新興技術識別中的不均衡分類研究
——基于代價敏感的隨機森林算法
2022-11-23 12:03:54盧小賓張楊燚楊冠燦行佳鑫
情報學報 2022年10期
盧小賓,張楊燚,楊冠燦,行佳鑫
(中國人民大學信息資源管理學院,北京 100872)
1 引言
隨著大數據的積累和全球化競爭的加劇,新興技術識別(emerging technologies identification)對于科技創新、競爭情報等相關領域的戰略意義日益凸顯。專利通常是一項技術誕生時尋求壟斷權利保護的有效和必要方式,大規模的專利數據包括了技術相關的各種關鍵信息,為新興技術的早期預測與識別積累了豐富而有價值的數據基礎。針對大規模的海量專利數據實現自動化的前瞻性預測逐漸成為新興技術識別的研究重點和發展趨勢,尤其是基于專利指標體系的機器學習分類預測,目前已被廣泛地應用于新興技術識別的各種場景。
然而,在新興技術識別這一復雜問題中,多數研究都關注如何根據特征工程構建更完善的專利指標以捕捉新興技術的特征信息,卻忽略了以專利為代表的海量技術發明涌現為新興技術這一事件往往具有小概率的特征,是一種典型的不均衡數據分類問題,其預測效果也會受數據集正負樣本分布不均衡因素等影響,出現分類結果偏向多數類的現象,無法實現成功預測少數新興技術涌現的理想效果。傳統研究中,為了規避數據不均衡對新興技術識別效果的制約,多在數據采集階段通過一系列人工的操作,獲取經人工篩選后的均衡數據集,使機器學習的過程可以運行。但隨著當前自動化專利推薦、新興技術識別趨勢的興起,如何改進與優化分類策略以提升機器學習面臨新興技術識別中不均衡分類問題的表現,實現在大規模數據上對新興技術進行自動化的識別,成為制約基于機器學習的新興技術識別效果的瓶頸。
本研究聚焦于機器學習方法在新興技術識別中面臨不均衡分類問題的應用,以預測癌癥藥物領域專利是否有成為新興技術潛質的二分類場景為例,在數據層面比較漸進式采樣思路對分類結果的影響,在評估層面引入代價敏感學習,探究在缺乏專家經驗時的代價矩陣驗證方式,并將其應用于算法層面和決策評估的改進。最終在此不均衡分類優化的研究框架下,通過對分類預測效果的有效評價,嘗試在數據、算法和評估三個層面綜合實現更好地處理不均衡問題的改進分類策略,解決新興技術識別場景下不均衡分類的預測問題。
2 相關研究
2.1 新興技術識別研究進展
新興技術(emerging technologies)的概念最早由沃頓商學院Geroge等學者于2000年出版的Wharton on Managing Emerging Technologies中提出,該書將其明確歸納為“在科學理論或實踐基礎上,具有新興行業開辟或者現有行業顛覆意義的創新型技術”[1]。早期的新興技術研究多聚焦于文獻或專利數據,但以往思路往往只能實現對已存新興技術的事后評價而非預測性識別[2]。以德爾菲法(Delphi method)為典型的傳統預測性研究也因對領域經驗和精力的高要求以及缺乏直接數據支撐解釋而不適用于當前大多數的預測情景[3]。當前,新興技術識別的需求處于調整過程中,基于大規模數據的實時預測正在成為新興技術識別的重點及趨勢。目前,新興技術識別的定量研究主要方法如表1所示。

表1 新興技術識別的主要方法
2.2 機器學習中的不均衡分類問題
機器學習的分類方法能將新興技術識別問題轉化為分類預測問題,推動新興技術由傳統的回溯性分析轉變為前向的預測性分析,已被廣泛地應用于新興技術識別的各種場景[9]。不均衡分類是數據分布復雜性導致的一種特殊分類場景[10],在不均衡分類問題中,原始數據里不同類別的樣本比例差距很大,由于少數類通常反映出更受重視的信息,是研究的重點,因此,將少數類記作正類,多數類記作負類[11]。在機器學習模型的訓練過程中,數據不均衡分類主要面臨幾個方面問題[12]:少數類樣本的稀缺性,包括少數樣本自身稀少的絕對稀缺和少數樣本自身不少但多數樣本過多的相對稀缺[13];難以區分噪聲數據與少數類數據的特征及差異,去噪工作難度大[14];以總體分類效果為學習目標的分類器出現傾向于多數類的偏向性[15];以整體指標(accura‐cy)評估模型缺乏價值。
2.3 不均衡分類問題的優化研究
針對不均衡分類現象,目前主要從數據層面、算法層面和評估層面改進分類模型的少數類預測能力。
(1)數據層面。對于不均衡分類數據集,可在進行模型訓練之前,將重采樣方法用于數據預處理以更改數據分布比例,達到均衡數據集訓練分類器的目標。目前,重采樣方法主要有擴充少數類數據的過采樣和減少多數類數據的欠采樣。常見的過采樣技術包括隨機過采樣方法(random oversampling)[16]、SMOTE(synthetic minority oversampling technique)算法[17]、邊界過采樣(borderline-SMOTE)[18]、自適應合成采樣(adaptive synthetic sampling,ADASYN)[19]等。常見的欠采樣技術有隨機欠采樣(random un‐dersampling)[20]、cluster centroids欠 采 樣[21]、near miss欠采樣[22]、Tomek links[23]。近年來,針對圖像、視頻方面的數據不均衡問題,生成對抗網絡(gen‐erative adversarial network,GAN)可以被用于數據增強,如研究顯示經過多重偽類生成對抗網絡(multiple fake classes GAN,MFC-GAN)[24]、條件生成對抗網絡(conditional GAN,cGAN)[25]數據增強后的分類效果都得到了顯著提升。
(2)算法優化。常用的分類算法在不均衡分類中,往往由于不均衡分類的特征表現出對少數類較弱的預測能力。集成學習的思想是通過不同的選舉方法,將多個弱分類器組合成一個最終學習效果顯著提升的強分類器[26]。目前,提升(boosting)和裝袋(bagging)是較為經典的兩種技術手段[27],構建元模型來融合多個學習器的堆疊(stacking)思想也得到了部分應用。但集成學習的目標仍然是提升總體學習準確率,在極度不均衡分類中不能解決根本性問題[28]。深度強化學習模型(deep reinforcement learning,DRL)[29]通過設計給予少數類樣本較大激勵函數的方法是有益的嘗試;圖卷積神經網絡(graph convolutional network,GCN)對于圖數據、流數據等體現出拓撲不均衡特征的數據而言也具有顯著優勢,如雙正則化GCN(dual-regularized GCN,DRGCN)[30]、重新加權GCN(re-weighted adversarial GCN,RA-GCN)[31]均能有效地防止基于圖的分類器偏向任何特定類。最后,結合了主動學習方法的均衡分類算法,能通過結合少量專家智慧極大提升模型分類的效率[32-33]。然而,上述研究進展主要聚焦于具有特定數據結構的研究領域,在適用范圍方面存在一定的局限性。因此,在解決不均衡分類場景時,還需要結合多層次多角度的嘗試進行綜合優化。例如,結合數據重采樣,Wu等[34]基于改進的SMOTE和Ada‐Boost算法提出了客戶留存及流失預測分類器;引入代價敏感[35],在AdaBoost樣例權值更新中引入代價因子,構建基于代價敏感的AdaBoost算法[36-38]。
(3)評估層面。代價敏感學習[39]用于誤分類代價不同的情況。其核心思想是利用代價矩陣(cost matrix)使不同誤分類產生有差異的懲罰,即非均等代價(unequal cost),使分類器更關注誤分類代價高的類別。目前,代價敏感信息的引入主要有以下類型[15]:①將代價敏感因子以權重的方式引入分類模型[40],如最經典的AdaBoost迭代改進就是Fan等[41]的基于代價權重的AdaCost;②將代價敏感作為結果處理階段的元模型,以stacking集成學習方式結合入傳統分類模型的輸出結果,例如,Domin‐gos[42]提出的MetaCost基于stacking“元學習”通過最小期望代價作用于類別修正標簽;③重新構建基于代價敏感特征的分類器,將代價敏感的特征直接擬合于分類器的基本邏輯,對其整體的損失函數、訓練特征或內部機制進行優化,例如,在決策樹的歸納過程中通過代價函數控制其剪枝規則[43]。
3 研究設計
本研究從數據、算法和評估三個方面綜合考慮如何解決新興技術識別中的數據不均衡問題,以期望獲得更優的新興技術識別的預測結果,為后續類似不均衡數據問題的解決提供參考。技術路線如圖1所示。
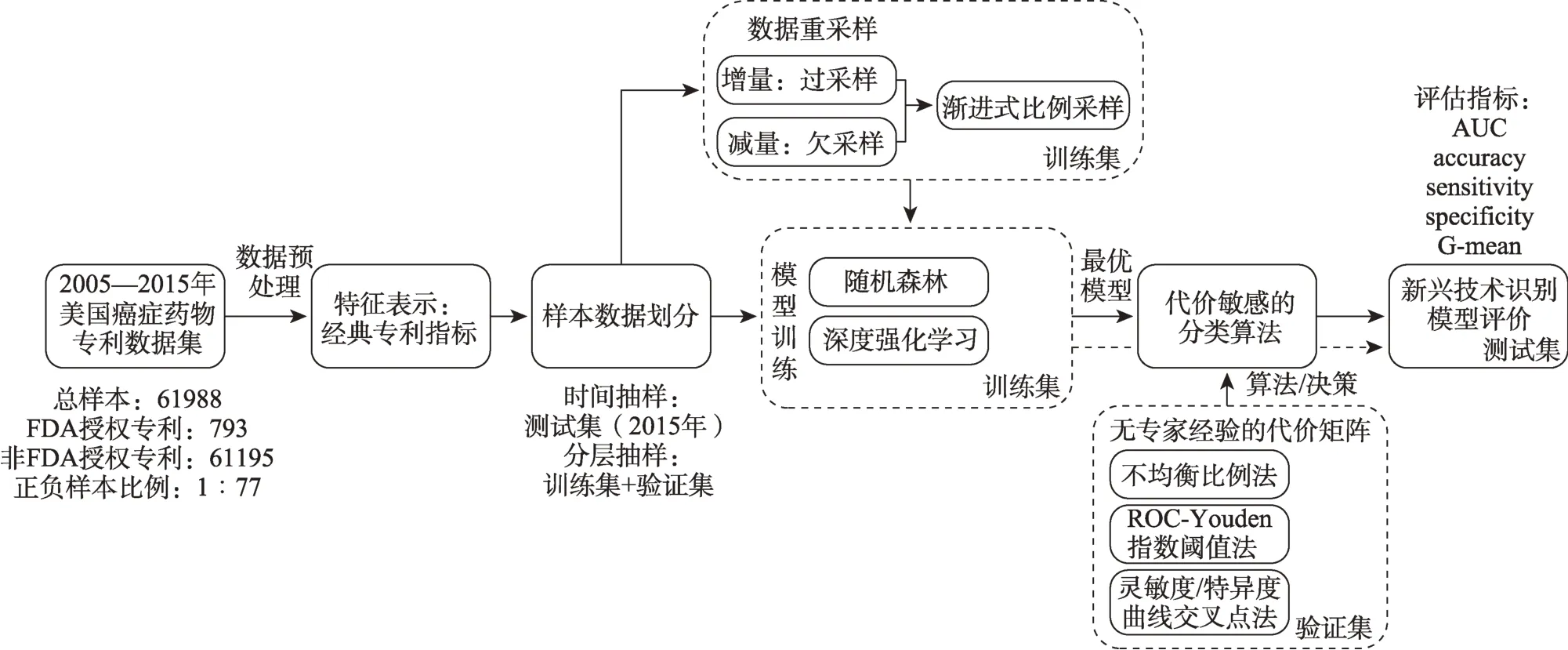
圖1 技術路線
3.1 數據來源
在各高新技術行業中,制藥領域的癌癥藥物研發專利一直受到廣泛關注,選擇該領域進行實證研究主要具有以下必要性和優勢:藥物專利數據集通常在全球范圍內都有較好的開放共享性;涉及大規模投資和研發高風險,且技術價值與其商業價值直接相關,能較好地體現與之相關的新興技術規劃與布局等戰略;藥物研發的創新性即是否能夠涌現為新興技術,相比于其他領域容易評價,例如,在美國,獲得專利頒發機構許可的癌癥藥物僅僅是獲得技術的認證,只有當其同時獲得了FDA(Food and Drug Administration,美國食品和藥物管理局)授權許可,才意味著其成為滿足上市要求的新藥。因此,癌癥藥物專利集作為該領域技術的集合,預測此類專利是否有可能獲得FDA授權可充分地作為新興技術識別的目標。
數 據 集 采 用2016年USPTO(United States Pat‐ent and Trademark Office)癌癥登月計劃開放的癌癥藥物專利數據集(Moonshot Cancer Drug Patents)。該癌癥藥物專利數據集包含了已發表和已授權的癌癥藥物相關的專利記錄及詳細信息。同時,為了補充本研究目標所需要而該數據集尚不完整的信息,基于專利號碼,進一步根據PatentsView API和EPO OPS API對需要的著錄數據和家族數據進行補充。此外,該專利數據集中的FDA授權許可信息僅截止到發布日期,通過FDA發布的授權藥品數據說明(即俗稱的“橘皮書”)補充了部分遺漏的藥物專利是否得到FDA授權的信息。
最終,經過數據預處理和篩選,得到2005年1月1日至2015年12月31日的癌癥藥物專利數據共61988條。其中,FDA授權的標簽數據僅有793條,非授權的標簽數據達到61195條,數據極不均衡,只有約1.28%的專利同時能得到FDA的授權,獲得批準上市,正負類樣本比例(imbalanced ratio,IR)約為1∶77.17,是典型的新興技術識別中的不均衡分類數據集。表2展示了該數據集的統計信息。
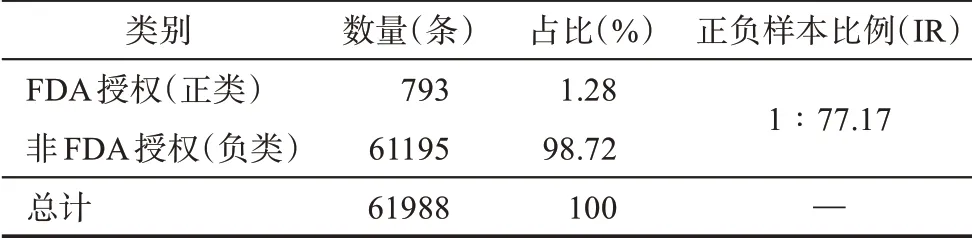
表2 數據集統計
3.2 專利特征指標
由于本研究的關注重點在于新興技術識別過程中不均衡分類問題的解決,因此,在選取專利特征指標時,遵循簡潔性、代表性和權威性的指導原則,采用經典研究中被廣泛采用的專利指標作為專利特征的評價,重點在于體現出新興技術的關鍵特征:創新性、相對增長性、連續性、社會經濟影響力[44-47]。具體的專利特征變量及說明如表3所示。抽取并計算特征變量,表4匯總了本研究中所有專利特征指標的描述性統計量。
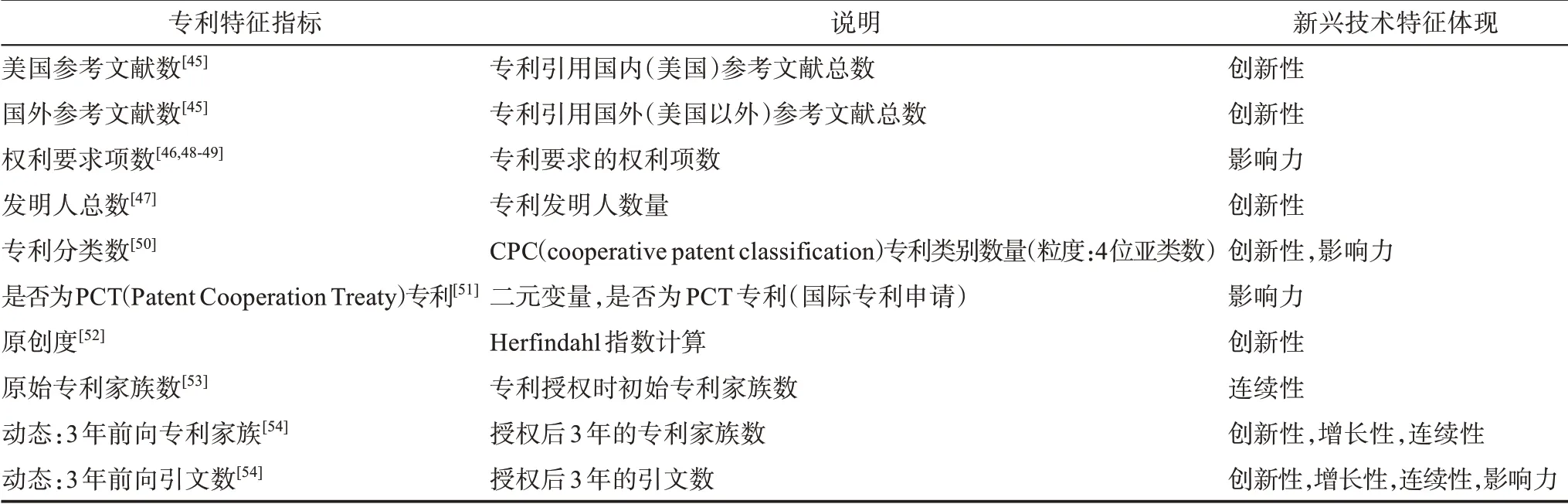
表3 專利特征指標及說明
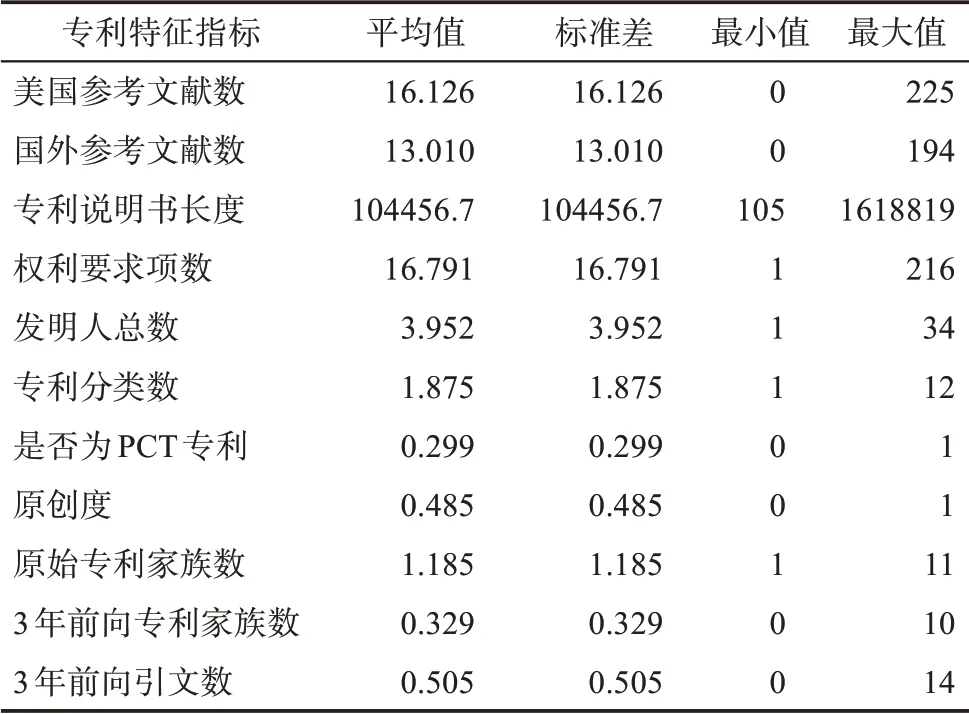
表4 專利特征指標的描述性統計
3.3 數據集劃分
采用時間抽樣(out-of-time sampling)和分層抽樣(stratified sampling)結合的方法將原始數據集抽分為三個互斥的樣本集,分別用于訓練、驗證及測試。首先,利用時間抽樣法將樣本分割為訓練集和測試集。時間抽樣法是一種非隨機的留出法(holdout sampling),其以時間為依據進行定向抽樣,在模型的評估中會更關注模型對于現在乃至未來成功預測出FDA授權的目標表現,符合面向未來的預測識別需求;其次,采用分層抽樣的方式進一步劃分訓練集和驗證集。分層抽樣能夠在數據集分割的同時,保持其中正負類樣本的比例不變,相當于分別對正負類樣本進行等比例抽樣,選取訓練集和驗證集的比例分別為80%和20%。最終,根據新興技術識別的具體應用場景劃分數據集,如表5所示,進一步印證了基于癌癥藥物領域專利的新興技術識別是不均衡分類的典型問題。
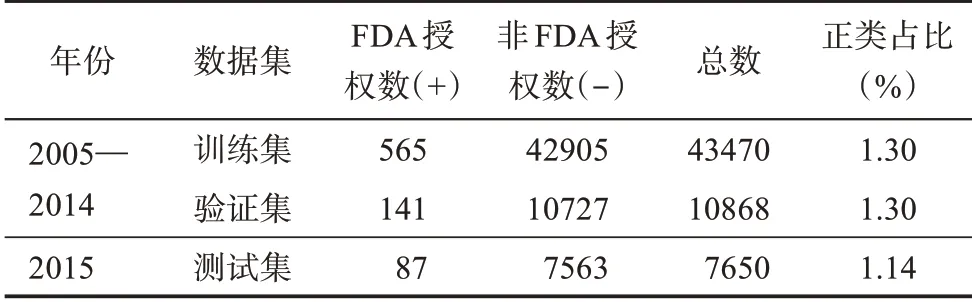
表5 數據集劃分統計
3.4 基于代價敏感學習的隨機森林構建
3.4.1 模型選擇
隨機森林(random forest,RF)是不剪枝的樹集成分類器[55],將多個互相獨立的決策樹通過裝袋(bootstrap aggregating,bagging)的形式構建出大規模的集成模型。因此,當決策樹的總量足夠大以及滿足抽樣隨機性時,隨機森林的多樣性和泛化能力會增強。在具體的實驗過程中,通過比較模擬確定以下綜合較優的關鍵超參數:n_estimators設置為400,即采用400棵子樹作為基分類器,此時模型的泛化能力飽和;max_features采用所有專利特征屬性,本研究的特征屬性僅11個,構建分類器時考慮所有特征的模型性能更優。在此基礎上,袋外評估和隨機性確保了隨機森林模型的泛化能力,且由于訓練集、驗證集和測試集中正負樣本的比例和完整數據集的比例較為一致,在模型結果評估時均采用測試集,不必再進行分層交叉驗證。
3.4.2 改進思想
遵循代價敏感學習的理念,將代價矩陣引入隨機森林的做法主要有三種:其一,以代價矩陣為基礎對隨機森林自主法采樣進行改進[40];其二,構建基于代價矩陣的代價敏感基分類器[56];其三,在決策階段針對決策樹的葉結點和集成決策環節采用加權的多數投票。如圖2所示。假定類別之間以代價矩陣的形式定義了不對稱的錯分成本,從而實現不同的錯誤分類懲罰項的方法被稱為加權隨機森林(weighted random forest)[57]。
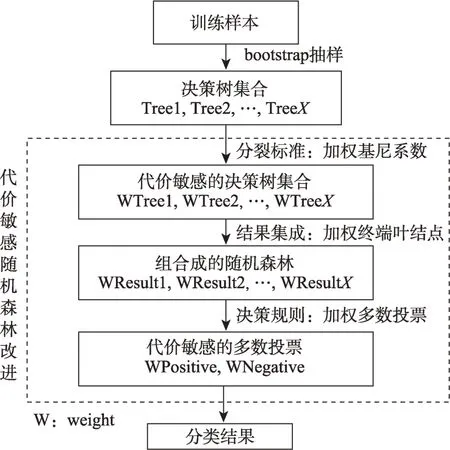
圖2 代價敏感隨機森林改進
3.4.3 分類訓練:代價敏感的基分類器
傳統隨機森林算法使用的基分類器是決策樹,隨機選取屬性進行分裂,而選擇最佳分割的方式通常是計算劃分后子結點的最低不純度,因為不純度越低,代表在此結點中的類分布就越有偏向性,越集中為某一類。不純度的估計一般以最小基尼系數法作為切分節點的分割標準。
在代價敏感的隨機森林中,針對單個基分類器的歸納過程,采用類權值計算用于選擇分裂切分點的Gini(t)的加權最小Gini(t),尋找對應的代價不純度最低的最佳分割標準。因此,Gini(t)的表達式轉變為
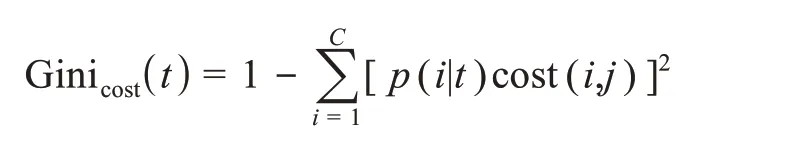
其中,i表示類別;C表示類別的個數。
3.4.4 決策規則:代價敏感的多數投票
除了修改作為基分類器的單個決策樹的分裂標準,代價敏感信息也會被加入樹的葉結點即終端決策規則中去。引入代價敏感思想后,每棵決策樹終端葉結點的類別判定不再取決于該結點樣本中數量居多的類別,而會納入以權重表示的代價。對于單棵決策樹來講,在最后的分類決策中,葉結點t指派為正類的概率轉變為
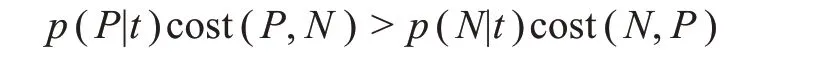
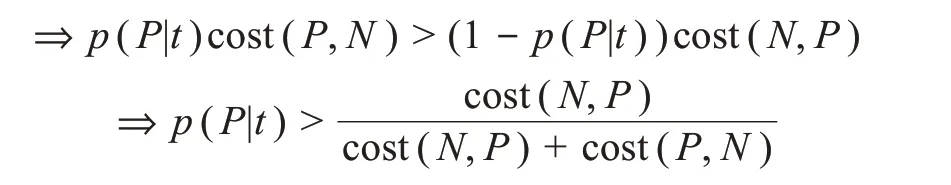
最后,每棵樹終端葉結點的類預測均轉為加權多數投票,隨機森林最終預測類別就是所有樹平均加權投票值高的類[57],提升了隨機森林中對不均衡分類更為敏感的樹在多數投票決策階段的話語權。
3.5 模型評估及目標
在不均衡分類問題中,由于少數類通常反映更受重視的預測結果,是重點的研究對象,一般都將少數類作為正類(positive,P),多數類記作負類(negative,N)[11]。根據測試樣本的實際歸屬類別與模型的預測結果輸出,混淆矩陣能組合出如表6所示的真正例、假正例、真負例和假負例四類分類評價。基于二分類混淆矩陣,本研究所采用的評估指標計算方式和說明如表6所示。

表6 二分類混淆矩陣
(1)整體準確率(accuracy):表示模型預測正確的樣本總和與所有樣本總和之比,
accuracy=(TP+TN)/(TP+TN+FP+FN)
(2)靈敏度(sensitivity)和特異度(specificity):靈敏度表示模型的真正率(true positive rate,TPR),即被正確預測為正類的樣本數量與實際所有正類樣本的比例,體現出少數類被正確預測出的分類水平;特異度表示模型的真負率(true negative rate,TNR),即被正確預測為負類的樣本數量與實際所有負類樣本的比例,體現出多數類的正確分類水平。計算公式分別為
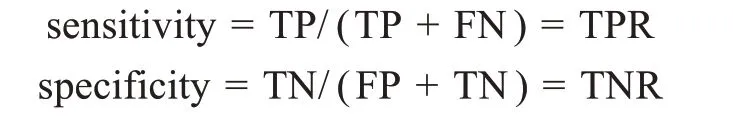
(3)ROC曲線與AUC值:ROC(receiver operat‐ing characteristic)曲線[58]根據混淆矩陣對所有可能的分類閾值效果進行綜合衡量,本質上是不同分類閾值下分類結果(TPR、FPR)表現的集合,是兼顧正負分類效果的評估方式,其中縱坐標TPR與橫坐標FPR(false positive rate)的計算方式分別為
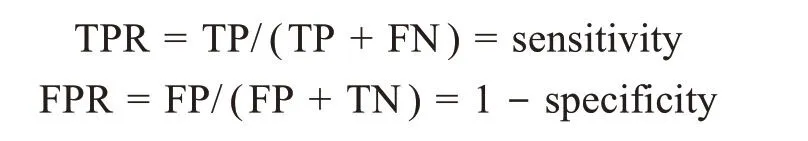
AUC值(area under curve)表示ROC曲線中TPR和FPR對應點的連線與坐標軸包圍區域的面積,常被作為評價模型整體性能的測度指標。AUC數值越大,模型的整體預測能力就越理想。
(4)G-mean[59-61]:在不均衡問題中,同時優化多個指標是困難的,通常需要進行權衡。相較于傳統的F1值可能會受到不均衡環境下高FP值的欺騙,產生誤導[62],G-mean表示模型靈敏度(sensitivity)和特異度(specificity)的幾何平均,能夠綜合體現有效識別的總體水平,
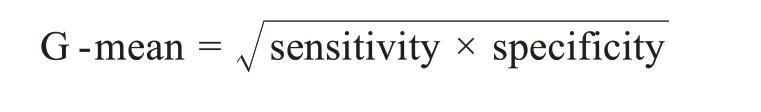
4 實證分析
4.1 漸進式采樣方法
以訓練集的完整數據為基礎,重構多種重采樣數據集,將其與完整的采樣數據進行比較。其中包括四種常見過采樣數據集:隨機過采樣數據、SMOTE過采樣數據、borderline-SMOTE數據和ADASYN數據,以及四種常見欠采樣數據集:隨機欠采樣數據、cluster centroids數據、near miss數據和Tomek links數據。圖3展示了不同模型下各采樣方式ROC曲線的比較。

圖3 各采樣方式ROC曲線的比較
該實驗結果表明,盡管部分欠采樣和過采樣方法都可以有效地解決不均衡數據分類預測結果偏向多數類的問題,但其總體的性能表現卻具有較大差異。隨機欠采樣表現出了整體更優的ROC曲線分布和AUC值,同時,不僅在預測建模上能夠顯著優化分類器的分類性能和少數類識別能力,更能大幅提升模型的計算效率,是本數據集最適宜的采樣方式。
此外,將不均衡數據集均衡到什么程度能得到最佳的分類表現也是不均衡分類問題中值得探索的領域。例如,Kim等[63]通過邏輯回歸、樸素貝葉斯、隨機森林測試了負訓練數據與正訓練數據的比率如何影響機器學習算法在消除作者姓名歧義方面的性能;Peng等[64]在預測實時交通事故風險的研究中探索了不同比例過采樣對實驗結果的影響。在保證正負樣本區分能力足夠的基礎上,不能簡單將正負類別的均衡比例設置為1∶1,而應當通過進一步的實驗結果,結合分類目標確定具體的均衡比例,注重數據均衡比例和原始樣本空間改變的平衡。因此,繼續采用隨機欠采樣,所有FDA授權的正類樣本仍然保留在數據集中,按照一定的比例隨機剔除整個樣本中的非FDA授權的負類數據,使數據分布更加均衡。正負類樣本比例分別從1∶1到1∶20用于形成重采樣后的建模數據集。表7展示了不同隨機欠采樣比例下的訓練集樣本描述,不同正負類均衡比例的組合在測試集的預測結果如圖4所示。
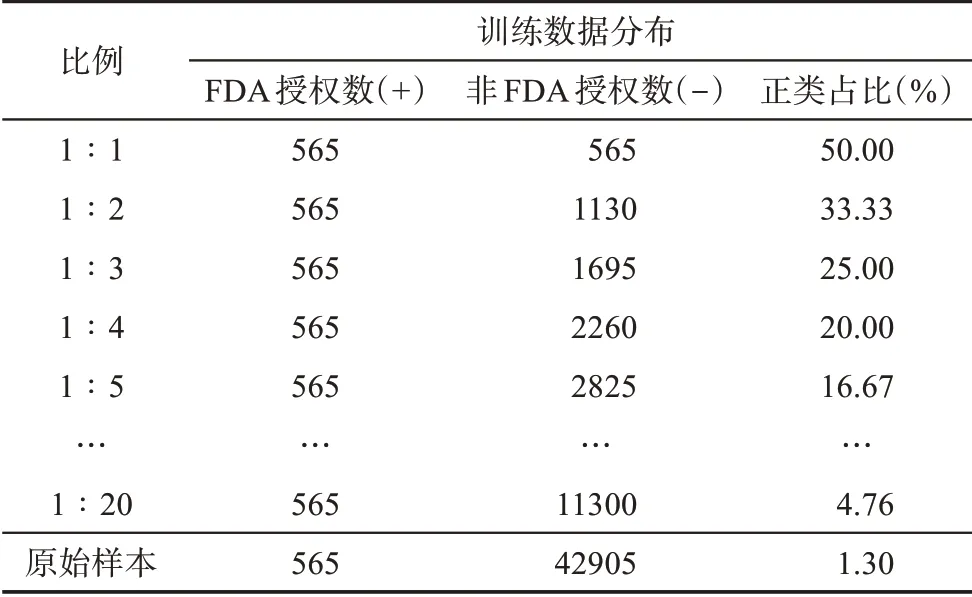
表7 漸進式隨機欠采樣的訓練集分布描述
從圖4可以發現,總體上看,1∶2時,隨機森林的AUC值為各比例下的最高值(0.881),且在Gmean相比于1∶1損失僅約為0.015的條件下,保持了較高的整體準確率。因此,使用隨機欠采樣并以正負均衡比例1∶2構建的隨機森林模型在大大減少了分析的數據量且保留相對更多原始多數類樣本信息的基礎上,取得了綜合預測能力提升趨勢較為飽和的不錯的預測結果,更適合作為本研究后續代價敏感學習的基礎。
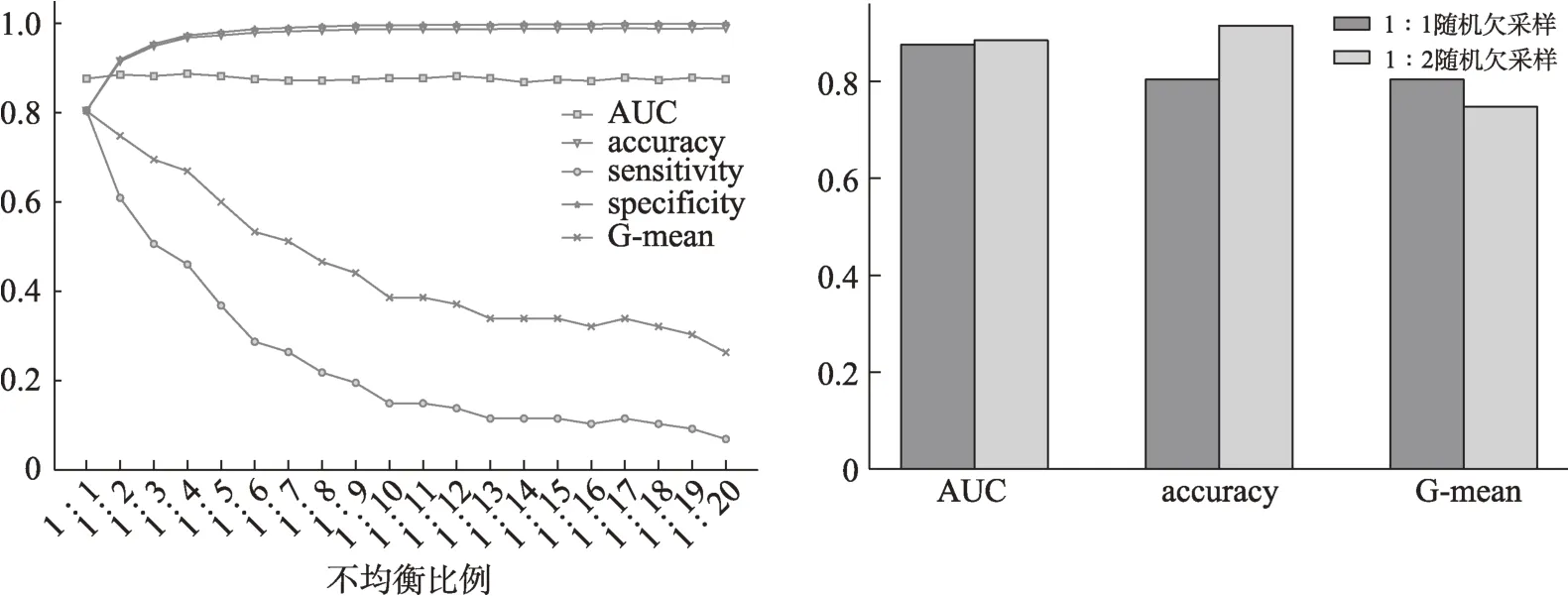
圖4 漸進式隨機欠采樣的隨機森林比較
4.2 代價矩陣的設定
代價敏感學習的有效性在很大程度上取決于代價矩陣的確定,錯誤的初始化成本會損害模型的學習過程。因此,代價矩陣提供的參數對于代價敏感學習至關重要。目前主要通過兩種方式獲得成本矩陣:領域專家提供經驗和目標,或者采取不同的代價矩陣驗證方法在分類器訓練階段學習獲得。然而在實際的不均衡分類問題中,諸多情景并不能直觀地依靠金錢損失、時間成本和發病率等就能得到較為可靠的代價矩陣。因此,更多地還是依靠后者來獲取具體問題的最優代價矩陣。
4.2.1 不均衡比例法
目前,針對專家經驗的較難獲取性,許多研究都將其簡化為利用不均衡比例(IR)作為估算成本的直接方法。IR方法直接根據不同類別的樣本比例來設置少數類的權重。以二分類問題為例,假設完整的樣本集為S,SP為少數類即正類數據的數量,SN為多數類即負類數據的數量,則數據集不均衡度IR的計算方式為
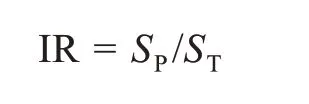
4.2.2 ROC-Youden指數閾值法
以ROC曲線的Youden指數作為選擇閾值的標準,稱為Youden指數閾值法[65]。Youden指數在ROC曲線上反映為點與對角交叉線(0,0)和(1,1)之間的縱向距離,Youden指數的計算公式為
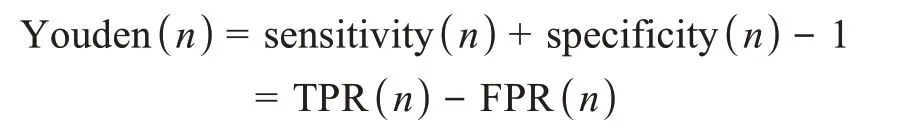
其中,n表示ROC曲線中點的集合;sensitivity(n)和specificity(n)分別為該點對應的分類閾值下模型的靈敏度和特異度。
4.2.3 靈敏度/特異度曲線交叉點法
由于靈敏度和特異度曲線交叉處代表同時較高的靈敏度和特異度,很多研究都通過選擇靈敏度和特異度曲線交叉點的方法來確定分類閾值[66-67]。利用ROC曲線計算Youden指數閾值的方法,通過驗證集采用靈敏度和特異度曲線交叉點法獲取對應閾值就能推導出代價矩陣:
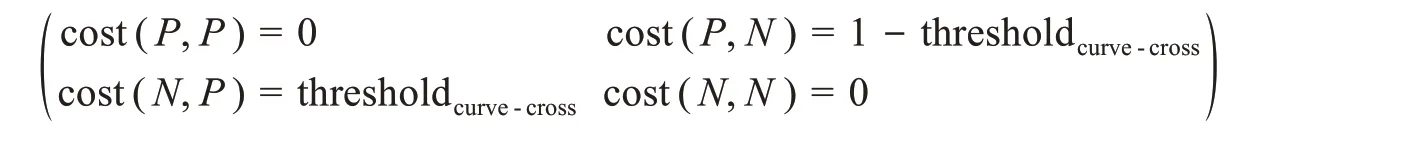
4.3 實驗效果分析
最終,通過不均衡比例法,以及驗證集基于ROC-Youden指數閾值法和靈敏度/特異度曲線交叉點法確定的代價矩陣,1∶2隨機欠采樣的代價敏感隨機森林和兩個對照實驗組的預測結果如圖5和表8所示。
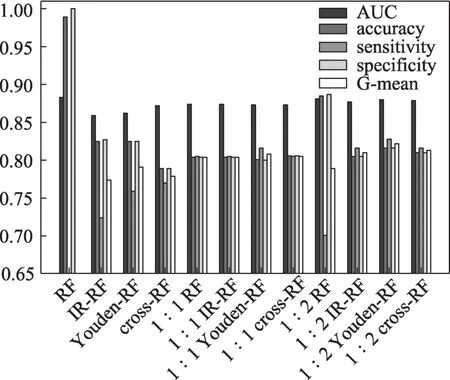
圖5 不同策略組合的分類器比較
從圖5和表8可發現,總體來看,采用三種方法確定代價矩陣的代價敏感隨機森林對于新興技術識別分類預測能力均有顯著提升,表明代價敏感學習對于是否進行數據采樣處理的分類算法均有提升少數類分類預測能力的作用。在未經任何數據重采樣預處理的原始樣本對照組中,代價敏感隨機森林相對原始模型的提升效果極為顯著,可以有效緩解模型無法預測出任何少數類的嚴重偏向性。而1∶1隨機欠采樣處理的對照組,則進一步驗證了漸進式采樣的必要性,因為代價敏感學習在此時僅能再有限地提升模型預測能力,過度的采樣已經損失了較多的原始數據集分布信息,對于多數類預測能力和整體性能的降低已經無法通過代價敏感學習彌補提升。
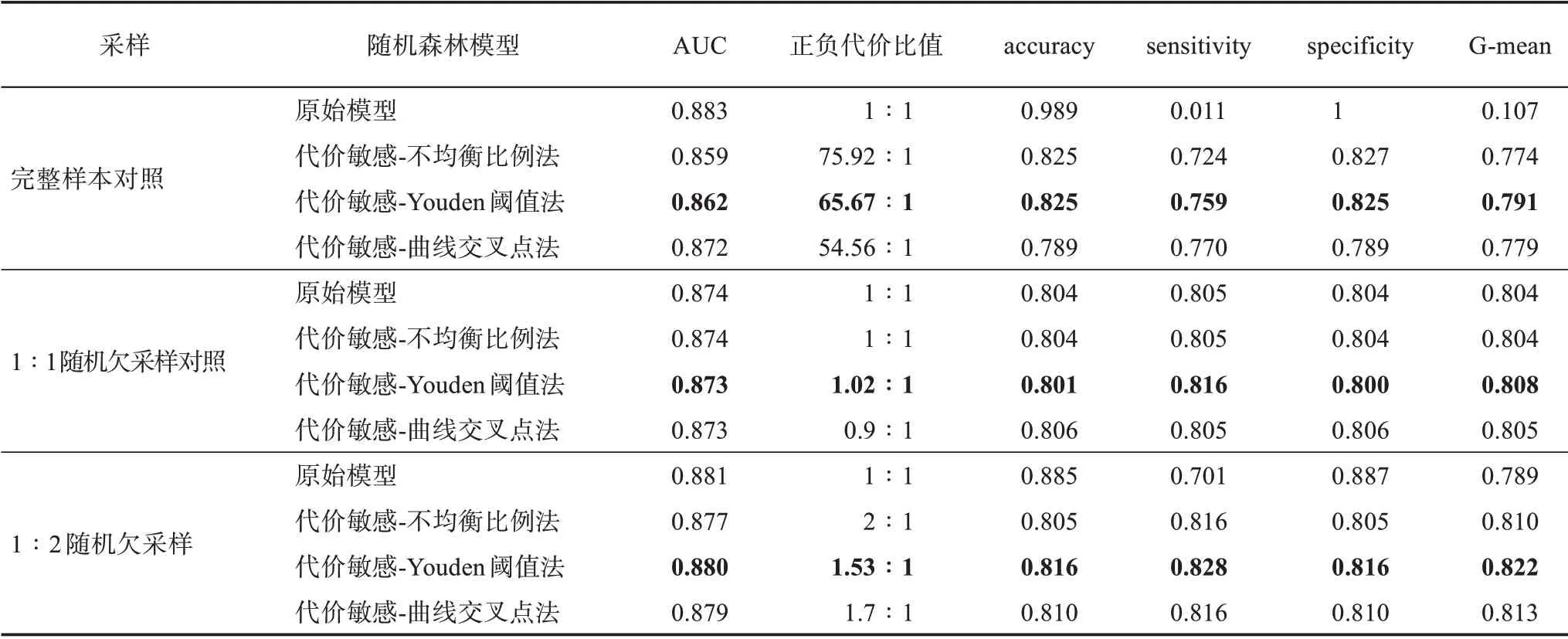
表8 不同策略組合的分類器預測結果統計
此外,通過計算分類結果的各項評估指標,發現其中最優的代價矩陣設定方式為ROC-Youden指數閾值代價矩陣,其各項性能表現均總體優于其他代價矩陣的改進。目前,最為常用的不均衡比例代價矩陣盡管很容易實現,不需要額外的模型計算成本,但具有結果不符合預期的重大局限性,因為數據集分布和實際錯分代價并不是簡單的直接關聯,不均衡比例并非不均衡分類中的唯一困難,正負樣本噪聲問題、樣本重疊等也會影響到其最優代價的變化,采用不均衡比例代價矩陣會對代價敏感問題過度簡化。值得注意的是,由于在第一階段代價未知時,訓練的分類器是原始的損失函數驅動而沒有引入代價敏感,因此,使用ROC-Youden指數閾值代價矩陣方法針對代價不敏感的算法來初始化代價矩陣參數的估計,然后通過估計的代價矩陣構建代價敏感學習算法,結果可能會存在一定偏差。盡管如此,該類方法實際上也包含了不均衡比例代價矩陣無法測度的正負樣本重疊、類內不均衡等各類因素對最優代價變化的影響。因此,在缺乏特定先驗矩陣的情況下,對比常用的不均衡比例代價矩陣,ROC-Youden指數閾值矩陣更能獲取符合預測目標模型的更優錯分代價,仍然為比較好的代價矩陣替代方案。
最后,基于1∶2均衡比例隨機欠采樣、以ROC-Youden指數閾值代價矩陣構建的代價敏感隨機森林模型取得了最好的分類表現,其AUC、ac‐curacy、sensitivity、specificity和G-mean分 別 達 到0.880、0.816、0.828、0.816和0.822,意味著在對應的新興技術識別目標中,采納該模型能預測出82.8%的新興技術,同時能正確識別81.6%的普通技術,實現僅17.2%的漏報率和18.4%的誤報率,進一步驗證了綜合漸進式采樣、算法優化和評估優化的分類改進策略為整體預測能力最好的策略組合。與其他對照組相比,其模型對于重點關注少數類預測能力的識別效果和平衡效果均較為良好,在此基礎上構建的基于專利指標的機器學習新興技術識別框架具有較強的前瞻性預測價值。
4.4 不均衡研究相關方法比較
為證明基于1∶2均衡比例隨機欠采樣、以ROC-Youden指數閾值代價矩陣構建的代價敏感隨機森林模型具備優勢,本研究選取不均衡分類研究中最近提出的相關方法——deep reinforcement learn‐ing(DRL)進行比較分析。以原始訓練集為基礎,通過隨機欠采樣構建出1∶1及1∶2重采樣數據集,在該環境下驗證DRL的性能指標,并選取最優的模型結果與本研究提出的基于代價敏感的隨機森林模型進行比較,結果如表9所示。
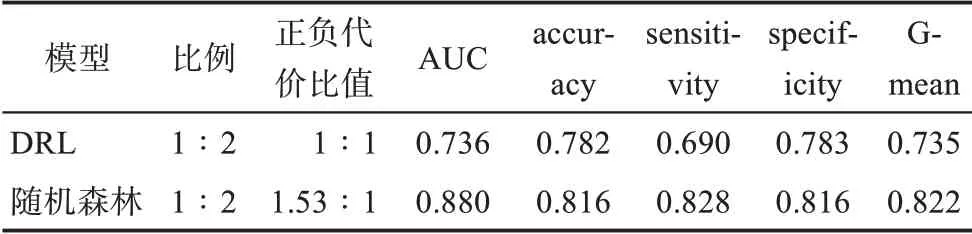
表9 deep reinforcement learning(DRL)與優化隨機森林的對比
從表9可以看出,本研究提出的基于代價敏感的隨機森林模型在各項指標上均顯著優于DRL,其中代表FDA授權樣本預測能力的sensitivity指標,較DRL模型高出13.8%,這一現象表明本研究提出的優化模型與現有的相關成果相比具備一定的優勢。
5 總結與展望
本研究通過數據維度、算法維度和評估維度三個層次的綜合優化策略組合,通過癌癥藥物領域專利的實證結果,驗證了所提出的基于機器學習的新興技術識別不均衡分類優化框架的可行性、有效性和價值意義。然而,本研究在研究思路、研究內容以及研究方法上存在一定的局限性與不足,在未來的深入研究中有優化和豐富的空間。
(1)本研究的核心為數據維度、算法維度和評估維度三個層次的綜合優化框架,盡管其中通過各項實驗組和對照組保證了最終模型組合策略的相對更優,驗證了本文所提出框架的有效性,但最后基于1∶2均衡比例隨機欠采樣、以ROC-Youden指數閾值代價矩陣構建的代價敏感隨機森林模型仍然為局部最優的方案,未來研究中可繼續探索采樣、算法及代價敏感學習的應用及組合。
(2)本研究尚未對不均衡數據集特征及不均衡分類面臨的本質問題開展更為深入的研究。未來不均衡分類問題的研究中,除了關注正負樣本類間不均衡比例造成的不均衡分類,還需要結合新興技術識別問題中的實際數據集納入更為細粒度的因素研究,如少數類噪聲、多數類和少數類的類間樣本重疊、類內不均衡以及概念漂移等問題,深入挖掘不均衡分類問題的本質。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
