基于彈幕文本挖掘的社交媒體KOL研究*
2022-12-22 12:06:56周忠寶朱文靜郭修遠王立峰
計算機工程與科學 2022年3期
周忠寶,朱文靜,王 皓,郭修遠,王立峰
(1.湖南大學工商管理學院,湖南 長沙 410082;2.湖南大學新聞與傳播學院,湖南 長沙 410082)
1 引言
隨著我國文化事業的飛速發展,社交媒體關鍵意見領袖KOL(Key Opinion Leader)作為互聯網時代文化產業的新生力量得到廣泛關注。社交媒體KOL擁有大量忠實粉絲,能憑借著自身強大的號召力和影響力使內容在粉絲人群中擁有深入的滲透力。作為廣告主和消費者的媒介者,KOL幫助品牌與消費者建立聯系,為品牌推廣帶來可信度,因此備受廣告主青睞[1]。但是,KOL行業的低門檻進入,使KOL人數日益增加。據卡思數據收錄,我國各平臺粉絲量在10萬以上的KOL已經超過20萬個,而且超半數的KOL營銷數據都存在刷量造假行為,這些都會導致廣告主無法僅從粉絲量級來分析KOL的商業價值。如何對KOL進行更全面的分析,成為了KOL營銷亟需解決的問題。
社交媒體KOL營銷的傳播媒介多元化,其中視頻因為具有更高的傳播示能和內容密度,使用更為廣泛。隨著視頻網站的發展,彈幕技術被廣泛運用。與傳統評論不同,彈幕是一種直接顯示在視頻上的滾動評論,有“視頻時間”和“自然時間”2個維度。作為一種新型的即時互動的視頻評論方式,彈幕的即時性使得觀眾可以超越時空限制,使人們獨自觀看視頻時有一種很多人共同觀看該視頻并產生共同情緒與吐槽點的奇妙心理,這種心理促使觀眾更愿意參與到討論中。人們觀看彈幕視頻獲取信息、娛樂和社交聯系[2],并且彈幕會影響觀眾感知[3,4],這為分析KOL提供了新的研究視角。通過對彈幕內容進行文本分析,不僅可以對彈幕的主題進行檢測[5],還能分析觀眾的情感[6,7]。
本文通過對社交媒體KOL視頻彈幕進行文本挖掘,使用動態主題模型和卷積神經網絡CNN(Convolutional Neural Network)模型對彈幕豐富的語義信息進行主題和情感分析,構建一種新的KOL分析體系,從而幫助廣告主找到粉絲群體符合品牌調性且具有正面影響力的KOL,更精準地進行KOL營銷。本文圍繞視頻彈幕主要從以下3個方面進行研究:(1)針對彈幕的時間屬性,對視頻彈幕的時間屬性進行描述性統計,從彈幕時間分布對觀眾的行為偏好進行刻畫。(2)對彈幕文本進行動態主題分析,對彈幕內容進行主題識別以及隨時間變化的細粒度主題詞演化分析。(3)對含有推廣的視頻進行情感分析,分析觀眾對于視頻中含有推廣的情感傾向。
2 相關研究
2.1 主題模型
主題模型通過分析文本中的詞來研究文檔中的語義主題結構,從而實現對文本的組織和歸納[8]。在主題模型中,主題是一個語義層面的假設,一個主題是一系列詞匯的概率分布,文檔可以由一系列主題表示。隱含狄利克雷分配LDA(Latent Dirichlet Allocation)作為最經典的主題模型[9],目前已經被廣泛應用于學術界和工業界。
但是,LDA忽視了語料庫中文本的時間順序,于是Blei等[10]提出動態主題模型DTM(Dynamic Topic Model)。DTM考慮了文檔的先后順序,假設主題隨時間發生變化,該模型被證明是一個能夠準確描述潛在主題及其動態變化的強有力工具。
傳統的語言建模方法使用Dirichlet分布來處理詞語分布的不確定性,但是Dirichlet分布對序列建模并不適用。為解決這一問題,DTM模型引入了高斯噪聲,通過狀態空間模型鏈接了每個主題的自然參數βt,k,其中βt,k表示時間切片t中主題k的自然參數。也就是說,在動態模型中通過連接高斯分布對組件隨機變量序列進行建模,并將值映射為單純形,將邏輯正態分布延伸至時間序列上的單純形數據。
對于文檔-主題概率分布θ,DTM模型使用平均值α的邏輯正態分布來表示概率分布的不確定性,其中各參數的含義如表1所示;同時通過式(1)所示的簡單的動態模型捕獲模型之間的順序結構:
αt|αt-1~N(αt-1,δ2I)
(1)
將主題和主題概率分布連接在一起,即可有序地得到一組主題模型。一組有序語料在時間切片t上的生成過程可以表述為:
(1)生成主題分布:
βt|βt-1~N(βt-1,σ2I)
(2)構建動態模型描述主題隨時間的變化:
αt|αt-1~N(αt-1,δ2I)
(3)對每篇文檔:
①生成文檔-主題分布參數:
η~N(αt,α2I)
②對文檔中的每個詞語:
a 生成文檔-主題分布:
Z~Mult(π(η))

Table 1 DTM paramaeter information
b 生成詞語-主題分布:
Wt,d,n~Mult(π(βt,z))
其中π(·)將多項自然參數映射為平均參數。如果去掉圖1中的方向箭頭,不考慮時間上的動態變化,整個流程可以看做一系列獨立主題模型的集合。考慮時間上的變化后,時間切片t上的第k個主題是在時間切片t-1的第k個主題的基礎上經過平滑的演變得到的。

Figure 1 DTM model illustration
2.2 卷積神經網絡
情感分析(Sentiment Analysis)是對文本中某個實體的觀點的情感及態度的計算[11]。它利用自然語言處理、文本分析、機器學習和計算語言學等方法對帶有情感色彩的文本進行分析、推理和歸納。情感分類作為情感分析技術的核心問題,其目標是判斷評論中的情感取向。隨著互聯網評論數據的日益增多,傳統基于詞典的情感分析方法[12 - 14]和基于機器學習情感方法[15 - 18]已經不能高效處理海量評論的情感分類問題。近年來隨著深度學習技術的快速發展,其在大規模文本數據的智能理解上表現出了獨特優勢,越來越多的研究人員青睞于使用深度學習技術來解決文本分類問題[19 - 24]。Socher等[21 - 23]在2011~2013年間提出了一系列基于遞歸神經網絡的分類模型來解決情感分類問題,Kim[24]則將卷積神經網絡運用于情感分類問題。實驗結果表明,卷積神經網絡的分類效果明顯優于遞歸神經網絡,卷積神經網絡在語句級別的情感分類問題上表現優秀。
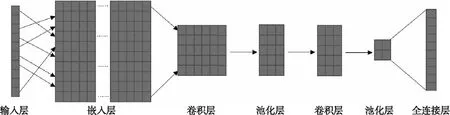
卷積神經網絡是多層網絡結構,主要結構按層次分卷積層(Convolutional Layer)、池化層(Pooling Layer)和全連接層(Fully-Connected Layer)。模型的輸入為按照文本中詞語的順序排列的詞向量,卷積層通過多個卷積過濾器來發現輸入文本中相鄰多個詞之間的局部特征,這些局部特征經過池化層得到卷積層中最重要的特征,并且保證對于不同長度的輸入文本能夠輸出相同長度的特征。最后全連接層將所有局部特征結合變成全局特征,用來計算最后每一類的得分,得到最終的分類結果。
3 基于彈幕文本的KOL分析模型構建
3.1 彈幕數據爬取及預處理
相較于其他平臺,嗶哩嗶哩彈幕視頻網站(B站)視頻因無廣告、彈幕有趣、社群屬性強等特點吸引了大量優質用戶。此外B站內容更加垂直、粉絲質量高、KOL數據造假的現象少。綜合以上優點,本文以B站為研究平臺,實驗使用Python語言爬取視頻彈幕,具體思路如下所示:
首先將爬蟲偽裝成瀏覽器:為了防止爬蟲被禁,需要設置頭文件和Cookie文件。頭文件信息比較容易找到,在Chrome的開發者工具中選擇Network,刷新頁面后選擇Headers就可以查看到本次訪問的頭文件信息,頭文件信息的旁邊還有一個Cookies標簽,其內容就是本次訪問的Cookies信息。之后爬取網頁的URL:根據視頻av號獲取彈幕cid,再按照固定格式拼接字符串得到數據請求URL。使用GET方式請求URL,然后與前面設置的頭文件信息和Cookie信息一起發送請求,從而獲取頁面信息。為了避免頻繁的請求導致返回空值,所以2次請求間隔設置為5 s。最后進行數據的存儲與清洗:解析返回的xml彈幕數據,對原始數據進行去重清洗,以CSV的格式存儲在本地。對不同視頻循環執行以上操作,直到所有視頻彈幕數據采集完成。
本文選擇B站時尚區具有代表性的up主“機智的黨妹”為研究對象,“機智的黨妹”賬號信息如表2所示,實驗共爬取了“機智的黨妹”143個視頻的約50萬條彈幕,數據更新時間截止到2019年11月2日。
爬取完彈幕數據后,需要對彈幕數據進行去停用詞和切詞處理。由于彈幕語言存在網絡詞匯較多、口語化及書寫不規范等問題,而現有的分詞詞庫不能滿足本文的切詞需求,因此本文人工建立領域詞典來對彈幕文本進行分詞處理。
本文在Jieba分詞庫的基礎上,對彈幕和美妝領域相關詞語進行收集后,通過人工篩選和整理獲得3 611個該領域的常用詞,并加入到基礎分詞庫中,匯總成實驗所需要的詞典。部分分詞詞語如表3所示。
分詞處理后對實驗數據進行去停用詞處理,本文整理了“中文停用詞庫”“哈工大停用詞表”“四川大學機器智能實驗室停用詞庫”和“百度停用詞表”,形成本文的停用詞表。
3.2 動態主題建模
實驗以對數似然度作為評估依據確定主題模型主題數,通過對不同主題數的實驗結果進行比較,圖2是實驗選擇不同主題數對應的對數似然數值。由圖2可以看出,主題數為3時出現了一個局部峰值,之后隨著主題數的增加,對數似然數呈遞增趨勢,主題數為10時對應的對數似然數最大,之后隨著主題數的增加,對數似然數呈遞減趨勢。綜合考慮,主題數為3時實驗概況性好、冗余度低。
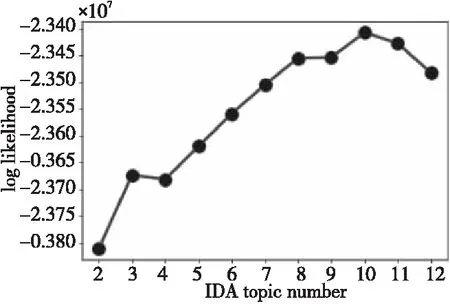
Figure 2 Log likehood
確定好主題數后,進一步對彈幕數據進行時間片劃分。本文將彈幕按照自然時間排序,將彈幕數據劃分為10個時間片段,具體如表4所示。
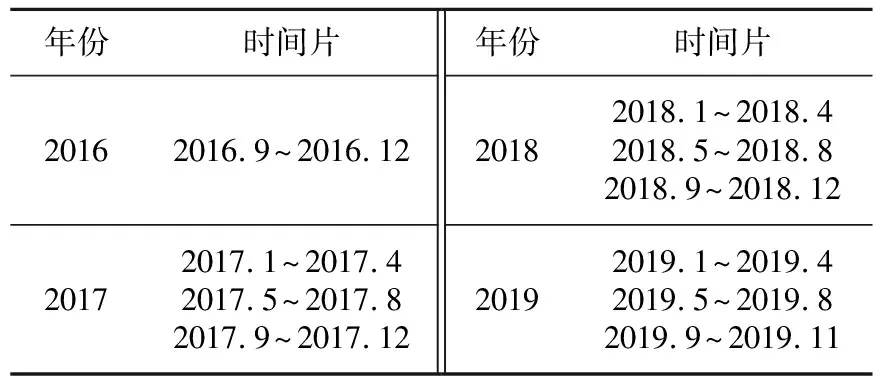
Table 4 Time slice partition
3.3 主題識別與細粒度主題詞演化
DTM模型中每個詞w在時間切片t中對于主題k的貢獻記作βt,k,w,該值隨時間、主題和詞的變化而變化。通過DTM建模,全部時間切片內的詞語分布概率之和表示詞語對主題的貢獻度,主題k中詞w的貢獻度為P(w|k)。=∑βt,k,w。將P(w|k)值進行排序,即根據詞w對文獻研究內容的貢獻度進行排序,人工判定最能體現文獻研究內容的主題。
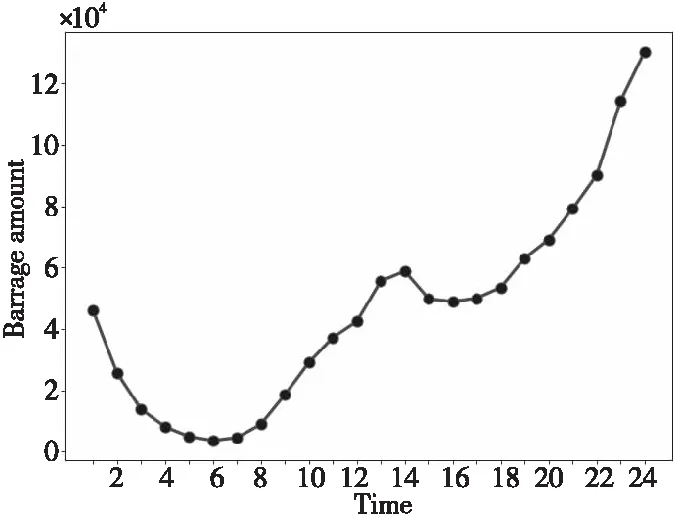
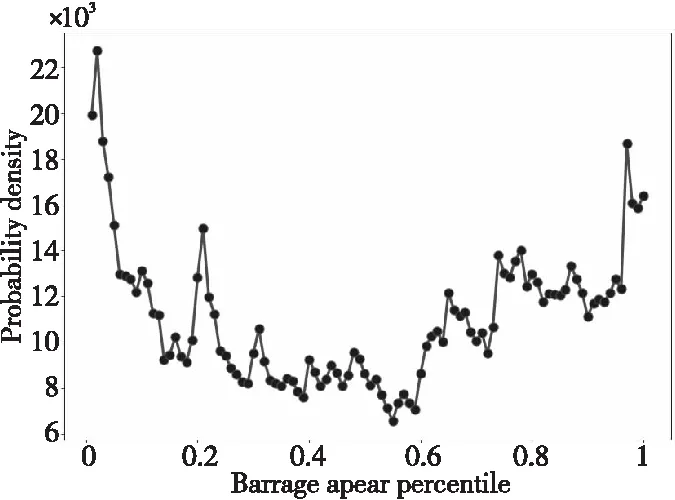
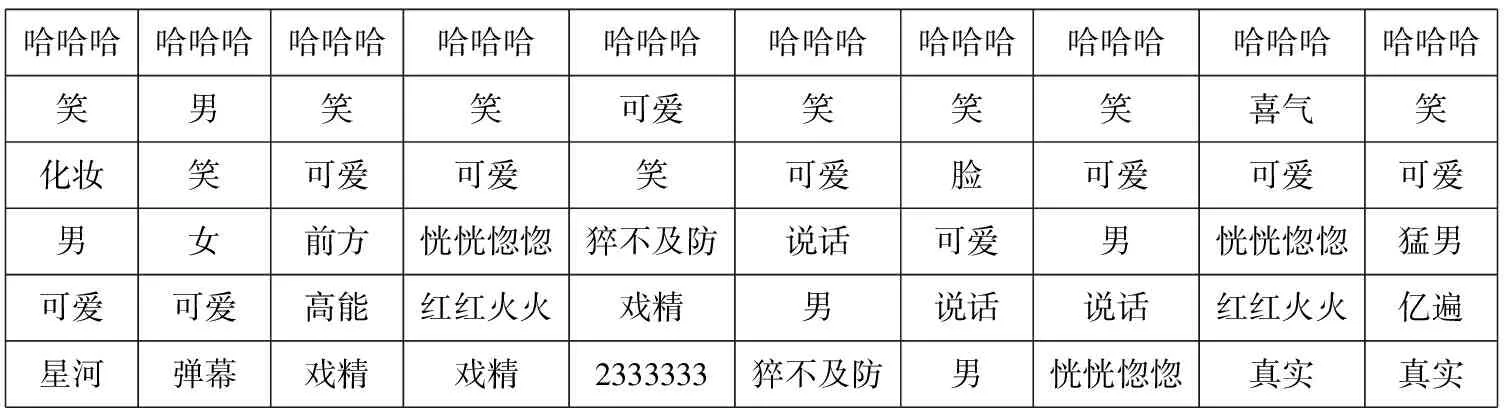
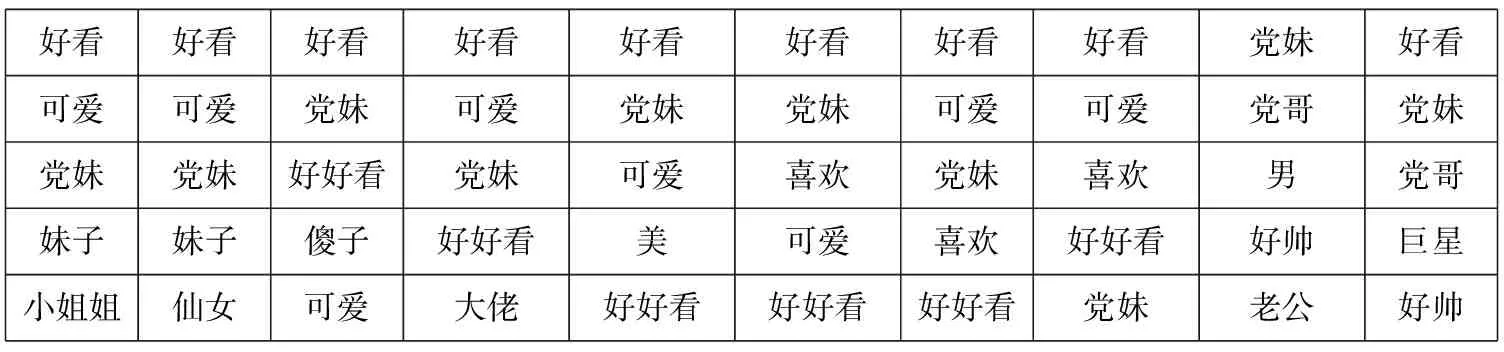
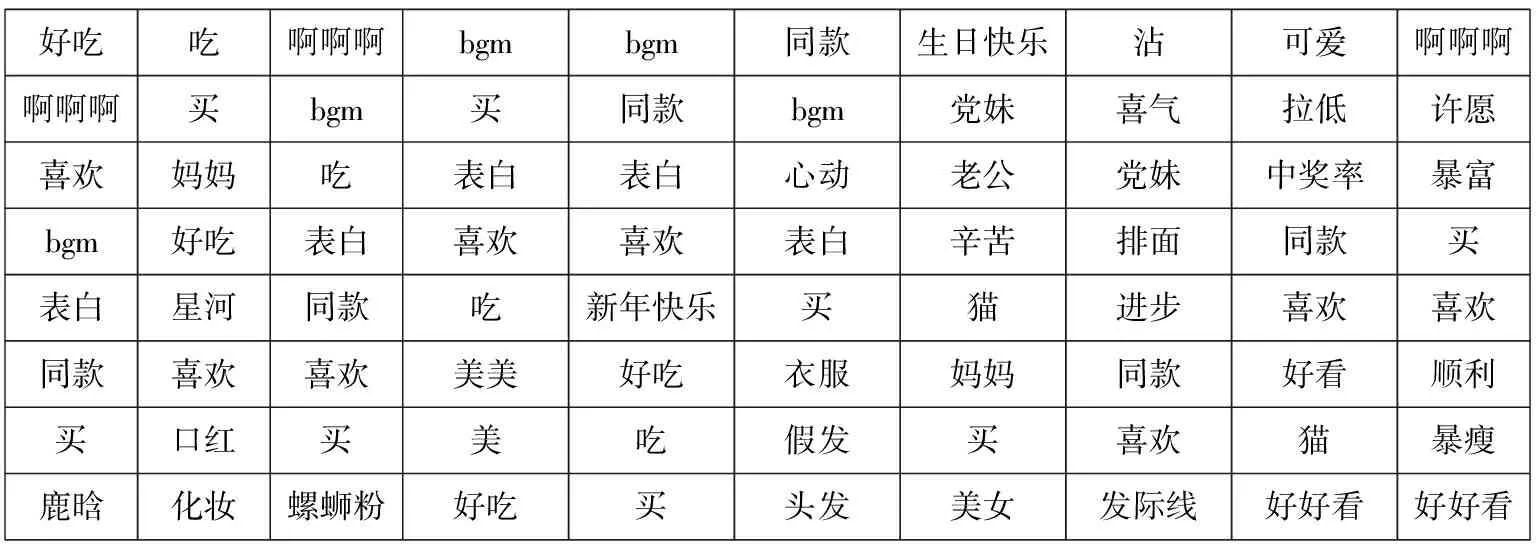
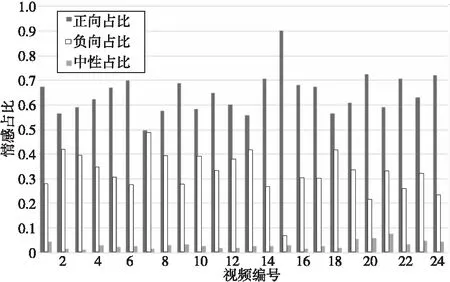
本文通過抽取關注度較高的詞語對主題進行描述。詞w的關注程度的變化可以通過相鄰時間切片內的概率正差值進行計算,即βt,k-βt-1,k(1 3.4.1 構建情感詞典 通用情感詞典(例如知網情感詞典和大連理工情感詞典)所包含的情感詞大多數是普通詞語,然而彈幕文本普遍精簡,且包含大量網絡詞匯,存在口語化和不規范的問題,所以使用通用情感詞典往往不能覆蓋彈幕文本中的情感,無法對彈幕文本的情感極性進行判斷。例如,“被圈粉”“被種草”中的“圈粉”“種草”就表達了直接的正面情感,但由于“圈粉”“種草”這類網絡用語并非傳統情感詞,所以無法通過傳統詞典對彈幕情感極性進行判斷。基于此,本文在通用情感詞典的基礎上人工添加“圈粉”“種草”“有點尬”等彈幕中常見網絡用語,形成適用于彈幕情感分析的正向詞典、負向詞典和中性詞典。部分情感詞如表5所示。 Table 5 Emotional dictionary 3.4.2 情感標注 文本情感標注主要目標是把彈幕標注成正向負向或中性3種情感,常用的打標方式有逐一打標、抽樣打標和詞匯正負向標注。考慮到實驗數據樣本量大,本文選用了詞匯正負向標注的方法,使用3種詞典進行文檔標注,通過統計情感類別符號確定每條彈幕評論文本中各類情感詞的個數,再使用式(2)計算彈幕的情感極性。 (2) 其中,Sentiment表示正、負、中3種元情感分類下的情感極性;Q表示情感詞個數,Q正表示正向情感詞的個數,Q負表示負向情感詞的個數。當Sentiment=0時,表示彈幕文本不含有情感;當Sentiment=1時,表示彈幕文本含有正向情感;當Sentiment=2時,表示彈幕文本含有負向情感;當Sentiment=3時,表示彈幕文本含有中性情感。 3.4.3 卷積神經網絡建模 由于卷積神經網絡模型最早是用于圖像識別,其輸入是二維矩陣形式,因此在使用時需要將文本數據轉換為二維數據矩陣后再作為模型的輸入。假定數據中長度最長的彈幕包含a個詞,xi∈Rk是該條彈幕中的第i個詞對應的b維詞嵌入向量。卷積神經網絡的輸入為由a個b維向量組合而成的a×b的二維數據矩陣。對于長度小于a的樣本,本文使用word2vec向量化后使用零向量進行補充,對于長度大于a的樣本,(a-1)個詞采用word2vec向量表示,超出部分的所有詞向量的均值填充在第a位。通過這一方式,可以使不同詞在向量中均勻分布。本文的彈幕數據集中數據相對較短,因此將a設定為10,詞嵌入向量設為160維,即b=160。 Figure 3 Proposed convolutional neural network model 本文的CNN模型結構如圖3所示。卷積層都采用相同大小的卷積核來提取出文本的局部特征,考慮到彈幕文本的情感具有顯著的特征,往往只需要通過幾個特征詞語便能判斷其情感,因此池化層采用最大池化提取出每個特征圖中最具代表性的特征。重復卷積池化操作,最后通過全連接層進行特征降維,降維后的數據進入分類層完成對彈幕情感的預測。 卷積核ω∈Rh×m在長為h的窗內進行卷積操作,輸出的特征如式(3)所示: si=f(ω×αi:i+h-1+b) (3) 其中,b為偏置項,f(·)為激活函數。神經網絡中有多種常用的激活函數,例如sigmod函數、tanh函數和ReLU函數等。由于ReLU函數具有加快訓練收斂速度、防止梯度消失、增加數據矩陣稀疏性以減少過擬合的特點,因此本文采用ReLU函數作為激活函數,如式(4)所示: f(x)=max(0,x) (4) 本文首先對“機智的黨妹”視頻彈幕的“自然時間”屬性和“視頻時間”屬性進行分析:將“自然時間”屬性轉化為24小時制,刻畫彈幕在24小時內的分布情況;將“視頻時間”屬性轉化為所在視頻時間內的百分比,刻畫彈幕在視頻時間內的分布情況。 圖4是“機智的黨妹”彈幕“自然時間”24小時分布統計圖,橫坐標是24小時制時間,縱坐標是彈幕數量。由圖4可以看出,觀看黨妹視頻的人的數量從6點到13點呈上升趨勢,12點到13點達到一個局部峰值;從13點到16點有小幅度回落;16點到23點逐步增加,23點達到整體的峰值;23點到5點開始逐漸下降,5點的觀看人數最少。整體來看觀眾更偏好于晚上觀看視頻。 圖5是“機智的黨妹”彈幕“視頻時間”的分布統計圖,橫坐標是彈幕出現在視頻中的時間占此視頻的比值,縱坐標是彈幕數量。由圖5可以看出,視頻時間內彈幕數量波動明顯,視頻開頭的彈幕數量最多,結尾次之,視頻之間出現幾次小幅度彈幕峰值。由此可以分析,觀眾更偏愛在視頻開頭和結尾發送彈幕,視頻中會出現幾次彈幕“小高峰”。整體看“機智的黨妹”視頻的觀眾視頻觀看完整度高,粉絲粘性強,互動性高。 Figure 4 Natural time distribution of barrage Figure 5 Percentage distribution of barrage 由于彈幕詞語偏短,本文將實驗中卷積神經網絡模型中的步長設置為1,卷積核的大小設置為5*5,同時為了防止特征圖變小,padding設置為2。將最大池化設置為2*2以提取特征圖上的顯著特征。之后再進行相同的卷積池化操作,以完成對特征的進一步提取。最后經過全連接層降維后進入分類層得到最后的情感分類。考慮到彈幕情感分布很不均勻,所以實驗設置權重交叉熵為142,以此提高對負向和中性標簽的損失權重,為不平衡的數據分布做了一定的補償。 本文按8∶2的比例劃分為訓練集與預測集,共選擇了2 000份樣本數據作為訓練集。實驗結果顯示,該模型準確率達到94%。 4.3.1 主題結果 基于DTM模型,實驗數據主要被分為3個主題大類,每個主題大類下選擇概率最大的20個詞表示,具體如表6所示。主題1主要是關于視頻風格的內容,從主題詞分析結果看,視頻節奏歡快,輕松搞笑,易引起觀眾集體大笑;主題2主要是關于形象特征的內容,從主題詞分析結果看,“機智的黨妹”的形象既包含女性化形象,又包含男性化形象,人物形象方面可能存在變化;主題3主要與視頻內容相關,從主題詞分析結果看,觀眾不僅對“機智的黨妹”所使用的化妝品感興趣,還熱衷于討論視頻中出現的食物、衣服等物品,從這點可以看出觀眾對“機智的黨妹”的興趣不只局限于美妝方面。 Table 6 Topic results 4.3.2 細粒度主題詞演化 在不同時間,不同彈幕主題的主題詞會發生變化。通過細粒度主題關鍵詞分析,可以得到不同時期“機智的黨妹”視頻彈幕的主題詞變化。3個主題分類中,主題1沒有發生很大變化,說明視頻風格一直以輕松搞笑的風格為主。主題2和主題3的主題詞存在變化。 表7是主題1隨時間變化的細粒度主題詞演化。由結果可以看出,各個時間切片的主題詞相似,沒有明顯變化。每個時間段都出現了“哈哈哈”“笑”“可愛”等主題詞,這表明“機智的黨妹”視頻風格輕松愉悅,視頻中存在大量笑點。 表8是主題2隨時間變化的細粒度主題詞演化。由結果可以看出,不同時間切片的主題詞存在差異。在前8個時間切片中,觀眾對“機智的黨妹”的形象評價以“好看”“可愛”“妹子”“小姐姐”等女性化稱呼為主;在后2個時間切片中,主題詞開始出現“黨哥”“好帥”“老公”等稱呼,說明“機智的黨妹”的個人形象特征存在變化,前期以女性化為主,后期出現男性化特征。 表9是主題3隨時間變化的細粒度主題詞演化。由結果可以看出,不同時間切片的主題詞存在差異。雖然“機智的黨妹”是一個美妝類up主,但是觀眾彈幕所討論的話題并不局限于美妝領域。“好吃” “買”“同款”等詞說明粉絲在觀看黨妹視頻時,不僅會關注視頻中的美妝類產品,對于視頻中出現的食物等其他產品,粉絲也表現出強烈的興趣和購買意愿。“bgm”“表白”“新年快樂”“生日快樂”等詞說明觀眾不僅是把“機智的黨妹”當成一個屏幕里面的人,還把她當成一個樂于分享的朋友,粉絲忠誠度高。后期出現的“沾”“喜氣”“中獎率”等詞,說明“機智的黨妹”在視頻中增加了粉絲福利,而觀眾對于這種福利表現積極,參與度高,這也可能是其后期彈幕內容發生變化的原因。 Table 7 Topic words evolution of Topic 1 Table 8 Topic words evolution of Topic 2 Table 9 Topic words evolution of Topic 3 本文從“機智的黨妹”143個視頻中篩選出了24個含有廣告的視頻,使用CNN模型對這24個視頻的彈幕進行情感分析。表10是24個含有推廣視頻的整體情感占比均值,由表10可知,正向情感均值占比約為0.65,負向情感均值占比約為0.32,中性情感均值占比約為0.03。正向情感占大多數。 Table 10 Sentiment analysis results 圖6是24個含有推廣視頻的彈幕情感極性分析的百分比堆積柱形圖。由圖6可以明顯看出,觀眾對于視頻中含有推廣的態度,持正向情感多于持負向情感,說明觀眾對于視頻中含有產品推廣的行為,大部分是理解與支持的。中性情感占少數。 Figure 6 Emotional polarity stacked bar chart 本文以社交媒體B站為研究平臺,利用彈幕這一用戶生成內容,以美妝類KOL“機智的黨妹”為例,對其視頻彈幕進行動態主題分析和情感分析,從而幫助品牌從文本挖掘視角對KOL進行全面了解,為品牌找到合適的KOL提供數據參考。 從分析結果看,彈幕的“自然時間”和“視頻時間”可以很好地刻畫觀眾的觀看行為特征,為廣告主應該在何時投放廣告提供參考;動態主題分析既可以從整體刻畫觀眾的彈幕主題,也可以從細粒度刻畫不同時間的主題詞演化,幫助廣告主具體了解不同KOL的粉絲群體特征,更加精準地進行廣告投放;情感分析可以分析觀眾對于KOL合作推廣的態度,避免因粉絲抵觸推廣行為而降低品牌好感度。 因為彈幕文本含有大量網絡語言,傳統文本挖掘方法不能完全適用對彈幕的文本分析,所以之后的工作可以從以下方面改進:首先構建更為專業的彈幕領域的分詞詞典,以便對彈幕文本進行更好的分詞處理,為之后的分析提供更好的數據支持。其次,構建更為專業的彈幕領域的情感詞典。彈幕文本的用語不規范導致同一個詞在不同語境中有不同的情感極性,這就需要更為細分的情感詞典為情感分析提供參考。此外,彈幕數據還可以作為輿情分析的數據源,不僅能幫助了解觀眾在觀看視頻時討論的主題變化,還能監控觀眾的情感變化,對KOL和品牌雙方都有借鑒意義。3.4 情感分析

4 實驗與結果分析
4.1 實驗數據描述
4.2 實驗設置
4.3 動態主題分析

4.4 情感分析

5 結束語
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中國生殖健康(2020年5期)2021-01-18 02:59:48
北極光(2019年12期)2020-01-18 06:22:10
小太陽畫報(2019年10期)2019-11-04 02:57:59
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:24
電子制作(2018年18期)2018-11-14 01:48:06
中國生殖健康(2018年5期)2018-11-06 07:15:40
山東工業技術(2016年15期)2016-12-01 05:31:22
小學教學參考(2015年20期)2016-01-15 08:44:38
