基于BERT-CRF的領域詞向量生成研究
2022-11-16 02:25:24郭振東李成城趙佳鵬
計算機工程與應用 2022年21期
郭振東,林 民,李成城,趙佳鵬
1.內蒙古師范大學 計算機科學技術學院,呼和浩特 010022
2.中國科學院大學 網絡空間安全學院,北京 100089
3.中國科學院 信息工程研究所,北京 100089
隨著深度學習等人工智能技術的發展,詞向量(word embedding)模型[1]由于其出色的語義表示能力在自然語言處理(natural language processing,NLP)領域越來越被重視,并被廣泛地應用在機器翻譯、信息抽取、自動問答等任務上,詞向量結合神經網絡模型成為深度學習在解決各類NLP任務的主流方法[2]。
BERT(bidirectional encoder representations from transformers,BERT)[3]是一種基于Transformer[4]雙向編碼器表示的詞向量預訓練模型,其旨在通過聯合調節所有層中詞匯的上下文來預訓練深度雙向表示,并刷新了11個NLP任務的當前最優效果[3]。然而,現有中文BERT預訓練模型大都以字或句子為向量表示單位,對于一些以粗粒度的領域專有詞匯(如領域術語、短語、實體詞)為處理單位的文本分析任務(如特定領域文本的主題分析任務等)并不適用,而原始BERT 模型無法直接獲取符合領域需求的高質量詞級向量;如何在BERT預訓練字向量基礎上,進一步進行fine-tuning獲得包含特定領域文本上下文語義信息的高質量領域詞向量表示,是目前研究的難點和熱點問題。
針對上述問題,本文提出了一種領域動態詞向量的生成方法。核心思想是利用少量領域專有詞匯,有監督的fine-tuning BERT 的網絡參數,使得BERT 在學習領域字的表示時,能夠感知到粗粒度的領域詞匯為一個語義整體,進而優化領域字的表示,從而緩解原始BERT無法有效表示粗粒度的領域專有詞匯的問題。
該方法首先利用少量的領域分詞標注數據,再以分詞為優化目標,采用BERT-CRF 的網絡結構fine-tuning BERT的網絡參數。再把經過fine-tuning的字向量采用不同的策略進行融合,生成粗粒度的領域專有詞匯的向量表示。實驗結果表明本文所提方法不僅有助于提高領域分詞準確率,而且達到了僅需少量領域標注數據,就能生成領域高質量詞向量表示的目的。
1 相關工作
在詞向量表示模型的發展中,傳統的Word2Vec[1]和GloVe[5]等模型的文本表征能力都受限于模型本身的結構[3],詞與向量是一對一的關系,無法有效解決一詞多義問題,靜態的詞向量表示無法針對特定任務做動態優化。后續提出的ELMo[6]和OpenAI GPT[7]等為單向的語言模型,每次僅能關注某個單向標記,因此特征表示能力有很大的局限性;Google研究員Jacob Devlin等受完形填空的啟發,提出了基于Transformer 的雙向編碼器表示[3]模型,其通過“遮罩語言模型”(masked language model,MLM)和“下個句子預測”任務解決單向約束和一詞多義等問題,是一種深層雙向Transformer 預訓練模型。為進一步促進中文信息處理的研究發展,哈工大訊飛聯合實驗室崔一鳴等人于2019年發布了基于全詞遮罩(whole word masking)技術的中文預訓練模型BERT-wwm,在多個中文數據集上取得了當前中文預訓練模型的最佳水平[8]。2020年,蘇劍林等提出了基于詞顆粒度的中文預訓練模型WoBERT[9],目前開源WoBERT是Base 版本,在哈工大開源的RoBERTa-wwm-ext 基礎上繼續進行預訓練,預訓練任務為MLM。初始化階段,將每個詞用BERT的Tokenizer切分為字,然后用字向量的平均作為詞向量的初始化。
近年來,隨著深度學習等技術發展,基于長短期記憶網絡(long short-term memory,LSTM)、雙向LSTM、CRF[10]以及注意力機制的中文分詞研究成為主流[11],但這些分詞算法對領域未登錄詞等識別效果差強人意,Jieba 等通用的中文分詞器應用到特定領域時,不能準確識別出領域專有名詞,并且難以構建覆蓋全面的領域詞典。因此,如何將文本特征表示能力更強的中文BERT-wwm 預訓練模型結合領域分詞任務來提升領域分詞準確率,并利用BERT 的fine-tuning 模型對特定領域任務動態優化BERT 字向量,以及怎樣融合BERT 字向量能得到高質量領域詞向量成為本文研究的重點。
針對以上問題,本文提出一種基于BERT-CRF的領域詞向量生成方法。在利用大規模自然語言文本數據進行預訓練的BERT模型基礎上,并結合能充分考慮標簽依存關系的CRF 模型[12],構建BERT-CRF 領域分詞器,使用少量的《軟件工程》樣本數據集對BERT網絡參數進行fine-tuning,可獲取符合領域文本上下文特征的中文字向量。對fine-tuning 后BERT 的12 層隱層字向量采用不同的融合策略進行實驗,獲取符合本領域更高質量的詞向量。
2 基于BERT-CRF的領域詞向量學習
基于BERT-CRF 的領域詞向量學習模型如圖1 所示。fine-tuning是指將預訓練模型遷移到新的模型上來進行二次訓練,本文方法可分為二次fine-tuning和字向量融合兩階段。在二次fine-tuning階段,將領域文本傳入BERT-CRF 分詞器,以領域分詞作為BERT 的下游任務,在訓練BERT-CRF領域分詞器的同時,對BERT字向量進行二次fine-tuning 訓練,使得BERT 字向量能夠感知到粗粒度的領域詞匯整體語義,返回包含領域詞整體語義的字向量和分詞標簽;字向量融合階段將包含領域詞整體語義的相關字向量按“全字求和平均”和“首尾字求和平均”兩種策略進行融合實驗。兩種融合策略說明如表1所示。
2.1 BERT模型
BERT 模型是一種深層雙向Transformer 編碼器的預訓練模型[3],其中,Transformer 是僅基于Attention機制的結構,用來處理序列模型相關問題。它沿用了Encoder-Decoder結構,但摒棄了傳統的循環神經網絡和卷積神經網絡,利用多頭注意力機制結合線性變換來提取特征信息,提升并行訓練速度的同時,也提升了模型準確性,而BERT 是利用了Transformer 的Encoder 部分進行預訓練,Transformer的Encoder結構如圖2所示。
在圖2 中,輸入為字向量與位置向量之和;位置向量首先由公式(1)[13]、(2)[13]獲取詞在句子中的絕對位置信息表示,再由三角函數公式(3)[13]、(4)[13]得到詞之間的相對位置信息表示,并通過注意力機制進行處理,注意力機制原理如公式(5)[14]所示。
其中,Q、K、V分別為查詢矩陣、關鍵詞矩陣,值矩陣、Q矩陣與K矩陣的維度為dk。而多頭注意力機制是通過多個不同的線性變換對Q、K、V進行投影,最后將不同的Attention結果拼接起來,如公式(6)和式(7)[14]。
使用多頭注意力處理求和后得到嵌入向量,并進行殘差求和及歸一化解決深度神經網絡中梯度消失問題,將結果通過一層前饋神經網絡并進行殘差求和及歸一化,得到生成的隱層向量。
而BERT是基于fine-tuning的方法,它沿用了Transformer的多頭注意力機制,能夠捕獲更為寬泛的文本語義特征,并結合遮罩語言模型任務和下一句預測任務進行預訓練,BERT的輸入形式如圖3所示。
其中,中文BERT 的輸入表示為詞向量、句向量和位置向量三部分之和,每個輸入序列的第一個標記[CLS]是一個特殊分類嵌入,用于分類任務中該句子序列的表示;句向量是用來區分句子序列的標記;位置向量包含模型學習到的位置信息。
2.2 CRF模型
在標簽分類任務中,條件隨機場模型相較于Softmax,能夠充分考慮標簽之間的依存關系,更適用于分詞任務,因此現有的分詞模型大都結合了CRF模型,它的模型結構如圖4所示[15]。
假定組成句子的字序列長度為n,且字序列為X=(x1,x2,…,xn-1,xn) ,其對應的預測標簽序列為Y=(y1,y2,…,yn-1,yn),預測序列標簽總得分如公式(8)[14]所示:
其中,A表示標簽之間的轉移分數,Pi,yi表示每個字對應的預測標簽yi的分數。
然后對所有的可能序列進行歸一化,得到最大概率正確的序列,如公式(9)[14]所示:
2.3 基于BERT-CRF的領域詞向量生成方法
基于BERT-CRF 的領域詞向量生成方法是以領域分詞為基礎,將fine-tuning的領域字向量融合得到領域詞向量,模型結構如圖5所示。
由圖5 可以看出,基于BERT-CRF 的領域詞向量生成方法就是將訓練數據轉換成BERT 的輸入表示并傳入到BERT-CRF 模型中,用分詞作為有監督信號,finetuning 得到基于BERT 的特征字向量表示,融合富含信息量的首尾字向量得到領域詞向量。
3 實驗與分析
3.1 實驗數據集介紹
本文所使用的語料為《軟件工程》(后稱SED)領域文本,版本為《軟件工程——理論與實踐》(第2 版),通過人工方式將全書錄為電子版文檔,并手工標注領域詞典,詞典共計2 405 個領域詞匯。首先將領域文本按句切分,確保切分后的句子長度不超過BERT的最大輸入長度512;然后使用Jieba分詞工具結合領域詞典處理數據集,并對分詞結果加上標簽,標簽采用B、M、E、S格式標注,其中B 表示非單字詞的詞頭標簽,M 表示三字詞及以上的詞中標簽,E表示非單字詞的詞尾標簽,S為單字詞標簽,例如:“軟件”的標簽為BE,“軟件工程”的標簽為BMME,“類”的標簽為S。語料以“字 標簽”格式存儲,句子之間由空行切分,語料規模共5 303 句,并將語料文本按7∶2∶1的比例劃分為訓練集、測試集和驗證集,語料統計如表2所示。

表2 SED領域語料數據統計Table 2 Corpus data statistics in SED field
3.2 實驗設置
(1)實驗模型的參數設置:訓練輸入序列最大長度為256,模型訓練的batch_size為24,模型的學習率為3×10-5,CRF的學習率1×10-3,為防止過擬合,添加了Dropout層,Dropout 率為0.1,在BERT 模型配置文件config.json中添加參數output_hidden_states 和output_attentions 并設置值為True,即獲取BERT的12個隱層向量以及注意力權重。
(2)環境設置:本文所提出的模型使用PyTorch 搭建,所使用的中文BERT是哈工大訊飛聯合實驗室發布中文BERT-wwm版本,該模型采用12層的Transformer,隱層維度大小為768,multi-head為12,模型的所有參數為110×106。本文將fine-tuning模型的12層隱層字向量和分詞器預測標簽同時作為領域分詞器模型的返回參數,并根據模型分詞標簽,對字向量采用多種融合策略得到領域詞匯的向量表示。
(3)評價指標:在對BERT-CRF 領域分詞器實驗效果進行評估時,對四種標簽都采用了精確率(Precision,P)、召回率(Recall,R)、F1值(F1-score)作為評價指標。
3.3 實驗結果分析
為了驗證本文所提軟件工程領域詞向量生成方法的有效性,本文做了詳細的對比實驗分別對生成的領域詞向量以及軟件工程領域分詞器的性能進行評估。
3.3.1 領域詞向量的性能分析
為了更好地評估本文生成領域詞向量的性能,本文分別采用聚類方法和詞語相似度計算方法做了詳細的對比分析。此外,本文也采用了具體的樣例對比分析本文所提方法的有效性。
(1)融合策略分析
本文將SED 領域句子“軟件開發模型有很多種,主要有瀑布模型、快速原型模型、增量模型、螺旋模型、噴泉模型、基于組件的開發模型、統一軟件開發過程模型以及敏捷模型與極限編程等。”傳入到原始BERT 模型和fine-tuning 模型,獲取BERT 的12 層隱層字向量,將字向量采用不同策略進行融合得到領域詞向量,對其中的“軟件開發模型”和“增量模型”兩個領域詞向量進行相似度分析,如圖6所示。
在圖6中,“全字求和平均”表示采用詞中所有字向量求和平均得到領域詞向量表示,即“軟件開發模型”的詞向量表示是組成這個詞的所有字向量求和平均的結果。“首尾字求和平均”表示采用首尾字向量求和平均得到領域詞向量表示,即“軟件開發模型”的詞向量表示是首字“軟”與尾字“型”的字向量求和平均的結果,“增量模型”同理,再將兩個詞向量表示計算余弦相似度,即為圖中結果;實驗表明,采用最后一層Transformer的隱層結果作為字向量表示所得到的結果均不理想;采用倒數第二層Transformer的隱層向量融合得到領域詞向量表示最優,fine-tuning模型獲得的詞向量相對于原始BERT直接獲得詞向量的質量更高,并且基于“首尾字求和平均”獲得的詞向量避免了詞中非關鍵字向量的影響,更具泛化性,獲得的詞向量質量高于“全字求和平均”的方式獲得的詞向量。本文后續實驗均將倒數第二層字向量通過“首尾字求和平均”融合得到詞向量進行研究。
(2)聚類分析
本文將學習到的領域詞向量采用k-means聚類,聚類中心數為6,對領域詞向量聚類結果進行分析,分析結果如表3所示。

表3 詞向量k-means聚類性能對比Table 3 Comparison of performance of word vector k-means clustering單位:%
由表3可以得知,fine-tuning模型的詞向量k-means聚類在精確率、召回率、F1值三方面均比Word2Vec以及原始BERT融合的詞向量有一定的提升,詞向量質量更高。
為了進一步驗證在SED領域內,基于BERT-CRF領域分詞器作為下游任務獲得的詞向量表示質量高于原始BERT獲得的詞向量表示,采用“首尾字求和平均”策略融合倒數第二層Transformer的隱層向量獲得領域詞向量,使用主成分分析算法(PCA)對領域詞向量進行降維,并進行詞向量可視化展示對比,如圖7所示。
從圖7分析知,fine-tuning后的BERT模型獲取的詞向量的分布更合理,包含相近語義的詞簇分布緊湊,聚類相對明顯,在向量空間中,具有相同語義的詞之間的距離也是相近的,例如,“字段”“索引”“觸發器”等詞都屬于數據庫中的領域專有詞,所以它們聚為一類的概率更大。
(3)詞語相似度計算的對比分析
由于基于“上下句”輸入的BERT-CRF 領域分詞器模型能夠捕獲更廣泛的文本信息,其獲得的詞向量表示包含的語義信息理應更為廣泛,其詞向量質量也應該高于單句的詞向量,本文對其進行了實驗驗證,選取了150個SED領域知識點,并分別計算它們與“增量模型”的相似度,按相似度遠近,前12個領域詞在向量空間中的分布如圖8所示。按相似度排序結果如表4所示。

表4 與“增量模型”語義相似度排序對比Table 4 Comparison with ranking of semantic similarity of“incremental model”
在上下句輸入的fine-tuning模型中,與“增量模型”相似度較高的詞包含了“rup模型”,即“統一軟件開發過程模型”,在一定程度上解決了“同義詞”的問題,并且包含的相關詞更多,證明上下句輸入的fine-tuning模型能夠捕獲更多的語義信息,獲得的詞向量質量更高,并將fine-tuning模型的注意力機制可視化驗證了本文結論如圖9所示。
圖9中例句在領域分詞器的分詞結果為“軟件特點包括:軟件是種邏輯實體,具有抽象性。”相對于原始BERT,fine-tuning模型的“抽”字注意力權重在“抽”“象”“性”三字上更大。原始BERT 在大規模語料下進行預訓練具有一定的先驗知識[16],但大規模的語料致使“抽”字的注意力權重分布寬泛;fine-tuning 模型在原始BERT基礎上,結合CRF模型捕捉領域分詞標簽之間的依存關系,因而能感知到粗粒度的“抽象性”為一個語義整體,其領域詞的平均多頭注意力權重提升了4.96%。
(4)“一詞多義”現象的樣例分析
對于BERT模型詞向量如何解決一詞多義的研究,本文用“蘋果”一詞進行實驗測試,實驗樣例如表5所示。

表5 一詞多義實驗樣例Table 5 Example of polysemy experiment
獲取fine-tuning 模型“蘋果”的詞向量,并用樣例1與其余各樣例中的“蘋果”進行詞向量的語義相似度計算,結果表6所示。
由表6分析可知,“蘋果”的詞嵌入對于每個句子都是不同的,這也是BERT 同Word2Vec 最重要的區別之一;一詞多義問題在一定程度上得到了解決,對于主題分析等任務的研究,也具有重要的意義。

表6 “蘋果”一詞多義結果對比Table 6 Result comparison of polysemy of word“apple”
3.3.2 領域分詞器的性能分析
(1)分詞性能分析
在SED 領域數據集上,對BERT-CRF 領域分詞器模型進行訓練。BERT 的一種輸入形式是“[CLS]Sentence[SEP]”,另一種輸入形式是“[CLS]Sentence1[SEP]Sentence2[SEP]”,將單句數據集進行“兩兩合并”,即每兩句采用第二種輸入格式進行處理,這樣做的目的是為了涵蓋SED領域文本的所有上下句關系,對兩種輸入方式進行實驗測試,并對訓練后的領域分詞器模型進行評估。實驗結果如表7所示。

表7 BERT-CRF領域分詞性能對比Table 7 Performance comparison of word segmentation in field of BERT-CRF單位:%
通過對表7 的分析,原始BERT 具有一定的先驗知識[16],但將其直接應用在領域任務效果不佳;fine-tuning的BERT 模型能明顯提升模型效果,其中,基于“上下句”輸入訓練得到的領域分詞器模型的精確率、召回率,F1值都有所提升,相對于“單句輸入”,其包含了語料中的上下文關系,訓練得到的分詞器模型質量更高。
(2)分詞樣例分析
然而對于領域分詞和通用分詞的標準不同,需要進一步對本文所涉及的領域分詞器分詞結果與數據集不一致的詞進行對比分析,如表8所示。
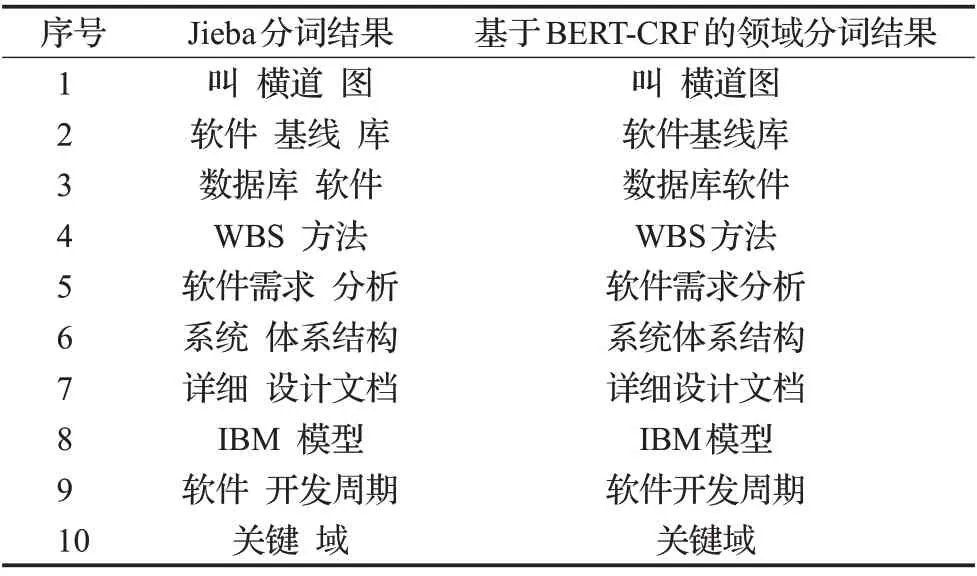
表8 Jieba分詞器與BERT-CRF領域分詞器分詞結果對比Table 8 Comparison of word segmentation results between Jieba tokenizer and BERT-CRF domain-specific tokenizer
通過對表8 的分析,基于BERT-CRF 的領域分詞器的分詞粒度更大,更符合SED領域分詞標準。對于一些未登錄詞,如橫道圖、關鍵域、軟件開發周期等,相較于Jieba分詞器,本文所提出的方法更有效地識別這些領域未登錄詞,對一些數據集標記不合理的詞也能在BERT預訓練模型的基礎上減少這些噪聲詞對分詞器模型的干擾。
4 總結與展望
本文采用BERT-CRF領域分詞器模型,基于該模型提出了一種領域詞向量的生成方法。該模型使用少量領域樣本二次訓練能獲得包含領域詞整體語義BERT字向量,根據字向量的分詞標簽采用“首尾字求和平均”策略對BERT 領域字向量進行融合獲得高質量領域詞向量表示。實驗表明,這種基于BERT-CRF的領域詞向量生成方法能獲得比原始BERT 字向量更高質量的領域詞向量,下一步將考慮將獲得的BERT領域詞向量應用在主題分析等任務上進一步提升主題表示性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
現代語文(2016年21期)2016-05-25 13:13:44
小學教學參考(2015年20期)2016-01-15 08:44:38
大連民族大學學報(2015年2期)2015-02-27 08:28:11
