融合實體外部知識的遠程監督關系抽取方法
2022-12-16 02:43:18高建偉萬懷宇林友芳
計算機研究與發展 2022年12期
高建偉 萬懷宇 林友芳
(北京交通大學計算機與信息技術學院 北京 100044)(gaojianwei@bjtu.edu.cn)
作為自然語言處理領域中一個重要的基礎研究課題,關系抽取旨在從無結構化的文本當中預測出給定實體對之間的關系事實.例如,從表1的第1行句子中,我們可以抽取出實體對Apple和Steve Jobs之間的關系是創始人.

Table 1 An Example of Sentences in a Bag Labeled by Distant Supervision
通常,大多數傳統的關系抽取模型[1-3]都采用有監督學習的方法來進行訓練,然而這一過程往往需要大量的高質量標注樣本來進行支撐,非常的耗費人力.Mintz等人[4]提出使用遠程監督的方法來緩解缺乏訓練數據的問題,該方法可以通過將知識圖譜(knowledge graph, KG)中的實體對與文本中相應的實體對進行對齊來自動生成帶標簽的訓練樣本.關系抽取中的遠程監督是基于這樣的假設來定義的:若在給定KG中的2個實體之間存在關系事實,那么我們認為所有包含該相同實體對的句子都表達了對應的關系.因此,遠程監督方法所具有的這種強有力的假設不可避免地會伴隨著錯誤標記的問題,從而導致了噪聲數據的產生.
因此,Riedel等人[5]提出了一個使用多示例學習(multi-instance learning, MIL)框架的方法來緩解噪聲數據的問題,這一方法提出了一種叫作“expressed-at-least-once”的假設來緩解先前約束較強的假設條件.該方法假設,在所有包含相同實體對的句子當中,至少有1個確實表達了它們的關系.在多示例學習框架當中,關系抽取的目標從句子級別變成了為包級別,其中每個包是由一組包含相同實體對的句子所組成的集合.此后,有許多研究者都受到該工作的啟發,基于MIL框架開展了一系列的研究工作來提高模型選擇有效句子的能力[6-9].其中,Lin等人[9]提出的選擇性注意力框架使用注意力機制來為句子分配權重,從而能夠充分地利用所有句子中所包含的信息.近些年來,基于選擇性注意力框架,提出了一系列新的關系抽取模型[10-13],它們大多使用卷積神經網絡(convolutional neural network, CNN)來作為句子編碼器,證明了這一結構的穩定性和有效性.
然而,盡管上述框架結構被廣泛使用在遠程監督關系抽取領域,但是傳統特征抽取器卻忽略了廣泛存在于實體之間的知識信息,這導致所捕獲的特征有可能會誤導選擇有效句子的過程.例如,表1中句子“Steve Jobs was the co-founder and CEO of Apple.”和“Steve Jobs argued with Wozniak,the co-founder of Apple.”在句式結構上非常相似.因此先前的模型會從這2個句子當中捕獲到相似的特征(即認為它們都表達了Steve Jobs和Apple是創始人的關系).在這樣的情況下,如果缺乏實體知識信息,模型就無法很好地辨別出正確的信息來生成有效的包級別的特征表示.
為了解決上述提到的問題,本文通過探索額外的實體知識提出了一種實體知識增強的神經網絡結構(entity knowledge enhanced neural network, EKNN).EKNN模型通過動態地將實體知識與詞嵌入融合在一起,從而能夠使模型將更多的注意力集中在與句子中給定實體對有關的信息上,提高了模型在句子級別的表達能力.本文的主要貢獻有3個方面:
1) 提出了一種知識感知的詞嵌入方法,將實體中的2種知識,即來自語料庫的語義知識和來自外部KG的結構知識動態地注入到詞嵌入中.
2) 在廣泛使用的“紐約時報”(New York Times, NYT)數據集[5]上評估了EKNN模型.實驗結果表明,本文提出的模型在2個版本的NYT數據集上的表現明顯優于其他最新模型.此外,通過額外的對比實驗確認了2個版本的數據集之間存在的差異.
3) 通過進一步的消融實驗,分別探究了2種不同的知識在關系抽取任務當中的有效性.
1 相關工作
大多數有監督的關系抽取模型[1-3]都會遇到標注數據不足的問題,而手動標記大規模的訓練數據既費時又費力.因此,有研究者提出了使用遠程監督的方法來自動完成標記訓練數據的工作[4].盡管遠程監督在一定程度上緩解了人工標注數據的困難,但仍然會伴隨著噪聲數據的問題.Riedel等人[5]和Hoffmann等人[6]都提出利用多示例學習的方法來緩解噪聲數據的問題,該方法不再使用單個句子作為樣本,而是將包含相同實體對的句子所組成的集合看作一個整體來作為樣本.
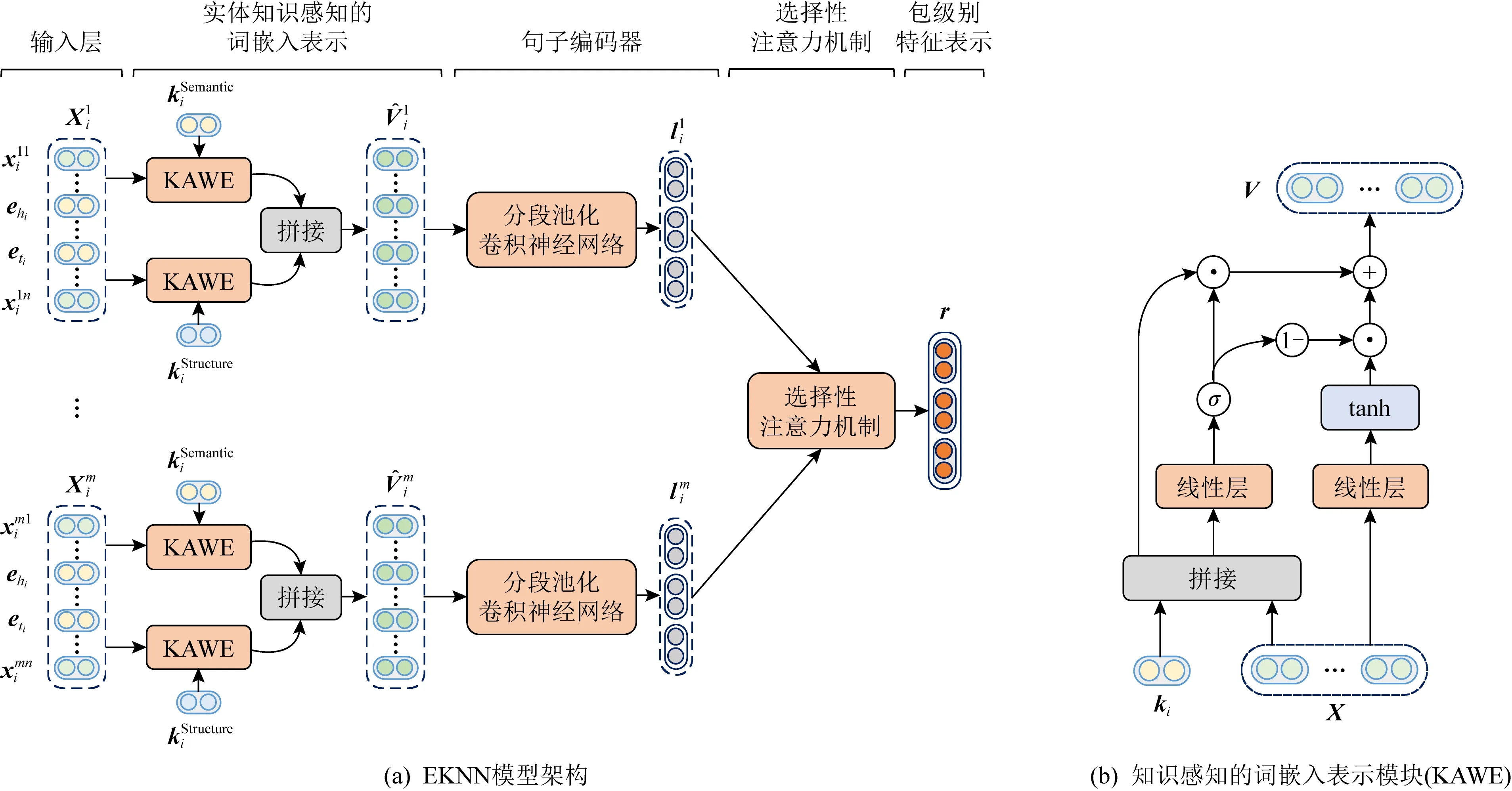
Fig. 1 The framework of our proposed neural architecture EKNN圖1 本文提出的EKNN模型架構圖
傳統的關系抽取方法主要是基于人工設計的特征進行的.近年來,隨著深度學習的發展,神經網絡模型已經被證明可以有效地捕獲句子中的語義特征,并且還避免了由人工特征所引起的誤差傳遞[14-16].Zeng等人[8]提出了分段池化卷積神經網絡(piecewise convolutional neural network, PCNN)從句子中更充分地提取實體之間的文本特征,并選擇可能性最大的句子來作為包級別的表示.Lin等人[9]提出了一個選擇性注意力框架,該框架通過對集合內的所有句子進行加權求和來生成包級別的特征表示,這一框架也被之后的許多研究工作所廣泛地采用[11-13].Shang等人[17]則提出了一種基于深度聚類方法的關系抽取模型,通過無監督的深度聚類方法來為噪聲句子重新生成可靠的標簽,進而緩解噪聲問題.此外,也有許多的工作嘗試利用實體相關的外部信息來改善模型性能.Han等人[18]提出了一種用于降噪的聯合學習框架,該框架能夠在知識圖譜和文本之間的相互指導下進行學習.Hu等人[19]利用知識圖譜的結構信息和實體的描述文本來選擇有效的句子進行關系提取.然而,這些方法大多數都僅僅考慮將知識信息用于降噪,并沒有充分地利用實體知識中所蘊含的豐富的信息.
因此,在本文中同時引入了結構知識和語義知識來生成知識感知的詞嵌入向量.通過這樣的方法,知識信息可以更加深入地融合到模型中.
2 實體知識感知的神經網絡模型
在本節中將介紹本文用于遠程監督關系抽取的EKNN模型的整體框架和細節描述.
2.1 符號定義

2.2 模型框架
給定一個實體對(hi,ti)及其實體對包Si,關系抽取的目的是預測實體對之間的關系ri.模型的總體框架如圖1(a)所示,主要有3個部分:
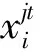

3) 選擇性注意力機制.給定實體對包Si中所有句子的語義上下文嵌入表示,包級別的特征表示通過注意力機制計算得到,最終用于預測關系類型.
2.3 知識感知的詞嵌入模塊
關系抽取的目標是預測2個實體之間的關系.因此,實體對中所包含的信息是非常重要的.在當前的研究當中,實體對中仍然還有很多隱含的信息尚未得到充分的利用.受這一想法的啟發,本文引入了語義信息和結構信息作為實體對的外部知識,以此來豐富傳統的詞嵌入表示.
2.3.1 語義知識嵌入
詞嵌入技術由Hinton等人[20]首次提出,其目的是為了將詞語轉換為向量空間當中的分布式向量表示,以捕獲詞語間的句法和語義特征.因此,本文采用詞嵌入作為語義信息的來源.給定一個實體對(hi,ti)及其詞嵌入(ehi,eti),將實體對的語義知識嵌入定義為
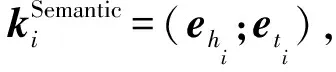
(1)
其中,ehi,eti∈2dw.
2.3.2 結構知識嵌入
典型的知識圖譜通常是一個具有多種關系類型的有向圖,可以將其表示為一系列關系三元組(h,r,t)的集合[12].因此,知識圖譜通常會包含有豐富的結構信息,可以將其看作本文結構知識的來源.本文使用TransE[21]作為知識圖譜嵌入模型,以此來得到實體和關系的預訓練嵌入向量.給定一個三元組(h,r,t)及其嵌入表示(h,r,t),TransE將關系r看作是從頭實體h到尾實體t的一種翻譯操作,如果(h,r,t)存在,則可以假設嵌入向量t應該接近于h+r.因此,將實體對的結構知識嵌入定義為

(2)
其中,hi,ti∈ds.
2.3.3 門控融合
為了能夠動態地將實體對的知識與原始的詞嵌入融合在一起,本文使用門控機制來生成知識感知的詞嵌入表示.
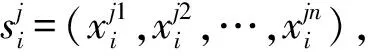
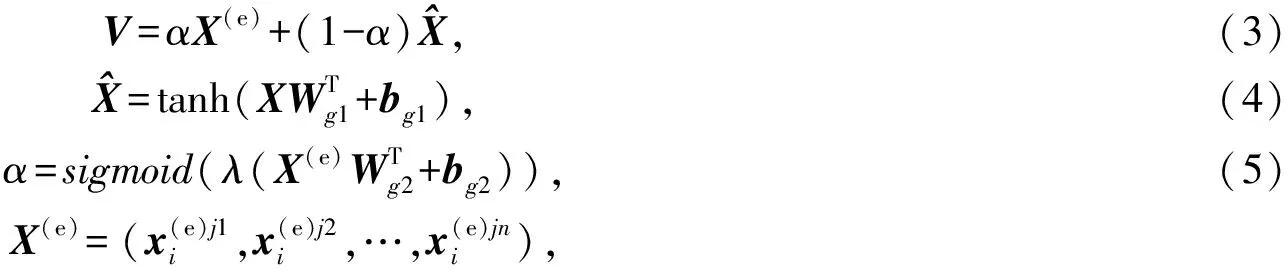
(6)
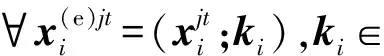


(7)

2.4 句子語義特征編碼
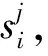
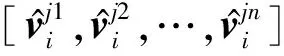
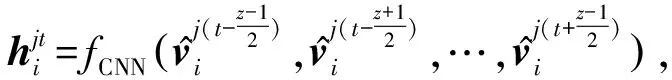
(8)

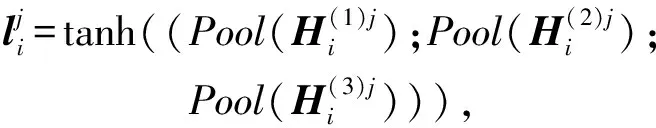
(9)

2.5 選擇性注意力機制
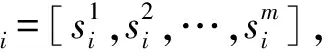
(10)
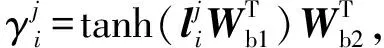
(11)
其中,Wb1∈db×3dc,Wb2∈1×db是可學習參數,db是超參數.之后,可以通過上述注意力分數來得到包級別的特征表示用于關系分類,其定義為
(12)
最終,特征r在經過線性變換后被送入到Softmax分類器當中.其計算公式定義為

(13)
其中,Mr是變換矩陣,br是偏置項.同時,與Lin等人[9]相同,本文在包級別的特征表示r上使用了dropout[22]來防止過擬合.
2.6 模型學習
在訓練階段,本文嘗試最小化交叉熵損失函數:
(14)
其中,θ表示模型中的所有參數,B=[S1,S2,…,S|B|]表示實體對包的集合,而[r1,r2,…,r|B|]則表示對應的關系標簽.本文中所有模型均使用隨機梯度下降(stochastic gradient descent, SGD)作為優化算法.
3 實驗及結果分析
3.1 數據集
在Riedel等人[5]公開的“紐約時報”NYT數據集上對本文的模型進行了評估,該數據集是通過將Freebase中的關系與NYT語料庫進行自動地對齊而生成的,它在目前許多最新的遠程監督關系抽取研究工作當中被廣泛使用.該數據集共包含53類關系和一個無關系NA標簽,無關系標簽表示2個實體之間沒有任何關系.值得一提的是,在當前的許多研究工作當中存在2個不同版本的NYT數據集,這是由于一次錯誤的數據集發布所造成的(1)https://github.com/thunlp/NRE/commit/77025e5cc6b42bc1adf3ec46835101d162013659.這2個版本數據集之間的主要區別在于訓練集部分不同,它們的測試集是相同的.具體而言,表2中列出了這2個數據集的一些數據統計情況.本文將這2個不同的訓練集分別稱為train-570K和train-520K.從表2中可以看出,train-570K和測試集在實體對而非句子上存在交集,而train-520K是比較干凈的訓練集,不存在交集.在交集部分,大多數實體對的標簽為NA,這使得模型更容易區分標簽為NA的樣本.因此可以推斷出,對于同一模型,使用train-570K數據集進行訓練的效果會高于train-520K數據集.
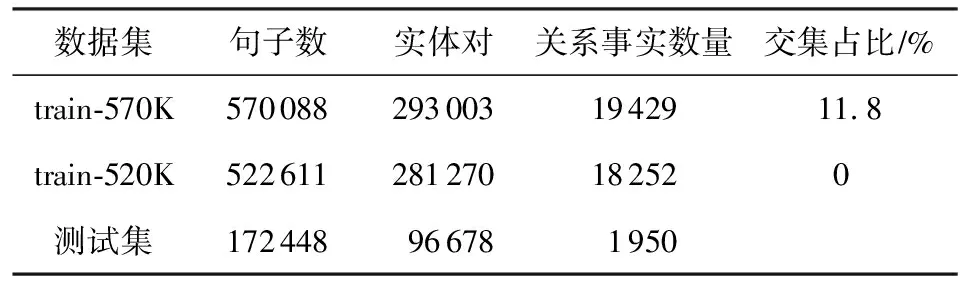
Table 2 Statistics of the NYT Dataset表2 NYT數據集統計情況
在評價指標方面,本文遵循了目前主流的研究工作[4,9,13],在NYT測試集上使用精確率-召回率(P-R)曲線以及該曲線下面積(AUC)和Top-N精確度(P@N)來作為評估指標.
3.2 實驗設置
3.2.1 知識圖譜嵌入
本文使用FB40K[23]來作為我們的外部知識圖譜,它包含大約40 000個實體和1 318種關系類型.為了生成預訓練的知識圖譜嵌入,使用OpenKE Toolkit[24]進行訓練,其中嵌入向量的大小ds=100,超參數margin=5,學習率設置為1,迭代輪數為500輪.值得注意的是,FB40K和測試集在實體對上沒有的任何交集.因此,在外部知識圖譜FB40K中不會包含任何出現在測試集中的實體對.
3.2.2 參數設置
在實驗中,通過網格法對超參數進行了選擇,其中批量大小B∈{50,120,160},CNN卷積核個數dc∈{64,128,230,256},隱藏層db∈{256,512,690},平滑參數λ∈{30,35,40,45,50},其余參數則與前人工作[9,12-13]保持一致.同時采用了Lin等人[9]發布的50維的詞向量用于初始化設置.表3列出了在2個版本的訓練集上進行實驗使用的所有超參數情況.此外,對于優化算法,在train-570K和train-520K上分別使用學習率為0.1和0.2的mini-batch SGD算法進行訓練.
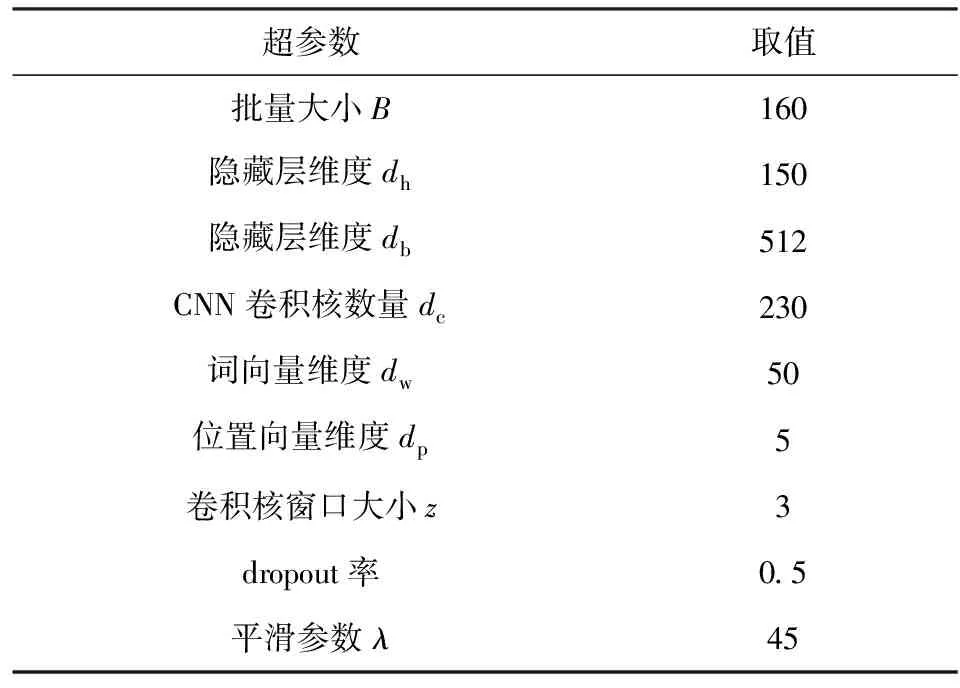
Table 3 Hyper-parameter Settings in Our Experiments表3 本實驗中的超參數設置
3.2.3 基準模型
為了對本文所提出的EKNN模型進行評估,將其與當前最新的基準模型進行了比較:PCNN+ATT[9]是最基礎的選擇性注意力模型;+HATT[12]采用層次注意力機制,在長尾關系抽取上的效果有很大的提升;+BAG-ATT[13]分別使用包內和包之間的注意力機制來緩解句子級別和包級別的噪聲;JointD+KATT[18]設計了一個聯合學習框架,通過知識圖譜和文本之間的相互指導學習來進行降噪;RELE[19]通過知識圖譜的結構化信息來指導標簽嵌入(label embedding)的學習從而進行降噪,提高了關系抽取的性能.此外,本文還與傳統的基于特征的模型進行了對比,包括Mintz[4],MultiR[6],MIML[7]等.
3.3 對比實驗結果與分析
從表4中所列出的P@N值結果中可以看出,對于CNN+ATT和PCNN+ATT,使用train-520K進行訓練的P@N要明顯低于使用train-570K進行訓練的P@N.這一實驗結果與數據集上(表2)所觀察到的現象是一致的,即訓練集和測試集之間的實體對存在交集可以在一定程度上提高模型在關系抽取任務上的性能.而對于當前最先進的研究方法,也使用train-520K重新進行了訓練.與上述實驗結果相似,這些模型的結果在train-520K也出現了顯著的性能下降.而所提出的EKNN模型在2個訓練集上進行訓練的結果也有所不同.但是與其他基準方法相比,在train-570K和train-520K上分別進行訓練時,本文的方法在P@N指標上仍然要明顯地優于其他方法.具體而言,在P@N均值這一指標上,相比PCNN+ATT模型在2個訓練集上分別提升了11.6%和5.0%.此外,與最優的基準模型+BAG-ATT相比,本文所提出的模型在2個訓練集上也有著顯著的性能提升.上述結果證明了本文所提出的遠程監督關系抽取方法的有效性.
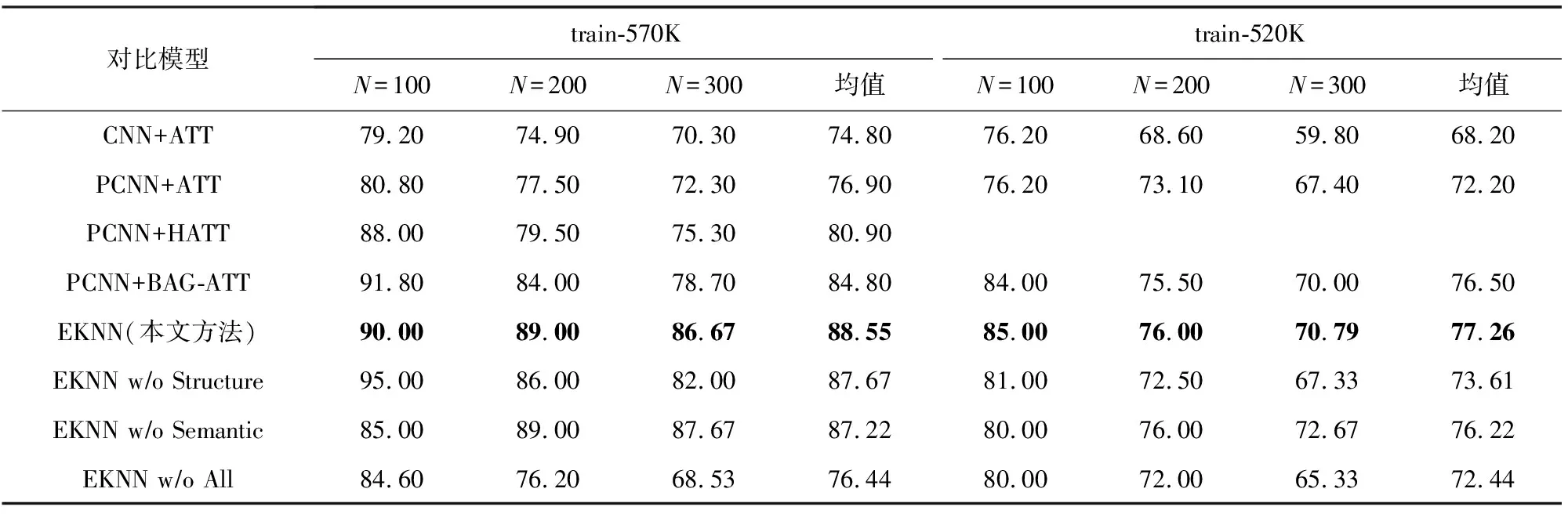
Table 4 P@N Values of Different Models on the Two Training Sets表4 各模型在2個訓練集上的P@N值 %
此外,圖2和表5也分別展示了精確率-召回率(P-R)曲線和AUC的結果.從圖2中的P-R曲線可以看出,隨著召回率的提升,各模型的精確率出現了急劇的下降,這是由于遠程監督數據集中的噪聲問題所導致的.而從表5中的AUC值還可以看出,對比train-570K上的結果,包括本文模型在內的所有模型在train-520K下進行訓練都有不同程度的性能下降,這與表4中的P@N指標的結果是一致的,也同樣驗證了在3.1節中所作的分析.但是,對比最優的基準模型+BAG-ATT,本文的方法在train-520K上仍然有顯著提升,這進一步證明了本文所提出模型的性能提升是穩定且有效的.具體而言,本文在2個數據集上,+BAG-ATT的AUC指標分別提高了0.12和0.05.

Fig. 2 Precision-recall curves of the proposed model and other baseline models圖2 本文模型與其他模型的精確率-召回率曲線
3.4 消融實驗結果與分析
為了進一步驗證本文所提出的方法中不同模塊的有效性,本文進行了充分的消融實驗,旨在探索什么樣的實體知識對于關系抽取任務更有價值.消融實驗的P@N指標結果在表4的6~8行列出,而精確率-召回率曲線和及其相應的AUC值在圖3和表5的部分區域進行展示.其中,w/o All表示去掉本文中設計的所有新模塊,相當于最基礎的選擇性注意力模型[9].在接下來的分析當中,可以將其作為基準和其它模型進行對比.

Fig. 3 Precision-recall curves for the ablation study圖3 消融實驗的精確率-召回率曲線
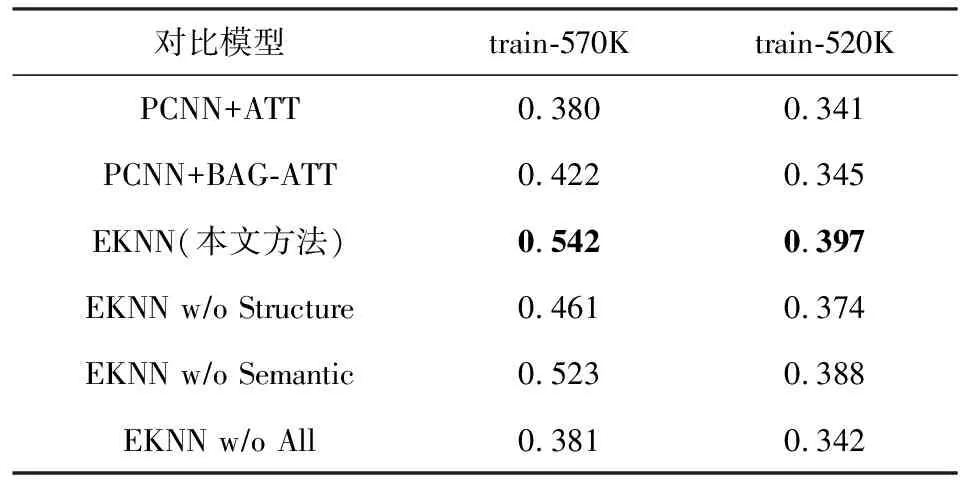
Table 5 AUC Values of Different Models on the Two Training Sets
在本文提出的EKNN模型中,引入了2類實體知識,分別為模型提供語義信息和結構化信息.為了驗證它們的有效性,設計了2個變種模型.具體而言,w/o Semantic和w/o Structure都表示丟棄其中一類知識而保留另一類.從結果當中可以發現,2類實體知識都可以豐富模型的表達能力,并顯著提高模型性能.以train-520K為例,假如去掉整個知識感知詞嵌入模塊(w/o All),P@N值和AUC指標分別下降了4.8%和0.055.此外,通過對比w/o Semantic和w/o Structure這2個變種模型,可以了解到在關系抽取任務當中結構化信息比語義信息具有更大的價值,這是由于模型從結構化數據中所學到的隱式嵌入具有更強的推理能力.
3.5 不同知識融合方式的對比實驗分析
為了驗證本文知識融合方法的有效性,本文與當前主流的融合知識的遠程監督關系抽取方法進行了對比,實驗結果如表6所示:
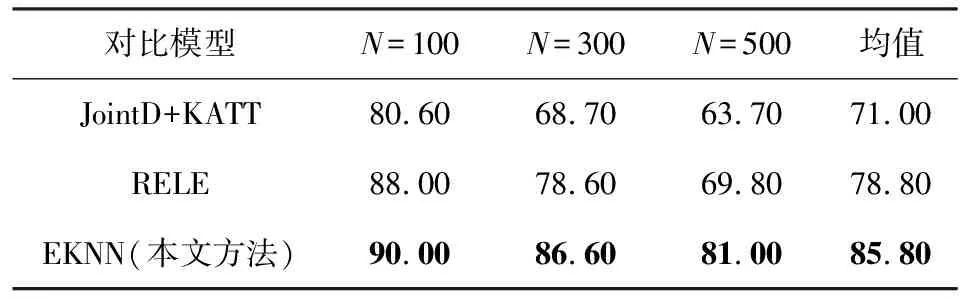
Table 6 P@N Values of Different Knowledge Integration Methods
從實驗結果中可以看出,所提出的實體知識感知的詞嵌入模塊擁有更加優越的性能提升.這是由于JointD+KATT和RELE僅僅考慮了將知識信息用于模型訓練和指導降噪的過程,而忽略了實體知識中所蘊含的豐富表示.EKNN模型通過知識信息和詞嵌入表示融合的方式,更加深層次地將知識整合進了模型,對實體知識進行了更充分地利用,因而獲得了更好的性能表現.
3.6 平滑參數λ對模型性能的影響
在實體知識感知的詞嵌入表示模塊當中,超參數λ用于對知識融合的過程進行平滑控制,圖4給出了不同的λ值對于模型性能的影響.從圖4中可以看出,當λ值在40~45之間時,模型中的實體知識和詞嵌入可以實現相對較好的融合效果,從而提升模型性能.
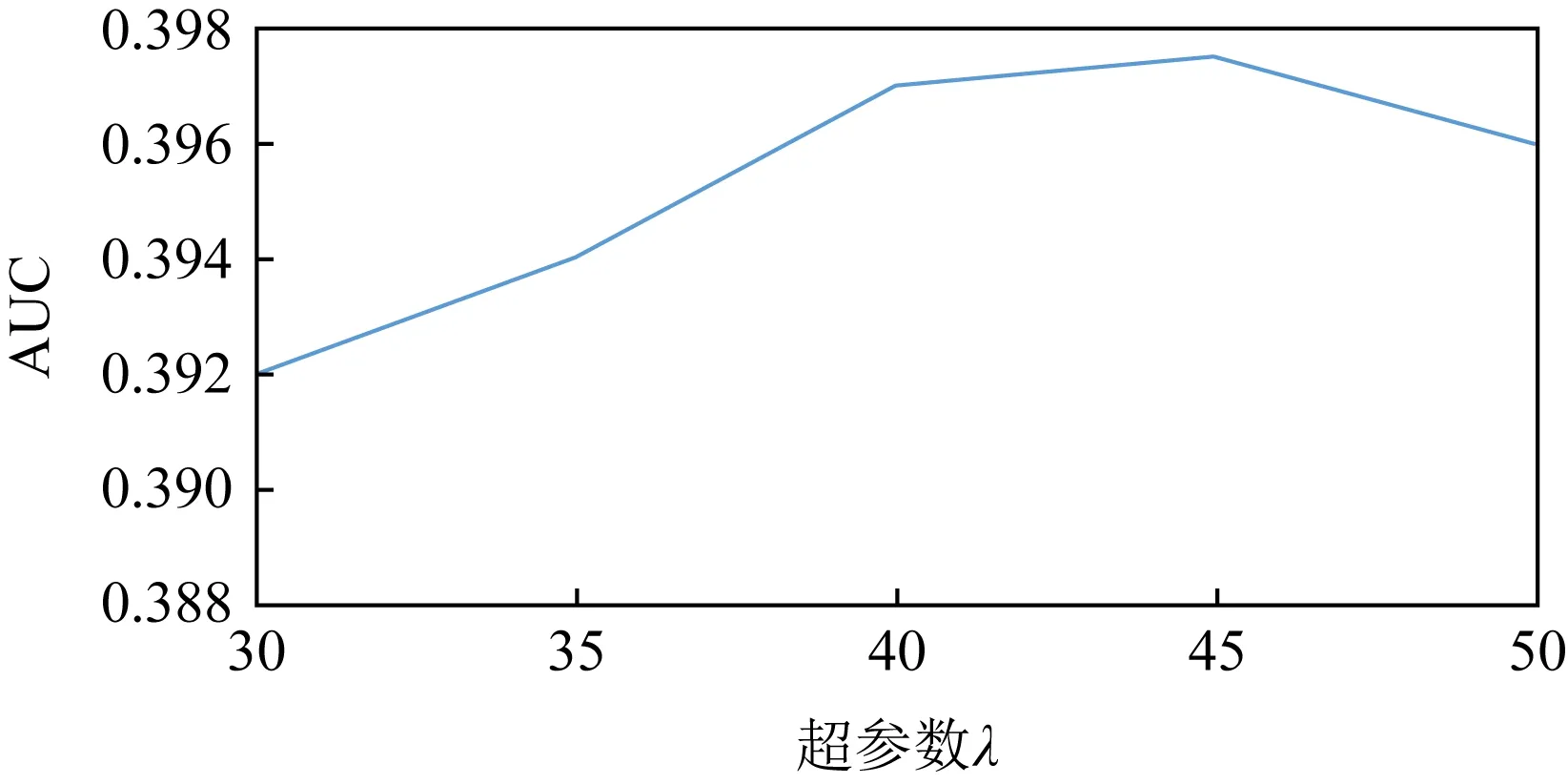
Fig. 4 The effect of hyperparameter λ on model performance圖4 超參數λ對模型性能的影響
4 總 結
本文提出了一種用于遠程監督關系抽取的神經網絡模型EKNN.為了提高模型的表達能力,引入了2類實體知識(即語義知識和結構知識)來動態地生成知識感知的詞嵌入.通過豐富的對比實驗,證明了本文的模型性能顯著優于當前最優的方法.此外,本文還通過對比實驗探究了“紐約時報”數據集上2個版本的訓練數據之間的差異,結果表明,由于排除了數據集間的實體對交集,train-520K數據集比train-570K數據能夠更有效的反映模型性能.
作者貢獻聲明:高建偉負責模型設計以及文章的撰寫;萬懷宇負責方法概念的提出文章的潤色和審閱校對;林友芳負責實驗數據的管理、文章的潤色和審閱校對.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
開放教育研究(2020年2期)2020-03-31 01:54:14
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
現代語文(2016年21期)2016-05-25 13:13:44
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
大連民族大學學報(2015年2期)2015-02-27 08:28:11
