基于無人機RGB圖像的棉花產(chǎn)量估算
2022-11-29 12:39:12張靜郭思夢韓迎春雷亞平邢芳芳杜文麗李亞兵馮璐
中國農(nóng)業(yè)科技導報 2022年11期
張靜,郭思夢,韓迎春,雷亞平,邢芳芳,杜文麗,李亞兵,*,馮璐,*
(1.鄭州大學農(nóng)學院,棉花生物學國家重點實驗室鄭州大學研究基地,鄭州 450000;2.中國農(nóng)業(yè)科學院棉花研究所,棉花生物學國家重點實驗室,河南 安陽 455000)
棉花是我國最重要的經(jīng)濟作物之一,棉花產(chǎn)量的快速準確估算對其精準管理和生產(chǎn)決策十分重要。傳統(tǒng)的作物產(chǎn)量估算主要依靠田間測產(chǎn)調(diào)查,不僅費時費工,而且準確性較低[1]。近年來,遙感技術在農(nóng)業(yè)生產(chǎn)監(jiān)測中應用越來越廣泛。衛(wèi)星遙感技術由于易受天氣影響不能滿足田塊尺度監(jiān)測的需要[2-3],而低空無人機遙感技術具有便于攜帶、低成本、高分辨等優(yōu)點[1,4],彌補了這一缺點,已成為精準農(nóng)業(yè)研究的熱門方向。
目前,國內(nèi)外學者基于無人機搭載不同圖像采集器(可見光相機、熱紅外相機、多光譜相機)對作物表型信息開展了大量研究[5-6],實現(xiàn)了對作物生長參數(shù),如株高[7]、生物量[8]、葉面積指數(shù)[9-10]等的有效評估。近年來,作物產(chǎn)量估算成為無人機生產(chǎn)監(jiān)測的重要研究內(nèi)容。王來剛等[11]基于多光譜圖像提取植被指數(shù)建立玉米估產(chǎn)模型,發(fā)現(xiàn)與單生育期相比,多生育期估算效果更好。申洋洋等[12]基于無人機的多光譜圖像利用結合機器學習算法提取植被指數(shù),建立了小麥產(chǎn)量估算模型,在抽穗期估算效果最好。此外,基于可見光相機采集的RGB圖像提取顏色、紋理等[13]特征,在小麥產(chǎn)量估測[14-15]中也得到了較好的驗證,且多特征融合比單一特征估算精度高;多類型圖像特征融合(如多光譜和熱紅外)較單一類型圖像特征估算精度高[16]。因此,無人機遙感技術在作物產(chǎn)量估算中具有良好的應用前景。然而,現(xiàn)有的圖像獲取大多是在同一飛行高度進行,研究發(fā)現(xiàn)3 m高度下的水稻估算產(chǎn)量模型優(yōu)于6和9 m[17],但是不同高度的比較研究仍然較少,此外,基于無人機估算作物產(chǎn)量的研究多集中于小麥、玉米等糧食作物,對棉花的研究相對較少,且已有關于棉花產(chǎn)量估算方面的研究多是基于多年氣象和棉花物候信息對全省范圍的產(chǎn)量建立模型[18-19],或者是通過光譜圖像對中型田塊進行棉花產(chǎn)量估算[1,20],少見基于無人機RGB圖像對田塊尺度的棉花產(chǎn)量估算。
因此,本研究以棉花為研究對象,通過無人機搭載可見光相機采集不同生育時期和不同高度的RGB圖像,為解決單一因素的預測精度不高的問題[4,6],提取顏色指數(shù)特征和紋理特征并將其結合,通過逐步回歸分析和因子分析2種方法處理數(shù)據(jù),建立多元回歸模型估算棉花產(chǎn)量,對比分析不同生育時期和不同高度建立的棉花產(chǎn)量估算模型,篩選出建模的最佳生育時期和最優(yōu)高度。旨在為利用無人機快速估算棉花產(chǎn)量提供參考。
1 材料與方法
1.1 研究區(qū)域與試驗設計
本試驗于2020年7月至2020年9月在河南省安陽市白璧鎮(zhèn)中國農(nóng)業(yè)科學院棉花研究所東場試驗基地(36°06′N,114°21′E)開展。供試棉花品種為魯棉研28(SCRC28)。試驗田共設24個小區(qū),各小區(qū)面積為64 m2(8 m×8 m),種植行間距0.8 m,共10行。每組6個小區(qū),均設置6個密度處理(1.5、3.3、5.1、6.9、8.7、10.5萬株·hm-2),共4次重復(重復Ⅰ~Ⅳ)。棉花田間管理采用常規(guī)高產(chǎn)管理方式。
1.2 棉花產(chǎn)量測定
在收獲期按小區(qū)實收測產(chǎn),2020年分別在9月28日和11月2日收取2次棉絮,10月29日收獲青鈴,將其相加計算實收籽棉產(chǎn)量,公式如下。

式中,Y1為收取棉絮后計算的產(chǎn)量,kg·hm-2;Y2為收取的青鈴產(chǎn)量,Y為總籽棉產(chǎn)量,W1為籽棉毛重,W2為口袋重,W3為小區(qū)青鈴重,單位均為kg;S指小區(qū)面積,單位為hm2。
1.3 圖像獲取與處理
本研究采用大疆精靈四旋翼無人機平臺,搭載2 048萬像素CMOS傳感器,F(xiàn)OV84°鏡頭,自動對焦。分別在棉花花鈴期和吐絮期采集冠層圖像,采集時間分別為7月10日至8月21日和8月25日至9月25日,各采集10次,圖像采集當天時間為9∶00—10∶00,選擇晴朗無風天氣,陰雨天氣順延。飛行高度分別設置為20、30和40 m,每隔4 d采集1次,各小區(qū)在每個高度下各采集1幅圖像,總計72幅圖像。鏡頭垂直向下,獲取圖像像素大小為5 472×3 078,同步存儲于Micro SD卡,以JEPG格式導入計算機中。
借助Photoshop CC2019和PyCharm 2020.2.3軟件對RGB棉花冠層圖像進行預處理和特征提取。預處理包括圖像裁剪、分割、灰度化處理等。裁剪是按照小區(qū)劃分裁剪成單一密度圖像,并將裁剪后的圖像保存為JPG格式;通過HSV閾值分割方法將棉株和背景(土壤、傳感器等)分離;采用視覺法對分割后的圖像進行灰度化進而提取紋理特征。經(jīng)預處理后,棉花花鈴期和吐絮期各飛行高度分別獲得240幅冠層圖像。
1.4 圖像特征參數(shù)計算
1.4.1 顏色指數(shù)特征提取圖像有多種顏色空間,無人機獲取的原始圖像是基于RGB彩色空間的[21]。本研究基于分割后的棉花冠層圖像提取RGB顏色特征值,為了減少陰影的影響,首先對其進行歸一化處理并計算出r、g、b值,然后根據(jù)不同組合計算12個可見光顏色指數(shù)(color index,CI)[22-26],分別是可見光大氣阻抗植被指數(shù)(visible atmospherically resistant index,VARI)、超綠植被指數(shù)(excess green vegetation index,EXG)、超紅植被指數(shù)(excess red vegetation index,EXR)、超藍植被指數(shù)(excess blue vegetation index,EXB)、綠紅差值指數(shù)(excess green minus excess red vegetation index,EXGR)、歸一化差分指數(shù)(normalized greenred difference index,NDI)、改良綠紅植被指數(shù)(modified green red vegetation index,MGRVI)、Woebbecke指數(shù)(woebbecke index,WI)、川島指數(shù)(kawashima index,IKAW)、綠葉指數(shù)(green leaf algorithm,GLI)、紅綠藍植被指數(shù)(red green blue vegetation index,RGBVI)、植物指數(shù)(vegetativen,VEG)。

式中,r、g、b分別為色度坐標,R、G、B分別為各分量的最大值。
1.4.2 紋理特征提取紋理反映了物體本身的屬性,整體上表現(xiàn)出某種規(guī)律性,其灰度分布具有周期性[21]。數(shù)字圖像中的紋理是相鄰像素的空間位置變化的視覺表現(xiàn)[21]。本研究基于灰度共生矩陣(gray-level co-occurrence matrix,GLCM)[14,27]和Tamura紋理特征[28-29]提取灰度圖像的紋理特征(textural feature,TF)。其中,灰度共生矩陣選擇了4個常用參數(shù),分別是能量(energy)、對比度(contrast)、熵(entropy)、逆差分矩(inverse different moment,IDM);而Tamura紋理特征選擇的3種常見指標是粗糙度(coarseness)、對比度(contrast)、方向度(directionality)。
1.5 產(chǎn)量估算
本文主要使用逐步回歸分析(stepwise regression,SWR)和因子分析(factor analysis,FN)方法對RGB圖像特征數(shù)據(jù)進行處理并建立多元回歸模型,主要步驟為:①各生育時期采集的10次圖像提取特征值計算平均值;②結合圖像特征參數(shù)(12個顏色指數(shù)特征、7個紋理特征),利用逐步回歸分析方法對所有特征值進行篩選,同時利用因子分析方法處理特征值,得到方差貢獻率高于90%的因子;③分別探討圖像特征參數(shù)與產(chǎn)量建立的模型,確定估算棉花產(chǎn)量的最佳生育時期和最佳高度;④選擇重復Ⅰ~Ⅲ為建模數(shù)據(jù)集,對建立的模型進行分析,用未參與建模的重復Ⅳ樣本驗證產(chǎn)量估算模型的精度。
逐步回歸分析原理是依次不斷反復引入自變量直到將所有顯著變量引入,采用F檢驗和t檢驗進行顯著性檢驗,最終將不顯著自變量刪除后得到最優(yōu)解釋變量集[30];因子回歸是利用降維方法將多變量歸結為少數(shù)幾個新變量,即因子的統(tǒng)計[31-32]。
1.6 評價指標
本研究采用決定系數(shù)(R2)、平均絕對百分比誤差(mean absolute percentage error,MAPE)、均方根誤差(root mean square error,RMSE)和標準均方根誤差(normal root mean square error,NRMSE)4個指標來評價預測值與實測值擬合性。R2越大模型擬合效果越好;MAPE、RMSE越小模型精度越高;NRMSE越小,預測值和實測值一致性越好。
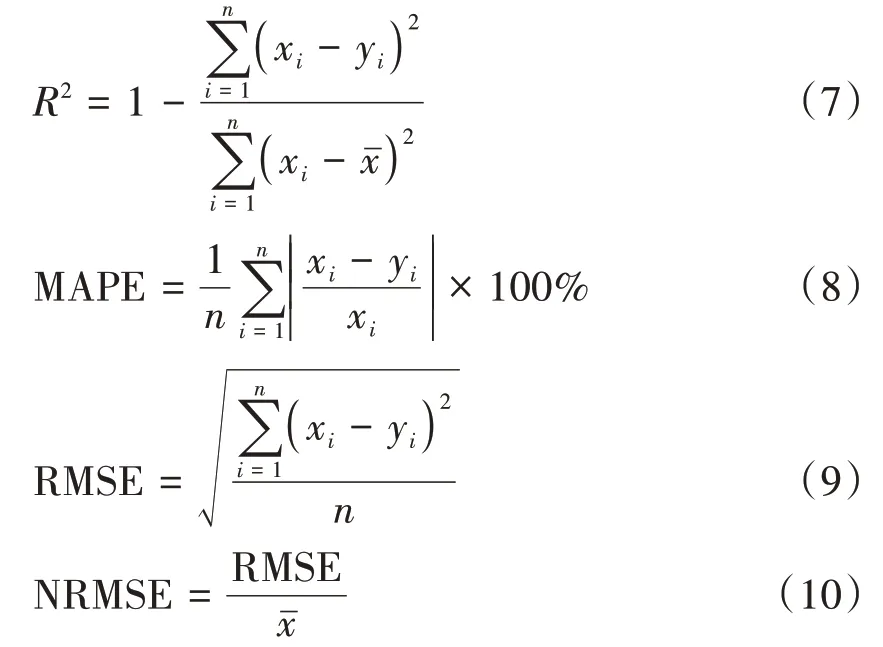
式中,xi為實測的棉花產(chǎn)量,為實測的棉花產(chǎn)量平均值;yi為預測的棉花產(chǎn)量;n為樣本數(shù)。
2 結果與分析
2.1 特征值篩選和因子選擇結果
將顏色指數(shù)特征和紋理特征結合起來,分別進行逐步回歸分析和因子分析。逐步回歸結果如表1所示,可以看出,WI、方向度和IKAW、方向度分別是高度20 m花鈴期和吐絮期篩選后的特征值;WI、ENG和WI分別是高度30 m花鈴期和吐絮期的影響因素;而高度40 m花鈴期和吐絮期篩選的特征值分別是IDM和粗糙度。表2中FA1、FA2、FA3分別表示不同高度、不同生育時期經(jīng)因子分析后貢獻率超90%的3個因子,經(jīng)計算得出各因子的系數(shù)值如表2所示。
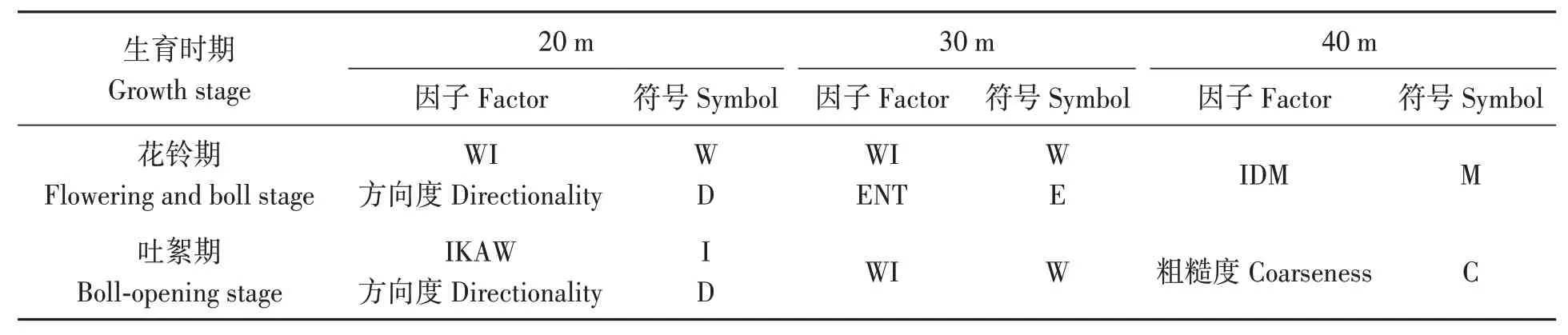
表1 逐步回歸分析結果Table 1 Results of stepwise regression analysis
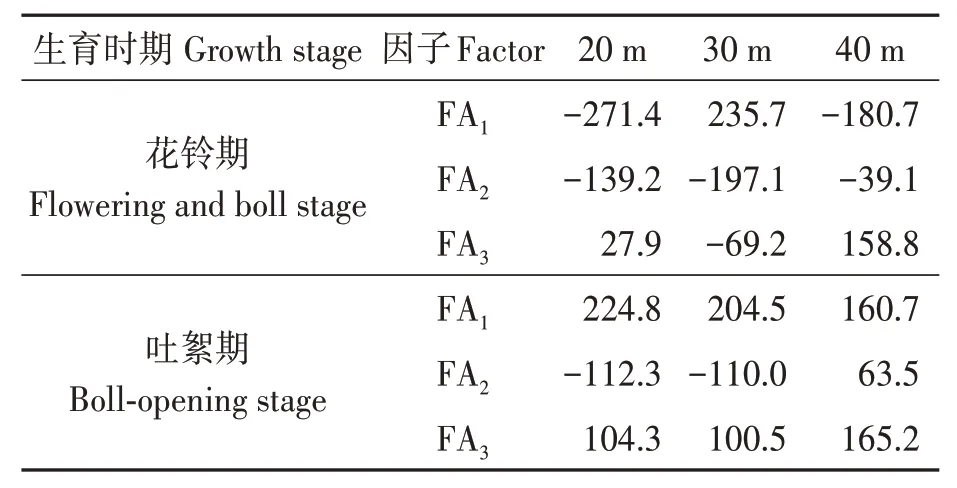
表2 因子分析結果Table 2 Results of factor analysis
2.2 不同產(chǎn)量模型擬合效果分析
分別將逐步回歸篩選出的特征值以及因子分析得出的因子與產(chǎn)量建立多元回歸模型,對同一高度下花鈴期和吐絮期的產(chǎn)量估算模型進行對比分析。由表3可知,在20 m高度下,花鈴期的R2比吐絮期高,RMSE、NRMSE比吐絮期低;在30 m高度下,花鈴期的R2均在0.7以上(=0.784 9,=0.757 4),而吐絮期的R2僅為0.415 9和0.505 2,RMSE、NRMSE均比花鈴期低;在40 m高度下,花鈴期和吐絮期的R2都在0.5左右,RMSE、NRMSE值較高,模型擬合效果一般。綜合來看,20和30 m的高度下,花鈴期產(chǎn)量估算模型擬合度均優(yōu)于吐絮期且擬合效果較好,而40 m高度花鈴期和吐絮期擬合效果一般。
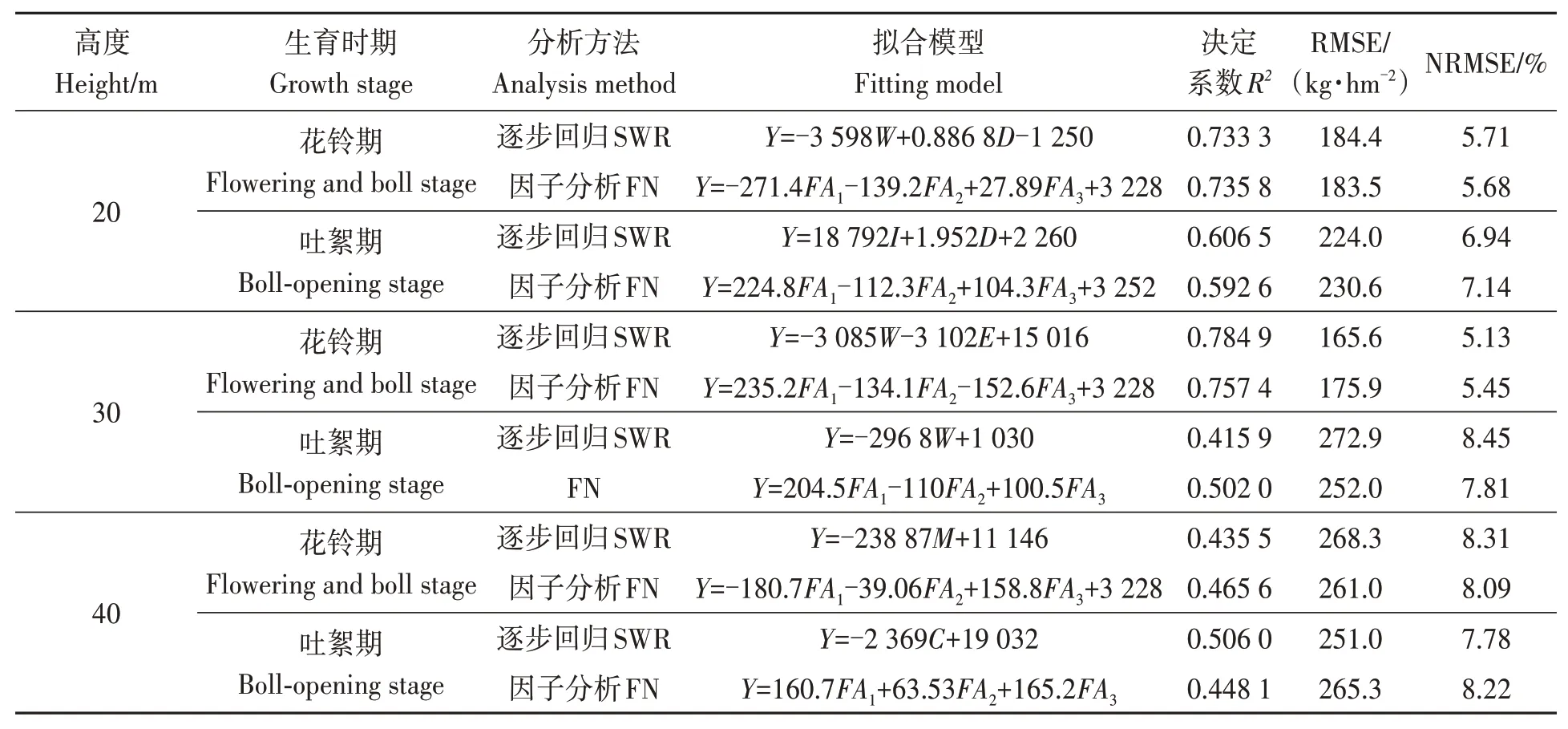
表3 不同產(chǎn)量模型對比分析Table 3 Comparative analysis of different yield models
2.3 不同生育時期產(chǎn)量模型驗證分析
2.3.1 高度20 m模型分析對建立的產(chǎn)量估算模型進行驗證分析,結果表明,對于高度20 m(圖1)建立的模型,在花鈴期通過逐步回歸方法建立的模型驗證結果顯著(P<0.05)而通過因子分析方法建立的估產(chǎn)模型不顯著(P>0.05);在吐絮期兩種方法建立的估產(chǎn)模型驗證結果都顯著(P<0.05),其中,通過因子分析方法的R2更高、擬合效果更好,但通過逐步回歸方法驗證的R2與之僅相差約0.05,而MAPE、RMSE和NRMSE更小,其模型具有更高的精度,與實測產(chǎn)量的一致性更好。綜合對比逐步回歸方法在花鈴期和吐絮期的擬合模型和驗證結果,花鈴期的產(chǎn)量估算模型擬合效果更好,模型精度更高。
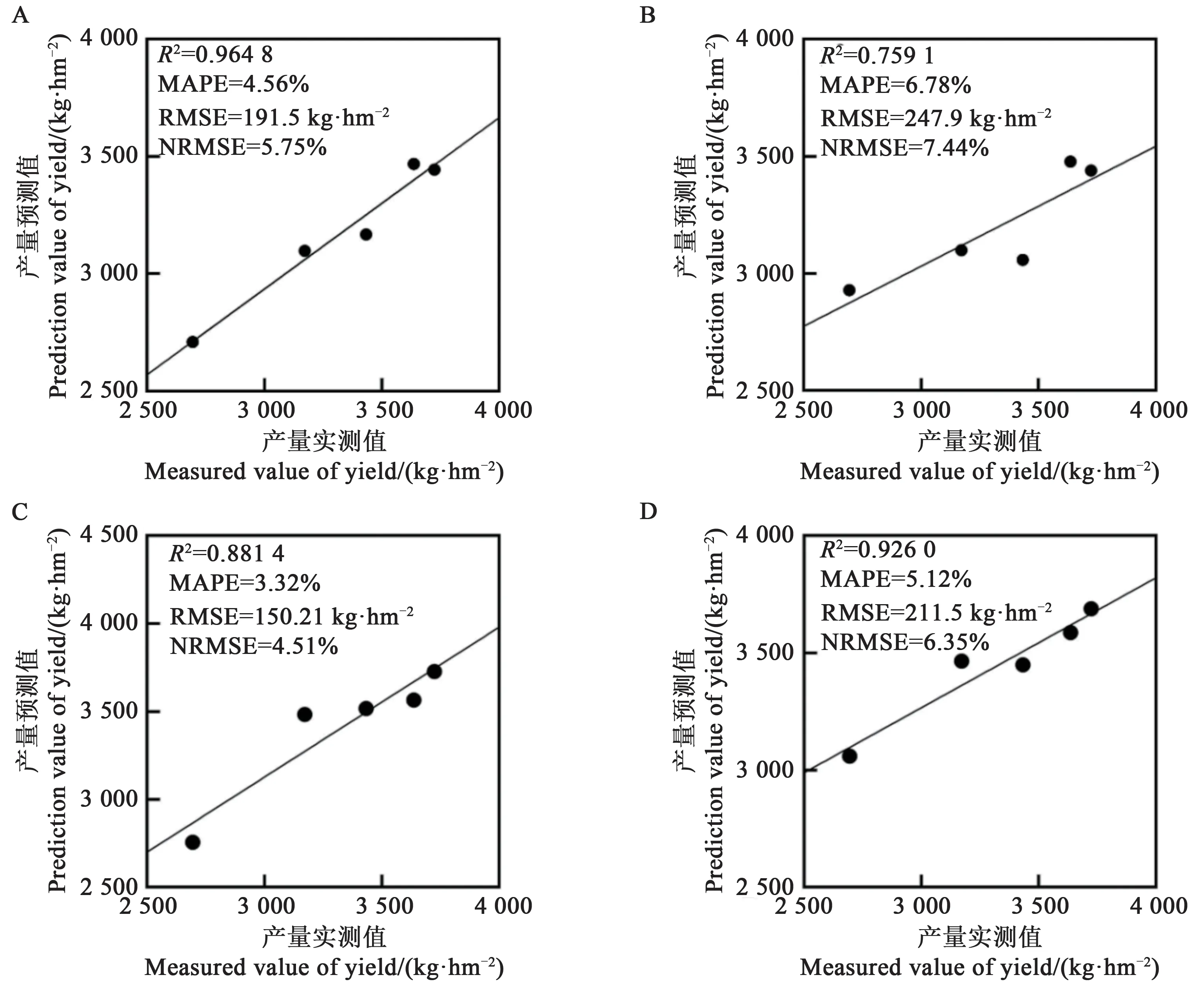
圖1 高度20 m花鈴期和吐絮期產(chǎn)量估算模型驗證結果Fig.1 Verification results of flowering and boll development stage and boll-opening stage yield estimation model at the height of 20 m
2.3.2 高度30 m模型分析 在30 m高度(圖2)下觀察到了類似的結果,無論是花鈴期還是吐絮期,驗證結果均顯著(P<0.05)。所有驗證的R2均達到了0.9以上,通過逐步回歸驗證的4個評價指標(R2、MAPE、RMSE和NRMSE)均優(yōu)于因子分析方法的驗證結果;對比通過逐步回歸方法在花鈴期和吐絮期的模型驗證結果,花鈴期的R2更高、擬合效果更好,RMSE和NRMSE更小,說明其模型具有更高的精度、與實測產(chǎn)量的一致性更好。因此,綜合對比產(chǎn)量估算模型和驗證結果,通過逐步回歸方法在花鈴期建立的產(chǎn)量估算模型擬合效果更好,模型精度更高。
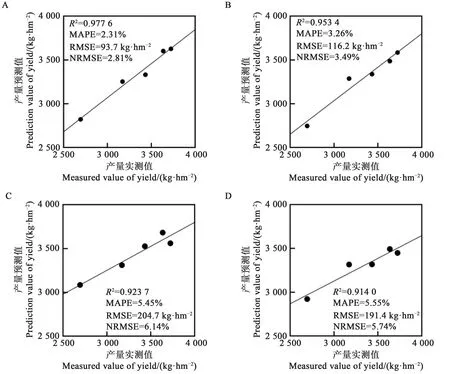
圖2 高度30 m花鈴期和吐絮期產(chǎn)量估算模型驗證結果Fig.2 Verification results of flowering and boll development stage and boll-opening stage yield estimation model at the height of 30 m
2.3.3 高度40 m模型分析40 m建立的產(chǎn)量估算模型驗證結果如圖3所示,可以看出,吐絮期驗證的R2在0.8以上(=0.801 2,=0.946 9),但與擬合模型相差較大(=0.506 0,=0.448 1)(表3),盡管通過逐步回歸方法驗證的R2比因子分析方法低,但MAPE、RMSE和NRMSE均比因子分析小,因此,與通過因子分析方法預測的結果相比,逐步回歸方法預測值更接近實測值。
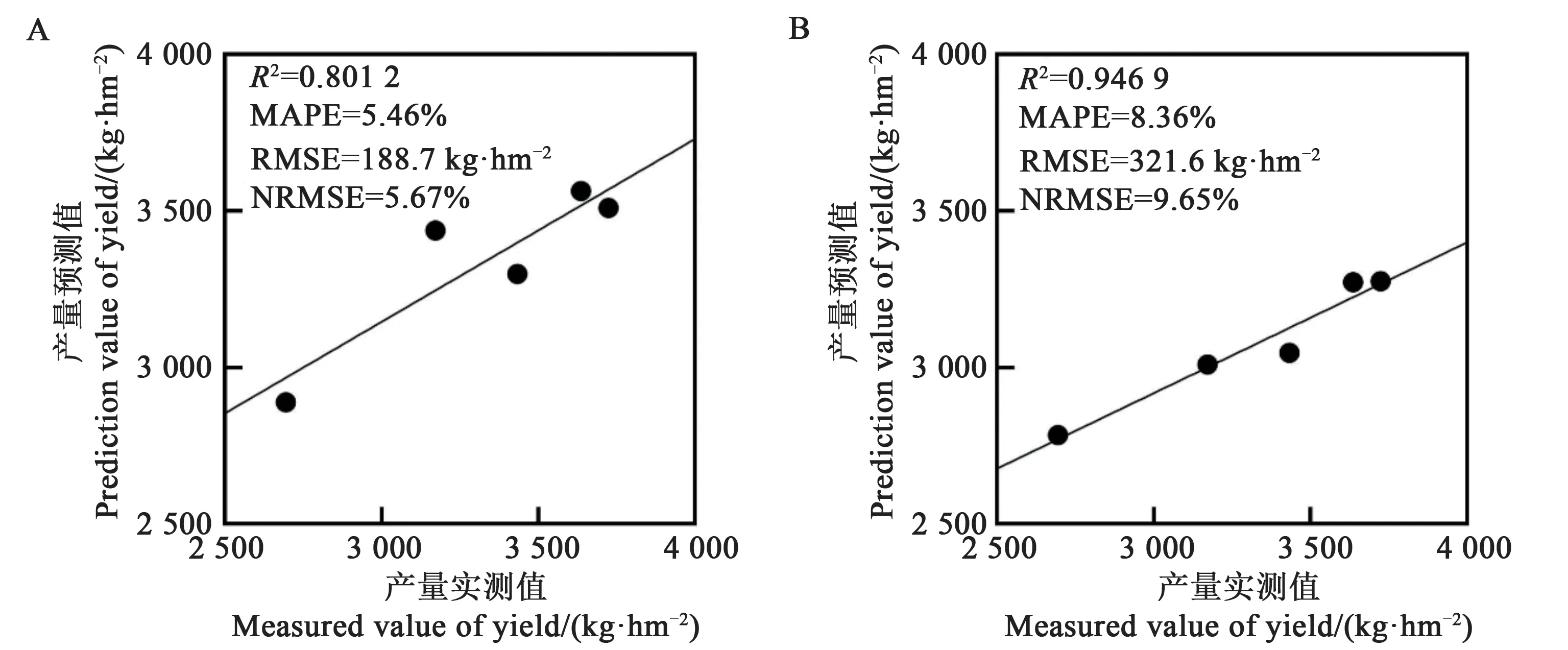
圖3 高度40 m吐絮期產(chǎn)量估算模型驗證結果Fig.3 Verification results of boll-opening stage yield estimation model at the height of 40 m
綜合來看,3個高度的2種方法對比結果均顯示,通過逐步回歸方法建立的產(chǎn)量估算模型擬合度和精度優(yōu)于因子分析方法。在高度20 m花鈴期建立的產(chǎn)量估算模型預測效果更好、精度更高;高度30 m在花鈴期建立的產(chǎn)量估算模型預測效果和精度相當;而40 m高度下,與花鈴期相比,在吐絮期建立的產(chǎn)量估算模型效果更好,但擬合效果一般,穩(wěn)定性較差。
2.4 不同高度模型對比
進一步比較通過SWR方法在20(花鈴期)、30(花鈴期)和40 m(吐絮期)3個高度下建立的3個模型并篩選出產(chǎn)量估算模型的最佳高度和最佳生育時期。由表3可知,高度30 m在花鈴期建立的模型R2(0.784 9)最高,20 m高度下在花鈴期建立的模型的R2(0.733 3)次之,高度40 m在吐絮期的R2(0.506 0)最低,而RMSE和NRMSE的值從小到大依次是高度30、20、40 m。綜合來看,在花鈴期、高度為30 m建立的產(chǎn)量估算模型擬合度優(yōu)于20和40 m。
分析3個擬合模型的驗證結果可知(圖1~3),以花鈴期、高度30 m圖像建立的模型驗證結果R2(0.977 6)最高,MAPE(2.31%)、RMSE(93.7 kg·hm-2)和NRMSE(2.81%)最小,與擬合的指標相差最小。因此,無論是從模型擬合度還是驗證集的評估指標來看,高度30 m下的模型擬合度最好、穩(wěn)定性最強、精度最高。
綜合不同生育時期、不同高度的分析結果,產(chǎn)量估算模型的最佳生育時期為花鈴期,最優(yōu)高度為30 m。
3 討論
多項研究表明,作物產(chǎn)量和圖像顏色特征、紋理特征存在相關性并能夠擬合模型進而估測產(chǎn)量,如龔紅菊[32]驗證了基于紋理特征估算水稻產(chǎn)量的可行性。但是通過無人機獲取圖像時,光照條件不同可能導致基于單一特征指數(shù)的預測效果隨機性較大,將顏色特征和紋理特征結合,其結果比單一顏色特征建立的小麥產(chǎn)量預測模型精度高[14]。本研究選擇結合棉花冠層圖像的顏色指數(shù)特征和紋理特征對產(chǎn)量進行估算并得到較穩(wěn)定的模型,與萬亮等[6]研究結果一致。
本研究探討了不同棉花生育時期建立的產(chǎn)量估算模型,但在不同的生育時期預測效果不同,高度20和30 m下,花鈴期建模效果均優(yōu)于吐絮期,模型擬合程度更高、驗證結果更顯著。劉煥軍等[33]基于時間序列Landsat影像建立棉花最優(yōu)產(chǎn)量估算模型,發(fā)現(xiàn)其隨著生長階段表現(xiàn)出差異,得出花鈴期更適合棉花產(chǎn)量估測的結果,與本研究結果一致。而在40 m高度下,吐絮期產(chǎn)量估算模型擬合度優(yōu)于花鈴期,但擬合模型的R2與驗證數(shù)據(jù)集相差較大,盡管棉絮占產(chǎn)量的大部分,但吐絮期葉片大量脫落、棉株倒伏[34]等原因可能導致提取特征不精確,也可能與樣本數(shù)量較少有關。本研究用一年數(shù)據(jù)進行建模,而田間試驗受氣溫、降水等自然環(huán)境條件、管理措施等影響較大[35],擬進一步增加樣本數(shù)量以及用不同品種、不同年限的棉花數(shù)據(jù)進行分析,得到更普遍的產(chǎn)量估算模型。
本文探討了不同高度的棉花產(chǎn)量模型對比分析,得到30 m的模型預測結果最好。一般來說,不同高度對試驗地的圖像分辨率不同,飛行高度越低精度越高[36],但本文結果不同,可能與高度設置較小有關,有研究者在10[14]、30[37]、50[1]、80 m[11]都得到了較好的預測結果;也有可能與采集圖像時的風力、光照變化[38]及預處理時使用的圖像分割方法相關。因此,今后可以設置更多高度梯度以找出更合適的飛行高度進一步優(yōu)化棉花產(chǎn)量估算模型,也可以基于聚類和深度學習[39]等方法對圖像進行分割處理找出更合適的分割算法。本研究結果表明,通過提取圖像特征建立產(chǎn)量估算模型是可行的,但仍需要進行更多的研究,例如氣候、農(nóng)藝性狀等信息與圖像結合進一步建立更復雜的模型。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
礦山安全信息(2022年40期)2022-04-07 02:16:52
當代水產(chǎn)(2021年10期)2021-12-05 16:31:48
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
今日農(nóng)業(yè)(2020年20期)2020-11-26 06:09:10
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
聚氯乙烯(2018年9期)2018-02-18 01:11:34
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
