保險絲線圈字符識別技術研究
2022-12-06 10:38:50歐陽家斌胡維平劉北北劉文揚
計算機工程與應用 2022年23期
歐陽家斌,胡維平,劉北北,2,劉文揚
1.廣西師范大學 電子工程學院,廣西 桂林 541000
2.中國科學院 自動化研究所 蘇州研究院,江蘇 蘇州 215000
保險絲線圈字符是保險絲的身份證,線圈字符識別對區別其型號等有效信息有著非常重要的作用,傳統識別線圈字符信息采用人眼讀取,這樣的操作不僅勞動強度大、效率低,隨著工作時間的增長,工人們容易造成漏識別和錯誤識別,同時也無法滿足流水線及自動化生產發展的需求[1],為了解決上述一些存在的問題,將機器視覺引入到線圈字符檢測中。
目前常用于字符分割的方法有投影法、字符邊緣檢測分割法和基于聚類分析的字符分割法[2]。常同于字符識別的方法分為圖像處理及機器學習兩類。基于圖像處理的識別主流方法有特征提取法[3]、模板匹配法[4]等,基于機器學習的主流方法有基于支持向量機(support vector machine,SVM)、基于多層感知機、基于誤差方向傳播(error back propagation,BP)神經網絡[5]。其中對于前者方法原理簡單,但容易受圖像噪聲的影響,魯棒性差。后者方法識別效果好,泛化能力強,具有很高的魯棒性。
文獻[6]提出了一種CNN網絡模型LeNet用于手寫字符識別,對促進CNN在圖像識別問題中的廣泛應用做出重要貢獻。文獻[7]以SSD算法[8]為框架基礎,使用多尺度圖像輸入進行端對端的訓練,較好地解決了文字尺度識別問題,但這樣的做法嚴重影響了模型的運行速度。文獻[9]采用微分思想將Anchor的橫向長度固定為16個像素點,并使用文本線將小寬度構造為文本行以此來克服預測框受長度劇烈變化的影響,但該網絡對形變字體識別較差,且無法準確定位文本兩端的位置。
文獻[10]是Faster R-CNN的開山之作,由于該網絡將字符生成了一個個候選區域再送入卷積網絡中學習訓練,使得計算量很大,在后續的分類和回歸網絡中,使用SVM分類器分別對二者進行訓練,導致魯棒性和時效性差。因此,在2015年,文獻[11]在R-CNN網絡的基礎上提出了Fast RCNN網絡,該網絡可實現端到端進行訓練,在訓練的速度上和測試速度上較R-CNN分別快于9倍和213倍。Fast RCNN所采用Selective Search區域生成方法[12]的弊端顯而易見,在特征提取耗時較大,因此這給Fast RCNN網絡繼續改進的機會,改進之后的網絡稱為Faster R-CNN[13],該網絡更快更強,魯棒性更高,對小物體的檢測以及擁擠、遮擋等較難檢測問題上提供了一個有效的解決方案。文獻[14]創造性地使用Anchor-free完成一階段檢測任務,提出了YOLO v1網絡,其思想是通過整張圖作為輸入,直接預測字符的類別與位置。2018年,Joseph等人繼續推出了YOLO v3版本[15],該版本較之前的版本有著更精確的檢測率和更為靈活的拓展空間。YOLO網絡的實時性較好,但對目標相近的物體檢測效果表現一般。
本文針對線圈字符的分割和識別問題,在字符分割上,使用投影法結合字符的先驗知識給出閾值進行去除上下邊框,再經過平滑濾波、閉運算去噪,在垂直投影中結合字符寬度解決黏連問題,從而達到切分屬于同一字符塊的目的,最后再對切分出來的字符進行膨脹處理,使字符清晰易識別。這樣對于后續的用于字符識別操作做了很好的前處理,較大地提高字符的識別率。在字符識別中,考慮到字符背景噪聲較多,部分字符結構受影響以及有字符黏連相近和壓縮形變情況,因此選擇改進的Faste R-CNN網絡進行定位作識別,使用ResNet101[16]代替原有的VGG16基網絡,使用K-means聚類算法[17]尋找最優的Anchor取值范圍,將RoI Pooling替換成RoI Align,并在RCNN中損失函數進行了設計,其目的是提高網絡模型的準確性和實時性。同時,將上階段中的分割出來的字符用于該階段中的LeNet[18]做識別,并將其與該方法和未改進網絡進行對比,最后通過實驗來驗證該方法的有效性。
1 本文算法
1.1 字符分割
由于工業相機采集出來的圖片較大,含有其他很多電路板和元器件等無用信息,不便于分析和研究,因此進行對數據集整理和清洗,統一將圖片的尺寸截取為1 110×180大小。線圈的上下部分有螺紋邊框,在高光的拍攝條件下,存在曝光過度的情況,對分割的結果影響極大,為了正確分割出字符,具體詳細操作步驟如下:
(1)如圖1所示,為本次實驗操作選取的典型例圖。首先對目標圖像進行灰度化,在灰度化后的圖像進行k-size為(3,3)的高斯濾波操作,目的是通過對鄰域取得九個數的高斯分布權重矩陣與原灰度化圖像進行卷積操作,從而平滑噪聲。

圖1 選取原圖Fig.1 Selecting original image
(2)使用THRESH_BINARY_INV和Otsu’s二值化,將前景和背景進行反相操作,并自適應找到最優閾值。
(3)水平投影法,對投影的每行累和的像素值設定閾值,如若大于設定的閾值,將該行中的所有像素點置于背景色,對投影中的整個波形來說,找到波谷點,將波谷線到邊界線的最小值這一段內范圍的所有像素點置于背景色,完成上下邊框去除。
(4)使用kernel為7×7的閉運算操作,為二值化后的圖像進行先膨脹后腐蝕的過程,目的為了填充字符內的小黑點以及去除背景中的噪聲點。
(5)通過前面一系列操作后,對每一列元素進行投影累加,分割出有像素值的列。對于左右無像素值的單個區域分割出來,若該區域比字符的寬度大,則選擇在分出來單個區域的波谷點進行分割,此操作的目的是分割出部分因曝光過度而產生黏連問題的字符。
(6)通過對之前水平投影行分割字符中的邊界保存,結合垂直投影列分割的字符區域邊界,完成對字符區域塊的分割操作。
為得到較為清晰分割出來的字符,再次使用THRESH_BINARY_INV和Otsu’s二值化,采用kernel為(4,4)的膨脹操作。并進行輪廓檢測,計算輪廓的垂直邊界最小矩形,對矩形的大小進行設置,當上邊框與下面框的絕對值小于字符的高度時,選擇濾去,本文設置的閾值為30像素值,最終得到膨脹反相單個字符圖,如圖2所示,其中圖2(a)和(b)分別為圖1(a)和(b)的最終結果。

圖2 膨脹單個字符分割圖Fig.2 Expanding single character segmentation graph
1.2 字符識別
本次實驗采集圖片共有620張,通常使用深度學習技術達到理想識別效果需要大量的樣本數據進行學習,因此需要對數據進行擴增,為了減少標注工作量,對已標注好的樣本為基本,對在真實場景可能會出現的情況進行數據增強,本文采用基礎操作的上下旋轉、左右置換,以及高級操作的亮度調整進行圖片擴增。
1.2.1 Faster R-CNN卷積神經網絡
Faster R-CNN是一個二階(two-stage)網絡,在R-CNN和Fast RCNN的基礎上改進而來,由Ren等人在2016年提出,該網絡可實現端對端進行訓練,取得了實時的檢測效果,其網絡結構主要包含四個部分:特征提取網絡、候選區域網絡(RPN)、RoI Pooling(region of interest)模塊和RCNN模塊。
第一部分的特征提取網絡是特征提取部分,Faster R-CNN采用的Backbone是VGG16,VGG16共有13個卷積層,3個全連接層,包含4個Pooling層,最后一個Pooling層一般在物體檢測中都不使用。下采樣率為16,如若輸入的是三通道1 110×180圖像,則經過基網絡處理之后輸出的特征圖大小為521×69×11。
第二部分的候選區域網絡為RPN模塊,其主要作用是生成Propasal(建議框)。RPN模塊包含了5個子模塊:Anchor的產生、RPN卷積網絡、計算RPN損失、生成Propasal和篩選Proposal得到RoI。
(1)Anchor的產生
Anchor在物體檢測的網絡中比較常用,為了使得檢測準確率更高,一般的網絡會選擇使用提供的先驗框在圖像上進行框定,然后再篩選和精修從而完成精確的定位。Anchor的本質是在原圖像中產生的一系列有一定比例大小的矩形框,Faster R-CNN網絡將這些矩形框和基網絡之后的特征圖進行了關聯。
(2)RPN卷積網絡
RPN卷積網絡在通過Backbone網絡之后先進行了3×3的卷積,之后分為分類分支和回歸分支。在分類分支中,首先利用1×1卷積在特征圖操作,將維度的特征點進行聯通,由于每個Anchor有前背景之分,并且每個特征點有9種尺寸大小,所以輸出的維度為2×9=18。而分類的過程中需要經過Softmax函數,故對向量維度進行reshape操作,之后再次reshape還原。在回歸分支中,同樣使用1×1卷積,每個點有9種Anchor,每個Anchor有4個數據,分別為框的中心點坐標和寬高,因此輸出的維度為4×9=36。
(3)計算RPN損失
從(1)中的Anchor產生可得知,其總數量將近兩萬個。為了解決正負樣本的失衡問題,因此需要對Anchor進行篩選,一般情況下,選擇最多不超過128個正樣本,總共有256個Anchor送入后續的損失計算。上述的正負樣本代表了預測的分類真值,而回歸部分需要利用Anchor與之對應的標簽求得偏移量值,將其保存在bbox_targets中。負樣本為背景,不需要回歸,故將bbox_outside_weights設置為0,而正樣本需要回歸,將bbox_inside_weights設置為1。RPN真值最后輸出有標簽label、偏移量值bbox_targets、正負樣本的兩個權重bbox_inside_weights和bbox_outside_weights。
(4)生成Proposal
首先對生成全部的Anchor進行回歸偏移調整,將超過圖像尺寸的Anchor去除,然后對接下來的Anchor按照confidence(置信度)排序,篩選出前12 000個得分高的Anchor,此時利用非極大值抑制(non maximum suppression,NMS)去掉一個物體可能含有多個Anchor的重疊框,最后將從建議區域中得到得分最高的2 000個框,作為后續的Proposal輸出到下一階段。
(5)篩選Proposal得到RoI
從(4)中得到2 000個框,含有很多的背景框,會造成負樣本過多,使得出現正負樣本不均衡,為了有效地送入后續的全連接網絡,減少不必要的計算,因此還需要從Proposal中繼續篩選出有效的正負樣本。根據標簽與Proposal的IoU值,篩選出正負樣本。通常情況下,將正負樣本的總數設定為256個,并對正負樣本的比例進行限制,正樣本和負樣本的比例為1∶3。
第三部分為RoI Pooling層。顧名思義是為了將上述輸入的RoI進行池化,所處理之后的特征圖為固定的大小,以供后續的RCNN計算預測值與真值的損失。
第四部分為全連接RCNN模塊。經過第三部分RoI Pooling操作之后,將池化后的操作送入RCNN進行訓練。值得一提的是,RCNN的損失函數和RPN保持相同,在分類中,同樣使用二分類,但這里共有21個類別,而不再是前背景兩個類別。在回歸任務中,選擇不超過64個正樣本進行回歸,負樣本則不參與計算。
1.2.2 改進的Fast R-CNN網絡結構
到目前為止,在機器視覺中誕生了很多的目標檢測網絡,但Faster R-CNN無疑成為了一個經典的目標檢測網絡算法[19],尤其對小物體檢測、擁擠和遮擋等困難場景提供了一個有效的解決方案,眾多優秀的目標檢測算法都基于Faster R-CNN的基礎上改進、完善和優化而來,因此,為了準確檢測(識別)保險絲字符,在以下四個方面進行改進。
(1)在特征提取階段使用ResNet101代替原來的VGG16
如圖3所示,為ResNet101的網絡結構圖,其一共有四個大卷積組,這四個大卷積組的Bottleneck數分別為3,4,6,3。采用ResNet101作為Faster R-CNN特征提取基網絡,首先對送入的圖像進行步長為2的卷積操作,此時特征圖縮小至原來的1/2,通道數為64,之后連續通過三個卷積組,通道數增加一倍,而特征圖減少至原來的1/2,卷積的過程直至經過第三個特征組時,將最后一次變為通道數為256的1×1卷積。因此ResNet101特征提取網絡為91層卷積操作,與VGG16相同的是,輸出的Feature map維度為512,下采樣率為16。

圖3 ResNet101網絡結構圖Fig.3 ResNet101 network structure diagram
(2)在RPN網絡中,尋找最佳的Anchor參數
使用K-means聚類算法尋找最佳的Anchor尺寸大小,首先對Anchor Box的K個數進行初始化,對Bounding Box左上角和右下角四個坐標提取出來,用右下角橫坐標與左上角橫坐標之差得到框的長,用右下角縱坐標與左上角縱坐標之差得到框的寬,之后計算Bounding Box與Anchor Box的IoU值,其目的是在Box尺寸比較大的時候,能夠減少相應的誤差值,使其直接聚類Bounding Box的寬和高,產生K個寬高組合的Anchor Boxes。在此使用IoU值,即為Anchor Box與Bounding Box的公共部分占所有部分的比例。引入誤差d,d為1減去IoU,每一個Bounding Box對于Anchor Box都有一個誤差d(n,K),其中n為Bounding Box,K為Anchor Box的初始化值。經過遍歷,選取誤差最小的Anchor Box分類給Bounding Box。隨后將屬于Anchor Box的Bounding Box取平均值作為一個尺寸進行更新,直到所有的Bounding Box都能找到Anchor Box的類。最后,找到每一個Bounding Box最高的IoU值,進行取平均值輸出精確度[20]。
通過加載標注的文件信息,最終聚類得出的9種Anchor,分別為:(8,219),(11,211),(13,221),(14,226),(16,214),(18,224),(20,228),(24,235),輸出的圖像size為416。準確率為92.53%。
(3)將RoI Pooling替換成RoI Align
由于RoI Pooling在實現的過程中,直接對特征量化取整,此操作雖然簡單快捷,但連續的兩次取整操作,必然會帶來較大的偏差,直至影響整個網絡的性能,最為直接的是導致預測框在回歸物體位置中不準確。RoI Align實現的過程可從如下分析,若預測的框為280×280大小,通過下采樣率16,因此進行區域生成的特征圖大小為280/16=17.5,保留其浮點數,之后將得到大小為17.5×17.5的特征圖處理成7×7的區域。因此需要以17.5/7=2.5的步長來選取,繼而保留浮點數,得到小方格2.5×2.5的區域,在此區域內采用最大值池化,作為該特征的輸出值,最終實現7×7的輸出。在此過程中,對每個小方格平均分成4份,在這4份的中心作為該內區域的值,而中心點通過選取周圍4個點進行雙線性插值得到,再對這4個中心點取最大值,將得出來的最大值作為池化輸出到7×7的特征。
(4)在RCNN中損失函數的設計
為了能在輸入寬高比差異較大圖像中也能達到良好的效果,因此對于本次實驗,平衡分類和回歸中的損失尤為重要。在經過RoI Pooling層之后,輸出的Anchor通常為256個,而feature map的分辨率大小為經過特征提取網絡之后所產生的值,在本次的保險絲字符定位作識別中,輸入的圖片為1 110×180,因此經過下采樣率為16之后得到的特征圖大小為(1 110/16)×(180/16)=780,而由Faster R-CNN網絡的損失函數可知[21],Ncls為樣本的總數量,即Anchor數量,為256,Nreg為feature map的分辨率大小,即上述求出的780,為了達到平衡損失條件,因而對參數的取值為λ=3,故損失本次使用的損失函數如式(1)所示:
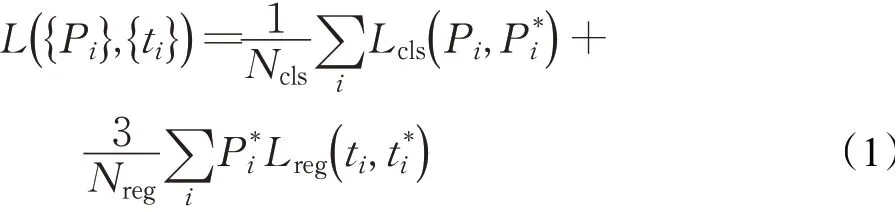
其中,Pi和分別是每個Anchor類別的真值和預測類別為分類損失為回歸損失,其中ti為偏移真值,t*i為預測偏移量。具體公式如下所示:
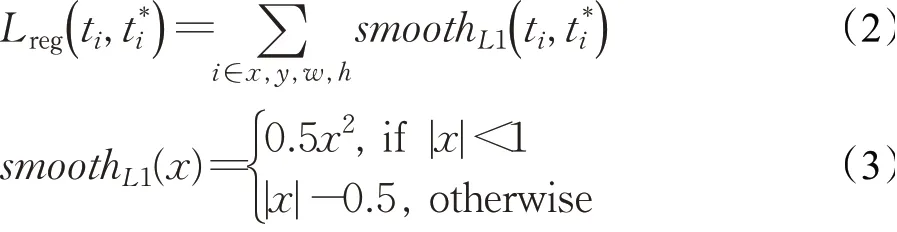
2 實驗
驗證改進之后的網絡算法性能,將其與未改進的Faster R-CNN進行對比,并對比上一階段分割出來的字符用于本階段的識別,識別算法使用LeNet網絡。
2.1 實驗環境
平臺采用Windows10(64 bit)專業版操作系統,處理器為Intel?CPU E5-2620 2.00 GHz,內存為24 GB,顯卡為NVIDIA Tesla M40(24 GB),使用語言環境python3.7.6,開發框架為pytorch,OpenCV的版本為4.1.1。
2.2 數據處理
采集的圖像共有620張,然后對原圖像進行三種數據增強的操作,分別為:對原圖像旋轉180°、以y軸為中心左右翻轉和對三通道中每個點加50像素值進行亮度調整。經過該操作后共得到2 480張圖片,而后按比例8∶1∶1分別分配給訓練集、驗證集和測試集。每個保險絲線圈,采用的三個角度進行捕獲,合并為一個圖像,因此有的區域字符為重復的字符,保險絲的線圈字符序列中一共有13~14個字符,合并之后的圖像含有的字符數有13~19個,三個對接的圖像有一定的左右鏡像能力,因此對一些嚴重模糊或曲面扭曲的圖像不進行操作,如圖4所示,對紅線框的字符視作無效字符。另外,數字打上對應的數字標簽,字符打上對應的小寫字母標簽,特別地,對于字符“L”的標簽為“ll”。

圖4 鏡像圖像中模糊和變形示意圖Fig.4 Schematic diagram of blur and distortion in mirror image
2.3 對比實驗
為了驗證改進算法的有效性,與改進前的算法進行對比實驗,如圖5所示,為本文改進算法的訓練損失曲線圖,當總損失將近收斂時,暫停訓練,共計5 000迭代次數。
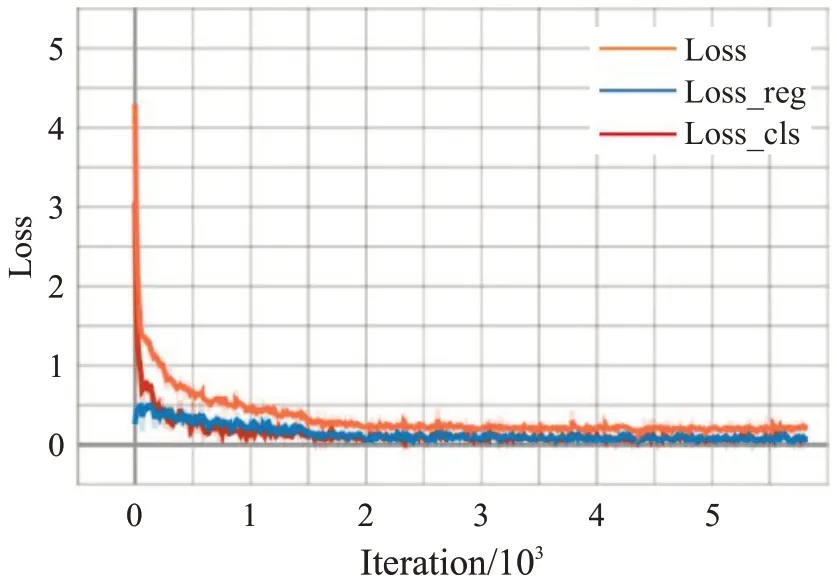
圖5 改進網絡的訓練損失曲線Fig.5 Training loss curve of improve network
如圖6所示,為選取兩組網絡改進前后識別效果對比圖,從第一組(a)和(b)可以看出,改進前的網絡對右側中“A”的壓縮小字符未能識別,并且對能夠準確識別的字符框有偏歪的現象,比如左側的“P”字符和右側的“T”字符;第二組中的(c)和(d),未改進的網絡在圖像右側識別中對倒“V”字符出現兩個框檢測,并存在一個誤檢框,誤檢的結果為“A”;由對比結果圖可知,改進之后的網絡對曲面或部分殘缺的字符能做到有效的識別,由此可見,改進后的模型,加強了網絡特征提取,提取了多層有效的語義信息,并對RoI Pooling的量化造成的偏差有一定的改善。

圖6 改進前后實驗對比結果Fig.6 Experimental comparison results before and after improvement
對于上一階段使用的測試數據集分割出來的單獨字符送入本階段進行識別,分割階段得到的字符共有2 871個,將該部分字符送入LeNet網絡進行訓練和推斷,計算其從分割后到識別的準確率,而使用定位作識別中,除去數據處理階段一些嚴重模糊、曲面扭曲和主體部分缺失的字符,在測試集數據248張圖像上共有3 497個有效字符。使用一階段網絡YOLO v1、SSD和二階段未改進網絡進行對比實驗,其各訓練參數如表1所示。
通過表1的參數進行訓練,將所得模型進行推斷,最終,通過實驗得到的結果如表2所示。
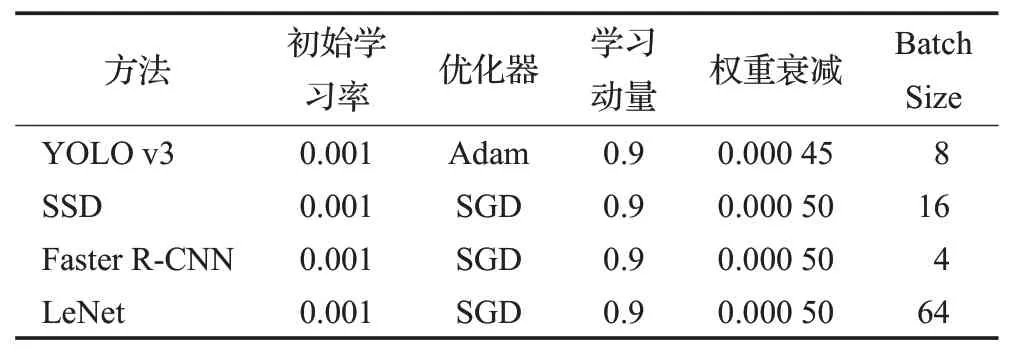
表1 對比實驗網絡訓練參數Table 1 Contrast experimental network training parameters
從表2的實驗結果對比可以看出來,在定位做識別中,YOLO v3網絡實時性效果較高,每秒可推斷35張圖片,但對字符的正確識別率只有96.69%,難以達到高精度的要求,而改進后的網絡對比未改進網絡在保持幀率不變的前提下準確率提高了1.17個百分點,對比SSD和YOLO v1網絡分別提高了4.03個百分點和3.22個百分點,使用分割結合LeNet識別的算法在分割率上有較大的損失,而對分割出來的字符因較多有殘缺部分導致識別效果欠佳。考慮工業圖像檢測的識別率和實時性訴求,結合精度和速度綜合考量,使用本文所采用改進的Faster R-CNN網絡通過實驗驗證了該方法在線圈字符識別問題的有效性,并有著顯著的識別效果,對這類OCR問題有一定的普適性。

表2 實驗對比結果Table 2 Results of comparative experiment
3 結束語
光學字符識別是計算機視覺中重要的研究方向之一,近年來成為了研究熱點,隨著中國制造不斷地發展,OCR的應用場景越來越廣闊。本文對保險絲線圈的字符進行了研究,采用了兩種方法進行識別,一種是通過字符的先驗知識使用投影法進行分割,將分割完成的字符送入LeNet網絡進行識別,另一種方法是以定位作識別,將每個字符進行目標檢測從而到達識別的效果。對比了一階段網絡和二階段網絡檢測算法,并最終選擇改進的Faster R-CNN目標檢測作為識別,其主要體現在四個方面的改進,優化之后的網絡讓字符識別效果更理想,在后續的研究中,可以將對線圈中的字符進行去重復化,排列出正確的字符序列來,組合得到線圈中的序列字符,以識別整個圖片的正確序列作為基準,以供線圈型號等信息的辨認。
通過本文的檢測作識別方法,能夠準確識別出曝光過度、部分殘缺和曲面壓縮等線圈的字符。實驗表明,使用定位作識別的方法在這類光學字符識別具有一定的推廣和借鑒價值。
猜你喜歡
艦船科學技術(2022年15期)2022-09-14 09:21:50
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
電子制作(2019年15期)2019-08-27 01:12:00
電子制作(2018年19期)2018-11-14 02:37:08
自動化學報(2017年11期)2017-04-04 02:52:58
海峽科技與產業(2016年3期)2016-05-17 04:32:12
