由于詞根相同,兩者算作同一個單詞。
3 手語識別與翻譯研究面臨的挑戰
3.1 手語視頻幀有效信息獲取
首先,手語視頻冗余性會導致關鍵幀提取困難。手語視頻普遍較長,并且有的視頻會有大量空白幀,有的任務背景過于復雜,系統在識別提取關鍵手勢時會遭遇困難。其次,針對連續手語識別,其本質上是一種弱監督的學習任務[122]。連續手語視頻中語義邊界是未知的,由于手語詞匯豐富,許多術語都有非常相似的手勢和動作。而且,因為不同的人有不同的動作速度,同樣的手語注釋可能有不同的長度。如何精確分割每個手勢是困難所在。如果對視頻進行時間分割時出現錯誤,會不可避免地將錯誤傳播到后續步驟中,從而影響結果的準確度。這些因素都會給手語視頻幀處理及特征提取帶來挑戰。表2 列舉了一些近年來代表性的在手語視頻特征處理上的研究工作。
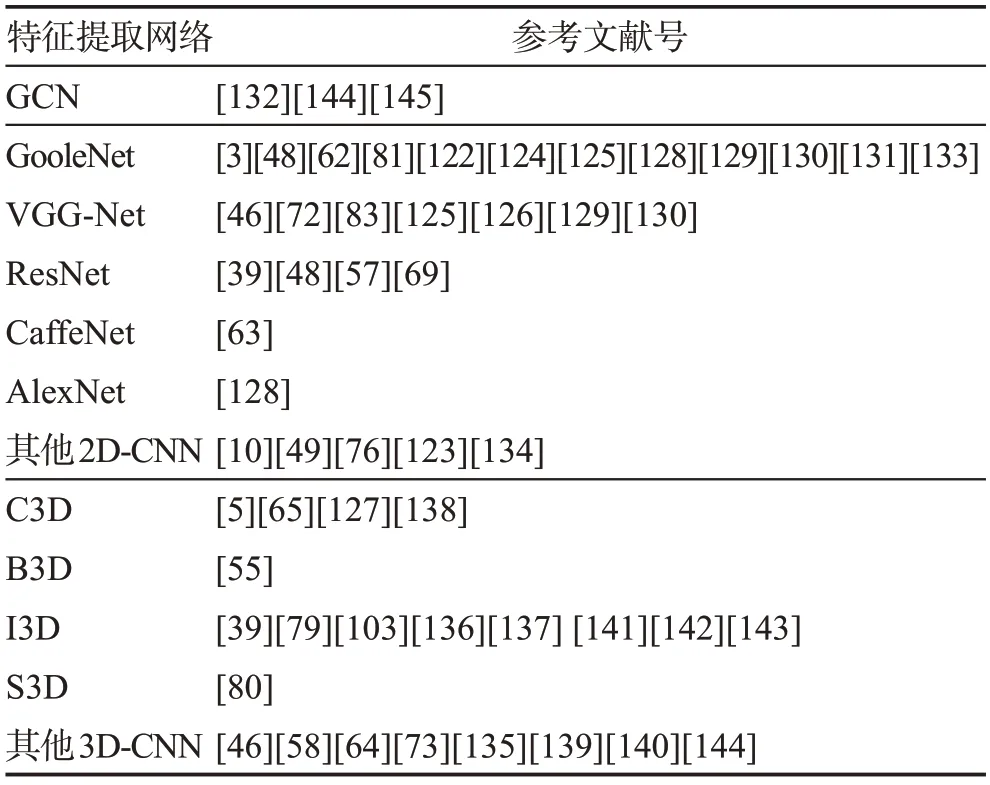
表2 特征提取代表性工作Table 2 Representative work of feature extraction
3.2 多線索權重分配
為了有效地進行手語識別與翻譯,需要從不同線索進行融合共同指導模型預測,因此如何綜合利用這些線索進行多角度的手語特征表達也是難點之一。首先,簡單的特征融合組合不一定比單個特征更好。其次,對于多線索而言,自適應地為不同線索設置模型參數并非易事,每個模型中所涉及到的關鍵動作的變化都可能會對參數造成影響。針對多線索融合問題,需要關注的重點是選擇哪些線索以及如何融合這些線索。一種可行的方案是通過大量的對比實驗,找出最優的特征融合方式,例如設置線索優先級、動態分配各個線索權重、設置多步融合模塊等。
3.3 手語語法和自然語言語法的對應
根據手語語言學研究,通常一些國家的手語可分為自然手語和規約手語(或稱手勢手語)。以中國手語舉例,中國手語可以分為自然手語和手勢漢語。自然手語主要由聽障人士使用,具備一套體系化的語法規則,而手勢漢語是一種在口語語法的基礎上直接進行手勢演練操作的人工語言,其和漢字具有一一對應的關系,因此又稱書面手語。如何將自然手語和規約手語進行映射是手語翻譯研究的挑戰之一。現有手語翻譯研究大多是在連續手語識別的基礎上,結合語言模型得到符合口語化描述的自然語言翻譯。未來可以考慮構建大型的文本對數據集,即自然手語注釋集及對應的規約手語注釋集,將語言模型在文本對數據集上先進行預訓練,然后遷移至手語翻譯的語言模型中。
3.4 數據集資源
相對于手語識別及翻譯研究模型所需的數據規模而言,目前的手語數據集還遠不能滿足模型需求,而基于數據驅動的識別及翻譯方案,很容易導致神經網絡過擬合。且大部分數據是在實驗室環境下拍攝收集,而在現實場景中,存在背景多變、陰影、遮擋等眾多干擾,這更容易導致模型無法較好地捕捉到手部、臉部及肢體等部位的變化,從而影響識別和翻譯結果。未來研究者們可以考慮構建規模更大、場景更復雜的通用手語數據集。
4 結束語
手語識別與翻譯是一個典型的多領域交叉研究方向,具備重要的研究及社會意義。由于手語的復雜性及當前客觀的技術及數據方面的制約,手語識別與翻譯研究充滿挑戰性,尤其是數據量不夠造成的模型過擬合問題以及模型過于復雜導致的實時性不夠的問題。文章對近年來手語識別與翻譯相關研究進行綜述,簡單介紹了主流方法情況及特點,同時介紹了手語識別與翻譯研究所涉及的數據集及評價方式,為研究者快速全面地了解手語識別與翻譯研究提供了有效的途徑。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
小學教學參考(2015年20期)2016-01-15 08:44:38
