基于多通道長短期記憶網絡的PM 2.5小時濃度預報
2022-12-20 06:22:22張鑫磊張冬峰郭媛媛任玉歡范志宣
環境科學研究 2022年12期
關鍵詞:模型
張鑫磊,張冬峰*,劉 偉,楊 倩,郭媛媛,任玉歡,范志宣
1.山西省氣候中心,山西太原 030006
2.吉林省氣象科學研究所,吉林長春 130062
PM2.5指空氣動力學直徑小于等于2.5μm的細顆粒物,是近年來主要的大氣污染物之一.研究[1-3]表明,在高濃度PM2.5環境下暴露數小時后,將增加患心血管疾病和呼吸道疾病的風險.因此,對未來多小時的PM2.5濃度進行逐小時滾動預報,可以提醒相關疾病易感人群及時調整出行計劃、提早預防短期高濃度PM2.5引發的健康問題,并進一步推動政府制定緊急預案,完善大氣污染治理制度[4].
目前關于PM2.5濃度預報的方法主要可分為兩大類.第一類是基于氣象學與數學理論的數值模擬方法,通過對污染物傳輸、擴散、轉化以及沉降等過程進行模擬,對污染物濃度進行預報[5].比較有代表性的幾個污染物模式為美國環境保護局研發的第三代空氣質量預報與評估系統中的CMAQ(Community Multiscale Air Quality)模式[6-7]、美國國家氣候中心預報系統實驗室開發的氣象-化學耦合模式WRF-Chem[8]以及由中國科學院大氣物理研究所研發的嵌套網格空氣質量預報模式系統NAQPMS[9]等.第二類是基于對歷史資料進行分析的統計方法與機器學習(深度學習)方法,通過對歷史數據的學習與分析,挖掘數據內在特征,基于當前的狀態對未來給出較合理的預報.相較數值模擬方法來說,第二類方法更為簡單、高效,且適用性廣[10].其中,有基于統計方法的多元線性回歸[11]、非線性回歸[12]等模型,基于機器學習方法的極端梯度提升(Extreme Gradient Boosting, XGBoost)[13]、隨機森林(Random Forest, RF)[14]與極限學習機(Extreme Learning Machine,ELM)[15]等模型,基于深度學習方法的卷積神經網絡(Convolutional Neural Networks,CNN)[16-17]與循環神經網絡(Recurrent Neural Network,RNN)[18-20]等模型.
隨著計算機芯片的發展,圖形處理器(Graphics Processing Unit,GPU)被應用到深度學習模型訓練中.作為機器學習方法中的一個新領域,深度學習不僅在序列預測與特征提取等方面優于傳統的機器學習方法,而且在數據預處理上也節省了較多的時間.在模型輸入要素的選取上,以空氣質量監測站各類污染物濃度為基礎,多位學者先后融合了監測站周圍的氣象條件、時間信息以及地理信息,有效提升了模型的預報精度[21-24].在觀測窗與預報時效的選擇上,多數研究利用8~72 h歷史資料來預報未來1~24 h的逐小時PM2.5濃度[24-27].但這些研究中觀測窗的寬度多為人為選取的固定值,可能無法獲取最優的預報結果.選取合理的觀測窗寬度,一方面可提升模型預報的準確性,另一方面也可以減少觀測窗過寬導致的運算成本[25-26]. 在預報模型構建上,有學者提出了CNN-RNN[24]、長短期記憶網絡(Long Short-Term Memory,LSTM)[25]以及CNN-LSTM[26]等深度學習預報模型,這些模型通過提取站點所有要素的歷史時間序列信息,對站點未來逐小時PM2.5濃度進行預報.在此基礎上,也有學者利用三維卷積神經網絡(3D-CNN)[21]、卷積長短期記憶網絡(Convolutional LSTM,ConvLSTM)[23]和圖卷積神經網絡(Graph Convolutional Network, GCN)[27]等模型進一步提取了輸入要素的空間特征,獲得了較高的預報精度,但同時也增加了數據預處理的難度以及模型的復雜度.
綜上,已有研究多為單個模型提取所有要素的時間序列及空間信息,然而不同要素的有效信息可能存在差異,對所有要素使用同一個神經網絡進行處理,或許無法獲取較高的預報精度;同時,以往研究中僅選取固定寬度的觀測窗也會對預報精度產生一定影響.因此,為進一步提升預報精度,該研究以太原市為研究區域,提出了一種多通道長短期記憶網絡(Multi-Channels Long Short Term Memory,MULTI-LSTM)模型,使用獨立的LSTM模型分別提取不同要素的歷史時間序列信息,利用不同氣象站點融合得到的氣象數據作為輔助輸入要素,對不同觀測窗與預報時效組合下模型的預報精度進行評價,以期為PM2.5預報研究中輸入要素、觀測窗選取和模型構建等問題提供新的研究思路.
1 材料與方法
1.1 研究區域概況與數據預處理
太原市位于山西省中部,位于37.45°N~38.42°N、111.5°E~113.15°E之間.總面積6 988 km2,截至2021年底常住人口為539萬.該文選取了太原市2019?2020年的空氣污染物與氣象要素小時資料.空氣污染物觀測數據源于中國環境監測總站的全國城市空氣質量實時發布平臺(https://air.cnemc.cn:18007),污染物包括PM2.5、PM10、NO2、CO、O3和SO2共6種.氣象要素觀測資料來自于太原市國家氣象觀測站與區域氣象觀測站(分別簡稱“國家站”與“區域站”).
該文選取的氣象資料包括距離每個空氣質量監測站最近的國家站的小時相對濕度、露點溫度、2 min平均風向/風速、10 min平均風向/風速、地面溫度、1 min/10 min能見度,以及每個空氣質量監測站5 km范圍內所有區域站的小時氣溫與降水要素的平均值.對個別缺失數據進行插補,將空氣質量數據與氣象數據按站點與時間合并,并將站點當前季節、月份以及小時等時間要素作為擴展屬性添加到資料中.最終共獲得20個要素,140 056條有效觀測數據.空氣污染物和氣象資料的數值類要素統計結果如表1所示.
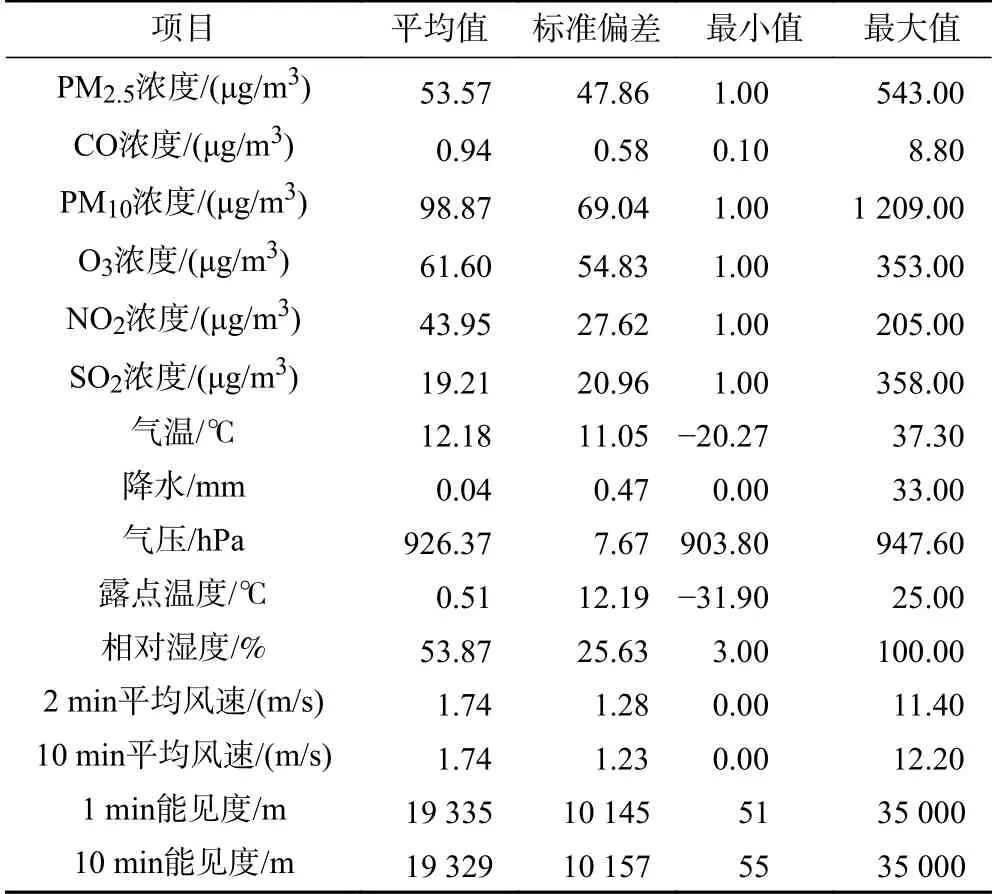
表1 空氣污染物和氣象資料的數值類要素統計結果Table 1 Statistical analysisof numerical elements of air pollutants and meteorological data
對空氣污染物和氣象數據的數值類要素進行歸一化處理,對風向、季節等非數值類要素進行獨熱編碼處理.從每個站點數據中選取80%樣本組成訓練集,剩下的20%組成測試集.另外,在訓練集中抽取5%的樣本作為模型訓練時的驗證集,用于超參數的調整,以期獲得預報精度較高的模型.
1.2 預報模型構建
由圖1可見,該文基于LSTM神經網絡進行深度學習模型構建,LSTM通過遺忘門Ft、輸入門It與輸出門Ot在單元之間傳遞信息,從而控制上一時刻信息與當前時刻信息的記憶與遺忘的程度.作為RNN的一種,LSTM可以彌補傳統RNN在長期記憶上導致的梯度爆炸或梯度消失的缺陷.遺忘門Ft與輸入門It控制著細胞狀態Ct,通過對上一時刻隱藏層狀態Ht?1以及當前時刻輸入信息Xt的輸入與遺忘,對細胞狀態Ct進行更新.輸出門Ot則控制隱藏層狀態Ht,通過輸出門Ot以及細胞狀態Ct來更新當前時刻的隱藏層狀態Ht,LSTM神經網絡通過歷史序列信息的輸入,不斷更新細胞的隱藏層狀態Ht,以達到提取特征序列(時間)信息的目的[28].
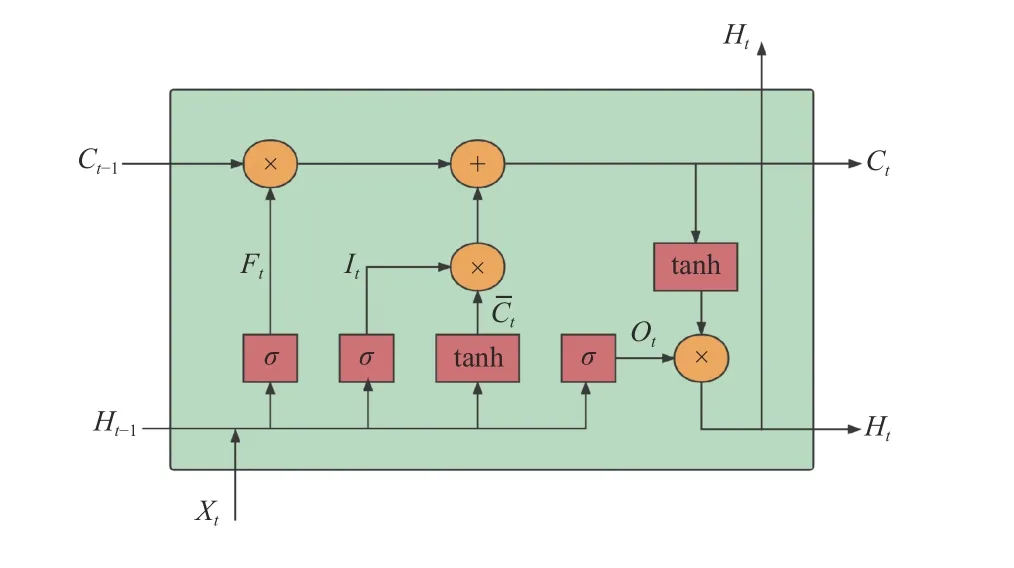
圖1 LSTM細胞結構Fig.1 Cell structure of LSTM
圖1中LSTM輸入輸出過程如式(1)~(8)所示.
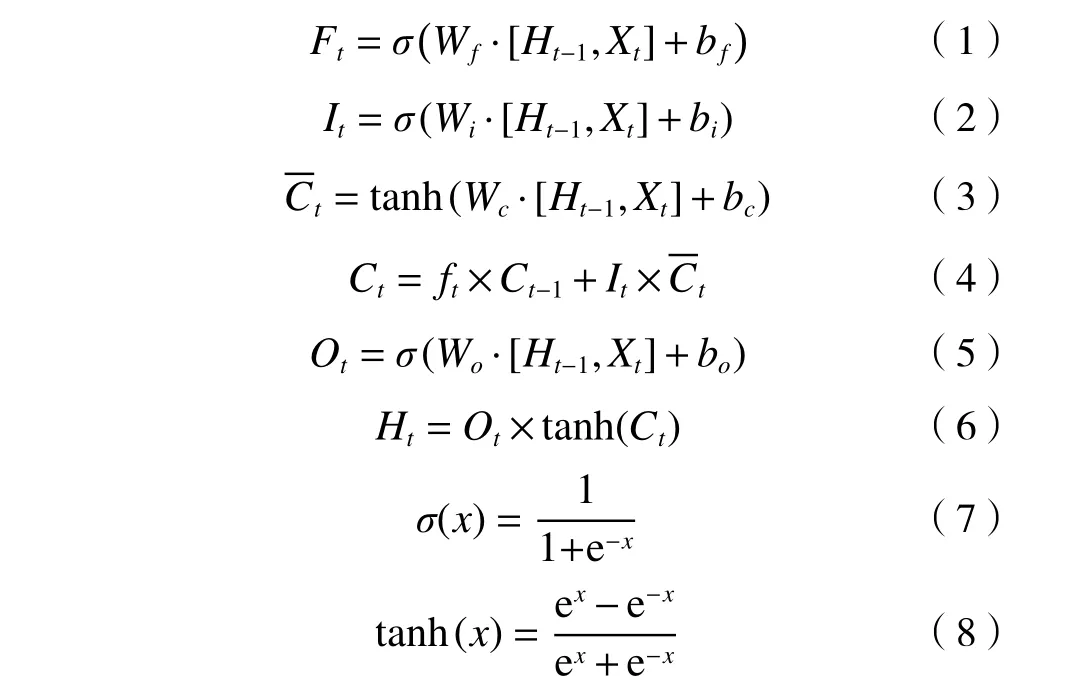
式中:σ與tanh分別表示sigmoid函數與雙曲正切函數;Wf、Wi、Wc、Wo、bf、bi、bc、bo均為模型參數,通過迭代訓練不斷更新.
構建MULTI-LSTM模型有以下幾步:首先,利用LSTM較強的時序處理能力,分別對每個要素的歷史時間序列樣本(過去逐n小時歷史資料)進行處理;然后,將各要素的處理結果通過Merge層進行融合;最終,通過3層全連接神經網絡輸出未來逐m小時的PM2.5濃度.MULTI-LSTM模型結構見圖2.為防止過擬合,使用Dropout層隨機移除一定比例的神經元以降低神經元之間的復雜性[29],優化函數采用Adamax[30].
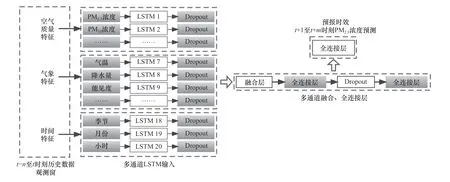
圖2 MULTI-LSTM模型結構Fig.2 The structure of MULTI-LSTM model
為了對比模型預報精度,分別構建單通道LSTM模型(BASE-LSTM)和LSTM擴展模型(LSTM extended,LSTME)[25].利用各模型對多組觀測窗-預報時效的數據集進行學習,核心參數如表2所示.
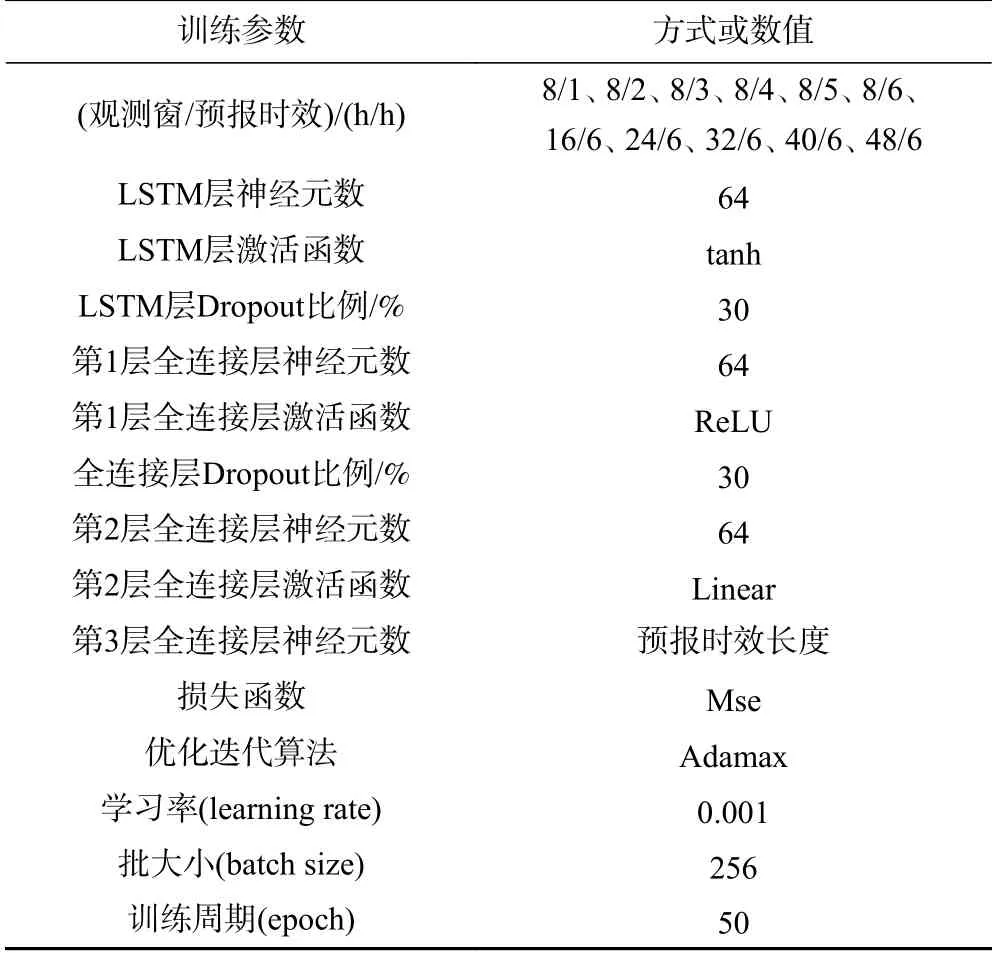
表2 訓練參數Table2 The training parameters
該試驗基于Python 3.8.5軟件,利用谷歌深度學習開源框架Tensorflow-gpu 2.4.1以及GPU并行計算構架cuda 11.0,構建并訓練上述模型.CPU為Xeon Gold 5222@3.80 GHz四核,使用1塊Nvidia Quadro P2000(5 GB)的顯卡進行GPU運算.
1.3 評價指標
為了更好地評估模型的準確性,在測試集上對模型的預報值與觀測值進行對比,從而評價預報效果.該研究采用均方根誤差(RMSE)、平均絕對百分誤差(MAPE)以及擬合指數(IA)作為評價指標.通過RMSE可以反映預報結果整體的精確度,評估整體的絕對誤差.MAPE用于相對誤差的測量,評估不同等級污染過程誤差的百分比.IA則用于比較預報值與觀測值的分布相似度,IA越接近1,說明二者越一致[24].
2 結果與分析
2.1 預報精度對比
以8 h觀測窗與6 h預報時效的MULTI-LSTM模型為例,模型訓練過程的損失函數如圖3所示.BASE-LSTM模型、LSTME模型和MULTI-LSTM模型在8 h觀測窗與不同預報時效組合下的RMSE如圖4所示.由圖4可見,MULTI-LSTM模型在不同預報時效下均表現最佳,在對觀測窗為8 h、預報時效為1 h(以下簡寫為“觀測窗/預報時效”的形式,此處為“8/1”)的預報中,RMSE為10.67μg/m3,IA在0.98以上,與BASE-LSTM模型表現相近,優于LSTME模型.但隨著預報時效延長,BASE-LSTM模型的預報精度明顯下降,MULTI-LSTM模型逐漸優于其他兩個模型.與BASE-LSTM模型和LSTME模型相比,在“8/6”組合下MULTI-LSTM模型的RMSE分別降低了7%和6%.
圖3 MULTI-LSTM模型訓練過程損失函數圖Fig.3 Loss function of the training process of MULTI-LSTM
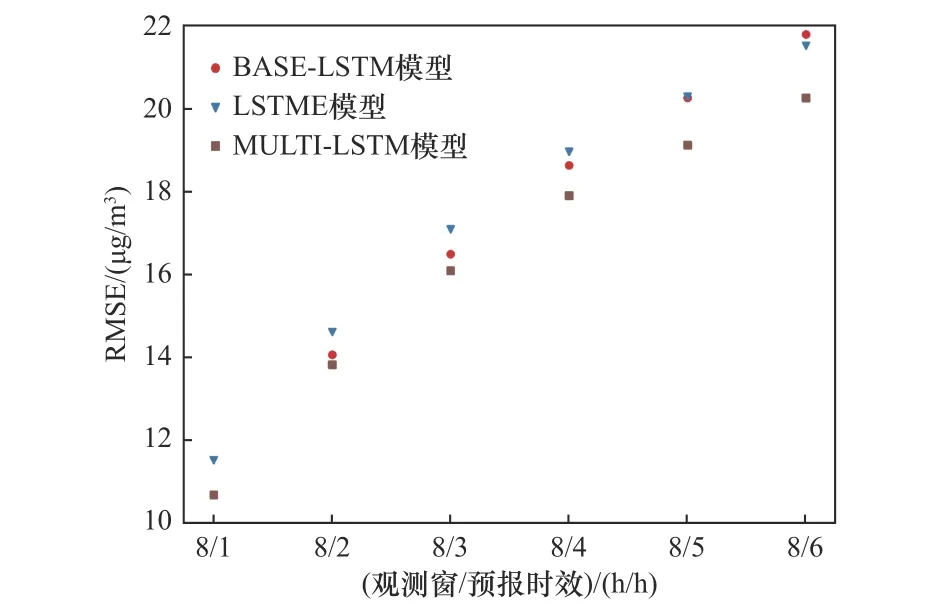
圖4 8 h觀測窗下不同預報時效的RMSEFig.4 The RMSE of different period validities in 8 hoursobservation windows
在6 h預報時效與不同觀測窗寬度的組合下,MULTI-LSTM模型的預報精度最高(見圖5).MULTILSTM模型在8~32 h的觀測窗內RMSE基本沒有變化,在40~48 h觀測窗內略有減小,相比較于8 h觀測窗,觀測窗寬度為40和48 h的RMSE分別降低了2%與3%.BASE-LSTM模型與LSTME模型的預報精度基本一致,在觀測窗寬度小于等于40 h范圍內,隨著觀測窗的變寬,LSTME模型的RMSE基本沒有變化,而BASE-LSTM模型的RMSE略微減小.當觀測窗寬度為48 h,BASE-LSTM模型與LSTME模型的RMSE均略有減小.
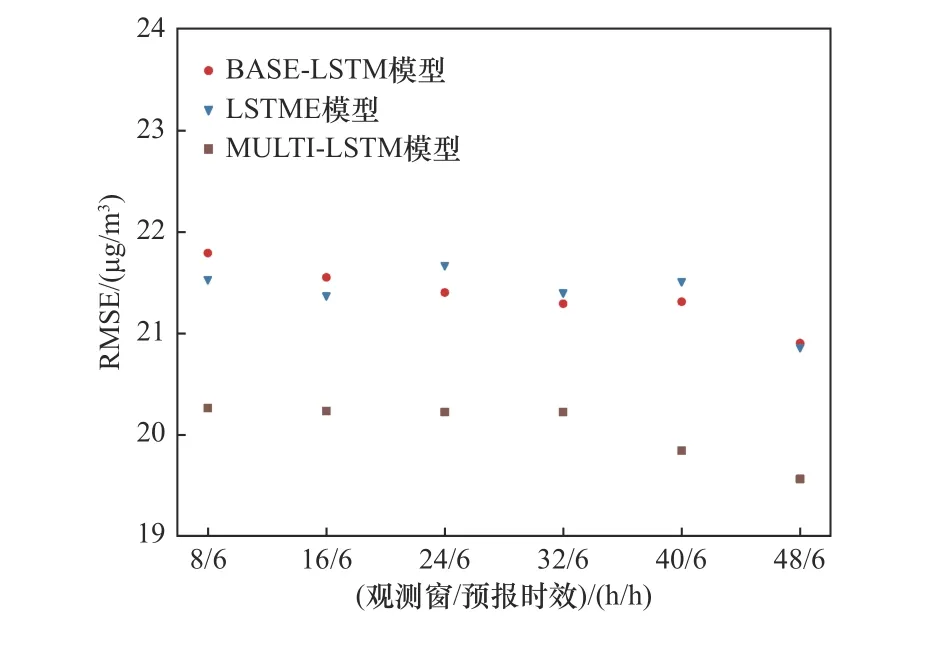
圖5 不同觀測窗下6 h預報時效的RMSEFig.5 The RMSE of different observation windows in 6 hours period validities
對原始數據集進行相關性分析,分別計算原始數據過去第n小時各輸入要素值與未來第m小時PM2.5濃度之間的相關系數.對過去第n小時各輸入要素值與未來第m小時PM2.5濃度之間的所有相關系數取絕對值后求平均值,得到平均相關系數(見圖6).由圖6可見,6條曲線的變化趨勢一致.曲線的變化主要分為4個階段,以未來第1小時PM2.5濃度與各輸入要素值的平均相關系數曲線為例,前15 h為下降階段,平均相關系數由0.35降至0.24;第16~24小時趨于平穩,平均相關系數在0.23~0.24之間;第2個下降階段為第25~39小時,平均相關系數由0.23降至0.17;第40~48小時平均相關系數略有升高,由0.17升至0.18.故根據預報結果與相關性結果可以推斷,增加輸入歷史序列的長度對預報精度提升的影響相對較小,只需根據相關性分析選取合適的輸入歷史序列長度.該文中進一步提升預報精度的觀測窗寬度為40~48 h.
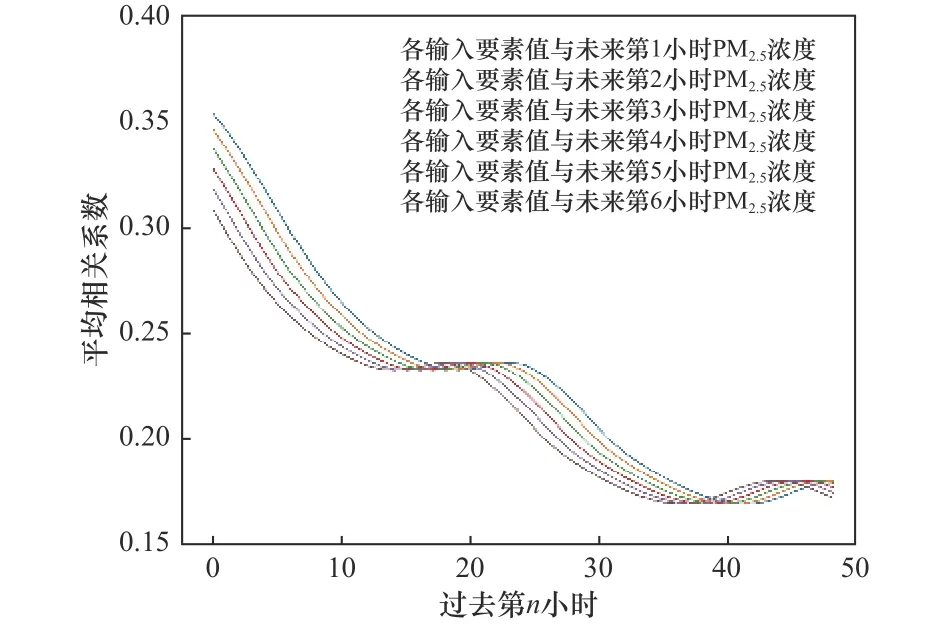
圖6 過去第n小時各輸入要素與未來第m小時PM 2.5濃度的平均相關系數Fig.6 Average correlation coefficient between inputs for the past n-th hour and PM 2.5 concentration for thenext m-th hour
2.2 預報性能評價
分別統計了不同PM2.5污染等級下3個模型在“8/6”組合下測試集的預報情況[31],并將MAPE作為評價指標(見表3).由表3可見,MULTI-LSTM模型的MAPE最小.
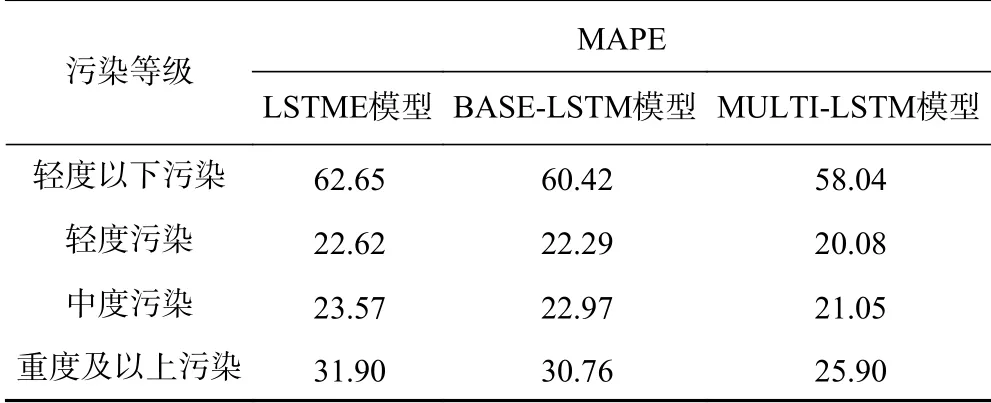
表3 不同模型在不同PM 2.5污染等級下的預報效果(MAPE)Table 3 MAPE of different models in different PM 2.5 pollution process class
對上蘭站(監測站編號:1083A)測試集時段的預報值與觀測值進行對比,選取了3個模型在“8/6”組合下未來6 h預報值與觀測值的平均值(見圖7).由圖7可見,BASE-LSTM模型、LSTME模型與MULTILSTM模型的預報值與觀測值之間的R2分別為0.94、0.93和0.97,MULTI-LSTM模型預報值與觀測值的一致性優于其他模型.此外,根據散點密度圖的線性擬合可以發現,3個基于LSTM構建的深度學習預報模型均存在一定程度的PM2.5低濃度預測偏高以及高濃度預測偏低的問題,但根據預報序列與觀測序列的重合程度來看,對于高濃度PM2.5的預測,MULTI-LSTM模型的預報值與觀測值重合程度更高.

圖7 上蘭站PM 2.5觀測值與不同模型預報值的對比Fig.7 Comparison of PM 2.5 observation values and prediction values of different models in Shanglan station
2.3 網絡深度測試
對“8/6”組合下不同LSTM層數的MULTI-LSTM模型進行訓練,模型預報精度如表4所示.由表4可見,將LSTM層數從1層增至7層,RMSE略有升高,而MAPE與IA變化均不明顯,故增加網絡層數無法明顯提升網絡的預報精度.
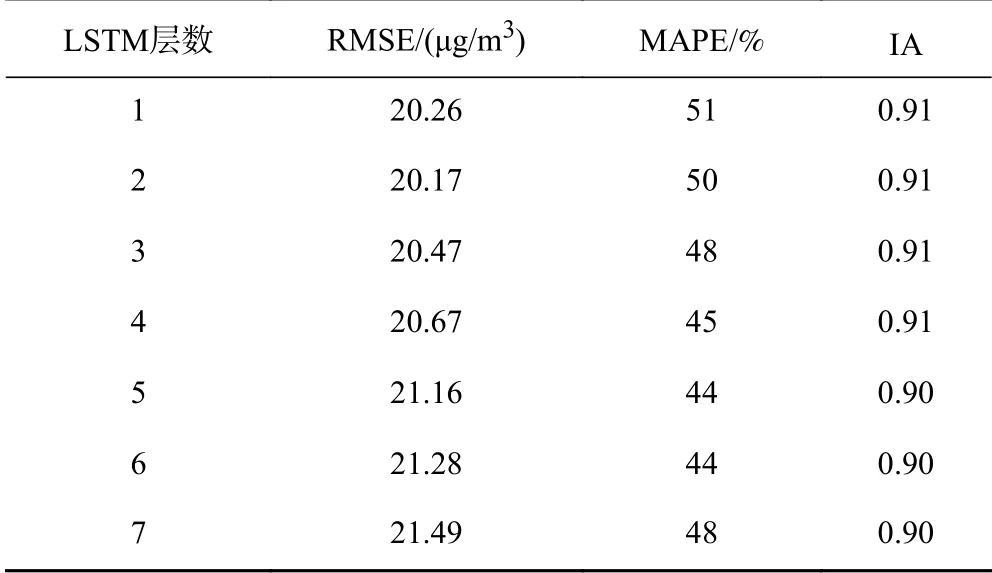
表4 不同LSTM層數的MULTI-LSTM模型整體預報精度Table 4 Accuracy of different LSTM layersof MULTI-LSTM model
3 討論
通過對比不同觀測窗與預報時效下各模型的預報精度發現,BASE-LSTM與LSTME模型預報精度相當,但均低于MULTI-LSTM模型. 利用獨立的LSTM對每個要素進行訓練,明顯提高了模型對PM2.5濃度的預報能力.同時,對于基于LSTM構建的深度學習預報模型來說,輸入要素歷史序列的有效信息具有一定長度,選擇合適的觀測窗寬度可以減少模型訓練的時間成本.以MULTI-LSTM模型為例,選擇8 h與32 h歷史要素預報未來逐6 h的PM2.5濃度,預報精度基本相同(RMSE分別為20.26、20.22μg/m3),將觀測窗寬度增至40 h,預報精度才會進一步提升(RMSE為19.84μg/m3).
選擇合適的網絡層深度也可以減少模型訓練的時間成本,從網絡深度測試的結果來看,增加網絡深度并沒有進一步提升預報精度.當LSTM層數為7時,MULTI-LSTM模型1個訓練周期(epoch)用時為37.5 s,與LSTM層數為1的1個epoch用時(5.6 s)相比,增加了約6倍.
對于氣象數據的選取,與不使用氣象要素或使用單一來源的氣象要素相比,該文使用了不同觀測級別氣象站的氣象數據作為研究區域內空氣質量監測站對應的氣象要素.其中,區域站在地理分布上更密集,從而為周圍空氣質量監測站的PM2.5預報提供更多有效預報信息.國家站觀測要素的種類更為豐富,可進一步挑選與PM2.5濃度變化相關的要素,為模型訓練提供更多相關信息.在后續研究中,可考慮加入氣象再分析數據,將不同位勢高度的氣象要素輸入到模型中,以期進一步提高模型的預報精度.
與CNN-LSTM[26]、GCN-Attention-Seq2Seq[27]、STAM-STGCN[32]、ST-LSTM[33]等基于深度學習的PM2.5濃度逐小時預報模型相比,該文提出的MULTI-LSTM模型將多個要素分別輸入到不同的LSTM模型中,分別提取不同要素的信息,從而降低了模型的復雜性,同時也獲得了相對較高的預報精度(見表5).模型復雜性降低,一方面可減少模型訓練的時間與數據預處理的難度;另一方面,也能進一步避免模型過擬合現象的發生.
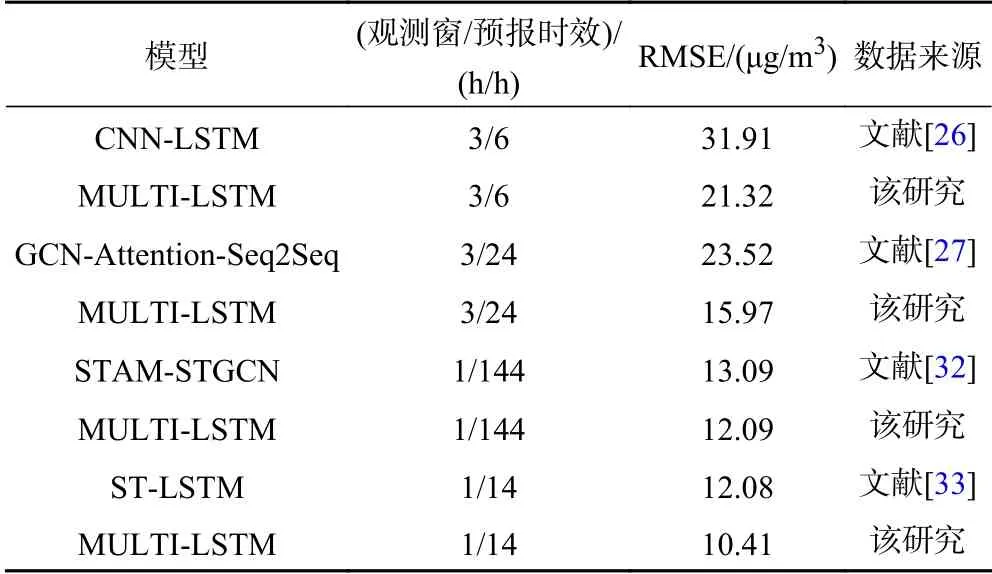
表5 不同模型預報精度對比Table 5 Prediction accuracy of each model
4 結論
a)該研究利用2019?2020年太原市空氣質量監測站、國家氣象觀測站和區域氣象觀測站逐小時數據,提出一種MULTI-LSTM模型,其使用獨立的LSTM分別對各要素進行處理,解決了不同要素的歷史時間序列對PM2.5濃度預報結果響應情況存在差異的問題.
b)對BASE-LSTM、LSTME和MULTI-LSTM模型進行比較,結果表明,MULTI-LSTM模型在不同觀測窗與預報時效組合下的RMSE均低于其他2個模型;同時,在一定范圍內增加觀測窗寬度或提升網絡深度無法進一步提升模型的預報精度.
c)通過選擇合適的觀測窗寬度和氣象要素,以MULTI-LSTM模型作為太原市短期PM2.5濃度預報模型,可獲得精度較高的預報結果,在8 h觀測窗和6 h預報時效組合下,RMSE、MAPE和IA分別為20.26 μg/m3、51%和0.91.下一步將利用MULTI-LSTM模型開展其他污染物的短期預報研究,以進一步驗證模型的預報性能和泛化能力.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
