基于TF-IDF算法的文本量化方法及作者識別應用
2022-11-19 09:15:40李楚
現代信息科技 2022年19期
李楚
(東北大學秦皇島分校,河北 秦皇島 066099)
0 引 言
作者識別問題于1887年首次由Mendenhall 提出,它的主要目標就是根據匿名文本的內容識別出匿名文本最可能的作者。作者識別任務可以被看作是多類別單標簽的分類問題,每個可能的作者身份代表一個標簽,最終目標是為每一個匿名文本匹配到最可能的作者標簽[1]。因此,許多文本分類技術已經被運用到作者識別任務中。
文本以一種非結構化或半結構化的形式存在,它沒有確定的形式,機器也無法直接理解其語義。為了將數據挖掘技術用于探索獲取文本信息,通常需要對文本進行預處理,再以統計的方法將其轉變為機器可以識別處理的數值型結構。
根據經典的詞袋模型(Bag-of-words)理念,文本可以看作是由若干個詞匯構成的集合。一個作者的寫作風格可以由該作者經常使用的文體特征表達,如詞頻、單詞長度、一個句子中動詞出現的頻率等等[2]。其中,詞頻用于表達文本內容十分常見。在一個文本中,有一部分詞匯攜帶了大量信息,能很好地表達文本的內容,同樣還有一部分詞匯,如沒有實際語義的停用詞和攜帶信息量極少的詞匯,不僅無法表達文本的內容,還會增加文本分類或作者識別過程的時間成本,并對最終的分類或識別結果造成不利影響,因此識別文中真正重要的詞匯十分重要[3]。
在作者識別任務中,文本預處理方法分為基于文本和基于實例兩種類型[4]。在基于文本的方法中需要將同一個作者的所有文本進行合并,而在基于實例的方法中每一個文本都是一個獨立的對象并對應一個作者標簽。在大部分研究中,采用相似度或距離度量識別匿名文本的作者時,一般以基于文本的方法預處理文本,而采用機器學習分類器識別作者時,則一般以基于實例的方法預處理文本。識別文本作者通常分為基于分類的方法和基于相似性的方法[5]。基于分類的作者識別方法主要利用文本訓練集的樣本實例訓練機器學習分類器,然后將訓練好的分類器用于預測匿名文本的作者標簽,而基于相似性的作者識別方法則是通過計算匿名文本和所有已知作者文本的相似度來判定匿名文本最可能的作者[6]。
文章基于詞頻-逆文檔頻率(TF-IDF)算法提出了一個新的文本量化方法用于將文本轉變為向量,還提出了一種混合距離度量用于識別匿名文本的作者身份。提出的方法的性能評估在英文、中文兩種不同類型的文本數據集上進行,分別使用TF-IDF 算法和提出的文本量化方法量化文本,然后運用提出的混合距離度量和七種常見的分類算法包括五種經典的機器學習分類器、閔可夫斯基距離度量和余弦相似度識別匿名文本的作者。
文章結構為:第一部分是對相關研究的綜述;第二部分介紹了一些文本處理的相關概念并提出了新的文本向量化方法和混合距離度量;第三部分引入了大量實驗對提出的算法進行評估;最后是文章的總結及未來研究工作的展望。
1 相關研究
目前針對作者識別任務的解決方法主要是在選擇文本特征并量化文本后,將其用于訓練機器學習分類器和計算文本之間的相似度、距離度量或關聯程度。因此,文本特征的選擇和量化受到了廣泛關注。許多學者旨在通過提取文本最重要的特征來提高分類算法的準確性并減少識別過程耗費的時間成本。比如BinSaeedan 和Alramlawi 基于二進制粒子群優化算法(BPSO)和卡方優化算法提出了CSBPSO 特征選擇算法用于提高識別阿拉伯語言電子郵件的作者的準確性,在實驗中分別考慮了動態和靜態特征,結果表明利用CS-BPSO 算法提取動態特征較好的提高了各個分類器的識別準確性[7]。Ramezani 提出了一種語言獨立的作者識別方法,該方法不需要任何的自然語言處理技術,基于改進的特征權值算法來計算匿名文本與已知作者文本的相似度并將與匿名文本相似度最高的已知文本的作者判定為匿名文本最可能的作者[6]。Bhatti 等人提出了一種專門針對烏爾都語的文本分類和文本相似度衡量的方法,該方法利用TFIDF 算法提取文本特征、利用chi-2 進一步選擇特征,然后利用線性判別分析(LDA)將文本向量映射到二維空間以達到較好的特征降維效果[8]。考慮到Word2vec 模型無法確定特征在文本中的重要性程度,Wang 和Zhu 將TF-IDF 算法與Word2vec 模型結合形成了加權的Word2vec 分類模型。在預處理過程中,他們還引入了一個新的特征提取算法來對StringToWordVector 算法進行改進并將其用于降低文本特征維度[9]等等,這些研究都取得了大量成果。
雖然目前存在許多的特征選擇與文本量化算法,且其中大部分都考慮了特征在目標文本中出現的頻率以及在其他文本中的普遍性兩個因素。然而文本集中特征分布的密集度這個因素卻被忽略了,考慮到這個因素,文章基于TF-IDF 算法提出了一個新的文本量化方法。另外,為了評估 閔可夫斯基距離度量和余弦相似度在作者識別任務中識別匿名文本作者的共同作用,還提出了一個混合距離度量用于計算兩個文本之間的距離并將與匿名文本距離最近的已知文本的作者判定為匿名文本最可能的作者。
2 提出的方法
2.1 向量空間模型
向量空間模型在文本處理、自動索引、信息檢索等領域中被廣泛使用。它旨在將文本由文字形式轉變為向量空間中的數值向量形式,一般采用向量之間的余弦夾角衡量文本之間的相似度。在向量空間模型中,一個文本被看作是由若干個不同的術語構成的集合,每個術語都代表文本的一個維度且可以根據其在文本中的重要性大小進行權值化。假設文本Dj由n 個不同的術語構成,則文本Dj可以表示成一個n 維向量,即Dj=(wj1,wj2,…,wjn),其中wji代表第i 個術語在文本Dj中的權值[10,11]。
2.2 原始TF-IDF 算法
TF-IDF 算法是一種用于文本特征數值化的統計計算方法,用于評估特征對于文本的重要性程度。根據TF-IDF 算法,一個在目標文本中頻繁出現但在所有文本中普遍性很小的特征對目標文本是十分重要的。如式(1)所示,特征i 在文本j 中的TF-IDF 權值表示為[12,13]:
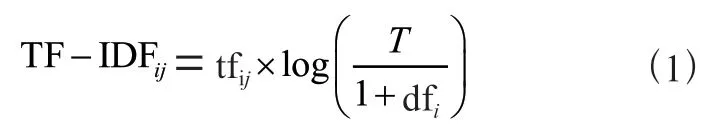
其中T 表示總文本數量,tfij表示特征i 在文本j 中出現的頻率,dfi表示含有特征i 的文本數量。TF-IDFij的值越大,則表明特征i 在文本j 中越重要。
2.3 余弦相似度
余弦相似度用于描述兩個文本向量之間的相似程度大小,如式(2)所示,任意兩個文本向量Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)的余弦相似度表示為[14,15]:
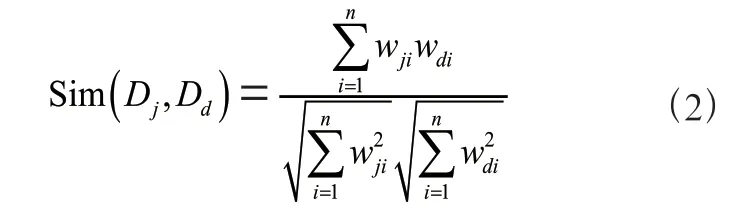
Sim(Dj,Dd)的值越大,則表明文本向量Dj和Dd越相似。
2.4 閔可夫斯基距離度量
閔可夫斯基距離度量是計算兩個文本向量之間距離大小的一種度量,如式(3)所示,任意兩個文本向量Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)的閔可夫斯基距離表示為[16]:
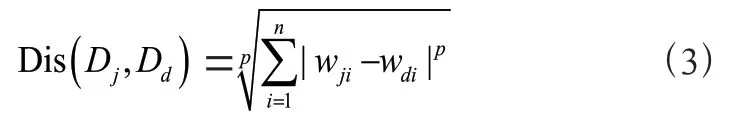
p 為可變的正整數:
p=1 時,Dis(Dj,Dd)稱為曼哈頓距離;
p=2 時,Dis(Dj,Dd)稱為歐氏距離;
p →∞時,Dis(Dj,Dd)稱為切比雪夫距離。
Dis(Dj,Dd)越小,則表明文本向量Dj和Dd越相似。
2.5 提出的方法
2.5.1 新TF-IDF 算法
為了更好地量化文本特征,在TF-IDF 算法的基礎上進行調整得到了一個新的TF-IDF 量化方法,如式(4)所示:
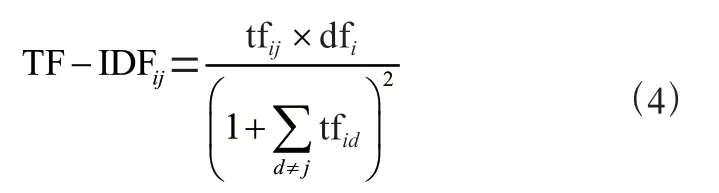
其中tfij表示特征i 在文本j 中出現的頻率,dfi表示含有特征i 的文本數量,表示特征i 在除文本j 以外的其他文本中出現的頻率之和。
新TF-IDF 量化算法在原始TF-IDF 量化算法的基礎上增加了幾點考慮,可根據如下案例表達:
(1)對于文本j 的兩個特征a 和b,若a 和b 在文本j 中出現的頻率相等,即tfaj=tfbj,且在所有文本中含有a 和b 的文本數量也相等,即dfa=dfb。那么根據原始TF-IDF 算法可得到a 和b 在文本j 中的權重值相等,即tf-idfaj=tf-idfbj。若繼續考慮a 和b 在其他文本中出現的頻率大小,當a 在其他文本中出現的總頻率大于b 在其他文本中出現的總頻率時,即客觀看來相比于a,b 對文本j 更加重要,因此在文本j 中賦予b 更大的權重值較為合理,根據新的TFIDF 算法可得到這個結果,即tf-idfaj≤tf-idfbj。
(2)對于文本j 的兩個特征a 和b,若a 和b 在文本j中出現的頻率相等,即tfaj=tfbj,a 和b 在其他文本中出現的總頻率也相等,即,而所有文本中包含a 的文本數量大于包含b 的文本數量,即dfa>dfb。根據原始TFIDF 算法可得到a 和b 在文本j 中的權重大小關系有tf-idfaj<tf-idfbj。而新的TF-IDF 算法則考慮特征在文本集中分布的密集度因素,一個在目標文本以及許多其他文本中分布密集的特征對任意一個文本的表達能力都很弱。由于包含a 的文本子集(不含文本j)中a 分布的平均密度小于包含b 的文本子集(不含文本j)中b 的平均密度,因此可以認為在文本j 中a 更重要,根據新的TF-IDF 算法可以得到這個結果,即tf-idfaj>tf-idfbj。
相比于原始TF-IDF 量化算法,新算法考慮的因素更加全面,如特征在其他文本中的頻率和在文本集中分布的密集度,其旨在通過更好的量化特征以達到提高分類準確率的目標。
2.5.2 混合距離度量
若Dj=(wj1,wj2,…,wjn)和Dd=(wd1,wd2,…,wdn)為兩個文本向量,如式(5)所示,文本j 和文本d 的混合距離定義為Dis(Dj, Dd):
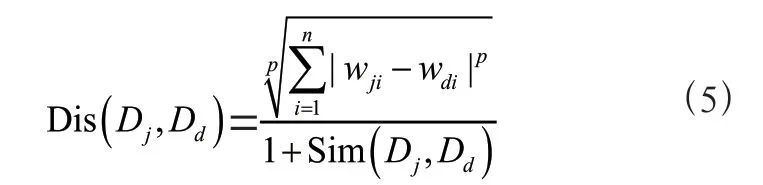
其中n 為特征個數,p 為可變的正整數,Sim(Dj,Dd)為文本向量Dj和Dd之間的余弦相似度。
提出的混合距離度量是閔可夫斯基距離度量和余弦相似度的結合體,它用于評估閔可夫斯基距離度量和余弦相似度在作者識別任務中的共同作用。Dis(Dj,Dd)的值越小,則表明文本向量Dj和Dd越相似。
3 實驗結果
3.1 數據描述和實驗方法
實驗部分使用了英文和中文兩種類型的文本數據集。兩個數據集均包含10部由不同著名文學作家撰寫的長篇小說,每部小說中均抽取了25個部分,其中80%的部分(20個部分)作為訓練集樣本,20%的部分(5 個部分)作為測試集樣本。
實驗運用提出的文本量化算法和原始TF-IDF 算法量化文本,運用提出的混合距離度量、余弦相似度、閔可夫斯基距離度量和五種機器學習分類器包括支持向量機(SVM)、隨機森林(RF)、樸素貝葉斯(NB)、K 近鄰(KNN)、神經網絡(NN)共八種分類算法識別文本的作者,最后根據測試集樣本的作者識別準確率評估所提出的算法的性能。如圖1 所示,在運用五種機器學習分類器的過程中需要根據文本量化算法將數據集樣本轉變為向量形式,每一個文本向量有對應的作者標簽,然后訓練集的實例會用于機器學習模型的訓練,最終在測試集上計算每個模型的作者識別準確率。如圖2 所示,在運用提出的混合距離度量、余弦相似度以及閔可夫斯基距離度量時,需要將訓練集中來自同一本書的所有部分融合成一個文本,每個文本對應一個作者標簽,而測試集中每個部分對應一個作者標簽,數據集的所有文本需根據量化算法轉變為向量形式,然后通過計算各測試集文本向量與所有訓練集文本向量的距離或相似度大小來預測測試集文本的作者,最終可得到測試集文本作者的識別準確率。
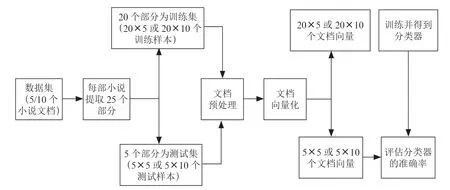
圖1 機器學習分類器識別文本作者的過程
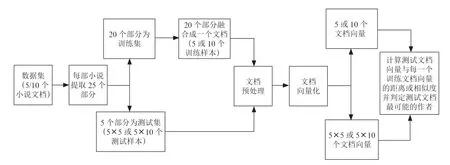
圖2 相似度及距離度量識別文本作者的過程
3.2 數據預處理
文本在量化之前還需要進行預處理。英文中單詞與單詞之間存在空格,且大部分英語單詞都有實際含義。中文以字為基本單位,由若干個字構成有意義的漢字字串,且字與字或者詞與詞之間沒有分隔,只有句子與句子之間存在標點符號。中英文文本的預處理過程包括以下四個步驟:
(1)文本標記的處理。最初的文本通常含有表情符、鏈接等噪音字符,它們通常無法對后續的作者識別提供直接有用的幫助還可能對識別結果造成不利影響,因此需要剔除這些標記。
(2)文本分詞的處理。英文文本根據單詞與單詞之間的空格進行劃分。中文文本則基于字符串匹配的方法進行劃分,該方法依賴于字典工具,根據字典中已經記錄的術語來判斷文本內相鄰的字是否構成一個詞語。
(3)去除停用詞。經過分詞后,文本中還存在一些沒有具體含義的停用詞,比如:而且、在、的,等等。停用詞普遍出現在各類文本中,它們無法提供有用的信息,還會增加文本量化的工作量,因此需要剔除文本中的停用詞。
(4)特征提取。剔除停用詞后,文本特征維度仍然很大,為了減少文本量化和文本作者識別的時間成本,需要進一步降低文本維度。實驗根據詞頻來提取文本特征,獨立的每個部分選擇詞頻最大的50 個特征,而經過合并形成的文本選擇詞頻最大的200 個特征。
3.3 分類算法和性能評估方法
3.3.1 分類算法
(1)支持向量機(SVM)。支持向量機是一種建立在特征空間上的使得類和類之間間隔最大的超平面,實驗運用引入核函數的支持向量機對非線性的文本進行識別[17],使用線性核函數進行非線性判別。
(2)隨機森林(RF)。隨機森林模型由多個決策樹模型構建而成,基于所有決策樹的分類結果,根據多數表決準則得到隨機森林模型最終的分類結果[18]。實驗使用100 棵樹的隨機森林模型,采用Gini 系數作為樹的分裂標準。
(3)樸素貝葉斯(NB)。樸素貝葉斯是一種基于貝葉斯定理和特征條件獨立性假設的分類算法[19]。實驗使用高斯貝葉斯分類器識別文本作者。
(4)K 近鄰(KNN)。K 近鄰是一種經典的分類算法,根據與目標對象最相近的K 個樣本的類別標簽來標記目標對象[20]。實驗指定K=5 以及閔可夫斯基距離作為度量。
(5)神經網絡(NN)。神經網絡是模擬生物神經網絡進行信息處理的一種數學模型,它由一個輸入、一個輸出和若干個隱藏層組成[21]。實驗訓練一個隱藏層數為100 的神經網絡模型,使用relu 激活函數,并設置最大迭代次數為1 000。
除了運用以上機器學習分類器識別文本的作者,實驗還使用提出的混合距離度量、余弦相似度以及閔可夫斯基距離度量識別文本的作者,與測試文本相似度最大或距離最小的訓練文本的作者被判定為該測試文本的作者。
3.3.2 性能評估方法
實驗根據分類結果的準確率(Accuracy)來評估提出的方法的性能,準確率指所有文本中被正確預測標簽的文本的占比,如式(6)和表1 所示,準確率表示為:
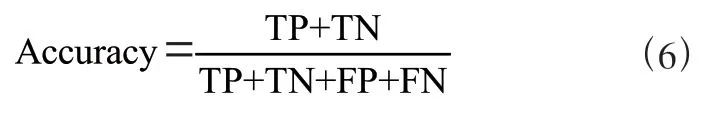

表1 式(6)中各指標含義
3.4 英文數據集實驗結果
如表2 所列,在5 個和10 個作者標簽的數據集上,與原始TF-IDF 算法相比,采用提出的量化方法量化文本使測試集中文本作者識別的平均準確率分別提高了10.7%和8.2%。其中支持向量機、K 近鄰、閔可夫斯基距離度量(p=1和p=2)和混合距離度量(p=1 和p=2)的準確率明顯提高,支持向量機模型的準確率分別提高了4%和22%,K 近鄰模型的準確率分別提高了36%和18%,閔可夫斯基距離(p=1)的準確率分別提高了24%和32%,閔可夫斯基距離度量(p=2)的準確率分別提高了32%和30%,混合距離度量(p=1)的準確率分別提高了20%和12%,混合距離度量(p=2)的準確率分別提高了16%和8%。根據準確率的方差可以發現,使用提出的量化算法使得分類算法的準確性能更加穩定,各分類算法的準確率波動范圍相對更小。
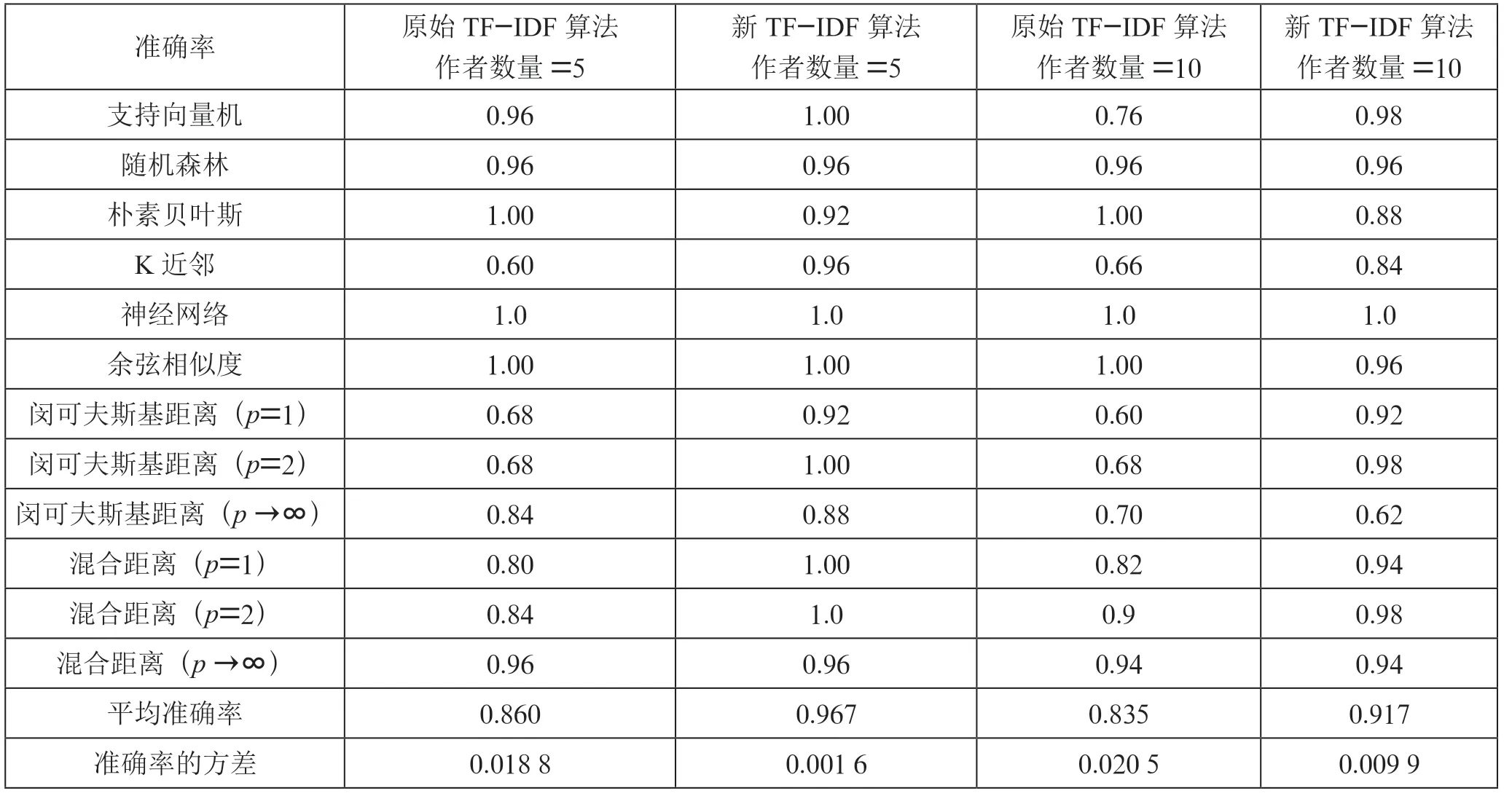
表2 英文數據集上作者識別的準確率
此外,與閔可夫斯基距離度量相比,混合距離度量的準確性能也更好。根據原始TF-IDF 算法量化文本時,在p=1 的情況下準確率分別高出12%和22%,在p=2 的情況下分別高出16%和22%,在p →∞的情況下分別高出12%和24%。根據提出的量化算法量化文本時,在p=1 的情況下準確率分別高出8%和2%,在p →∞的情況下分別高出8%和32%。
通過實驗還可以發現,在采用樸素貝葉斯和余弦相似度算法識別文本作者時,采用原始TF-IDF 算法量化文本會有更好的識別效果。
3.5 中文數據集實驗結果
如表3 所列,在5 個和10 個作者標簽的數據集上,與原始TF-IDF 算法相比,采用提出的量化方法量化文本使測試集中文本作者識別的平均準確率分別提高了7.7%和2.5%。其中支持向量機、K 近鄰和閔可夫斯基距離度量(p=1 和p=2)的準確率明顯提高,支持向量機模型的準確率分別提高了24%和52%,K 近鄰模型的準確率分別提高了24%和16%,閔可夫斯基距離(p=1)的準確率分別提高了44%和22%,閔可夫斯基距離度量(p=2)的準確率分別提高了16%和8%。與英文數據集相似,根據準確率的方差可以發現,使用提出的量化算法使得分類算法的準確性能更加穩定,各分類算法的準確率波動范圍相對更小,說明提出的量化方法普遍適用性更好。
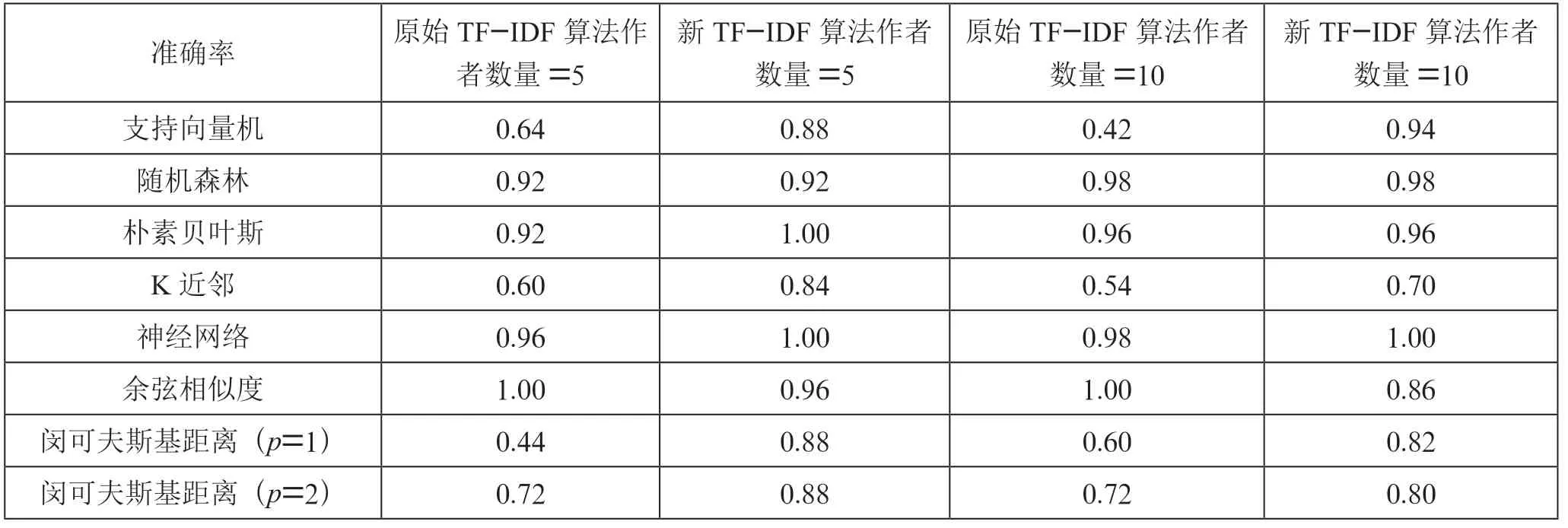
表3 中文數據集上作者識別的準確率
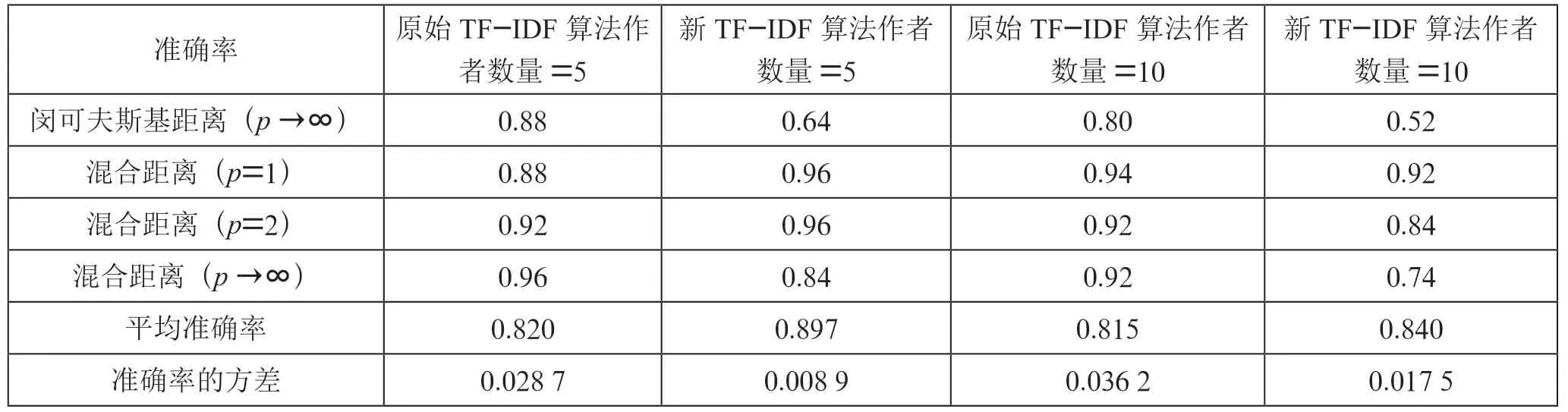
續表
此外,與閔可夫斯基距離度量相比,混合距離度量的準確性能也更好。根據原始TF-IDF 算法量化文本時,在p=1的情況下準確率分別高出44%和34%,在p=2 的情況下分別高出20%和20%,在p →∞的情況下分別高出8%和12%。根據提出的量化算法量化文本時,在p=1 的情況下準確率分別高出8%和10%,在p=2 的情況下分別高出8%和4%,在p →∞的情況下分別高出20%和22%。
通過實驗還可以發現,在采用余弦相似度、閔可夫斯基距離度量(p→∞)和混合距離度量(p→∞)識別文本作者時,采用原始TF-IDF 算法量化文本會有更好的識別效果。
4 結 論
在作者識別任務中,文本內容的量化十分關鍵,它會直接影響作者識別的準確率。為了更好的量化文本特征,提出了基于改進TF-IDF 算法的文本量化方法,還提出了混合距離度量用于評估閔可夫斯基距離度量和余弦相似度識別文本作者的共同作用。
相比于原始TF-IDF 算法,提出的量化方法還考慮了特征在其他文本中的頻率和在文本集中分布的密集度兩個因素。運用提出的量化算法量化文本明顯提高了支持向量機、K 近鄰、閔可夫斯基距離度量(p=1 和p=2)和混合距離度量(p=1 和p=2)在英文數據集上的作者識別準確率。對于中文數據集,運用提出的量化算法量化文本明顯提高了支持向量機、K 近鄰和閔可夫斯基距離度量(p=1和p=2)的作者識別準確率。此外,在中英文兩種數據集上,相比于閔可夫斯基距離度量,混合距離度量的準確性能也更好。
在實驗過程中,根據提出的量化算法量化文本所耗的時間成本更高,主要是因為提出的量化算法考慮的因素更多,形式更加復雜。另外,預處理之后的文本特征維度仍然很大,直接影響了作者識別過程的效率。因此未來工作將著重研究特征降維的相關技術,如何提高大規模作者標簽的作者識別準確率也值得進一步關注。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
甘肅教育(2020年8期)2020-06-11 06:10:02
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
制造技術與機床(2019年10期)2019-10-26 02:48:08
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年18期)2018-11-14 01:48:06
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
