改進SSD的可回收垃圾檢測方法
2022-12-06 10:38:34耿麗婷阿里甫庫爾班米娜瓦爾阿不拉蔣潤熙新疆大學軟件學院烏魯木齊830046
計算機工程與應用 2022年23期
耿麗婷,阿里甫·庫爾班,米娜瓦爾·阿不拉,丁 培,蔣潤熙新疆大學 軟件學院,烏魯木齊 830046
隨著我國經濟生活的進步,人們生活質量大幅提升,垃圾產量迅猛增加。伴隨著2019年7月1日上海市《上海市生活垃圾管理條例》的實施,垃圾分類也逐漸進入大家的視野[1]。然而如今我國垃圾的再利用主要依靠人工分揀的方式,造成人力資源浪費、分揀效率低下、資源利用率低等問題。因此,本文提出利用深度學習技術檢測可回收垃圾,提高資源利用率,促進生態文明建設。
近年來,深度學習的飛速發展,目標檢測技術也取得了矚目成就。目前主流的檢測方法,主要分為兩類[2]。一類是基于候選框的兩階檢測算法,將檢測分為兩步,先產生候選框,再對候選框分類。常見的算法有R-CNN[3]、SPPNet[4]、Fast R-CNN[5]、Faster R-CNN[6]等。另一類是基于回歸的一階檢測算法,該方法不需要產生候選框,直接將目標框定位問題轉化為回歸問題處理,雖然精度會有所損失,但是檢測速度一般比兩階算法更快。常見的算法有SSD[7]和YOLO[8-9]系列。
深度學習技術在垃圾檢測方面也取得了較大進展。Liu等人[10]提出采用MobileNet-YOLOv2[11]的輕量化的神經網絡與物聯網技術相結合,將卷積神經網絡應用于嵌入式端,降低工業檢測成本。劉恩乾[12]提出采用CBAM注意力機制和SSD算法相結合用于檢測和分類生活垃圾。寧凱等人[13]提出采用改進的YOLOv2算法嵌入到機器人中用于檢測和分類垃圾,實現了智能掃地機器人。Cui等人[14]采用YOLOv3算法檢測街道的生活垃圾、裝修垃圾以及大型垃圾,在GTX1080Ti上檢測速度可以達到60 ms。雖然以上研究為垃圾檢測任務做出了一定貢獻,但是在精度或者檢測速度等方面仍有較大的改進空間。SSD算法作為經典的目標檢測算法之一,具有檢測速度快的優勢,便于實時檢測。但是在實際應用中,需要考慮占用硬件的內存空間、檢測速度以及檢測精度等問題。而原始SSD以VGG16作為骨干網絡,存在模型參數量大的問題,難以應用于算力低的嵌入式設備中,同時隨著深度學習的不斷發展,VGG16-SSD算法的精度已經遠達不到實際需求。
因此本文主要針對可回收垃圾檢測實時性和精度的需求,以SSD算法為基礎進行改進,提出基于輕量化高精度卷積神經網絡。采用輕量的RepVGG作為骨干網絡,通過結構重參數化方式大幅減少計算量,滿足實時性要求。對SSD算法的輔助卷積層提出改進的同時引入SK模塊,動態調整感受野尺寸,提高網絡空間信息的聚合能力,提高檢測精度。實驗表明,該方法在可回收垃圾檢測任務中具有良好的檢測性能,可以更好地應用于工業。
1 傳統的SSD檢測模型
SSD模型的網絡結構如圖1所示,該結構由兩部分組成。SSD模型在特征提取部分中采用VGG16[15]結構,通過深度卷積提取多個尺度的特征圖。另一部分為輔助卷積層,通過不同尺度的卷積層輸出進行特征融合。
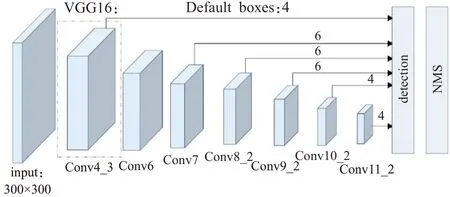
圖1 SSD模型圖Fig.1 SSD model diagram
SSD使用VGGNet作為骨干網絡時,使用了VGGNet的前13個網絡層,其中Conv4_3作為提取特征的特征圖。為了獲取更多的特征信息,在VGGNet后增加了幾層卷積結構,即組成了SSD算法的輔助卷積層。使用Conv6、Conv7取代原始VGGNet中的全連接層。Conv6中使用擴張率為6的空洞卷積,使用該結構可以在增加感受野的同時保持參數量不變。由骨干網絡和輔助卷積層生成的6個不同尺度的特征圖,如圖1中所示的Conv4_3生成大小為38×38的特征圖,Conv7至Conv11依次輸出大小為19×19、10×10、5×5、3×3和1×1的特征圖。其中淺層的特征圖用于檢測小物體,深層的特征圖用于檢測大物體。
6個特征圖分別對應人工設置的PriorBox,分別為4、6、6、6、4、4。將其與標簽邊框匹配,篩選出正負樣本,并計算損失。通過分類網絡和回歸網絡預測不同大小目標的位置和分類。
2 改進的SSD目標檢測模型
由于SSD算法采用多層特征圖進行預測,且為一階網絡,因此在速度和精度上都有較好的效果。尤其是在速度方面可以很好地應用于工業中,可滿足可回收垃圾檢測任務的速度要求。
本文試圖采用輕量級的網絡結構在保證精度的情況下,以解決由VGG16網絡造成的參數量大、內存占有率高等問題。同時對SSD算法的輔助卷積層進行改進,對比了多種卷積結構,最終選用由不對稱卷積組成的RepVGG式結構與ReLU相結合的方式作為SSD的輔助卷積層。為進一步降低參數量和計算量,采用結構重參數化提高模型的推理速度。同時對可回收垃圾數據進行研究,發現其尺寸變化大的問題,因此引入了SK模塊旨在提高網絡結構的檢測準確率。算法的具體網絡結構如圖2所示。
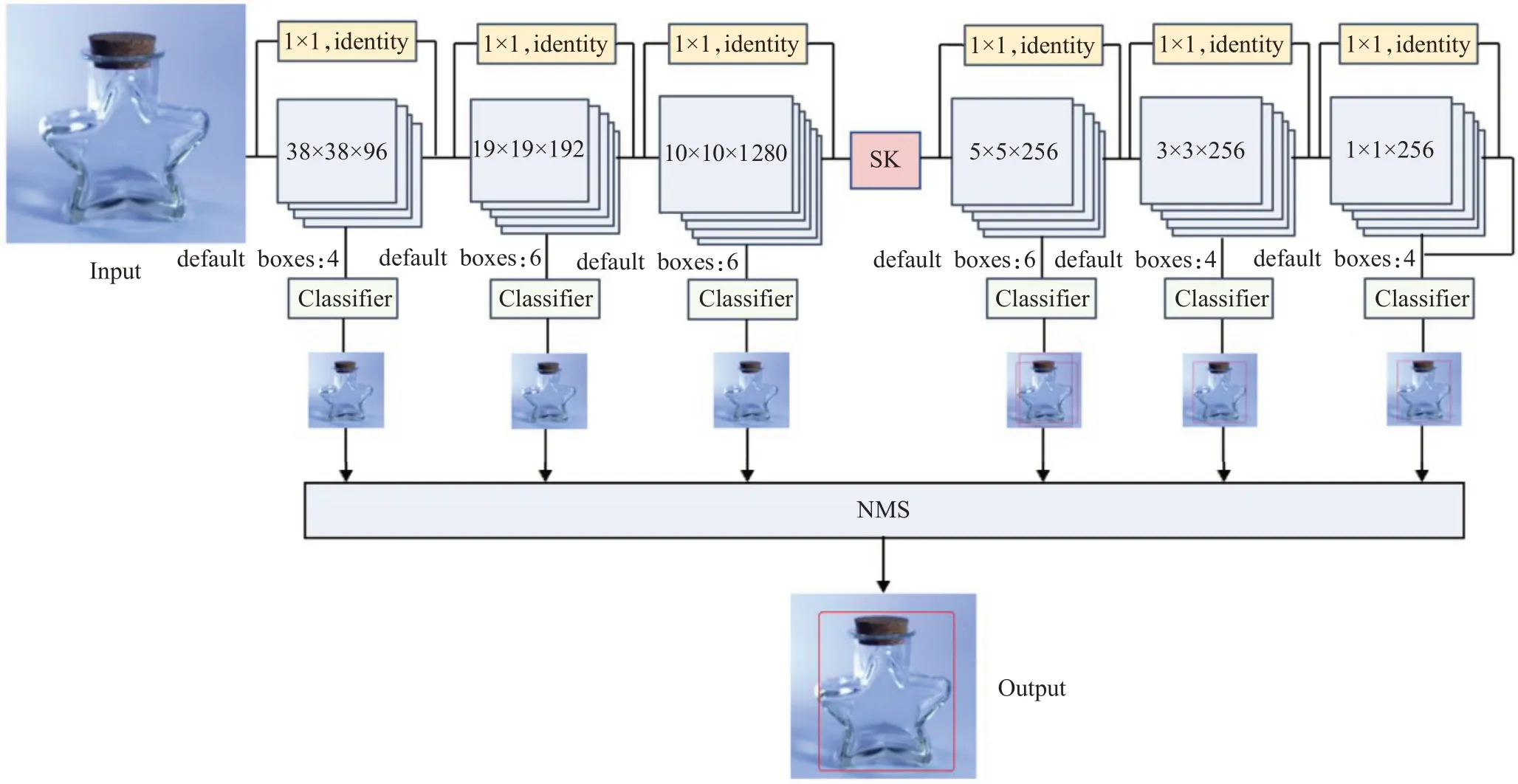
圖2 實驗模型圖Fig.2 Experimental model diagram
2.1 骨干網絡的選取
2021年Ding等人[16]提出了RepVGG網絡,組建了一個由3×3卷積、1×1卷積分支和identity的殘差分支結合的結構。同時該網絡中采用了結構重參數化方式,將訓練階段和推理階段分割開。訓練階段的模型可以更好地提取特征,更方便優化,得到更好的訓練結果,獲取更多的特征信息。在訓練階段選用組合的殘差結構以提高檢測精度,同時在推理階段轉化為類VGG的架構,極大地提高了推理速度,方便模型部署和加速。
類VGG式的結構有諸多優勢。首先在GPU中3×3的卷積結構相較于1×1卷積甚至是5×5卷積而言計算密度更大,因此使用3×3的卷積結構在GPU運行上速度更快。其次,VGG結構采用單路架構,具有較高的并行度更加節省內存。
因此,RepVGG網絡采用結構重參數化的方式后,具有以下幾個優點:
(1)采用結構重參數化的方式,可將分支結構轉變為簡單的3×3卷積、ReLU堆疊的方式,提高模型的推理速度,方便模型高效部署。
(2)推理后的模型為單路結構,速度快且并行度高,節省內存。同時單路結構靈活性更好,方便模型剪枝。
為滿足檢測模型實時性和精度的需求,本文使用RepVGG作為骨干網絡用于特征提取。在訓練階段中引入1×1卷積分支,形成不對稱卷積結構,提高模型的特征分辨能力,獲取更多特征信息;采用identity的殘差結構使模型更易收斂,避免出現梯度消失問題。而推理階段的模型更方便部署,大幅減少計算量,提高檢測速度。RepVGG結構在訓練階段和推理階段的模型結構,如圖3所示。
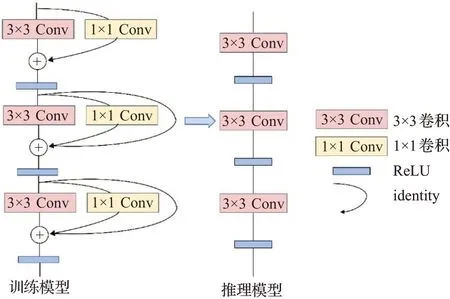
圖3 RepVGG網絡在訓練和推理時的結構圖Fig.3 Structure diagram of RepVGG network in training and inference
本文采用的RepVGG網絡為RepVGG-A0結構,該網絡結構在RepVGG網絡系列中是最輕量的網絡,同時RepVGG-A0不僅具有更少的參數量,擁有更快的推理速度,在獲取特征信息方面也有較好的性能。因此本文考慮到可回收垃圾檢測任務需要部署于工業應用,采用RepVGG-A0作為骨干網絡。
整個RepVGG網絡共分為5個Stage,本文未改變原始SSD算法的輸出特征圖大小,將RepVGG作為骨干網絡時輸出的特征圖為38×38、19×19、10×10,分別由Stage2、Stage3和Stage4生成。其中Stage3設置層數為14,可獲取更多信息。RepVGG的網絡結構設置如表1所示。
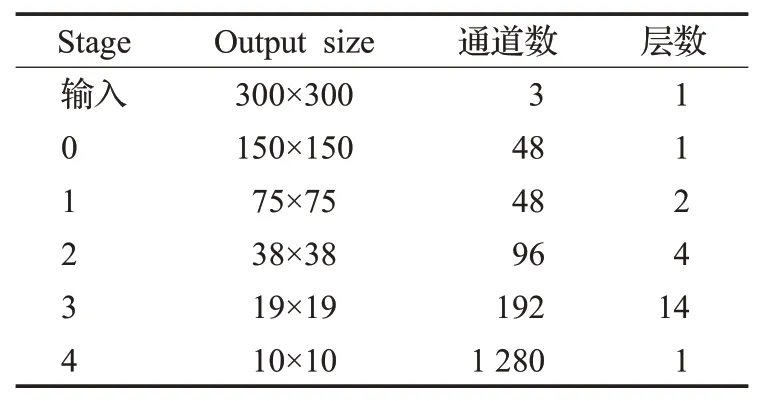
表1 RepVGG網絡結構Table 1 RepVGG network structure
2.2 結構重參數化
結構重參數化這一思想是指在訓練階段和推理階段采用不同的網絡結構和模型參數,將訓練階段產生的模型通過結構和參數變化得到推理模型。推理階段的模型所表達的模型功能在數學推理上是等價的,因此采用該方法可以大幅降低參數量,方便模型高效部署。
Ding于ICCV2019中提出的ACNet[17]和ICCV2021中提出的RepVGG網絡將結構重參數化這一思想貫徹到底。為提高模型的推理速度,在結構重參數化思想中主要采用數學推導的方式,并經過實驗驗證了該思想的有效性,而本文主要采用了其中的Conv-BN合并、分支合并的思路,以下將對這兩個思路進行分析,從而驗證該方法。
2.2.1 Conv-BN合并
在神經網絡中,BN(batch normalization)層的加入,可以快速收斂加速網絡,有效解決梯度消失和梯度爆炸問題。雖然BN結構有諸多優勢,但是BN層在網絡前向推理是會占用更多的內存和顯存,影響模型性能。為減少模型在前向推理時的耗時,本文采用Conv層和BN層融合的方式。公式推導如下所示:
卷積層計算的公式,如公式(1)所示,其中ω為權重,b為偏置:

BN層的計算如公式(2)所示,其中γ和β是學習參數,u是樣本均值,σ是方差,ε表示一個很小的數(防止分母為0):

將公式(1)代入公式(2)中,卷積和BN合并得到公式(3):

將公式(3)拆分后即可得到公式(4),如下所示:
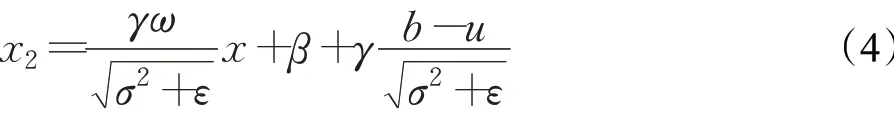

根據卷積的齊次性,合并BN層的過程是線性運算,該過程相當于對卷積核進行修改,而卷積仍不變。因此根據推理得知,采用卷積層和BN層合并可以提升模型前向推理的速度。
2.2.2 分支合并
在RepVGG結構中有1×1卷積核identity兩種分支結構。對1×1卷積而言可以將1×1卷積padding為3×3卷積,在該3×3卷積中,除了卷積核中心位置,其他位置都為0,即將卷積核移動至3×3卷積核中心。而對identity而言可利用權重等于1的卷積核,將identity結構構造為一個1×1的卷積,同時該卷積的權重值為1。通過設置一個3×3的卷積核,對輸入特征映射相乘后,identity前后值不變。此時1×1卷積和identity均可轉變為3×3卷積,而根據卷積的加法特性,卷積核在形狀一致的情況下,可以滿足可加性。因此三個卷積分支可以融合,具體過程如圖4所示。
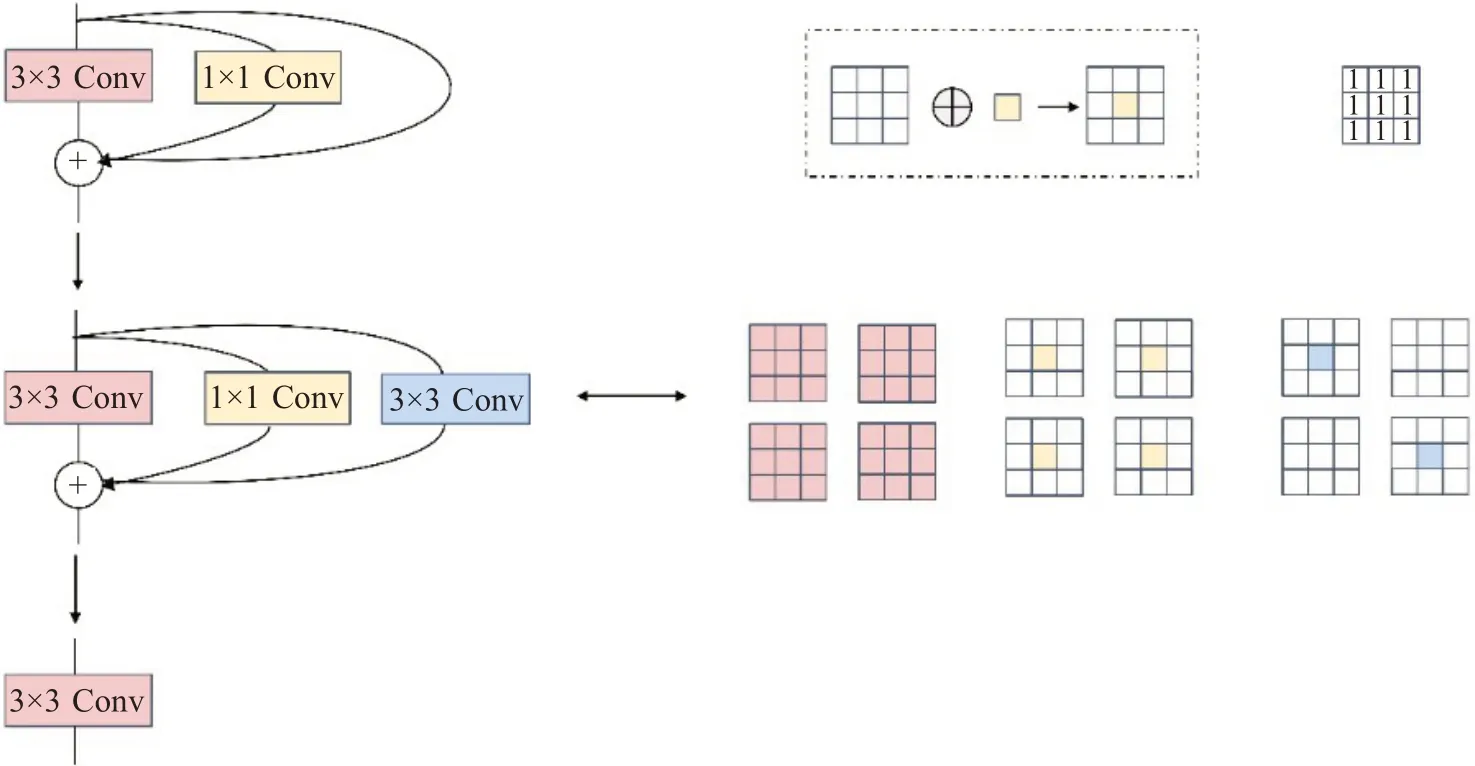
圖4 分支合并過程Fig.4 Branch merge process
2.3 SK模塊
在CVPR2019中Li等人[18]提出selective kernel networks(SKNet),該網絡是對squeeze-and-excitation networks(SENet)[19]提出的改進網絡。SKNet可以根據不同的圖像得到具有不同重要性信息的卷積核,相較于Inception[20]結構而言,SKNet更具靈活性。Inception結構的參數是固定的,而SKNet可以根據卷積核的權重值,針對不同尺度的圖像自適應生成卷積參數。圖5是本文采用的數據集樣本分布圖,可見該數據樣本尺度存在不均衡的情況。因此引入SK模塊以適應本文圖像尺度變化大的問題。
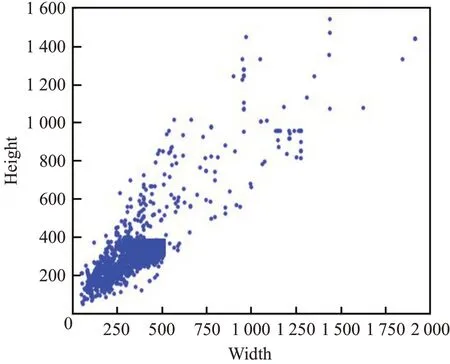
圖5 樣本分布圖Fig.5 Sample distribution
SK模塊主要由Split、Fuse和Select三部分組成,圖6展示了SK模塊的結構。其中,Split部分是對輸入向量進行不同卷積核大小的卷積操作的過程,該部分可根據輸入的特征圖自適應產生多個分支結構。Fuse部分對特征進行融合,根據聚合多個分支的信息以計算每個卷積核的權重。Select部分是根據不同卷積核的權重信息計算后得到新的特征圖的過程。研究發現,SK模塊可以自適應地調整結構,以獲取不同感受野信息。
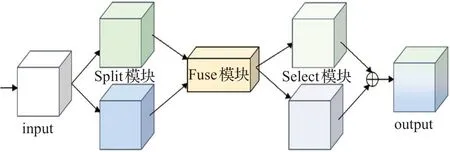
圖6 SK模塊圖Fig.6 SK module structure diagram
2.4 改進輔助卷積層
原始SSD算法采用普通卷積結構、空洞卷積、池化操作和ReLU相結合的思路。該結構采用了大量的池化操作,該方式會丟失大量的信息,同時普通卷積相較于本文的RepVGG式結構而言,有諸多弊端,因此為進一步降低模型參數量,本文延續RepVGG中結構重參數化的思路,采用3×3卷積、1×1卷積分支和ReLU相結合的方式,結構Block如圖7所示。

圖7 Block結構Fig.7 Block structure
將SSD輔助卷積層結構重置,改用Block結構,減小了卷積層數,同時采用步長為2的方式改變輸出特征圖的大小。
改進后的SSD的輔助卷積結構如表2所示,其中輸出大小為5×5、3×3和1×1的特征圖作為檢測層。最后同樣采用結構重參數化法在推理階段將Block的殘差結構轉化為普通卷積結構,極大地提高了模型的推理速度。
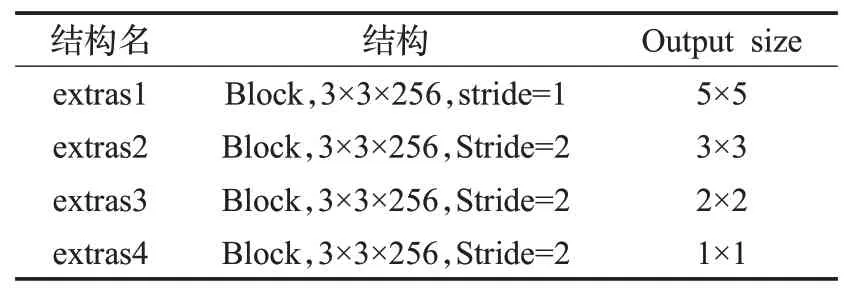
表2 RepVGG網絡結構Table 2 RepVGG network structure
3 實驗對比及分析
3.1 數據集的劃分
本文所采用的數據集主要來源于Kaggle網站中的Waste Classification data數據集(https://www.kaggle.com/techsash/wasteclassification-data),由于該數據集分為有機廢物和可回收廢物兩類,并未對可回收垃圾的類別分類,因此本文選取了部分Waste Classification data數據,并通過網絡爬蟲、相機拍攝的方式,獲得1 650張數據,部分樣本如圖8所示。數據共分為三類:紙板(cardboard)、玻璃(glass)、塑料(plastic)。采用LabeLImg軟件對數據集進行人工標注,數據集為PASCAL_VOC格式。將原始數據集劃分70%作為訓練數據,20%作為測試數據,10%作為驗證集。后采用數據擴充的方式,經過隨機旋轉30°、270°、330°,將原始數據集擴充3倍后,得到新數據集共4 950張數據。

圖8 部分數據集內容Fig.8 Partial dataset content
3.2 實驗分析
實驗在CPU E5 2450 2.10 GHz,16 GB內存,Ubuntu 16.04系統下搭建的Pytorch環境下進行,顯卡為GeForce GTX1080Ti。
為驗證本文改進的SSD算法在可回收垃圾檢測任務上的有效性,本文設計了4組實驗。第一組實驗是驗證RepVGG作為骨干網絡時的性能,對比了原始SSD算法與RepVGG-SSD算法;第二組實驗是驗證本文所提出的SSD輔助卷積層結構,對比了普通卷積結構、Mobile-Netv2中的深度可分離結構以及本文所采用的RepVGG式的Block結構;第三組實驗是為了驗證結構重參數化的效果,對比了使用結構重參數化時和未使用時的效果;第四組實驗是加入SK模塊后,與目前主流的網絡在可回收垃圾檢測任務上的性能進行比較,以驗證本文所提出的網絡的優勢。
訓練時輸入圖像設置為300×300,采用SGD作為優化函數對模型進行訓練。初始學習率為1E-4,學習率在60 000時降低為1E-5,至90 000停止訓練,本實驗采用與原始SSD相同的圖像增強方法。
本文采用的評判標準有:mAP(mean average precision)、每秒傳輸幀數(frames per second,FPS)、浮點運算數量(giga floating-point operations per second,GFLOPs)、乘加運算次數(MAdds)、參數量(parameters,Params)、內存占有量(Memory)、讀入和寫入時的內存量(MemR+W)。其中Memory反應運行時占用的內存量,GFLOPs用來衡量模型或算法的復雜度,Params表示模型的大小。通常GFLOPs和Params越小,代表模型所需要的算力越小,對硬件的性能要求越低,越容易搭建于低端設備中。
實驗一比較了以VGG16和RepVGG作為SSD的骨干網絡時的效果,如表3所示。驗證發現采用RepVGG作為骨干網絡時精度提升1.7個百分點,同時GFLOPs大幅降低,提高了檢測速度。

表3 RepVGG性能比較Table 3 Performance comparison of RepVGG
為進一步減小模型的計算量,本文更換了SSD的輔助卷積層。實驗二對比了更換為深度可分離結構的卷積層和RepVGG結構時的卷積層,效果如表4所示。采用RepVGG結構時相較于深度可分離結構提升了1.63個百分點,相較于原始SSD結構精度提升了0.93個百分點。同時,采用該結構時的浮點數最小為5.82,參數量雖然相較于深度可分離結構有小幅提升,但是在精度方面展現的效果更好。
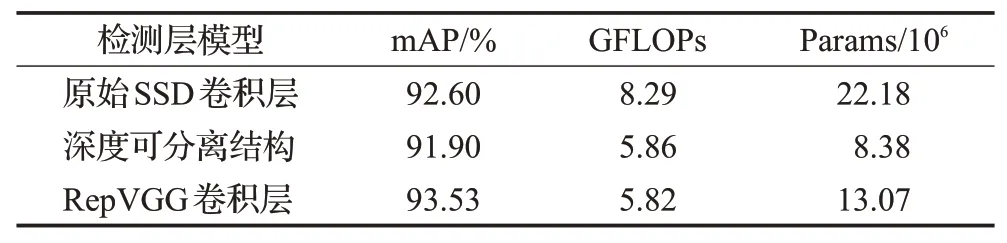
表4 SSD輔助卷積層比較Table 4 Comparison of SSD auxiliary convolution layer
由于可回收垃圾檢測通常應用于工業中,為滿足輕量化的要求,方便日后的模型部署于移動端和嵌入式端,本文采用BN層和卷積層融合,分支結構合并的思路,減小模型前向推理的時間,提高檢測速度。主要通過結構重參數化的方式,為驗證該方式的有效性,本文設計了實驗三。表5對使用結構重參數化和未使用時進行了比較。由實驗可見,內存占有量降低了43.65×106,讀入寫入時的內存也下降了近一半。因此該方式可大幅減小參數量和計算量,加快模型推理。

表5 結構重參數化性能比較Table 5 Comparison of performance of structural re-parameterization
本文加入了SK模塊,用于自適應調整感受野尺寸,所提出的網絡為RepVGG-SK-SSD。為進一步驗證所提算法的有效性,本文比對了VGG16-SSD、MobileNet-YOLOv3、CBAM+SSD、YOLOv3、MobilNet-SSDLite、RepVGG-SSD、RFBNet[21]等網絡結構的性能,如表6所示。由實驗可得,本文所提算法在可回收垃圾檢測任務上可達到95.23%的精度。相較于原始SSD算法,共提升了4.33個百分點。同時,該算法的參數量和計算量較小,浮點數只有5.16,參數量也只有10.33×106。相較于原始SSD的浮點數為60.29以及22.94×106的參數量而言,本文所提算法做出了更大的改進,且擁有更好的性能。雖然MobileNet-YOLOv3的精度相對本文所提算法高了0.47個百分點,但是其浮點數以及參數量遠大于本文算法。同時驗證該算法在單個GTX1080TI顯卡下可達64 FPS,可滿足在移動端和嵌入式端部署的需求。
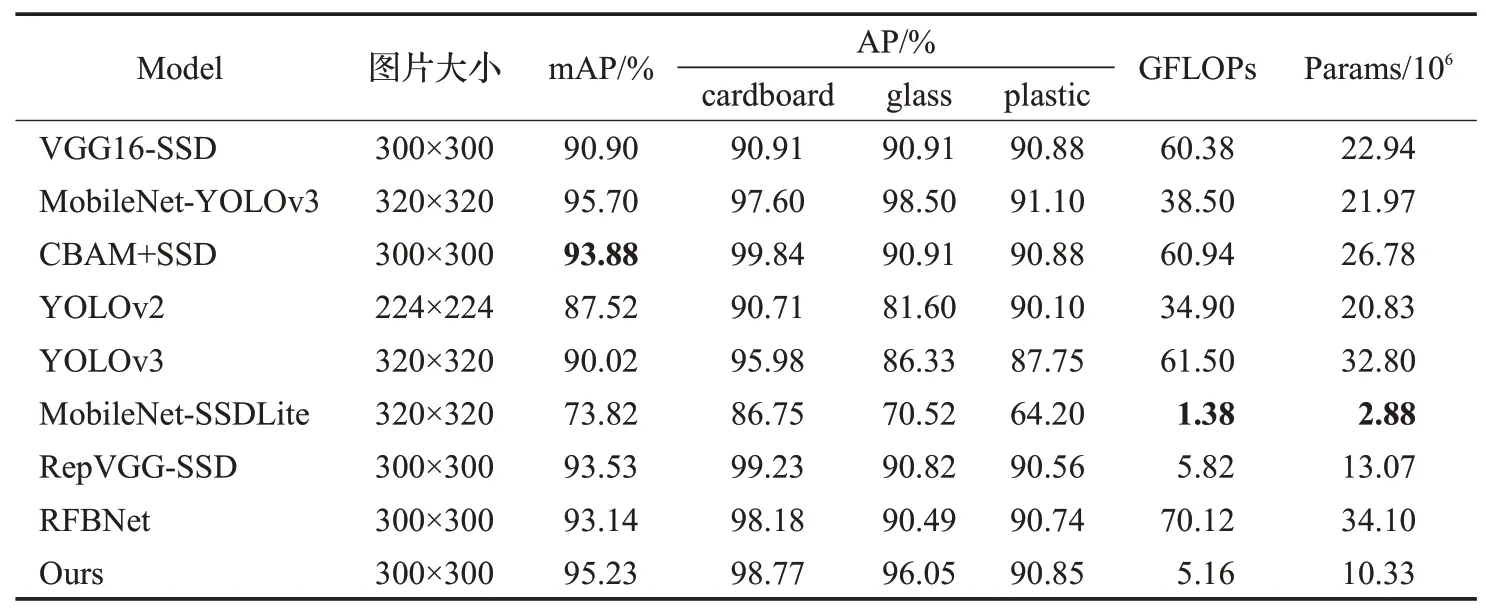
表6 不同算法測試結果對比Table 6 Comparison of detection results of different algorithms
本文將RepVGG網絡與SK模塊融合,選用新的輔助卷積層,實驗也驗證了該算法的有效性,圖9展示了本文所提算法的檢測效果。

圖9 檢測效果圖Fig.9 Inspection effect picture
4 結束語
本文提出了一個實時高效的基于SSD算法的可回收垃圾檢測器。針對VGG16模型過大、運行內存量過高,無法用于工業部署問題。提出采用輕量化的網絡RepVGG作為骨干網絡,使用結構重參數化的方式減少參數量和計算量,提高模型的推理速度,實現實時檢測。同時為進一步減少參數量,提高模型的檢測速度,修改了SSD的輔助卷積層。針對圖像尺度變化大的問題,提出采用SK模塊,自適應調節感受野尺寸,提高檢測精度。實驗表明,本模型具有良好的檢測精度和實時性,可以更好地應用于可回收垃圾檢測任務。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
哲學評論(2021年2期)2021-08-22 01:53:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華詩詞(2019年7期)2019-11-25 01:43:04
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
海峽科技與產業(2016年3期)2016-05-17 04:32:12
