領域外人臉活體檢測綜述
2022-11-15 16:17:22史屹琛肖立軒賀晶晶胡晶晶
計算機與生活 2022年11期
史屹琛,封 筠+,肖立軒,賀晶晶,胡晶晶
1.石家莊鐵道大學 信息科學與技術學院,石家莊050043
2.北京理工大學 計算機科學與技術學院,北京100081
人臉識別因其低成本、易采集及特異性強等特點被廣泛應用于智能安防、公安刑偵、智能家居、電子商務及金融服務等領域。但其極易受到各種形式的惡意攻擊,如呈現攻擊、對抗攻擊與合成攻擊,這三種攻擊方式共同之處是不攻擊人臉識別系統的后端,而是嘗試通過對用戶人臉的再次呈現、生成來欺騙人臉識別系統。呈現攻擊通過使用照片、視頻、3D面具等在攝像頭前再次呈現進行攻擊;對抗攻擊則通過佩戴專門設計的眼鏡、帽子來欺騙人臉識別模型[1];合成攻擊則通過DeepFake[2]等工具生成偽造的人臉圖片直接攻擊人臉識別系統,與前兩種攻擊方式不同的是,進行識別的圖片并未通過攝像頭進行拍攝。以上三種對人臉識別系統的惡意攻擊如圖1所示。相較于對抗攻擊和合成攻擊,呈現攻擊更加容易實施,攻擊者可以輕易地獲取到目標用戶的人臉信息,在系統前再次重現人臉進行攻擊。為了保護人臉識別系統不被這種假體呈現攻擊所破壞,人臉活體檢測或稱人臉反欺詐(face anti-spoofing,FAS)技術應運而生。靜默型人臉活體檢測模型無需用戶做出特定的動作進行配合,相較于交互式活體檢測速度更快,用戶體驗也更好,但同時對算法的要求更高,因此吸引了大量的研究人員關注。
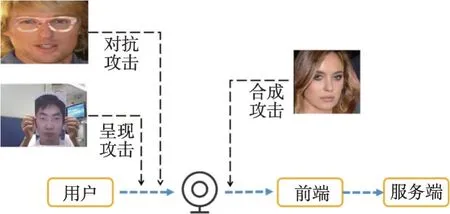
圖1 針對人臉識別系統的不同攻擊方式Fig.1 Several attack modes against face recognition system
對于靜默型人臉活體檢測的研究可以分為手工提取特征的方法和基于深度學習的方法。手工提取特征的方法通常基于研究人員的先驗知識,從紋理如局部二值模式(local binary patterns,LBP)[3-4]、方向梯度直方圖(histogram of oriented gradients,HOG)[5]、尺度不變特征變換(scale-invariant feature transform,SIFT)[6]、SURF(speeded-up robust features)[7]、圖像質量以及輔助信息遠程光電體積描記術(remote photoplethysmography,rPPG)[8-9]等角度進行人臉活體檢測。基于深度學習的方法則使用神經網絡提取圖像的特征進行分類,除訓練一個端到端的神經網絡進行檢測之外[10],研究人員也通過各種方式將先驗知識融合到網絡模型之中:將傳統的手工算子與神經網絡結合[11-13],提取圖片的輔助信息如深度圖[9,14-15]、反射圖[16-17]、rPPG[18]及光流信號[19-21]等。神經網絡強大的表征能力也使得這些方法的測評結果大幅度優于基于傳統方法的活體檢測模型。
雖然當前基于深度學習方法的人臉活體檢測模型在各個數據集的測評上取得了令人滿意的結果,但這些模型都是基于訓練數據與測試數據服從獨立同分布(independent identically distributed,i.i.d)的假設[22],往往會使得訓練得到的模型采用大量領域特有的特征進行分類,如背景、光照等,而無法學習到可以真正判別真實人臉和假體攻擊的特征,易使得模型在各個數據集上過擬合。在真實世界中,進行推理測試時的樣本和算法訓練時使用的數據存在著大量差異,例如環境、攻擊方式等。因此,在訓練集上過擬合的算法無法泛化到真實的使用場景中,即模型需要面對領域外場景下泛化能力弱的問題。
目前,針對人臉活體檢測的綜述文獻大都從傳統機器學習算法和深度學習兩個角度進行介紹。謝曉華等人從手工設計特征、深度學習方法以多種機器學習范式(神經網絡搜索、元學習等)對模型方法進行總結[23]。馬玉琨等人從基于手工設計的特征和基于深度學習方法的角度介紹人臉活體檢測任務[24],包括:基于靜態特征和動態特征、基于輔助信息、域自適應與解耦等。盧子謙等人總結了多種傳統方法和深度學習方法的活體檢測模型,并對活體檢測競賽的各參賽方法及結果進行介紹[25]。鄧雄等人著重闡述了基于手工設計特征方法和基于模型融合策略的人臉活體檢測模型[26]。當前關于人臉活體檢測的綜述大都總結的是基于i.i.d假設下的深度學習方法,只有部分文獻提到關于域自適應、域泛化的活體檢測模型[27]。因此,根據已有研究成果,有必要從人臉活體檢測任務在真實世界的過程中遇到的實際問題出發,從遷移學習的角度討論不同場景下出現的分布差異以及問題的難度。
本文系統地總結分析了近期針對領域外場景下深度學習人臉活體檢測模型相關的研究進展。從人臉活體檢測方法在現實場景遇到的難點和挑戰出發,將問題分為兩類:遇到未知環境和遇到未知攻擊方式。針對每種問題的不同方法進行總結,繼而將解決遇到未知環境的方法分為領域自適應、領域泛化兩類,將解決遇到未知攻擊方式的方法分為零樣本/小樣本、異常檢測兩類,詳述了代表性方法的原理、優勢和不足。之后對領域外人臉活體檢測方法使用的常用數據集進行整理,對算法評估常用的性能指標和測評協議進行了介紹,最后對領域外人臉活體檢測技術的未來發展趨勢進行展望。
1 領域外人臉活體檢測方法
人臉活體檢測是一個開集檢測問題,在實際使用中會遇到大量與訓練數據分布不同的樣本,模型將要面對跨域遷移和分布外(out of distribution,OOD)泛化的問題,主要為遇到未知的領域(光照、背景、人臉外觀與相機的質量等)以及遇到未知的攻擊方式(照片人臉攻擊、視頻回放攻擊與3D人臉面具攻擊等)。對于各種問題有著不同的解決方式,領域自適應和領域泛化等技術被用于減少不同領域之間的數據分布差異,零樣本/小樣本以及異常檢測技術則用于識別出訓練集中未曾出現過的攻擊方式。
1.1 領域未知
領域領域D主要由數據和生成這些數據的概率分布組成,領域上的一個樣本包含輸入x∈X和輸出y∈Y,聯合分布記為P(x,y),即(x,y)~P(x,y),其中X和Y為數據所處的特征空間和標簽空間,則一個領域為D={X,Y,P(x,y)}。在遷移學習中,將有大量數據標注,用于訓練模型的領域稱為源域(source domain),將待學習且只有少量有標注或無標注數據的領域稱為目標域(target domain),即要最終賦予知識,賦予標注的領域[8]。
分布差異一般來講,傳統的統計機器學習算法是基于i.i.d假設,而真實應用中該假設并不容易被滿足,即Ps(x,y)≠Pt(x,y),這使得在訓練集上獲得的模型無法在測試集上得到理想的結果[28]。
通常來說,在人臉活體檢測任務中,最主要的分布差異是協變量偏移(covariate shift)[29],符合Ps(y|x)=Pt(y|x)且Ps(x)≠Pt(x),也就是訓練數據和測試的邊緣分布不同,但是生成最終標簽的機制是不變的,其條件分布相同[27]。
如圖2 所示,不同數據集的采集環境各不相同,這些環境差異會在領域的分布上體現出來。領域自適應技術目的在于通過使用所給的目標域知識來使得在源域上訓練的模型在目標域上表現盡可能得好[30],而領域泛化技術則無需目標域的知識,通過挖掘多個源域之間的內在聯系,使得源域上訓練的模型泛化性盡可能得高[31]。

圖2 不同數據集中的人臉圖像Fig.2 Face images in different datasets
1.1.1 領域自適應
給定一個有標記的源域Ds={xi,yi}和一個目標域Dt={xi,yi},假設其特征空間和類別空間相同,但其聯合分布不同,即Xs=Xt,Ys=Yt,Ps(x,y)≠Pt(x,y)。領域自適應的任務是利用源域數據去學習一個目標域上的預測函數f:xt→yt,使得f在目標域上擁有最小的預測誤差。
領域自適應技術通過嘗試減小源域和目標域之間的差異來使得模型在目標域上得到的結果更好。通常來說,目標域都是無標簽的數據,如圖3所示,因此無法使用一般的預訓練-微調的策略。針對人臉活體檢測中的領域自適應問題,研究人員主要從領域分布差異、對抗遷移學習等方向進行探索。
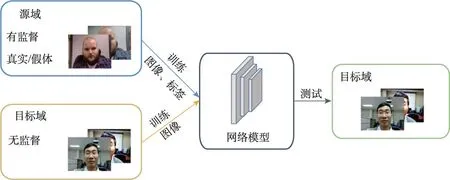
圖3 領域自適應框架Fig.3 Domain adaptation framework
(1)領域分布差異
Li等人通過最小化源域和目標域特征空間之間的最大均值差異(maximum mean discrepancy,MMD)[32]學習到一個泛化性更強的分類器[33]。Tu等人通過減小源域和目標域之間基于核方法的MMD 距離來提高模型的泛化性[34]。然而僅僅通過減小領域之間的MMD距離可能無法充分探索源域之間的有用信息,因此目前使用對抗遷移學習的方式成為研究熱點。
(2)對抗遷移學習
Kim等人提出一種風格指導的領域自適應框架,通過風格選擇歸一化來構造推理自適應模型,實現利用特定領域的風格信息指導,自動將模型適配到目標數據[35]。Hamblin等人提出了一種新的領域自適應框架,該框架利用了多模式數據來改善基于可見光的呈現攻擊檢測(presentation attack detection,PAD)任務[36]。孫文赟等人提出了一種基于深度特征增廣的跨域小樣本人臉欺詐檢測算法[37]。該算法在已有的基于全卷積神經網絡的人臉欺詐檢測網絡的中部嵌入域自適應層,將卷積特征圖增廣,借助目標域中的小樣本擴展訓練數據來適配源域和目標域的差異,提升跨域性能。但在目標域標簽未知的無監督域自適應學習任務以及目標域圖像與標簽未知的零樣本學習任務中效果欠佳。Huang 等人提出一種針對小樣本的跨域活體檢測模型,使用集成了適配器與特征變換的ViT(vision transformer)模型作為主干,進而提高小樣本跨域活體檢測的穩健性[38]。
Wang等人使用對抗訓練的方式使得特征提取器提取到源域和目標域共同的特征[39],同時使用三元組損失使得真實人臉和假體攻擊在特征空間上盡可能分散,最后使用KNN(K-nearest neighbor)分類器進行分類。El-Din 等人認為只使用對抗訓練的方式進行領域自適應會在目標域和源域攻擊方式和設備類型不同的情況下無法得到很好的結果,為了保存目標域一些特有的屬性[40],使用了深度聚類生成偽標簽進行輔助訓練。Jia等人提出了邊緣分布對齊模塊和條件分布對齊模塊[41],通過對抗訓練的方式尋找領域不變的特征空間,使得同一類的特征做到類內緊湊,并且通過添加、刪除條件分布對齊模塊,網絡可以切換為半監督、無監督模式。Wang 等人提出了一種基于無監督對抗遷移的方法,由度量學習模塊(metric learning net,ML-Net)、無監督域自適應模塊(unsupervised domain adaptation net,UDA-Net)和解耦重構模 塊(disentangled representation learning net,DRNet)三個模塊組成[42]。ML-Net通過使用有標簽的源域人臉圖像來學習真實人臉與欺騙人臉之間有判別力的特征。UDA-Net 通過無監督的對抗域式自適應,聯合優化源域和目標域的特征編碼器,從而獲得被兩個域共享的公共特征空間,進而可以讓源域的ML-Net模型對目標域的無標簽人臉圖像也具有判別能力。DR-Net通過從公共特征空間重建源域和目標域人臉圖像,將域無關和域相關的特征解耦,進一步提升共同特征空間的重構能力和判別能力。除了對抗遷移學習的方式,學者們還探索使用其他方法解決人臉活體檢測中的領域自適應問題。
(3)其他方法
Tu 等人同時考慮到人臉活體檢測和人臉識別,在提高泛化能力的部分[43],提出了TPC(total pairwise confusion)損失函數和快速領域自適應模塊,分別用以提高假體攻擊表征的泛化性和減少領域改變時帶來的負影響。Wang等人不同于一般的領域自適應和領域泛化的方法[44],提出了自域自適應框架,采用元學習的方法,在多個源域上不僅學習到可判別的特征,還訓練一個調節器,在推理階段遇到目標域的無標簽數據時,調節器來適配目標域的特征分布。Mohammadi 等人通過剪枝,將泛化性強的特征提取層保留[45],使得最終的模型在多個目標域上得到理想的結果。
基于領域自適應的方法可以有效地提高模型的泛化能力,但仍需使用目標域的數據進行學習,挖掘源域與目標域之間的關系,可是該條件有時并不能滿足。表1 對基于領域自適應的人臉活體檢測方法從機制、模型結構、優點、局限性及適用場景等方面進行對比總結。

表1 基于領域自適應的FAS方法總結Table 1 Summary of FAS methods based on domain adaptation
1.1.2 領域泛化
訓練數據D來自N個具有不同但相似數據分布的領域,假定每個領域均含有M個樣本,每個領域的數據均服從自己的數據分布(xm,ym)~Pi(x,y)表示,領域泛化要求從這N個領域中學習模型f:x→R,使得f在未知的目標域Dt上預測誤差達到最小[31]。領域泛化任務相較于領域自適應任務更為困難,無法得到目標域上的標注數據,訓練得到的模型在面對分布外場景時也需保證魯棒性。領域泛化假設在多個已知源域和未知的目標域之間存在一個泛化的特征空間,因此需要模型通過多個源域學習到該特征空間,使得模型在未知的目標域上取得滿意的結果,如圖4所示。針對人臉活體檢測中的領域泛化問題,研究人員主要從元學習與對抗遷移學習兩個方向進行探索。
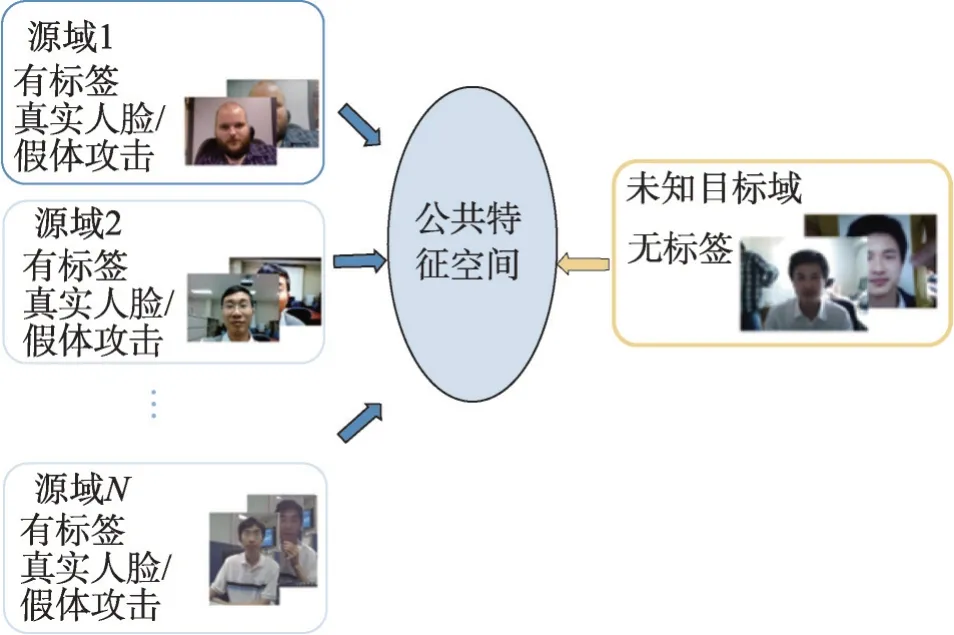
圖4 領域泛化框架Fig.4 Domain generalization framework
(1)元學習
Shao等人將人臉活體檢測的領域知識作為正則化項[46],使得元學習在領域知識監督下正則化的特征空間中進行,更有可能找到廣義的學習方向,此外還采用了細粒度的學習策略,在每次迭代的過程中同時在各個領域場景中進行元學習。Cai 等人提取元特征[47],以替換手工設計特征的方式,之后將輸入圖像和提取到的元特征融合,利用神經網絡進行分類。Kim 等人不是簡單地認為一個數據集為一個領域,而是使網絡能夠通過中間層的卷積特征統計信息來自行判斷其屬于哪個領域[48],之后使用MLDG(meta-learning domain generalization)[49]框架訓練分類器。同樣Chen等人認為實際應用中收集的數據集總是包含混合域,直接認為一個數據集為一個領域的大多數方法在這種情況下可能無法工作[50]。為了克服這一限制,作者提出了域動態調整元學習,在不使用域標簽的條件下,根據實例歸一化(instance normalization,IN)[51]和域表征學習模塊對領域進行聚類。元學習方法通常涉及到雙層優化的問題,需要大規模的計算資源和較長的訓練時間,因此使用對抗訓練的方式進行領域泛化是另一個熱點方向。
(2)對抗遷移學習
蔡體健等人提出了基于條件對抗域泛化的人臉活體檢測方法,利用多線性映射將特征提取器的輸出特征和分類預測的結果結合起來作為條件輸入到域判別器,通過對抗訓練提取多個源域的共性特征,在特征和類層面同時對齊多個源域的分布,相比現存的域泛化人臉活體檢測方法在數據分布上匹配得更好[52]。李策等人提出了一種采用超復數小波生成對抗網絡的活體人臉檢測算法,將三個源域數據輸入到對抗網絡,生成區別于源域但兼具三個源域共享特征的特征空間,提高判別人臉活性特征的泛化能力[53]。Wang 等人提出一種SSAN(shuffled style assembly network)網絡,利用對抗學習來融合不同領域的圖像內容特征,利用對比學習策略來抑制特定領域的風格特征,進而將兩種特征整合來應對不同領域間的差異[54]。域泛化任務中將所有人臉完美映射到共享特征空間是困難的。
針對上述問題,Liu等人提出一個特征生成和假設驗證框架來緩解上述問題[55],在FAS任務中首次引入了特征生成網絡,該網絡生成真實人臉和已知攻擊的假設。應用兩個假設驗證模塊來分別判斷輸入人臉是否來自真實人臉空間和真實人臉分布。Shao等人為多個源域分別建立特征提取器與泛化特征提取器進行對抗訓練[56],同時使用輔助深度監督來提高特征提取器的泛化能力,使用雙力三元組挖掘約束,使得不同領域之間的活體人臉與假體攻擊在得到的泛化特征空間上達到類內緊湊且類間分散的結果。Jia等人認為直接拉近不同的領域假體攻擊在特征空間上的分布,會因為過于忽視不同領域的特有信息,無法得到很好的結果[57],所以使用單邊對抗學習和不平等三元組損失,使得每個領域的假體攻擊和所有領域的活體人臉分別作為多個類別進行訓練,以達到類內緊湊且類間分散的結果。Liu 等人認為之前將各個領域的樣本同等對待,直接提取一個公共特征空間的方法,會由于數據的復雜性而破壞泛化能力[58],進而提出了一種雙重加權域泛化框架,使用樣本加權模塊和特征加權模塊進行兩次加權,同時結合判別器,兩個模塊的迭代促進了公共特征的提取。表2對基于領域泛化的人臉活體檢測方法從機制、模型結構、優點、局限性及適用場景等方面進行對比總結。
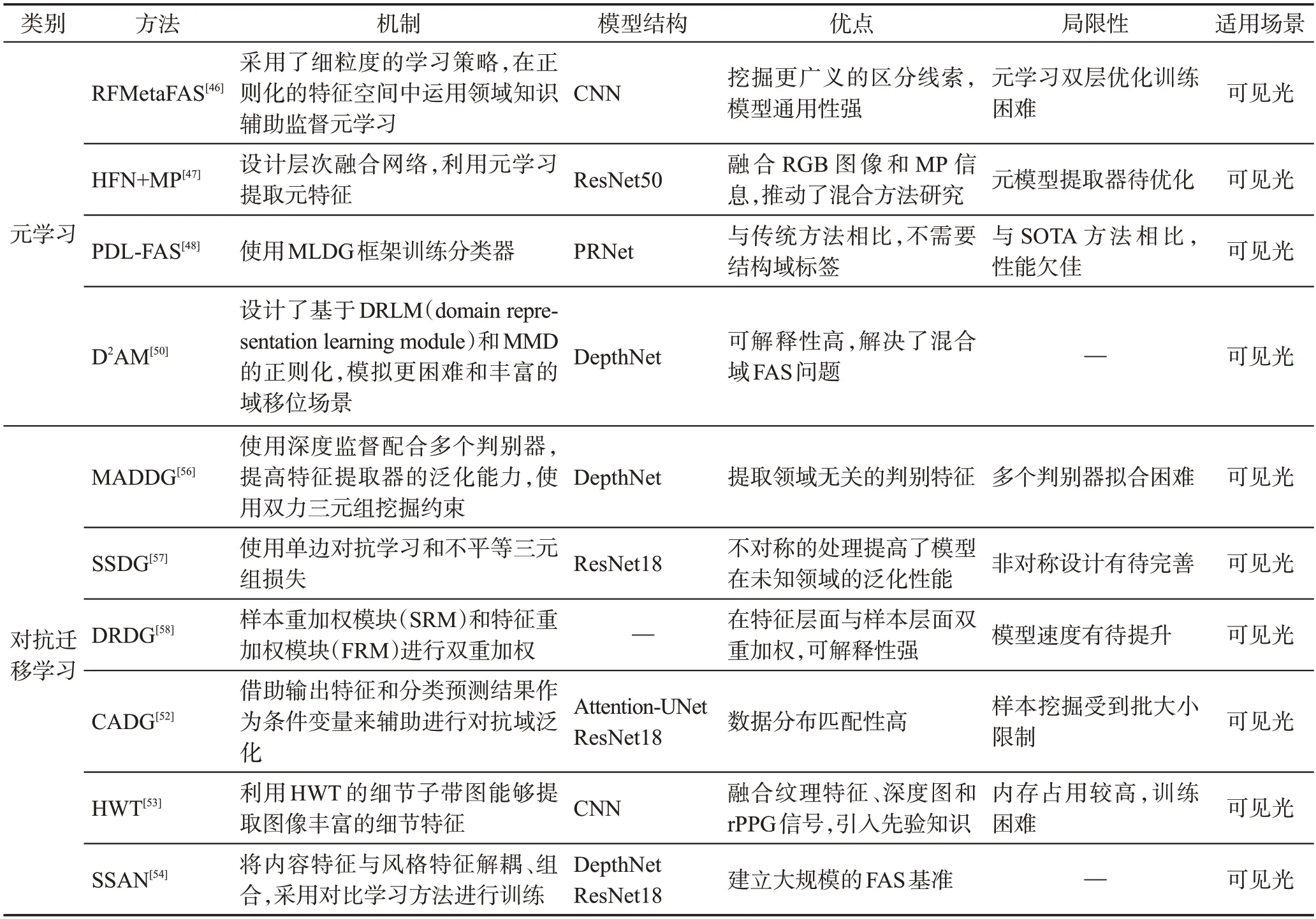
表2 基于領域泛化的FAS方法總結Table 2 Summary of FAS methods based on domain generalization
1.2 攻擊方式未知
人臉活體檢測算法在實際應用中除了會遇到領域偏移問題之外,未知的攻擊方式同樣使檢測模型的結果不盡人意。之前的大部分基于深度學習的方法將人臉活體檢測任務視為閉集預測問題,檢測各種之前預先定義好的假體攻擊。然而期望數據集中包含所有的攻擊方式是不現實的,使得模型很容易在已知的攻擊方式上過擬合,仍會輕易被未知的攻擊所破壞。因此,最近研究者們致力于探索如何使人臉活體檢測模型遇到未知的攻擊方式時仍然魯棒,零樣本/小樣本學習和異常檢測的技術應用于檢測未知的攻擊方式是當前的兩個熱門方向。
1.2.1 零樣本/小樣本學習
小樣本學習旨在通過少量樣本學習到解決問題的模型[59],零樣本學習則是指在沒有訓練數據的情況下,利用預先定義的一些類別屬性等訓練模型[60]。小樣本學習任務通常指的是N-wayK-shot任務,即選擇N個未知的類別,每個類別有K個樣本待學習。相較于傳統的分類任務,提供給模型的每個類別的樣本數量(K)都極少,且這N×K個樣本構成支持集。在評估階段,從N個未知的類別中挑選出部分樣本作為查詢集。零樣本學習任務要求只根據一些屬性描述或語義信息等即可學習到未知的類別,即支持集只包含未知類別的語義描述。
George 等人認為對預訓練的ViT 模型進行微調后,在未知攻擊方面表現出良好的性能,同時在跨數據集評估方面的性能比已有方法提高了一個數量級[61],充分展示了ViT模型在遇到未知領域和未知攻擊時有很好的泛化能力。Pérez-Cabo 等人首次提出了一種遵循小樣本學習范式的連續元學習的人臉活體檢測框架[62]。該框架同時適用于連續學習和元學習環境,不僅解決了傳統連續學習任務在面對新攻擊方式時的災難性遺忘問題,還在新攻擊數據順序到達的情況下,實現模型持續學習,達到了使用全部數據同時訓練模型的結果。Qin 等人將人臉活體檢測定義為零樣本和小樣本學習問題,提出了一種新的自適應更新人臉活體檢測方法[63],通過學習預定義的活體、欺詐的人臉以及一些新攻擊的樣本,進而檢測未知的欺詐類型。該方法在現有的零樣本FAS協議中的性能優于已有的算法,但其只關注了模型在目標域的性能,忽略了模型在源域的性能。
Quan 等人設計了一種自適應轉移機制[64],通過逐漸增加未標記目標域數據在訓練中的貢獻來改善域偏差。Yang等人認為之前的方法都犧牲了模型在源域上的性能,而這在人臉活體檢測任務中是不可取的,因此提出了小樣本的領域擴展策略[65],從語義空間上對齊源域和目標域,使模型在源域和目標域的聯合擴展域上表現良好。Liu 等人引入首個包含多種欺詐攻擊類型的人臉反欺詐數據庫,廣泛研究了13 種類型欺詐攻擊中的ZSFA(zero shot face antispoofing)問題,包括打印、重放與3D 面具等,進而提出了一種新的深度樹網絡[66]。該方法以無監督的方式將欺詐樣本劃分為語義子群,當攻擊數據樣本到達時,模型將其劃分到最相似的欺詐簇,并進行二進制決策。表3對基于零樣本/小樣本學習的人臉活體檢測方法從機制、模型結構、優點、局限性及適用場景等方面進行對比總結。

表3 基于零樣本/小樣本學習的FAS方法總結Table 3 Summary of FAS methods based on zero/few shot learning
1.2.2 異常檢測
異常檢測的目的是在測試過程中檢測出任何與預定的常態所偏離的異常樣本,這些異常樣本往往由協變量偏移或語義偏移造成[67]。人臉活體檢測任務中將活體人臉認為是正常類別,而將假體攻擊當作異常樣本。如圖5所示,與之前將人臉活體檢測視為二分類任務不同,基于異常檢測方法的人臉活體檢測模型通常采用的是單分類,在訓練階段只使用真實人臉。因為在實際應用中,攻擊的類型很有可能是未知的,在特征領域中占據廣泛的空間。
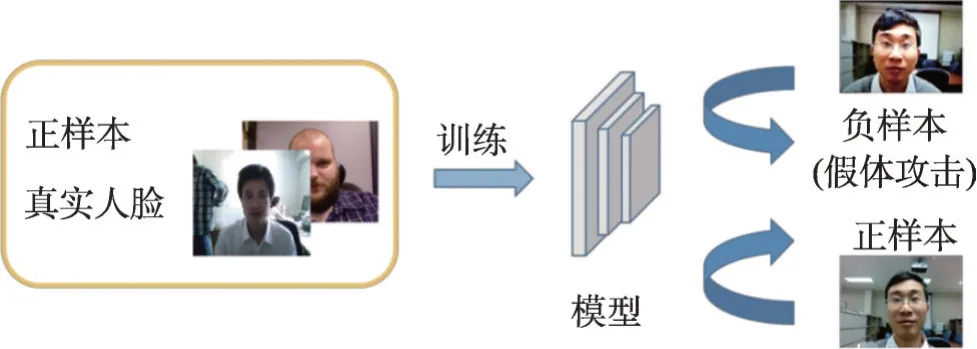
圖5 異常檢測框架Fig.5 Anomaly detection framework
Arashloo 等人從異常檢測的角度看待人臉活體檢測任務,提出一種基于異常檢測的單分類方法[68],該方法中的訓練集僅來自正樣本即真實人臉,測試集包含正負樣本即真實人臉和假體攻擊,有效避免了對負訓練樣本可用性的需要,并且該方法與傳統二分類方法相比毫不遜色。Abduh 等人研究證明基于異常檢測的人臉活體檢測模型,訓練數據不應局限于人臉活體檢測領域專業數據集,使用加入非專業數據的混合數據集進行訓練的活體檢測模型,在面對未知攻擊時泛化能力更強[69]。Baweja 等人提出了一個端到端的異常檢測模型進行人臉活體檢測,在提取真實人臉特征的過程中,建立一個新的高斯分布用于取樣偽負樣本,與真實的人臉特征一起訓練得到一個卷積神經網絡[70]。但其高斯分布參數的計算方式過于單一,生成的樣本難以代表真實場景中復雜的攻擊方式,且模型對協變量偏移不具備魯棒性。George等人認為現有活體檢測通常是二分類任務,這會導致對已知攻擊的過度擬合,對未知攻擊的泛化性能較差。針對此問題提出一種基于多通道卷積神經網絡進行表征學習的單分類器框架,將未見過的假體攻擊作為異常樣本進行檢測,其適用場景廣泛,包含可見光、深度圖和近紅外等[71]。Nikisins等人提出使用圖像質量度量特征和高斯混合模型來表示真實樣本的概率分布[72],進而對假體攻擊進行識別。Fatemifar 等人在基于異常問題公式的基礎上分析了部署特定于客戶端的面部欺騙檢測信息[73],使用從預先訓練網絡中獲得的表示來訓練一類特定于客戶的分類器(生成式和區別式)。Pérez-Cabo 等人從異常檢測的角度提出深度度量學習模型,三重焦點損失負責指導學習過程在嵌入空間中更有區別的特征表示[74]。通過引入少量的后驗概率估計,無需分類器對學習到的特征進行訓練。表4 對基于異常檢測的人臉活體檢測方法從機制、模型結構、優點、局限性及適用場景等方面進行對比總結。
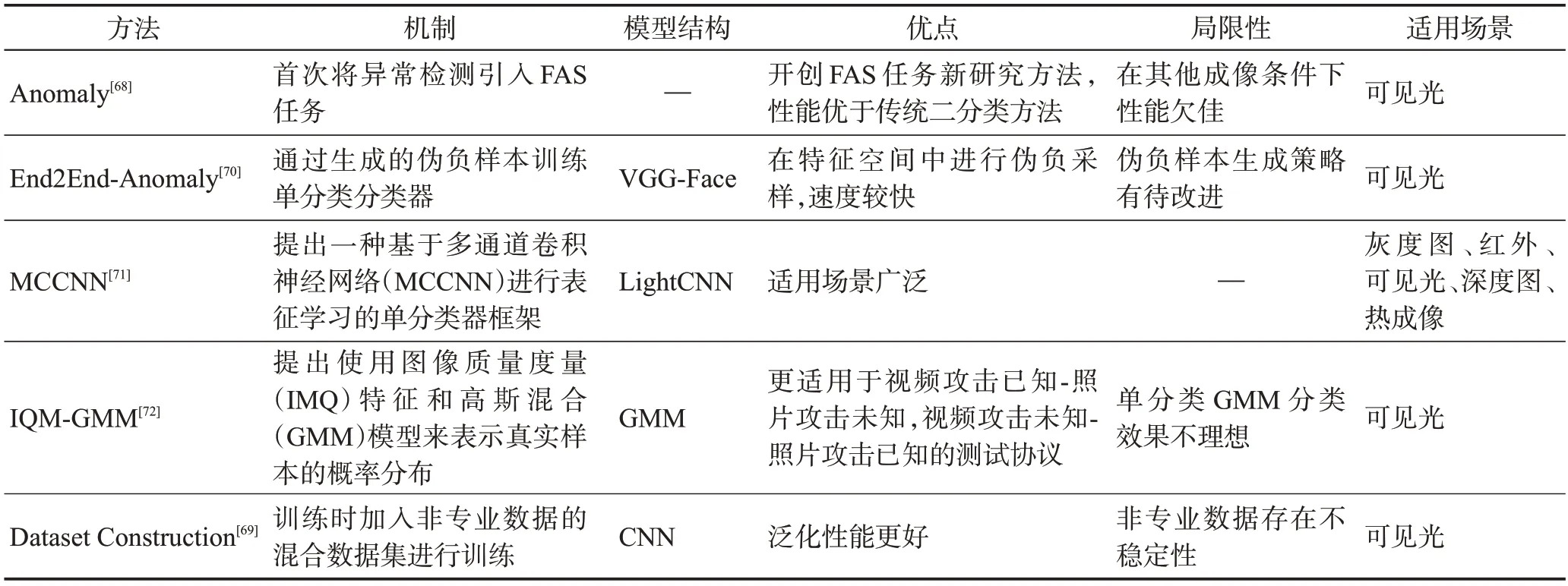
表4 基于異常檢測的FAS方法總結Table 4 Summary of FAS methods based on anomaly detection
2 人臉活體檢測常用數據集
數據集的樣本數量及數據類型的豐富程度會影響人臉活體檢測模型的性能。不同數據集的收集方式、個體數量、攻擊方式與數據模態都有所不同。
下面對領域外場景下的人臉活體檢測主流數據集進行闡述,主要從數據集的特點、所包含的活體人臉和假體人臉的數量、圖像的大小等方面進行介紹,表5給出常用主流數據集的總覽介紹。

表5 主流數據集總覽Table 5 Overview of mainstream datasets
Oulu-NPU[75]一共有55 個志愿者參與錄制,共計4 950 個視頻,這些視頻使用6 款移動設備的前置攝像頭在三種不同光照條件和背景場景拍攝。數據集中采用的演示攻擊類型是打印攻擊和視頻重放攻擊,使用兩臺不同的打印機和兩臺不同的顯示設備進行攻擊。
CASIA-MFSD[76]一共有50 個志愿者參與錄制,共計600 個視頻。該數據集收集的活體和假體的人臉信息較為豐富,其中每個志愿者錄制了3個活體人臉視頻和9 個假體人臉視頻,共計12 個視頻。假體人臉包括完整的彩色照片假體人臉、挖去眼睛的假體人臉以及視頻類假體人臉。照片類假體人臉同時包括正面平展照片以及彎曲照片的情況。
Replay-Attack[77]數據集一共有50 個志愿者參與錄制,共計1 300 段視頻。每個志愿者錄制了4 個活體人臉視頻和20個假體人臉視頻。假體人臉的攻擊方式包括打印人臉照片攻擊、手機呈現攻擊和平板視頻重放攻擊,分為手持設備和固定設備兩種欺騙手段。數據集包括固定場景和復雜場景兩種環境,其中固定場景的背景環境單一,復雜場景的背景顏色豐富,為裝飾性壁畫,室內無燈光。
MSU-MFSD[78]數據集一共有35個志愿者參與錄制,共計380 段視頻,使用兩種不同分辨率的相機進行采集。對于真實人臉,每個人分別使用筆記本電腦和手機采集兩段視頻。其中,視頻攻擊使用兩種相機進行采集,照片攻擊使用惠普彩色打印機進行打印。
SiW[9]數據集一共有165 個志愿者參與錄制,共計4 478段視頻。所有的視頻均為30 frame/s,約15 s長,1080 高清分辨率。活體人臉在錄制時考慮與攝像機的距離、姿態、光照及表情四方面因素。打印攻擊提供高分辨率(5 184×3 456)和低分辨率兩種,視頻重放攻擊則使用三星s8、iPhone7、iPadpro 以及PC顯示器展示。
HQ-WMCA[79]數據集一共有51 個志愿者參與錄制,共計2 904段多模態視頻。數據來源于多個通道(色彩、深度、熱成像、近紅外光譜與短波紅外),攻擊方式包含打印照片攻擊、視頻重放攻擊、三維人臉面具攻擊、化妝與紋身等。
CASIA-SURF[80]數據集一共有1 000個志愿者參與錄制,共計21 000 段視頻多模態視頻。數據來源于多個通道(可見光、深度圖與近紅外),采用平攤打印攻擊或卷曲打印攻擊,隨機扣除掉眼睛、鼻子及嘴巴等區域。
3 評價指標與測評協議
3.1 評價指標
常用的人臉活體檢測性能評價指標主要有兩類:一類是錯誤接受率(false acceptance rate,FAR)、錯誤拒絕率(false rejection rate,FRR)、等錯誤率(equal error rate,EER)以及半錯誤率(half total error rate,HTER)指標;一類是ISO/IEC DIS 30107-3:2017標準提出的假體人臉分類錯誤率(attack presentation classification error rate,APCER)、活體人臉分類錯誤率(bonafide presentation classification error rate,BPCER)以及平均分類錯誤率(average classification error rate,ACER)指標,近年也被廣泛使用。APCER、BPCER同前一類性能評價指標FAR、FRR類似,但FAR、FRR在計算時不考慮具體的攻擊類別,APCER在計算時考慮到每種攻擊類別。
FAR表示把假體人臉判斷成活體人臉的比率,其中,Ns2b表示將假體人臉(spoofing)識別為活體人臉(bonafide)的次數,Ns表示假體人臉攻擊的總次數,定義如式(1)所示:

FRR表示把活體人臉判斷成假體人臉的比率,定義如式(2)所示:

其中,Nb2s表示將活體人臉識別為假體人臉的次數,Nb表示活體人臉檢測的總次數。在訓練集上分別以FRR和FAR為x軸與y軸畫出ROC 曲線。當FRR等于FAR時,其值為EER,以訓練集上EER的閾值作為測試集上的閾值計算出的FAR和FRR的均值為HTER,計算方式如式(3)所示,同時ROC 曲線之下的面積AUC代表著真實人臉和假體攻擊之間的分離程度。

APCER表示將攻擊的假體人臉錯分為真實人臉的比率。對每種攻擊方式(presentation attack instrument,PAI),其APCERPAI計算方式如式(4)所示:
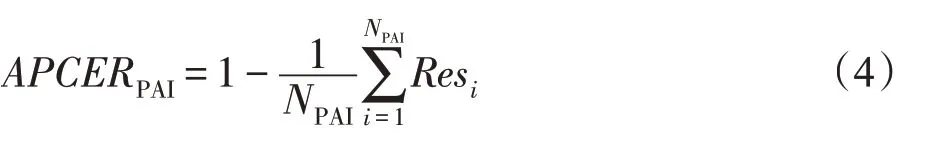
其中,NPAI表示某一類假體攻擊的攻擊次數,將攻擊的假體人臉判斷為假體攻擊時Resi的值為1,將攻擊的假體人臉判斷為真實人臉時Resi的值為0。
假設存在S種攻擊方式,則APCER為所有攻擊方式中APCERPAI最大的那個,其計算方式如式(5)所示:
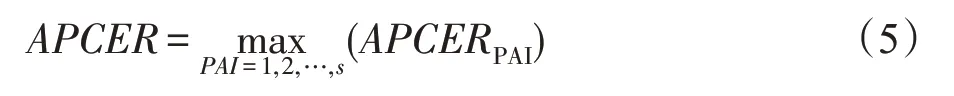
BPCER表示將真實人臉錯誤地判斷為假體攻擊的比率,其計算方式如式(6)所示:

其中,NBF表示真實人臉個數,將真實人臉錯誤地判斷為假體攻擊時Resi的值為1,將真實的人臉識別正確時Resi的值為0。
EER指訓練集上APCER和BPCER相等時APCER和BPCER的均值,ACER指在以EER對應的閾值為測試集閾值時計算的APCER和BPCER的均值,計算如式(7)所示:

3.2 測評協議
為了評估跨域FAS 模型對數據集的識別與泛化能力,下面對目前領域外場景下的FAS 模型測評方法進行總結。現有工作主要基于三種協議:跨庫同攻擊方式、同庫跨攻擊方式以及跨庫跨攻擊方式。
3.2.1 跨庫同攻擊協議
這種測評方案主要側重于度量FAS 模型在跨數據集時遇到不同的光照、背景及環境時的泛化能力。要求FAS 模型在一個或多個源域數據集上訓練,使用訓練階段未知的目標域數據集進行測試,且要保證目標域與源域的攻擊方式相同。當前使用最廣泛的源域與目標域數據集組合為:CASIA-MFSD(簡寫為C)&Replay-Attack(簡寫為I)&MSU-MFSD(簡寫為M)&Oulu-NPU(簡寫為O)[54]。表6 總結了使用上述組合的部分FAS模型的性能。
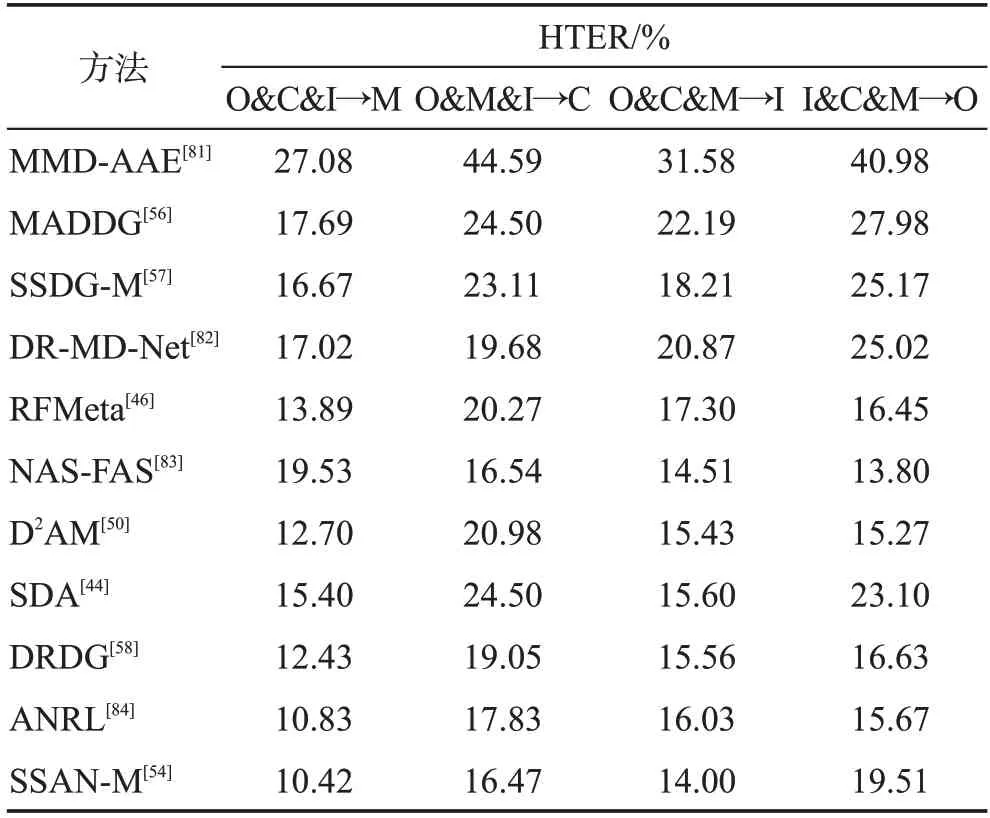
表6 CASIA-MFSD、Replay-Attack、MSU-MFSD和Oulu-NPU的跨數據集測試結果Table 6 Results of cross-dataset testing on CASIAMFSD,Replay-Attack,MSU-MFSD and Oulu-NPU
3.2.2 同庫跨攻擊協議
這種評測方案主要側重于FAS 模型在面對未知攻擊方式時的泛化能力。要求FAS模型在訓練階段使用真實人臉和N-1 種攻擊方式訓練,在測試階段加入第N種攻擊方式的樣本進行測試,即只有一種攻擊類型僅在測試階段出現。SiW-M數據集包含13種攻擊類型,更適合評估FAS 模型對未知攻擊的泛化能力,因此常作為FAS 模型在本評測方案上使用的數據集。表7 總結了近期部分FAS 模型在SiW-M數據集上面對未知攻擊的泛化性能。
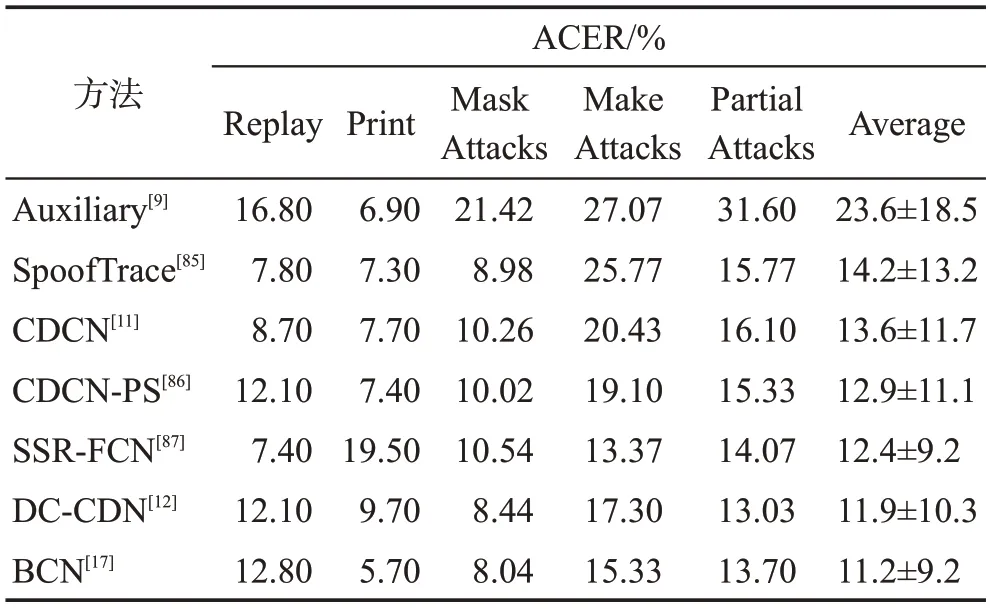
表7 SiW-M數據集上交叉型測試結果Table 7 Results of cross-type testing on SiW-M dataset
3.2.3 跨庫跨攻擊協議
盡管以上測評方案已經涵蓋了人臉活體檢測在面對領域外泛化時的大多數情況,但更有挑戰性、更真實的測評方式是跨庫跨攻擊方式。這種評測方案由Yu 等人[83]提出,用于衡量FAS 模型在未知域和未知攻擊類型上的泛化能力。要求FAS模型在訓練階段使用的數據集包含N種攻擊方式,測試階段使用訓練階段未知的數據集,且攻擊方式沒有與訓練時重合的情況。在該評測方案中,通常用Oulu-NPU和SiW-M(2D 攻擊)混合來訓練FAS 模型,HKBUMARS 和3DMASK(3D 攻擊)用于測試。當前先進的模型在該協議下對于上述兩個測試集的HTER分別達到了6.75%與15.00%。
Wang等人提出了一種更為貼近真實場景的測評協議[54],將12 個公開數據集分為兩個子集P1 與P2,其中一個作為訓練集,另一個作為測試集,如表8 所示。該測評方式中測試集涵蓋了更多未知的數據集和更復雜的未知攻擊,極具挑戰性,且由于提出時間較短,相關研究成果較少。

表8 數據集及其對應的編號Table 8 Datasets and their corresponding numbers
4 未來可能的研究方向
隨著研究的不斷深入,領域外人臉活體檢測方法研究已經取得了一系列的進展,但仍面臨著很多難點與挑戰,未來可能的發展方向主要有:
(1)如何在數據受限場景下得到泛化、魯棒的模型。無監督領域自適應是基于源域和目標域都可以獲得的假設,而因為隱私保護等法規政策,多個領域數據有時無法同時得到,存在只可以獲得在源域上訓練的模型而無法使用源域數據的情況。如何在這種條件下完成無源域的領域自適應任務是一個待解決的難題。同時也存在只可以獲得單個源域而無法得到目標域數據的情況,如何進行單域泛化仍待解決。由于惡意攻擊的不斷進步,在訓練階段收集到所有的攻擊方式并不現實,如何防范未見過的假體攻擊以及如何使用新的攻擊方式持續地更新模型是值得研究的問題。
(2)目前大部分活體檢測數據集包含的攻擊方式多為照片、視頻重放攻擊和面具類的三維假體人臉攻擊。受限于人力、物力等成本因素,數據集包含的假體類別較為單一,視頻重放使用的設備并不全面、先進,數據的模態單一,多為可見光模態。當前收集人臉及假體數據的流程主要為:使用人臉檢測模型檢測視頻流的當前幀是否存在人臉,如果存在則保存當前幀及人臉框的坐標。由于幀與幀之間的時間間隔過短,使得大量的圖片過于相似,收集到的數據集冗余信息過多。數據在深度學習模型的研究中起到了至關重要的作用,數據量大且種類豐富的數據集可以幫助模型更有效地學到泛化的分類特征。如何高效、低成本地收集數據,建立一個模態豐富、攻擊方式全面及個體數量多的數據集,并設計更符合真實應用場景的協議是值得思考和具有挑戰性的問題。
(3)當前先進的人臉活體檢測模型,大都使用卷積神經網絡提取特征。如何使用更加先進靈活的網絡結構,如近兩年來被得到廣泛關注的ViT 模型,同時考慮將傳統紋理特征提取算子與神經網絡進行深層次融合,以提取能更好區分真假人臉的泛化性強、魯棒高的特征信息,以及對檢測模型的輕量化實時處理,解決人臉活體檢測模型在實際應用中可能遇到的問題,仍是需要探索的難點。
(4)當前人臉識別流程大多由人臉檢測、活體檢測與人臉識別三個階段構成,每個階段分開設計,有必要設計三者融合、統一的模型,壓縮模型大小,提升識別速度,減少訓練開發的成本,降低整個人臉識別流程被攻擊的風險。
(5)基于深度學習的人臉活體檢測方法在模型精度方面占據主導地位。然而,受限于深度學習的可解釋性差,很難判斷已有的活體檢測方法是根據什么特征進行真人和假體的鑒別,因此有必要探究活體檢測模型可解釋的問題。可解釋性機制有助于設計更合理、更高效的網絡結構,避免網絡在特定數據集的混淆因子上過擬合。將因果推斷引入深度學習模型,解決模型只學到了相關關系而不是因果關系的問題來探索模型的可解釋性是一個研究熱點。目前并未見將因果推斷技術引入人臉活體檢測領域的相關報道,這方面的研究探索值得期待。
5 結束語
隨著深度學習的飛速發展,人臉活體檢測的研究非常活躍,但同時也存在著很多困難與挑戰。本文從提高檢測模型泛化性出發,分析了目前人臉活體檢測方法在遇到領域外場景時會出現的問題,將對應的解決方法進行分類,并詳細闡述分析了每類方法的主要思想、優點與局限。整理和歸納了當前領域外場景下的人臉活體檢測方法常用的主流數據集,對數據集大小、攻擊方式等特點進行分析和比較。總結了常用的兩類算法性能評價指標,并分析了針對領域外活體檢測提出的三種評價協議及其應用場景。本文對提高人臉活體檢測模型的泛化性未來可能的研究方向進行了分析和展望。相信人臉活體檢測所面臨的問題,必將在理論和實踐的共同發展下,通過學術界和工業界的不斷努力,得到更好的解決,人臉活體檢測的應用也將推動人臉識別技術更廣泛、更深入的發展。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
