
數據挖掘技術在電網設備故障診斷中的應用
2022-11-25 08:05:00內蒙古電力集團有限責任公司烏海供電分公司內蒙古科技大學經濟與管理學院
電力設備管理 2022年19期
內蒙古電力(集團)有限責任公司烏海供電分公司 余 洋 內蒙古科技大學經濟與管理學院 孫 斌
經過多年的快速發展,我國的供電網絡已成為世界上規模最大、最復雜、效率最高的電力網絡系統。為監控電網中各類設備的運行情況,在電力網絡系統中建設了許多信息系統,存在電力設備基礎臺賬數據、運行狀態電量數據等大量數據。這些數據具有種類繁多、數據量大、數據格式復雜、價值密度低、分布廣等特點。需要一種數據處理技術來提高數據處理的效率和深度。數據挖掘技術在電力系統中具有廣闊的應用前景。
目前很多學者都在探討如何利用數據挖掘技術提高電網設備管理能力。如FEI Siyuan(2018)分析并提出大數據技術在配電網運行、檢修、規劃和資產管理的前景與展望[1];胥佳等(2020)提出一種基于Change-Point 的風電數據挖掘算法,用來解決風電機組故障及變化發生時間點查找問題[2];黃大榮等(2017)通過數據挖掘的方法對電力變壓器故障數據進行故障特征提取,采用模式識別理論實現故障診斷[3];蔡澤祥等(2019)將數據挖掘技術應用到電力設備的狀態評估,為突破設備狀態評估的瓶頸帶來了全新的解決思路和技術手段[4]。
目前,烏海各級電網調度中心均配備運行監控和數據采集系統(SCADA)與能量管理系統(EMS)。在輸電網絡突發故障時,相應的數據監控設備會產生報警信息,例如開關跳閘、自動保護裝置動作、欠電壓、過電流和設備過負荷等信息并由專用網絡上傳到電力調度中心。特別是當整體架構規模巨大的電力輸送系統發生故障、電網發生復故障或自動裝置動作不正常時,會在短時間內產生大量的故障報警信息到達控制中心。其中包括大量的由保護或斷路器誤動、拒動,信道傳輸干擾錯誤,保護動作時間偏差等因素造成的不確定性的知識和數據。
電網調度中心工作人員面對如此紛繁復雜的報警信息,要從中快速準確的查找到故障源,判斷故障類型,進行正確的故障處理,專業知識的匱乏以及精神壓力可能會做出誤判,進而造成電網故障范圍的擴大或延長供電系統恢復時間,因此變電設備故障診斷分析是電力生產業務的重中之重。
1 電網故障診斷模型構建過程
1.1 數據選取與預處理
通過調研烏海地區的調度、生產相關主站系統數據和圖模情況,對多種電網監控系統的跨平臺數據獲取和預處理。基于電網設備拓撲模型構建運行數據、設備在線監測及歷史故障信息等多維度統一存儲方式,結合多種大數據處理方法,對多源信息進行一致性檢查、無效值剔除以及缺失值補漏,提供數據利用率。融合多種統計學模型與智能算法,建立數據關系預處理模型,對設備數據、運行數據和生產數據等多元數據進行預處理。
1.2 算法模型的選擇
數據挖掘算法的種類多種多樣,技術特點和適應性也不盡相同。因此需要根據不同的數據類型選擇最為合適的算法。本文收集的設備狀態量是在設備不同故障類型下獲得的,主要需要解決的是設備故障分類問題。由于涉及的狀態量較多,單一決策樹模型的分類性能有時無法高效解決問題。在決策樹算法的基礎上,學者專家又提出了一種具有更好的處理能力和處理效率的算法、即隨機森林算法。隨機森林算法得益于算法原理層次的隨機性和集成學習的優勢,使它在高維特征處理中具有更好的魯棒性,且抗過擬合能力更強。
1.3 基于隨機森林算法的電網設備故障診斷評估模型構建過程
樣本集的抽樣。隨機森林算法是采用Bagging方法進行抽樣的,Bagging 方法基于Bootstrap 重抽樣,可以增強樣本的隨機性。在從原始樣本集抽取樣本形成子樣本集的過程中,原始樣本集中的所有樣本都有可能被抽取。但受限算法特性,有一些樣本無法抽取,不被抽取的約為0.368。因此,隨機森林算法生成的每個子樣本集的樣本數約為原始樣本集的63.2%。子樣本集中的樣本會因Bagging 采樣特性而產生一些重復,降低了構造的決策樹產生局部最優解的可能性,優化了隨機森林算法的泛化性能。
決策樹的構建。隨機森林的隨機性體現在子樣本集生成和屬性隨機選擇的過程中,建樹過程一般調用決策樹算法。通過比較決策樹常用的ID3、C4.5、CART 算法的特點,考慮CART 算法只能生成二叉樹,ID3算法傾向于選擇取值較多的屬性作為分支節點,這會導致模型分類性能下降。而C4.5算法不僅支持多個分支,還通過引入懲罰參數計算信息增益率,解決了ID3算法存在的問題。故本文選擇C4.5算法作為隨機森林決策樹的構建方法。
隨機森林的形成和組合。按照相同的建樹過程,將Bagging 抽取的不同數據集累計構建起m 棵決策樹。將m 棵決策樹組合在一起就形成該數據集的隨機森林模型。根據各決策樹模型的輸出結果,按照規定好的投票機制(如一票否決制、少數服從多數、加權多數),決定隨機森林模型的最終輸出。
2 實例分析
2.1 樣本數據集的處理
本文收集的變壓器油中溶解氣體數據來源有烏海供電公司部分變壓器在線監測和油化試驗數據、內蒙古電網變壓器歷史故障數據和期刊論文內數據,共收集了1039個用于構建算法的變壓器油色譜樣本數據。樣本數據包括六種類型的電力變壓器(正常、低能放電、高能放電、局部放電、中低溫過熱、高溫過熱)油所中溶解的H2、CH4、C2H6、C2H4、C2H2、CO、CO2的氣體含量。然后將收集故障數據,按8∶2劃分為訓練集1378組、測試集345組。在此基礎上進行比較分析,驗證隨機森林模型的性能。實驗仿真平臺為Anaconda,編程語言為Python3.7。樣本集中各類故障類型個數為:高能放電275、高溫放電250、低能放電196、中低溫過熱152、正常狀態113、局部放電53。
2.2 模型參數的調整
調整參數的目的也是為了使模型達到泛化誤差的最低點,從而使模型獲得更高的分數。本文基于Python 的sklearn 庫對隨機森林模型的進行參數調優,主要對模型影響最大的參數決策樹的數量(n_estimators)和決策樹最大深度(max_depth)進行調優,直到最合適。調優過程中測試集的準確率變化如圖1。可看出,隨機森林的決策樹的數量和決策樹最大深度參數經過5輪160次的迭代,變壓器故障的診斷正確率分別在第58、102、13、23、82次迭代中達到最優,如表1所示。根據測試集準確率結果,最終選擇兩個參數分別50與8,準確率最佳分數為0.788461538。

表1 RF 測試集最佳參數表
2.3 模型結果分析與性能對比
2.3.1 不同模型性能對比
根據樣本集劃分,以無編碼比值作為特征參量輸入邏輯回歸模型、最近鄰算法模型、支持向量機分類模型和隨機森林模型,進行不同診斷模型的對比分析,其結果如表2所示。
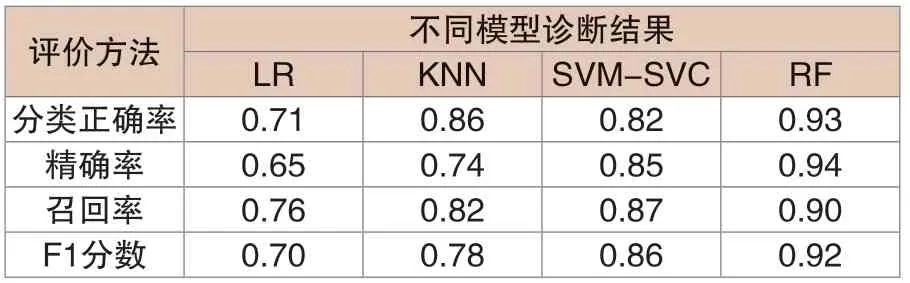
表2 不同診斷模型的結果比較
可以看出,隨機森林診斷模型的各評價指標均超過0.9,表現優秀。本文提出模型分類正確率較最近鄰算法模型、支持向量機分類模型分別提升了8%和13%,衡量整體性能的F1分數也遠高于其余算法模型,這表明本文提出的診斷模型在故障診斷分類方面具有優越的性能。
2.3.2 不同故障集結果分析
為進一步對比不同故障樣本集對模型診斷正確率的影響,將收集的樣本數據根據不同的故障類型,分為6個樣本,再按8∶2比例劃分訓練集和測試集,以未編碼比率作為特征輸入,通過比較獲得的診斷結果示于表3中。可以看出,正常數據、高能放電、中低溫過熱和高溫過熱等故障數據診斷精確率較高,F1分數也均在0.8以上,診斷性能較好。

表3 不同故障集診斷結果比較
2.3.3 不同特征量對結果的影響
為了研究這些特征屬性對于整體模型的重要程度,分析了特征屬性對模型評分的影響,結果如圖1所示。可以看出,C10(C2H2/C2H4)、C13(C2H4/C2H6)、C14(C2H4/總)、C12(C2H2/總)、C11(C2H2/C2H6)對于整體的模型的影響程度排在1至5位。前三組特征量正是《變壓器油中溶解氣體分析與判斷導則》中推薦了三比值法的特征氣體含量,這從側面證明了該模型分類的正確性。因此,對于特征量C14(C2H4/總)、C12(C2H2/總)在今后的故障診斷中,結合案例要重點關注其特征量,豐富故障的判斷依據。
將本文所開發的故障預警系統應用于烏海供電公司,通過實時分析該局110kV 新地變電站主變絕緣油色譜數據,對主變的運行狀況進行了及時預警。圖3為烏海110kV 新地變電站主變絕緣油色譜在線監測數據,表4為烏海電業局110kV 新地變電站主變故障診斷結果。

表4 故障類型診斷
通過絕緣油的熱力學研究表明,隨著故障點溫度的升高,變壓器油裂解產生的烴類氣體按CH4->C2H6->C2H4->C2H2的順序推移。故障原因的分析也隨著氣體間含量比值的變化而改變。
3 結語
本文在研究各類大數據算法的基礎上,提出一種基于隨機森林算法的變壓器故障診斷模型,并重點圍繞決策樹的數量和決策樹最大深度兩個參數進行調整。以收集到的故障變壓器油中溶解氣體數據為例,對所提故障診斷模型進行了數據訓練和仿真測試。再通過對比邏輯回歸模型、最近鄰算法模型、支持向量機分類模型以及隨機森林模型,得出提出的隨機森林模型具備更高的故障診斷正確率和性能。根據實際分析案例,證明了診斷模型的正確性和可行性,從而可以在以后的工作中將該診斷模型和系統運用于實際,更早的發現了判斷設備故障,保障地區電網安全穩定運行。
猜你喜歡
中學生數理化(高中版.高考理化)(2020年11期)2020-12-14 07:36:08
汽車維修與保養(2019年7期)2020-01-06 03:30:42
通信電源技術(2018年3期)2018-06-26 06:33:30
汽車維護與修理(2016年10期)2016-07-10 08:17:41
現代工業經濟和信息化(2016年4期)2016-05-17 05:35:38
通信電源技術(2016年3期)2016-03-26 07:13:46
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
