基于預(yù)訓(xùn)練與答案選擇模型的機(jī)器問答研究1
2022-12-27 00:49:16周浩軒周筠昌孫晶萌陳珂
廣東石油化工學(xué)院學(xué)報 2022年6期
周浩軒,周筠昌,孫晶萌,陳珂
(廣東石油化工學(xué)院 計算機(jī)學(xué)院,廣東 茂名 525000)
機(jī)器問答(QA)是借助自然語言處理(NLP)技術(shù),使計算機(jī)可以了解和回復(fù)人們用自然語言所提交的問題[1]。傳統(tǒng)機(jī)器問答系統(tǒng)依靠關(guān)鍵字和網(wǎng)頁超鏈接為基礎(chǔ)來實現(xiàn)。隨著時代和技術(shù)的發(fā)展,使用該方式的傳統(tǒng)搜索引擎難以滿足用戶的需求,為了準(zhǔn)確回答用戶提出的問題,采用了自然語言搜索為主要方式,并且?guī)砹烁斓奶幚硭俣龋屪匀徽Z言搜索技術(shù)研究漸漸成為自然語言處理領(lǐng)域的熱門研究[2]。隨著NLP技術(shù)的發(fā)展,深度神經(jīng)網(wǎng)絡(luò)模型開始應(yīng)用到各種自然語言處理任務(wù)中[3]。在機(jī)器問答任務(wù)中使用深度神經(jīng)網(wǎng)絡(luò)模型則不需要再進(jìn)行額外的特征提取,在數(shù)據(jù)預(yù)處理后,即可以訓(xùn)練出語義信息豐富的詞向量,用來代替人工對詞向量進(jìn)行標(biāo)注[4]。因此,基于深度神經(jīng)網(wǎng)絡(luò)的機(jī)器問答模型在性能上遠(yuǎn)遠(yuǎn)優(yōu)于傳統(tǒng)模型。
目前,在大量研究中采用深度神經(jīng)網(wǎng)絡(luò)作為編碼器來提取句子的特征,并用向量表示,進(jìn)一步減少人工提取特征的步驟[5]。Wang等[6]對句子進(jìn)行詞匯語義的分解和組合,計算每個單詞的語義匹配向量進(jìn)行相似度學(xué)習(xí)。Chen 等[7]提出了一個協(xié)作對抗網(wǎng)絡(luò)(CAN),通過使用一個生成器和鑒別器對兩個句子之間的共同特征進(jìn)行建模,也檢測了兩個句子中的對齊詞并吸收其上下文,進(jìn)一步對遞歸神經(jīng)網(wǎng)絡(luò)(RNN)的隱藏狀態(tài)建模。Rzayev等[8]提出了一種集成的方法,將細(xì)粒度的問題分類與為答案選擇任務(wù)設(shè)計的深度學(xué)習(xí)模型相集成。受到上述研究和Bert(bidirectional encoder representations from transformers)模型的啟發(fā),本文提出了一種基于Bert模型的答案選擇型機(jī)器問答方法。
1 模型結(jié)構(gòu)
基于Bert的問答模型不同于傳統(tǒng)模型,在不需要其他模塊的情況下可以直接向用戶輸出答案。該模型包括預(yù)處理模塊、預(yù)訓(xùn)練模塊和答案選擇模塊。預(yù)處理模塊主要處理輸入的問題和回答,進(jìn)行分詞、刪除停止詞、低頻詞、非正式文本以及詞性替換的內(nèi)容,分詞模塊采用了jieba中文詞庫進(jìn)行分詞,在數(shù)據(jù)清洗后將處理后的句子傳遞給下一部分。預(yù)處理后,句子被送入預(yù)訓(xùn)練模型中,進(jìn)行特征提取操作,該方法可以有效地讓機(jī)器通過矩陣權(quán)重理解自然語言,隨后輸出的特征向量將帶有深層語義信息;語義特征向量通過進(jìn)入預(yù)訓(xùn)練Bert微調(diào)模型解碼模塊輸出,送入答案分類模型,得到候選答案。模型架構(gòu)如圖1 所示。
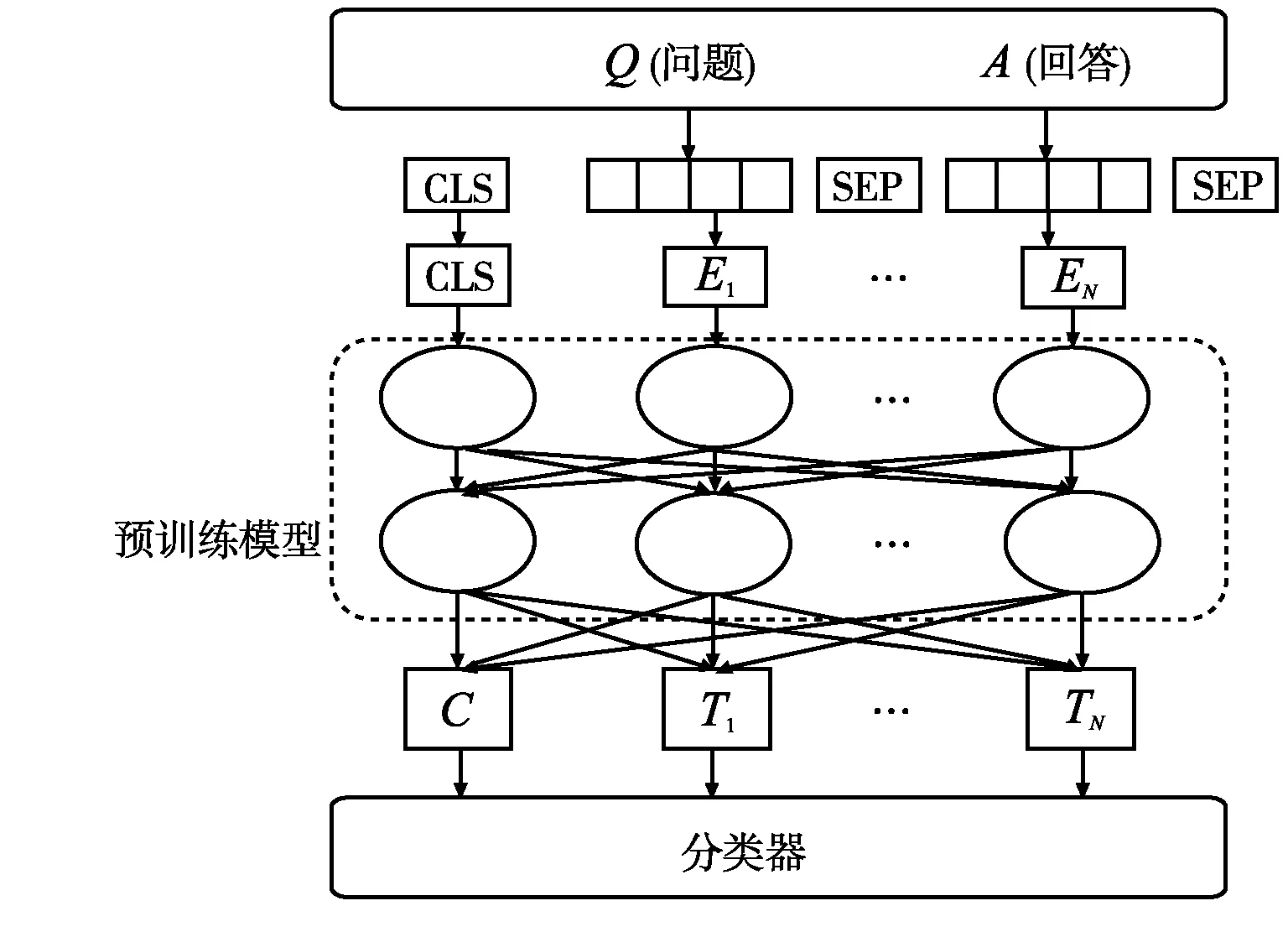
圖1 基于Bert模型的機(jī)器問答結(jié)構(gòu)
1.1 Bert預(yù)訓(xùn)練
Bert的核心是一個Transformer模型,具有可變數(shù)量的編碼層和自我注意力模型。當(dāng) Bert 模型進(jìn)行預(yù)訓(xùn)練形成語言表示模型后,只需要對模型進(jìn)行遷移學(xué)習(xí)網(wǎng)絡(luò)訓(xùn)練,即可應(yīng)用于下游特定性語言處理任務(wù),對字級、句級、句對級的自然語言處理任務(wù)均適用。 Bert的兩個主要步驟是預(yù)訓(xùn)練和微調(diào)。預(yù)訓(xùn)練的目的是先在未標(biāo)記數(shù)據(jù)上進(jìn)行訓(xùn)練;而微調(diào)則是預(yù)訓(xùn)練會對其參數(shù)進(jìn)行初始化,再用下游任務(wù)訓(xùn)練后產(chǎn)生的標(biāo)記數(shù)據(jù)對Bert模型所有參數(shù)進(jìn)行微調(diào)[9]。
在Bert模型預(yù)訓(xùn)練主要有兩個任務(wù),分別是掩碼語言模型(MLM)和下一句預(yù)測(NSP)。MLM任務(wù)使用了Mask(面具)對15%已分類的單詞進(jìn)行屏蔽,然后通過Bert模型進(jìn)行預(yù)測,并利用最終的損失函數(shù)計算被遮蓋住的標(biāo)記,該任務(wù)的目的是關(guān)注語料集中的每個詞語,從而得到更準(zhǔn)確的上下文的語義信息。NSP的目的是讓模型理解句子間的關(guān)聯(lián)性,可在任何一個級別語料庫進(jìn)行訓(xùn)練,對句子對A和B,B有一半的概率是緊隨A的實際下一句(IsNext),另一半概率則是語料庫中的隨機(jī)句子(NotNext)。將這個句子對進(jìn)行拼接時在句首添加標(biāo)識[CLS],A、B間則用標(biāo)識[SEP]分隔開來,并對[CLS]做一個二分類任務(wù)。
1.2 BiLSTM網(wǎng)絡(luò)模型
長短記憶網(wǎng)絡(luò)(LSTM)是循環(huán)神經(jīng)網(wǎng)絡(luò)的一種改進(jìn),通過加入細(xì)胞狀態(tài)、記憶門、遺忘門、輸出門等結(jié)構(gòu)[10],使網(wǎng)絡(luò)更適合學(xué)習(xí)長距離依賴關(guān)系。
1.3 基于全連接神經(jīng)網(wǎng)絡(luò)模型的答案選擇模型
在Devlin等[10]所提方法的基礎(chǔ)上加以改進(jìn),將1.1節(jié)得到的[CLS]向量作為輸入向量送入全連接神經(jīng)網(wǎng)絡(luò)模型(FC模型)中進(jìn)行分類(見圖2)。全連接的隱藏層大小為1024,輸入一維向量,長度為768,輸出層大小為2。經(jīng)過Softmax函數(shù)后,以概率形式進(jìn)行輸出。對數(shù)據(jù)進(jìn)行清洗過程,此時文本數(shù)據(jù)格式進(jìn)行轉(zhuǎn)換,其表示為Input=Bertpro(Q,A);Bert模型輸入為(ECLS,E1,…,EN)=Bert(Input);FC模型的relu激活函數(shù)為HL=relu(Wh1ECLS+bh1);歸一化指數(shù)函數(shù)為f(Q,A)=Softmax(Wh2HL+bh2)。其中,Wh1∈R768×1024、Wh2∈R1024×2為FC輸出層參數(shù)矩陣;bh1∈R1024、bh2∈R2為偏置函數(shù)。
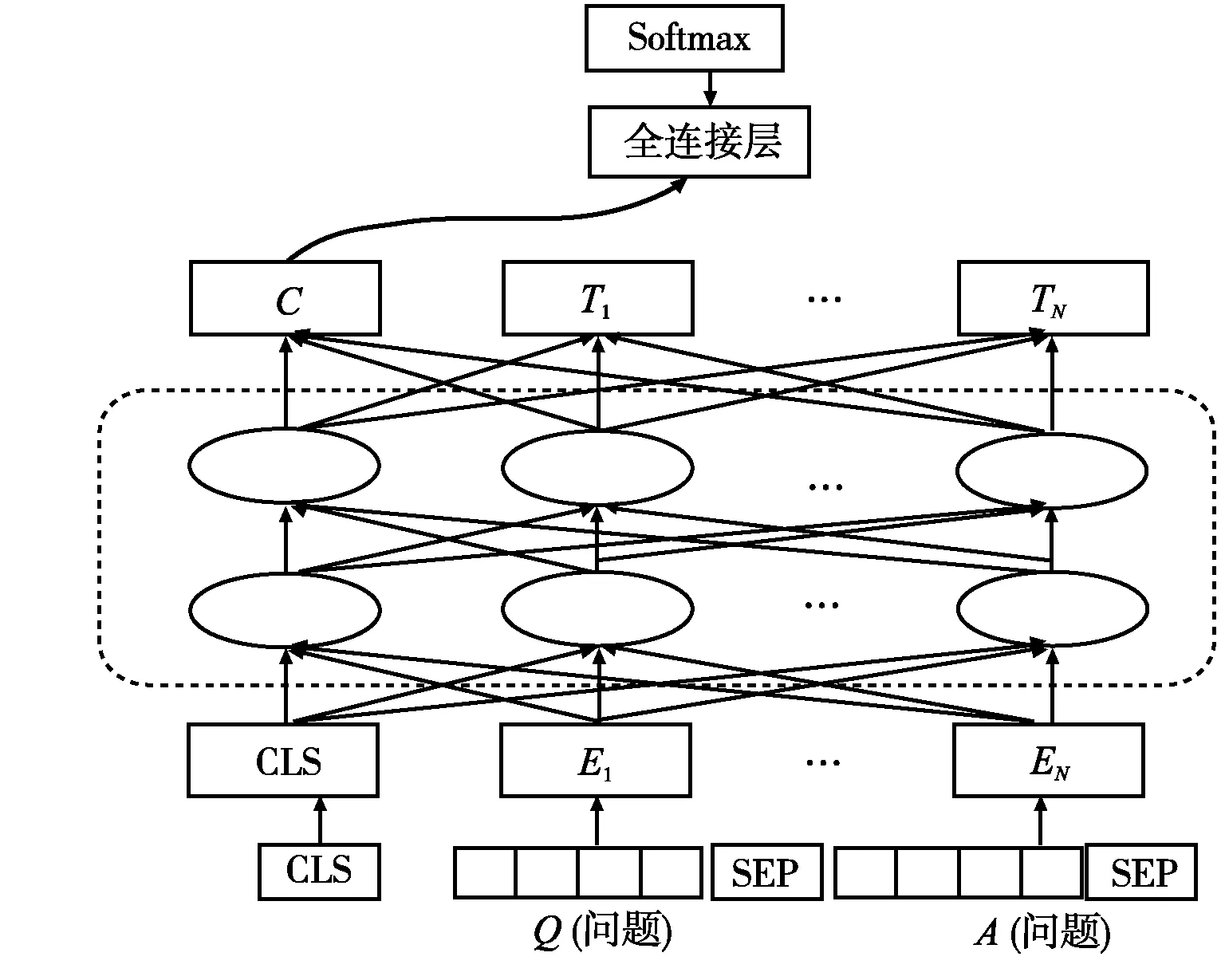
圖2 預(yù)訓(xùn)練Bert模型+FC模型結(jié)構(gòu)
1.4 基于BiLSTM的答案選擇模型
模型的輸出由雙向LSTM模型中隱藏層輸出拼接而成,輸入向量在Bert模型中不同層中對預(yù)測結(jié)果會產(chǎn)生不同影響,因此,提取出Transformer模型和Bert模型中不同層的輸出向量,對這些向量合成拼接,送入BiLSTM中進(jìn)行訓(xùn)練,最終作為全連接神經(jīng)網(wǎng)絡(luò)輸入執(zhí)行分類操作,模型結(jié)構(gòu)如圖3所示。
提取Transformer層問答對的token向量,其輸出向量表示為Tokenlayer=Bertlayer(Input)。
對不同Transformer層問答對的token向量進(jìn)行合成拼接操作,表示為Econcat=fconcat(Tokenlayer1,…,Tokenlayern)
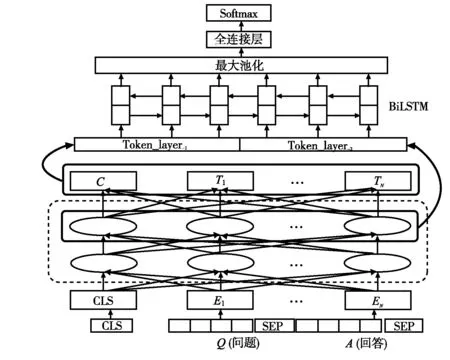
圖3 預(yù)訓(xùn)練Bert+BiLSTM模型結(jié)構(gòu)
將合成拼接后的向量輸入至BiLSTM網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練,得到h=BiLSTM(Econcat)。
最后,進(jìn)行最大池化操作,此時有h0=fpool(h)。
2 實驗分析
2.1 數(shù)據(jù)集選擇
本文采用的數(shù)據(jù)集是由騰訊實驗室提出的中文多輪話題驅(qū)動的對話數(shù)據(jù)集Natural-Conv,它是一個針對多輪話題驅(qū)動的情景對話的中文對話數(shù)據(jù)集,適用于模擬多輪自然對話中的話題互動,該數(shù)據(jù)集的語料庫中的數(shù)據(jù)是以對話為基礎(chǔ)的,基于新聞文章的內(nèi)容展開特定的話題進(jìn)行交流。與常見的數(shù)據(jù)集有所不同:首先,此次對話的參與者可以談?wù)摮掝}外他們想要交流的任何事情,并且在話題間轉(zhuǎn)換十分自然;其次,該語料集的兩位參與者在進(jìn)行對話任務(wù)時是遵循正常邏輯的;最后,該語料集允許在談話中進(jìn)行閑聊和問候。該數(shù)據(jù)集包含了約40萬條預(yù)料和19.9萬個對話,涉及多個領(lǐng)域,平均對話回合約20。
2.2 評價標(biāo)準(zhǔn)
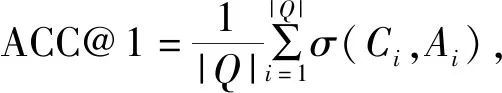
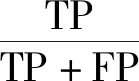
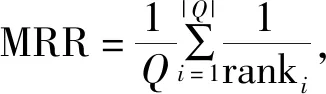
2.3 實驗結(jié)果和分析
本實驗采用的是Google開放域機(jī)器問答競賽項目的金牌項目解決方案,模型為Bert-large ,使用與論文中頭數(shù)相同的4個注意力頭數(shù)的Transformer,全連接網(wǎng)絡(luò)寬度為512,輸入輸出均為512。
本文將Bert+FC模型在Google 的GPU上經(jīng)過50次的迭代訓(xùn)練,平均訓(xùn)練時間為680 min。設(shè)置的Epoch為50,但模型運(yùn)行時,發(fā)現(xiàn)迭代次數(shù)為38次時產(chǎn)生了最優(yōu)模型,再訓(xùn)練無法更加優(yōu)化隨即停止。此時,該模型在訓(xùn)練集和測試集上,損失值與訓(xùn)練迭代次數(shù)的關(guān)系如圖4所示,訓(xùn)練集和測試集上的準(zhǔn)確率與迭代次數(shù)的關(guān)系如圖5所示。
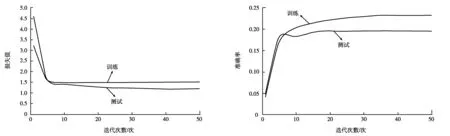
圖4 損失函數(shù)與迭代次數(shù)的關(guān)系 圖5 迭代次數(shù)與準(zhǔn)確率的提升
由圖4、圖5可知,當(dāng)訓(xùn)練次數(shù)約為38次時,所得損失函數(shù)及準(zhǔn)確率趨于穩(wěn)定。
為了比較模型在不同數(shù)據(jù)集上的表現(xiàn),本文又采用了NLPCC-ICCPOL DBQA數(shù)據(jù)集。所選用的NLPCC-ICCPOL DBQA同樣是中文數(shù)據(jù)集,由人工對其進(jìn)行標(biāo)注,訓(xùn)練集和測試集分類如表1所示。該數(shù)據(jù)集中提供的問題,需要模型從一系列候選答案中找出正確的答案語句,每條數(shù)據(jù)由三個部分組成:問題、答案和標(biāo)簽,具體與Natural-Conv數(shù)據(jù)集差距不大。 在兩個數(shù)據(jù)集上,對Bert+FC模型和Bert+BiLSTM模型進(jìn)行驗證,其結(jié)果如表2所示。
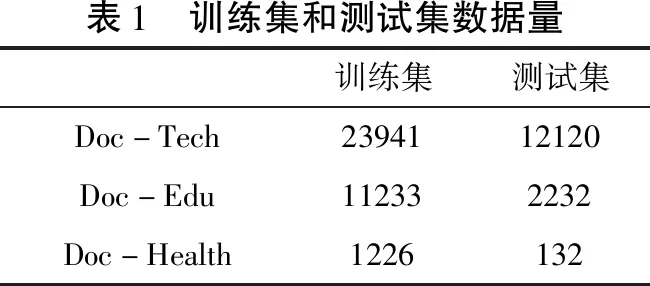
表1 訓(xùn)練集和測試集數(shù)據(jù)量訓(xùn)練集測試集Doc-Tech2394112120Doc-Edu112332232Doc-Health1226132
由表2可知,兩個模型在不同的數(shù)據(jù)集上都取得了較為優(yōu)異的成果,針對Bert+BiLSTM模型,在Natural-Conv數(shù)據(jù)集上的MRR和MAP指標(biāo)相對NLPCC-ICCPOL DBQA高出約1%,而ACC@1指標(biāo)高出約2.8%。整體而言,Bert+BiLSTM模型比Bert+FC模型表現(xiàn)更優(yōu)秀;且Bert+BiLSTM模型和Bert+FC模型在NLPCC-ICCPOL DBQA上的結(jié)果不如Natural-Conv數(shù)據(jù)集。其主要是Natural-Conv數(shù)據(jù)集訓(xùn)練數(shù)據(jù)為181882條,而NLPCC-ICCPOL DBQA訓(xùn)練數(shù)據(jù)為53417條,由此可知,訓(xùn)練數(shù)據(jù)對結(jié)果產(chǎn)生影響十分深遠(yuǎn)。
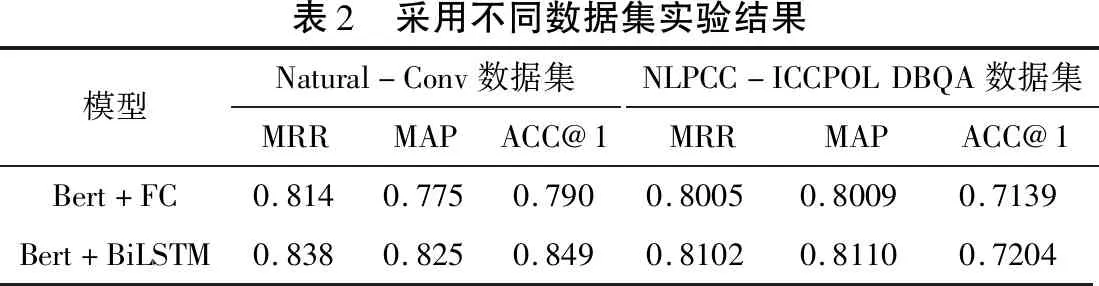
表2 采用不同數(shù)據(jù)集實驗結(jié)果模型Natural-Conv數(shù)據(jù)集MRRMAPACC@1NLPCC-ICCPOLDBQA數(shù)據(jù)集MRRMAPACC@1Bert+FC0.8140.7750.7900.80050.80090.7139Bert+BiLSTM0.8380.8250.8490.81020.81100.7204
對比2020年Github公布在Natural-Conv數(shù)據(jù)集上最新的任務(wù)評測數(shù)據(jù),其結(jié)果如表3所示。
由表3可看出,本文提出的答案選擇模型效果相比其他大部分模型較為有效。Bert+FC模型在MRR、MAP、ACC@1三個評價指標(biāo)上較為優(yōu)異,這證明相比沒采用預(yù)訓(xùn)練Bert微調(diào)模型的其他模型,本文模型在數(shù)據(jù)處理時有更大優(yōu)勢;Bert+BiLSTM模型在MRR、MAP、ACC@1三個評價指標(biāo)中與Bert+FC模型相比,不分伯仲,這證明了本文采用的基于預(yù)訓(xùn)練Bert模型微調(diào)策略的有效性。表3中的模型大多單一采用BiLSTM模型和Transformer模型作為學(xué)習(xí)模型,相比而言,本文的基于預(yù)訓(xùn)練Bert微調(diào)模型在獲取文本語義、上下文信息方面有著更為顯著的優(yōu)勢。
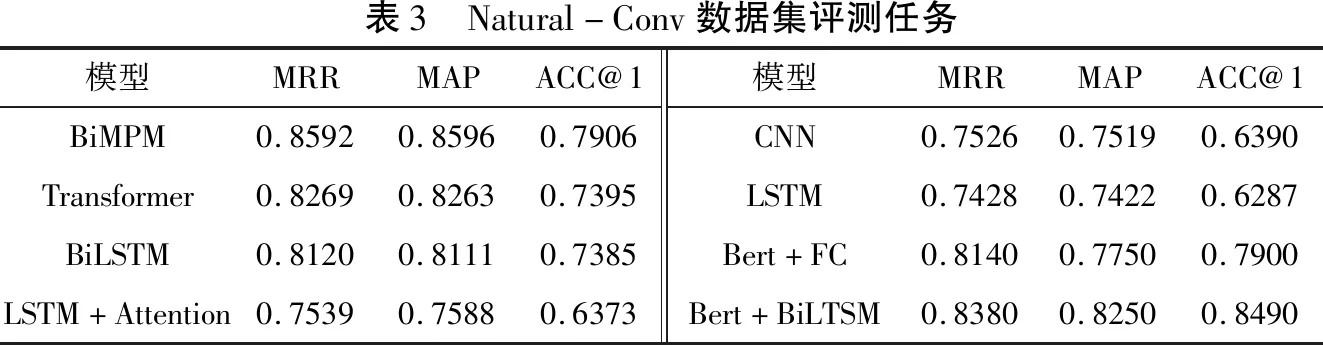
表3 Natural-Conv數(shù)據(jù)集評測任務(wù)模型MRRMAPACC@1BiMPM0.85920.85960.7906Transformer0.82690.82630.7395BiLSTM0.81200.81110.7385LSTM+Attention0.75390.75880.6373模型MRRMAPACC@1CNN0.75260.75190.6390LSTM0.74280.74220.6287Bert+FC0.81400.77500.7900Bert+BiLTSM0.83800.82500.8490
3 結(jié)語
本文研究了基于Bert模型的機(jī)器問答技術(shù),采用了預(yù)訓(xùn)練Bert模型的使用方式和微調(diào)方式,使用FC模型和BiLSTM模型與其相結(jié)合構(gòu)建出新的模型。并在Natural-Conv數(shù)據(jù)集和NLPCC-ICCPOL DBQA數(shù)據(jù)集上,對本文采用的方法和模型都做出了實驗驗證。結(jié)果表明,相對傳統(tǒng)的深度學(xué)習(xí)模型來說,基于預(yù)訓(xùn)練Bert模型的答案選擇模型性能有著明顯的提高。在實驗過程中發(fā)現(xiàn)Bert預(yù)訓(xùn)練模型對數(shù)據(jù)量大小也十分敏感,但由于在微調(diào)階段參數(shù)過多,需要多次調(diào)試才能達(dá)到最佳性能。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
開放教育研究(2020年2期)2020-03-31 01:54:14
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
現(xiàn)代語文(2016年21期)2016-05-25 13:13:44
核科學(xué)與工程(2015年4期)2015-09-26 11:59:03
大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11
當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
外語學(xué)刊(2011年1期)2011-01-22 03:38:33
