基于RELM的時間序列數(shù)據(jù)加權集成分類方法*
2022-12-22 11:32:56趙林鎖丁琳琳宋寶燕
計算機工程與科學 2022年3期
趙林鎖,陳 澤,丁琳琳,宋寶燕
(1.遼寧工程技術大學力學與工程學院,遼寧 阜新 123000;2.遼寧大學信息學院,遼寧 沈陽 110036)
1 引言
時間序列數(shù)據(jù)通常是指一系列帶有時間間隔的實值型數(shù)據(jù)[1]。它的特點是不同時刻數(shù)據(jù)之間存在著某種關聯(lián),這種特性反映了數(shù)據(jù)在隨著時間變化的過程中存在著某種規(guī)律[2]。時間序列數(shù)據(jù)廣泛應用于災害監(jiān)測[3]、金融監(jiān)管[4]和醫(yī)療[5]等領域。時間序列數(shù)據(jù)之間的類別差異具體體現(xiàn)在其數(shù)據(jù)的傳播頻率不同、數(shù)據(jù)幅值大小差別以及數(shù)據(jù)點間的時間間隔不同等方面。例如,對于礦山監(jiān)測領域所產(chǎn)生的時間序列數(shù)據(jù)來說,微震監(jiān)測系統(tǒng)中的傳感器接收到微震波,均會產(chǎn)生微震時間序列數(shù)據(jù),由于其傳播速度不同,產(chǎn)生的幅值大小不同,導致每次發(fā)生的微震事件類型不同,造成的危害程度也不同,后期救援的方式方法亦不同[6];對于醫(yī)療領域的心電時間序列數(shù)據(jù)來說,醫(yī)療心電信號也是一種時間序列數(shù)據(jù),醫(yī)生會依據(jù)心電信號的頻率大小和幅值高低來區(qū)分心電信號的類別,根據(jù)不同類型的心電信號給出不同的診治方案[7]。因此,有效分類時間序列數(shù)據(jù)具有極其重要的意義。
然而,現(xiàn)實應用中的時間序列數(shù)據(jù)常常伴有大量的環(huán)境噪聲[8]。例如,礦山微震時間序列數(shù)據(jù)中,由于礦區(qū)環(huán)境復雜,傳感器產(chǎn)生的時間序列數(shù)據(jù)常常伴有大型機械作業(yè)、水流等環(huán)境噪聲;心電時間序列數(shù)據(jù)中,大量患者的心電時間序列數(shù)據(jù)通常會受到外來環(huán)境因素干擾,產(chǎn)生環(huán)境背景噪聲。噪聲引起對應的時間序列數(shù)據(jù)出現(xiàn)偏差,極大地改變了時間序列數(shù)據(jù)的真實形態(tài),在一定程度上影響了時間序列數(shù)據(jù)的分類精度。因此,在對此類時間序列數(shù)據(jù)分類之前,需要對時間序列數(shù)據(jù)進行降噪預處理。
由于時間序列數(shù)據(jù)通常具有維度高、數(shù)據(jù)量較大的特性,許多學者對其分類方法進行了深入研究。Luo等[9]提出了一種基于SVM(Support Vector Machine)的重構訓練集RTS-SVM(Reconstructed Train Set-Support Vector Machine)方法來實現(xiàn)時間序列數(shù)據(jù)分類,并采用了輪盤賭協(xié)同進化算法R-CC(Roulette Cooperative Coevolution)優(yōu)化RTS-SVM的參數(shù)。但是,該方法沒有充分考慮到關鍵支持向量,分類性能仍有待提升。Yang等[10]提出了一種卷積神經(jīng)網(wǎng)絡CNN(Convolutional Neural Network)和遞歸神經(jīng)網(wǎng)絡RNN(Recurrent Neural Network)相結合的分類方法DPCRCN(Dual Path CNN RNN Cascade Network),首先利用CNN進行數(shù)據(jù)特征提取,再使用RNN學習特征和輸出映射,但其中的數(shù)據(jù)融合方法仍然存在問題,且訓練模型時間較長。Li等[11]提出了一種基于極限學習機ELM(Extreme Learning Machine)和自適應集成技術的時間序列預測方法,并在大量的時間序列數(shù)據(jù)集上進行了驗證,算法的泛化性能還有待提升。綜上,使用機器學習算法對時間序列數(shù)據(jù)分類還存在著預測精度較低、泛化性能較差的缺陷。
本文以正則化極限學習機RELM(Regularized Extreme Learning Machine)作為基分類器,提出了一種基于RELM的時間序列數(shù)據(jù)加權集成分類方法E-PSO-RELM(Ensemble-Particle Swarm Optimization-Regularized Extreme Learning Machine)。在數(shù)據(jù)挖掘領域的UCR時間序列數(shù)據(jù)開源數(shù)據(jù)集[12]上進行了仿真實驗,實驗結果表明,相比于其他方法,本文方法能夠有效提高時間序列數(shù)據(jù)的預測精度且提升了泛化性能。本文主要貢獻如下所示:
(1)針對時間序列數(shù)據(jù)中所含有的噪聲,引入了小波包變換WPT(Wavelet Packet Transform)方法,基于其較高的時間序列數(shù)據(jù)時頻分辨率,通過閾值函數(shù)處理小波包系數(shù),進而去除噪聲。即將時間序列數(shù)據(jù)通過WPT方法分解成小波包系數(shù),并對小波包系數(shù)進行閾值量化處理,再對其重構得到去噪后的時間序列數(shù)據(jù)。
(2)針對去噪后的時間序列數(shù)據(jù)分類,本文提出了一種有效選取RELM基分類器的方法。通過訓練RELM的隱藏層節(jié)點的數(shù)量,計算得到不同隱藏層節(jié)點數(shù)量下的預測標簽,并選出分類精度最高的隱藏層節(jié)點數(shù)量所對應的RELM作為基分類器。
(3)針對時間序列數(shù)據(jù)維度高、數(shù)據(jù)量較大,導致單個基分類器的預測精度較低、泛化性能較差的問題,本文提出了一種基于粒子群優(yōu)化PSO(Particle Swarm Optimization)算法的RELM基分類器權值優(yōu)化方法。考慮到PSO算法結構簡單、迭代速度快的特點,同時考慮到各個RELM基分類器之間的信息互補性,通過PSO算法不斷優(yōu)化基分類器的權值,對時間序列數(shù)據(jù)進行加權集成分類。
2 相關工作
近年來,許多學者對時間序列數(shù)據(jù)進行了廣泛深入的研究[13]。在時間序列數(shù)據(jù)分類的問題中,極限學習機(ELM)作為一種單隱層前饋神經(jīng)網(wǎng)絡機器學習算法,其具有算法結構簡單、泛化性能好的特點,往往只需設置隱藏層節(jié)點的數(shù)量即可求得最優(yōu)唯一解[14],ELM憑借這些特點被廣泛地應用在關于時間序列數(shù)據(jù)的處理問題中[15,16]。Yan等[17]提出了一種基于卡爾曼濾波器與ELM相結合的方法CS-DELM(Cost Sensitive-Dissimilar ELM)對時間序列數(shù)據(jù)進行了分類研究,但該方法在處理時間序列數(shù)據(jù)時仍然存在不穩(wěn)定性,泛化性能有待提升。Xu等[18]提出了一種基于MOPSO-ELM(Multi Objectives Particle Swarm Optimization-ELM)的分類方法,利用改進的粒子群優(yōu)化算法(PSO)對ELM的參數(shù)進行了優(yōu)化,提高了預測精度,但算法的復雜度較高,訓練時間較長。Fan等[19]提出了一種基于極限學習機(ELM)的改進分層集成結構EILEA(ELM-Improved Layered Ensemble Architecture)對時間序列數(shù)據(jù)進行了預測,該方法提升了平均預測精度和運行效率,但沒有對ELM的隱藏層節(jié)點數(shù)量進行優(yōu)化,泛化性能較差。
綜上,在使用單分類器對時間序列數(shù)據(jù)進行分類時會出現(xiàn)分類結果不穩(wěn)定、泛化性能較差的問題。集成分類方法往往能夠有效解決這一問題。集成分類方法通常按照某種規(guī)則對性能較差的弱分類器進行組合,能夠有效提高分類性能[20]。但是,在實際應用中,若所需的基分類器數(shù)量較少或是重用常見分類器的一些經(jīng)驗時,研究者往往會選擇具有一定分類性能的強分類器作為基分類器來提升分類性能,并且通過對分類器的權值進行優(yōu)化,能夠充分利用分類器間的信息互補性,并給每個基分類器賦予不同權值來彌補分類器之間的差異。Liu等[21]提出了一種基于ELM的加權集成分類方法,針對數(shù)據(jù)的不平衡現(xiàn)象,結合樣本的分布引入了平衡因子,并通過加權集成方法提升了方法的穩(wěn)定性。Feng等[22]提出了一種基于馬爾科夫鏈的動態(tài)加權集成信用評分方法,根據(jù)每個基分類器分類性能的變化,調整基分類器的權重,并驗證了方法的預測精度和效率。
在集成分類方法中的基分類器選擇方面,傳統(tǒng)的ELM分類方法中的輸出權值矩陣是由隱含層矩陣的廣義逆所得出的,導致傳統(tǒng)的ELM分類方法仍然存在過擬合現(xiàn)象,降低了分類精度和泛化性能;針對ELM的這種缺陷,RELM通過引入正則化因子,并同時考慮了經(jīng)驗風險和結構風險,構建了新的目標函數(shù);相對于ELM能夠有效地提高分類精度和泛化性能[23]。
因此,本文針對現(xiàn)有時間序列數(shù)據(jù)分類方法的不足,為提高分類方法的預測精度、泛化性能,以及考慮到集成分類方法的良好特性,以RELM作為基分類器,提出了一種基于RELM的時間序列數(shù)據(jù)加權集成分類方法。
3 時間序列數(shù)據(jù)去噪
時間序列數(shù)據(jù)常常伴有大量的環(huán)境噪聲,降低了分類精度,影響了時間序列數(shù)據(jù)的后續(xù)處理,因此對時間序列數(shù)據(jù)進行去噪是非常必要的。考慮到小波包方法的多頻率分析特性,本文使用基于小波包的去噪方法,通過對時間序列數(shù)據(jù)的頻帶多尺度劃分獲取小波包系數(shù),然后對高頻和低頻小波包系數(shù)進行閾值量化處理,并通過對小波包系數(shù)重構,得到去噪后的時間序列數(shù)據(jù)。
3.1 小波包系數(shù)的獲取
小波包系數(shù)的獲取是指對時間序列數(shù)據(jù)逐層分解,并將分解后得到的小波包系數(shù)進行閾值量化處理,以優(yōu)化小波包系數(shù),從而達到去噪效果的過程。圖1所示為對帶有環(huán)境噪聲的時間序列數(shù)據(jù)X(t)進行3層小波包系數(shù)分解,其中P[i,j]表示分解得到的小波包系數(shù)。
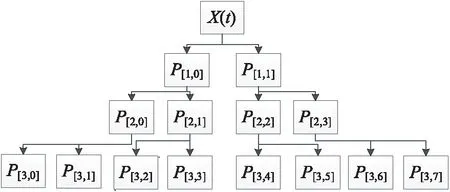
Figure 1 Wavelet packet coefficient decomposition
在圖1所示的小波包分解過程中,首先對時間序列數(shù)據(jù)X(t)分解為第1層小波包系數(shù)P[1,0]和P[1,1],分解公式如式(1)所示:
(1)
其中,將原始時間序列數(shù)據(jù)X(t)分別通過低通濾波器h和高通濾波器g(其中k,l表示濾波器系數(shù),z表示分解總層數(shù))分解為第1層小波包系數(shù)P[1,0]和P[1,1],P[1,0]表示低頻小波包系數(shù),P[1,1]表示高頻小波包系數(shù)。并且在接下來的每一次分解過程中均會將每一組小波系數(shù)P[i,j]分解成2個頻率子帶的小波包系數(shù),得到低頻小波包系數(shù)P[i+1,2j]與高頻小波包系數(shù)P[i+1,2j+1],每組小波包系數(shù)分解公式如式(2)所示:
(2)
其中P[i,j]表示第i層第j組小波包系數(shù)。
經(jīng)過小波包分解后,時間序列數(shù)據(jù)與小波包的系數(shù)關系也可近似表示為式(3)所示:
X(t)=P[1,0]+P[1,1]=
P[2,0]+P[2,1]+P[2,2]+P[2,3]=
P[3,0]+P[3,1]+P[3,2]+P[3,3]+
P[3,4]+P[3,5]+P[3,6]+P[3,7]
(3)
接下來,根據(jù)軟閾值函數(shù)處理原則[24],對最后一層的每組小波包系數(shù)P[i,j]={P[i,j](1),P[i,j](2),…,P[i,j](n)}進行閾值量化處理,n表示小波包系數(shù)的個數(shù),閾值處理函數(shù)如式(4)所示:
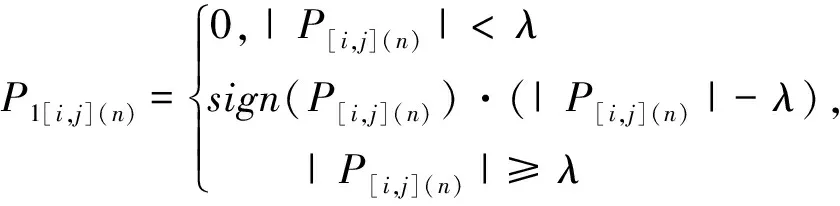
(4)
其中,λ表示設定的閾值,P[i,j](n)表示需要被優(yōu)化的小波包系數(shù),P1[i,j](n)表示優(yōu)化后的小波包系數(shù),sign(·)表示階躍函數(shù)。
3.2 小波包系數(shù)的重構
小波包系數(shù)的重構是指對最后一層使用閾值函數(shù)處理后的小波包系數(shù)逐層重構得到去噪后的時間序列數(shù)據(jù)的過程,小波包系數(shù)重構的過程如圖2所示,其中Y(t)表示去噪后的時間序列數(shù)據(jù),P1[i,j]表示優(yōu)化后的小波包系數(shù)。
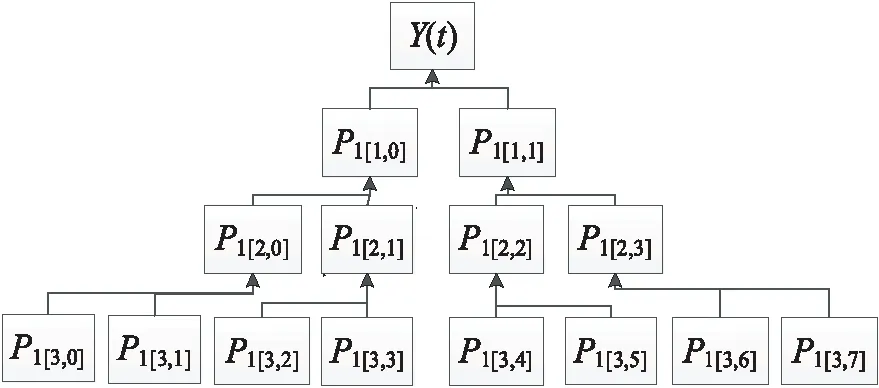
Figure 2 Reconstruction of wavelet packet coefficient
在每一層中的小波包系數(shù)重構公式如式(5)所示:
(5)
其中,h和g分別表示為低通濾波器和高通濾波器。最后由第1層小波包系數(shù)重構得到時間序列數(shù)據(jù)Y(t)。
在本節(jié)中經(jīng)過小波包去噪后所得到的時間序列數(shù)據(jù)Y(t),再通過下一節(jié)的加權集成分類方法進行分類。
4 時間序列數(shù)據(jù)的加權集成分類
針對去噪后的時間序列數(shù)據(jù),本文提出了一種訓練RELM隱藏層節(jié)點數(shù)量的方法,可有效選取基分類器。針對時間序列數(shù)據(jù)的數(shù)據(jù)量較大、數(shù)據(jù)維度較高的特點,以及在實際應用中使用單個基分類器分類時較易出現(xiàn)不穩(wěn)定性,導致分類器預測精度不高、泛化性能較差的缺陷,本文提出了一種基于PSO算法的RELM基分類器權值優(yōu)化方法,結合PSO算法的特點,通過PSO對基分類器進行權值優(yōu)化,實現(xiàn)對時間序列數(shù)據(jù)的加權集成分類。
4.1 基分類器選取
RELM是一種結構簡單、計算迅速的單隱層前饋神經(jīng)網(wǎng)絡學習算法。在集成分類方法中,不同的隱藏層節(jié)點數(shù)量對應著不同性能的RELM基分類器。首先計算各個基分類器的預測標簽,再選取較高分類精度所對應的隱藏層節(jié)點數(shù)量,從而確定RELM基分類器。
(1)預測標簽的計算。
針對去噪后的時間序列數(shù)據(jù),初始化多個RELM基分類器,并以去噪后的時間序列數(shù)據(jù)作為輸入,來計算RELM基分類器的預測標簽。
其過程可表述為將去噪后的時間序列數(shù)據(jù)輸入到各個初始化的RELM中,并以RELM的隱藏層節(jié)點數(shù)量為循環(huán)條件,計算每個隱藏層節(jié)點數(shù)量下的預測集標簽。具體過程為:假設去噪后的時間序列數(shù)據(jù)為Y={y1,y2,…,yk},數(shù)據(jù)的類別標簽為T={1,2,…,a},其中a表示標簽個數(shù),首先將數(shù)據(jù)分為訓練集數(shù)據(jù)Y1和預測集數(shù)據(jù)Y2,以RELM的隱藏層節(jié)點數(shù)量J做為循環(huán)條件,將訓練集數(shù)據(jù)Y1輸入到RELM,并計算當前隱藏層節(jié)點數(shù)量為J時的輸出權值矩陣LW,將預測集數(shù)據(jù)Y2輸入到RELM中,通過LW得到當前隱藏層節(jié)點數(shù)量下的預測集標簽T′(J)。
(2)隱藏層節(jié)點數(shù)量的獲取。
得到預測集標簽后,計算不同隱藏層節(jié)點數(shù)量下的分類精度,選取分類精度較高時的隱藏層節(jié)點數(shù)量,作為所需的RELM基分類器的隱藏層節(jié)點數(shù)量。
其具體過程為:通過(1)中所得到的預測集標簽T′(J),根據(jù)預測標簽的結果計算當隱藏層節(jié)點數(shù)量為J時的分類精度acc(J),并將acc(J)存儲到列表S中。再根據(jù)acc(J)選取集成分類方法中的分類器。其具體做法為:令集成分類中的基分類器個數(shù)為q,隨著隱藏層節(jié)點數(shù)量J的不斷增加,分類精度會趨于穩(wěn)定,但過多的隱藏層節(jié)點數(shù)量會使運行效率變低,則需計算q個分類精度的平均值。由于在訓練初期,精度平均值相對較低,而隨著隱藏層節(jié)點數(shù)量J的增加,其平均值也會逐漸變大,為了避免隱藏層節(jié)點數(shù)量J較大,則需在平均值處于相對較高且趨于穩(wěn)定的初期時,獲取其對應的隱藏層節(jié)點數(shù)量值,從而能夠得到對應的基分類器數(shù)量。其中,為了有效識別平均值何時保持穩(wěn)定,在訓練過程中設定閾值λ,若在相鄰w個精度平均值中任意2個值均小于或等于λ,則選取當前條件下的第1個平均值所對應的隱藏層節(jié)點數(shù)量J。
(3)算法描述。
確定了隱藏層節(jié)點數(shù)量J,也就是確定了所需的RELM基分類器。RELM基分類器選取方法如算法1所示。輸入去噪后的時間序列數(shù)據(jù)Y,通過訓練隱藏層節(jié)點數(shù)量J的方法得到預測集標簽;然后根據(jù)預測標簽計算隱藏層節(jié)點數(shù)量J所對應的分類精度acc(J),并通過acc(J)來選取所需的基分類器。其中,g表示調諧參數(shù),G(·)表示激活函數(shù)。
算法1基分類器選取方法
Input:數(shù)據(jù)集Y={y1,y2,…,yk},數(shù)據(jù)類別T={1,2,…,a},隱藏層節(jié)點數(shù)量取值范圍為[m,v],c為步長。/*m表示初始值,v表示最大值*/
Output:隱藏層節(jié)點數(shù)量J和對應分類精度acc(J)。
Initialization:訓練集數(shù)據(jù)被隨機分為2組向量,命名為Y1 和Y2;創(chuàng)建S列表,SJ存儲J及其對應的分類精度acc(J)。
//獲得預測數(shù)據(jù)標簽T′(J)
1forJ=mtovdo
2IW,B←Y1;
3H=G(IW*Y1+B);
4LW=(H′H+gI)H′Y1;
5IW1,B1←Y2;
6H1=G(IW1*Y2+B1);
7T′(J)←Softmax((H′1*LW)′);
8endfor
//計算分類精度
9forJ=m:c:vdo
10sum=0;
11while(T(J)=T′(J)):
12sum++;
13endwhile
14v=T(J).length;
15acc(J)=sum/n;
16S←J,acc(J);
17endfor
//選取多個基分類器
18t=1;
19whilet≤5:
/*計算相鄰5個基分類器的分類精度平均值avg_acc*/
20ifavg_acc≤λ
21t=t+1;
22elseJ=J+50;
23endwhile
在時間復雜度方面,算法1由3個循環(huán)組成,其平均時間復雜度為O(n),最好和最壞情況下的時間復雜度也為O(n)。在空間復雜度方面,算法1的存儲空間會隨著RELM的隱藏層節(jié)點數(shù)量的變化而變化,因此空間復雜度為S(n)。
4.2 基于PSO的基分類器權值優(yōu)化
在得到RELM基分類器后,為每個基分類器賦予初始權值,再通過PSO算法不斷優(yōu)化基分類器的權值,對時間序列數(shù)據(jù)進行加權集成分類。
(1)基分類器的權值優(yōu)化。
針對時間序列數(shù)據(jù)維度高、數(shù)據(jù)量較大的特性,在使用單個分類器分類時仍然存在預測精度低、泛化性能較差的問題,并考慮到PSO的特點以及各個RELM基分類器之間的信息互補性,本節(jié)給出了一種基于PSO的基分類器權值優(yōu)化方法。
其具體過程為:以基分類器的權值作為PSO的粒子,以預測精度作為PSO的適應度函數(shù)值,隨著迭代次數(shù)的增加不斷優(yōu)化基分類器的權值。假設輸入樣本集數(shù)據(jù)Y,初始化種群規(guī)模為K,即共有K個粒子Xi和粒子速度Vi,其中,Xi=[xi1,xi2,…,xin],Vi=[vi1,vi2,…,vin],i∈{1,2,…,K},xij存儲的值為第i個粒子的第j個基分類器的權值aj,Vi是元素值為[0,1]的隨機矩陣。對每次迭代中的每個粒子計算其預測結果T;并求出每個粒子的適應度函數(shù)值,即分類精度acc={acc(1),acc(2),…,acc(t),…,acc(K)},其中acc(i)表示第i個粒子的適應度函數(shù)值。根據(jù)所有粒子的適應度函數(shù)值,得到每個粒子Xi的全局最優(yōu)值gbesti和每個粒子的個體最優(yōu)值pbesti,其中i∈{1,2,…,K}。通過PSO的粒子更新公式來優(yōu)化每個粒子的下一次迭代的粒子和速度。隨著迭代次數(shù)的增加,當?shù)螖?shù)達到最大值時,得到最優(yōu)基分類器權值a。
(2)加權集成分類。
得到基分類器優(yōu)化的權值后,接下來對時間序列數(shù)據(jù)進行加權集成分類:
通過上一節(jié)中所得到的每個分類器的權值ai,則每個樣本Xk被分到j類中的概率值為xjk,計算公式如式(6)所示:
(6)
其中,yji表示第i個分類器將樣本分類到j類的概率值,n表示分類器個數(shù)。
再根據(jù)加權分類器的加權投票方法選出最大值所對應的類別作為Xk的預測分類結果j,如式(7)所示。
Xjk=max{x1k,x2k,x3k,…,xmk}
(7)
(3)方法描述。
優(yōu)化了基分類器的權值后,對時間序列數(shù)據(jù)進行加權集成分類,算法2為本文提出的基于RELM的加權集成分類方法(E-PSO-RELM)。其中將分類器的權值作為PSO算法的粒子,通過式(6)和式(7)來計算每次迭代過程中的預測結果,并計算出預測精度作為PSO的適應度函數(shù)值,通過迭代次數(shù)的增加來優(yōu)化基分類器的權值,得到優(yōu)化的權值后再對數(shù)據(jù)集進行集成分類。
算法2基于RELM的加權集成分類方法(E-PSO-RELM)
Input:數(shù)據(jù)集Y,分類器個數(shù)n,迭代次數(shù)最大值Tmax; PSO相關參數(shù):慣性權重ω,學習因子c1,c2,種群數(shù)量K。
Output:基分類器的權值(a1,a2,a3,…,an)。
Initialization:隨機初始化K個粒子Xi=[xi1,xi2,…,xin],i∈{1,2,…,K};n表示分類器的數(shù)量;xij表示第j個 基分類器的權重ai,和K個種群規(guī)模的粒子速度值Vi=[vi1,vi2,…,vin],i∈{1,2,…,K}。
1whilet≤Tmaxdo:
//計算預測結果acc=[acc1,acc2,…,accK];
2fori=1 toKdo:
3fora=1 tomdo:
5T′(a)←argmax{x1i,x2i,x3i,…,xmi};
6endfor
7acc(i)←(ACC{T(i)′-T(i)};
8gbesti,pbesti←Find(acc);
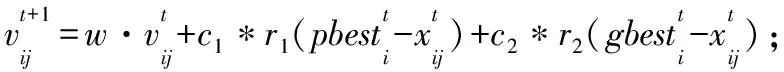
11endfor
12t=t+1;
13endwhile
在該算法中,根據(jù)設定的PSO種群規(guī)模K值和設定的分類器數(shù)量n,其平均時間復雜度為O(nK);并且由于算法2沒有額外的存儲空間開銷,其空間復雜度為S(1)。
5 實驗評估
為了驗證本文方法的有效性,將其與目前常用的3種分類方法進行了對比。實驗的硬件配置為Windows 10系統(tǒng)主機、16 GB內存、Intel(R)Core i5-9300H CPU 2.40 GHz以及64位操作系統(tǒng)。分類算法均在Matlab 2018a上實現(xiàn)。
5.1 數(shù)據(jù)集介紹
本文實驗所選取的所有數(shù)據(jù)來自于時間序列挖掘領域的開源數(shù)據(jù)集資源UCR時間序列數(shù)據(jù)集[12]。由于UCR中數(shù)據(jù)集的數(shù)量較多,且數(shù)據(jù)集的數(shù)據(jù)維度具有較大差異,因此本文根據(jù)UCR數(shù)據(jù)集的數(shù)據(jù)特征,選取了具有代表性的16組數(shù)據(jù)集作為實驗數(shù)據(jù)集。實驗中所用到的數(shù)據(jù)集的具體信息如表1所示。
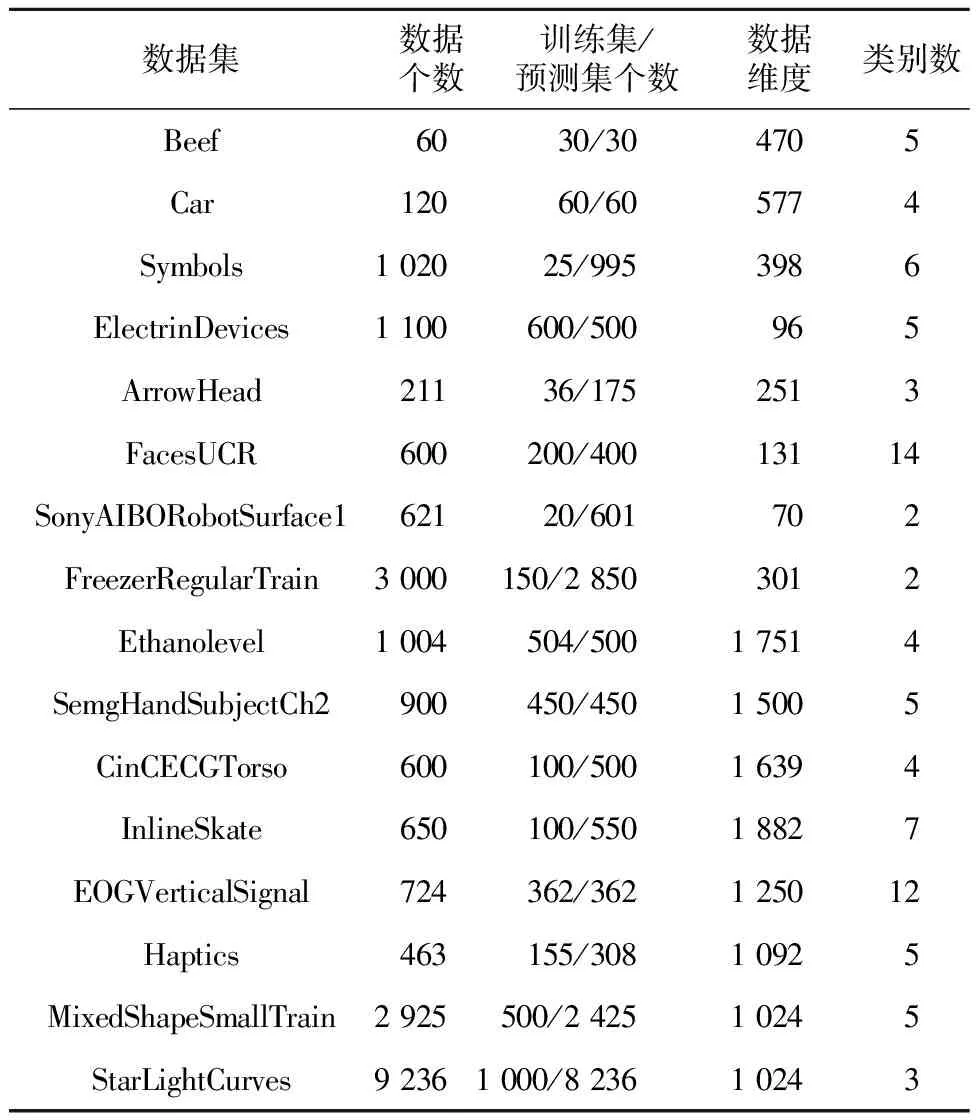
Table 1 Introduction of data sets
5.2 實驗結果與分析
(1)基分類器選取實驗。
選擇5個RELM基分類器對本文集成分類方法進行集成分類實驗。在本節(jié)中,通過本文提出的訓練隱藏層節(jié)點數(shù)量的方法來確定每個數(shù)據(jù)集的RELM分類器數(shù)量;針對數(shù)據(jù)維度的不同,將16個數(shù)據(jù)集分為2組進行對比實驗。
圖3所示為訓練RELM隱藏層節(jié)點數(shù)量實驗結果,其中由于部分數(shù)據(jù)集的數(shù)據(jù)維度較高,所選取的隱藏層節(jié)點數(shù)量區(qū)間,即算法1中的[m,v],取值為[100,2000],如圖3b表示;其他數(shù)據(jù)集的隱藏層節(jié)點數(shù)量區(qū)間選擇為[100,1200],如圖3a表示。由于隱藏層節(jié)點數(shù)量相近時,通常得到的精度差別較小,因此,在實驗中,以50為步長依次選取隱藏層節(jié)點數(shù),這里的50為經(jīng)驗值,同時為算法1中的c值。
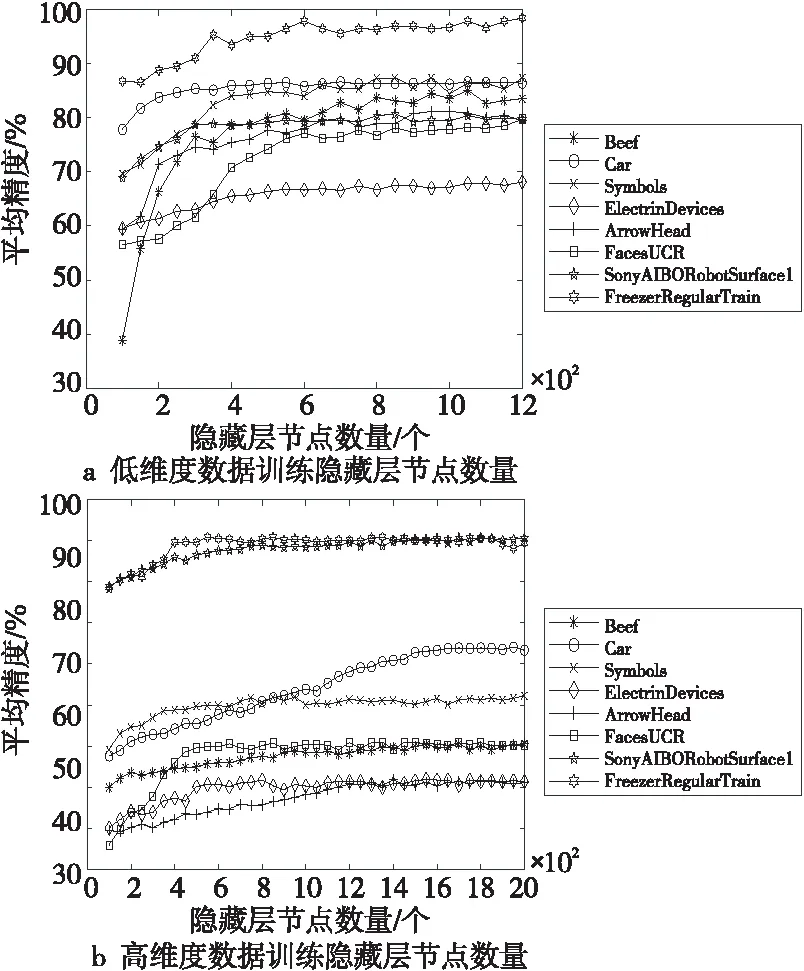
Figure 3 Number of hidden layer nodes in training RELM
在進行加權集成分類實驗之前,先通過4.1節(jié)中提出的方法進行了訓練隱藏層節(jié)點數(shù)量實驗來確定每個數(shù)據(jù)集的基分類器數(shù)量;每個數(shù)據(jù)集上分別進行了20次實驗,選取平均分類精度作為實驗的評價標準。從圖3中可以看出,不同的樣本的平均分類精度以及所選取的隱藏層節(jié)點數(shù)量是不同的,并且平均精度的值在初始階段均處于上升趨勢,但數(shù)據(jù)集的維度和大小不同,得到的精度值大小也有差異,最終均會處于一個相對穩(wěn)定的狀態(tài)。根據(jù)4.1節(jié)中的方法,在保證分類精度相對穩(wěn)定時即開始選取隱藏層節(jié)點數(shù)量,為能夠有效地選取隱藏層節(jié)點數(shù)量,令算法1中的閾值λ取值為[0.35,0.5],即選取多個平均分類精度差值在[0.35,0.5]內的值,并將該值對應的隱藏層節(jié)點數(shù)作為實驗所需的隱藏層節(jié)點數(shù),此區(qū)間值為本次實驗的經(jīng)驗值。根據(jù)圖3中的信息,對數(shù)據(jù)集的基分類器進行了選取,每個數(shù)據(jù)集選取的基分類器所對應的隱藏層節(jié)點數(shù)量信息如表2所示。
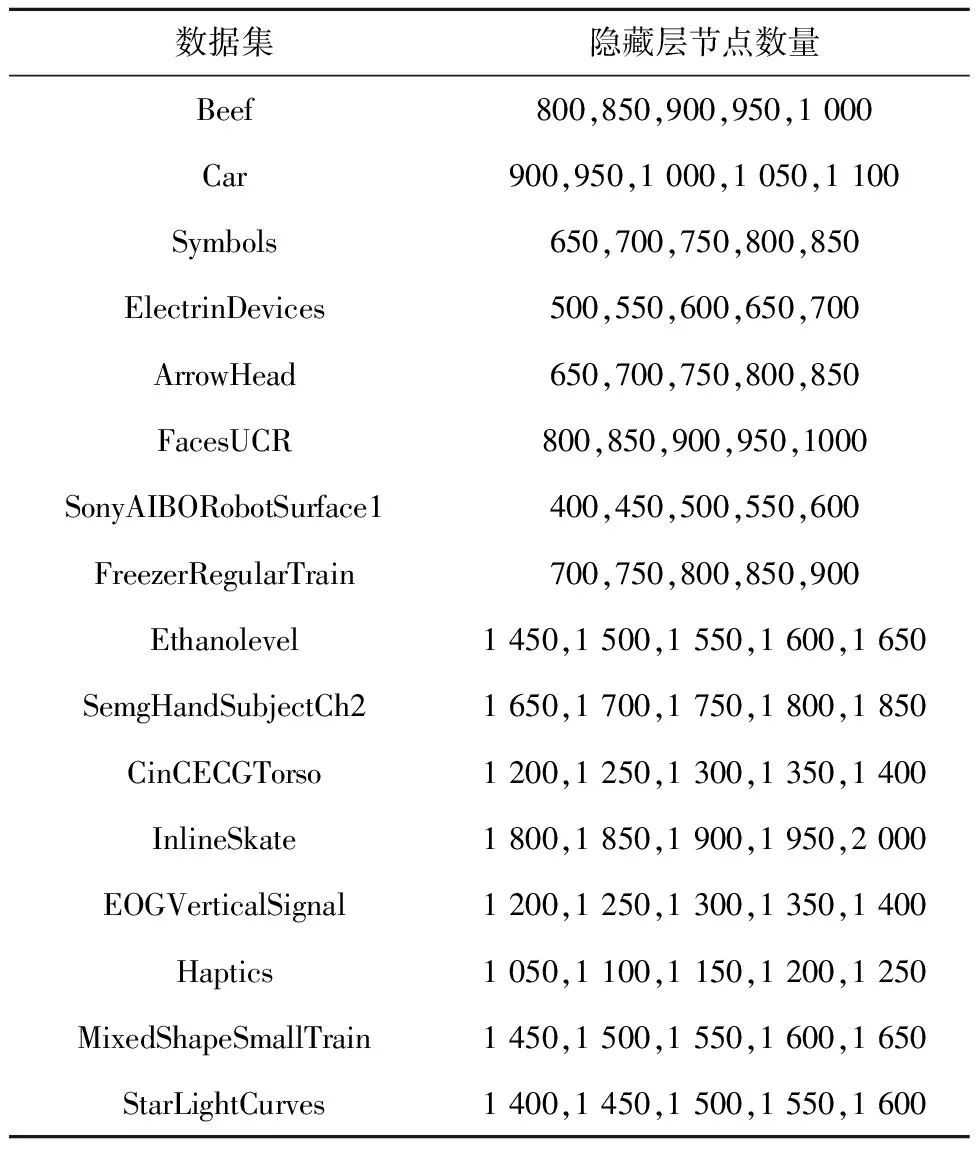
Table 2 Classifier selection
(2)加權集成分類實驗。
在通過上述方法得到5個基分類器后,為了確保分類器之間具有一定的區(qū)分性,為每個分類器均賦予不同的激活函數(shù)sig(x),目前被廣泛使用的激活函數(shù)有sigmoid函數(shù)、ReLU(Rectified Linear Units)函數(shù)、Swish函數(shù)、sin函數(shù)和RBF(Radial Basis Function)函數(shù)[13]。
為了更好地驗證本文方法的分類性能,選取ELM、E-ELM(Ensemble-ELM)、Vote-ELM、MGEoT(Multi Granularity Ensemble classification method)[25]、PCA-LSTM(Principal Component Analysis-Long Short Time Memory)[26]5種方法進行對比實驗,各方法的具體介紹如表3所示。
在進行實驗之前,首先對時間序列數(shù)據(jù)進行WPT去噪處理,然后每次實驗均進行20次,取平均預測精度作為評價標準;并對本文提出方法中的PSO參數(shù)進行初始化,PSO的迭代次數(shù)為200次,學習因子c1和c2分別為0.8和0.2,慣性權重ω為0.5。并將本文提出的方法中的基分類器的初始權值ai均設為1。

Table 3 Introduction to classification methods
方法的泛化性能是指通過訓練樣本數(shù)據(jù)訓練出來的模型,不僅能夠對原有的訓練集數(shù)據(jù)進行準確的分類,同樣能夠對預測集數(shù)據(jù)進行準確分類。為驗證本文方法的泛化性能,本文選取預測集數(shù)據(jù)分類結果的平均分類精度作為評價標準。圖4所示為不同分類方法對預測集數(shù)據(jù)分類結果的平均分類精度比較。
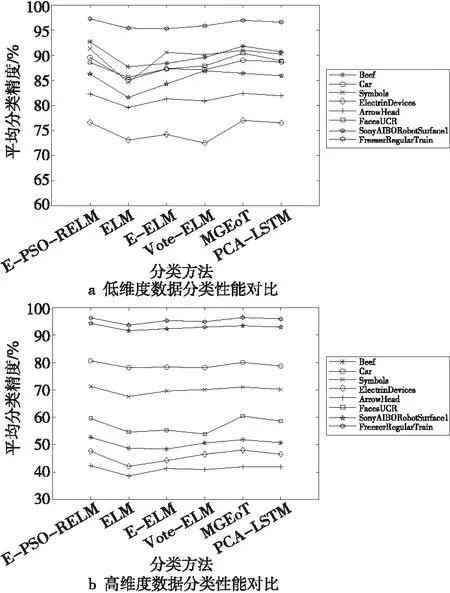
Figure 4 Comparison of average classification accuracy of methods
從圖4中可發(fā)現(xiàn),對比單個分類器,集成分類方法均有較好的效果。從圖4a中可發(fā)現(xiàn),在Symbols和SonyAIBORobotSurface1這2個低維度數(shù)據(jù)集上,由于訓練集和測試集的數(shù)據(jù)個數(shù)差別較大,在單個分類器分類時由于訓練數(shù)據(jù)較少不能夠較好地得到訓練模型,導致分類精度較低,泛化性能較差,而通過實驗表明,集成分類方法較好地彌補了這一缺陷。在實驗結果中,利用不同的分類方法處理不同的數(shù)據(jù)集所得到的分類結果均不同,對于低維度的數(shù)據(jù)集,集成分類的優(yōu)化效果相比于其他4種高維度數(shù)據(jù)不夠明顯,這體現(xiàn)了集成分類能夠很好地彌補分類器在處理高維度數(shù)據(jù)時所存在的差異性。通過圖4也能發(fā)現(xiàn),本文提出的對權值優(yōu)化的E-PSO-RELM相比其他2種不對權值優(yōu)化的方法E-ELM和Vote-ELM的分類性能均要好一些,并且具有與MGEoT和PCA-LSTM這2種方法相近的分類性能。并且從圖4b中可發(fā)現(xiàn),在MixedShapeSmallTrain和StarLightCurves這3個數(shù)據(jù)集上,對比于其他高維度數(shù)據(jù)集,本文方法得到的分類結果均較良好,這是由于雖然這2個數(shù)據(jù)集的維度較高,但在保證數(shù)據(jù)集個數(shù)一定多的條件下,也有助于提升分類性能。因此,在今后的實驗中可以通過不斷增加數(shù)據(jù)集的個數(shù)來檢測分類器的性能。從圖4中還能發(fā)現(xiàn),對于維度最高的InlineSkate數(shù)據(jù)集,在使用單個ELM分類器分類時,由于單個分類器往往存在不穩(wěn)定性,導致每次得到的預測精度大小差別較大,因此所求得的平均值較低。本文提出的E-PSO-RELM加權集成方法,對分類器賦予不同的權值,有效地改善了這種缺陷,同時也較好地提升了分類器的分類性能。然而,由于PSO屬于一個迭代過程,在訓練及分類過程中均需要一定的時間進行迭代,相比于其他2種方法在運行效率方面仍有一定的缺陷。
6 結束語
時間序列數(shù)據(jù)有效分類在人們日常生活中變得越來越重要。針對時間序列數(shù)據(jù)中通常伴有大量環(huán)境噪聲的問題,本文結合小波包去噪方法的優(yōu)勢,通過閾值量化處理小波包系數(shù),有效地去除了噪聲。針對時間序列數(shù)據(jù)維度高、數(shù)據(jù)量較大的特性,本文提出的基于RELM的時間序列數(shù)據(jù)加權集成分類方法,充分利用了PSO算法的優(yōu)勢以及各個RELM基分類器之間的信息互補性,實現(xiàn)了對時間序列數(shù)據(jù)的有效分類。在仿真實驗中,將本文方法與目前典型的時間序列分類方法進行了性能對比,結果表明:本文所提出的分類方法優(yōu)于其他3種對比方法,通過有效提高分類的預測精度和泛化性能,進而有效提升了對時間序列數(shù)據(jù)的分類性能。
猜你喜歡
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
