面向概念漂移且不平衡數據流的G-mean加權分類方法
2022-12-16 02:42:44李光輝代成龍
計算機研究與發展 2022年12期
梁 斌 李光輝 代成龍
(江南大學人工智能與計算機學院 江蘇無錫 214122)(1634113866@qq.com)
信息的爆炸性增長導致數據流廣泛出現在各個應用領域中,如無線傳感器數據流、銀行交易數據流等[1-3].數據流中的潛在分布或目標概念隨著時間推移發生變化,這種現象被稱為“概念漂移”[4-5].概念漂移會導致在過去數據上訓練的分類模型性能顯著下降,無法適應當前的新概念,這給傳統的數據挖掘算法帶來新的挑戰.另一方面,當數據流中存在類別不平衡現象時,即某一類的實例數量顯著多于其他類,數據流分類會變得更加困難,因為少類實例(minority class instance)[6-7]出現頻率過低導致分類模型對它們學習不充分,而我們通常更關注少類的分類情況,因為誤分類一個少類實例的代價通常遠大于誤分類一個多類實例(majority class instance)的代價,例如在癌癥診斷中,將患癌人群診斷為健康會帶來嚴重后果.
目前可以同時處理概念漂移和類別不平衡問題的數據流分類方法大多是基于集成學習的思想,主要包括在線集成和基于數據塊的集成方法[8].在線集成方法以Wang等人[9]提出的OOB(oversampling online bagging)和UOB(undersampling online bagging)為代表,它們將過采樣和欠采樣技術與Online Bagging[10]相結合,動態調整采樣頻率,有效解決了數據流中類別不平衡問題.在線集成方法通常還與針對不平衡數據流設計的漂移檢測方法結合,例如Wang等人[11]提出的DDM-OCI(drift detection method for online class imbalance learning)結合Online Bagging,通過監測少類召回率的變化在不平衡數據流中檢測漂移.但DDM-OCI假設數據流服從高斯分布,因而在實際應用中存在較高的誤報率.為此,Wang等人[12]又提出了LFR(linear four rates)使用統計學檢驗分析中的TPR(true positive rate),TNR(true negative rate),PPV(positive predicted value),NPV(negative predicted value)4個指標的變化顯著性來檢測漂移,有效降低了DDM-OCI的誤報率.而Wang等人[13]提出的HLFR(hierarchical linear four rate)使用分層假設檢測框架,在第1層使用LFR檢測漂移,第2層使用排列檢驗(permutation test)驗證漂移的真實性,進一步降低了LFR檢測漂移的誤報率.在所有基于數據塊的集成方法中,Gao等人[14]提出的UB(uncorrelated bagging)是第一個解決數據流中類別不平衡的方法.UB使用集成框架,不斷累積數據流中的少類實例,然后添加到當前數據塊中平衡數據分布.然而這種策略不僅需要大量的內存空間來存儲累積的少類實例,而且沒有考慮少類實例上可能發生概念漂移的問題,有較大的局限性.為此,Chen等人[15]提出的SERA(selectively recursive approach)改進了UB,它使用馬氏距離計算累積的少類實例和當前數據塊中少類實例的相似度,只選擇相似度較高的少類實例平衡當前數據塊的類別分布.進一步,Chen等人[16]又提出了REA(recursive ensemble approach),該方法使用KNN(k-nearest neighbors)計算相似度,替換SERA中的馬氏距離度量,解決了少類實例中的子概念問題.而針對重采樣過程存在的一些困難因素,例如異常數據,類別重疊等,Ren等人[17]提出了GRE(gradual recursive ensemble),它使用DBSCAN聚類技術將當前少類實例分為若干個簇,然后分別計算各個簇中實例和過去數據塊中少類實例的相似度,選擇部分少類實例填充至當前數據塊,解決了重采樣過程中數據異常和類別重疊問題.Wu等人[18]提出的DFGW-IS(dynamic feature group weighting with importance sampling)通過分析當前數據塊和過去數據塊的海林格距離差異來檢測概念漂移,同時結合重要性采樣處理類別不平衡問題.基于數據塊的集成方法存在一個共性問題:它們都假設少類實例的概念不會發生變化,即過去數據塊中的少類實例可以繼續使用.然而在實際情況中,類的先驗概率隨時間也會發生變化,過去數據塊中少類實例可能就是當前數據塊中的多類實例.另外,重復訪問歷史數據也不符合數據流挖掘的要求.因此,以Ditzler等人[19]的Lean++CDS和Lean++NIE為代表,一些不需要保存歷史數據的集成方法被提出.Lean++CDS是Learn++NSE和SMOTE(synthetic minority class oversampling technique)的簡單結合,其中Learn++NSE用于處理概念漂移,而SMOTE產生新的少類實例以平衡當前數據塊的類別分布,無需保存任何歷史數據.Lean++NIE也不需要訪問歷史數據,在每個數據塊上對多類實例進行欠采樣,結合Bagging技術生成一個由多個成員分類器組成的子集成模塊,并根據成員分類器在過去和當前數據塊上的G-mean性能分配權重,有效平衡每個類別的重要性.此外,Lu等人[20]提出的DWMIL(dynamic weighted majority for imbalance learning)在集成模型中只保留有限數量的成員分類器,每個成員分類器的權重根據在當前數據塊上的G-mean性能決定,并隨著時間衰減,直至小于某個閾值被移除,兼顧了效率和性能.
基于上述分析,目前已有的方法主要存在2個問題:一是需要大量空間保存過去的少類實例進行重復使用,且沒有考慮類先驗概率變化的情況;二是集成方法中的成員分類器權重是基于數據塊更新的,缺乏在線更新機制,面對突變型漂移或發生在數據塊內的漂移時,難以快速應對.為此,針對二分類數據流,本文在基于數據塊集成方法上引入了在線更新機制,提出了一種基于G-mean加權的在線不平衡數據流分類方法(online G-mean update ensemble for imbalance learning, OGUEIL),以集成框架為基礎,每到達1個新實例,增量更新每個成員分類器及其權重,并對少類實例隨機過采樣,無須保存歷史數據,同時周期性地訓練多個具有差異性的候選分類器以提高集成模型的泛化能力.與同類方法相比,本文主要貢獻有3個方面:
1) 提出了一種基于G-mean的在線加權策略,可以根據當前數據分布及時調整每個成員分類器的權重,有效解決不平衡數據流中的概念漂移問題.
2) 在集成模型在線更新過程中引入了對少類實例的隨機過采樣策略,既提高了少類實例的召回率,又增加了集成的多樣性.
3) 基于混合采樣和自適應滑動窗口技術提出了一種候選分類器訓練策略,周期性地對當前窗口上的數據同時使用邊界人工少類實例合成技術[21]和隨機欠采樣技術生成多個具有差異性的候選分類器,并將它們選擇性地添加至當前集成模型中,提高泛化能力.
1 相關知識
1.1 數據流概述
在數據流分類領域,數據流由大量按時間順序到達的實例組成,表示為S={s1,s2,…,st,…},其中st=(Xt,yt)表示時刻t到達的實例,Xt=(d1,d2,…,dn)代表n維向量,意味著數據流S是n維的,yt∈{c1,c2,…,ck}表示實例st真實類別,k為數據流S中所有類別數量.
1.2 概念漂移定義和分類
概念漂移是指數據流中的目標概念隨時間發生改變,在數據流分類領域,目標概念一般指當前分類模型學習到的決策邊界.具體而言,假設數據流S服從某分布Ft(X,y),P(y|X)表示y關于X的條件概率分布,代表決策邊界,若在時刻t+1有Ft(X,y)≠Ft+1(X,y)且Pt(y|X)≠Pt+1(y|X),表明原有的決策邊界發生變化,這種現象稱為概念漂移[8,22].
概念漂移的分類普遍是基于概念變化的速度[22-23].當新舊概念過渡很快,舊的概念突然被另一個數據分布完全不同的新概念取代,這種漂移屬于突變型概念漂移(abrupt concept drift);反之,新舊概念過渡較慢時,舊概念被新概念逐漸替換,且二者在漂移前后或多或少有些相似,則屬于漸變型概念漂移(gradual concept drift).
1.3 在線過采樣集成算法OOB
針對數據流中的類別不平衡問題,Wang等人在OB(online bagging)[10]基礎上提出了在線過采樣集成算法OOB(oversampling OB)[9].OB將傳統的集成學習算法Bagging從靜態數據領域擴展到了數據流領域.Bagging算法首先對所有樣本放回隨機采樣,然后得到多個訓練集,最后訓練多個不同的成員分類器.因此每個樣本會被重復選擇k次,且k服從二項分布,如式(1)所示:
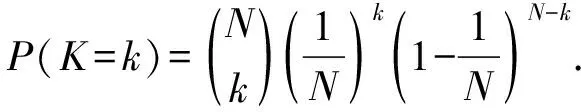
(1)

2 基于G-mean加權的在線不平衡數據流分類方法
針對二分類數據流中的概念漂移和類別不平衡問題,本文提出了一種基于G-mean加權的數據流分類方法(OGUEIL).OGUEIL屬于在線集成方法,其主要思想是通過使用在線決策樹Hoeffding tree[24]和基于G-mean的在線加權機制,在基于數據塊的集成方法中引入在線更新機制,避免數據塊大小難以選擇的問題,可以有效處理各種類型的概念漂移,包括突變型、漸變型以及發生在數據塊內部的漂移,提高分類性能.在線更新過程中,OGUEIL結合OOB[9]對少類實例進行隨機過采樣,既提高了少類實例的召回率,又增加了集成的多樣性,且不需要保存任何歷史數據.此外,OGUEIL會周期性地添加和淘汰集成中的成員分類器以維持集成模型的分類效率和性能.OGUEIL包含更新、淘汰、候選分類器訓練、加權和決策5個過程,下面分別詳細介紹各過程的算法思路與偽代碼.
2.1 在線更新和淘汰機制
在OGUEIL中,每獲得一個新實例(xt,yt),所有成員分類器更新一次.為解決數據流中類別不平衡導致少類召回率過低的問題,OGUEIL結合OOB[9]算法對少類實例隨機過采樣,即對每個少類實例學習k次,且k服從參數為ξ的泊松分布,ξ為當前數據流中多類實例與少類實例的數量比,OOB偽代碼如算法1所示.由于數據流的不穩定性,類的先驗分布可能發生變化,甚至少類和多類發生角色互換,因此OGUEIL需要實時監測數據流中多類實例和少類實例的分布情況.
算法1.OOB[9].
輸入:時刻t到達的實例(xt,yt),當前集成模型Ω,當前多類實例數量|Ymaj|,當前少類實例數量|Ymin|;
輸出:更新后的集成模型Ω.
① while到達一個新實例
② 對于當前集成模型Ω中的每一個分類器Ci:
③ 計算當前數據流的不平衡率ξ←|Ymaj|/|Ymin|;
④ if當前實例屬于少類
⑤ 根據式(3)設置k~Poisson(ξ);
⑥ else
⑦ 設置k~Poisson(1);
⑧ end if
⑨ 更新k次分類器Ci;
⑩ end while

(2)
如果xt的真實類別是正類cp,那么[(xt,cp)]=1,否則[(xt,cp)]=0,對于負類cn也是同理,而λ為預設的時間衰減因子.區別于傳統累加每個類別實例的方式,這種方式使用時間衰減因子進行指數平滑,強調當前數據的影響同時弱化舊數據的影響,更適合用在數據流中.然后根據式(3)確定少類和多類,其中δ為預設的閾值.若滿足式(3),正類cp被標記為多類,負類cn為少類,反之亦然.

(3)
在本文中,參數δ是通過大量實驗獲得的經驗值,δ過大或過小均會影響到算法性能.在第3節實驗中,本文將詳細介紹各個參數的設置.為保證集成分類的效率和準確率,OGUEIL使用淘汰機制優化集成結構:每當創建一個新候選分類器時,若集成模型的成員數量沒有達到預設的最大值m,直接添加成員,否則替換權重最小的成員,這樣保證了集成模型的成員不會隨時間無限增加,降低內存消耗.
2.2 候選分類器訓練
如何訓練泛化能力強的候選分類器是克服多類別不平衡、提高少類分類準確率的關鍵.普遍的解決方案是對多類實例欠采樣或對少類實例過采樣,這2種方法都有各自的優點和缺陷.本文結合過采樣和欠采樣,提出了一種基于混合采樣的候選分類器訓練方法(candidate classifier training, CCT),如算法2所示.OGUEIL每隔固定周期檢測當前窗口中各類實例的數量是否均超過預設值β,若滿足則開始訓練T(T>1)個新候選分類器.首先確定當前窗口中所有類實例數量的最大值(max)和最小值(min),然后在min和max之間隨機取值N作為之后每類實例的重采樣數量.對于實例數量少于N的類,OGUEIL使用邊界人工合成少類樣本方法(BorderlineSMOTE)[21]將其數量過采樣至N,值得注意的是,它屬于過采樣方法的一種,通過在決策邊界附近人工合成少類樣本來平衡數據分布,既增強了決策邊界,又降低了過擬合的風險;而對于實例數量大于N的類,通過隨機欠采樣(RUS)將其數量削減,最終使用類分布相對平衡的數據集訓練候選分類器.由于OGUEIL每次生成不止一個候選分類器,且每次的采樣數量都是隨機選取,因此可以最大限度減少有價值的信息的丟失.同時,由于訓練每個候選分類器的數據集都不同,OGUEIL會得到一組具有足夠多樣性的候選分類器,可以增強整體集成分類器的泛化能力.生成T個候選分類器后,此時如果當前集成規模|Ω|與T之和小于預設的集成最大成員數m,直接添加成員分類器,否則移除集成中權重最小的成員分類器,直至滿足|Ω|+T 算法2.CCT. 輸入:當前窗口W中的數據D; 輸出:新的候選分類器. ① 確定D中所有類實例數量的最大值max和最小值min; ② 在[min,max]內隨機取值N作為之后每個類實例的重采樣數量; ③ 對實例數量少于N的類使用Borderline-SMOTE過采樣至N; ④ 對實例數量大于N的類使用RUS欠采樣至N; ⑤ 使用處理后的數據集D訓練一個新的候選分類器. 數據流集成分類方法的加權機制大都是基于數據塊的,即每到達一個數據塊,集成中每個成員分類器的權重由在當前數據塊上的分類精度決定.當面對突變型漂移或發生在數據塊內的漂移時,基于數據塊的加權機制難以快速調整成員分類器的權重.此外,基于分類精度的加權機制容易受到類分布的影響,導致成員分類器偏向多類,忽略少類.為此本文提出了一種基于G-mean的在線加權機制,它的特點是每到達一個新實例而不是一個完整的數據塊,所有成員分類器的權重更新一次且不受類分布的影響.更新成員分類器時既考慮該分類器創建的時間,又考慮它在最近d個數據上的G-mean性能.二分類數據流中,G-mean就是正類cp上的準確率PR和負類cn上的準確率NR的幾何平均值,如式(4)所示: (4) (5) (6) (7) 在時刻t,每個成員分類器的權重通過式(8)~(11)更新: (8) (9) (11) (12) 其中,sgn(·)為符號函數,若括號中結果大于0,返回1,代表正類cp;否則返回-1,代表負類cn.OGUEIL的偽代碼如算法3所示: 算法3.OGUEIL. 輸入:數據流S、檢測周期d、集成模型容量m、成員分類器Ci、少類實例數量最小值β、滑動窗口W、候選分類器個數T; 輸出:加權集成模型Ω. ① while每到達一個新實例(xt,yt) ③ 根據式(2)增量計算每個類的實例大小; ④ 根據式(3)確定當前數據流中的少類和多類; ⑤ 把新實例(xt,yt)添加到窗口W中; ⑥ 根據式(8)~(11),使用(xt,yt)更新集成中每個成員分類器Ci的權重; ⑦ 每隔d個實例: ⑧ if窗口W中的少類實例數量大于β: ⑨ 調用CCT算法T次,訓練T個新的候選分類器; ⑩ end if OGUEIL集成模型使用Hoeffding tree做基分類器,Hoeffding tree學習每個實例的時間復雜度為O(1),故含有m個Hoeffding tree的集成模型學習時間復雜度為O(m).OOB使每個Hoeffding tree訓練k次,k服從泊松分布,OGUEIL的時間復雜度變為O(km).每個類的數量計算均通過增量計算,所以時間復雜度為O(1).CCT算法創建T個候選分類器的時間復雜度為O(2TN),N代表采樣數量,而每個基分類器通過式(8)~(11)加權需要O(1)時間,對m個基分類器加權的時間復雜度為O(m).綜上,OGUEIL的時間復雜度為O(km+2TN+m),由于k,m,N,T均與輸入數據流的規模無關,故OGUEIL關于數據流規模的時間復雜度可解析為O(1). 關于方法的空間復雜度,由于OGUEIL使用滑動窗口處理數據,創建分類器時需存儲N個樣本數據.因此方法的空間復雜度為O(TN),這里T為候選分類器個數.顯然,滑動窗口大小、采樣數量和分類器個數均與輸入數據流的規模無關,故關于輸入數據流規模的空間復雜度仍可視為O(1). 為驗證OGUEIL方法的性能,本節將OGUEIL和其他5種同類方法在人工和真實數據集上進行實驗比較.對比方法可分為2類:一類是基于數據塊的集成方法:DWMIL[20],Learn++NIE[19](后面簡稱為LPN)和REA[16];另一類是在線集成方法:OAUE[26],OOB[9].實驗環境:1臺處理器為Intel Core i7-7700HQ,內存為16 GB的筆記本電腦,運行Windows 10系統和python3.7.在該環境下,分別實現了本文方法和對比方法,對比方法的參數設置均各參照對應文獻.OGUEIL的參數設置為:成員分類器使用python的scikit-multiflow包[27]的Hoeffding tree使用默認設置;時間衰減因子λ和類別不平衡檢測閾值δ設置參照文獻[9],分別設為0.9和0;p根據大量實驗確定,設為500;集成最大成員數量m=15;創建候選分類器所需的最小少類實例數量β=15;ε=0.000 000 1. 本文利用以下指標對方法進行評價,包括二分類數據流中的分類準確率ACC(accuracy)、幾何均值Gmean(geometry mean)、少類召回率MCR(minority class recall),其具體定義如式(13)(14)所示. (14) Table 1 Confusion Matrix表1 混淆矩陣 實驗共用到6個人工數據集和2個真實數據集,詳情如下: Sine數據集[4].該數據集生成器有2個屬性x和y.分類函數是y=sin(x),在第1次漂移之前,函數曲線下方的實例被標記為正類,曲線上方的實例被標記為負類,共有2個類別.在漂移點,通過反轉分類規則來產生漂移.Sine共包含100 000個實例,每隔20 000個實例產生1次漂移,類分布平衡,含10%噪聲. Sea數據集[28].該數據集生成器有3個屬性,其中第3個屬性與類別無關,如果x1+x2<α,實例分類為正,否則為負,x1,x2表示前2個屬性.通過欠采樣生成2個新的數據集:1)Seaac通過欠采樣產生類別不平衡,不平衡率(指少類實例所占百分比)初始化為0.05,在數據流中某處會突然上升至0.95,即多類實例變為少類實例;2)Seanc通過欠采樣產生類別不平衡,不平衡率固定為0.05. Circle數據集[4].該數據集生成器有2個屬性x和y.4個不同圓方程表示4個不同概念.圓內的實例被分類為正,圓外為負,共2個類別.在漂移點通過更換圓的方程來產生漂移.Circle數據集共包含50 000個實例,每隔12 500個實例產生1次漂移,類分布平衡,含10%噪聲. Hyper Plane數據集[28].該數據集生成器有10個屬性,通過連續旋轉決策超平面產生漂移.Hyper Planenc包含50 000個實例,不平衡率固定為0.05. Gaussian數據集[28].該數據集生成器有2個屬性,通過改變高斯成分的均值和方差產生漂移.本實驗中通過欠采樣產生類別不平衡數據集Gaussiangc,不平衡率初始化為0.05,然后逐漸上升至0.95. Electricity數據集[4].該數據集為真實數據集,收集了澳大利亞新南威爾士州電力市場的45 312個電價數據,包含8個屬性和2個類別. Weather數據集[20].該數據集為真實數據集,包含貝爾維尤和內布拉斯加州50多年來的天氣信息.任務是預測一天是否下雨.本實驗中通過欠采樣實現類別不平衡[20],不平衡固定為0.05,包含18 159個實例,有8個屬性和2個類別. 表2總結了所有數據集的信息.實驗用到的8個數據集進一步可分為四大類,模擬4種不同場景:1)概念漂移的類平衡數據集,包括Sine,Circle,Electricity;2)有概念漂移的類別不平衡數據集且包含不平衡率突然變化的情況,包括Seaac;3)有概念漂移的類別不平衡數據集且包含不平衡率逐漸變化的情況,包括Gaussiangc;4)有概念漂移的類別不平衡數據集且不平衡率固定不變,包括Seanc,Hyper Planenc. Table 2 Description of Datasets表2 數據集的描述 本節用OGUEIL的參數p(基分類器更新周期)的不同值對算法G-mean性能進行了實驗,結果如表3所示. 由表3中數據可知,參數p的不同取值對OGUEIL的G-mean性能影響較小,同時p=500時在8個數據集上的平均排名最高,所以最終OGUEIL的參數p設置為500. Table 3 G-Mean Results of OGUEIL Under Different p Values表3 不同p值下的OGUEIL的G-mean結果 本節比較了OGUEIL和其他5種方法在上述8個數據集上的分類準確率,G-mean和少類召回率,結果如表4~6所示.表4給出了所有方法的8個數據集上的準確率結果.根據表4可以看出:其一,Sine,Circle,Electricity 3個數據集的類分布相對平衡,準確率可以較好地反映每種方法的性能,OGUEIL在這3個數據集上準確率均排在第1,表明OGUEIL可以很好地處理各種類型概念漂移,緊接著是OAUE和DWMIL,二者結果相近;其二,在其余類分布不平衡數據集上,OAUE均排名第1,但這不能表明OAUE處理類別不平衡數據流中概念漂移的能力強于其他方法,因為數據流的類分布嚴重不平衡時,準確率會偏向于多類,意味著一個方法只有把所有實例預測為多類就可以獲得很高的準確率,嚴重忽略少類實例,不能合理地反映方法性能.表5給出了各方法G-mean的實驗結果,G-mean對類分布不敏感,在平衡或不平衡數據流中都可很好地反映一個方法的性能.結果顯示:OGUEIL在7個數據集上平均排名最高,DWMIL次之,而OAUE的G-mean性能很差,在Weather上甚至為0,但它的準確率很高,這表明它的多類性能很好而少類性能很差,主要因為它沒有處理類別不平衡的機制,容易將少類實例誤分類為多類實例.REA是針對不平衡數據流的方法,但它的G-mean性能很差,甚至弱于OAUE,主要因為它保存過去所有數據塊中的少類實例,然后通過KNN(k-nearest neighbors)選擇部分少類實例平衡當前數據塊的類分布,這種機制很容易受到概念漂移的影響,當少類上的概念發生漂移時,少類實例會和多類實例大量重疊,嚴重影響方法G-mean性能.少類召回率的結果如表6所示,OGUEIL和DWMIL的平均排名并列第1,特別地,在Sine,Circle,Electricity這3個類分布相對平衡的數據集上,OGUEIL的少類召回率高于DWMIL,而在剩下的類分布不平衡數據集上OGUEIL的少類召回率低于DWMIL.結合表4,5,OGUEIL在準確率和G-mean上的表現均優于DWMIL,表明OGUEIL在維持少類性能的同時沒有過多犧牲多類的性能,在2個類上的性能達到了最佳平衡. Table 4 Accuracy Results of All Datasets表4 所有數據集上的準確率結果 Table 5 G-Mean Results of All Datasets表5 所有數據集上G-mean結果 Table 6 Minority Class Recall Results of All Datasets表6 所有數據集上少類召回率結果 Fig. 1 Experimental results on the Sine dataset圖1 Sine數據集上的實驗結果 Fig. 2 Experimental results on the Hyper Planenc dataset圖2 Hyper Planenc數據集上的實驗結果 圖1為Sine數據集上的結果,該數據集為類分布平衡數據集,可以發現各方法在準確率、G-mean和少類召回率上的性能變化曲線基本一致,以圖1(a)的準確率結果為例,可以得到以下觀測結果:1)OGUEIL的準確率最高,OAUE和DWMIL次之,REA的準確率最低,表明OGUEIL,OAUE和DWMIL的抵抗概念漂移能力較強.2)Sine數據集每隔全部數據的20%,通過反轉分類規則產生一次突變型概念漂移,OGUEIL,OAUE,DWMIL受影響較小,準確率輕微下降后迅速恢復,其中OGUEIL得益于它的在線更新和在線加權機制,發生漂移后迅速更新所有成員分類器及其權重值,最先完成新概念的學習,準確率曲線率先上升.3)LPN,OOB,REA受概念漂移影響嚴重,尤其是REA,準確率甚至下降至0.5左右,這主要因為REA所有成員分類器無法增量更新,集成模型缺少成員分類器的淘汰機制,遭遇概念漂移時,在舊概念上訓練的大量成員分類器既不能增量更新,也不被淘汰,從而嚴重影響性能.LPN和REA類似,所有成員分類器也無法增量更新,集成模型也沒有淘汰機制,但它有獨特的加權機制,LPN中每個成員分類根據分類性能調整權重時,會使用sigmoid函數對它在當前數據塊上的性能和過去所有數據塊上的性能加權,可以快速地消除舊概念對當前集成模型的影響,同時若發現某個成員分類器的性能弱于隨機分類器,該成員分類器的權重置則被設置為0,消除它對最終決策的負面影響,故它處理概念漂移的能力強于REA.OOB沒有加權機制和成員分類器淘汰機制,但它的成員分類器是在線分類器,遭遇概念漂移時通過在線更新緩慢適應新的概念,整體效果略好于REA. 圖2為Hyper Planenc上的結果,該數據集是類分布不平衡的且不平衡率固定為5%,包含漸變型概念漂移.OAUE的準確率始終保持較高水平,但這以嚴重犧牲少類上的性能為前提,它的少類召回率遠低于其他方法.OGUEIL在3個評價指標上的性能曲線都沒有較大波動,始終保持著較高的水平,表現出較強的抗概念漂移能力.并且它在準確率和少類召回率上排名第2,在G-mean上排名第1,這表明OGUEIL很好地平衡了在每個類上的性能.DWMIL在少類召回率上性能很好,排名第1,但它準確率排在第5,這表明DWMIL以大幅犧牲多類上的性能為代價提高它在少類上的性能,處理類分布不平衡的策略有些激進.LPN的G-mean曲線和DWMIL的G-mean曲線十分接近,但它的少類召回率低于DWMIL少類召回率而準確率高于LPN的準確率,表明LPN處理類分布不平衡的策略較DWMIL保守一些,沒有為了提高少類上的性能而過多犧牲多類上的性能.OOB和REA在少類召回率上保持穩定,都高于OAUE的少類召回率,但在準確率和G-mean上低于OAUE的且存在較大的波動,主要因為它們對概念漂移的響應較慢,影響了在多類上的性能. Fig. 3 Experimental results on the Seaac dataset圖3 Seaac數據集上的實驗結果 Fig. 4 Experimental results on the Gaussiangc dataset圖4 Gaussiangc數據集上的實驗結果 圖3給出了各方法在Seaac上的實驗結果,該數據集是包含漸變漂移的類分布不平衡數據集,而且不平衡率會在數據集中發生突變,導致多類實例和少類實例的角色互換,因此在不平衡率變化處重置所有評價指標,如圖3中虛線所示(數據流40%的位置,虛線和實線部分重合).OGUEIL在各項性能指標上一直比較穩定,不平衡率突變后,它會根據當前數據流中類分布快速識別出多類實例和少類實例,然后調整集成中的所有成員分類器過采樣的目標,性能恢復最快,最終在準確率上排名第2,G-mean上排名第1,少類召回率上排名第4.而LPN,DWMIL,OOB,REA的恢復速度依次遞減.至于OAUE,它在準確率上受不平衡率突變影響最小,始終保持較高水平,原因與Hyper Planenc數據集上的相同,但它在G-mean和少類召回率上波動很大,在不平衡率突變前,隨著少類實例的增加,各項性能逐漸上升,突變后,由于缺乏處理類分布不平衡機制,一直處在下降狀態.值得注意的是,REA的少類召回率在不平衡率突變前很低,突變后,少類召回率大幅上升,甚至最后排名第1,這是因為突變前REA將大量多類實例預測為少類實例,突變后,多類實例變為少類實例,從而獲得了較高的少類召回率. 圖4為Gaussiangc上的結果,該數據集是包含漸變漂移的類分布不平衡數據集,而且不平衡率會在數據集中逐漸發生變化,數據流的狀態由不平衡逐漸變到平衡然后又到不平衡,因此在2次不平衡率變化處重置所有評價指標,如圖4中虛線所示.在第1次不平衡率變化后,數據流狀態由類分布嚴重不平衡逐步過渡到平衡狀態,除REA外所有方法的性能都保持穩定或上升狀態.第2次變化后,數據流又從平衡狀態轉變至不平衡狀態,多類實例變為少類實例,而少類實例變為多類實例,由于類分布的變化,所有方法的性能都有所下跌,然后隨數據流增加逐漸上升.OGUEIL的準確率基本保持穩定,最終排名第2,在G-mean和少類召回率上在短暫下降后迅速恢復,最終排名分別為第1和第3,整體上在3個性能指標上沒有出現較大波動,始終保持較高水平,表明OGUEIL有效地降低了概念漂移和類分布變化對集成性能的影響.除了少類召回率,REA和LPN在準確率和G-mean上均顯著低于沒有處理類分布不平衡機制的OAUE的準確率和G-mean,可能的原因是該數據集上的概念漂移嚴重影響了REA和LPN在多類實例上的準確率. 8個數據集上,所有方法的運行時間如表7所示.平均運行時間最短的是OOB,主要因為OOB的方法結構簡單,它沒有加權機制,沒有成員分類器的添加和淘汰機制,也無需保存任何歷史數據,只需維護集成模型在線更新和對少類實例的過采樣.OGUEIL在所有數據集上的運行時間都慢于OAUE,二者的加權和集成模型成員的創建、添加和淘汰操作的耗時相近,主要差別在于OGUEIL整合了OOB,集成模型的在線更新比OAUE增加了少類實例的過采樣.REA集成模型的成員分類器為靜態批處理方法,無法在線更新,減少了時間消耗,但是它的集成模型沒有淘汰機制,會保留所有成員分類器,同時它需要從歷史數據塊中尋找k個最近鄰用以平衡當前數據塊的類分布,這些機制導致了REA在小規模數據集上的運行效率較高,例如Electricity,Gaussianac等,而大規模的數據集上效率較低,例如Sine,Circle等,因為數據量越大,REA創建的成員分類器越多,搜索k個最近鄰的耗時也越高.DWMIL和LPN的運行時間明顯高于其他方法,主要因為二者都使用由若干靜態批處理分類器組成的集成分類器作為集成模型的成員分類器,不過DWMIL的集成模型有剪枝策略,LPN沒有,這就意味著LPN的規模會隨數據流無限擴大,導致決策時間消耗越來越大.此外,LPN在權重計算階段,不僅要考慮每個成員分類器在當前數據塊上的性能,還要考慮它在之前每個數據塊上的性能,這也會嚴重增加時間消耗. Table 7 Comparison of Running Time表7 運行時間對比 s 本文針對數據流中存在概念漂移和類別不平衡的問題,提出了一種新的不平衡數據流分類方法OGUEIL,它基于集成學習框架,綜合基于數據塊的方法和在線方法的優點,可以有效處理不平衡數據流中的概念漂移.OGUEIL是基于完全增量的方法,無需保存任何歷史數據,使用在線分類器作為成員分類器,每到達一個實例,對集成模型中的所有成員在線更新的同時根據每個成員在最近若干數據上的G-mean性能加權,性能越好的成員獲得權重值也越大.每隔固定周期,OGUEIL檢查當前是否滿足創建新候選分類器條件,若滿足就通過混合采樣創建多個具有差異性的候選分類器,然后選擇性地添加至集成中,并使用2種淘汰機制控制集成模型的規模,保持決策的高效性和準確性. 本文利用6個人工數據集和2個真實數據集模擬了4種不同場景,對OGUEIL與5種主流的同類方法進行了全面的對比實驗.結果表明,OGUEIL在少類數據上保持良好性能的同時沒有犧牲在多類數據上的性能,在平衡與不平衡數據流下都可以有效處理概念漂移,綜合性能優于其它方法,具有較強的魯棒性. 作者貢獻聲明:梁斌提出了算法思路和實驗方案,完成實驗并撰寫論文;李光輝和代成龍提出了指導意見并修改論文.2.3 加權和決策機制
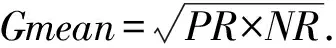
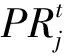

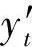
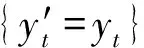

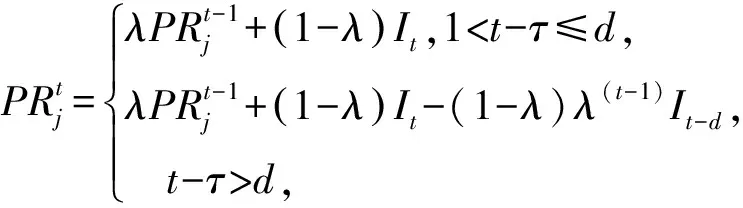
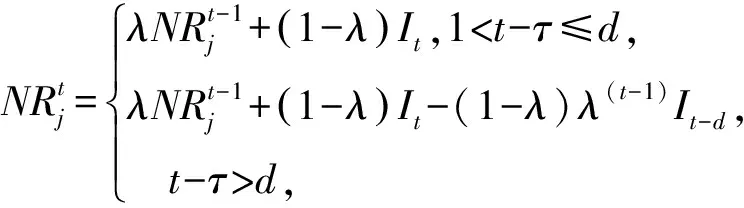
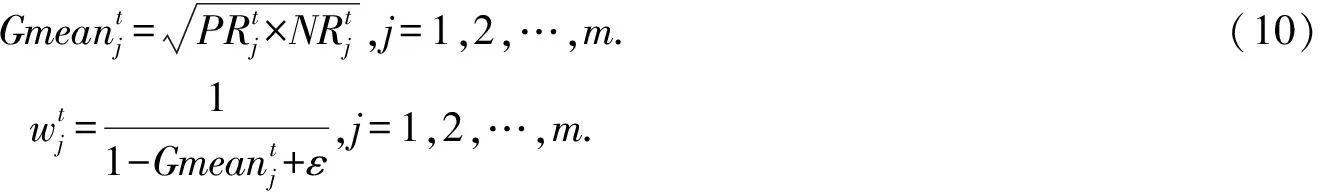
2.4 計算復雜度分析
3 實驗結果及其分析
3.1 性能評價指標


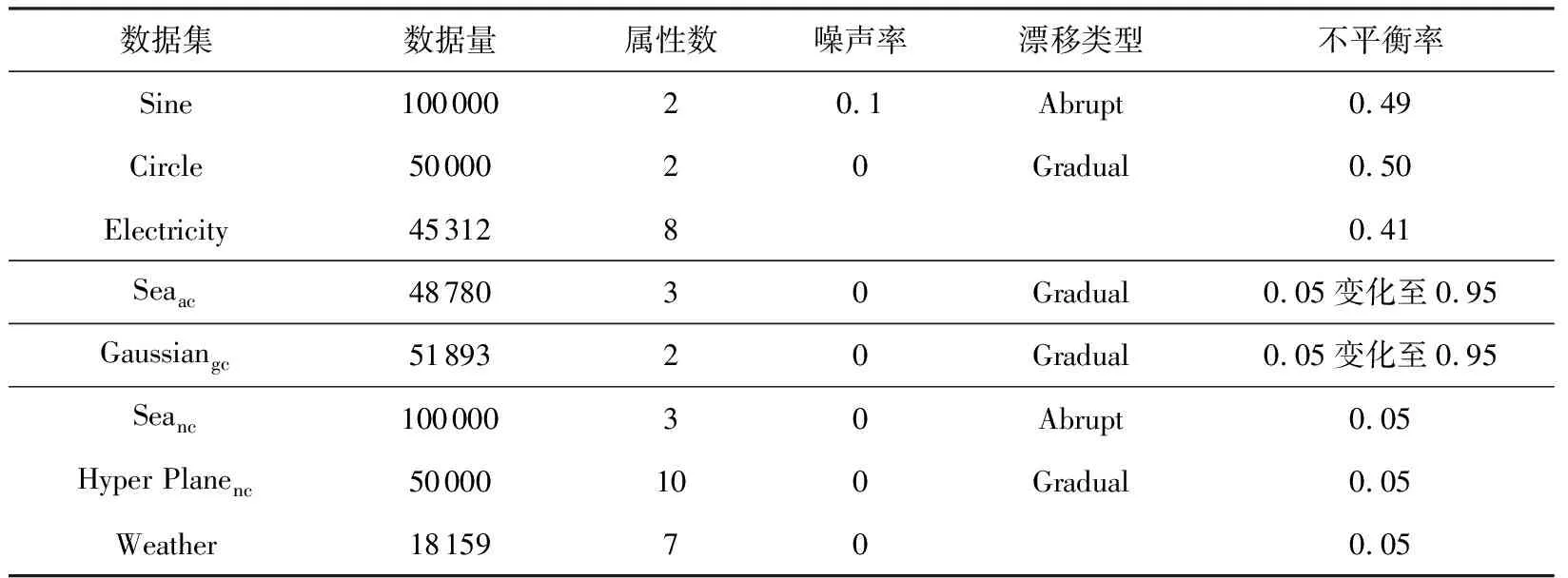
3.2 數據集介紹
3.3 參數實驗
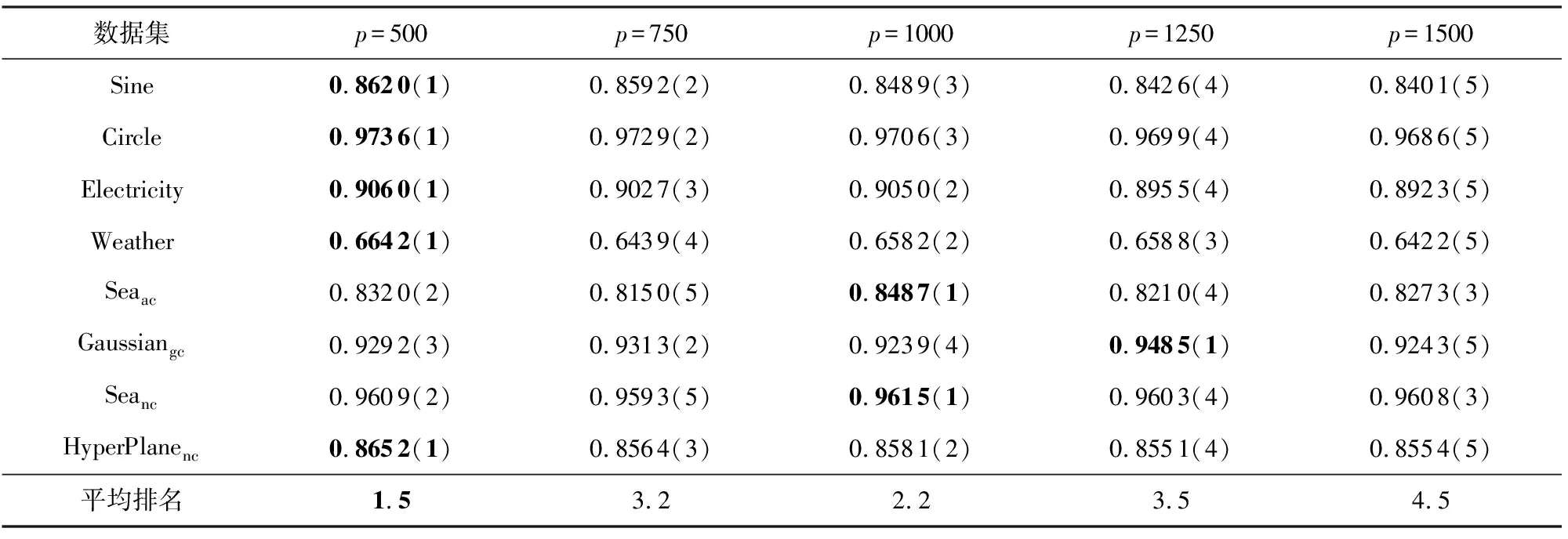
3.4 實驗結果分析
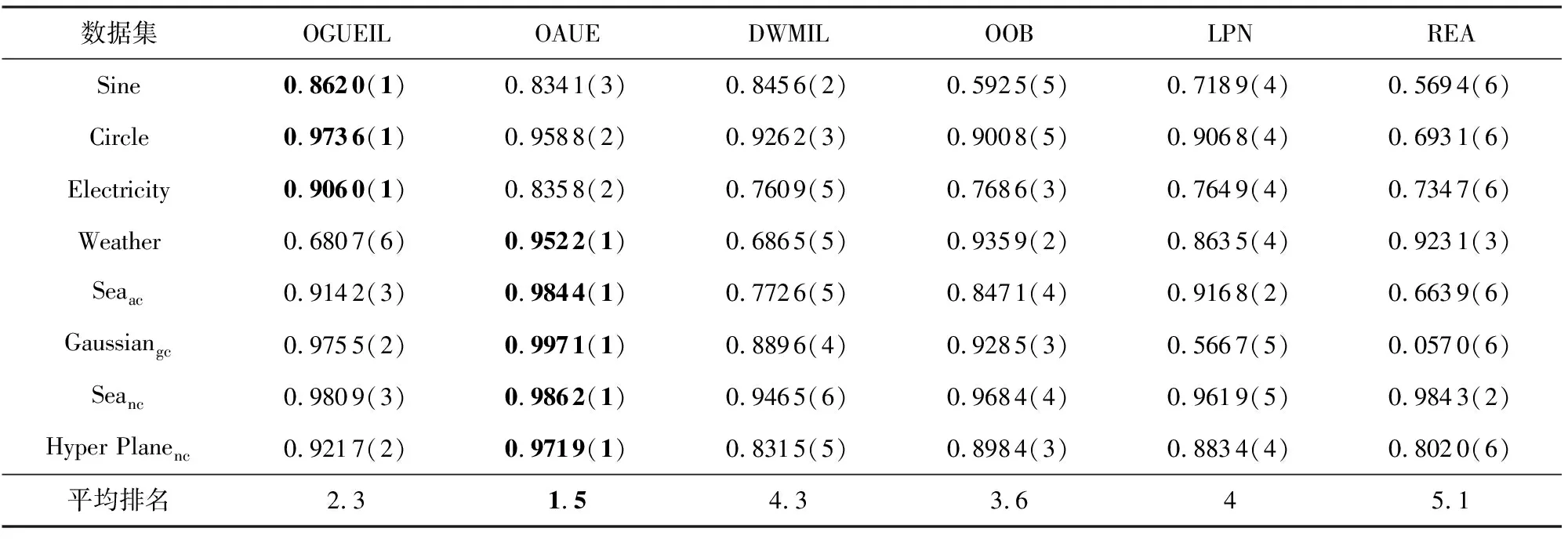
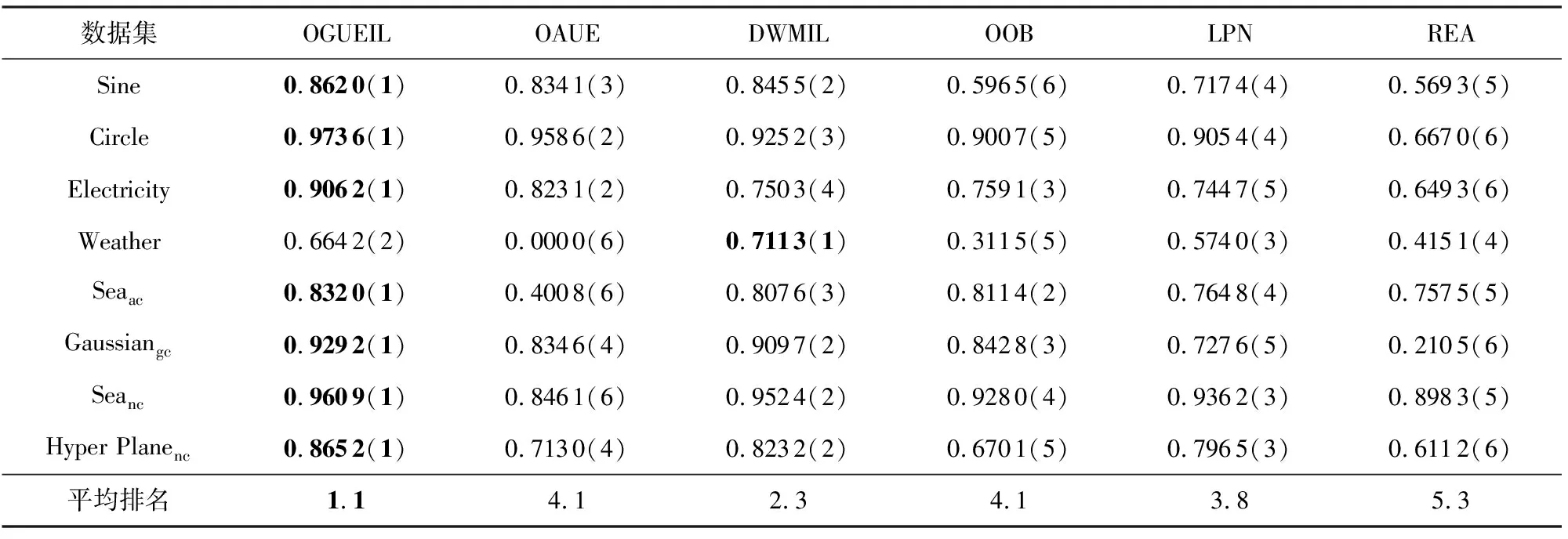

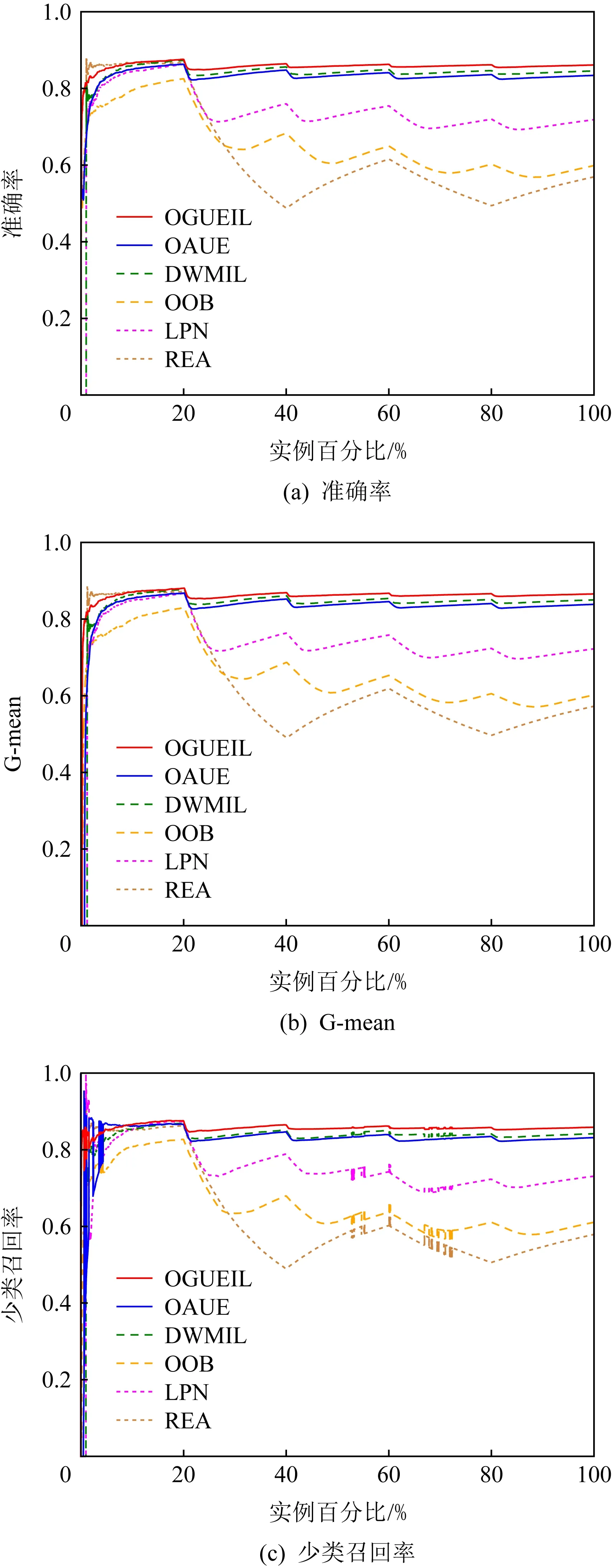

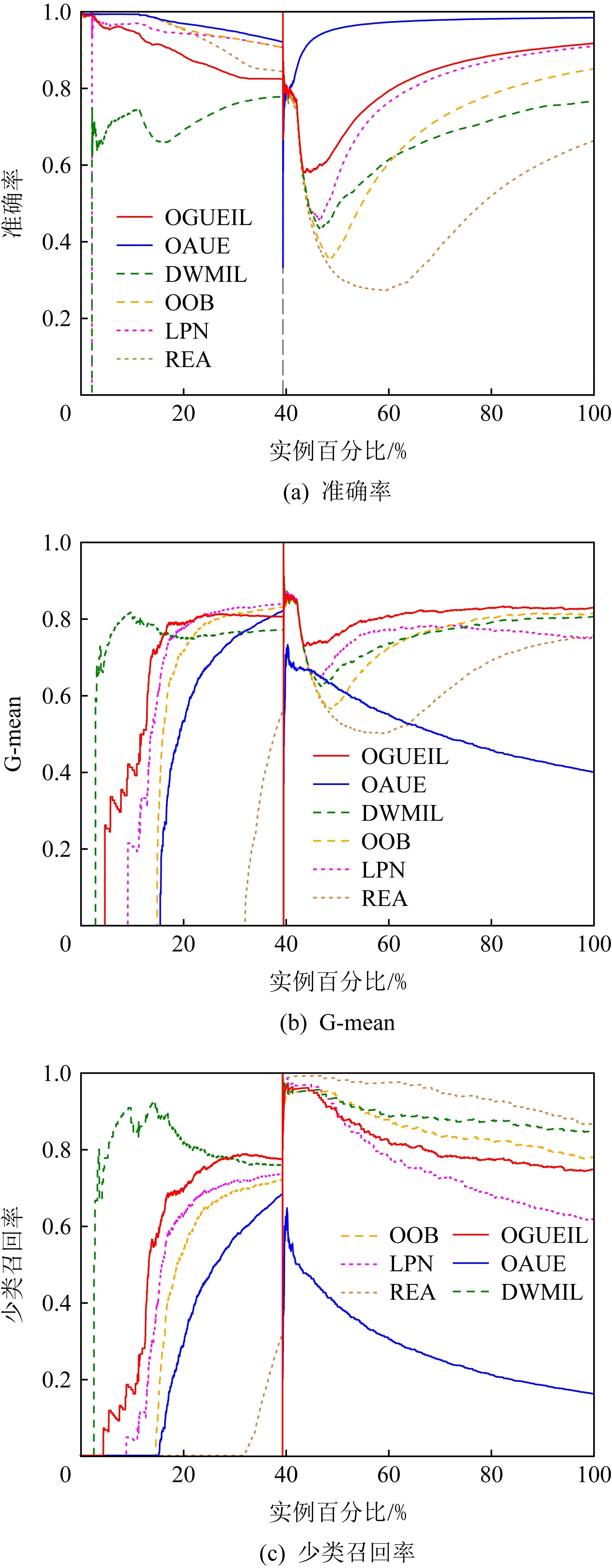
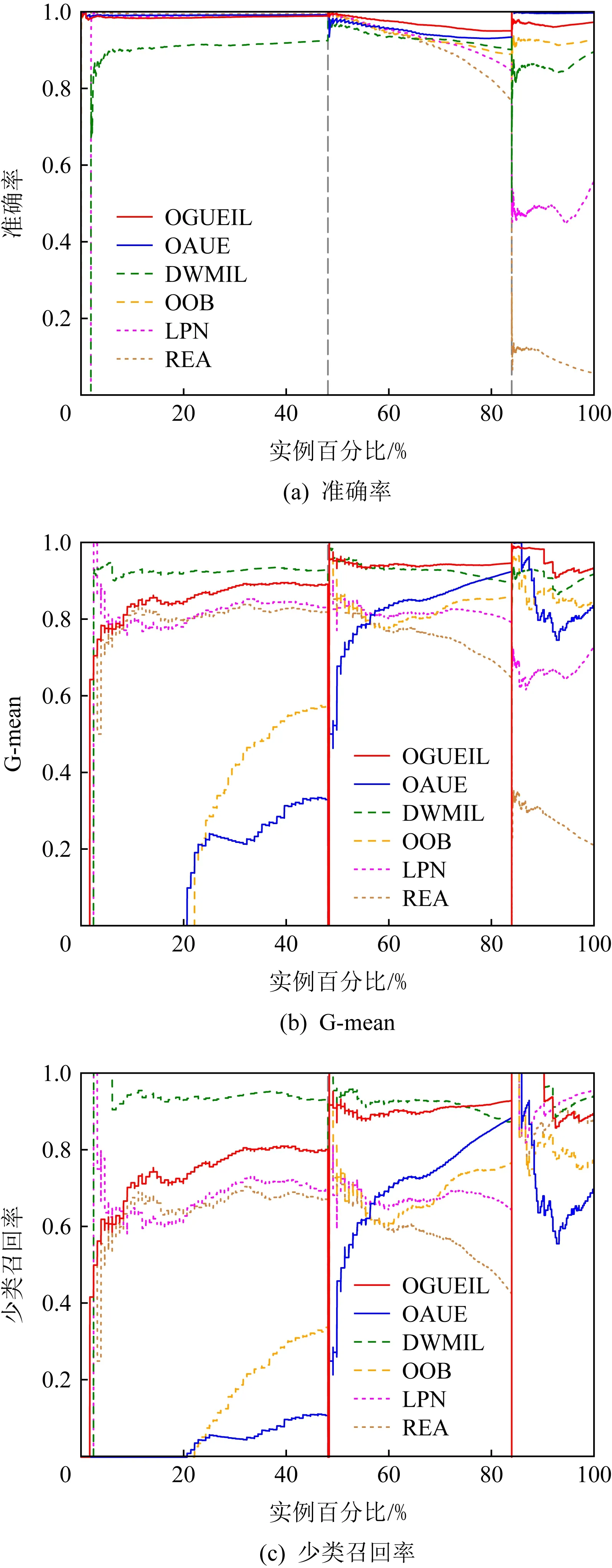
3.5 運行時間比較
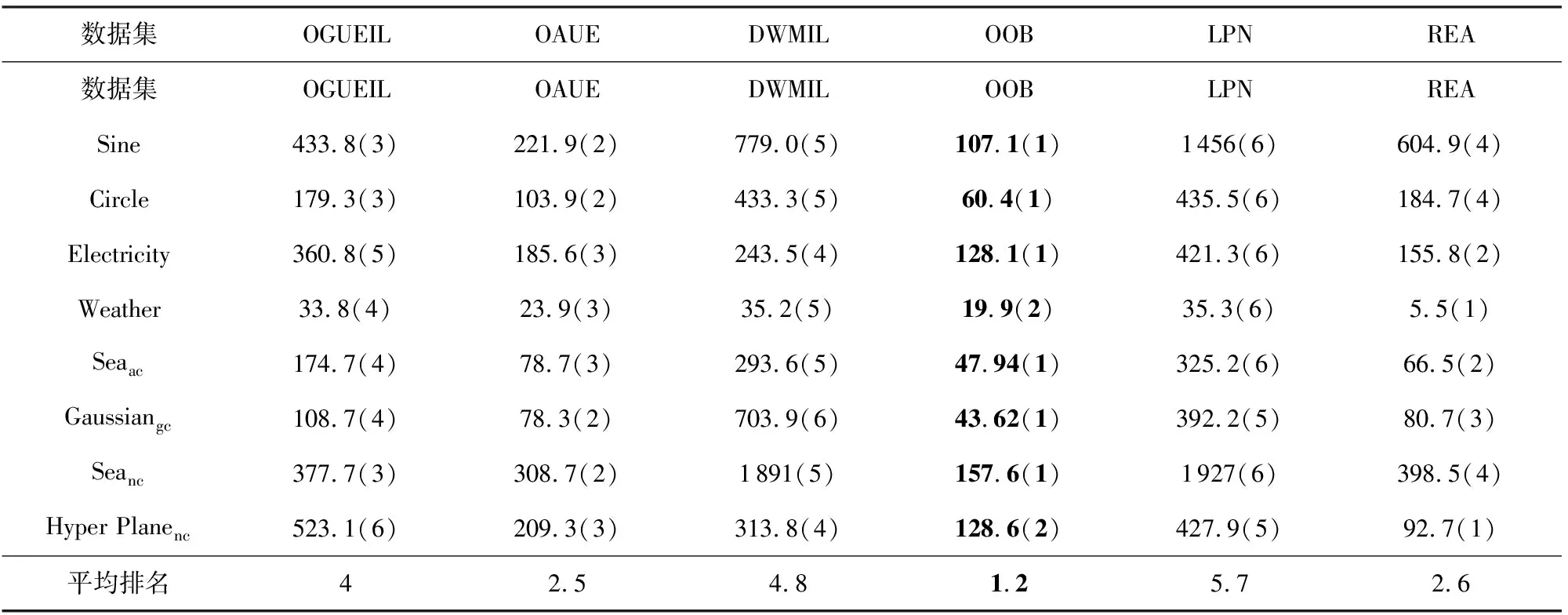
4 結束語
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
現代裝飾(2020年2期)2020-03-03 13:37:44
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
