基于全局注意力的室內(nèi)人數(shù)統(tǒng)計模型*
2022-12-22 11:32:52張長倫王恒友
計算機工程與科學 2022年3期
李 靜,何 強,張長倫,3,王恒友
(1.北京建筑大學理學院,北京 100044;2.北京建筑大學大數(shù)據(jù)建模理論與技術(shù)研究所,北京 100044;3.北京建筑大學北京未來城市設計高精尖創(chuàng)新中心,北京 100044)
1 引言
隨著深度學習的不斷發(fā)展和進步,目標檢測也取得了令人矚目的進展,廣泛應用于機器人導航、智能視頻監(jiān)控、工業(yè)檢測和航空航天等諸多領(lǐng)域,在人臉識別、行人檢測和人群計數(shù)等任務中起著至關(guān)重要的作用。與傳統(tǒng)的室內(nèi)人數(shù)統(tǒng)計方法相比,利用目標檢測進行人數(shù)統(tǒng)計越來越多地被用在人工智能監(jiān)控中,比如考場人數(shù)統(tǒng)計和會議人數(shù)統(tǒng)計。但是,由于室內(nèi)的監(jiān)控一般都是俯拍機位,在一些大型室內(nèi)場景中,俯拍下的人頭都很小,五官較模糊,影響了檢測效果,因此如何提高室內(nèi)人數(shù)統(tǒng)計的準確率是近年來的一個研究熱點。
目前,基于深度學習[1-4]且應用前景[5,6]比較廣闊的目標檢測算法[7-9]有了很大的進步,常見的一階段目標檢測算法有YOLO(You Only Look Once)系列[10-12]和SSD(Single Shot multibox Detector)[13]等。這類算法效率較高,但精度略低。常見的兩階段目標檢測算法有Fast R-CNN[14]、SPP-Net(Spatial Pyramid Pooling Net)[15]、Corner-Net[16]、Faster R-CNN[17]和Mask R-CNN[18]等。雖然兩階段算法的精度更高一些,但算法效率較低。人數(shù)統(tǒng)計需要滿足一定的實時性,所以一階段目標檢測算法更適合進行人數(shù)統(tǒng)計。
近些年來,用目標檢測進行人數(shù)統(tǒng)計的研究取得了一定的突破,由于人數(shù)統(tǒng)計最大的困難在于目標過小或者特征不明顯,所以如何更好地提取特征信息是人數(shù)統(tǒng)計研究的重點。2012年錢鶴慶等[19]提出一種基于人臉檢測的人數(shù)統(tǒng)計方法,利用AdaBoost算法和跳幀檢測方法進行實驗,最終檢測效果和統(tǒng)計速度都有提升;2019年陳久紅等[20]通過改進R-FCN(Region-based Fully Convolutional Network)網(wǎng)絡大大提高了目標檢測算法對小目標的識別能力,準確率有較大的提升;鞠默然等[21]針對小目標檢測率低、虛警率高等問題,提出了改進YOLOv3的模型結(jié)構(gòu),結(jié)果顯示改進后的模型結(jié)構(gòu)對小目標的召回率和準確率都有明顯提升。結(jié)合以上文獻,本文提出了一種基于全局注意力的室內(nèi)人數(shù)統(tǒng)計模型。
本文的主要貢獻如下:
(1)自建室內(nèi)人群檢測數(shù)據(jù)集,并利用聚類算法對錨框進行優(yōu)化。
(2)引入注意力機制CA(Coordinate Attention)[22]模塊對YOLOv3的特征提取網(wǎng)絡進行改進,將CA模塊與ResNet[23]模塊相結(jié)合,根據(jù)不同的結(jié)合方式,組成2種不同的CA-ResNet模塊,依次替換傳統(tǒng)YOLOv3的殘差模塊,檢測不同結(jié)合方式對算法性能帶來的影響,以此提取更多的特征信息,提高模糊或者較小目標的檢測精度。
(3)對CA模塊進行改進,使其能夠更好地從網(wǎng)絡中提取全局的特征信息。
在自建室內(nèi)人群檢測數(shù)據(jù)集上訓練新模型,結(jié)果表明改進后的YOLOv3算法能夠提取更多重要特征,測試的召回率和平均精度有明顯提升。
2 背景知識
2.1 YOLOv3算法簡介
YOLOv3算法以YOLOv1和YOLOv2為基礎,在YOLOv2提出的骨干網(wǎng)絡Darknet-19的基礎上引入了殘差模塊,并進一步加深了Darknet-19網(wǎng)絡,改進后的骨干網(wǎng)絡有53個卷積層,命名為Darknet-53。另外,YOLOv3借鑒了特征金字塔網(wǎng)絡的思想,從不同尺度提取特征進行目標檢測,在保持速度優(yōu)勢的前提下提升了預測精度,尤其是加強了對小目標的識別能力。YOLOv3算法以Darknet-53網(wǎng)絡作為主干網(wǎng)絡,同時與多尺度預測進行結(jié)合,網(wǎng)絡結(jié)構(gòu)如圖1所示。
Darknet-53借用了ResNet的思想,在YOLOv2提出的骨干網(wǎng)絡Darknet-19中加入了殘差模塊。每個殘差模塊由2個CBL單元和1個快捷鏈路層構(gòu)成,其中,CBL(Convolutional_Batch Normalization_Leaky ReLU)單元包含卷積層、批正則化BN(Batch Normalization)層和Leaky ReLU[24]激活函數(shù),這樣有利于解決一些深層次網(wǎng)絡的梯度問題。Darknet-53的網(wǎng)絡結(jié)構(gòu)一共包含53層卷積層,1,2,8,8和4代表有幾個重復的殘差模塊,YOLOv3中沒有池化層和全連接層,網(wǎng)絡的下采樣是通過設置卷積的步長為2來實現(xiàn)的,圖像經(jīng)過該卷積層之后尺寸就會減小一半。
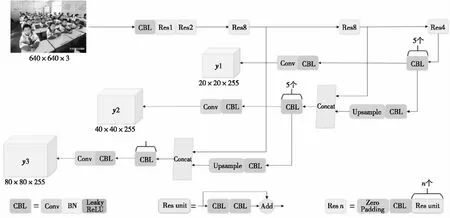
Figure 1 YOLOv3 network structure
2.2 注意力機制CA模塊
CA模塊是一種靈活且輕量的注意力機制,普通的通道注意力機制,如SE-Net(Squeeze and Excitation-Network)[25]中的SE模塊,是通過學習的方式來自動獲取每個特征通道的重要程度,然后依照重要程度增強有用的特征并抑制對當前任務用處不大的特征,從而實現(xiàn)特征通道的自適應校準,但是此方法并沒有充分利用全局上下文信息,通常會忽略位置信息,且增加了整個網(wǎng)絡的計算量,SE模塊結(jié)構(gòu)如圖2a所示。而CA將位置信息嵌入到通道注意力中,如圖2b所示,分別對水平方向和垂直方向進行平均池化得到2個一維向量,在空間維度上拼接和1×1卷積來壓縮通道,再通過BN層和非線性激活函數(shù)來編碼垂直方向和水平方向的空間信息,接下來分割,再各自通過1×1卷積得到輸入特征圖一樣的通道數(shù),最后把空間信息通過在通道上加權(quán)的方式融合。這樣既可捕獲跨通道的信息,也可保留精確的位置信息。將生成的特征圖分別編碼,形成一對方向感知和位置敏感的特征圖,可以互補地應用于輸入特征圖中增強感興趣的目標的表示,CA模塊結(jié)構(gòu)如圖2b所示。
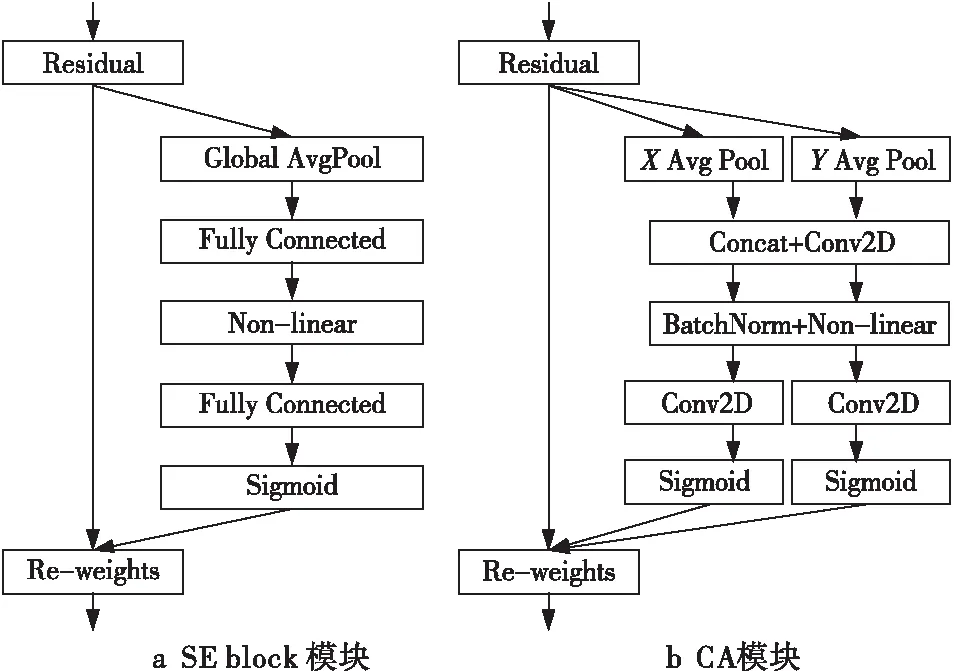
Figure 2 Attention mechanism module
3 基于全局注意力的人員檢測模型
3.1 自建室內(nèi)人群檢測數(shù)據(jù)集
在傳統(tǒng)YOLOv3使用的常規(guī)數(shù)據(jù)集,如Pascal VOC(Visual Object Classes)數(shù)據(jù)集和Microsoft COCO(Common Objects in COntext)數(shù)據(jù)集,可檢測的目標種類過多,包含人頭的圖像過少,甚至有些過于模糊或太小的人頭并沒有標注出來,因此在常規(guī)目標檢測數(shù)據(jù)集上的檢測效果并不理想,需要有針對性地制作數(shù)據(jù)集完成訓練和檢測任務。本文制作室內(nèi)人群檢測數(shù)據(jù)集的方法如下:
(1)利用Python網(wǎng)絡爬蟲技術(shù)從必應和百度網(wǎng)站爬取包含室內(nèi)場景人群的圖像,部分示例如圖3所示。

Figure 3 Several images in the static dataset
(2)搜集北京建筑大學不同教室不同時間的監(jiān)控視頻,視頻大小共20 GB,格式為MKV,本文將視頻以1/8 fps的標準轉(zhuǎn)換成相應的圖像序列,部分示例如圖4所示。

Figure 4 Several images in the dynamic dataset
(3)為了豐富數(shù)據(jù)集,對獲得的所有圖像進行數(shù)據(jù)增強,將經(jīng)過人工篩選得到符合要求的圖像組成數(shù)據(jù)集,共1 000幅圖像,然后將1 000幅圖像中的所有人頭均采用LabelImg進行手工標注,標注效果如圖5所示。
Figure 5 Annotation effect
3.2 聚類候選錨框
對于選擇錨框的形狀,YOLOv2已經(jīng)開始采用K-means聚類得到先驗框的尺寸。傳統(tǒng)YOLOv3延續(xù)了這種方法,使用K-means算法對訓練集中所有樣本的真實框聚類,得到具有代表性形狀的寬和高(維度聚類)。
利用K-means算法對自建數(shù)據(jù)集所有樣本真實框(Ground Truth)的寬和高進行聚類,得到先驗框大小。關(guān)于錨框數(shù)量,原YOLOv3的網(wǎng)絡結(jié)構(gòu)最終輸出3個尺寸的特征圖,所以取了9個錨框。在自建數(shù)據(jù)集上這9個先驗框的大小是:(12×21),(20×37),(33×56),(44×93),(72×117),(74×211),(115×164),(124×277),(207×313)。
3.3 CA-ResNet模塊設計
為了使YOLOv3能夠獲取更多特征信息,增強對模糊或者較小目標的檢測能力,本文改進了YOLOv3算法的特征提取網(wǎng)絡,將CA模塊與ResNet模塊相結(jié)合,根據(jù)不同的結(jié)合方式組成2種不同的CA-ResNet模塊,分別記為CA-ResNet A和CA-ResNet B,來替換傳統(tǒng)YOLOv3的殘差模塊。CA-ResNet模塊改進的基本思想是捕獲跨通道的信息,并不是每個通道都對信息傳遞非常有用,因此可通過對這些通道進行過濾來得到優(yōu)化后的特征,幫助YOLOv3更加精準地定位和識別感興趣的目標,提升檢測精度。
CA-ResNet系列模塊均由ResNet模塊和CA模塊構(gòu)成。傳統(tǒng)的ResNet模塊結(jié)構(gòu)如圖6所示,改進后的2種CA-ResNet模塊如圖7所示,用CA-ResNet模塊替換傳統(tǒng)YOLOv3的殘差模塊,由于改進后的Darknet-53網(wǎng)絡結(jié)構(gòu)增加了卷積層,特征細節(jié)會有所丟失,因此為了更好地進行高層信息與低層信息的特征融合,本文對YOLOv3進行了改進,改進后的CA-ResNet-YOLOv3的網(wǎng)絡結(jié)構(gòu)如圖8所示。
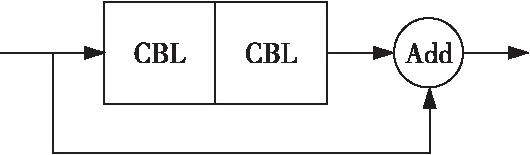
Figure 6 ResNet module
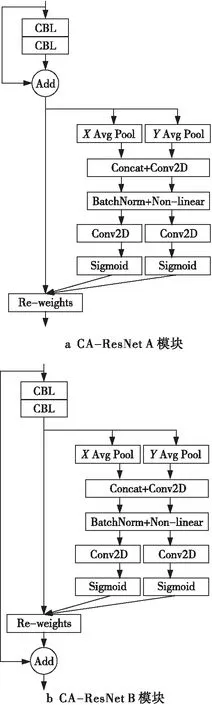
Figure 7 CA-ResNet module

Figure 8 Network structure of CA-ResNet-YOLOv3
3.4 CA模塊改進
CA模塊中使用了平均池化來對數(shù)據(jù)進行下采樣,這樣既可以保留更多的圖像背景信息,強調(diào)對整體特征信息進行下采樣,也可以更大程度上減少參數(shù),并且加強信息的完整傳遞。由于池化丟失的信息太多,雖然最大池化和平均池化都對數(shù)據(jù)進行下采樣,但是最大池化更像是進行特征選擇,選出分類辨識度更好的特征,保留更多細節(jié)特征。因此,本文采用平均池化與最大池化并行的連接方式,這樣設計比使用單一的池化丟失的信息更少,改進的模塊稱為CA1(Coordinate Attention 1),其結(jié)構(gòu)如圖9所示。
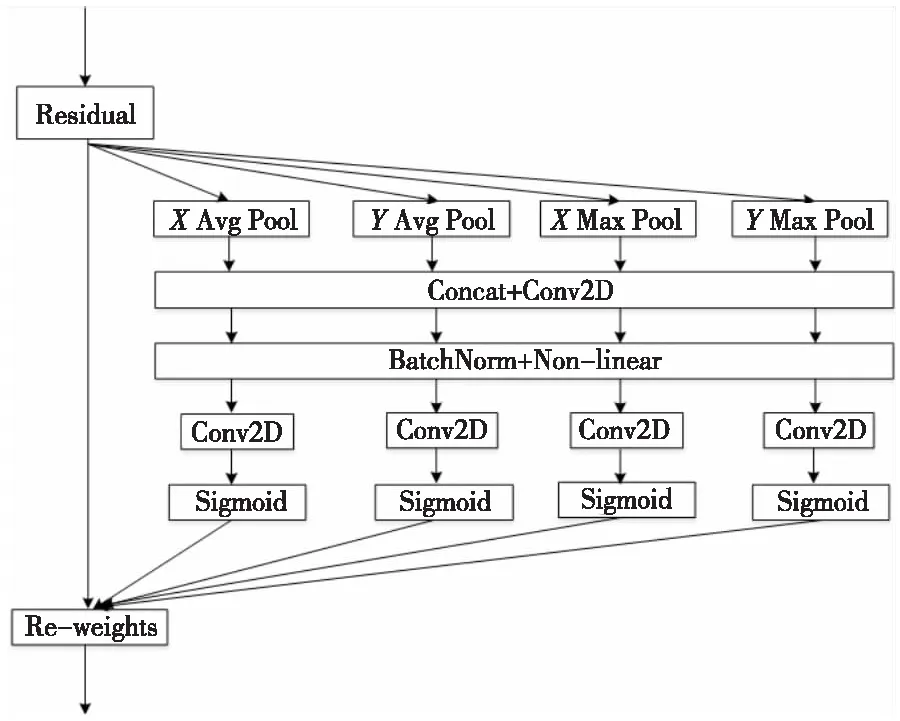
Figure 9 CA1 module
4 實驗設計
本文將進行4組對比實驗來驗證改進的效果:(1)將CA-ResNet A模塊和CA-ResNet B模塊嵌入傳統(tǒng)YOLOv3算法的網(wǎng)絡結(jié)構(gòu)中,得到CA-ResNet A-YOLOv3算法和CA-ResNet B-YOLOv3算法,將這2個算法在自建室內(nèi)人群檢測數(shù)據(jù)集上進行實驗,對比傳統(tǒng)YOLOv3模型的檢測性能,以檢驗CA模塊嵌入殘差模塊中不同位置所帶來的性能變化;(2)用GC(Global Context)[26]模塊和CA1模塊替換圖7b中的CA模塊,組成GC-ResNet B模塊和CA1-ResNet B模塊,嵌入YOLOv3的殘差模塊中,得到GC-ResNet B-YOLOv3和CA1-ResNet B-YOLOv3,對比不同注意力模塊對YOLOv3算法性能的影響;(3)在自建室內(nèi)人群數(shù)據(jù)集上用傳統(tǒng)YOLOv3算法和CA1-ResNet B-YOLOv3算法進行對比實驗,從評價指標的結(jié)果和檢測圖像的效果2方面來檢驗改進后的YOLOv3算法的性能;(4)將所提的CA1-ResNet B-YOLOv3算法與傳統(tǒng)YOLOv3算法、SSD算法以及鞠默然等[21]改進的YOLOv3算法在自建人群檢測數(shù)據(jù)集上進行對比實驗。
4.1 評價指標
本文采用目前主流的目標檢測算法的評價指標:準確率Precision、目標召回率Recall和均值平均精度mAP。
準確率Precision指算法預測為正的樣本中,真實正樣本的比例,一般用來評估算法的全局準確程度,其定義如式(1)所示:
(1)
召回率Recall指在原始樣本的正樣本中,最后被正確預測為正樣本的概率,其定義如式(2)所示:
(2)
本文以室內(nèi)人群檢測為例,TP為正確檢測出的人數(shù),F(xiàn)P為誤檢人數(shù),F(xiàn)N為漏檢人數(shù)。
mAP是每個類別AP(Average Precision)的平均值,AP是P-R曲線下的面積。以召回率為橫坐標,準確率為縱坐標,繪制P-R曲線,利用積分可求出mAP的值,其定義如式(3)所示:
(3)
其中,c表示類別數(shù),p表示Precision,r表示Recall,p(r)是一個以r為參數(shù)的函數(shù)。
虛警率=1-Precision
(4)
漏警率=1-Recall
(5)
因此,準確率Precision值越大則虛警率越小,召回率Recall值越大則漏警率越小,mAP用于衡量算法好壞,值越大說明其識別效果越好。
4.2 數(shù)據(jù)集
本文的自建數(shù)據(jù)集通過視頻提取和網(wǎng)絡爬蟲2種方法得到,經(jīng)過篩選對其中一部分圖像進行了數(shù)據(jù)增強,最終數(shù)據(jù)集包含有1 000幅圖像,只有1個類別person,然后采用開源的LabelImg軟件對采集到的1 000幅圖像進行標注,得到了對應的1 000個xml文件,以9∶1的比例將圖像分為訓練樣本和測試樣本。
4.3 實驗環(huán)境和訓練參數(shù)
實驗條件:本文提出的模型是使用PyTorch和Python實現(xiàn)的,操作系統(tǒng)為Ubuntu 16.04,深度學習框架為Darknet,GPU為NVIDIA GeForce RTX 2080Ti。
訓練參數(shù)設置為:(1)訓練迭代次數(shù)epoch設置為100;(2)每次迭代訓練的圖像數(shù)目batch_size設置為4;(3)subdivision設置為1;(4)輸入尺寸為640×640;(5)學習率為0.001。
5 實驗結(jié)果與分析
(1)CA模塊嵌入殘差模塊中不同位置所帶來的性能變化,實驗結(jié)果如表1所示。
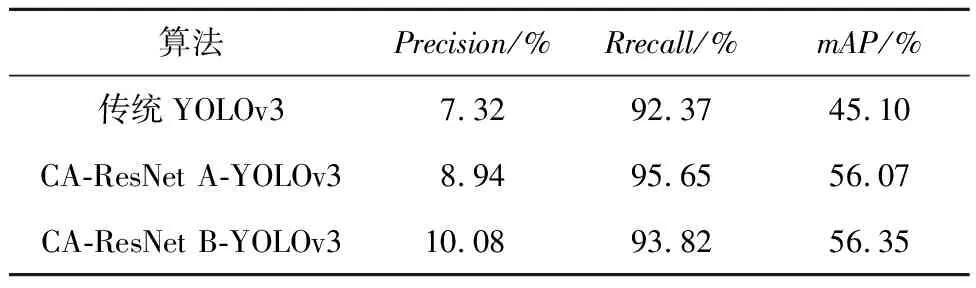
Table 1 Detection results on self-built dataset
從表1可以看出,CA-ResNet B-YOLOv3算法的mAP值最大,比傳統(tǒng)YOLOv3的高出11.25%,比CA-ResNet A-YOLOv3算法的高出0.28%,也就是說,將CA模塊嵌入在殘差模塊中Add之前的效果更好,可以保留更多目標在特征圖中的語義信息,便于模糊目標的識別。
(2)不同注意力模塊對YOLOv3算法性能的影響,實驗結(jié)果如圖10和表2所示。
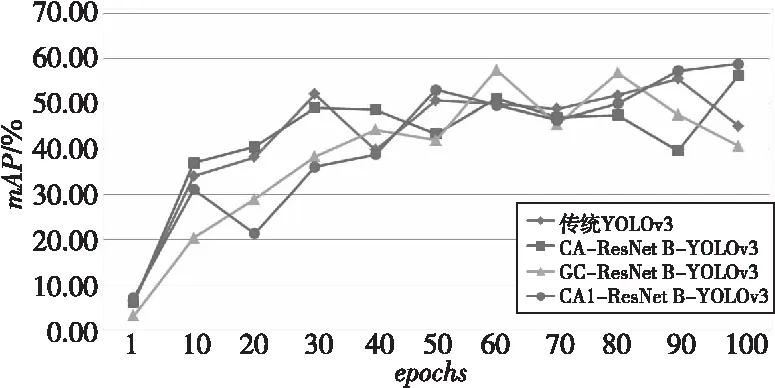
Figure 10 Changes of mAP during training of different algorithms
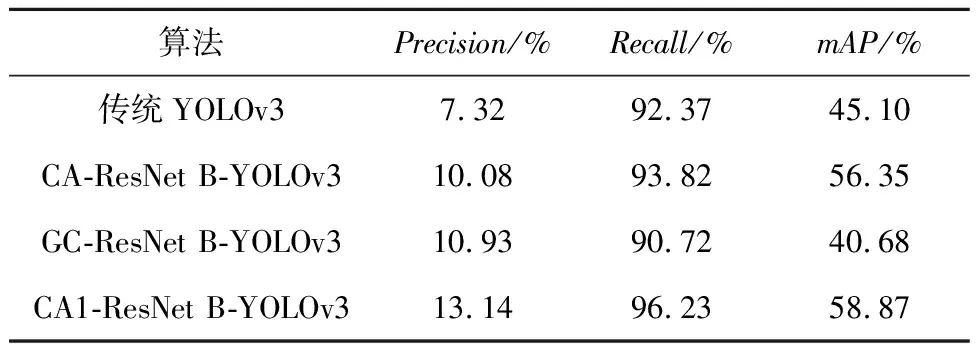
Table 2 Performance effects of different attention modules
從實驗結(jié)果可明顯看出,使用改進后CA1模塊的YOLOv3算法各個指標都有明顯提升,無論是Precision值還是Recall值都有明顯增長,即達到了減少漏警率和誤檢率的目的,從最終的mAP值可以看出算法性能獲得了改善。
(3)CA1-ResNet B-YOLOv3算法的效能評估和分析,只有一個目標類別person,在自建數(shù)據(jù)集上的檢測性能如表3所示。

Table 3 Performance of CA1-ResNet B-YOLOv3 algorithm on self-built dataset
從表3的實驗結(jié)果可以看出,與傳統(tǒng)YOLOv3相比,CA1-ResNet B-YOLOv3算法的檢測準確率提升了5.82%,召回率由92.37%提高到96.23%,上升了3.86%,CA1-ResNet B-YOLOv3算法的mAP由45.10%提高到了58.87%,檢測效果如圖11和圖12所示。
對比圖11和12可以看出,CA1-ResNet B-YOLOv3算法對于一些復雜場景,如與背景相近的陰暗處的人也可以較好地識別,定位準確度提高了很多,誤檢和漏檢的情況也有顯著改善。

Figure 11 Detection results of traditional YOLOv3 algorithm on self-built dataset

Figure 12 Detection results of CA1-ResNet B-YOLOv3 algorithm on self-built dataset
(4)在自建數(shù)據(jù)集上對比經(jīng)典算法。硬件平臺為NVIDIA GeForce RTX 2080Ti,檢測結(jié)果如表4所示。在NVIDIA GeForce RTX 2080Ti嵌入式平臺上,結(jié)合表4對比不同算法在自建人群檢測數(shù)據(jù)集上的檢測精度可以看出,CA1-ResNet B-YOLOv3算法相較于傳統(tǒng)YOLOv3模型在mAP指標上提高了約13.77%,Recall值有很大的提升,漏警率降低了許多;相較于同樣是一階段目標檢測算法的SSD算法,其mAP提升了9.32%,相較于復現(xiàn)的鞠默然等[21]提出的改進的YOLOv3算法,其mAP提高了3.13%,Recall值提高了1.93%。
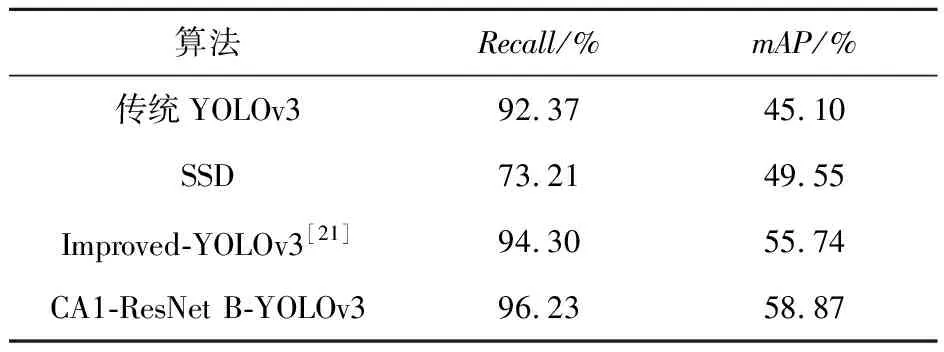
Table 4 Performance comparison of different algorithms
6 結(jié)束語
本文基于全局注意力來進行人數(shù)統(tǒng)計。首先,利用動態(tài)數(shù)據(jù)集和靜態(tài)數(shù)據(jù)集相結(jié)合自建數(shù)據(jù)集,并對部分數(shù)據(jù)集進行了數(shù)據(jù)增強;通過K-means算法重新聚類錨框;然后將CA模塊與ResNet模塊相結(jié)合,構(gòu)成2種不同組合方式的CA-ResNet模塊,替換傳統(tǒng)YOLOv3的殘差模塊;并對CA模塊進行了改進,使其更好地提取細節(jié)特征信息;最后根據(jù)識別出來的人進行統(tǒng)計,實時返回畫面中的人數(shù)。實驗結(jié)果表明,改進后的CA1-ResNet B-YOLOv3算法對于室內(nèi)人群識別的召回率、檢測的平均精度都有明顯提升。
但是,改進后的算法在訓練速度和人數(shù)統(tǒng)計的實時性方面上還有較大提升空間。下一步將在不影響檢測性能的情況下降低計算量、精簡網(wǎng)絡結(jié)構(gòu)進行深入研究。
猜你喜歡
數(shù)學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2021年6期)2021-11-22 07:50:58
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
中學生數(shù)理化·七年級數(shù)學人教版(2020年12期)2021-01-18 06:57:46
世界科學技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
