隨機集成策略遷移
2022-11-15 16:17:34章宗長
計算機與生活 2022年11期
常 田,章宗長,俞 揚
南京大學 計算機軟件新技術國家重點實驗室,南京210023
深度強化學習(deep reinforcement learning,DRL)在很多有挑戰性的任務中取得了相當大的成功[1-2]。然而,DRL 在訓練過程中需要與環境不斷交互,當面對復雜任務時,算法的訓練需要很長的交互過程,如果對每個任務從頭開始獨立學習,需要大量的時間和數據,這導致DRL 在解決實際問題時效率低下。最近,遷移學習(transfer learning,TL)被用來解決這樣的問題[3]。TL 通過利用從過去相關任務中學到的先驗知識來加速DRL在新任務上的學習。一類常見的遷移強化學習方法是比較源任務和目標任務的相似度。文獻[4]提出了計算兩個馬爾科夫決策過程相似度的方法,根據相似度來遷移價值函數。文獻[5]對馬爾科夫決策過程的相似度進行了擴展,提出根據N步返回值來度量相似度的方法。另一類方法是估計多個源策略在目標任務上的性能,以此選擇合適的源策略進行遷移。文獻[6]將策略遷移建模為多臂賭博機模型,在目標任務上比較源策略的性能,選擇最高者進行遷移。文獻[7]將策略遷移建模為選項學習問題,為每個源策略更新價值和終止概率,然后選擇價值最高的源策略進行遷移。
無論通過什么途徑來評估源策略,此類算法往往無法避免一個共同的問題:對源策略的評估可能不準。尤其是在訓練過程前期,智能體與環境的交互不夠,對源策略的評估存在較大誤差,不能保證評估值最高的策略一定是適合目標任務的源策略。而一旦選擇了不合適的源策略,就會造成負遷移。對此一般的方法是通過ε-貪婪來選擇策略,即以1-ε的概率利用,選擇評估最高的策略,以ε的概率探索,任意選擇一個策略。然而,ε-貪婪在進行探索時選擇的策略是隨機的,這沒有利用除最優策略外其他源策略的評估信息。基于以上問題,本文提出一種隨機集成策略遷移方法(stochastic ensemble policy transfer,SEPT)。方法將策略遷移建模為選項學習問題,通過終止概率對所有源策略進行評價。然后根據評價為它們賦予權值,根據權值集成出教師策略進行遷移。
本文的主要貢獻包括三方面:
(1)提出了一種隨機集成策略遷移方法SEPT,通過在策略庫中生成教師策略來進行遷移;
(2)利用選項學習中的終止概率概念為源策略計算概率權重,和類似的工作相比降低了出現負遷移的可能性;
(3)在不同的實驗環境中驗證SEPT,結果表明SEPT 可以明顯加速強化學習的訓練,并且超過了之前性能最佳的策略遷移方法。
1 背景知識
在強化學習中,智能體與環境不斷交互,目的是學習得到最大回報的動作策略[1]。通常RL以馬爾科夫決策過程(Markov decision process,MDP)為框架,由四元組(S,A,P,R)表示。在每一個離散時刻t中,智能體觀測到狀態st∈S,選擇執行動作at∈A,得到即時獎賞rt~R(st,at)并達到新的環境狀態st+1~P(st,at)。智能體最終尋找一個最優策略π*來最大化期望折扣回報U=,其中γ∈[0,1]是折扣因子。
選項(option)的概念由Sutton 等人提出[8],選項是一種廣義的動作,由初始狀態集I、策略π和終止函數β三元組組成。選項只有在I中包含的狀態下可用,在t時刻執行選項o=<Io,πo,βo>,就表示從πo(·|st)中獲得一個動作at,然后在t+1時刻以βo(st+1)的概率終止。如果不終止,則繼續執行選項內策略提供的動作直到終止。動作價值函數可以擴展到選項上,即選項價值函數Qπ(s,o),它表示在指定的狀態和選項下的期望回報。這個期望回報對應的是從指定狀態開始,執行指定選項直至終止,之后繼續執行策略π的整個過程。
集成學習(ensemble learning)是一類常用的機器學習方法[9]。這類方法構建若干個個體學習器,然后通過一定策略將它們結合,最后獲得一個優于個體學習器的強學習器。
2 策略遷移相關工作
策略遷移問題指給定一組源任務M1,M2,…,MK和對應的專家策略,在目標任務上,學生策略π通過從源策略中遷移知識來幫助學習,其中1 ≤i≤K[10]。
早期的策略遷移工作中往往研究一對一的遷移,即K=1。此類方法需要假設源策略在目標任務上也是接近最優的,而這個假設在復雜場景中不太可能滿足。最近的工作主要研究一對多的策略遷移問題。在這種問題中,每一個源策略可能只在某些時刻對目標任務有效,因此相關工作的研究關鍵在于如何選擇當前時刻最適合于目標任務的策略。Li等人[11]和Yang 等人[7]分別提出了利用選項進行策略遷移的方法CAPS(context aware policy reuse)和PTF(policy transfer framework)。兩種方法都將策略遷移建模為選項學習問題,估計出選項的價值,選擇價值最高的選項對應的源策略進行遷移。然而,選項的價值估計會有誤差,任務場景越復雜價值估計的誤差會越大,直接根據價值進行選擇可能會誤選到不適合目標任務的源策略,造成負遷移。因此,本文提出的SEPT 方法旨在降低選項價值估計誤差帶來的負面影響。
3 隨機集成策略遷移方法
3.1 方法總覽
圖1 為SEPT 算法框架。與PTF 一樣,在SEPT中,智能體用于策略更新的方法不受限制,既可以使用值函數方法,也可以使用策略梯度方法。首先,SEPT 將源策略庫中的每一個策略設置為選項,用神經網絡生成其終止概率。之后通過以下流程進行訓練:智能體與環境進行交互學習策略,交互結束時將狀態轉移四元組(s,a,r,s′)存入回放池里;利用回放池的數據更新源策略對應選項的終止概率網絡;終止概率網絡輸出當前狀態對應的各選項的終止概率,利用終止概率計算每個源策略的概率權重;根據概率權重,將源策略集成為教師策略;教師策略對智能體的策略進行策略蒸餾[12],實現知識遷移,智能體策略完成更新,至此一輪訓練結束,重復執行訓練流程。接下來將從選項終止概率更新、集成教師策略和策略蒸餾與更新三方面具體說明。
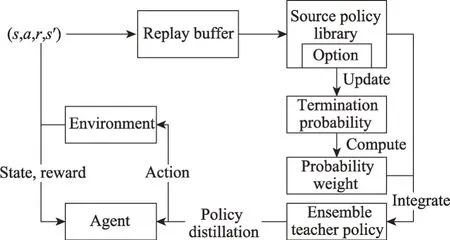
圖1 隨機集成策略遷移框架Fig.1 Framework of stochastic ensemble policy transfer
3.2 選項終止概率更新
在智能體與環境交互過程中,狀態轉移四元組(s,a,r,s′)被存儲到回放池以用來更新選項價值函數和終止概率。對選項進行調用的動作模式是選擇價值最高的選項進行調用,直到基于終止概率終止其調用,然后根據價值重新選擇一個選項。
根據文獻[8],基于這種動作模式從所有選項O中調用選項o的期望回報U*(s′,o)為:
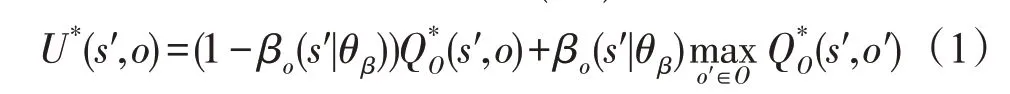
對U求終止概率參數θβ的梯度[13]:
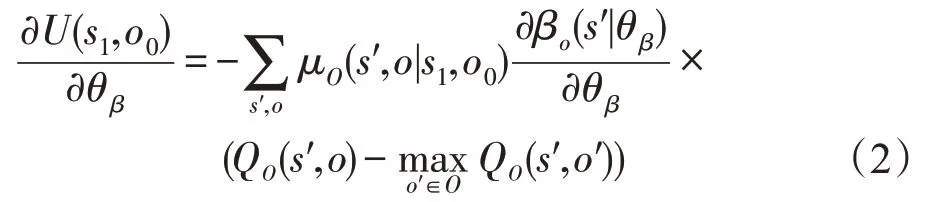
其中,μO(s′,o|s1,o0)為從初始狀態(s1,o0)到(s′,o)的轉移概率,無法直接求出,只能通過采樣估計。根據文獻[11]的討論,此項可以省略。基于式(1)和式(2),下面提出更新選項價值函數QO和終止概率參數θβ的算法,其中αQ為更新QO的學習率,αβ為更新θβ的學習率。
算法1更新QO(s,o)和θβ

3.3 集成教師策略
選擇選項價值最高的選項進行利用的方式在遷移任務中有一定的缺陷。這是因為選項的價值估計依賴于智能體提供的回放池里的信息,而這只包括整個環境信息的一小部分,僅憑這些信息顯然無法對環境有完整的認識。因此,選項價值估計往往存在較大誤差,以至于價值最高的選項對應的策略可能并非最優策略。
為了解決這個問題,提出了集成教師策略的方法。SEPT 并不選擇一個策略進行遷移,而是從策略庫中新生成一個教師策略πT,這個教師策略是各個選項內策略的集成。對于選項o,終止概率βo表示停止調用選項o的概率。顯然,1-βo表示繼續調用選項o的概率,這項數值越高,說明對應的選項相對于其他選項越可靠。本文用ρo來表示選項的可靠程度,ρo=1-βo。根據ρo來計算教師策略中選項o的概率權重可以降低價值估計的方差帶來的負面影響。
接下來,本文使用Softmax來生成各個選項的概率權重Wo,即:

其中,T為溫度參數,溫度越大,得到的概率分布越平滑;溫度越小則得到的概率分布越尖銳。得到教師策略πT后,πT會根據概率權重Wo選擇一個選項o,然后輸出選項內策略πo的動作概率分布。
3.4 策略蒸餾與更新
在得到教師策略輸出的動作概率分布后,通過策略蒸餾[12]的方法向學生策略進行遷移。蒸餾的概念由Hinton等人提出[14],指一種通過讓學生模型模仿教師模型的輸出來進行知識遷移的監督學習方法。在策略蒸餾中,學生策略πs會盡可能減少其與教師策略πT在輸出動作分布上的差別。具體地,設學生策略上采集的狀態序列為軌跡τ,學生策略的梯度為下式:

其中,H為交叉熵,τt為軌跡τ在t時刻的狀態。
在SEPT 中,智能體的策略在通過RL 學習的同時也通過策略蒸餾加速學習。這里采用Schmitt等人提出的方法[15],將策略蒸餾的損失和RL 的損失一同用來更新智能體策略參數θt:

其中,αRL表示RL 的學習率,αT表示策略蒸餾的學習率。在αT的設置上參考了PTF[7]的做法,設置了以訓練輪數為輸入的函數f(t)=0.5+tanh(3-0.001×t)/2作為動態學習率。這樣,在訓練早期,智能體的策略還不完善時,智能體更傾向于學習教師策略;而隨著訓練時間逐漸變長,智能體本身的策略趨近完善,則減小教師策略的影響。
4 實驗與討論
為驗證本文算法性能,本章在同類型工作中常用的兩種環境進行實驗,分別是Gym[16]中的Gridworld和Pinball。本文比較了SEPT 和當前表現最好的遷移強化學習方法PTF的性能,兩者的智能體算法設定為A3C[17]。為了保證公平性,PTF的超參數全部按其論文提供的進行設置。同時也用A3C作為基線來進行對比,以便確認遷移是否有效果。
4.1 Gridworld環境
在Gridworld 實驗里,智能體在柵格世界中隨機選擇一點出發,目標是走到指定的終點。Gridworld是離散環境,智能體的動作空間為上下左右,表示智能體向指定的方向移動一格。狀態空間為智能體坐標與周圍一格距離內墻的分布。在Gridworld中設定了四個不同終點的源任務,在這四個源任務上訓練了四個策略作為源策略庫以供遷移。
一般來說,源任務與目標任務越相似,遷移難度越小。設計了兩組遷移難度不同的場景進行實驗。簡單場景中有一個源任務與目標任務較為相似,即兩者的終點距離很近,遷移難度比較小;困難場景中所有源任務的終點與目標任務都相距較遠,遷移難度比較大。如圖2 和圖3 所示,黑色部分代表墻,四個藍色的點代表源任務的終點,紅色的點代表目標任務終點。

圖2 Gridworld上的簡單場景Fig.2 Simple scenario on Gridworld
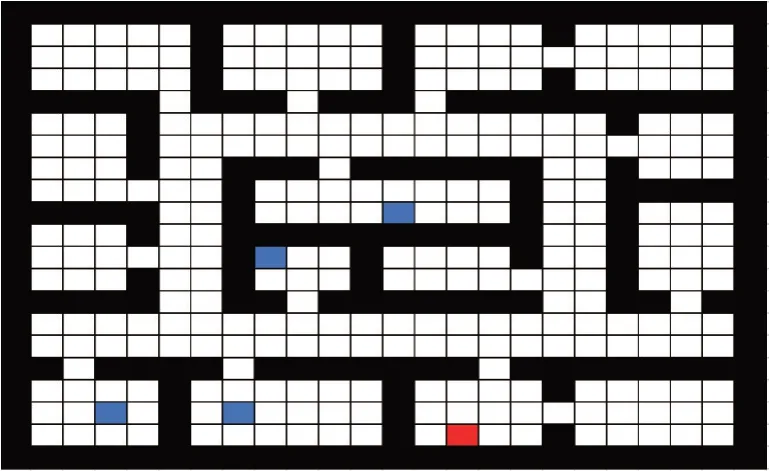
圖3 Gridworld上的困難場景Fig.3 Hard scenario on Gridworld
實驗中,智能體的單輪最大步數為99,回報折扣率γ設置為0.99,選項更新的學習率αβ設置為1×10-3,智能體策略更新學習率αRL設置為3×10-4,生成權重的溫度T設定為1。最后結果為圖4和圖5。

圖4 簡單場景上的折扣回報Fig.4 Discount return on simple scenario
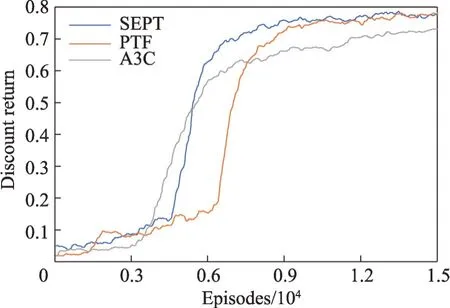
圖5 困難場景上的折扣回報Fig.5 Discount return on hard scenario
4.2 Pinball環境
在Pinball 環境中,智能體控制一個彈球通過一個由各種多邊體障礙物組成的迷宮,到達指定的終點。Pinball是連續環境,彈球的動作空間為水平方向和垂直方向的加速度,狀態空間為彈球的坐標和速度。具體如圖6所示,藍點為彈球,紅點為指定終點。

圖6 Pinball環境Fig.6 Pinball scenario
以左上角、右上角和右下角為終點設置了三個源任務,并訓練策略作為源策略庫以供遷移。實驗中,智能體的單輪最大步數為500,回報折扣率γ設置為0.99,選項更新的學習率αβ設置為1×10-3,智能體策略更新學習率αRL設置為3×10-4,生成權重的溫度T設定為0.25。最后結果為圖7。
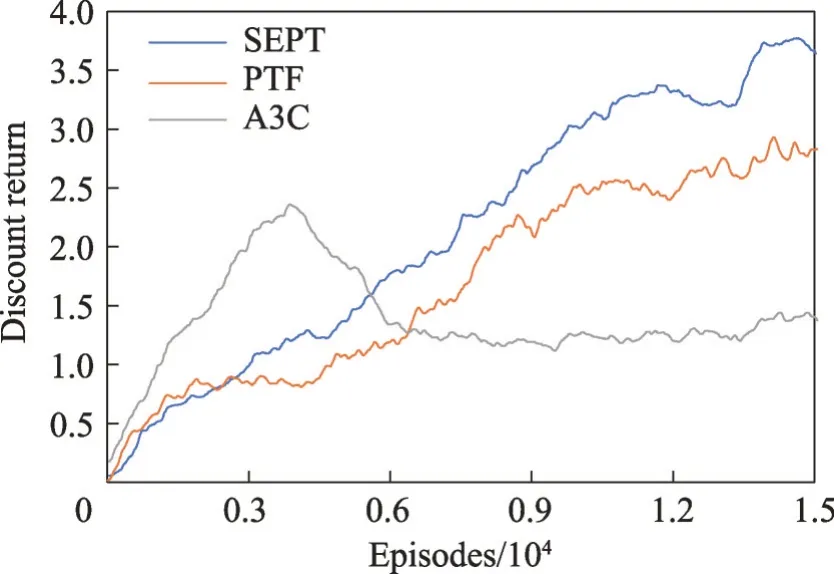
圖7 Pinball場景上的折扣回報Fig.7 Discount return on Pinball scenario
從結果來看,比起其他方法,SEPT性能上有明顯提升。這是因為彈球環境比較復雜且狀態空間是連續的,選項價值估計會有比較大的誤差,智能體會經常選中不合適的源策略,導致遷移效果較小甚至出現負遷移。而SEPT的教師策略受影響較小,能夠持續進行正向遷移。
5 結束語
本文提出了一種隨機集成策略遷移方法SEPT。這種遷移強化學習方法將源策略設置為選項并對選項進行持續更新。之后根據選項的終止概率生成每個選項內策略對應的概率權重,集成出教師策略,利用教師策略來指導學生策略進行學習。實驗表明SEPT 的性能超過了已有的策略遷移方法,能明顯加速智能體的訓練。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學學報(自然科學版)(2021年1期)2021-06-09 08:43:00
中國生殖健康(2020年6期)2020-02-01 06:28:50
中國生殖健康(2019年11期)2019-01-07 01:28:02
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
文理導航·科普童話(2016年7期)2017-02-04 15:09:20
小天使·四年級語數英綜合(2016年11期)2016-11-29 22:37:30
