面向用戶生成內容的多粒度知識組織研究
2022-11-23 12:03:50王忠義鄭鑫王珂瑩
情報學報 2022年10期
王忠義,鄭鑫,王珂瑩
(華中師范大學信息管理學院,武漢 430079)
1 引言
在大數據時代,網絡信息資源已經成為了大數據的重要來源之一。作為網絡信息資源中的重要組成部分,用戶生成內容(user generated content,UGC)也相應地成為一種重要的大數據資源。UGC是指網絡用戶通過各種社交媒體平臺所發布的信息,包含了大量人們在工作、生活中總結出的經驗、訣竅等知識內容,成為人們獲取知識的重要來源之一。與傳統信息資源不同,UGC以碎片化的形式廣泛地存在于各個社交媒體平臺。盡管這種碎片化的知識可以幫助人們精準且快捷地獲取知識,但就人類的認知規律而言,不利于人們對知識的理解和有效使用以及構建相應的知識體系。從總體上看,人們的知識獲取行為符合從局部到整體、從低層概念到高層概念逐步構建知識體系的認知規律。處在不同認知階段的用戶具有不同粒度的知識需求,處在高級認知階段的領域專家用戶往往需要細粒度的知識來優化已有的知識結構,而處在低級認知階段的普通用戶則更需要構建較粗粒度的知識體系。因此,對碎片化的UGC知識進行從點到面、從局部到整體的多粒度組織十分必要。
2 相關研究
2.1 大數據環境下的UGC研究
UGC這一概念在2005年由O'Reilly學者首次提出[1],隨后在國內外受到了學者們的廣泛關注。總體來說,可以將有關UGC的研究劃分為基礎理論研究、應用研究以及“碎片化”研究等幾個方面。UGC基礎理論研究包括內涵研究、生成動機研究、傳播機制研究、質量研究、內容分析研究以及法律問題研究等;UGC應用研究主要涵蓋了教育、地理、電商、民主政治、公共媒體、圖書館、博物館等領域;UGC“碎片化”研究可以分為對UGC碎片化現象和內容的研究兩個部分,新聞傳播領域的學者主要針對“碎片化”現象進行研究[2],計算機科學、圖書檔案和信息科學等領域的學者主要針對“碎片化”內容進行相關研究,以知識圖譜和知識地圖的形式結構發現和揭示碎片化知識間的關聯[3-5]。總體來說,針對UGC碎片化的研究還相對較少,研究的方向較為單一。
2.2 基于知識元的知識組織研究
知識組織(knowledge organization)的概念最早由美國分類法專家布利斯在1929年提出[6]。在知識組織的過程中,組織單元的選擇至關重要。知識元是不可分割的最小知識單元。溫有奎[7]和姜永常等[8]通過系統論證,認為知識元應該是進行知識組織的基本單位,姜永常等[8]還具體給出了基于知識元的知識組織流程,包括知識元抽取、知識分類與標引、知識元庫和知識倉庫構建四個部分[7];陳果等[9-10]提出知識元可以是細粒度的具備語義完整性的知識組織單位[9],并且界定了具有一定領域性特征資源中知識元的概念[10];李銳等[11]以學科已有的層次結構為基礎建立知識模塊,并將知識模塊進一步劃分為多個子模塊,將子模塊看作一個知識元來建立知識組織體系,該方法有一定的參考價值,但對知識元的描述不夠準確且適用范圍有限。還有部分學者提出了要對不同粒度的知識進行多粒度組織。徐緒堪等[12]將客體知識通過分類和聚類的方式分為不同粒度的知識,結合用戶需求對多粒度的知識進行組織;馮儒佳等[13]對科技文獻進行了多粒度知識組織建模,對科技文獻資源和知識元分別進行了粗、中、細粒度的劃分,并建立了不同粒度資源和知識元之間的映射,實現了基于科技文獻的多粒度知識組織和集成。
2.3 面向UGC的知識組織研究
當前面向UGC的知識組織研究相對較少,根據組織對象的不同,主要可以劃分為兩個部分:面向UGC文獻的知識組織和面向UGC內容的知識組織。
面向UGC文獻的知識組織主要是借助相關的詞表或構建相應的領域本體知識庫對UGC文獻進行知識組織。丁文姚等[14]結合FOAF(friend-of-afriend)詞表對UGC用戶信息進行組織。么媛媛等[15]基于本體理論構建UGC、用戶和發布平臺三個元概念及元關系構建了一套UGC元數據標準模板。胡華[16]提出了結合UGC信息源中半結構化的維基百科信息和UGC信息源中非結構化的文本資源信息的本體構建方法體系。陳果[9]在構建領域知識庫的基礎上,結合知識庫中的語義關聯以及UGC資源中的共現相似度生成知識元鏈接,對UGC文檔中的知識元進行了標識并建立了和文檔資源的鏈接。唐曉波等[17]基于詞性規則和中心詞進行概念和概念短語的抽取,應用互信息和左右信息熵的統計方法進行概念過濾,建立了基于UGC信息源的本體概念抽取模式。鄭姝雅等[18]提出了一套自動構建UGC本體的方法,完成了領域UGC本體的自動構建。
面向UGC內容的知識組織主要從主題角度出發進行知識組織,需要借助各種主題模型來確定文檔-主題以及主題-詞之間的概率關系。趙華[19]基于主題模型構建了UGC主題層次體系,結合用戶建模和社區發現建立三維度關聯并對UGC進行信息組織。金碧漪[20]對來自大眾普遍使用的社交媒體上的多種疾病數據進行采集分析,提煉健康主題,提取特征詞匯及特征詞間關系,最終構建了消費者健康知識圖譜。陳曉威[21]以話題為基本知識單元,借助LDA(latent Dirichlet allocation)主題模型生成社會化問答平臺“文檔-主題”概率矩陣,并通過二元圖投影構建知識網絡模型。
綜上,通過對相關研究進行梳理和分析后發現,目前圖書情報學領域關于UGC的相關研究較少,特別是在UGC內容組織方面,還缺乏較為系統和成熟的研究。已有的UGC知識組織研究多側重于從概念層次或利用主題模型來對UGC中的知識進行組織,前者對知識的描述形式過于單一,粒度過粗,后者在海量的碎片化UGC內容中存在很大的主題漂移風險;且已有的面向UGC的知識組織研究中較少考慮人的認知規律,難以提供個性化服務。為此,如何在已有組織方法的基礎上探尋新的符合UGC特點和用戶認知規律的知識組織方法成為UGC知識組織研究的一種發展趨勢。
3 面向UGC的多粒度知識組織模型構建
在上述分析的基礎上,本課題組提出了基于碎片化UGC的多粒度知識組織模型[22]。如圖1所示,該模型自下而上分為三個模塊:碎片化UGC知識元抽取、碎片化UGC多粒度關聯、碎片化UGC多粒度索引。①碎片化UGC知識元抽取。先借助知識要素抽取算法,從碎片化UGC中抽取組成知識元的知識要素,接著借助改進的K-means方法對知識要素進行聚類,得到知識元的屬性特征,最后根據知識元描述模型生成面向碎片化UGC的知識元。②碎片化UGC多粒度關聯。先借助概念匹配方法發現知識元之間的等同關聯,然后利用多階關聯分析方法發現知識元之間的非等同關聯。③碎片化UGC多粒度索引。先基于RDF(resource description framework)描述框架建立面向UGC的細粒度的知識元索引,然后在此基礎上生成粗粒度的“概念→知識元”索引和概念索引,通過多粒度索引可以為UGC用戶提供多粒度的知識檢索服務。接下來,本文將詳細論述各部分的具體實現過程。

圖1 碎片化UGC多粒度知識組織模型[22]
3.1 UGC知識元抽取
知識元的抽取是知識組織的基礎,為從碎片化的UGC中抽取出能夠完整表達知識內容的最小單元,本課題組結合UGC文本的特性,基于知識元抽取的相關理論提出了一種面向碎片化UGC的知識元抽取方法[23],具體的抽取流程如圖2所示。
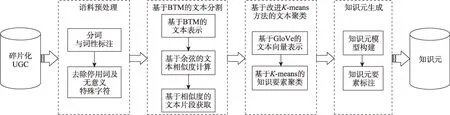
圖2 碎片化UGC知識元抽取流程[23]
(1)語料預處理。此階段主要任務是對語料庫中的UGC文本進行分詞和停用詞處理。UGC文本用詞隨意,因此包含很多無意義的特殊字符,如表情的轉換字符、錯詞等,需要去除。
(2)基 于BTM(balise transmission module)的文本分割。先根據Gibbs采樣算法構建BTM模型;接著由BTM模型推導出UGC文本的主題分布[24],即文本的主題向量;最后由主題向量的余弦相似度計算文本之間的相似度。對于相似度達到閾值m且與線索詞所在語句相鄰的文本,將其合并為一個文本片段,即知識要素的具體內容;若未達到閾值m,則中止相關文本片段搜索,文本分割完成。
(3)基于改進K-means方法的文本聚類。為了克服傳統TextRank方法存在的不足,本文選取中文維基百科數據作為GloVe(global vectors)詞向量訓練的語料生成GloVe詞向量,基于GloVe詞向量[25]對文本片段進行向量化表示。將文本片段的GloVe向量作為K-means輸入值,通過計算余弦相似度完成聚類中心初始化,然后進行知識要素聚類并測試不同的K值以獲取最佳聚類個數。
(4)知識元生成。知識元生成包括兩個步驟:知識元模型構建和知識元要素標注。在知識元模型構建中,本文定義了一個四元組來對知識元進行描述,即<id,標識詞,屬性,知識要素>。知識元要素標注主要是基于知識元模型,對從碎片化UGC中識別的知識要素進行標注,進而完成知識元的構建。
3.2 碎片化UGC的多粒度關聯構建
為實現碎片化UGC的多粒度關聯構建,本文先借助概念匹配方法構建知識元間等同關系關聯,然后借助多階關聯分析方法構建知識元間非等同關系關聯,最終形成碎片化UGC的多粒度關聯體系。
3.2.1 知識元等同關系關聯
當兩個知識元之間具有相同或相近的含義時,判定這兩個知識元之間具有等同關系的關聯。本文借助概念匹配的方式識別知識元之間的等同關系,通過對兩個知識元中所包含概念進行相似度計算來判斷。具體來說,本文借助已有的知識組織體系,將其中的等同和相近概念作為語料庫,對知識元標識詞進行概念匹配,若兩個知識元標識詞均匹配到同一概念,則判定這兩個知識元之間存在等同關系。在完成等同關系關聯后,對抽取后的UGC知識元描述模型加以擴展,即為KS=(id,標識詞,屬性,知識要素,概念關聯集),概念關聯集為上述操作后所形成的概念網絡,具體可描述為概念關聯集=[(c1,c2,s1),(c1,c3,s2),…],其中c1、c2、c3為概念,s1、s2為關聯,(c1,c2,s1)意為c1和c2以s1關系相關聯。然后進行知識元間等同關聯的構建。具體來說,是對UGC中存在等同關系的知識元建立等同關聯。相應地,知識元模型中的知識要素和屬性共享,概念集中的標識詞可互相替換。例如,設知識元A=(id1,標識詞c,屬性a,知識要素kn1,概念關聯集=[(c,c1,s1),(c,c2,s2)]),知識元B=(id2,標識詞c′,屬 性b,知 識 要 素kn2,概 念 關 聯 集=[(c′,c3,s3)]),如果標識詞c和標識詞c′概念匹配為等同關系,那么知識元A將具有知識要素kn2和屬性b,并在其概念關聯集中添加(c,c3,s3)。同理,對于知識元B而言,其也將具有知識要素kn1和屬性a,并在其概念關聯集中添加(c′,c1,s1)和(c′,c2,s2)。知識元A和知識元B的關聯如圖3所示。
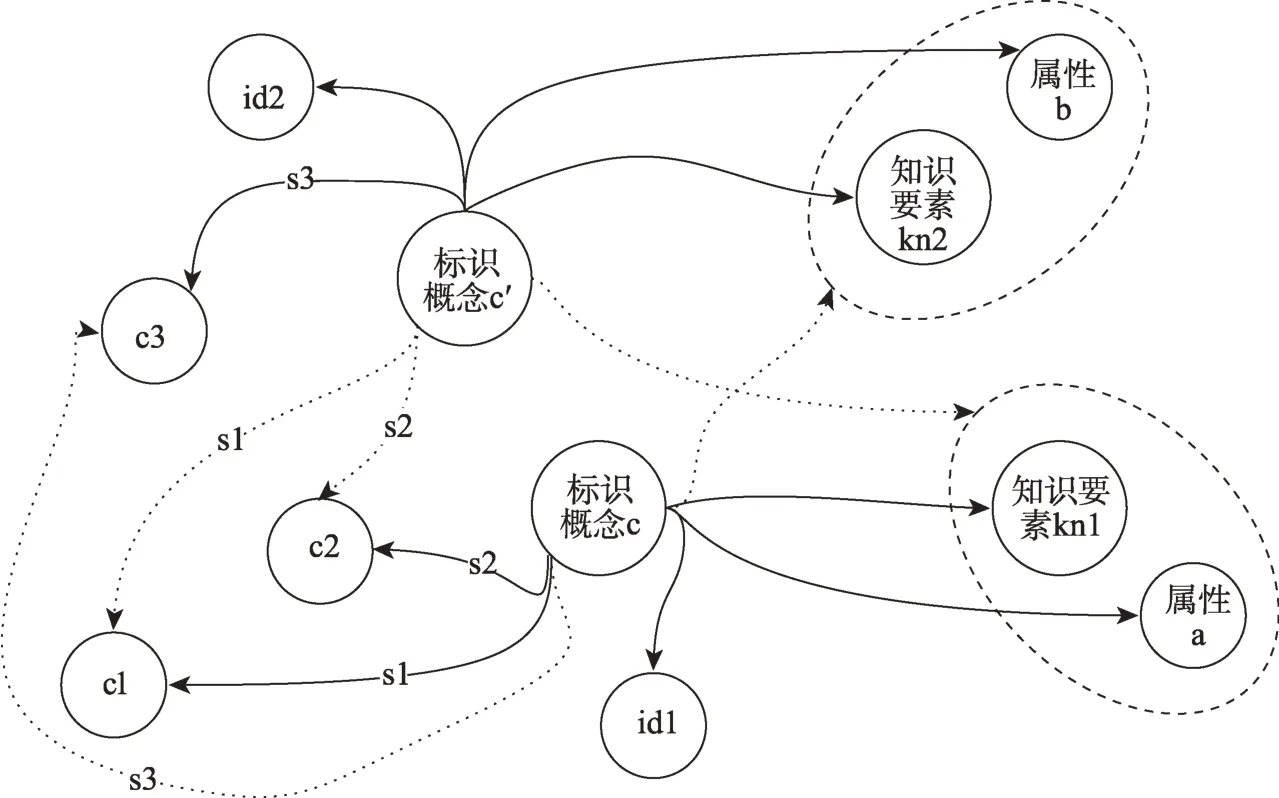
圖3 UGC知識元等同關聯示例
3.2.2 知識元非等同關系關聯
當兩個UGC知識元之間存在關聯但不滿足概念匹配的條件時,即判斷這兩個知識元之間存在非等同關系。本文中對非等同關系的判斷借助于多階關聯分析的方式,該方法主要包括知識元標識詞對提取、二階知識發現、三階知識發現和關聯強度計算等。知識元標識詞對提取的主要任務是依據非相關知識元的知識表示模型,從非相關知識元中抽取出標識詞,構建主題詞對。二階和三階知識發現的主要功能是挖掘出非相關知識元之間可能存在的各種潛在關聯關系(圖4)。二階(實線部分)和三階(虛線部分)知識發現流程為:①以非相關知識元a為起始知識單元,發現所有與知識元a相關聯的中間知識元b;②將中間知識元b和目標非相關知識元c的標識詞組成主題詞對進行共現匹配,若匹配結果不為空,則記錄知識元b和c之間的共現頻次;若匹配結果為空,則說明知識元b和c之間不存在關聯,返回,繼續以中間知識元b為起始點,發現所有與知識元b存在共現關系的中間知識元d;③將中間知識元d和目標知識元c的標識詞組成主題詞對進行共現匹配,若匹配結果不為空,則記錄知識元d和c之間的共現頻次;若為空,則說明知識元d和c之間不存在關聯,終止整個循環;④依據二階和三階關聯發現的結果,構建起始知識元a和目標知識元c之間的鏈接,借助相關推理規則或公式分析出非相關知識元a和c之間的關聯類型。
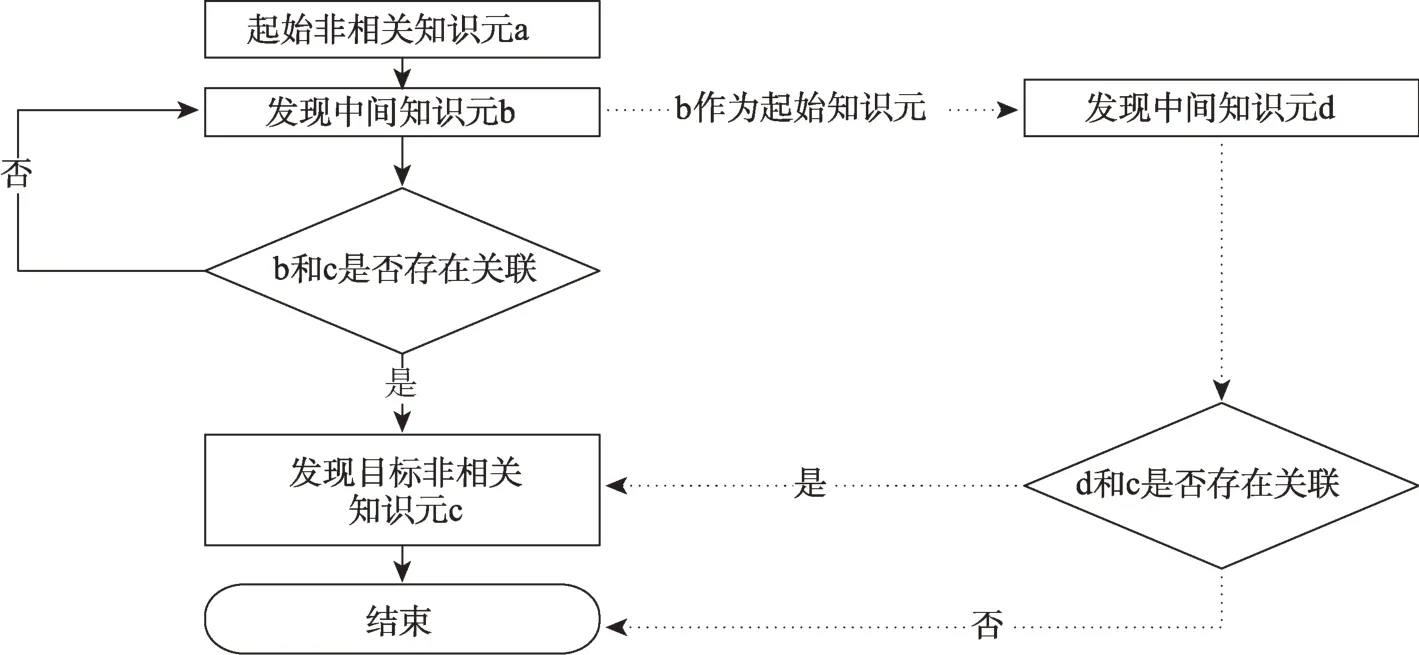
圖4 多階關聯分析流程
關聯強度計算的主要功能是基于非相關知識元之間的共現關系,計算兩個非相關知識元之間的相關強度,即,
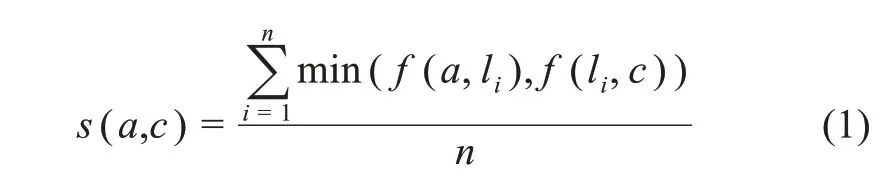
當兩個非相關知識元的相關性程度低于閾值時,舍棄;當兩個非相關知識元的相關性程度超過一定的閾值時,在它們之間建立關聯關系,從而實現非等同關系的發現。其中,n為中間知識元的個數,n=1,表示二階知識發現,n=2,表示三階知識發現;li為中間知識元;f(x,y)表示知識元x和y的直接關聯度,其計算方法為
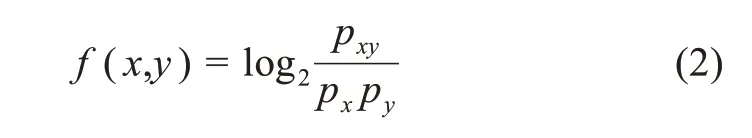
其中,pxy為標識詞x和y在各種粒度大小的知識元中共現的概率;px、py分別表示標識詞x和y出現的概率。pxy的計算方法為
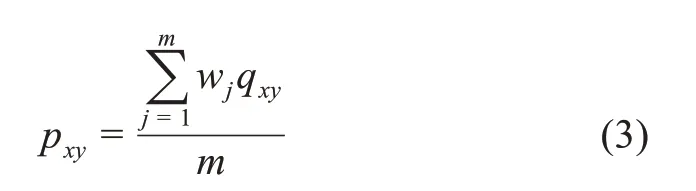
其中,m為知識元粒度劃分的類別個數;qxy為標識詞x和y在相同粒度大小的知識元中共現的概率。
3.3 碎片化UGC多粒度索引
為實現對碎片化UGC建立語義層面的多粒度索引,本文依據語義索引模式提出了面向碎片化UGC的多粒度索引方式,如圖5所示。首先,以UGC知識元描述模型為基礎構建細粒度的知識元索引,以多粒度關聯為基礎構建粗粒度的概念-知識元索引和概念索引,三者結合構成面向碎片化UGC的多粒度語義索引模式;其次,用戶在輸入檢索詞表達檢索需求后,先對檢索詞進行基本處理,然后在知識元索引中搜尋相關知識元內容,再根據概念-知識元索引獲取命中知識元的對應概念,接著根據概念索引完成知識元概念層的定位;最后,返回命中知識元和其知識元概念層級結構,呈現詳細知識元語義信息,且在此基礎上用戶可點擊知識元結構中的概念描述集和知識元關系關聯圖,將以在三種語義索引中搜尋的方式返回檢索結果,實現不同粒度知識元間的相互跳轉,從而在語義層面上深入擴展用戶檢索需求。
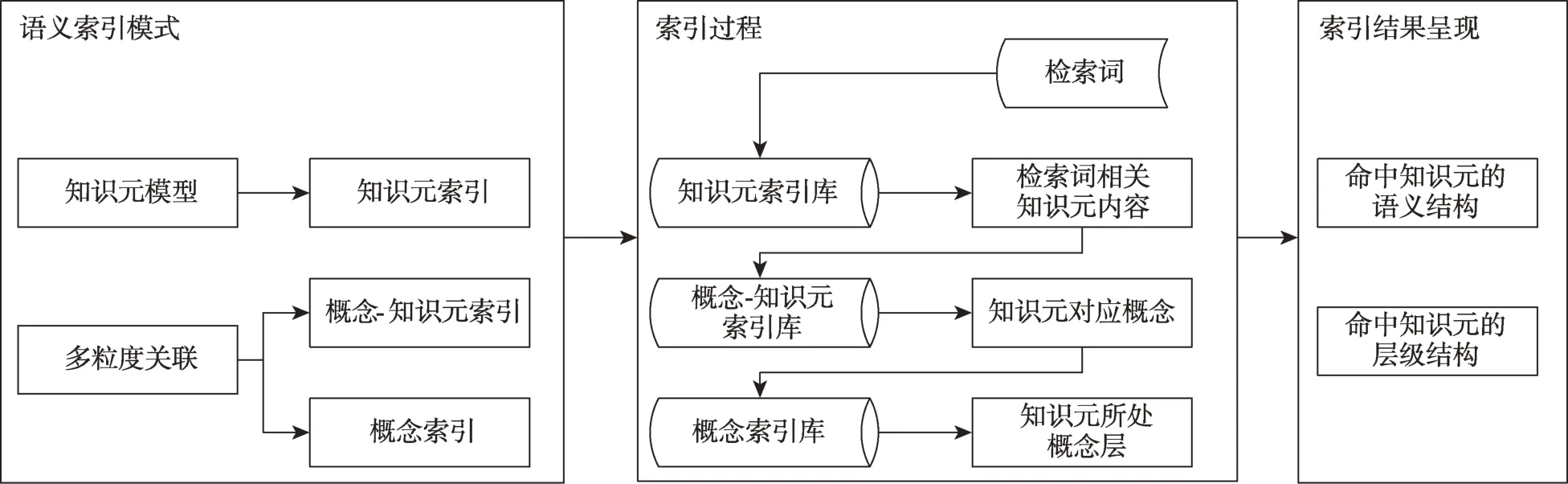
圖5 碎片化UGC多粒度索引
3.3.1 細粒度的知識元索引
知識元是UGC的基本知識單元,是細粒度的知識構件,建立知識元索引將滿足對細粒度UGC知識的檢索需求。UGC知識元描述模型及其擴展概念關聯集是構建知識元索引的基礎,RDF描述框架則為具體的索引實現提供描述方式。本文選擇以RDF為描述框架,依據UGC知識元描述模型對知識元建立索引,如圖6所示。

圖6 知識元索引
具體來說,UGC知識元模型表示為五元組,即(id,標識詞,屬性,知識要素,概念關聯集),id、標識詞、知識要素和屬性都可以直接表示為(主體,謂詞,客體)的三元組形式,其中屬性描述的是知識要素的特征,因此,其三元組形式為(知識元,屬性,知識要素)。概念關聯集是知識要素中的概念及其關聯的集合,因此,其三元組中的謂詞為概念關聯集類型,客體為概念關聯集,概念關聯集中又包含概念關聯所轉換的三元組,比如,若知識元G的概念關聯集為[(c,c1,s1),(c,c2,s2)],則概念關聯集所轉換的三元組為(知識元,概念關聯集,[(c,c1,s1),(c,c2,s2)])。綜上,基于RDF描述框架對UGC知識元完成三元組描述。
UGC知識元轉換為基于RDF的三元組描述方式后,就能夠根據主體、謂詞和客體建立知識元索引。一個UGC知識元可轉換為多個三元組,三元組屬性中含有知識元中的某個特征項,將所有主體作為一個虛擬文檔索引單位建立倒排文檔,將主體里的內容作為索引對象,謂詞和客體以同樣的方式建立索引。知識元索引除了對知識元模型參數建立索引之外,還需要對知識元的直接關聯知識元建立索引,例如,若知識元K1與知識元K2之間存在關聯s,則有三元組(K1,s,K2),建立索引時K1與K2為知識元唯一標識符。
3.3.2 粗粒度的概念索引
知識元索引能夠對UGC知識元進行三元組檢索,檢索知識元的各項屬性和特征,并且能夠索引與知識元直接關聯的其他知識元。但其從單個知識元出發,對知識元關聯的特征標引只考慮了直接關聯,對整體知識元關聯結構的標引不充分。為了提升UGC多粒度關聯標引的效率,本文提出了構建粗粒度的概念索引來解決這一問題。概念索引是UGC知識元在概念層的關聯索引。概念索引具體分為概念-知識元索引和概念索引兩部分,如圖7所示。

圖7 概念索引
概念-知識元索引所標引的是一個概念與多個知識元之間的關系,即多個具有相同概念含義的知識元與概念之間的關系。概念-知識元索引提供兩個方面的檢索服務,一是搜尋某一概念下的所有知識元,二是由某個知識元查詢其所屬概念,從而可以獲取與知識元相關的其他知識元,既可能包含直接關聯知識元,也可能包含間接關聯知識元,也可以根據知識元所屬概念層定位。概念-知識元索引同樣采用三元組形式,主體為概念,謂詞為包含,客體為概念所屬知識元。概念索引建立是在概念-知識元索引的基礎上所建立的概念層概念之間關聯的索引,概念索引反映的是概念之間的層級關聯,而層級關聯來源于不同概念所包含的知識元間的關聯。概念層可視為粗粒度的知識關聯層,概念索引的三元組描述為(概念,層級關系,概念),層級關系為上下級關系。概念索引展現概念間粒度關系,可將概念分解為多個細粒度的概念,又可獲取更粗粒度的概念。
綜上,概念索引作為概念層結構索引,提供總架構;概念-知識元索引將多個知識元與概念建立索引;知識元索引提供與知識元相關的各項屬性特征檢索,為最細粒度的知識單元索引。這三者結合起來既可以提供細粒度的知識元檢索,又可以根據粗粒度的概念檢索,不同粒度概念之間也可相互跳轉,而概念又可由細粒度知識元集來揭示,從而滿足UGC的多粒度索引與檢索的需求。
4 實證研究
4.1 數據來源及處理
本文的實驗數據分別來自CSDN(Chinese soft‐ware developer network)和博客園兩種專業博客。之所以選取這兩種博客作為實驗數據的來源,其原因主要在于它們具有較高的知識密度[26],這有利于克服碎片化UGC多源分布性導致的知識內容離散分布的問題,進而提高知識要素抽取和知識元生成的效率。具體而言,首先,借助網絡爬蟲從CSDN和博客園中爬取與“檢索”這一主題相關的UGC文本片段;然后,借助NLPIR(natural language pro‐cessing and information retrieval)分 詞 工 具,融 合“檢索”相關的詞條,對爬取的UGC文本片段進行分詞,并去除分詞結果中的停用詞。
4.2 UGC多粒度關聯實證
UGC多粒度關聯實證包括三個部分:生成知識元概念關聯集,獲取知識元等同關系,獲取知識元非等同關系。
4.2.1 概念關聯集創建
本文選擇分類-主題詞表和維基百科數據作為已有知識組織體系數據,采用命名實體識別的技術方法,對UGC知識元知識要素進行概念識別,在識別出的概念之間進行關聯查找。關聯查找先是從已有知識組織體系中提取,若出現沖突則以分類-主題詞表為準,在此基礎上對于沒有識別出關聯的概念,再使用基于規則和句法結構的方法提取部分關系。表1為“搜索引擎”下的部分知識元概念關聯集。
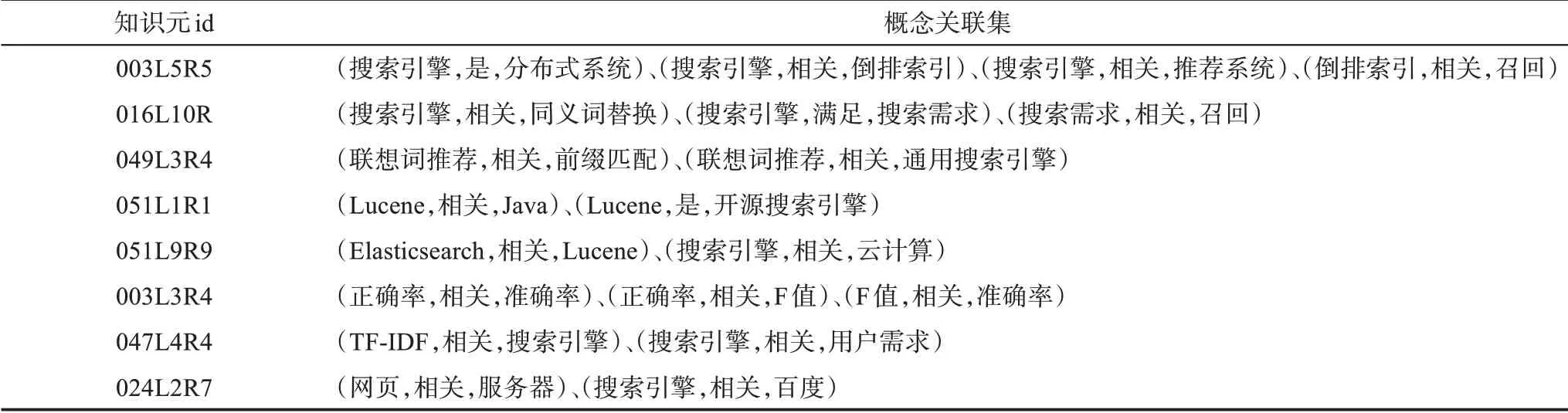
表1 “搜索引擎”標識詞下的部分知識元概念關聯集
4.2.2 知識元等同關聯構建
等同關聯實證分為兩步。首先,在已有知識組織體系中查詢兩個知識元標識詞之間是否為等同概念,若滿足條件,則將兩個知識元視為等同關聯知識元;否則,計算兩個知識元的知識要素的相似度,再根據相似度進行判斷。具體而言,先以知識元抽取中所構建的BTM+GloVe的語義向量作為知識要素向量,計算向量余弦值,若其大于閾值,則視為知識要素相關性強;然后進入知識元概念關聯集相似度的判斷,比較概念關聯集中關聯邊,每條邊以完全匹配的方式判斷,即節點及節點間的關系都需要完全相匹配才能判定兩條邊一致;具有等同概念關系的節點視為相同節點,若關聯集相似度高于閾值,則判定知識元具備等同關系。本文共構建了56對等同關聯,其中與“倒排索引”等同關聯的知識元及關聯判定依據如表2所示。

表2 與“倒排索引”等同關聯的知識元及關聯判定依據
若知識組織體系匹配為1,則表示在已有知識組織中有匹配到等同關系;若為0,則表示沒有,需要進行下一步;Null表示不需要進行下一步便可判定有等同關聯。為了便于直觀查看,這里的知識元直接用概念標識詞表示,實際是指概念標識詞中的某個知識元,省略了知識元id。需要注意的是,若知識元具有等同關系,則其各自所屬的概念標識詞之間也具備等同關系;但若概念標識詞具有等同關系,則其下屬知識元之間不能認為有等同關系。
4.2.3 知識元非等同關聯構建
關于非等同關聯的判定,首先在已有知識組織體系中查詢兩個知識元標識詞之間是否存在除等同關系以外的其他關聯關系,如層級和相關關系。若有,則作為兩個知識元間的關聯關系;若無,則基于概念關聯集,借助于多階關聯分析的方式來識別知識元之間的非等同關聯關系。本實驗共構建了274對非等同關聯,其中部分非等同關聯的知識元及關聯如表3所示。
從表3可以看出,“檢索”和“圖像檢索”之間存在層級關系,“音樂檢索”和“哼唱檢索”存在包含關系,“模糊檢索”和“精確匹配”、“查準率”和“召回率”、“創建索引”和“分詞器”、“布爾檢索”和“布爾邏輯”之間存在相關關系。
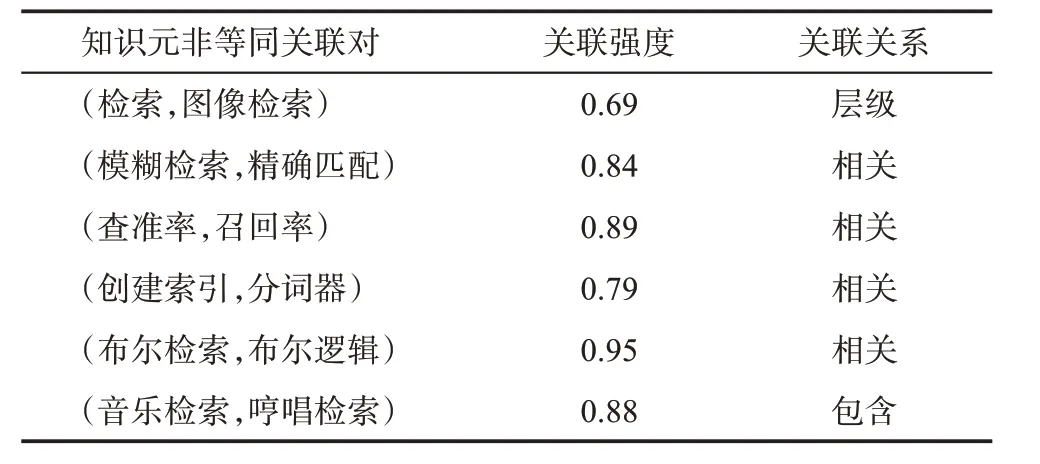
表3 非等同關聯的知識元及關聯關系(部分)
4.3 碎片化UGC多粒度索引及服務實證
4.3.1 UGC多粒度索引創建
對于上文所得到的UGC知識元和知識元關聯,將其以知識元語義描述模型的方法存儲到數據庫中,本節選擇關系型數據庫MySQL存儲數據,調用lucene架包實現索引創建。從數據庫中讀取出數據,根據上述內容創建知識元索引、概念-知識元索引和概念索引,生成倒排文檔。其中,對知識元索引的主體和客體采用Field.Store.YES,Field.Index.TOKENIZED索引,既存儲也分詞;謂詞采用Field.Store.YES,Field.Index.UN_TOKENIZED索引但不分詞;對于概念-知識元索引和概念索引,三元組均采用索引但不分詞方式創建索引。每個索引生成相應索引文件。
4.3.2 UGC多粒度知識組織檢索服務
本文實證的最終模塊是為用戶提供檢索服務。用戶輸入檢索詞,如圖8所示,在生成的索引文件中進行檢索,并返回結果。為直觀展示檢索結果,本文選擇以可視化的方式顯示檢索結果界面,如圖9所示,其主要包含四個部分內容,左上為與檢索式相匹配的知識元整體模型顯示,點擊其中的概念標識詞會返回同一標識詞下的所有知識元,左下為知識元對應知識要素,右上為該知識元所在的概念上下層級結構,點擊可進行不同粒度概念跳轉,右下為與該知識元直接相關聯的其他知識元,點擊將跳轉為該知識元可視化界面。

圖8 輸入“搜索引擎”關鍵詞查詢
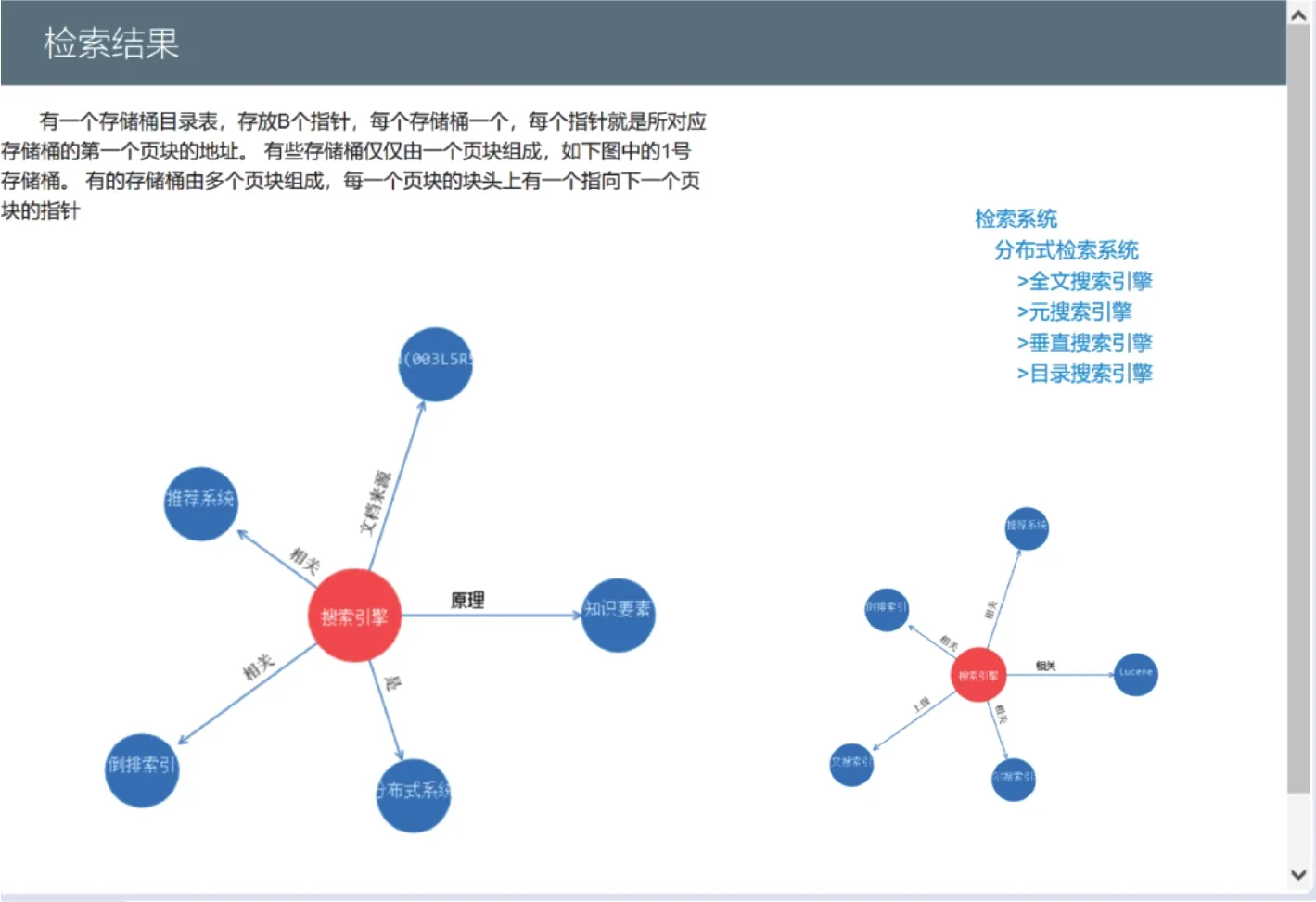
圖9 查詢返回可視化界面
5 總結與展望
本文以知識元作為知識組織的基本單位,首先,借助知識要素的抽取和聚類生成面向UGC內容的知識元;其次,通過概念匹配和多階關聯分析的方法構建UGC知識元間的多粒度關聯關系;最后,以RDF三元組描述框架構建UGC知識元索引、概念-知識元索引和概念索引,實現對碎片化UGC的多粒度知識組織。在此基礎上,以CSDN和博客園為UGC數據來源進行實證研究,研究結果證明了本文所提出的對碎片化UGC進行知識組織流程的有效性。雖然本文提出了一種面向UGC的多粒度知識組織的方法,但本文對面向UGC的多粒度知識服務的討論不夠深入,如何根據用戶需求構建個性化知識服務尚需深入討論。為此,未來將基于用戶認知和行為特征進一步探究面向UGC的多粒度融合知識服務問題。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:30
當代陜西(2021年17期)2021-11-06 03:21:36
現代裝飾(2020年2期)2020-03-03 13:37:44
當代陜西(2019年15期)2019-09-02 01:52:00
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
學苑創造·A版(2018年11期)2018-02-01 06:29:20
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
讀者(2017年5期)2017-02-15 18:04:18
湘江法律評論(2016年0期)2016-06-15 20:29:32
