論標準文獻服務工作的內容與流程
2022-12-09 10:29:52康云
大眾標準化 2022年22期
康 云
(福建省標準化研究院,福建 福州 350000)
1 標準文獻工作的發展
20世紀80年代初,我國的標準文獻服務工作就已開展,當時的查詢對象有國家標準、專業標準、企業標準,國際上有國際標準、區域性標準化組織標準、各先進工業國家標準和有關專業協會標準,服務的主要內容有:標準查詢及委托檢索服務、標準查新服務、標準有效性確認服務、標準翻譯服務、標準水平評價服務,如圖1:
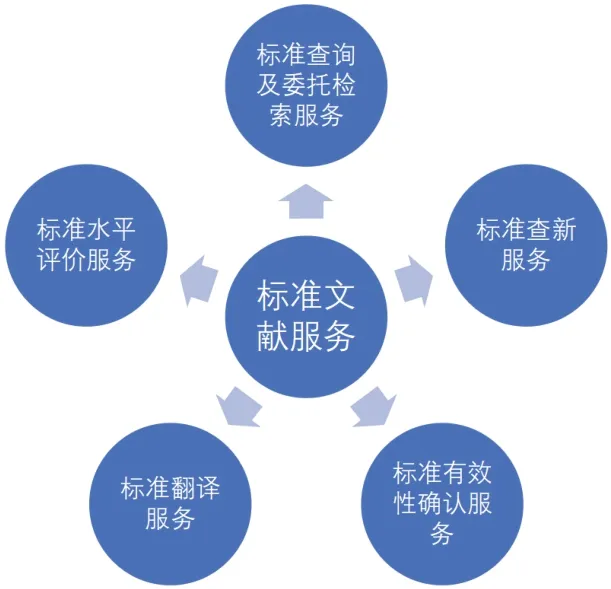
圖1 20世紀80年代我國的標準文獻服務工作內容
這一階段標準文獻工作的特點是服務內容單一,人工干預多,服務效率低。以檢索標準為例:首先,客戶要上門查找標準,先填寫提交索書單,標準文獻前臺服務人員根據客戶需要的內容,要先檢索標準紙質目錄,或是從目錄卡片查找對應的標準,再轉交庫房管理員提取標準,并交給客戶,客戶根據自身需要,要么現場閱讀,要么復制拷貝或購買原版標準帶回,寫成標準化服務流程就是,如圖2。

圖2 20世紀80年代我國的標準文獻服務工作流程
傳統標準文獻服務雖有較強的權威性,但工作效率低,難有深層次的擴展服務。隨著經濟活動的頻繁,標準文獻的不斷涌現,標準化服務推進受到了極大的阻礙,標準文獻服務方法亟待改進。
20世紀90年代,隨著計算機及數據庫技術的發展,單機版的標準信息檢索系統的出現,標準文獻服務流程也隨之改變,如上述流程中手工檢索標準題錄工作、查找標準索取號工作都可以在計算機上完成。這使標準文獻服務工作在標準題錄檢索、抽取標準文本的時間大為縮短,這一階段的標準化服務流程變為,如圖3。

圖3 20世紀90年代我國的標準文獻服務工作流程
隨著人類科技水平的快速發展,各個學科相互交叉、滲透,學科的綜合化、整體化越來越強,社會對于標準文獻的需求量越來越大的同時,對標準文獻服務的要求也在不斷提升,用戶不再單純需要現有館藏的原文傳遞服務,而是迫切希望標準服務機構更多提供有針對性的、多方面、全方位的、綜合化的標準文獻深層次的知識服務。
進入2000年,隨著計算機數據庫技術及互聯網技術發展,服務方式也有了進一步的發展:標準文獻館藏電子化、標準文獻電子版閱讀、標準文本遠程打印、標準文獻資源整合也成為可能。
在標準文獻數據加工方面,將數十萬份的標準文本通過標準文獻加工系統,掃描轉化為電子文檔,在電腦中儲存起來,實現標準文檔的電子化,同時建立標準題錄數據庫,并將題錄數據與全文建立關聯索引,實現了標準館藏電子化。
在同一單位實現整合資源,實現共享,使標準文獻館藏電子化加工、檢索系統與標準文本遠程發行系統整合,改變了傳統的服務模式,用信息化、網絡化手段實現標準文獻、發行資源的整合,建立統一服務窗口,實現統一窗口、統一服務,進一步提高了單位標準文獻的服務質量。
調查顯示,城市學生的身高、體重、坐高、胸圍、肺活量等指標高于農村學生,與楊旭等[4]的研究結果一致,可能與城市學生的營養狀況好于農村學生有關。農村學生的握力、50m跑、立定跳遠、耐力跑、肌力、坐位體前屈等指標好于城市學生,與顧昉等[5]的研究結果一致,可能與農村學生除學習之外,還參加一定的體力勞動有關。
在全國同級單位,實現標準資源互補,資源共享,節約開支。例如,某省標準化機構與全國其他省份的標準化機構本著互利合作的原則,簽訂了資源采購互補協議,特別是國外標準,品種多、價格高,通過采購相關原版標準,在各自需要時,通過全國標準資源大市場,以互補方式,獲取標準資源,為國家節約了大量資金,實現了標準資源的共享。
綜上所述,隨著計算機技術發展及網絡化程度的不斷提高,標準閱讀的便利性,標準服務范圍從省內用戶內轉向全國用戶還擴大了服務范圍,縮小了時空差距,大幅提高了標準文獻的服務工作效率,這一階段的標準化服務流程變為,如圖4。

圖4 21世紀初我國的標準文獻服務工作流程
2 標準文獻工作的現狀
進入21世紀10年代,大數據的快速發展對互聯網技術而言如虎添翼,它具有數量大、數據類型多、商業價值高、處理速度快的特點。如今,它用于標準文獻服務工作方面使其內容拓展為:標準文獻檢索、標準文獻閱覽服務、標準信息跟蹤服務、標準查新及有效性確認服務、標準數據庫加工服務、標準內容指標檢索與對比、標準全文檢索、標準大數據應用服務。
圖5中,標準文獻服務內容涵蓋了我國標準文獻服務工作40年的發展內容,不僅含有傳統的“標準查新及標準有效性確認”項目,還包括了近年的大數據在標準化方面的應用,例如大數據分析手段,從時間、地域、起草單位等多維度分析各級標準的起草情況。在傳統項目方面,由于檢索系統設備的更新,效率大幅提高。在標準深加工方面,隨著各種系統的開發和應用,標準內容的深度揭示,給標準文獻服務工作帶來了極大的發展空間。對應的標準文獻服務流程也呈現出多頭并舉發展的態勢,見圖6。
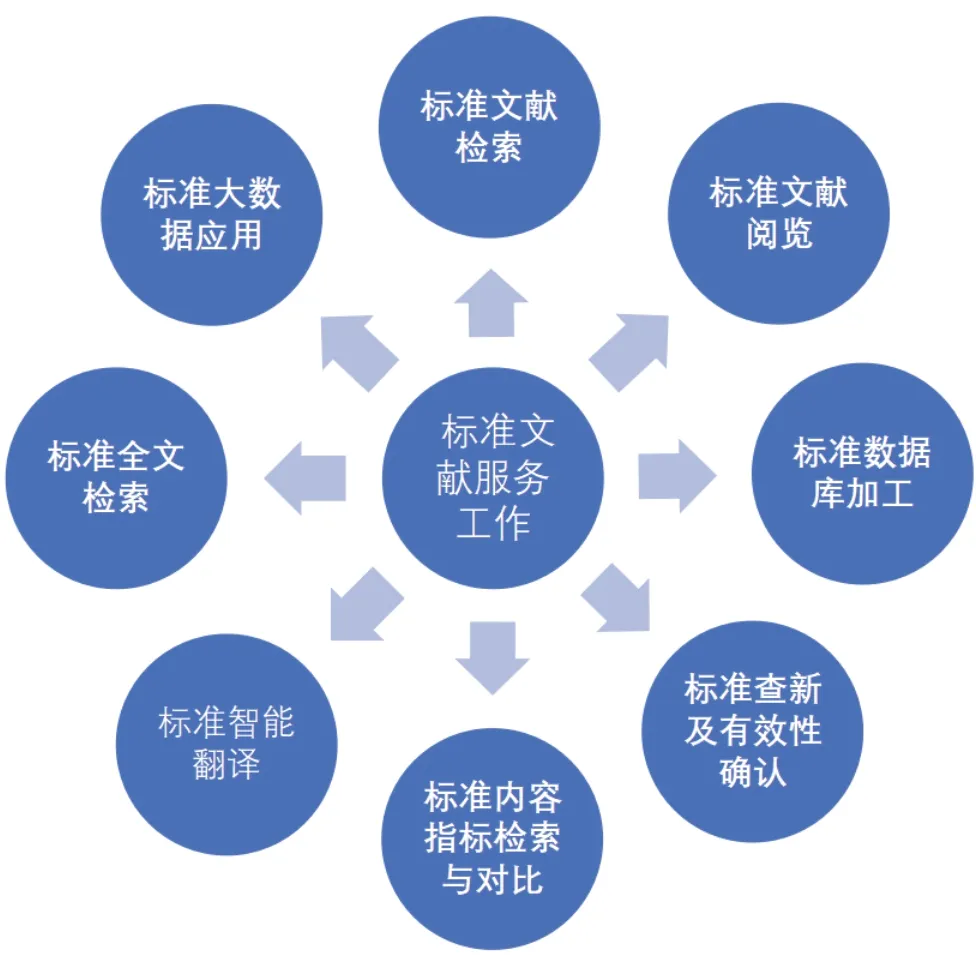
圖5 21世紀10年代我國的標準文獻服務工作內容
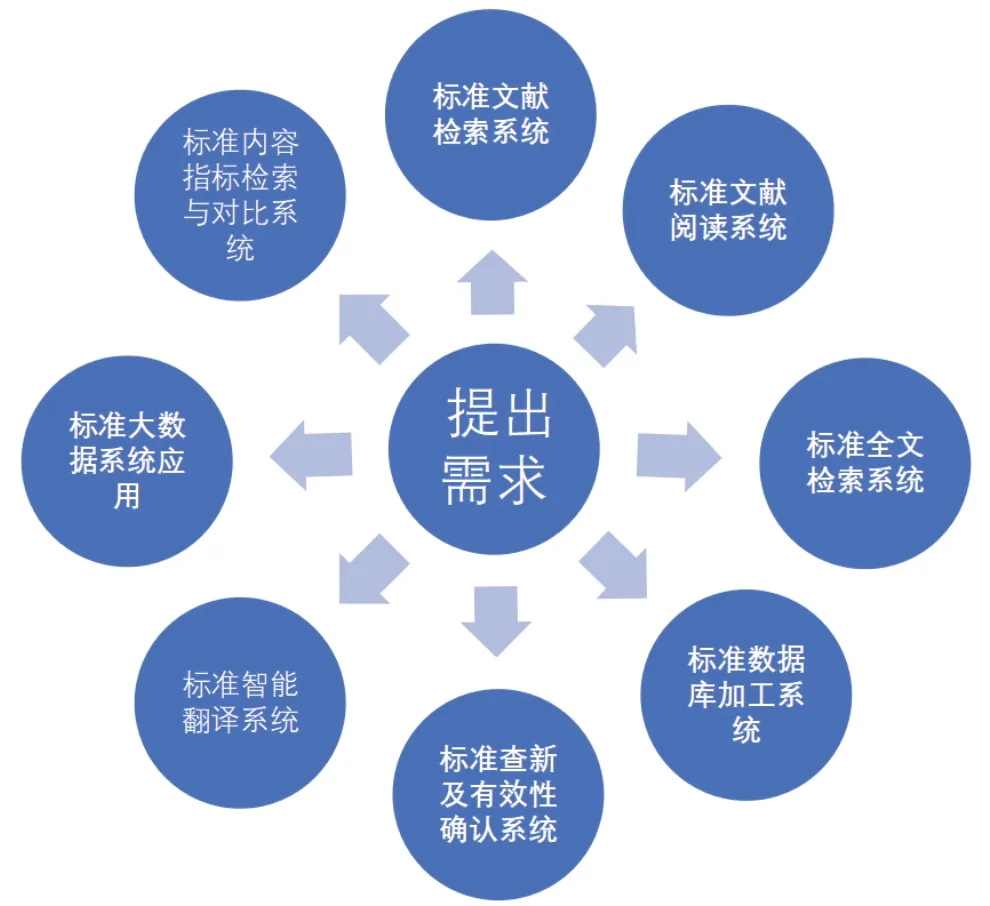
圖6 21世紀10年代我國標準文獻服務工作流程
從流程來看,標準文獻服務從傳統的針對一對多流程轉變為多對多的流程,從解決問題的范圍來看,能解決更多問題,從解決問題的時間來看,大幅縮短了服務時間,從解決問題的深度看,服務內容更精準,因此,在標準文獻服務方面能更廣泛、更深刻、更高效地解決對標準文獻的需求問題。
“標準有效性確認服務”:依據各類大型標準信息數據庫、標準組織的官方網站和期刊等多種權威信息渠道,對標準的有效性進行確認,查驗標準的更新、替代、廢止信息,并出具權威的確認報告,為企業用戶認證、質量評定及標準應用提供技術保障。現有的技術手段,可以自動跟蹤各種標準組織官方網站、各種期刊網站的最新標準信息,并在數據庫中自動標記更新情況,確保了正確開展標準有效性服務。
“標準文獻閱讀系統”:可以輸入關鍵詞或主題詞進行檢索,系統在相關的題錄中查找相關題錄,通過人機互動選擇相關題錄并引導系統指向相關文本進行閱讀。
“標準全文檢索系統”:在進行檢索前需要對標準進行全文加工,全文加工是對圖像進行一系列的處理,最終得到圖像上的文字信息,并產生多種形式的文字類型的電子文檔。全文加工除了要進行拆分圖像、圖像處理之外,還要對圖像進行版面分析、OCR識別、校對、導出等工序的處理。
版面分析對圖像按照其內容的形式進行區域劃分,并標記出每一個區域分別是橫排文本、豎排文本、圖片還是表格,以及每一個文字和表格區域的語言類型等。這部分內容一般由軟件自動處理,如果有分析失敗的情況,則需要有人工進行調整。
在版面分析的結果之上,由TH-OCR文字識別核心進行自動地識別處理。這一步驟不需要人工干預,完全由計算機程序完成。
校對工序通過提供強大便捷的軟件校對技術手段,可以過濾處大部分的識別錯誤,最后通過人工把關,可以大大提高工作效率。
導出工序可以將識別結果導出為各種形式的文檔,例如純文本的TXT文件、RTF文件、可檢索的雙層PDF文件等。
在進行全文加工后,對于需要檢索特定標準中的特定信息,通過“標準全文檢索系統”,可以很方便地實現迅速找到在特定標準中的任意字符,并查看任意字符的上下文關系,快速定位到查找目標。
“標準數據加工系統”:針對標準全文的加工按照加工的精細程度可分為:題錄加工、圖像加工、全文加工和結構化全文加工。這三種加工方式,每一種加工都比前一種更進一步,但得到的數據也更豐富,在此基礎上可以提供的服務也更豐富多樣。所謂結構化加工就是按照一定的規則,將標準的內容進行結構化的描述。例如將其中的前言、范圍、引用文件、圖片、表格、公式等內容以不同的標記標注出來。“結構化全文加工”需要進行結構化全文標注的處理。所謂結構化全文標注是指對標準全文中的不同部分,采用相應的標記進行標識,最終得到一個包含了標注信息的結構化全文文件。這一工序也可以由計算機自動完成,加工人員需要檢查自動處理的正確性,并進行手工修正。“結構化加工”的目標是:一是實現數據庫共享,通過結構化全文的建設,對國家標準、行業標準進行結構化處理,加工成果可用于在標準信息服務平臺進行數據共享。二是數據存儲結構設計的合理性:使用關系型模式保存,針對題錄數據的特點,設計合理的存儲模式,必須要符合關系型數據庫的一系列設計規范。全文的存儲模式在設計時既要考慮合理性又要考慮其實用性。三是實現對標準全文進行結構化檢索。例如,可以在標準前言中檢索起草單位,這樣就可以很方便地了解特定單位到底參加了哪些標準的制定,是主導制定還是參與制定;也可以在標準范圍中進行檢索,例如,可以輸入“冷鏈物流”,那么所有在范圍中有涉及“冷鏈物流”的標準都會快速顯示出來。
“標準內容指標檢索與對比”:通過大數據系統,對特定領域或產品,涉及的國內外標準關鍵指標進行深層揭示、技術指標提取和對比分析,以信息化作為支撐,對比產品所執行的標準與國標、國外標準的技術指標差異。例如,針對基礎標準化研究領域的產品與環境的人性化設計與測評服務(包括產品與環境的人性化設計、用戶體驗測評、人體工程學設計與測評、人類工效學設計與測評)、中國人體特性數據服務(包括樣本年齡、采樣地域分布、人體尺寸、力量、關節活動范圍、視覺、聽覺、觸覺、認知以及熱感知特性等中國人群的工效學特性數據)、公共信息導向系統規劃設計服務、圖形符號數據查詢服務(包括收集和整理了國內外各類圖形符號相關標準,可以對標準圖形符號進行查詢、瀏覽和下載)、標準術語查詢服務(標準術語的中文詞、外文詞、定義、符號、出處、相關術語、所在標準信息)等,這些應用標準深層次的標準文獻服務隨著大數據的出現應運而生,不斷推動著標準文獻服務工作向更深層次發展。
猜你喜歡
城市道橋與防洪(2022年4期)2022-07-01 06:04:12
今日農業(2019年14期)2019-09-18 01:21:54
今日農業(2019年12期)2019-08-15 00:56:32
當代陜西(2019年8期)2019-05-09 02:22:48
動漫星空(興趣百科)(2019年3期)2019-03-07 07:23:10
今日農業(2019年10期)2019-01-04 04:28:15
今日農業(2019年15期)2019-01-03 12:11:33
今日農業(2019年16期)2019-01-03 11:39:20
家庭影院技術(2018年4期)2018-05-09 07:07:52
商周刊(2017年9期)2017-08-22 02:57:56
