基于YOLOv3算法與3D視覺的農業采摘機器人目標識別與定位研究*
2022-12-02 06:03:58高帥劉永華高菊玲吳丹姬麗雯
中國農機化學報 2022年12期
高帥,劉永華,高菊玲,吳丹,姬麗雯
(1. 江蘇農林職業技術學院,江蘇鎮江,212400; 2. 江蘇省現代農業裝備工程中心,江蘇鎮江,212400)
0 引言
隨著工業化和城鎮化的不斷發展,從事直接農業勞動人口開始不斷減少,此外人口老齡化也已成為不可避免的事實,這一切都導致農業勞動力成本持續上升,因此后工業化時期農業機械化逐漸向智能化發展[1]。而農業采摘是最費勞動力、最難實現智能化作業的環節,農業采摘機器運行環境復雜,不確定環境因素較多,對農業采摘目標的準確識別和精準定位是實現機器人采摘的重要前提[2-4]。隨著3D視覺技術的發展,賦予了農業機器類似人眼一樣的視覺功能,研究人員在采摘蘋果[5]、番茄[6]、草莓[7]、櫻桃番茄[8]等果蔬領域展開了一系列的研究,且開發了相應的農業采摘機器人,但目前尚未有成熟應用的商業案例,還需進一步優化算法結構,提高果實目標的識別與定位精度。
基于視覺的目標識別方法經歷了傳統數字圖像處理技術、機器學習的圖像分割技術和分類器以及深度學習的卷積神經網絡算法[9]。傳統數字圖像處理技術依靠采集圖像的顏色、紋理和形狀或者多個特征的融合。機器學習的圖像分割技術和分類器通過擬定訓練方法,對輸入輸出進行評估預測,如王瑾等[10]提出一將AdaBoost分類器和顏色特征分類器相結合用于番茄采摘機器人的目標識別方法;李寒等[11]提出一種基于RGB-D圖像和K-means優化的算法來進行果實的識別與定位,有著較強的準確性和魯棒性。
由于農業采摘機器人容易受到采摘目標形狀不同、大小不同、外界影響環境復雜的影響,傳統目標識別方法準確率和定位精度效果并不理想,而深度學習具有很強的學習能力,受環境干擾程度比較小,特別是深度學習的卷積神經網絡算法已經被廣泛應用于果實的檢測識別與定位領域。近年來已經出現AlexNet網絡模型[12]、Fast RCNN深度卷積神經網絡[13]、Mask RCNN網絡模型[14]、SDD網絡模型[15-16]、YOLO模型[17-18]等算法用于農業機器人的采摘,但各種算法不具備通用性,對每種采摘對象的識別和定位能力也不相同,這也進一步制約了農業機器人的發展。本文以番茄為研究對象,提出一種改進的YOLOv3卷積神經網絡算法與3D視覺技術相結合的方法,實現農業采摘機器人目標的準確識別和精準定位,并與之前的YOLOv3算法、Fast RCNN算法和Faster RCNN算法進行綜合比較,對于農業采摘機器人的識別定位發展具有重大意義。
1 目標識別算法
基于卷積神經網絡的YOLOv3算法,不同于以往的YOLO算法,YOLOv3算法是YOLO算法的改進版本,它采用了殘差模型,去除了池化層,使用Darknet-53(包含53個卷積層)進行特征圖像的提取;同時YOLOv3算法采用了FPN架構,使得網絡架構更深,可以實現目標的多尺度檢測,檢測精度進一步得到提升[19]。
YOLOv3算法主要由卷積層、Darknet-53結構、Res層和YOLO層組成[20-21],網絡結構流程如圖1所示,其中Conv代表卷積、Res代表殘差塊、CBL代表Conv與批量正則Leaky ReLU激活函數的合成。YOLOv3算法的基本流程是通過Darknet-53結構將輸入圖片(416像素×416像素)輸出成最小尺度(13像素×13像素)、中尺度(26像素×26像素)、最大尺度(52像素×52像素)的特征圖,運用Logistic Regression算法將3組9個先驗框進行線性回歸求解,并將置信度最高分作為圖像的最終預測結果輸出。
置信度反映了目標落在特定框區域的真實性程度,判斷公式如式(1)所示。
(1)
式中:score——置信度的置信值;
Pr(Object)——預測框訓練樣本的概率;
IOU——候選框與原標記框的交疊率。

圖1 YOLOv3網絡結構示意圖
作為對誤檢測樣本懲罰的依據,YOLOv3算法損失函數對檢測精度的影響至關重要。YOLOv3算法損失函數主要包括目標坐標預測的損失、預測框置信度的損失和分類的損失。
Lcoord=λxyδ(x,y)+λwhδ(w,h)
(2)
Lconf=λconfδ(conf)
(3)
Lclass=λclassδ(class)
(4)
Loss=Lcoord+Lconf+Lclass
(5)
式中:Loss——YOLOv3總損失;
Lcoord——目標坐標預測的損失;
Lconf——預測框置信度的損失;
Lclass——分類的損失;
λxy——中心誤差權重系數;
λwh——寬高誤差權重系數;
λconf——置信度誤差權重系數;
λclass——分類誤差權重系數;
δ(x,y)——預測邊界框中心坐標(x,y)的誤差函數;
δ(w,h)——預測邊界框寬w和高h的誤差函數;
δ(conf)——預測置信度的誤差函數;
δ(class)——目標物體類別的誤差函數。
提出的改進YOLOv3算法是以YOLOv3算法為基本結構,在YOLOv3第一級檢測之前加上一個SPP模塊,通過改進模型可以實現小目標的精準識別,降低漏檢率。SPP模塊是由3個不同尺度的最大池化層組成的結構,如圖2所示。其中Maxpool代表最大值池化,/1代表步長stride=1。

圖2 SPP模塊示意圖
2 目標識別定位
2.1 目標識別定位系統
目標識別定位系統主要包含3D圖像采集軟件和遠程動作執行軟件,采用3D視覺相機里的深度相機獲取采摘對象的立體信息,同時通過主相機獲取空間顏色信息,通過計算機的圖像識別與3D位置數據分析后,可以實現快速立體定位采摘對象。3D圖像采集主要是顯示作業實時采集圖像,在相機計算機中運行,如圖3(a)所示;遠程執行軟件主要是進行算法的選擇、相機坐標標定、圖像處理、機械臂手動測試、手動與自動目標識別與定位等功能,在客戶端計算機中運行,如圖3(b)所示。
農業采摘機器人3D視覺相機采用MYNTAI 3D雙目視覺相機,位于整機上部,并可在空間范圍內實現多角度的無級調整,利用視覺識別信息指導機器人進行行駛路線規劃和尋找采摘目標的識別與定位功能。3D視覺相機的主要參數如表1所示。

(a) 3D圖像采集軟件

(b) 遠程動作執行軟件

表1 相機主要參數Tab. 1 Camera main parameters
2.2 目標坐標轉換
由于3D視覺相機視野中捕獲目標物體的坐標系與機器人坐標系不一致,它們各自的坐標沒有聯系,所以為了使兩者坐標系形成關聯,以便引導機器人進行采摘,故需要將相機的坐標系變換到機器人坐標系中,即進行標定。要完成農業采摘機器人與物體的坐標變換標定,需要一個4×4的矩陣,這個矩陣包含著一個旋轉矩陣(3×3)和一個平移矩陣(1×3),主要步驟如圖4所示。
步驟1:選擇標定點:選擇四個差異化的標定點,比如遠近位置各不相同,同時又應該在相機的拍攝范圍和機械臂的可采摘范圍之內。
步驟2:目標圖像采集:確保機器人在采摘初始位置,相機在初始采摘位置拍照。
步驟3:記錄像素坐標:根據3D視覺相機拍攝照片,標定出目標位置的x,y,z的value值。
步驟4:記錄世界坐標:利用示教器遙控機械臂到當前標定點所在的果實位置,記錄下示教器的位置X,Y,Z的value值。
步驟5:相機標定數據:重復步驟3和步驟4,記錄下四個標定點的相機像素坐標、機器人世界坐標,得到相機標定數據,將標定數據填入農業采摘機器人軟件平臺中,點擊生成變換矩陣,至此完成兩個坐標系的轉換。


(a) 選擇標定點 (b) 目標圖像采集


(c) 記錄像素坐標 (d) 記錄世界坐標
3 試驗與結果分析
為驗證基于改進YOLOv3算法與3D視覺的目標識別與定位系統的可靠性和優越性,本文對其進行了模型訓練和測試。所用計算機的CPU型號為Inter Core i7-10700,CPU頻率為2.9 GHz,性能級獨立顯卡,顯卡芯片為AMD Radeon RX 550X,內存容量為16 G,操作系統為Windows 10 64位簡體中文版,開發語言為python。
3.1 模型訓練分析
目標圖像數據采集在江蘇農博園番茄溫室進行,為了保證樣本的多樣性,拍攝全天不同時間、不同角度、不同位置、不同品種類型的圖像1 334張。按照訓練集和測試集按照3∶1比例進行分配,其中訓練集1 000 張、測試集334張,通過Labelimg軟件對數據集中的番茄位置和類別信息進行手工標注。
然后利用候選框與原標記框的交疊率IOU、準確率P、召回率R來進行模型性能的評估,如式(6)、式(7)所示。
(6)

(7)
式中:TP——IOU大于等于設定閾值的數量即預測框與標記框正確匹配的數量;
FP——IOU小于設定閾值的數量即預測錯誤的數量;
FN——IOU等于0的數量即漏檢的數量。
訓練參數設置每批量樣本個數為64,動量因子設置為0.95,權值衰減設置為0.000 5,學習率設為0.001,非極大抑制設為0.5,最大迭代次數設置為30 000。且每次迭代完成后,均保存成對應的模型,最后選出具有最高精度的模型,在訓練的過程中得到訓練損失趨勢曲線如圖5所示。

圖5 訓練損失趨勢曲線
由圖5曲線圖可以看出,在模型訓練過程中,當迭代次數小于400次時,損失函數值迅速降低至4左右;當迭代次數大于400次時,損失速度變緩,說明模型訓練效果較好,隨著迭代次數的增加,損失函數值不斷減小,在訓練迭代次數達到16 000次時,損失函數值已經趨于平穩,并穩定在0.4附近,說明迭代次數在16 000 次時停止模型訓練比較合適。
3.2 識別準確率、識別召回率和平均識別時間分析
為了驗證改進YOLOv3算法的目標識別相比于之前的神經網絡算法的可靠性和優越性,隨機抽取600個訓練樣本照片,分別利用YOLOv3算法、改進YOLOv3算法、Fast RCNN算法和Faster RCNN算法進行目標的識別,目標識別效果如圖6所示。并對目標的識別準確率、識別召回率和平均識別時間進行了比較,如表2所示。

圖6 目標識別效果
從表2的對比結果可以看出,所用改進YOLOv3算法和3D視覺的識別準確率和召回率分別達到97.2%和95.8%,改進YOLOv3算法要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的準確率要高,在同等條件下分別提高5.5%、9%、1.4%;改進YOLOv3算法同時要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的召回率要高,在同等條件下分別提高1.4%、2%、3%;改進YOLOv3算法的平均識別時間要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的少,在同等條件下分別降低20.1%、25.6%、52.1%,這表明改進YOLOv3算法完全可以滿足后期農業采摘機器人實際工況下的模型識別檢測要求。

表2 四種算法的準確率和召回率對比Tab. 2 Four algorithms comparison of accuracy and recall rate
3.3 定位結果分析
為驗證本文所提方法的定位精度,由于試驗條件所限,采用一個番茄進行定位試驗,其初始位置為(0 mm,0 mm,100 mm),每次向遠離攝像頭Z方向移動10 mm,農業采摘機器人共進行10次位置定位,分別采用Fast RCNN算法、Faster RCNN算法、YOLOv3算法和改進YOLOv3算法對采摘點進行空間定位試驗,并綜合比較四種算法的定位誤差,計算方法如式(8)所示。
(8)
式中:xli,yli,zli——第i次位置理論坐標值;
xci,yci,zci——第i次測量位置坐標值;
Elc——定位誤差。
以定位誤差來衡量最終的定位精度,如表3所示。
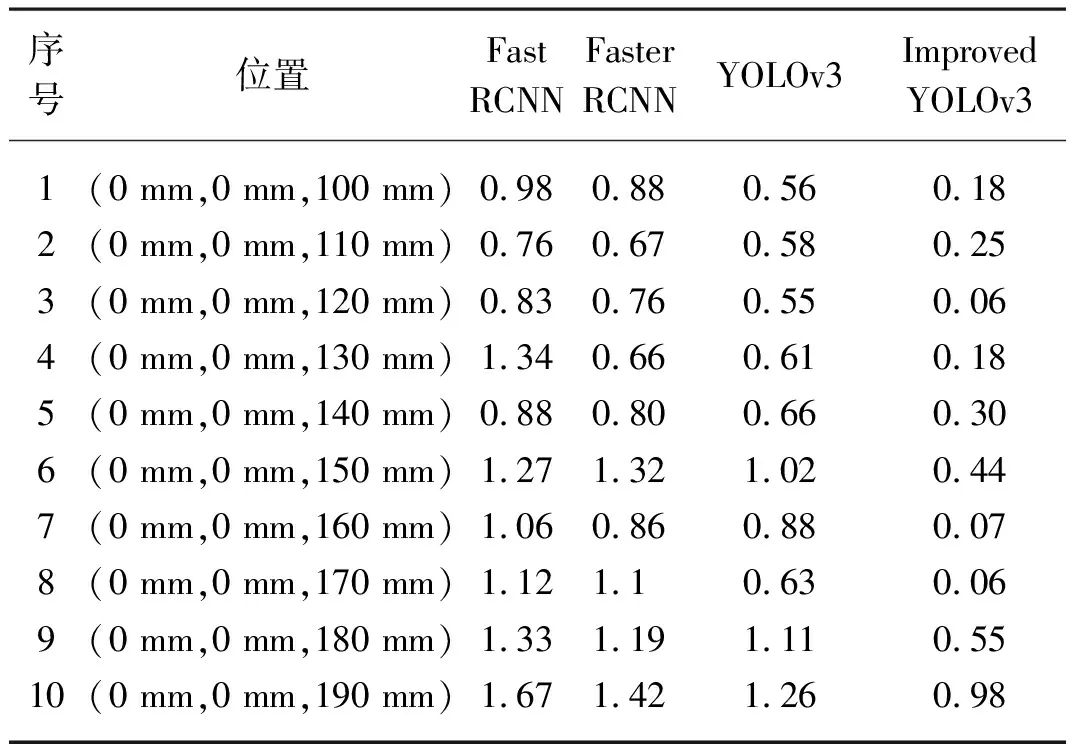
表3 四種算法的定位誤差對比Tab. 3 Four algorithms comparison of localizing error mm
從表3中可以看出Fast RCNN算法、Faster RCNN算法、YOLOv3算法在10次的定位試驗中最大定位誤差分別是1.67、1.42、1.26 mm,而改進YOLOv3算法的在10次的定位試驗中最大定位誤差只有0.98 mm,分別比Fast RCNN算法、Faster RCNN算法、YOLOv3算法的最大定位誤差降低0.69、0.44、0.28 mm,且改進YOLOv3算法的定位誤差多次在0值附近進行波動,證明了改進YOLOv3算法系統具有一定的準確性和穩定性。
4 結論
1) 傳統目標識別方法準確率和定位精度效果并不理想,本文采用改進YOLOv3算法進行了模型訓練,模型訓練效果較好,在訓練迭代次數達到16 000次時,損失函數值趨于平穩,并穩定在0.4附近,說明迭代次數在16 000次時停止模型訓練比較合適。
2) 通過試驗對比分析,改進YOLOv3算法要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的準確率要高,在同等條件下分別提高5.5%、9%、1.4%;改進YOLOv3算法同時要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法的召回率要高,在同等條件下分別提高1.4%、2%、3%;改進YOLOv3算法的平均識別時間要比YOLOv3算法、Fast RCNN算法和Faster RCNN算法降低20.1%、25.6%、52.1%,可以滿足后期農業采摘機器人實際工況下的模型識別檢測要求。
3) 通過試驗對比分析,改進后的YOLOv3算法的最大定位誤差分別比Fast RCNN算法、Faster RCNN算法、YOLOv3算法降低0.69、0.44、0.28 mm,且改進后的YOLOv3算法定位誤差多次在0值附近進行波動,證明改進后的YOLOv3算法系統具有一定的準確性和穩定性,可以更好地完成采摘工作,同時也為農業采摘機器人目標識別與定位方法的改進提供了重要的參考價值。后續研究可以對匹配算法進行進一步的完善,逐步提高農業采摘機器人識別與定位的性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
今日農業(2021年14期)2021-11-25 23:57:29
今日農業(2021年13期)2021-08-14 01:38:18
今日農業(2020年15期)2020-12-15 10:16:11
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
